MVSim:面向VLIW多核向量处理器的快速、可扩展和精确的体系结构模拟器
2024-02-28邓让钰钱程东
刘 仲,李 程,田 希,刘 胜,邓让钰,钱程东
(1.国防科技大学计算机学院,湖南 长沙 410073;2.先进微处理器芯片与系统重点实验室,湖南 长沙 410073;3.天津先进CPU企业重点实验室,天津 300000)
1 引言
随着人们对计算能力需求的不断增长,处理器体系结构变得越来越复杂。例如,AMD在2021年11月9日正式发布的Instinct MI200 GPU加速卡[1],单芯片64位浮点峰值性能高达144 TFlops,总共有580亿个晶体管,包含多达220个计算单元以及880个矩阵内核。设计和制造这样一个复杂的处理器所需要的时间成本和资金成本是极其高昂的。通常,生产一款新的处理器需要经过体系结构设计、设计评估与验证、逻辑设计与验证、电路设计与验证、布局设计和生产制造等多个阶段。而且,这里的每一个阶段都需要多次迭代以保证质量。从时间成本上看,该过程通常会持续2~5年甚至更长时间;从资金成本上看,现有新工艺的芯片开发成本都是数亿元级别以上。因此,为了降低处理器的设计风险,迫切需要研究高质量的模拟器,通过软件模拟技术降低设计成本和缩短设计周期。
深度神经网络技术在图像识别与分类、目标检测、视频分析、语音识别、自然语言处理等方面取得了令人瞩目的成就。通用CPU具有很高的灵活性和较好的并行计算能力,但是深度神经网络算法并不能取得很高的计算效率。GPU因为其特有的多核结构和出众的并行计算能力而被广泛应用于深度神经网络的训练和推理,但其功耗较大。超长指令字VLIW(Very Long Instruction Word)架构体系结构因性能高、功耗低等优点一直在DSP领域被广泛使用。Intel在VISION 2022大会公布了基于VLIW SIMD架构的新款AI专用芯片Habana Gaudi 2和Greco[2],使得VLIW SIMD架构成为了深度学习加速器的重要研究方向之一。
2 相关工作
在新的体系结构研究与设计中,模拟器是不可缺少的工具。因此,处理器体系结构软件模拟技术一直是学术界和工业界非常重要的研究内容[3,4]。
gem5[5]是一个全系统模拟器,能够在其支持的特定硬件上启动Linux、Solaris和Android操作系统。SimpleScalar是学术界广泛使用的体系结构模拟器,可根据模拟需求配置成不同体系结构的模拟器,如仅模拟ISA的sim-safe、对执行性能进行优化的sim-fast[6]、支持推测和乱序执行的超标量处理器性能模型的sim-outorder、支持向前或向后执行程序的Simics[7]、支持Alpha处理器的功能模拟器SimCore[8]、支持多线程微架构模拟的MSim(Multithreaded architectural Simulation)[9]和支持功耗模拟的SimWattch[10]。QEMU(Quick EMUlator)[11]是一个通用模拟器和虚拟机,其采用二进制指令翻译技术,通过提取guest代码,将其翻译成TCG中间代码,最后再将中间代码翻译成host指定架构的代码,如x86或ARM体系结构。文献[12]提供了千核系统的快速准确的微体系结构模拟。德州仪器TI(Texas Instruments)[13]公司提供了CCS(Code Composer Studio)集成开发环境,集编辑、编译、链接、软件仿真、硬件调试及实时跟踪等功能于一体,极大地方便了用户对DSP芯片的开发与设计。CCS开发环境自带了TI公司各种处理器的软件模拟器,在CCS配置中选择对应型号的Simulator CPU之后,就可以加载程序代码,模拟程序在该型号CPU上的运行情况。其缺陷是模拟不够完善,仅仅是对DSP芯片内部运行状况的模拟,无法模拟DSP与外设之间的操作。
尽管与模拟器相关的研究文献很多,开源社区也有许多知名的模拟器项目,但迄今为止,没有看到与VLIW SIMD多核向量处理器相关的模拟器和文献。为了对VLIW SIMD多核向量加速器体系结构进行深入研究和对设计空间进行探索,本文设计了一个快速、可扩展和精确的多核向量体系结构模拟器MVSim(Multi-core Vector Simulator)。MVSim根据处理器的指令集体系结构,用软件模拟的方式实现了处理器的逻辑功能实现,能够节拍精准地模拟硬件处理器对程序指令的运行处理过程,提供程序指令执行、寄存器读写、存储器访问、DMA(Direct Memory Access)传输等执行过程的完整记录。实际使用情况证明,该模拟器软件对处理器的设计具有非常重要的作用:(1)由于处理器的设计工程量巨大,且芯片的投片成本极高,任何不恰当的设计都将带来巨大损失。模拟器可以预先模拟程序执行流程,反馈设计是否满足需求,从而改进处理器设计。(2)模拟器有助于芯片设计过程中的芯片测试与验证,通过对照检查RTL测试结果与模拟器执行结果能及时发现设计错误。(3)模拟器能够模拟运行程序在处理器上的执行过程,支持完整的程序执行日志;能对程序指令执行、寄存器读写、存储器访问、DMA数据传输等执行过程进行完整的记录;能够快速定位程序错误原因,有助于应用程序的开发、调试和性能分析。(4)模拟器可以提供给潜在用户进行早期应用开发,有助于加速芯片的应用推广和用户应用的快速开发与部署。
3 MVSim的设计与实现
3.1 MVSim的软件架构
多核模拟器的总体框架如图1所示,其核心主要包括以下3个部分:

Figure 1 Framework of multi-core simulator图1 多核模拟器的总体框架
(1)硬件抽象模型。基于现有的多款VLIW架构多核处理器,深入研究其指令集体系结构,抽象、分析与归纳其底层硬件描述。构建了可扩展的、通用的指令取指、指令译码、指令执行、访存、Cache管理、硬件资源冲突检测机制、DMA数据传输和多核通信模型。
(2)性能评价模型。基于现有的多款VLIW架构多核处理器,构建了通用的程序执行性能模型、Stall和Busy统计模型、访存性能模型和DMA数据传输性能模型。
(3)多核模拟器内核。基于现有的多款VLIW架构多核处理器,通过深入研究其体系结构,构建了通用的程序加载、执行、调试和性能统计模型。
3.2 多核向量处理器模型
如图2所示,MVSim的目标多核向量处理器包含多个VLIW SIMD向量处理器核心VPC(Vector Processor Core),VPC通过CrossNet数据网络共享高速全局共享存储器和大容量片外HBM/DDR存储系统。单个VPC包括取指单元、指令派发单元、标量处理单元SPU(Scalar Processing Unit)、向量处理单元VPU(Vector Processing Unit)、阵列存储单元AM(Array Memory)和DMA等。
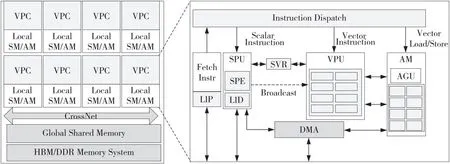
Figure 2 Multi-core processor model of VLIW SIMD architecture图2 VLIW SIMD架构的多核处理器模型
取指单元根据指令流控完成指令的获取操作。该单元包含L1P 程序Cache,当L1P不命中时,自动向外部发出取指失效请求,每次请求粒度为一个取指包。取指部件将获取到的指令包发送给指令派发单元。
指令派发单元接收到指令包后,将执行指令从指令包中提取出来,发送到SPU、VPU和AM中并发执行。当前的VPC采用11发射的VLIW结构(标量5流出,向量6流出),单条指令采用可变长编码(目前支持16/32位、40/80位)。
SPU包括指令流控、SPE(Scalar Processing Element)和标量存储SM(Scalar Memory)。指令流控包括分支、中断/异常控制等,用于控制程序流。SPE接收指令派发单元派发的标量运算类指令,译码后送到SPE内对应的功能运算单元执行。SPE内部集成了3个运算单元,包括2个SMAC(Scalar Multiply ACcumulate)和1个SIEU(Scalar Integer Element Unit)。2个SMAC运算单元同构,支持标量半精度、单精度和双精度浮点乘加操作;SIEU支持标量定点运算。每个标量运算单元,对应VLIW执行包中的一条标量指令。SPE内包含64个32/64位的通用寄存器。
SM实现标量数据的访存和控制,支持一条标量访存指令或地址加减法指令,可实现标量访存指令对核内外可见的数据空间和配置空间的访问。SM存储容量可配置,支持配置为Cache或SRAM的2种访问模式。配置为SRAM模式时,通过DMA实现SM与核外的数据搬移。
VPU由16(可配置)个同构的VPE(Vector Processing Element)构成。VPE内部集成了4个VMAC(Vector Multiply ACcumulate)运算单元,VMAC支持半精度、单精度和双精度浮点的向量乘加操作。VPE内包含64个32/64位的局部通用寄存器。
DMA单元接收SPU配置的传输参数,启动对特定存储资源的访问。这种数据传输通过DMA通用通道实现,包含读操作和写操作。DMA访问的存储资源包括:片上AM存储器、片上SM存储器、片外HBM(High Bandwidth Memory)/DDR(Double Data Rate)存储空间,全局共享存储配置而成的SRAM(Static Random Access Memory)空间。DMA支持点对点、组播和广播3种传输模式。
3.3 VPC指令集体系结构的模拟
3.3.1 取指包和执行包格式
VPC采用VLIW体系结构,可变长的指令编码使得编译器能够根据计算需求选择不同长度的指令,便于程序代码和性能优化。MVSim支持2种可变长的指令编码:32位处理器采用16/32位指令编码;64位处理器采用40/80位指令编码。根据目标应用的需求,可以很容易地扩展到其他格式的指令编码。这里以64位处理器为例进行介绍。
取指包和执行包的格式如图3所示。所有指令均为40/80位指令,指令长度通过指令编码的第2~3位值进行区分。处理器每次从外存中取出512位的取指包,取指包内包含1个以上的执行包,2个执行包之间无填充,执行包边界由指令的并行位决定。指令中的并行位P(第0位)的含义是:P=0表示本条指令与下一条指令不在同一个执行包中;P=1表示本条指令与下一条指令在同一个执行包中。一个执行包按40 位对齐,包括标量指令与向量指令。
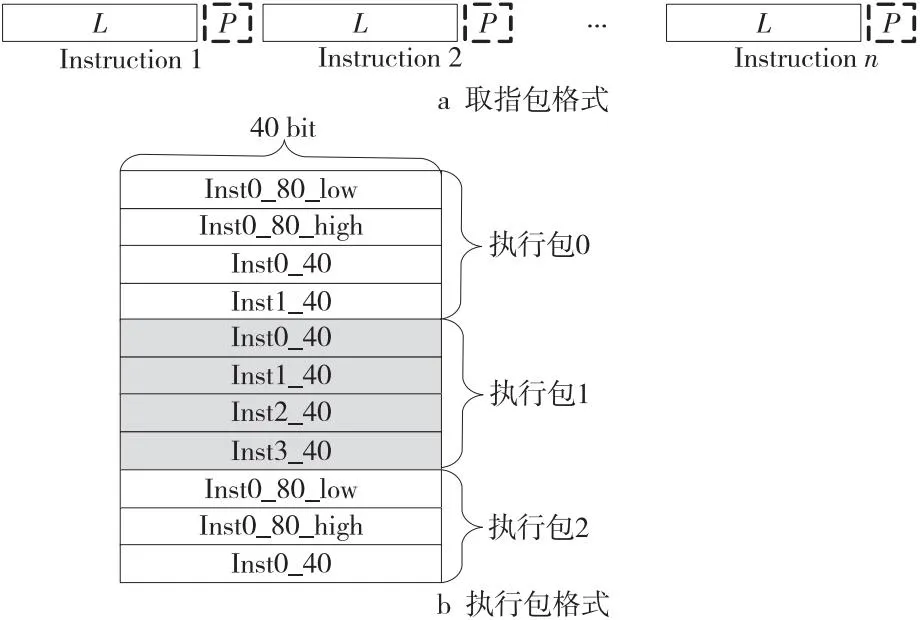
Figure 3 Formats of instruction fetch packet and execution packet图3 取指包和执行包的格式
一个执行包内80位指令集中在前面,40位指令集中在后面。一个执行包至多包含4条80位指令,且一个执行包大小不超过480 bit。处理器包含5个标量部件和6个向量部件。因此,一个执行包可包含1~11条指令,其长度为5~60个字节。执行包的构成为x*80+y*40格式,其中x和y均大于0且满足:
(1)x≤4;
(2)y≤11;
(3)x+y≤11;
(4)x*80+y*40≤480。
图3b描述了多个执行包在存储器中的位置,其中,80_low表示80位指令的低40位,80_high表示80位指令的高40位,40表示40位指令。
3.3.2 取指和指令解码
VPC的指令根据操作数的个数和种类分别划分为长立即数MOV指令(40位、80位)、长立即数分支指令、长立即数Load/Store 指令、单操作数指令、双操作数指令和三操作数指令。以三操作数指令为例说明如何根据指令格式进行指令解码。三操作数指令编码格式如图4所示。

Figure 4 Encoding format of three-operand instructions图4 三操作数指令编码
VPC的指令支持条件操作,Reg字段用以标识条件寄存器编号。Z字段用于条件判断,若Z=0,则条件寄存器为非0时执行当前指令;若Z=1,则条件寄存器为0时执行当前指令。V字段用以标识标量或向量指令,若V=0则当前指令为标量指令,若V=1则当前指令为向量指令。P字段标识当前指令是否与下一条指令并行执行,若P=0,则当前指令不与下一条指令并行执行,若P=1,则当前指令与下一条指令并行执行。Dst、Src1、Src2、Src3字段分别标识当前指令的目的、源操作数1、源操作数2、源操作数3的寄存器编号。OP字段用以标识执行指令的操作码。Type字段用以标识当前指令所属功能单元和指令分类。
VPC的取指过程如下所示:
pos=0;
do{
readBufferFrom(&next_inst,currentPC+pos.InstLen);
type=parser(next_inst);
switch(type){
caseLONGIMMMOV40:
decodeLongImmMov40(next_inst);
break;
caseLONGIMMMOV80:
decodeLongImmMov80(next_inst);
break;
caseLONGIMMBRANCH:
decodeLongImmBranch(next_inst);
break;
caseLONGIMMLOATSTORE:
decodeLongImmLoatStore(next_inst);
break;
caseONEOPERATION:
decodeOneOperation(next_inst);
break;
caseTWOOperation:
decodeTwooperation(next_inst);
break;
caseTHREEOperation:
decodeThreeoperation(next_inst);
break;
)while(next_inst[0]&1)
模拟器循环读取取指包,直到读取的指令的P字段值为0为止。对读取到的每一条指令,解析指令的Type字段,根据解析到的字段值将指令派发到不同指令类型的解码函数。解码函数根据指令编码格式执行详细的指令解码。
3.4 多级存储体系结构模型
多核处理器的多级存储体系结构模型如图5所示,共包含4个层级。
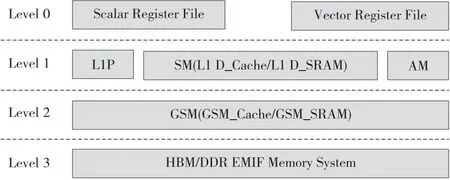
Figure 5 Multi-level storage architecture model图5 多级存储体系结构模型
第0级:VPC的标量寄存器文件和向量寄存器文件;
第1级:VPC的L1P、标量存储器(可配置为L1D Cache或SRAM模式)和阵列存储器;
第2级:全局共享存储器(可配置为全局共享Cache或SRAM模式);
第3级:片外的大容量HBM/DDR、EMIF的数据空间。
其中第1级的标量存储可配置为L1D Cache或SRAM模式,第2级的全局共享存储可配置为全局共享Cache或SRAM模式。
L1P缺省配置为2路组相联Cache,Cache容量(capacity)为64 KB,Cache行大小(line size)为64 B,CPU(access time)访问时间为1个时钟周期,Cache行分配策略为读分配。Cache替换策略为最近最少使用的Cache行被替换,且标记新载入的Cache行最近被使用。
数据Cache支持2级Cache(第1级的标量存储可配置为L1D Cache,第2级的全局共享存储可配置为全局共享L2D Cache)。数据Cache访存分为命中和缺失。若是读缺失,则向下一级Cache或存储发送缺失请求,并返回缺失数据,Cache行依据LRU替换策略。若是写缺失,则采取写回写分配策略,先从下一级Cache或存储读取缺失数据,并依据LRU替换策略替换旧的Cache行,再执行写操作。若是读命中,命中的Cache行数据返回给CPU,同时更新LRU位。若是写命中,采用写回策略将数据写入Cache。当Cache行被改写时,该行的对应的Dirty位被置1,记为脏行。当脏行因为其他的缺失被替换时,需要将脏行写回至数据空间。
为方便使用和灵活扩展,Cache模块的各种参数均设计为可配置,包括Cache容量(capacity)、Cache行大小(line size)、Cache组大小(ways)、CPU access time、Single read miss stall、Write miss等。
3.5 DMA的模拟
MVSim支持以下3种DMA数据传输模式:
(1)点对点传输模式。点对点传输是指VPC核通过DMA发起的片上存储器(SM和AM)和片外存储器(GSM和HBM/DDR)之间的数据交换。每次DMA启动可完成一个一维或二维数据块的传输。
(2)分段传输模式。分段传输是指DMA从片外存储器(GSM和HBM/DDR)中读取连续数据段,并根据数据分段模式向多个VPC核发送数据段,不同VPC可接收不同的数据段。数据分段模式是程序员可配置的,其决定每个数据段的目标核,如第1段数据发给哪些核,第2段数据发给哪些核等。数据分段模式由分段传输控制寄存器控制,包含4个字段:循环分段模式、循环次数、循环步长和分段粒度。循环分段模式是指数据返回给多个VPC内核的形式;循环次数是指移位的次数;循环步长是指下一段数据传输时循环分段模式右移的长度;分段粒度是指每一段数据的长度。
(3)广播传输模式。广播传输指的是DMA将从HBM/DDR读取的一个数据块发送至所有目标核。
上述模式中,点对点传输由每个核独立控制,数据传输过程中不需要与其他核进行同步。而分段传输和广播传输都是由一个主机核进行配置和启动,从机核进行计数,多核之间需要通过栅栏机制完成同步。
3.6 多核栅栏同步的模拟
多核栅栏同步的模拟过程如图6所示。由于目标多核处理器的核间共享了GSM和HBM/DDR存储空间,需要设计硬件栅栏机制实现多核同步。硬件栅栏同步功能是通过Load指令访问存储器完成。所有的栅栏同步单元全局统一编址,通过访问Memory Map Register的地址进行栅栏同步操作。栅栏同步单元用于多核间的相互等待,当多个核需要在某个点进行同步的时候需要用到栅栏同步操作。所有的栅栏实例对程序员透明,程序员仅需明确参与同一栅栏同步的处理器核和核数量,以及赋予同一栅栏同步的编号。
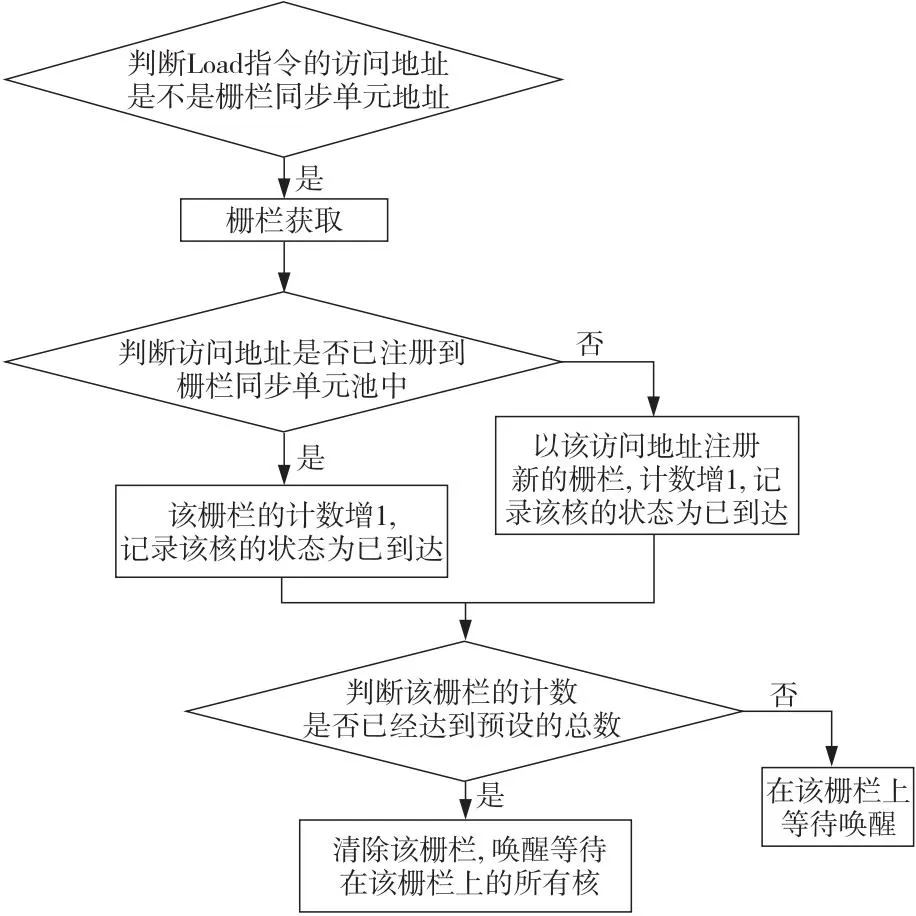
Figure 6 Simulation process of multi-core fence synchronization图6 多核栅栏同步的模拟过程
Address[31:20](=12’h301)表明这是访问栅栏同步单元的操作。Address[19]设置为0表示是栅栏同步请求,设置为1表示对栅栏同步单元寄存器进行配置。Address[7:4]为此次栅栏同步编号,所有参与同一栅栏同步的处理器核通过该编号确认是不是同一次栅栏同步。Address[11:8]表示参与此次栅栏同步的处理器核总数。
3.7 多核处理器的模拟及性能模型
MVSim采用多线程模拟多核向量处理器,用一个主线程模拟多核向量处理器,读取配置文件,根据核数创建相应数量的线程,每一个VPC核用一个线程模拟。因此,MVSim是用主机上的一个多线程程序来模拟目标处理器上的一个多核程序运行。这种方法一方面尽可能真实地模拟了多核程序的并发执行,同时也尽可能多地利用了主机的多核处理器资源,大幅度提高了模拟器的运行速度。每个线程记录了对应VPC核的所有运行状态,包括详细的程序指令执行、寄存器读写、存储器访问、DMA数据传输、Cache访问、性能统计等。主线程一直运行,直到所有线程结束。最后,输出每个线程的运行日志,取所有核的运行时间最大值作为多核程序的运行时间。
如图7所示,影响程序执行时间的因素包括:程序指令执行时间、内存访问时间、访存冲突引起的流水线停顿时间和DMA数据传输时间。程序指令执行时间是指指令数据就绪情况下的指令执行时间。内存访问时间Tmem是指程序指令执行过程中因取指或取数发生的存储访问时间,其计算如式(1)所示:
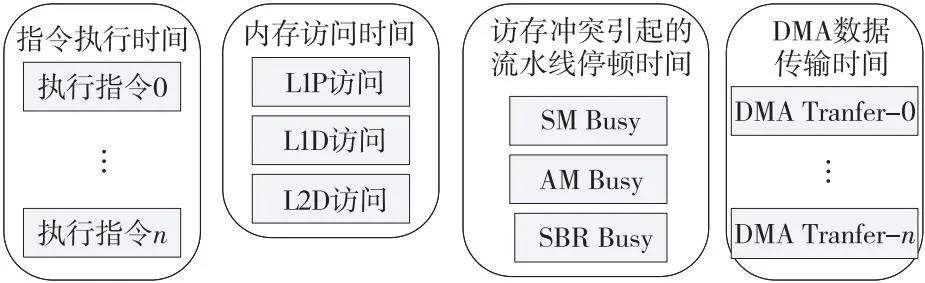
Figure 7 Factors affecting program execution time图7 影响程序执行时间的因素
Tmem=countHit*timeHit+
countMiss*penaltyMiss
(1)
其中,countHit、timeHit分别为Cache命中时的次数和访存时间,countMiss、penaltyMiss分别为Cache不命中时的次数和访存时间。countHit和countMiss由模拟器根据程序运行情况统计得到,而timeHit和penaltyMiss是可配置的,根据模拟的目标处理器情况在模拟器配置文件中进行修改。
访存冲突引起的流水线停顿时间主要包括以下3类:
(1)SBR Busy时间:分支目标所在的执行包跨了取指包边界会引起流水线停顿,该停顿时间记为TSBR;
(2)SM Busy时间:标量Load/Store指令与DMA访问标量存储器的同一个存储体(Bank)时,会导致访问冲突,该冲突引起的流水线停顿时间记为TSM。
(3)AM Busy时间:2条向量Load/Store指令同时访问一个Bank,或者向量Load/Store指令与DMA访问阵列存储器的同一个Bank时,会导致冲突,该冲突引起的流水线停顿时间记为TAM。
DMA数据传输时间TDMA是根据传输数据量Total_Byte与平均数据传输带宽Bm得到的,具体计算如式(2)所示:
TDMA=Total_Byte*Bm
(2)
其中,Total_Byte由模拟器根据程序运行情况统计得到;平均数据传输带宽Bm是可配置的,根据模拟的目标处理器情况在模拟器配置文件中进行修改。平均数据传输带宽按照源地址与目的地址的不同分为6类(GSM to SM,GSM to AM,DDR to SM,DDR to DDR,DDR to GSM),可以预先分别进行测试与统计,取其平均值作为模拟器的配置参数。
由于DMA传输是后台操作,与程序指令执行时间重叠。每次DMA事务结束时,根据DMA数据传输时间对程序指令执行时间进行修订。设DMA启动与结束时刻的当前程序指令执行时间分别为Time0和Time1,当次计算得到的DMA数据传输时间为TDMA。若TDMA>(Time1-Time0),则修订后的当前程序指令执行时间为Time1=Time0+TDMA,否则保持不变。
第i个核上程序执行时间为Ti如式(3)所示:
Ti=TSBR+TSM+IAM+Tx
(3)
其中,Tx表示修订后的当前程序指令执行时间。
最后取所有核上程序执行时间最大值作为程序的执行时间,如式(4)所示:
T=max(Ti)
(4)
4 实验测试与结果评估
本文测试集包括7个关键算法(单核和多核、单精度和半精度)的28个程序,用于测试和评估MVSim的准确性和性能。表1描述了这些算法及其输入参数。后续测试程序名称以首字母区分精度(如单精度gemm用sgemm表示,半精度gemm用hgemm表示);以后缀数字区分单核和四核测试程序(如单精度单核gemm用sgemm_1表示,如单精度四核gemm用sgemm_4表示)。

Table 1 Test program set
4.1 精度测试
L1P和L1D:分别在寄存器传输级(RTL)实现和MVSim中模拟7个单精度程序,并统计程序执行期间L1P未命中的次数。表2列出了测试程序的L1P未命中次数、代码大小和指令获取数据包。获取数据包的指令数是根据代码大小Dcode计算得到的。假设指令获取包的大小为64 B,那么指令获取包数量NFP=Dcode/64。从表2中可以看出,RTL和MVSim获得的L1P未命中的数量相同,这与计算的提取分组的数量完全相同。

Table 2 Performance of various test programs
(1)计算结果:RTL和MVSim分别模拟了7个单精度程序和7个半精度程序,计算结果完全一致。
(2)程序计算性能:有2种情况:①数据存储在片上存储器中,并分别在RTL和MVSim中模拟了7个单精度程序和7个半精度程序,程序计算性能完全相同。②数据在片外存储器中。由于MVSim对DMA、DDR和多核围栏的模拟是一种功能模拟,因此程序的计算性能取决于统计获得的参数数据,存在一定的性能误差。图8显示了gemm和fft程序(单核和四核,单精度和半精度)的性能误差,它们的平均性能误差约为2.9%。
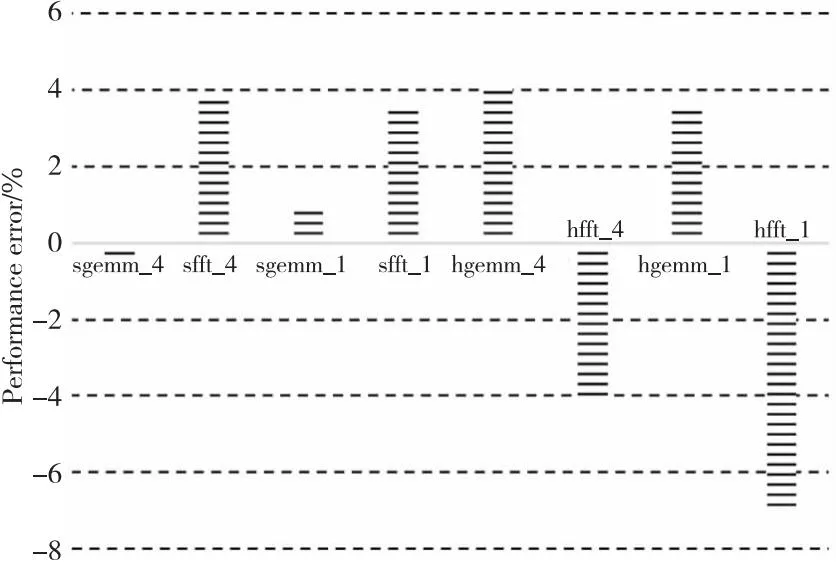
Figure 8 Performance error of gemm and fft in RTL and MVSim图8 RTL和MVSim中gemm和fft的性能误差
4.2 性能测试
(1)模拟器性能。如图9所示,分别在MVSim、CCS和RTL模拟器中测试了7个程序在不同条件下(单核和四核、单精度和半精度)的模拟执行时间。图9a显示,在模拟单精度单核程序时,MVSim分别比RTL和CCS的快63倍和4倍。图9b显示,在模拟单精度四核并行程序时,MVSim的分别比RTL和CCS的快315倍和4.5倍。图9c显示,在模拟半精度单核程序时,MVSim的分别比RTL和CCS的快66倍和4.7倍。图9d显示,在模拟半精度四核并行程序时,MVSim的分别比RTL和CCS的快465倍和7倍。
(2)模拟器的可扩展性。在3台不同配置的主机上测试了不同核数模拟器的执行性能,结果如图10所示。从图10可以看出,MVSim具有良好的可扩展性。
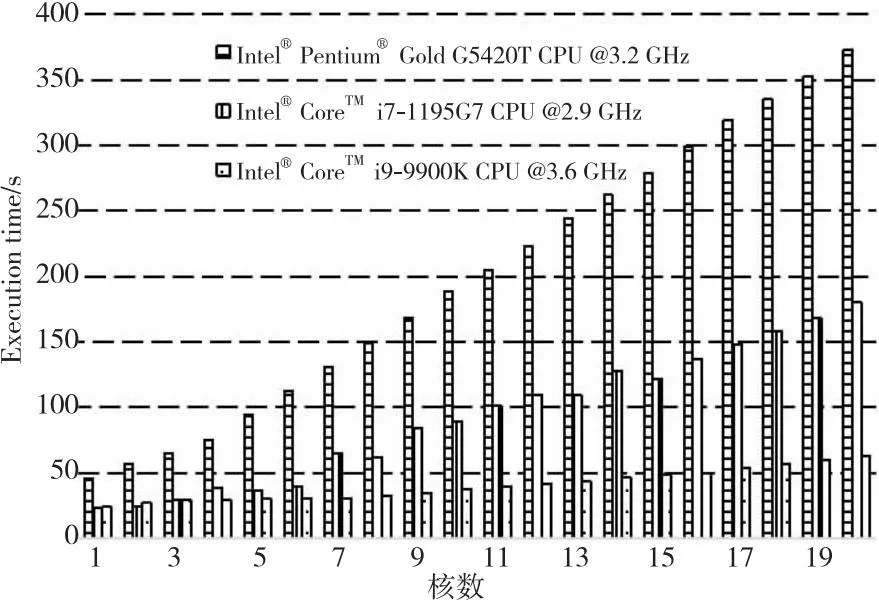
Figure 10 Execution performance of simulators with different kernel numbers图10 不同核数模拟器的执行性能
5 结束语
本文设计了一种适用于多核向量体系结构的快速、可扩展、性能精确的软件模拟器MVSim。它模拟了处理器的逻辑功能,可以准确地模拟硬件处理器程序指令的运行过程。实际使用结果表明,该模拟器在处理器的设计中能够发挥非常重要的作用:(1) 模拟器可以提前模拟程序执行过程,并反馈设计是否符合要求,从而改进处理器设计;(2) 该模拟器有助于芯片设计过程中的芯片测试和验证,通过比较RTL测试结果与模拟器执行结果,可以及时发现设计错误;(3) 模拟器可以模拟运行程序在处理器上的执行过程,记录完整的程序执行日志,有助于应用程序的开发、调试和性能分析;(4) 模拟器可以提供给潜在用户进行早期应用开发,有助于加快芯片的应用推广和用户应用的快速开发与部署。
