面向高性能计算的互连网络拥塞控制分析与评估
2024-02-28张建民孙舜禹
孙 岩,张建民,黎 渊,孙舜禹
(国防科技大学计算机学院,湖南 长沙 410073)
1 引言
高性能计算HPC(High Performance Computing)系统已经进入E级规模。E级计算系统具有空前庞大的规模和异常复杂的结构,HPC的许多特性在E级系统上都更加突出,如节点数量和种类更多、互连结构更复杂、通信延时和吞吐率要求更高等。在E级计算系统面临的众多挑战中,数据通信是最为关键的因素之一[1]。高吞吐、低延时、高消息率和高利用率的互连通信系统成为提升HPC性能的关键支撑技术。
为了提升性能和效率,当前大部分HPC的互连系统都构建在无损的可靠网络上,通过基于信用或优先级的流控确保传输过程中无丢包。由于避免了数据包重传,无损网络显著提高了报文传输的性能和效率,但也带来了新的问题,如数据流公平性、头阻塞和拥塞传播等[2]。当网络中发生局部拥塞时,流控机制会向前反压,形成拥塞树,造成全局拥塞,显著降低网络的吞吐率,延长数据流的完成时间FCT(Flow Complete Time)。随着计算系统性能和网络通信需求的进一步提升,拥塞问题变得更加严重,成为HPC互连网络性能和可靠性提升的最主要限制[3,4]。
解决HPC互连网络拥塞问题的根本方法是通过端到端的拥塞控制CC(Congestion Control)机制消除局部拥塞。拥塞控制机制通过在网络中监测拥塞相关信息(如交换机队列长度或报文往返时间)来判断或预测局部拥塞的发生,并将该信息反馈到源端,源端基于拥塞信息对数据发送速率进行调整。通过网络中源节点、目的节点和交换节点多部件的配合,形成控制闭环,端到端的拥塞控制从源头避免或消除了网络中的拥塞。
在当前国际领先的HPC系统中,互连网络主要有以下几种:NVIDIA/Mellanox公司的InfiniBand系列、Cray公司的Slingshot系列、日本Fujitsu公司的Tofu Interconnect,以及中国的“太湖·之光”Sunway互连和“天河”系统的TH Express系列等[5]。在拥塞控制方面,这几种互连系统各有特色。然而,专门针对HPC的拥塞控制研究仍然相对较少,这主要是因为HPC系统的互连网络虽然重要,但仍属于“小众”,研究相对较少。此外,HPC的技术细节往往公开较少,特别是拥塞控制这种高性能网络的关键技术。
近年来,数据中心网络发展迅速,研究人员提出了很多优秀的拥塞控制方法,如DCQCN(Data Center Quantized Congestion Notification)、TIMELY(Transport Informed by MEasurement of LatencY)和HPCC(High Precision Congestion Control)等。虽然数据中心网络与HPC网络在系统结构、通信特性、传输协议和应用模式等方面有一定区别,但也有很多相似之处,如都具有集中化、高带宽、低时延和高并发等特点。二者可相互借鉴,相互融合。我们预计,这也将是未来HPC互连网络发展的趋势。
当前,将数据中心和HPC互连网络进行融合设计的工作还比较少,特别是在拥塞控制方面。本文正是基于这一背景,主要解决以下问题:(1) 数据中心的主要拥塞控制方法是否适用于HPC网络?(2) HPC的仿真模拟应当使用怎样的流量模型?(3) 如何客观准确地评估HPC网络的拥塞控制机制效果?
2 拥塞控制方法分析与评估
近十几年来,数据中心网络快速发展,出现了很多优秀的拥塞控制方法。一些拥塞控制技术成功应用于大规模数据中心,取得了很好的效果。
为了在数据中心网络中实现数据传输的低延迟、高吞吐和高容忍度,斯坦福大学联合微软研究院于2010年提出DCTCP(Data Center Transmission Control Protocol)[6],其在交换机上使用简单的主动队列管理和阈值标记,再在接收端将标记包传回发送节点,发送方维护数据包标记估值并定时更新。DCTCP比TCP(Transmission Control Protocol)的吞吐量更高,缓冲区占用更少,并具有高突发容限和低延迟。然而,DCTCP的控制方式仍然简单,在平均队列长度、数据吞吐率等方面有较大的优化空间,此外也不支持远程直接内存访问RDMA(Remote Direct Memory Access)等无损网络。
RDMA技术在数据中心网络中被大规模采用,但PFC(Priority-based Flow Control)风暴和死锁问题凸显。为了解决该问题,微软公司于2015年提出DCQCN拥塞控制方法,并将其部署在数据中心[7]。DCQCN结合DCTCP的显式反馈和QCN(Quantized Congestion Notification)[8]的速率控制,可以在PFC机制触发前缓解拥塞,减少PFC触发,较好地解决了PFC引起的公平性和受害流问题,成为数据中心中最经典的拥塞控制技术之一。但是,DCQCN很难实现速率和网络状态的精确匹配,流延时较大,并且参数众多,参数调整困难。
针对RDMA的拥塞问题,谷歌也于2015年提出了TIMELY拥塞控制方法[9]。与DCQCN不同的是,TIMELY借助的拥塞标记信号是报文往返时间RTT(Round-Trip Time),对延迟梯度作出反应。这是因为延迟梯度具有较好的稳定性和收敛性,无需等待队列形成,有助于实现低延迟。TIMELY在提供高带宽的同时还能够保持较低的延迟,并且控制都在端节点上完成,无需交换机支持,具有更好的可部署性。但是,TIMELY对基于RTT信息的拥塞控制反应相对偏慢;队列长度和公平性无法兼顾;反馈抖动引入了噪声,导致收敛性较差。
阿里巴巴公司于2019年提出一种基于网内遥测INT(In-Network Telemetry)的拥塞控制方法HPCC[10]。HPCC利用INT信息获得精确的链路负载信息,能够对流量进行更准确的控制。通过智能网卡与交换机的配合,端到端实时抓取拥塞信息,从而精确获取实时的链路负载,并计算合适的发送速率,能够快速收敛、降低缓存依赖、保证数据公平性。HPCC的FCT相比DCQCN的降低了95%,需调整的参数很少。但是,HPCC传送INT信息的开销较大,降低了数据吞吐率;交换机改动较大,难以进行大规模部署。
为了解决HPCC开销较大的问题,哈佛大学等于2020年提出了PINT(Probabilistic In-band Network Telemetry)技术[11]。PINT将INT信息编码在多个报文中,同时限制每个报文中INT信息的字节数,从而有效地降低了传送INT信息带来的吞吐率开销。PINT在多个数据包上对INT数据进行编码,每个数据包的开销最低可达到1 bit。PINT可实现与HPCC近似的流完成时间,长流吞吐率有显著改善。但是,PINT是基于概率的算法,当数据流较短时效果不佳;此外,PINT仅进行了中小规模的实验,还没有在实际系统中大规模应用。
为了对以上拥塞控制方法的特点进行分析比较,本文搭建了一个小规模的模拟环境,使用相同的网络拓扑和测试负载对以上几种拥塞控制方法进行模拟分析,直观地比较各方法的性能。模拟使用修改的NS-3网络模拟器[10],使用的网络拓扑如图1所示,其中,2号、3号节点为交换机,其余节点为服务器;设置的链路带宽为100 Gbps,链路延时为1 μs。
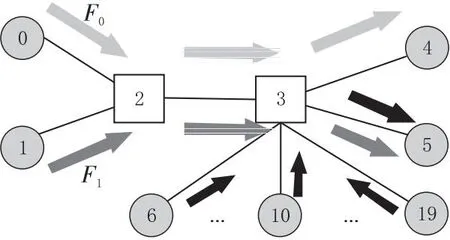
Figure 1 Schematics of network topology and traffic图1 网络拓扑结构与流量示意
模拟的流包含2条长流与224条短流。其中2条长流由0号节点和1号节点分别发送到4号节点和5号节点(记为F0和F1)。而短流则是由6号到19号共14个节点分别产生的16条到5号节点的流组成。长流的大小为100 MB,在time=0时开始发送;短流的大小为64 KB,在time=5 ms时开始发送。实验分别对长流吞吐率、短流完成时间、PFC时间等进行分析和比较。
模拟结果显示主要的拥塞出现在3号节点接收突发的大量短流时。对于F0而言,它本身与短流并不存在竞争关系,但是如果拥塞控制方法没有及时根据拥塞情况调整流发送速率,大量短流会引起3号节点的缓冲区溢出,使得F0的吞吐率受到影响。图2给出了几种方法的F0和F1流的吞吐率变化情况。

Figure 2 Long flow throughput图2 长流吞吐率
从图2可以看出,DCTCP和TIMELY的F0和F1吞吐率出现了明显的震荡;DCQCN的F0吞吐率受到短流影响出现降低的情形;HPCC和PINT的F0吞吐率表现较好,没有受到突发短流的影响,但PINT的F1吞吐率恢复较慢。
除了长流的吞吐率,短流的完成时间FCT也是重要的性能指标。本文对每种方法中短流的FCT进行统计并生成累积分布函数CDF(Cumulative Distribution Function)图,如图3所示。
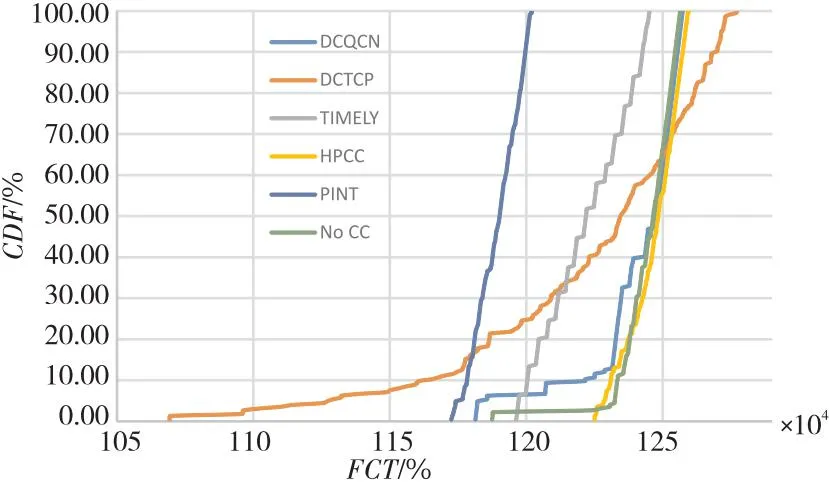
Figure 3 CDF of short flow completion time图3 短流完成时间CDF
由图3可见,PINT的短流FCT最佳,TIMELY和DCQCN的短流FCT比无CC的要好,HPCC的短流FCT与无CC的近似,但一致性更好。DCTCP的短流FCT表现出长尾的特点,说明短流间的公平性表现不佳。
表1列出了2条长流的吞吐率和224条短流的FCT。可以看到,HPCC和PINT的F0吞吐率较好,受到突发短流的影响较小,同时对F1进行了较好的速率控制,因此短流的FCT也较短,实现了很好的公平性。这是由于HPCC和PINT使用了细粒度的网络遥测数据进行拥塞控制,可实现更快速和更精确的控制。
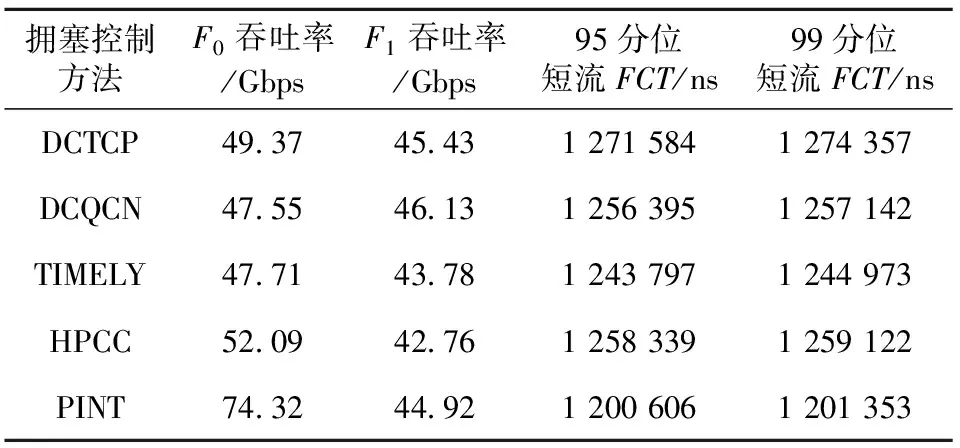
Table 1 Results of throughput and FCT
本文对每种方法的PFC时间进行统计,如图4所示。可以看出,在无拥塞控制机制时,报文发送处于失控状态,如果网络中出现拥塞会触发PFC,使得链路报文发送暂停,并快速向前级传播,造成PFC风暴;DCQCN和TIMELY的PFC时间也很长,说明这2种方法对报文发送的控制并不能与网络状态很好地匹配;HPCC和PINT的PFC时间与其它方法相比小1个数量级,表明其速率控制机制能够更好地与网络状态相匹配。
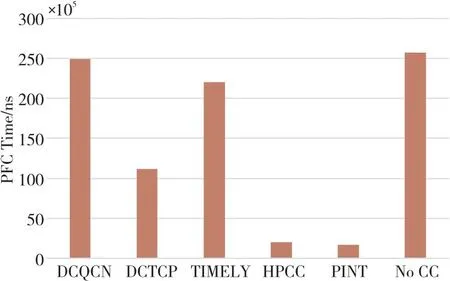
Figure 4 PFC time图4 PFC时间
从以上分析可以看到,衡量一种拥塞控制方法的优劣,与长流的吞吐率、短流的完成时间及触发的PFC时间相关,此外,还有队列长度、打标数量等多个指标与之相关。如何将这些评价指标合理地结合,并针对HPC网络的特点进行综合评价,是本文后2节重点讨论的内容。
3 HPC网络拥塞流量模型
数据中心网络和HPC互连网络最主要的不同就是流量特性和行为的不同。因此,若要对HPC互连网络的网络拥塞控制进行模拟,就需要设计出适用于HPC互连网络、接近HPC互连网络真实流量情况的流文件生成工具。
由美国阿贡国家实验室和Cray公司等开发的GPCNeT(Global Performance and Congestion Network Tests)[12]是适用于实际HPC互连网络的测试基准,主要用于在HPC互连网络中产生网络拥塞并对其进行测量,从而方便对网络的拥塞控制特性进行评价和比较。GPCNeT适用于各种拓扑结构,用简单的方式产生复杂的通信模式,很难针对性优化。GPCNeT测试基准获得了HPC领域的认可,并被应用于多个研究中,但其使用MPI(Message Passing Interface)生成网络负载,无法直接应用于模拟器中。因此,本文参考GPCNeT的流量生成方法,结合HPC互连网络模拟的实际需求进行适当简化,设计了一种HPC互连网络测试负载流量模型和流文件生成工具,为基于模拟器的HPC拥塞控制实验提供相应的流文件。
本文提出的流文件生成模型结构如图5所示。将待测网络中的节点随机地分为2部分,其中一部分负责产生待测流(约占整个网络总节点数的20%),另一部分负责产生背景流(约占整个网络总节点数的80%,可以根据网络负载进行参数调节)。待测流是主要进行测试的部分,通过测试这部分流的延时、带宽等参数对网络拥塞控制方法的性能作出评估。待测流根据流的大小和特性可以分为长流、短流和All-reduce流,分别用于测试网络拥塞控制效果的不同指标。背景流的作用则是为了模拟真实网络中的流量特点,产生拥塞。背景流主要包括Incast流、Broadcast流和All-to-All流,它们可以模拟网络中常见的流的特性,和待测流竞争带宽并产生拥塞。为了尽量模拟真实的网络环境以及保证最终结果的可靠性,所有的节点选择、流生成都使用随机的方法,一方面可以保证待测节点较为均匀地分布在整个网络中,另一方面可以保证产生流的随机性。
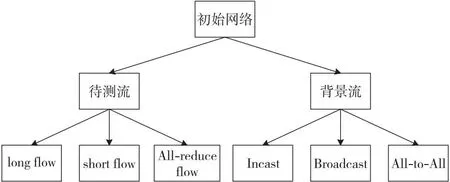
Figure 5 Schematic diagram of flow generation model图5 流生成模型示意
基于该模型,本文使用Python语言开发了流文件生成工具。根据输入的节点数和交换机节点号随机生成2组节点,一组负责待测流的生成,另一组负责背景流的生成。其中,待测流的生成相对固定,由所有节点中的20%产生。而背景流的生成还会受到负载因子的影响,负载因子用于表示网络中的拥塞程度,较大的负载因子会产生更多的背景流,从而导致更严重的拥塞。根据这些参数,流文件生成工具能够生成相应的流文件。此外还会产生只包含待测流的独立流文件,用于将模拟结果与加入背景流的情况进行对比。图6给出了流文件生成的工作流程。
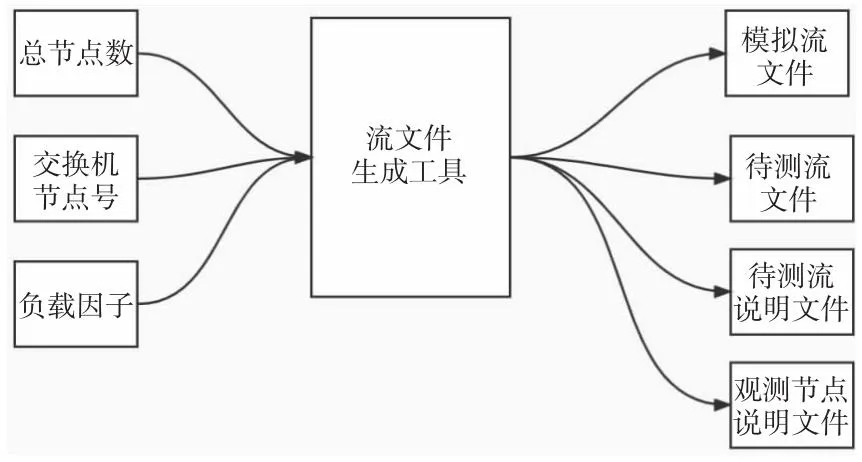
Figure 6 Flow chart of flow file generation图6 流文件生成流程图
图7是网络负载分别为30%,60%和90%时200个节点的负载分布图。其中,横坐标代表源节点,纵坐标代表目的节点,例如若在(40,180)处有点,则表示有一条从40号节点发往180号节点的流。圆点表示待测流,三角表示背景流。可以看出,待测流的分布在整个网络中较为均匀,其中较为集中的背景流为广播流。
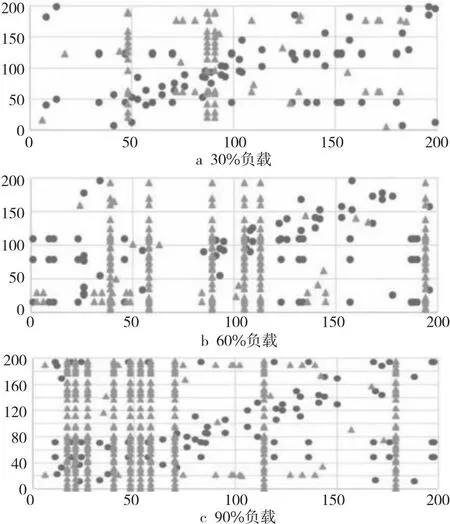
Figure 7 Scatter diagram of flow distribution图7 流量分布散点图
4 拥塞控制评价指标
对各种拥塞控制方法的性能进行评价,需要找到能够有效评判拥塞控制方法性能的指标。在拥塞控制相关研究中,主要的评价指标还是带宽、网络利用率、延时和流完成时间等,还没有一个综合的评价指标能够公正地反映拥塞控制的整体性能。此外,在实际应用中,不同场景对网络拥塞控制的需求可能存在差异,完善的评价指标应可通过参数调节适用于不同的需求场景。因此,需要一种综合的性能指标,用于分析和评价HPC互连网络拥塞控制效果。
拥塞控制方法的性能主要取决于长流带宽与短流延时,但是并不能直接使用模拟的结果作为评价结果。考虑到每次生成的流都具有随机性,直接使用长流带宽和短流延时作为评价指标可能会导致模拟实验结果差别较大,且无法生成标准化的结果。因此,可以对长流带宽和短流延时进行标准化处理。
对于长流带宽,使用式(1)作为评价指标:
SL=Li/Lc
(1)
其中,Li表示仅包含待测流i时的长流带宽,Lc表示加入拥塞流之后的待测流长流带宽。
对于短流延时,使用式(2)进行标准化:
SS=Sc/Sj
(2)
其中,Sj和Sc分别表示仅包含待测短流j的延时和加入拥塞流之后的待测短流延时。
All-reduce流作为特殊的短流,其评价指标与短流的类似,但是需要将其作为独立指标加入到总体评价指标中,如式(3)所示:
SA=Ac/Ak
(3)
其中,Ak和Ac分别表示仅包含待测All-reduce流k的延时和加入拥塞流之后的待测All-reduce流延时。这种评价指标评估的是拥塞控制方法的优化程度,而不是直接表示带宽、延时的数据,从而避免了评价指标因为每次产生的流文件不同而导致较大出入。另一方面,使得评价指标可以同时包含长流带宽、短流延时和All-reduce流延时等几方面的信息。
因此,拥塞控制评价指标可以表示为式(4):
S=SL+SS+SA
(4)
大多数情况下,认为长流带宽、短流延时和All-reduce流延时的重要性是相同的,通常3部分优化水平较为平均的结果是最为优秀的。短流延时优化较好但导致了长流的带宽急剧下降或者相反的情况往往是不够优秀的。因此,可以加入表征优化平均程度的指标,即方差项,如式(5)所示:
(5)
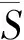
但是,在很多特殊的网络实际应用中,长流带宽和短流延时的重要程度是不同的。需要加入一项表征长流带宽与短流延时的重要性的评价指标,用于调整二者在最终评价指标中的占比。
因此,最终的评价指标公式如式(6)所示:
S=aL×SL+aS×SS+aA×SA+W
(6)
其中,aL、aS和aA分别为长流带宽、短流延时和All-reduce流延时的占比因子,通常情况下取值均为1/3。在实际使用时,可以根据需求调节。S为最终的评价指标,称为性能下降参数,它的大小表征了方法在拥塞情况下相对空闲情况的性能下降程度。
本文通过一个简单网络的模拟实验说明该评价指标的实际应用场景。模拟选择的网络为哑铃型拓扑,即2个交换机直连,各连接5个服务器节点。本文对DCQCN、TIMELY和HPCC进行了网络模拟,结果如图8所示。

Figure 8 Experimental results of evaluation metric图8 评价指标实验结果
从图8可以看出,3种CC方法对短流的延时优化性能接近,而对于长流带宽的优化HPCC性能最佳,All-reduce流的性能在加入拥塞流前后没有太大变化。这是由于本文实验选用的All-reduce流在网络中的位置与背景流相对独立,因此受背景流的影响造成的性能下降较少。
5 大规模网络拥塞控制模拟评估
本文大规模实验采用多根胖树结构,共计376个节点,其中包括56个交换机节点,320个服务器节点,其拓扑如图9所示。这种拓扑结构是HPC中最常见的网络拓扑,使用该结构目的是尽量使模拟实验更加接近真实情况。链路带宽设置为100 Gbps,链路延时为1 μs。流文件采用本文设计的流文件生成工具生成,共计产生了19 181条流,具体参数如表2所示。
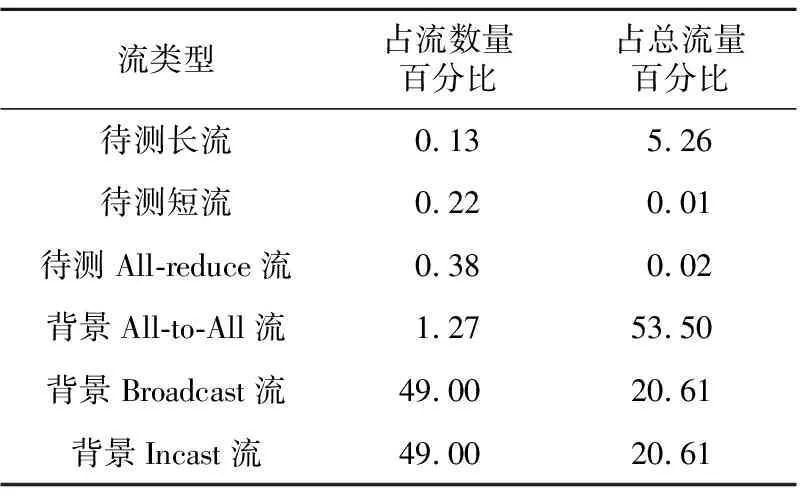
Table 2 Traffic statistics of large-scale experiment
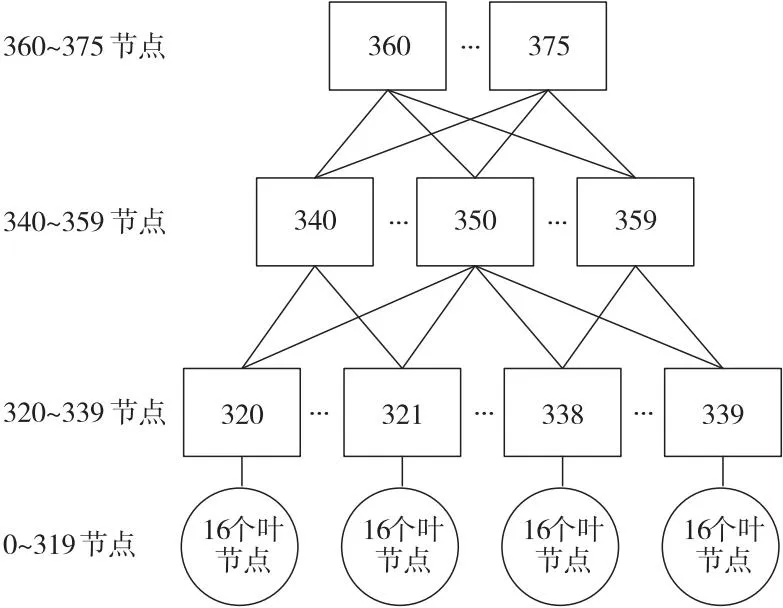
Figure 9 Topology of large-scale experiment图9 大规模实验拓扑结构
实验的流量模仿实际网络中的流量,从统计数据可以看出,所有的长流(包括待测长流和背景All-to-All流)在所有流数量中只占了1.4%,但是却提供了58.76%的流量,这是为了模拟真实情况下HPC中的网络流量环境。实验力求能在负载允许的情况下尽可能接近真实情况。
根据本文提出的评价指标对几种拥塞控制方法进行评价,实验结果表3所示。表3中,后缀为实验共选择了3组不同的配置。配置1为aL=aS=aA=1/3,表示评价指标中各种流的权重相同。在此种情形下,5种方法对于长流带宽和短流延时的优化性能比较接近,而HPCC和PINT对于All-reduce流的优化能力较强,最终成为性能较优的2种拥塞控制方法。All-reduce流的形成源于某个服务器对其它几个服务器同时发出或接受短流,属于突发且会造成较为严重拥塞情况的一类流。其它3种方法是基于显式拥塞通知ECN(Explicit Congestion Notification)标记或RTT进行拥塞判断的,在短时间感知网络拥塞情况变化的能力较弱,对于All-reduce这类突发流的调节能力相应较弱。而HPCC和PINT是基于INT的,每当一个报文发送完成后,发送方都能够根据响应报文ACK(ACKnowledgement)中携带的INT数据获得网络中的拥塞信息,可以及时地调整自身的发送速率,从而避免拥塞情况的产生。
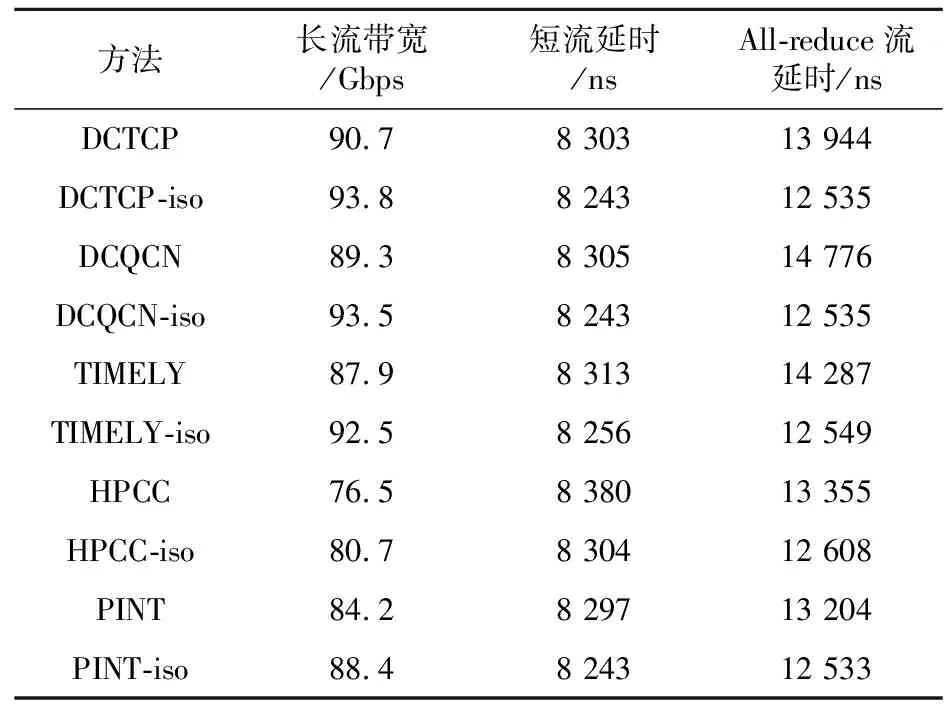
Table 3 Results of large-scale experiment
iso的行表示在只有待测流独立运行时的各项指标数据。根据以上数据,图10给出了对aL、aS、aA分别取不同值时,5种拥塞控制方法的最终性能下降情况。

Figure 10 Experimental results of performance degradation with different parameters图10 不同参数下性能下降实验结果
配置2为aL=0.5,aS=aA=0.25,这是为了模拟长流带宽更为关键的应用情形,例如大规模的存储服务等,需要网络为长流提供足够的带宽来满足大量长流的并行传输。与配置1不同,在这种应用情形下HPCC和PINT与其它方法相比优势不再明显。HPCC和PINT对长流带宽的支持性较差,是因为一方面INT信息的传送对长流造成了一定的开销,使得长流的有效带宽有所下降;另一方面,这2种方法为了降低排队延时,实现了超短队列,因此会导致交换机缓冲区的占用较小,从而影响各个交换机上游节点对于长流的传输。考虑到此次实验产生的流文件中,长流的流量占用约为总流量的58.76%,而在实际的应用中这一占比可能会更高,HPCC和PINT的性能可能会进一步下降。
配置3为aA=0.5,aL=aS=0.25,这一组数值的设置模拟的是更为看重短流的应用,选择了All-reduce流作为评价的重点。因为在网络的各类短流中,All-reduce这类突发性的局部范围的短流是更加不容易被优化的。因为其突发性强,且出现后会迅速地导致较为严重的拥塞,而各类拥塞控制方法对于拥塞的反应总是需要时间的,所以会导致各种方法对于All-reduce流的优化效果都不够理想。从结果来看,5种方法的指标与配置1数据相比都有上升,表明All-reduce流的延时对于5种方法都是性能瓶颈。结合延时信息不难发现,在配置3中,对于长度相同的短流和All-reduce流,延时却存在着明显的差异,这也表明All-reduce流的优化难度。在注重短流延时的应用中,如何提高拥塞控制方法对于拥塞的敏感度和反应速度,以提高对于All-reduce流的优化能力,是各类拥塞控制方法应该研究的重点。
6 结束语
E级高性能计算时代已经到来,互连通信是HPC系统的关键组成部分,拥塞问题是HPC互连网络性能提升的主要限制之一。本文针对HPC互连网络的拥塞问题进行研究,实验分析了主要拥塞控制方法的设计思想、工作原理及其优缺点;设计了用于HPC网络拥塞控制模拟的流量模型和流文件生成工具;根据高性能网络对拥塞控制算法的需求,设计了综合的拥塞控制算法评价指标;使用提出的流量模型,在较大规模网络中对不同拥塞控制方法进行模拟,并基于所提出的评价指标对几种拥塞控制方法的性能进行了分析和评估。
