基于动态定位和特征融合的多分支细粒度识别方法
2024-02-28杨晓强黄加诚
杨晓强,黄加诚
(西安科技大学计算机科学与技术学院,陕西 西安 710000)
1 引言
对物体进行分类是计算机视觉领域最为常见的一项任务。经典的猫狗分类旨在对2大类物体进行跨物种划分,即粗粒度分类。而细粒度分类重点在于对单一大类物体进行进一步分类,是目前研究热点之一。
细粒度分类方法可根据是否需要额外标注信息分为2大类:一是基于强监督的细粒度分类方法,除图像标签外,该类方法还需要对象标定框或关键节点等标注信息辅助分类;二是基于弱监督的细粒度分类方法,该类方法只需图像标签即可完成分类工作。
基于强监督的细粒度分类方法有以下研究成果。Zhang等[1]设计了基于部位的区域卷积神经网络Part-based R-CNN(Part-based Region- Convolutional Neural Network),使用自下而上的区域推荐算法学习整个对象和部位检测器。Branson等[2]在姿态归一化网络中使用鸟类原型对部位级别图像进行姿态对齐操作。Huang等[3]提出部件堆积网络,该网络包含2个部分:一部分为全卷积网络,负责定位部件;另一部分为双流分类网络,负责物体以及部件的特征编码工作。Lin等[4]构建了部件定位、对齐和分类网络,其中阀门连接函数是对齐子网络中的关键模块,负责网络的反向传播,同时协调优化分类和定位子网络之间的衔接。Wei等[5]在掩膜卷积网络Mask-CNN中借助全卷积网络来分割头部和躯干部位。额外的标注信息需要专业人员手工制作,耗时耗力,因此基于弱监督的细粒度分类逐渐成为研究的主流。
基于弱监督的细粒度分类方法有以下研究成果。Xiao等[6]在两级注意力模型中借助对象级、部件级区域特征完成分类。Liu等[7]设计了基于强化学习的全卷积注意力网络来定位部件,首先获取置信度映射图,然后选取置信度最高的区域作为部件区域。Zhao等[8]借助注意力画布从输入图像中采样多尺度的子区域图像,并使用LSTM(Long Short Term Memory)学习子区域图像特征的多个注意力映射。Fu等[9]反复使用递归注意力网络裁剪注意力区域,以得到多个尺度的注意力图像。Zheng等[10]设计了一种多级注意力网络,通过对每个部件进行分类促使网络学习更多的判别性特征。Yang等[11]构建了一种自监督团结协作学习模型。Zhuang等[12]在成对交互网络中通过2幅图像间的成对交互来捕捉对比线索。Gao等[13]设计了一个通道交互网络,模拟了图像内部和图像之间的通道交互。He等[14]提出基于 Transformer 的细粒度图像识别网络框架,使用部分选择模块选取具有判别性的图像块。Zhang等[15]通过选择注意力收集模块过滤、筛选重要图像块。Liu等[16]使用峰值抑制模块和知识引导模块来辅助网络进行识别。Conde等[17]提出了一种多阶段的细粒度图像识别框架,利用ViT(Vision Transformer)自带的多头注意力机制定位关键图像区域。Wang等[18]构建了一种特征融合视觉 Transformer框架,使用token选择模块有效地引导网络选择具有区别性的token。
细粒度识别存在以下识别难点:(1)类间差异小,不同类别的目标物体外貌十分相似,非专业人员难以区分。(2)类内差异大,同一类别的目标物体受姿态动作、拍摄背景等因素影响而存在较大的差异。这些因素影响了目前相关方法的识别精度,因此细粒度识别仍是一项具有挑战性的研究。
Swin Transformer是Liu等[19]2021年提出的视觉领域Transformer,其在视觉任务上的综合表现优于ViT和各类CNN网络,是当下一种泛用性较高的特征提取网络。本文针对细粒度识别存在的问题,以Swin Transformer为基础,提出了改进的多分支特征融合模型TBformer(Three Branch transformer)。TBformer的创新点有如下几点:(1)使用ECA(Efficient Channel Attention)[20]、Resnet50(Residual network 50)[21]和SCDA(Selective Convolutional Descriptor Aggregation)[22]相结合的动态定位模块DLModule(Dynamic Localization Module)消除图像背景干扰信息并定位目标。同时,设计了基于DLModule的三分支特征提取模块,充分提取目标关键特征。(2)提出了基于ECA的特征融合方法来融合多特征,融合后特征内部的细粒度信息表征更丰富、更精确。(3)采用对比损失[14]和交叉熵损失相混合的方法,以一种新颖的多损失训练模型,提升模型整体性能。
2 Swin Transformer
Swin Transformer[19]网络结构如图1所示。首先,Patch Partition模块将三通道原图像划分为若干大小为4×4像素的独立Patch,将Patch在通道方向上展平,通道数相应地扩充至原先的16倍;然后,通过4层Stage网络生成不同大小的特征图;最后通过分类层输出最终结果。Stage1网络通过Linear Embedding层将每个Patch维度重新编码为C。Stage2~Stage4网络使用Patch Merging层对Patch进行下采样,将上一层每2×2的像素合并为一个Patch,Patch经过拼接、线性映射后大小减半,深度翻倍。每层Stage中的Swin Transformer Block用于对Patch进行自注意力计算。Swin Transformer Block使用2种不同的改进多头注意力:基于规则窗口的多头注意力和基于移动窗口的多头注意力。这2种注意力在网络中成对使用。
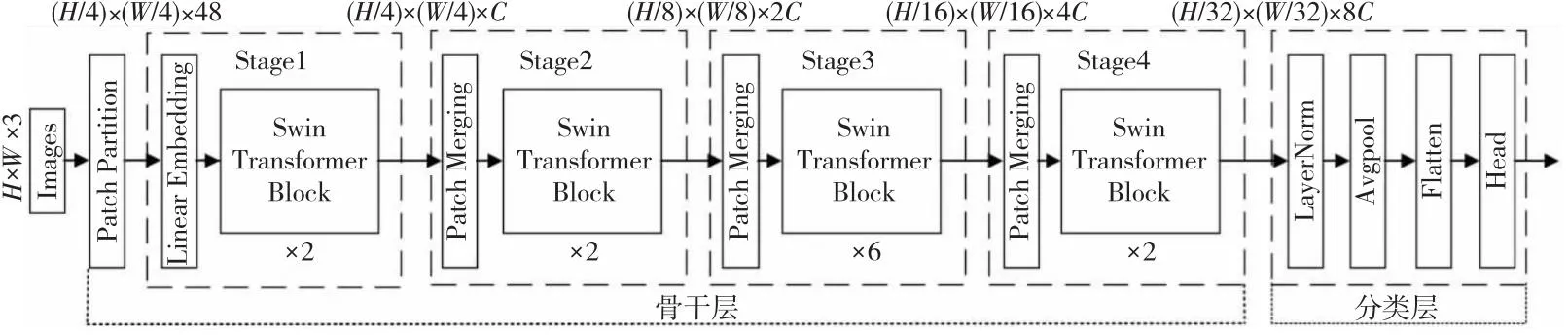
Figure 1 Structure of Swin Transformer图1 Swin Transformer结构
3 TBformer
TBformer总体结构如图2所示,图中Transformer为Swin Transformer骨干层。该模型可概括为3个部分:三分支特征提取、特征融合和分类3个模块,其中特征提取和特征融合2个模块为主要部分。三分支特征提取模块使用DLModule提取用于消除背景信息的定位图像,并充分提取原始图像和定位图像中目标判别性特征。特征融合模块基于ECA对特征进行融合,充分挖掘特征深层细粒度信息,以构建更全面和精确的特征表示,提高模型的鲁棒性。TBformer首先从原始图像和定位图像中提取3个分支特征,然后对3个分支特征进行特征融合,最后分类模块处理融合特征并输出预测结果。TBformer采用多损失策略训练模型,使性能得到有效提升。
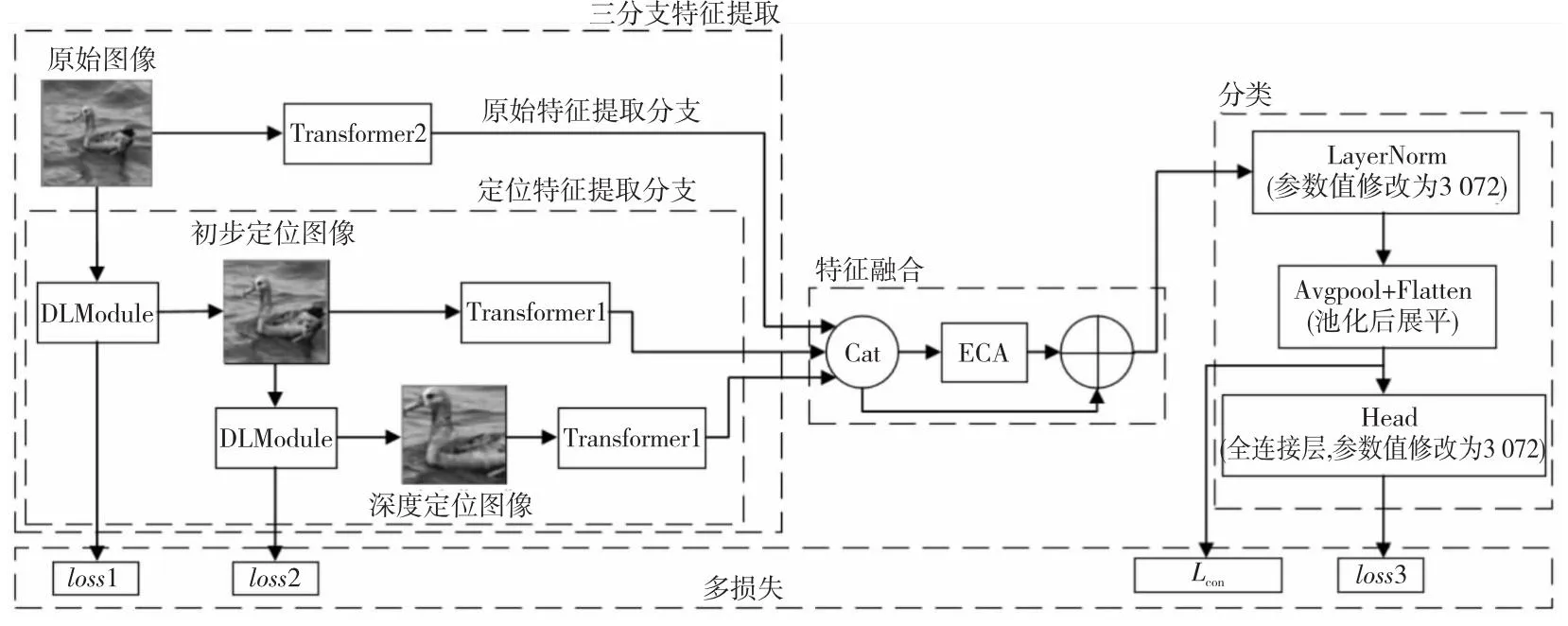
Figure 2 Structure of TBformer图2 TBformer结构
3.1 三分支特征提取模块
三分支特征提取模块包含2个部分:一部分为定位特征提取分支,其循环使用DLModule获取定位图像并从定位图像中提取特征;另一部分为原始特征提取分支,负责从原始图像中提取特征。
首先,将原始图像输入至DLModule中,在DLModule第1次作用下,生成去除部分背景的初步定位图像,并输出交叉熵损失loss1。然后,以初步定位图像作为输入,在DLModule第2次作用下,生成去除更多无关背景的深度定位图像,并输出交叉熵损失loss2。最后,将初步定位图像和深度定位图像输入至Transformer1中提取定位特征,将原始图像输入至Transformer2中提取原始特征。三分支特征提取模块最终输出原始特征、初步定位特征和深度定位特征3个分支特征。
3.1.1 定位特征提取分支
拍摄的原始图像含有较多复杂背景信息,这对模型识别产生了干扰。传统的物体定位方法有中心裁剪定位、随机裁剪定位等,但这些定位方法的定位方式要么不够灵活,要么随机性太强,并不能有效地捕获关键物体。SCDA[22]为一种图像检索领域中的局部定位方法,该方法基于特征图来高效地定位物体并裁剪出带有关键物体的图像。文献[22]中SCDA使用VGG16(Visual Geometry Group 16)[23]作为特征提取网络,但VGG16参数较多导致训练时间过长。本文用嵌入ECA通道注意力的Resnet50(简称ERnet)替换VGG16得到动态定位模块DLModule。DLModule利用参数可更新的ERnet为SCDA提供特征图,并以此动态性地提取关键物体图像。DLModule结构如图3所示。

Figure 3 Structure of DLModule图3 DLModule结构
(1)ECA通道注意力。
ECA-Net[20]提出了新型的通道注意力ECA模块(如图4所示)。适当的跨信道交互相比直接降维更能促进通道注意力的学习,所以在采用不降维的局部跨信道交互策略和一维卷积核大小自适应函数的基础上,ECA实现了更高效的注意力学习,既提升了模型性能又降低了模型复杂度。
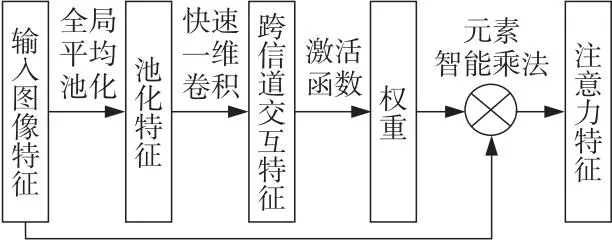
Figure 4 ECA module图4 ECA模块
ECA通道注意力模块工作原理如图4所示。首先,对输入图像特征进行全局平均池化得到池化特征。接着,通过快速一维卷积获取跨信道交互特征。然后,将跨信道交互特征输入至激活函数生成各通道的权重。最后,对原始特征和通道权重做元素智能乘法操作,以获取具有通道注意力的特征。
(2)ERnet结构。
ERnet结构如图5所示。由于浅层网络的低维特征包含更多局部信息,深层网络的高维特征包含更多全局信息,而细粒度识别在已有全局信息条件下需要局部信息辅助分类。故不同于将注意力模块嵌入Resnet50[21]瓶颈层中的做法,本文在图像经过第1个卷积层conv1卷积后连接一个ECA注意力模块,ECA通过捕捉低维特征有效通道内的局部信息,协助网络区分目标与干扰项。
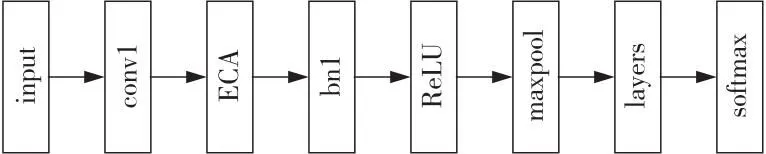
Figure 5 Structure of ERnet图5 ERnet结构
(3)基于ERnet的SCDA。
ERnet最后一个卷积层有3个卷积块。记F∈RC×H×W为输入图像X在某个卷积块最后一次卷积后得到的特征图,其中,C、H、W3个参数依次代表图像的通道数、高、宽。特征图F所有通道聚合而成的激活特征图A如式(1)所示:
(1)
其中,Sn代表第n个通道的特征图。
通道对应的感兴趣区域呈现不同的分布,有的聚焦头部或躯干部位,有的则偏向关注无关背景。通过激活特征图A和如式(2)所示的阈值a可进一步准确定位关键物体区域。
(2)
其中,(x,y)是激活特征图A中的位置坐标;A(x,y)为坐标值;a为阈值,取值为激活特征图中所有位置坐标值的平均值,用于判断激活特征图中的元素是否为物体的一部分。从ERnet最后一个卷积层的第2个卷积块convblock_2和第3个卷积块convblock_3的特征图中按式(3)提取特征,设得到的初始掩码分别为Mconvblock_2和Mconvblock_3。
(3)
由于关键物体总是在初始掩码的最大联通区域内,故使用最大联通区域的最小外接边框作为物体对象定位结果。设Mconvblock_3的最大联通区域为Maxconvblock_3,将Mconvblock_2和Maxconvblock_3按式(4)取交集以实现鲁棒性更强的物体对象定位,最终的掩码记为Mintersection。最后将Mintersection的最小外接边框映射至图像对应区域,并对映射区域进行上采样处理得到最终定位图像。
Mintersection=Mconvblock_2∩Maxconvblock_3
(4)
定位特征提取分支使用DLModule消除背景信息,并获取目标图像。提取到的目标图像分为2种:初步定位图和深度定位图,如图6所示。由于首次提取到的图像仍含有冗余背景信息,故将初步定位图再次输入至DLModule,得到关键信息密度更高的深度定位图。将2类定位图输入至定位特征提取分支中的Transformer1提取定位特征。

Figure 6 Examples of original images and positioning images图6 原始图和定位图样例
3.1.2 原始特征提取分支
除定位特征外,本文还将原始特征纳入判别性特征提取范围内,原始特征由原始特征提取分支网络中的Transformer1从原始图像中提取。DLModule的原理是提取ERnet感兴趣的区域,由于存在ERnet只关注目标某些部分的可能,导致定位区域内关键物体有时会丢失某些部位。如图6所示从上到下分别对应3种不同的鸟类,第1行初步定位图和深度定位图均缺失了尾部,第2行深度定位图头部及尾部均有缺失,第3行深度定位图缺失了脚部,而这些缺失部位有可能是区分不同类别的关键部位。故引入原始特征能在一定程度上弥补定位特征潜在的损失。
3.2 特征融合模块
原始特征、初步定位特征、深度定位特征组成了三分支特征。为了充分挖掘三分支特征包含的细粒度信息,使用一种基于ECA[20]通道注意力的融合方法来融合特征。
图7为特征融合流程,初步定位特征和深度定位特征由Transformer1从定位图像中提取,原始特征由Transformer2从原始图像中提取。记fswt1为初步定位特征,fswt2为深度定位特征,fswt3为原始特征,3个特征通道维度均为1 024。首先在通道维度上拼接特征fswt1、fswt2和fswt3,该操作用“”表示,记拼接操作为cat(fswt1,fswt2,fswt3),拼接后特征为fc,其通道维度为3 072。然后由于fc为三维特征,经过重塑形状、转换维度处理后转换为四维拼接特征fc2。fc2随即在ECA注意力模块的作用下转化为注意力特征fe,记该操作为E(fc2)。接着在融合特征前注意力特征fe经过转换维度、重塑形状处理后转换为三维注意力特征fe2。最后对拼接特征fc和注意力特征fe2做元素智能加法操作生成融合特征ff,该操作用符号“⊕”表示,记该操作为fc+fe2。
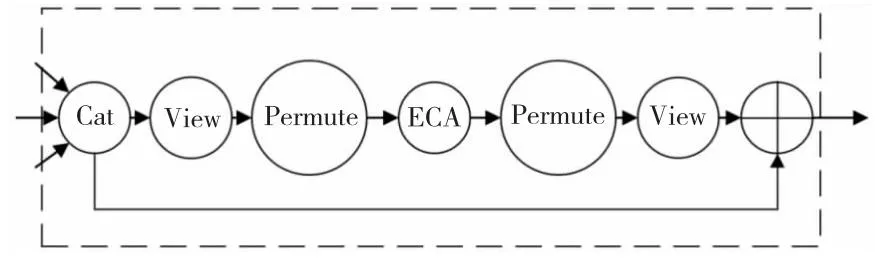
Figure 7 Process of feature fusion图7 特征融合流程
本文提出了基于ECA通道注意力的特征融合方法处理三分支特征,帮助网络更高效地挖掘多特征中的深层细粒度信息。融合后的特征表示更全面精确、更具有区分性,模型的鲁棒性也得到提升。特征融合操作如算法1所示。

算法1 特征融合输入:3个特征fswt1、fswt2、fswt3。输出:融合特征ff。Step 1 fc=cat(fswt1,fswt2,fswt3);Step 2 B,D,U=fc.size();Step 3 d=sqrtD();Step 4 fc2=fc.view(B,d,d,U).permute(0,3,1,2);Step 5 fe= Efc2();Step 6 fe2=fe.permute(0,2,3,1).view(B,D,U);Step 7 ff=fc+fe2。
3.3 多损失训练
由于细粒度分类存在类间差异小、类内差异大的问题,仅使用交叉熵损失不足以完全监督多特征的学习,为此本文引入对比损失[14]Lcon辅助模型更新参数。Lcon通过扩大类间方差、缩小类内方差,形成类间相对比而类内相促进的学习关系,从而改善网络对多特征学习的不完全监督性,提升网络整体性能。不同父类类别间相对子类间的差异较大即方差较大,为了防止Lcon被方差较大的不同父类类别样本主导,设定一个阈值k,只有方差小于k的样本才对Lcon的计算起作用。Lcon计算如式(5)所示:
(5)
其中,m为数据批次大小,np为实际标签值,nq为预测标签值,zp和zq为经过L2范数归一化预处理的特征图矩阵和特征图转置矩阵,dot(zp,zq)为zp和zq的点积。
本文采用多损失训练模型。图2中loss1 和loss2为ERnet输出的交叉熵损失;loss3为TBformer输出的交叉熵损失;Lcon为不经过TBformer全连接层的对比损失。最后记本文的总损失为L,如式(6)所示:
L=loss1+loss2+loss3+Lcon
(6)
4 实验与结果分析
4.1 数据集
本文使用了3个公开的数据集CUB-200-2011[24](CUB)、Stanford Dogs[25](DOG)、NABirds[26](NAB)。表1为各数据集相关统计信息。TBformer不需要边界框或位置关键点等标注信息,仅使用分类标签即可完成端到端的弱监督训练及测试。

Table 1 Statistical information of each dataset
4.2 实验环境及参数设置
实验采用的显卡为NVIDIA RTXTMA5000专业图形显卡,CPU为14核Intel®Xeon®Gold 6330 @2.00 GHz,内存为30 GB,Python版本为3.8,CUDA版本为11.3。实验基于版本为1.10.0的PyTorch框架进行开发,并在Ubuntu系统环境下运行。实验采用的Resnet50和Swin Transformer网络均从官方权重进行迁移学习,其中Swin Transformer选择的版本参数如下:patch大小为4,window大小为7,其加载的权重为swin_base_patch4_window7_224_in22k。
本文方法只需分辨率为224×224的图像进行实验。训练初始学习率为0.002,采用SGD(Stochastic Gradient Descent)随机梯度下降算法作为优化器,动量设置为0.9,每16幅图像为一个批次进行训练,学习率每训练20次衰减为原来的0.1。
4.3 实验结果
4.3.1 对比实验
为了验证本文方法的有效性,对Part-based R-CNN[1]、API-Net(Attentive Pairwise Interaction Network)[12]、CIN(Channel Interaction Network)[13]、PC-DenseNet-161(Pairwise Confusion Dense convolutional Network 161)[27]、TASN (Trilinear Attention Sampling Network)[28]、BARAN (Bilinear Aggregate Residual Attention Network)[29]、ACNet (Attention Convolutional binary Neural tree)[30]、 MHEM(Moderate Hard Example Modulation)[31]、GCL(Graph-propagation based Correlation Learning)[32]、Grad-CAM(Gradient-weighted Class Activation Mapping)[33]、GAT(Gaze Augmentation Training)[34]、PCA-Net (Progressive Co-Attention Network)[35]、Knowledge Transfer[36]、PAIRS(Pose-AlIgned RepreSentation)[37]、Ding[38]、 GB-HO-RD(Graph-Based High-Order Relation Discovery)[39]、PMG(Progressive Multi-Granularity)[40]、AENet (Alignment Enhancement Network)[41]、PART(PArt-guided Relational Transformers)[42]、Mix+(attribute Mix)[43]、Stacked LSTM[44]、Bilinear-CNN(Bilinear Convolutional Neural Network)[45]、MaxEnt-CNN(Maximum Entropy Convolutional Neural Network)[46]、FCAN (Fully Convolutional Attention Network)[47]、BYOL+CVSA (Bootstrap Your Own Latent+ Cross View Saliency Alignment)[48]和MAMC(Multi-Attention Multi-class Constraint)[49]在CUB、DOG和NAB上进行实验对比,结果见表2~表4。其中,Method表示对比方法,Resolution表示输入图像分辨率,Acc(Accuracy)表示识别准确率,Baseline指代Swin Transformer。
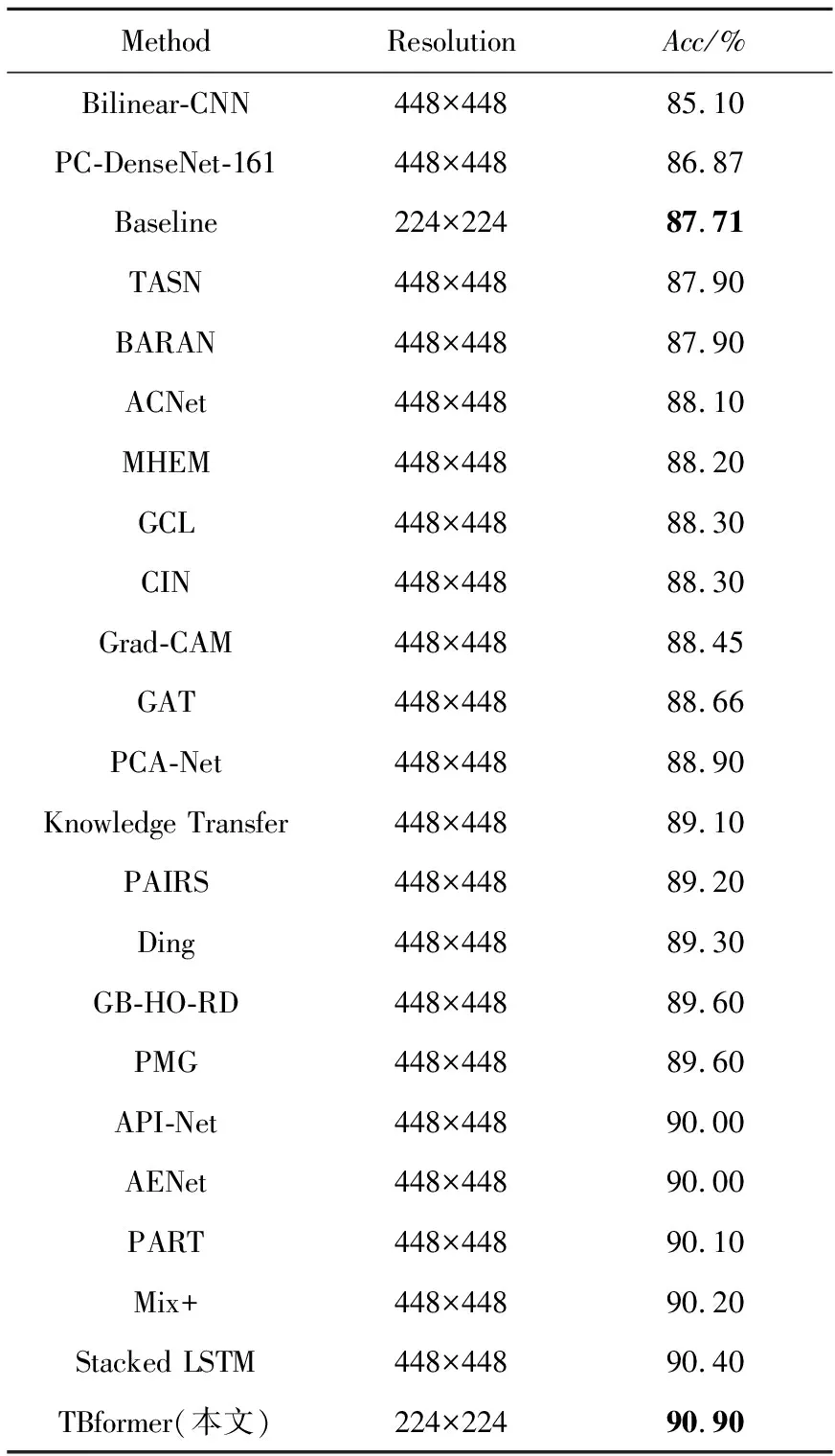
Table 2 Experimental results on CUB
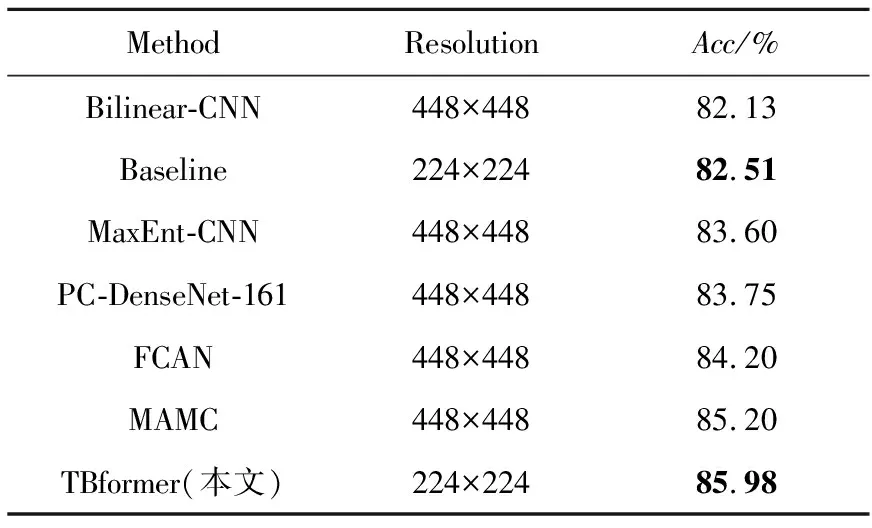
Table 3 Experimental results on DOG
在CUB上,TBformer的准确率比Baseline的高3.19%,比MHEM的高2.7%,比Stacked LSTM的高0.5%。在DOG上,TBformer的准确率比Baseline的高3.47%,比FCAN的高1.78%,比MAMC的高0.78%。在NAB上,TBformer的准确率比Baseline的高1.09%,比MaxEnt-CNN的高2.31%。表5对比了TBformer和Baseline的复杂度、参数量和推理速度。从表5可知,虽然TBformer的复杂度和参数量增长较为明显,但其推理速度相比Baseline的只减弱了25%左右。综合考虑精度与速度因素,TBformer仍是一种性价比较高的模型,且其只需输入低分辨率图像即可达到较先进的水平,具有一定程度的优越性。
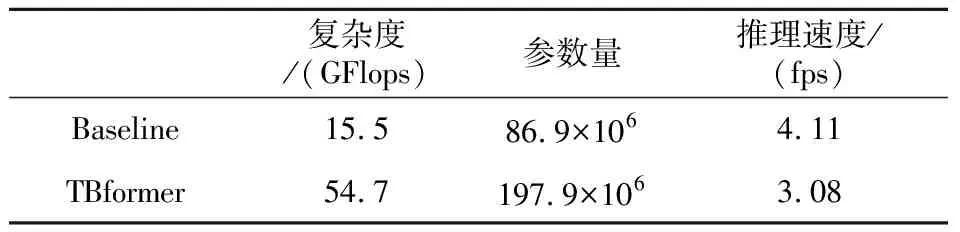
Table 5 Comparison results of model complexity,parameter number and inference speed
4.3.2 消融实验
为了验证本文模型的有效性,在CUB上对三分支特征提取、特征融合和多损失训练进行消融实验,实验结果如表6所示。

Table 6 CUB ablation results
由表6可知,本文提出的三分支特征提取、特征融合和多损失训练均比Baseline表现更佳。DLModule负责消除冗余背景信息的干扰并定位关键目标。定位双分支捕获了定位图像中更精细的特征信息。三分支特征提取引入原始特征作为定位特征的补充,充分提取了目标判别性特征。特征融合成功捕捉了多特征中的深层细粒度信息。多损失训练通过调整类间、类内方差,有效改善了模型对多特征的不完全监督性。最终本文方法在CUB上的识别准确率达到了90.9%,相比Baseline的提升了3.19%,证明了提出的三分支特征提取、特征融合和多损失训练的有效性和互补性。
4.3.3 辅助对比实验
为了验证ECA通道注意力的有效性,表7在CUB上对TBformer引入不同注意力机制进行了对比。TBformer通过自注意力计算像素间的依赖,在特征融合时,CBAM(Convolution Block Attention Module)[50]和GCNet(Global Context Network)[51]由于引入了空间维度信息干扰了网络对特征的自注意力建模,导致网络识别能力下降。SE(Squeeze-and-Excitation)[52]和ECA通过筛选出有效通道,对计算像素间依赖起到正向调节作用。SE直接降维损失了部分通道信息,ECA避免直接降维保留了更多关键通道信息,因此后者效果好于前者的。分析表明,TBformer中引入ECA通道注意力的确是一种有效的做法。

Table 7 Performance comparison of different attention mechanisms
为了进一步验证ERnet中ECA嵌入方式的有效性,表8在CUB上对不同嵌入方式进行了对比。特征经过4层主干卷积后维度逐层加深。随着特征维度增加,ECA能捕捉的局部信息减少,影响了ERnet对目标的定位,削弱了DLModule提取定位图像的准确性,从而导致TBformer的识别能力下降。在ERnet主干卷积层前嵌入ECA对TBformer识别能力的提升最为明显,是一种有效的嵌入方式。
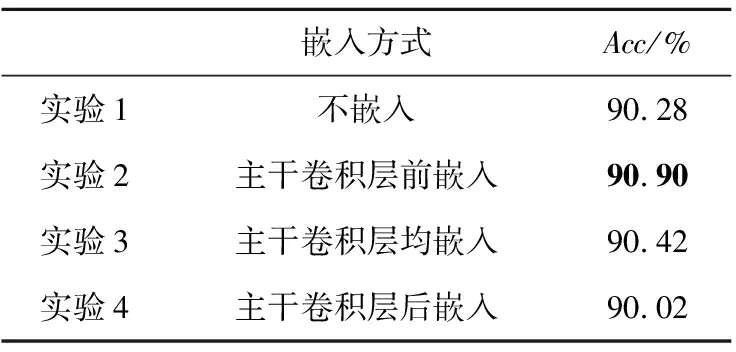
Table 8 Comparison of ECA embedding methods in ERnet
4.3.4 热力图分析
为了直观地表现出TBformer的先进性,本文选取CUB数据集中2种不同父类进行可视化分析。图8为Baseline和TBformer对部分图像的热力图,每一部分从上到下依次为原始图、Baseline热力图、TBformer热力图。模型重点关注部分以热力图中白色实线包围区域表示,其中黄胸大莺无兄弟类,靛蓝彩鹀、琉璃彩鹀、丽色彩鹀同属彩鹀类。TBformer通过多分支特征提取模块剔除无关背景和其它干扰因素并充分提取关键特征,且使用特征融合模块构建更精确、更全面的特征,从而相比Baseline其克服复杂背景、抗干扰、识别能力更强。对于黄胸大莺类别,在简单或复杂背景下,TBformer都能更准确地捕获头部判别性区域。琉璃彩鹀的判别性区域为头部,靛蓝彩鹀和丽色彩鹀的判别性区域为腹部和翅部,对于这3类彩鹀,TBformer仍能更准确地捕获各类判别性区域。上述分析表明,在某个类别有或无子类的情况下,TBformer都比Baseline表现更佳,是一种有效的细粒度分类方法。
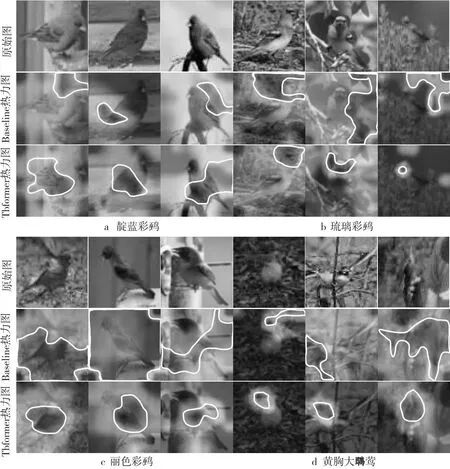
Figure 8 Heat maps of four species of birds based on Baseline and TBformer图8 Baseline和TBformer对4种鸟类的热力图
4.3.5 探讨性实验
考虑到定位图像仍含有部分背景,对方法性能有一定的影响,因此本节尝试对图像做进一步分割处理。由于目前CUB、DOG、NAB数据集缺少绝大多数分割算法需要的相应标注,如trimap(三元图,一般用白色表示前景,黑色表示背景,灰色表示待识别的部分)或scribbles(在前景和背景画几笔的草图),导致分割操作难以进行。GrabCut[53]是一种只需分割对象的指定边界框即可完成分割的算法,用在本文中边界框大小可用图像的原始大小代替。
GrabCut基于图割(Graph Cut)实现图像分割,通过高斯混合模型GMM(Gaussian Mixture Module)来分离背景和前景。由于部分图像(包括原始图像和定位图像)前景和背景的颜色、纹理较为相似,导致基于GrabCut的分割效果较差,从而影响方法最终性能,故考虑对分割图像进行人工弱筛选处理。而且,模型在训练时需等待分割完成后才顺序处理分割图像,而基于GrabCut的分割由CPU完成,其速度较为缓慢,故若在TBformer内进行分割操作将造成GPU资源的浪费,从而使模型训练时间大幅度延长。
综合上述分析,最终本文选择在对图像进行预处理时采用分割操作,并采取图9所示的预处理方法完成分割以及弱筛选过程。
预处理方法具体操作步骤如下:首先,使用GrabCut处理原始图像生成分割图像;然后,对分割图像进行如下弱筛选:依次观察分割图像每个类别数据,一经发现某个类别下含有丢失较多部位的图像,则将此类下所有分割图像复原为原始图像,即该类下图像一律不进行分割处理;最后,分割图像经弱筛选后转变为由原始图像和分割图像组成的混合图像。
对原始图像进行预处理后将混合图像输入至TBformer进行训练,TBformer在原始数据、分割数据以及混合数据上的结果对比如表9所示。
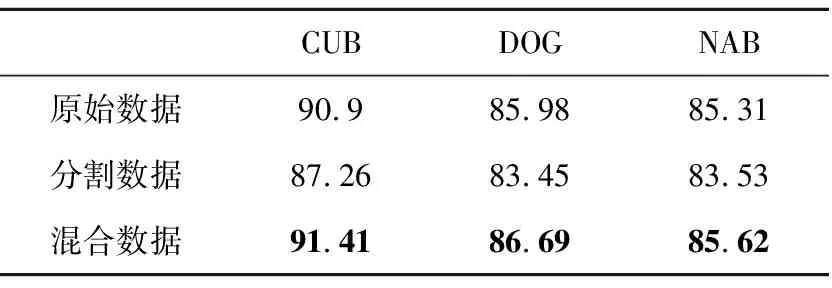
Table 9 Results of TBformer on raw data,seg data and mixed data
由表9可知,TBformer在分割数据上的性能较原始数据上的反而有所下降,而在经过弱筛选的混合数据上性能较原始数据上的则有所提升,在CUB、DOG、NAB数据集上的准确率分别提升了0.52%,0.71%和0.31%,证实了对分割图像进行弱筛选的有效性。但是,在数据标注缺失、不对分割图像做辅助处理的情况下,如何得到高准确率的分割数据仍是一个挑战。
5 结束语
在Swin Transformer基础上,本文提出了一种改进的细粒度识别模型TBformer。该模型使用DLModule提取目标定位图像,有效缓解了背景的干扰。为了弥补定位图像潜在的损失,设计了基于DLModule的三分支特征提取模块,充分提取了目标判别性特征。在提取特征后使用特征融合模块处理三分支特征,该模块通过挖掘特征内深层细粒度信息,增强三分支特征的全面性、精确性,提高模型的鲁棒性。为了完全监督多特征的学习,混合交叉熵损失和对比损失得到多种损失,基于多损失训练模型,提升了本文方法整体性能。相较基础方法,本文方法的性能在CUB、DOG、NAB数据集上取得了较为显著的提升。相较其它方法,本文TBformer在3个数据集上也有不俗的表现。最后,由于定位图像仍含有的部分背景可能对方法性能造成一定的影响,本文对图像分割进行了探讨性实验。TBformer在经过GrabCut处理的分割数据上的性能反而不如原始数据上的,而对分割数据进行弱筛选后,TBformer在混合数据上的性能较原始数据上的则有所提升,表明对分割图像进行弱筛选确实是一种有效的做法。但是,在目前分割算法所需相应标注缺失、不对分割图像做辅助处理的情况下,如何获得高准确率的分割数据仍是一个挑战,未来将对该方面工作做进一步研究。
