基于图强化学习的配电网故障恢复决策
2024-02-20陈玉鑫王光华李晓影
张 沛,陈玉鑫,王光华,李晓影
(1.北京交通大学电气工程学院,北京市 100044;2.国网河北省电力有限公司保定供电分公司,河北省 保定市 071000)
0 引言
配电网造成的故障停电时间占总停电时间的80%[1]。分布式电源(distributed generator,DG)的接入使传统的辐射状配电网变成了多电源多端系统,使配电网的运行和保护更加复杂[2]。因此,研究有效的含DG 配电网的故障恢复方法十分必要。
配电网故障恢复是指在配电网线路发生故障并被切除后,通过对系统中常用馈线与联络线的线路开关控制,重新组织系统网络拓扑以完成对下游失电负荷的供电恢复。国内外对此已做了大量相关研究,常见的方法有启发式搜索算法、专家系统法、数学优化算法、图论算法、混合算法等[3]。当DG 大量并入电网后,其带来的电源支撑作用受到关注。文献[4-6]提出了配电网停电状态下的孤岛划分方法,但没有考虑到输电网电源供电下的网络重构问题。文献[7-9]综合考虑DG 发电与网络重构进行配电网故障恢复,将主动孤岛与网络重构相结合。文献[10]首先确定各孤岛系统的最佳供电范围,然后利用改进支路交换法进行重构优化。文献[11]在电网重构过程中进行孤岛划分,将孤岛划分后的负荷恢复率纳入总体目标函数,使重构和孤岛划分结果同时影响最终的全局最优解。以上文献同时考虑了DG 的支撑作用与网络拓扑变换两种故障恢复方式,但忽略了DG 带来的不确定性,即都只在一个“时间断面”上对故障恢复进行研究,忽略了DG 的出力变化。
对于以上问题,文献[12]提出多时间尺度下的含DG 配电网故障动态恢复策略,证明了在电网含DG 时,不同的DG 出力场景会显著影响恢复策略;文献[13]利用滚动预测模型考虑了多个时间段之间配电网状态的相关性,提出了基于鲁棒模型预测控制的弹性运行策略;文献[14]考虑光伏及负荷的时变性,验证了其对故障恢复决策的影响,同时证明了不同故障恢复时间尺度也会影响光伏及负荷的变化,从而最终影响故障恢复决策。
除了DG,考虑到方法的实用性,不少学者将实际检修场景与配电开关设备纳入考量。文献[15]将DG 的黑启动能力与实际情况中的检修次序纳入考虑,在减少故障下切负荷量的同时优化故障检修策略;文献[16]进一步考虑配电网中不同种类开关的可控性差异,从而与检修人员的检修策略结合进行优化;文献[17-18]提出了基于新型电力电子装置智能软开关(soft open point,SOP)的故障恢复策略,但其对配电设备本身性能具有较强的依赖性。以上成果均充分研究了含DG 的配电网故障恢复问题,但仍存在以下不足:1)所建模型均为规划模型与搜索模型,而在大规模系统中,DG 与负荷的不确定性将使得求解场景变得复杂,且开关动作组合将出现爆炸式增长,以上求解算法的求解速度将大大限制其在线应用的能力;2)均只在一种固定的配电网拓扑结构进行故障恢复的研究,故障恢复方法对配电网频繁变化的拓扑结构适应性不强。
因此,本文考虑配电网网络拓扑变化,提出一种基于图强化学习的含DG 的配电网故障恢复决策方法。本文的主要贡献如下:
1)将图神经网络与强化学习(reinforcement learning,RL)相结合,搭建了图强化学习(graph reinforcement learning,GRL)故障恢复模型,设计GRL 状态空间、动作空间与奖励函数,完成智能体的训练与交互;
2)利用图数据表征配电网拓扑结构与电气特征信息,设置前置图神经网络接收并处理图数据,利用图神经网络对变化拓扑的处理能力提高对配电网拓扑变化的适应性;
3)设置后置图神经网络嵌入强化学习框架,在利用配电网网架结构信息的同时,充分利用RL 对不确定性因素的天然适应性进行快速求解,满足在线求解需求。
1 GRL 模型框架
GRL 的整体框架如图1 所示。首先,将含DG的实际配电网抽象为图数据,图数据包含实际配电网的网络拓扑及其电压特征数据X两部分。然后,将抽象出来的图数据输入GRL 模型,GRL 中先搭建两层前置图卷积网络(graph convolutional network,GCN)来处理图数据,完成图数据的接收、信息提取、聚合与转化后,将处理后的特征信息传递给下游任务。在下游深度Q 网络(deep Q network,DQN)框架的eval net 和target net 中各嵌入两层GCN,以进一步提取网架信息与电压电流特征信息,且这两层GCN 将随DQN 一起更新,最终由eval net 输出t时刻动作值at。智能体执行动作at,环境状态由当前状态st切换为下一状态st+1,并反馈当前动作奖励值rt供智能体进行学习。
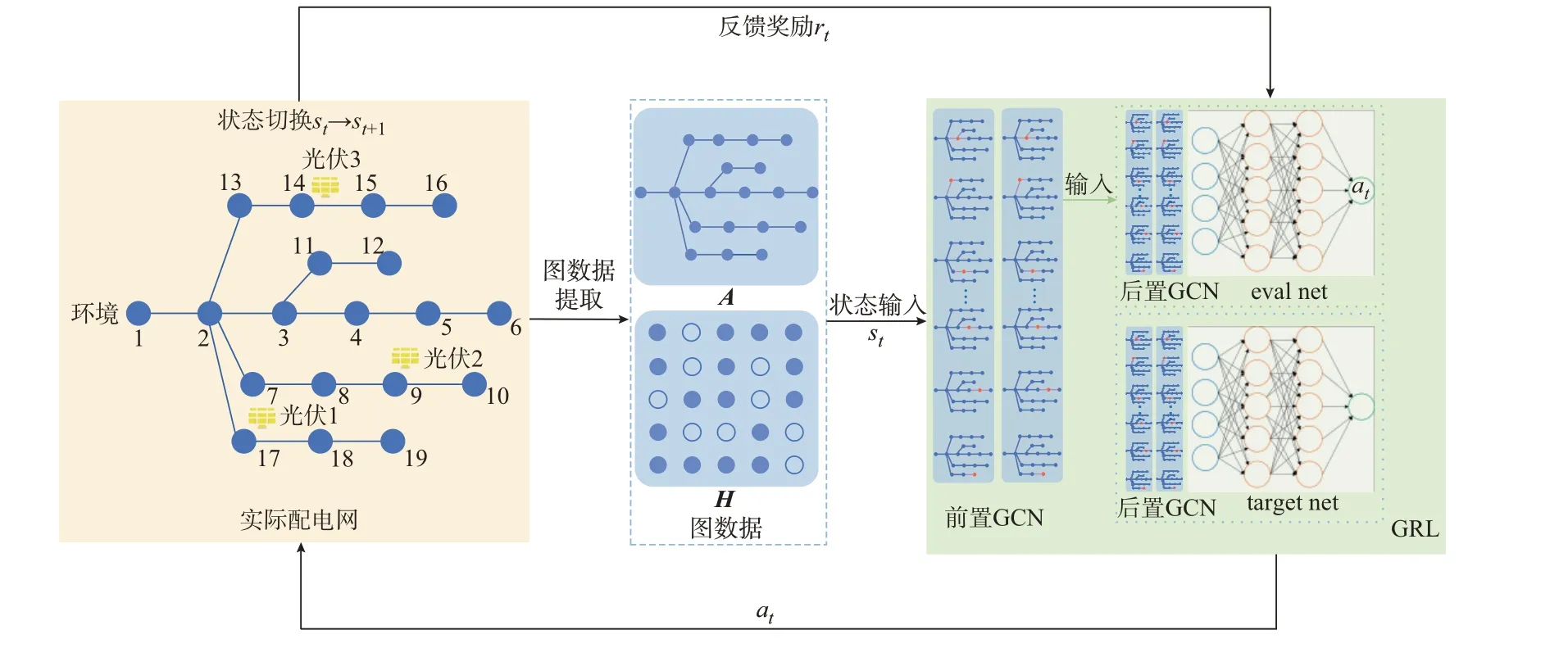
图1 GRL 算法框架Fig.1 Framework of GRL algorithm
在图数据提取部分,将实际配电网的网架拓扑与电气特征信息抽象为图数据。其中,网架拓扑结构常用邻接矩阵来描述。设图G=(V,E)中含有n个节点,节点集合V={v1,v2,…,vn},其中,vi表示第i个节点,i=1,2,…,n,则其邻接矩阵A(G)=[aef]n×n,其元素aef可表示为:
式中:下标e和f为节点编号;E为边集合。
图1 中实际配电网的邻接矩阵ADN为:
由实际配电网接线关系抽象出来的图的邻接矩阵表征各节点之间的连接关系,即拓扑结构。而节点电压与线路电流分别为节点与边上的特征数据,拓扑结构与特征数据H共同组成了图数据。
在状态输入部分,首先由前置GCN 完成对配电网图数据的接收、信息提取、聚合与转化。GCN 是深度神经网络(deep neural network,GNN)中的典型类型,其将卷积运算从图像等传统数据推广到图数据。图卷积操作的实现公式为:
式中:H(l+1)为第l层GCN 卷积处理后的输出信息;H(l)为第l层GCN 的输入信息;Â=A+Ιn,其中,A为图的邻接矩阵,In为单位矩阵;D为度矩阵;W(l)为第l层GCN 的权重参数矩阵;σ(·)为激活函数。L=又称拉普拉斯矩阵,其作用是防止在运算中出现数值不稳定的情况。
由式(3)可知,W(l)的矩阵维度与图的规模(即图中节点数量)无关,只与各节点输入特征维度有关,即每个节点上的图卷积核参数W(l)是共享的。例如,当图中包含g个节点且每个节点的输入特征维度为k时,即每个节点上采取了k个不同的特征输入(本文模型的节点输入特征为三相电压,即k=3),则H(1)的维度为g×k,W(1)的维度为k×k,与整个图的维度g无关。这意味着,GCN 在每一层实现了参数矩阵的全图共享,这也是GCN 在训练过程中可以处理变化拓扑任务的根本原因。图2 显示了GCN 在针对图数据进行卷积操作过程中的参数共享方式。
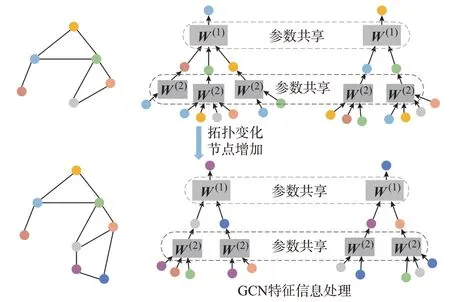
图2 GCN 参数共享示意图Fig.2 Schematic diagram of GCN parameter sharing
前置GCN 将处理后的信息传递给下游GRL 智能体,在RL 框架中嵌入了两层后置GCN,后置GCN 在训练过程中与全连接神经网络保持同步更新。考虑到配电网故障恢复决策问题中的控制对象为系统中的各线路开关,每个线路开关只有“断开”与“闭合”两种状态,而一个确定的配电网中的线路开关数量是有限的,属于离散动作输出。因此,选择RL 中的DQN 算法,其算法流程如图3 所示。
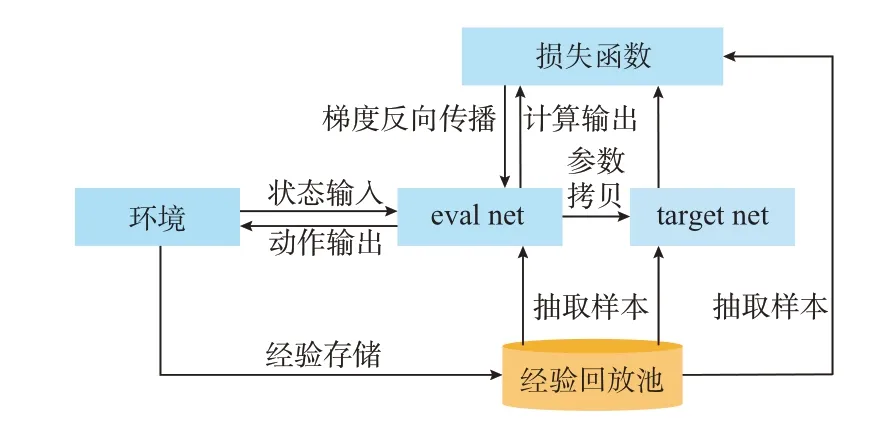
图3 DQN 算法流程Fig.3 Process of DQN algorithm
DQN 算法通过经验回放池与冻结神经网络两项机制打破数据之间的相关性,提升训练效率[19]。如图3 所示,智能体训练过程中每完成一次训练交互过程便产生一条经验放入经验回放池,当经验回放池中经验存到一定数量后智能体开始进行学习,即从经验回放池中提取批记忆,分别将记忆中的(s,a)与s'输入eval net 与target net 计算Q值,其中,s'为状态s的下一个状态,a为动作,再利用Q值计算损失函数,并根据神经网络的反向传播算法对当前eval net 网络的参数进行更新,经过固定迭代次数后,将target net 网络参数替换为eval net 网络参数。
2 马尔可夫决策过程建模
2.1 状态空间
智能体所能获取的所有系统信息共同组成了系统状态空间。系统状态信息代表了智能体所感知到的环境信息,包括执行完智能体输出的动作后环境所发生的变化。从强化学习的目标来看,状态信息是智能体制定决策和评估其长期收益的依据。因此,状态空间设计的好坏直接决定了GRL 算法能否收敛、收敛速度以及最终性能。
本文提出的GRL 配电网故障恢复方法中系统状态空间设计为:
式中:St为t时刻系统状态空间;Vt为t时刻系统节点电压向量;Gt为t时刻配电系统拓扑图,其内含网络拓扑的结构信息。
2.2 动作空间
考虑到配电网故障恢复策略的执行过程中,不仅需要获知故障恢复后系统中各线路开关的状态,也需要获知在故障恢复过程中每步动作的具体开关操作顺序,本文模型中的动作空间Aa设计为:
式中:ai为改变系统中第i条线路的开关状态,即若当前系统中第i条线路为断开状态,则闭合其线路开关使线路重新投入,若当前系统中第i条线路为闭合状态,则打开其线路开关使线路断开以退出运行,这种设计有效避免了动作选择的不合法性;下标Nl为系统中的支路数量;Nj为第j个回合已经操作过的线路集合,这样可以有效避免动作的无效性。
2.3 奖励函数和状态转移概率
奖励函数R分为两部分,即奖励部分Rr与惩罚部分Rp。首先明确一个完整回合包含多个单步动作,其中,第h回合第c次动作的奖励的数学表达式为:
式中:Rr,c为当前回合第c次动作奖励函数的奖励部分值;Ploss,c为第c次动作执行完后的负荷损失功率;Pnet,c为第c次动作执行完后的网络损耗功率;PL为配电系统总负荷;ΔRr,c为附加奖励部分,其含义为本回合中当前动作与上一个动作相比负荷恢复率的增加值,用来描述当前动作在故障恢复任务中作出的新贡献;Rgreat为稀疏奖励值,当前动作执行完后系统负荷恢复率为100%,且满足各种运行约束,此时赋予较大的稀疏奖励值以加强对智能体学习方向的引导。若Ploss,c-1-Ploss,c>0,则当前动作与上一个动作相比故障恢复率有所上升,即当前动作对故障恢复产生了新的积极影响;若Ploss,c-1-Ploss,c<0,则说明当前动作不仅没有恢复更多的失电负荷,反而使停电范围进一步扩大。另外,若当前动作为本回合的第1 个动作,即c=1 时,附加奖励值为0。考虑到实际系统中的倒闸操作时间与误操作率,在达到相同故障恢复效果时,开关动作次数应越少越好。
动作的惩罚部分包括电压越限惩罚、电流越限惩罚和配电网辐射状拓扑约束惩罚。第h回合第c次动作的惩罚的数学表达式为:
式中:Rp,c为当前回合第c次动作奖励函数的惩罚部分值;PV,c、PI,c和PLoop,c分别为第c次动作的电压越限惩罚、电流越限惩罚和配电网辐射状拓扑约束惩罚。
对于电压越限惩罚和电流越限惩罚,其数学表达式如下:
式中:PU为当出现电压越限时设置的惩罚值;PI为当出现电流越限时设置的惩罚值。
对于配电网辐射状拓扑约束惩罚,综合考虑经济性与安全性,配电网要求“闭环设计、开环运行”,配电系统环网示意图见附录A 图A1。若配电网拓扑出现环网结构,在发生短路故障时易造成短路电流过大等问题,从而降低供电可靠性。因此,此时要给予相应开关动作一定的惩罚。第h回合第c次动作的配电网辐射状拓扑约束惩罚的数学表达式为:
式中:PLoop为配电网辐射状拓扑约束惩罚。
智能体最终的目标是长期奖励最大化,最终系统奖励函数Rc为奖励部分与惩罚部分之和:
在不计动作时间的前提下,系统每执行完一个开关动作后其下一个状态都是确定的。因此,在本模型中,状态转移概率始终为1。
3 算例仿真
3.1 测试算例与效果展示
为验证本文所提方法的有效性,本节利用改进的PG&E 69[20]节点算例进行验证。
PG&E 69 节点算例系统中包含69 个节点、78 条线路,如图4 所示。其中,该系统包括73 条常用馈线与5 条备用联络线,其24 h 负荷功率曲线参考文献[21],分布式光伏24 h 出力及位置设置参考文献[14]。在节点5、19、23、44、47、63 处设置分布式光伏,渗透率为52.7%,DG 具体参数见附录B 表B1。需要指出的是,考虑到目前实际配电网中并未实现完全自动化,实际电网中线路开关切换操作仍由调度操控人员参与执行,本文的求解结果更倾向于“给调度操控人员提供开关动作参考”而非直接“参与自动控制流程”。本文提出的方法最终求解出的恢复策略包括具体的开关操作位置与操作顺序,至于前后两个开关动作之间应该间隔多长时间,应取决于调度操控人员的指令下达及实际开关切换的执行情况。因此,本文的重点在于复杂场景下恢复策略的求解上,而不在恢复策略的执行上。
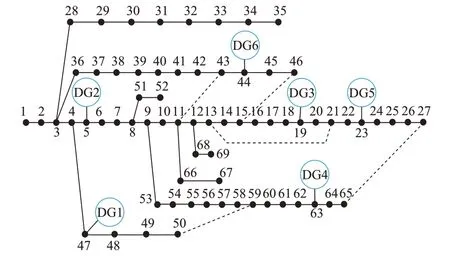
图4 PG&E 69 节点配电系统Fig.4 PG&E 69-bus distribution system
本文提出的GRL 模型共进行了20 000 回合的训练,训练时间共计2 h,最终收敛效果较好。其中,奖励函数曲线如图5 所示。单一回合中每次动作获取的奖励函数最能够直观反映模型的表现,奖励函数变化曲线能够展现模型的训练成长过程。
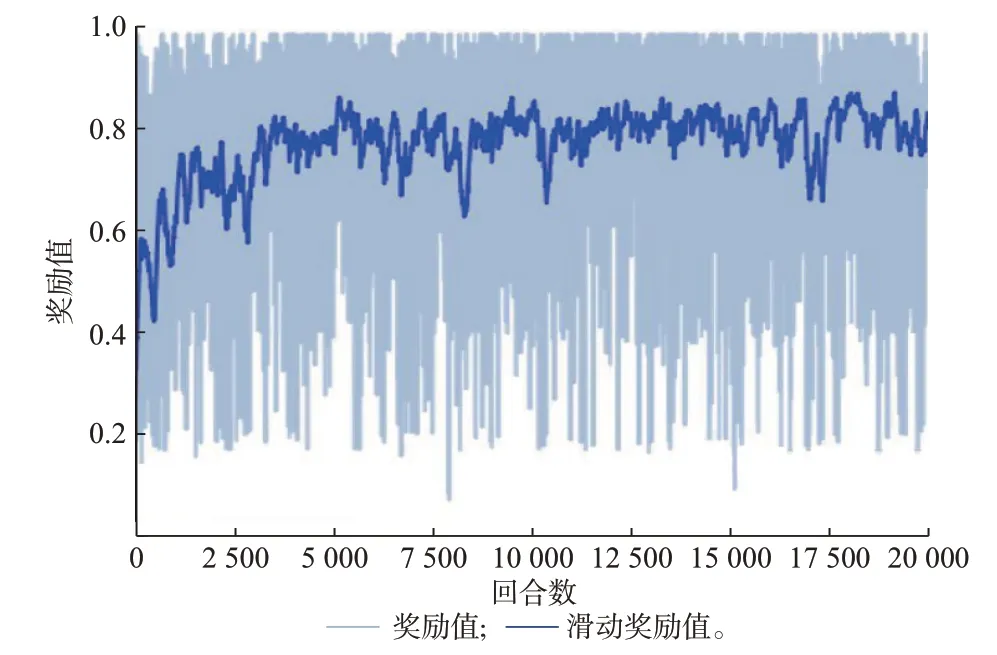
图5 奖励函数曲线Fig.5 Curves of reward function
根据图5 可知,训练初期由于无先验知识,智能体在训练环境中多进行随机探索;训练中期,经验记忆池中累积了足够多的先验知识,智能体开始周期性地提取先验知识进行学习,然后在此基础上再次针对不同环境选择动作,继续训练;训练后期,智能体以99%的概率选择其认为的最优动作,保持1%的概率随机选择动作,即保持1%的随机探索。此时,奖励函数到达收敛值,智能体对系统中绝大部分故障均能给出有效的恢复策略。表1 为训练完成的智能体针对部分故障给出的恢复策略。其中,负荷的恢复通过仿真平台OpenDSS 提供数据进行计算,负荷恢复率是指当前在线负荷占初始总负荷的比率,线路用首末端编号表示。
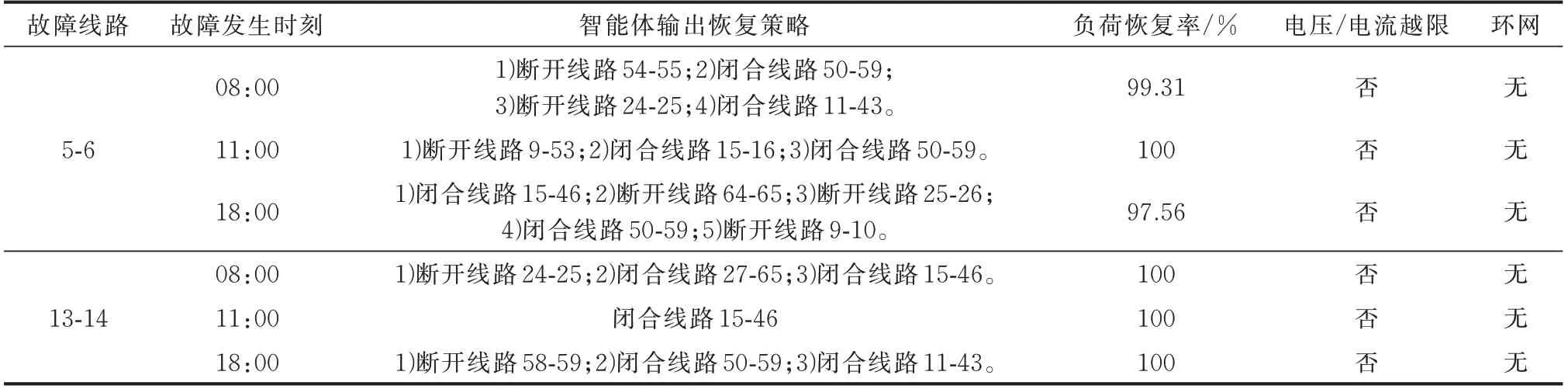
表1 故障恢复策略Table 1 Fault recovery strategy
假设两处特征线路发生故障:线路5-6 靠近主网电源,大部分联络线在其下游;线路13-14 靠近辐射状支路中段,临近位置联络线较多。针对每处故障,假设在3 个特征时刻发生故障:08:00 时分布式光伏有部分出力能力,负荷处于一天中的上升阶段;11:00 时分布式光伏出力达到最大值;18:00 时负荷值为一天中的最大值,此时日落光伏出力为0,分布式光伏无法提供电源支撑能力,只能控制线路开关状态重构网络拓扑,使失电负荷与主网电源重新建立有效连接以恢复供电。
当线路5-6 在18:00 发生故障时,由于分布式光伏此时无法提供电源支撑,与08:00 时相同线路发生故障相比,其恢复策略中动作次数较多,负荷恢复率较低。线路5-6 在18:00 发生故障时的恢复策略中,首先闭合线路15-46 将下游失电负荷与上游主网电源进行连接,但此时由于支路负荷过长,负荷节点多,下游末端节点53 至65、25 至27 出现严重电压越下限现象,智能体判断进行切负荷操作,依次断开线路65-65 和25-26,切负荷后电压越限仍然存在。然后,闭合线路50-59,从另一方向利用主网电源进行供电支撑,此时各节点电压恢复至允许范围之内,但拓扑结构层面存在环网。最后,断开线路9-10,环网消除,完成负荷恢复。
如表1 所示,不同线路在不同时刻发生故障时,本文构建的GRL 模型中智能体均可以给出可行的故障恢复策略,包括具体的线路开关操作位置及操作顺序。两处线路在任意时刻发生故障时,智能体输出的恢复策略负荷恢复率均能达到99%以上,且均能满足电压不越限、网络拓扑无环网的运行约束。可见,本文构建的GRL 模型在含DG 的配电网发生故障后可给出满足各种约束的可行故障恢复策略。
为了进一步体现本文所提方法的优势,下面就本文提出的方法与其他方法在3 个方面进行对比分析。
3.2 算例对比分析
3.2.1 故障恢复策略效果对比
表2 展示了线路5-6 在08:00 发生故障后不同方法的恢复策略及恢复效果。如表2 所示,面对故障后的复杂形势,4 种方法均能求解出有效的恢复策略。其中,方法1 为启发式方法,按制定好的规则进行寻优,策略中动作次数最多,负荷恢复率较低;方法2 为蚁群算法,求解完成后直接给出最终策略中包含的所有动作,并未给出动作执行的先后顺序,与电网调度中心的实际操作要求不符;方法3、方法4 均属于人工智能强化学习算法,序贯决策下均能给出包含开关动作顺序的恢复策略,负荷恢复率高且决策时间短,能够有效缩短用户停电时间,负荷恢复率均能达到99%以上。
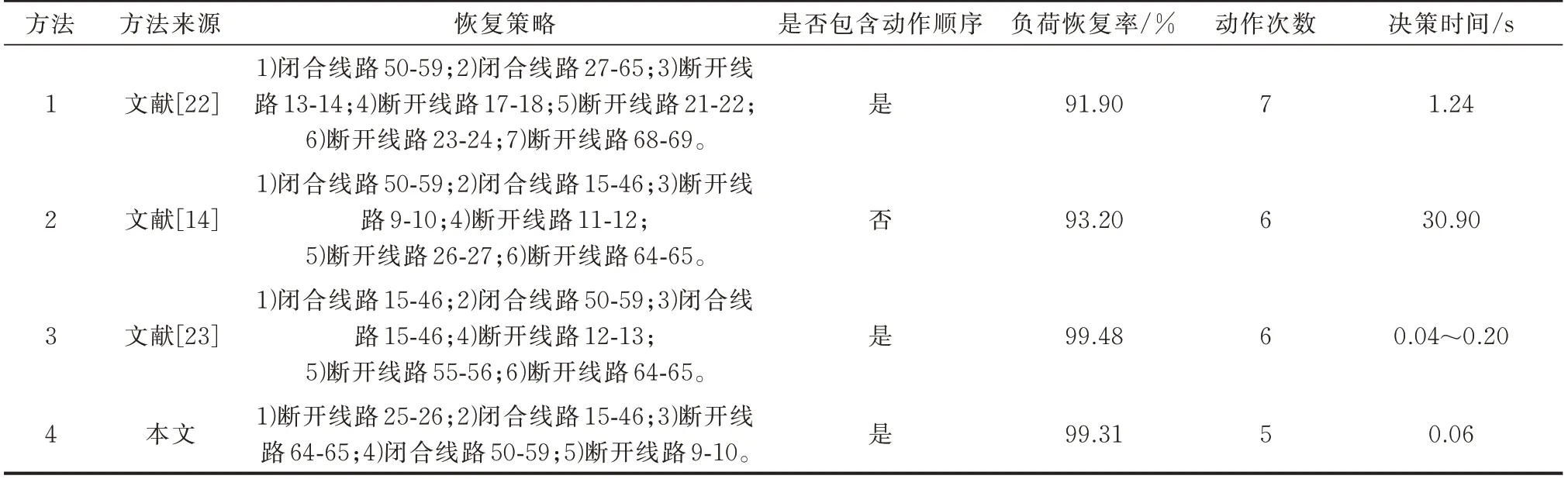
表2 故障恢复策略效果对比Table 2 Effect comparison of fault recovery strategies
3.2.2 变化拓扑下RL 与GRL 恢复效果对比
假设算例系统因负荷投切、优化线损或发生计划性检修等原因发生网络拓扑变化,变化后的网络拓扑图见附录C 图C1。直接利用拓扑变化之前训练好的本文模型与深度强化学习模型分别对拓扑变化后的配电网进行故障恢复决策。从发展的角度,假设配电网发生规划层面的扩建,在原系统架构基础上在节点52、69 下游新增负荷节点70 至74,新增节点的节点负荷均与上游连接节点一致。此时,系统节点数量发生变化,模型输入维度也发生变化,而深度强化学习模型中的神经网络输入层维度不变,深度强化学习方法将不再适用。测试结果如表3 所示。表中:平均负荷恢复率为在变化后电网拓扑基础上,随机选取5 处故障进行故障恢复后的负荷恢复率的平均值。
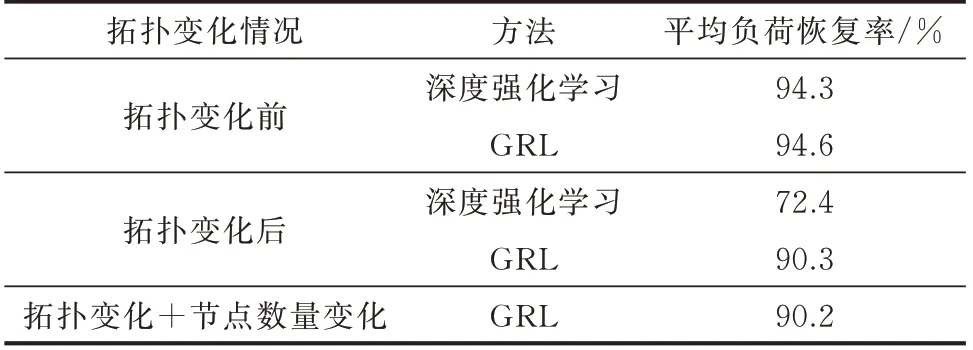
表3 拓扑改变后的恢复效果对比Table 3 Comparison of recovery effects after topology changes
根据表3 可知,深度强化学习在拓扑变化后平均负荷恢复率下降幅度较大。本文提出的GRL 方法负荷恢复率略有下降,对“拓扑变化+节点数量变化”的情形,平均负荷恢复率也能维持在90%以上,对拓扑变化表现出了良好的适应能力,电网拓扑变化后仍能给出有效的故障恢复策略,与RL 方法比较优势较为明显。
因此,本文提出的方法在兼顾求解速度与故障恢复率的基础上,保证了对配电网网络拓扑变化的适应性,充分体现了RL 方法与图神经网络的优势。
4 结语
针对配电系统拓扑频繁变化使配电网故障恢复策略求解效率下降的问题,本文提出了基于GRL 的含DG 的配电网故障恢复方法,并利用PG&E 69 节点算例进行测试。通过与其他求解方法进行对比分析可得出以下结论:
1)本文提出的方法能够在线求解含DG 的配电网故障恢复策略,包括具体的操作开关与操作顺序,求解策略故障恢复率高,求解时间短,兼顾求解质量与速度。
2)与启发式算法、优化算法相比,相同故障情形下GRL 模型决策故障恢复率更高,求解速度优势明显。
3)本文提出的方法对配电网拓扑变化具有更好的适应性,训练好的模型应用到拓扑变化后的配电网故障恢复问题中,仍有较好的故障恢复决策效果。
本文考虑了DG 与负荷不确定性造成的复杂求解场景,也考虑了不同时刻、不同位置发生故障对决策带来的影响,但求解用到的源荷出力都是故障时刻的实际值,并不是预测值,未考虑到因动作执行或指令下达所造成的求解时刻与动作执行时刻之间的“时间差”,也就是“时间滞后”带来的影响,这在一定程度上会影响方法的实用性;为简化模型,本文训练过程中设置的负荷曲线为固定曲线,对负荷不确定性模拟尚可提高;智能体并不能在实际的配电网环境中直接试错训练,可先通过仿真模拟的方法进行智能体训练及超参的优化,待训练完成后投入使用,以保证不会对实际配电网带来安全运行上的问题。
附录见本刊网络版(http://www.aeps-info.com/aeps/ch/index.aspx),扫英文摘要后二维码可以阅读网络全文。
