基于多尺度特征融合的负荷辨识及其可解释交互增强方法
2024-02-20刘熙鹏罗庆全蓝超凡蔡清淮吴毓峰
刘熙鹏,罗庆全,余 涛,2,蓝超凡,蔡清淮,吴毓峰
(1.华南理工大学电力学院,广东省 广州市 510640;2.广东省电网智能量测与先进计量企业重点实验室,广东省 广州市 510640)
0 引言
在“双碳”目标驱动和新型电力系统建设的要求下,构建清洁低碳、安全高效的能源体系成为电网发展的主题[1]。负荷辨识技术通过对用电负荷的快速识别,能够有效获取用户用电信息,据此制定针对性的家庭能量管理方案[2-3]和需求响应策略[4],提高需求侧电能调度能力,改善电网潮流状态[5]。
随着智能量测体系的逐步完善和人工智能技术的发展,负荷辨识领域的研究也取得了长足的进展[6]。但是,现有方法在负荷长短期特征利用和模型可解释性等方面仍存在不足,限制了辨识模型鲁棒性、泛化性和可靠性的提升。因此,本文以上述不足为切入点,开展具有较高识别精度和泛化能力的基础辨识模型的设计研究。
在特征提取方面,国内外研究围绕负荷的各频率量测数据提取了一系列负荷特征[7-8]。根据文献[6],将负荷特征划分为依赖于高频量测的短期特征和依赖于中、低频量测的长期特征。其中,长期特征按照时间尺度的不同又分为启动特征和运行特征。启动特征反映了负荷在投切过程中的动态特性[9],如启动尖峰[10]、启动时长[11]。运行特征则反映了负荷的工作模式,如体现运行波动性的功率差分值、功率浪涌[12],体现运行规律特性的占空比、峰峰值、能量分箱[13-14],以及体现运行时间特性的运行时长、使用时段[15]。短期特征则体现了负荷的电路结构特性,除有功功率、无功功率、谐波等基础特征[16]和波形不对称度、尖峰电流比等电流波形特征[17]外,图像化特征成为近期研究的热点[18-20],如递归图[18]、电压-电流(V-I)轨迹[21]。为实现对多种短期特征的综合利用,也有文献将传统短期特征与V-I轨迹图像结合,形成一系列彩色V-I轨迹特征[22-24]。
同类型电器由于实现电路不同,在短期特征上可能存在差异,而不同类型的电器也可能因工作模式的相似而具有相近的长期特征。因此,充分利用负荷长、短期特征间的互补作用可以提升识别效果。文献[25]利用shapelet 提取多尺度特征,并采用线性加权实现特征融合;文献[10,26-27]分别利用时序概率模型、D-S 证据理论和神经网络融合长短期特征。但从总体上看,结合长、短期特征进行负荷辨识的研究仍然较少,且存在提取特征表征能力局限、多尺度特征融合能力不足的问题。
在模型可解释评估方面,现有深度学习模型往往性能强大,却无法对其决策过程做出有效解释。由于缺少模型的可解释过程,使用人员难以完全信任模型结果,也难以通过人机协同交互实现模型持续趋优。因此,人在回路的混合增强智能[28-29]、代理模型[30]、互信息优化[31]等可解释框架和方法也在电力系统的各个领域得到了初步尝试。然而,到目前为止,利用人机可解释交互实现模型改进和可解释验证的相关研究仍相当缺乏。
近年来,在特征提取模型方面,双塔模型在异构特征学习上初步展现有效性[32-33]。其通过不同分支对不同模态的输入进行特征提取,自适应地学习特定于负荷的特征表示,如文献[34]利用双流神经网络实现负荷时域和频域特征图像的融合与分类。而在特征融合模型方面,能够自动学习和计算特征重要度的注意力机制近期在自然语言、图像识别等领域取得了优异效果[35-36]。但是,此类方法依赖于较多注意力层的堆叠和对大量样本的学习,存在模型复杂度高、样本数量需求大的问题。而度量学习是一种基于样本间距离的空间映射方法,可以通过拉近同类型样本特征距离、推远不同类型样本特征距离的方式提高模型学习效率,减少模型训练的样本需求量[37-38]。
因此,本文将注意力机制与度量学习训练方法相结合,提出一种基于多尺度特征融合的负荷辨识方法,并采用梯度加权类激活图映射(gradientweighted class activation mapping,GradCAM++)的可解释方法进行模型调优和效果验证[39]。与现有研究工作相比,其主要贡献如下:
1)针对当前研究存在的多尺度特征提取与融合能力不足的问题,构建负荷多尺度特征体系,设计双塔特征提取网络与基于自注意力和交叉注意力的特征融合网络,实现特征的高效融合与泛化性能的提升。
2)针对负荷特征融合效率低的问题,采用基于度量学习的训练方法,提升同类负荷的特征相似性与特征融合效果,并增强模型对噪声样本的鲁棒性。
3)针对现有识别方法可解释性差、特征融合效果难以验证和改进的问题,采用GradCAM++方法量化特征重要性,并以此提出自适应的模型调优方法。最后,基于可解释结果证明本文模型的性能提升源于多尺度特征的充分利用。
1 负荷辨识方法及其解释性分析框架
带有可解释反馈环节的多尺度特征融合负荷辨识方法的主要流程如图1 所示。
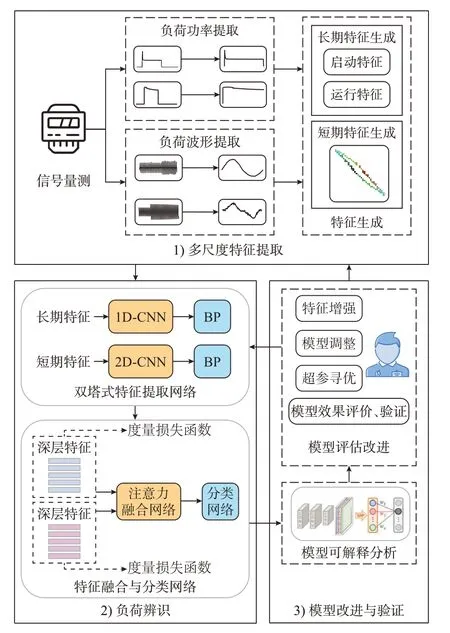
图1 负荷辨识方法总体框架Fig.1 General framework of load identification method
1)事件检测与增量提取。利用滑动窗双边有效值累积和(cumulative sum,CUSUM)的方法对总功率数据进行负荷投切事件检测。当检测到出现事件时,通过增量提取获取对应负荷的高低频电气数据。
2)多尺度负荷特征生成。对采集到的负荷高频波形构建三通道彩色V-I轨迹图,对负荷低频数据计算相应的启动特征和运行特征。
3)深层特征提取。利用生成的彩色V-I轨迹图和长期特征构建负荷数据集,将数据集样本按比例划分为训练集、验证集和测试集后,采用度量学习的方式对双塔神经网络进行训练,得到自适应提取的深层特征。
4)特征融合与负荷分类。利用自注意力和交叉注意力机制对输出的深层特征进行融合,由全连接层实现负荷类别映射。
5)特征增强、模型寻优与效果验证。对识别结果进行可解释分析,将分析结果结合专家先验知识指导特征增强和模型优化,并对模型的特征利用和融合效果进行验证,实现人机可解释交互的闭环。
2 负荷信号分离与多尺度特征提取
为提取目标负荷的用电特征,进而实现负荷类型辨识,首先,需要利用事件检测方法定位投切事件,并采用增量提取技术分离出目标负荷的用电信息。
2.1 事件检测
本文采取滑动窗双边有效值CUSUM 算法[40]进行事件检测,通过累计信号序列的偏移值,以阈值触发的形式确定负荷运行状态改变的时刻。
为准确捕捉间续工作负荷的运行时段,同时忽略投入时间过短和功率过小的负荷,本文还增加了两个事件发生的阈值判断条件:
式中:td为负荷的投切状态持续时间;tthr为负荷状态持续时间的阈值,可依据负荷辨识下游任务的特点灵活设置;Pdiff为事件前后稳态功率的差值;Pthr为投切事件判定的功率差阈值。Pthr和tthr值可结合负荷辨识目标的功率水平和波动情况灵活设置。为兼顾不同功率范围和运行时长的电器,本文实验将tthr值设置为1 min,Pthr值设置为5 W。
2.2 增量提取
对于负荷高频信息而言,负荷电压波形等于总线的电压波形,负荷电流波形可利用如下增量提取的方式获得:
1)基于电压过零点对齐电流各周期的相位,提取事件前、后各一个周期内的第t个采样点时刻电流Ia(t)和Ib(t);
2)事件对应的负荷电流I(t)可以近似为事件后与事件前的电流差值,即I(t)=|Ib(t)-Ia(t)|。
对于负荷低频信息而言,依据功率可加性原理可实现负荷有功功率和无功功率的提取。为避免电压波动的影响,根据基准电压Vref对功率进行标准化处理,得到负荷有功、无功功率的提取公式如下:
式中:P(t)和Q(t)分别为分离出的负荷有功功率和无功功率;Pa(t)、分别为投切事件前第t个采样点时刻的有功功率、电压有效值、电流有效值;Pb(t)、分别为投切事件后第t个采样点时刻的有功功率、电压有效值、电流有效值。
2.3 多尺度负荷特征生成
2.3.1 基于波形的短期特征生成
相较于电流波形、电流谐波、稳态功率等负荷特征,V-I轨迹曲线更好地反映了负荷电压、电流及其之间的变化趋势。针对V-I轨迹无法体现负荷功率信息的问题,采用彩色编码方法,在红绿蓝(RGB)三通道中分别融合按波形幅值归一化的瞬时功率、按负荷水平归一化的瞬时功率和电压与电流变化率的比值,构建彩色V-I轨迹。其主要流程如下。
1)假设V-I轨迹图的分辨率为f×f,则对各负荷电压、电流波形数值转换到0~f范围后,以电流值为行、电压值为列,对V-I轨迹图各通道的相应位置进行填充,本文实验部分V-I轨迹图的分辨率设置为32。负荷电压、电流的转换公式为:
2)R 通道的填充值是按波形幅值归一化的瞬时功率,反映了一个周期内功率的变化趋势。具体计算公式如下:
式中:R(̂)为R 通道矩阵第行列位置的值,其中,和̂分别为转换后第g个采样点的电压、电流值;Pg为第g个采样点的瞬时功率;和分别为一个周期内瞬时功率的最大值、最小值。
G 通道的填充值是按负荷水平归一化的瞬时功率,反映了某负荷在数据集中所处的功率水平。具体计算公式与式(6)一致。不同的是,式中和分别为各训练样本在该波形采样点上瞬时功率的最大值、最小值。
B 通道的填充值是电压与电流变化率的比值,反映了一个周期内电压、电流的变化趋势。具体计算公式如下:
3)将RGB 三通道矩阵组合后,即完成对负荷彩色V-I轨迹特征的构建。
附录A 图A1 展示了热水壶等4 类负荷常用品牌生成的彩色V-I轨迹特征。可以看出,各类型电器在曲线轨迹和颜色上具有明显区别。热水壶的电流波形属于典型正弦波,其V-I轨迹呈直线形态;电吹风属于半波工作电器,其V-I轨迹呈“Ί”字型,且在工作部分具有更鲜艳的颜色;充电器、电脑属于电力电子型负荷,电流波形含有大量谐波,其轨迹也具有更为复杂的形态。
2.3.2 基于功率的长期特征生成
负荷的长期特征包括启动特征和运行特征。参考文献[10-11],提取的启动特征指标包括:1)启动尖峰PT-spike,即负荷启动过程中有功功率的最大值;2)启动时间Tstart,即负荷从启动到稳定运行过程所用的时间。
参考文献[12-14,41],提取的运行特征指标包括:
1)有功功率(最大值Pmax、最小值Pmin、平均值Pmean、方差Pvar):负荷运行过程的有功功率特性。
2)无功功率(最大值Qmax、最小值Qmin、平均值Qmean、方差Qvar):负荷运行过程的无功功率特性。
3)功率因数(最大值φmax、最小值φmin、平均值φmean、方差φvar):负荷运行过程的功率因数特性。其中,负荷稳态运行功率因数曲线φ(t)可由负荷稳态有功功率P(t)和稳态无功功率Q(t)计算,如式(8)所示。
4)工作时长Twork:负荷一个工作周期的时长。
5)占空比D:负荷处于运行状态的时间Ton与负荷工作时长Twork的比值,如式(9)所示。
式中:n为小波分解层数;为负荷第n层小波细节系数;L为负荷第n层细节系数的长度。
8)功率尖峰数量Nspike:负荷在运行过程中功率波动大于阈值的次数,如式(11)所示。
式中:ks为波动阈值参数,本文设置为10;δ(·)为指示函数,当括号内的值大于0 时取值为1,否则取值为0。
以训练效果最优和降低特征冗余为原则,在计算小波系数指标过程中,本文选择db3 小波作为小波基函数,小波分解的层数设置为1 层。综上,本文共提取出25 个长期特征指标用于负荷的识别。
3 负荷多尺度特征融合与辨识模型设计
3.1 模型总体结构
基于多尺度特征融合的负荷辨识模型结构如图2 所示。图中:括号内部分表示网络结构参数,其中卷积层括号内表示(卷积核尺寸,滑动步长,输出通道数),池化层括号内表示(池化核尺寸,滑动步长)全连接层括号内表示(输入维度数,输出维度数);“⊕”表示特征的横向拼接操作。本文负荷辨识模型主要由深层特征提取网络和特征融合与分类网络两部分组成。特征提取网络采用双塔结构进行深层特征提取,并使用度量损失函数进行训练。特征融合与分类网络采取自注意力与交叉注意力分别在相似样本之间和多尺度特征之间进行融合,深度挖掘同类负荷的相似性与长短期特征的互补特性。最后,由全连接分类网络实现负荷类型的映射。
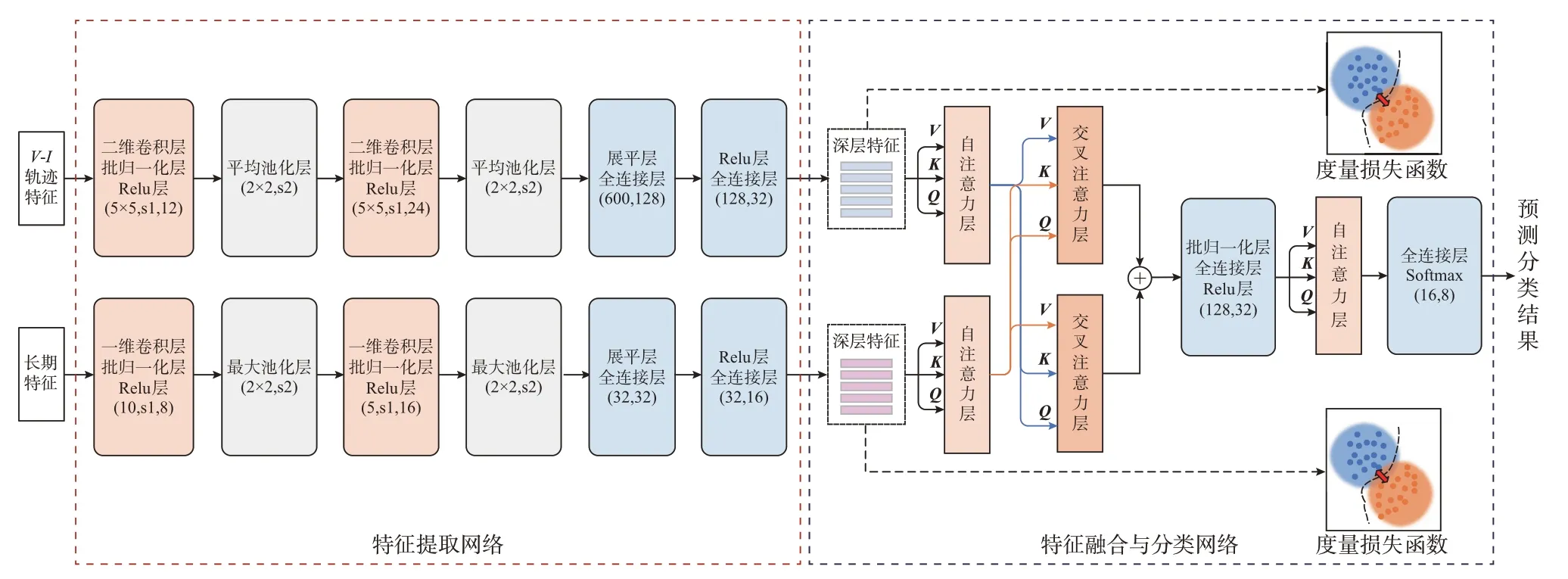
图2 基于多尺度特征融合的负荷辨识模型Fig.2 Load identification model based on multi-scale feature fusion
3.2 特征提取网络设计
考虑到负荷V-I轨迹特征为二维稀疏特征,而长期特征为手工提取的一维指标型特征,二者维度和表征能力各不相同。因此,本文采用双塔结构的卷积神经网络(convolutional neural network,CNN)作为特征提取网络,以保证后续特征融合和分类的有效性。负荷长、短期特征分别通过二维CNN(2DCNN)和一维CNN(1D-CNN)进行深层特征提取和加工,各分支网络均是以“卷积层-批归一化层-激活层-池化层”堆叠后与全连接层相连的形式构成。
3.3 基于注意力机制的特征融合网络设计
本文基于注意力机制[42],设置“自注意力层-交叉注意力层-自注意力层”结构的特征融合网络。第1 个自注意力层和交叉注意力层采用批注意力的形式在样本层面实现融合[43],第2 个自注意力层在特征空间层面实现融合。
在第1 个自注意力层中,以样本高频特征为例,设Xh∈RN×m1为上一层网络输出样本的高频特征矩阵,Att(Q,K,V)为本文注意力层网络函数,其中,N为样本数量,m1为高频特征长度,Q、K、V分别为输入注意力网络层的查询矩阵、键矩阵和值矩阵,则第1 个注意力层的融合方式为:
在同类型样本中,表现负荷信息的特征部分一般具有相似性,而由噪声产生的特征部分具有差异性,利用自注意力机制可以使模型更关注同类型样本之间的共有特征,降低噪声对识别结果的干扰。
在交叉注意力层中,设Xs∈RN×m2为上一层网络输出样本的低频特征矩阵,其中,m2为低频特征长度。以样本高频特征为例,可以将交叉注意力的融合方式写为:
当同类型样本间因型号或噪声导致某一尺度特征产生较大差异时,交叉注意力层可以根据样本在另一尺度特征上的相似性融合同类样本,有效提高模型对含噪声样本和新样本的识别能力。
第2 个自注意力层的输入为长、短期特征拼接构成的总体特征,对每个样本的总体特征进行自注意力融合,其作用是强化更具有负荷类型表达能力的特征、消除冗余特征、提高分类层的分类效果。以输入样本i为例,设∈Rm×1为样本i经过维度扩充处理的输入特征向量,则样本i经过第2 个自注意层的输出向量可以表示为:
本文注意力层内部结构如图3 所示。图中:“Ⓣ”表示矩阵转置;“⊗”表示矩阵乘法;“⊕”表示矩阵加法;“Scale”为尺度化操作,表示将输入的矩阵元素除以K矩阵特征长度的0.5 次方。考虑到同类型负荷样本特征之间可能存在多种隐含的相似关系,需要模型能够捕捉不同角度的负荷特征信息。因此,自注意力层与交叉注意力层均采用多头注意力形式,注意力头数为4。计算各注意力头的均值得到与输入维度相同的输出。同时,为避免特征融合可能导致的负荷特征平滑化的情况,各注意力层都加入了残差连接机制。
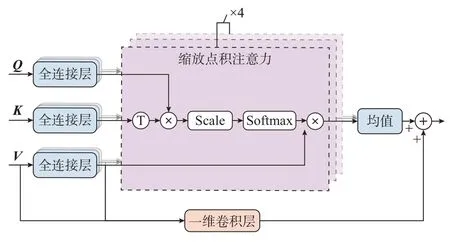
图3 注意力层内部结构Fig.3 Internal structure of attention layer
3.4 基于度量学习的损失函数设计
本文的特征融合与分类网络可采用分类损失函数进行训练,本文的分类损失函数L1采用交叉熵损失函数:
式中:Nc为样本类别数量;lic为0-1 变量,如果样本i的真实类别与类别c相同则取1,否则为0;pic为样本i预测为类别c的概率。
特征提取网络有两个任务:1)获得对负荷本体进行充分表征的深层特征;2)将同类型负荷的深层特征映射到尽可能相近的特征空间,以提高后续负荷融合的准确性。对于第1 个任务,在获得特征提取网络输出的高频、低频深层特征后,分别连接一个全连接层,并采用交叉熵损失函数L2和L3作为高频和低频部分的损失函数。对于第2 个任务,则依据度量学习的思路实现。度量学习依次选取数据集中样本作为锚样本,从与锚样本标签相同的数据中选取正样本,从与锚样本标签不同的数据中选取负样本,通过度量锚样本与正、负样本间的距离拉近同类型样本特征。
本文选取度量损失函数作为度量损失函数,其通过距离加权采样的方式[44],依据输入样本数据的分布均匀抽取负样本并计算损失,能够以低计算量有效挖掘利于训练的负样本,同时减少样本噪声数据的干扰。对于批量中的每个样本,在采样得到正、负样本后,即可计算度量损失Lmargin:
式中:H为锚样本i的正负样本数量;β(i)为针对样本i的可训练边界参数;v为β(i)的正则化超参数;lmargin(i,j)为锚样本i与样本j之间的距离度量函数;α为控制样本分离边际的变量;yij为符号函数,当样本i与样本j类别一致则为1,否则为-1;Dij为样本i与样本j特征之间的欧氏距离;(·)+为斜坡函数,当函数输入值小于0 时,输出值为0,否则函数输出值与输入值相同。
相较于传统的对比损失,度量损失函数在正负样本距离的约束上更加宽松,使它能够在样本分布不同的负荷数据集中起到良好的训练效果,而相较于三元组损失,它的损失计算更为简单,能够以更高的计算效率达到度量的目的。
按照此方式,在特征提取网络的两个分支上分别加上度量损失函数L4和L5。由此,负荷辨识模型的总体损失函数Ltotal由以上5 个损失函数加权得到:
式中:wk为第k个损失函数的权重。
考虑到当前损失函数较多,各损失函数的训练难度不同,利用手工调整权重的方法需要大量时间,且不能保证效果。 因此,本文采用automatic weighted loss 的方式[45],依据各损失函数的方差不确定性为损失函数自动设置权重:
式中:σk为Lk衡量方差不确定性的参数,是一个可学习的变量,损失函数后半部分的常数项为正则化项,以避免σk过大。
3.5 基于GradCAM++可解释结果的特征增强与模型改进
针对模型缺少可解释依据、模型效果难以验证和改进的问题,本文利用GradCAM++方法进行解释性分析,可视化模型的识别依据,同时实现输入特征增强和模型优化。
GradCAM++是一种针对神经网络的可解释分析方法,它能够根据分类的目标输出相对于任一层网络输出特征的梯度计算权重,将模型的分类结果归因于输入特征的加权和,以此确定不同特征对于输出类别的贡献程度。
针对提取的多尺度特征中可能存在冗余特征和无关特征的问题,利用GradCAM++计算结果对重要特征进行增强。具体方式为:利用专家的先验知识构建初始特征权重矩阵,与每次训练利用可解释方法生成的特征重要度矩阵加权平均得到总特征权重矩阵;再将权重矩阵与各负荷样本的特征按元素相乘,即根据模型解释结果对特征加权,得到更利于模型识别的增强特征。随着训练的进行,初始矩阵的权重不断衰减,模型生成的可解释矩阵权重增加,逐步形成输入特征自优化的过程。第e次训练所用的权重矩阵Me的表达式为:
式中:J为元素值全为1 的矩阵;w为特征增强程度;γ为权重衰减因子;M0为初始权重矩阵;为第e-1 次训练生成的特征重要度矩阵,是训练集样本特征重要度矩阵的平均值。
针对模型训练过程缺乏人机可解释交互,导致识别结果可解释性较差的问题,将模型可解释结果与先验知识的契合度也作为模型结构调整和超参数调优的目标。具体方式为:从验证集的各类型负荷中随机抽取等量样本,采用专家验证的方法判断其特征重要度结果是否与先验知识相吻合,将符合先验知识的样本数量与验证样本数量的比值作为可解释率,以可解释率与验证集准确率的均值作为评价指标进行模型调优。
3.6 训练与测试方法
采用批量训练方式,将训练样本分成若干批次输入模型进行训练,同时各批次采用均衡采样的方法,使每批具有相同数量的各类型负荷。根据本文负荷融合策略,模型在训练过程中需要选择较大样本批量,本文实验部分所用样本批量大小为128。选择RMSProp 优化器利用梯度下降优化模型参数,若模型在验证集中的损失连续10 个回合不再下降,则结束训练。
在模型测试阶段,由于注意力模块在特征融合时考虑了样本间的相似关系,为提高模型在样本层面的融合效果,从训练集中选取典型样本与测试集样本一同输入模型,辅助模型对测试样本的识别。典型样本为基于密度的有噪空间聚类(densitybased spatial clustering of applications with noise,DBSCAN)算法,根据训练集中的样本电流波形数据和长期特征得到聚类中心。
4 实验设计及结果
在实验阶段,基于Python 语言开发本文模型,采用PyTorch1.8.1 深度学习框架实现,在一台配有4 张GeForce RTX 2080 Ti 显卡的服务器上进行实验,并使用图形处理器(GPU)进行加速。
4.1 实验评价指标
为量化评价与验证本文方法相较于其他负荷识别方法的性能和效果,采用识别准确率Pacc和F1分数作为实验性能的主要评估指标。各评估指标的具体计算公式如下:
式中:TP为正确识别的正类数量;TN为正确识别的负类数量;FP为错误识别的负类数量;FN为错误识别的正类数量;Precall为识别正确的正类比例;Pprecision为实际正类占所有识别为正类的样本比例。Pacc和F1分数取值范围为0~1,且值越大表明识别效果越好。
4.2 数据来源及处理
针对多尺度的数据采样需求,本文选择Blond公开数据集[46]和自采数据集相结合的方式形成实验数据集1,以Blued 公开数据集作为实验数据集2,对本文所提模型进行训练和测试。Blond 数据集以50 kHz 和250 kHz 的采样频率对某办公环境中的16 种电器53 个品牌的电压、电流分别进行213 d和50 d 的连续测量。自采数据集以20 kHz 和1 Hz的采样频率,分别对电风扇、热水壶等4 种电器18 种常用品牌的电压、电流进行10 min 的连续测量。Blued 数据集[47]以12 kHz 的电压、电流采样频率和60 Hz 的功率采样频率对美国某家庭A 相和B 相电路中的电灯、冰箱等10 种电器进行了一周的测量。
考虑到数据集情况和实际数据需求,实验数据集1 选取Blond 数据集2016 年10 月至2017 年3 月的数据与自采数据集结合,选取显示屏、热水壶、手机充电器、笔记本电脑、台式电脑、电灯、电吹风、电风扇8 种常用电器共37 个品牌、53 种型号作为实验对象,并通过下采样将高频采样频率统一为6.4 kHz,低频采样频率统一为1 Hz。实验所用各电器品牌型号信息见附录A 表A1。由于Blued 数据集中B 相事件标签存在缺失,实验数据集2 选取Blued 数据集中A 相的冰箱、电吹风、空气压缩机、电灯和厨房辅助刀5 种电器作为识别对象,其高、低频频率保持为12 kHz 和60 Hz 不变。
按照2.1 节与2.2 节所述方法,从实验数据集1中检测出2 732 条负荷投切事件,与手工标注的真实事件位置对比,事件检测F1值为0.887;从实验数据集2 中检测出957 条负荷投切事件,事件检测F1值为0.972,满足实际应用要求。
为平衡数据集中各型号样本数量,通过滑动窗过采样方法,依据事件从实验数据集1 中提取5 653 条负荷样本数据,从实验数据集2 中提取1 830 条负荷数据,扩充后数据集1 情况如表1所示。
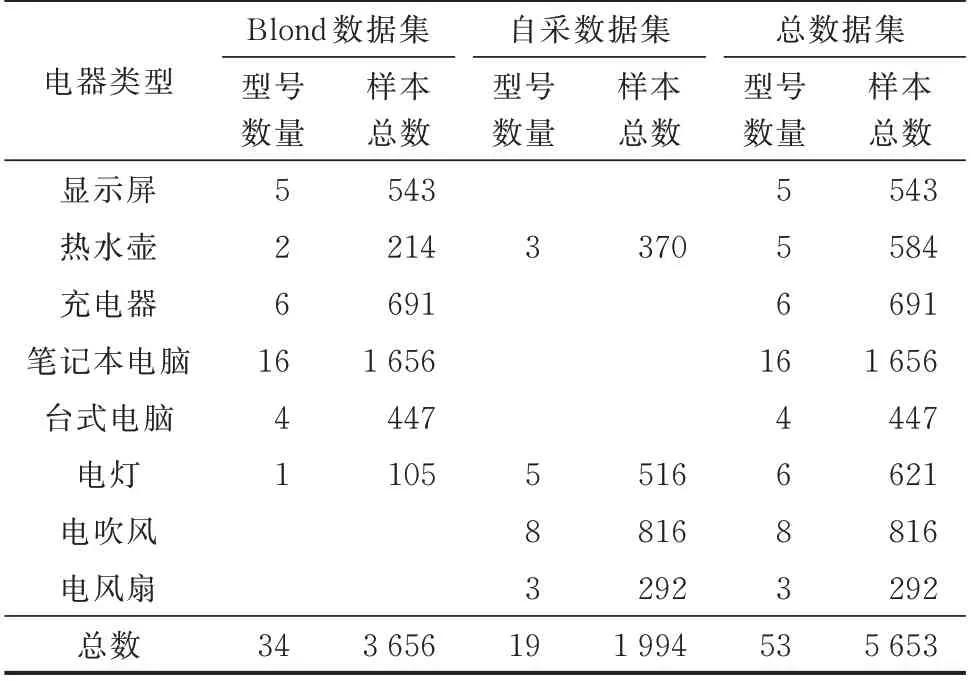
表1 实验数据集样本情况Table 1 Sample situation of experimental data set
然后,按照2.3.1 节和2.3.2 节方法生成负荷的高频和长期特征。对负荷长期特征进行正规标准化处理,表达式为:
式中:xi和分别为处理前、后第i个样本的低频负荷特征;μ和σ分别为所有负荷中该特征的平均值和标准差。
最后,根据处理后所有负荷的长、短期特征构建负荷特征数据集,用于后续的模型训练与验证。
4.3 识别准确率对比实验
针对本文负荷辨识方法的特点,分别从长期特征识别、短期特征识别和特征融合识别的角度,选择基于功率曲线特征的Bagging[14]、基于电流波形的自适应加权递归图(adaptive weighted recurrence graph,AWRG)[18]、V-I轨迹特征与功率特征融合的LeNet-5 网络[27]等现阶段先进识别方法作为对比组。此外,本文基于长短期特征结合进行识别的思路,还设计了电流波形与长期特征直接拼接识别的反向传播(back propagation,BP)网络、电流波形与长期特征后融合的双塔1D-CNN 两种常规方法加入对比组,验证本文方法的有效性。
为避免实验结果的偶然性,本文按照3∶1∶1 的比例将实验数据划分为训练集、验证集和测试集,并以10 次随机抽样验证求均值的方法,计算各方法的识别准确率。在实验数据集1 和实验数据集2 上的识别结果如表2 所示,各类型负荷辨识具体情况如附录B 表B1 和表B2 所示。依据识别结果,多尺度特征识别方法比当前单一尺度特征识别的先进方法具有更优的识别性能,证明多尺度特征比单尺度特征具有更好的分类能力。而与其他特征融合模型相比,本文模型在几乎所有负荷类型的识别中都取得了更高的识别准确率,证明本文模型能够更好地利用多尺度特征实现负荷的分类。
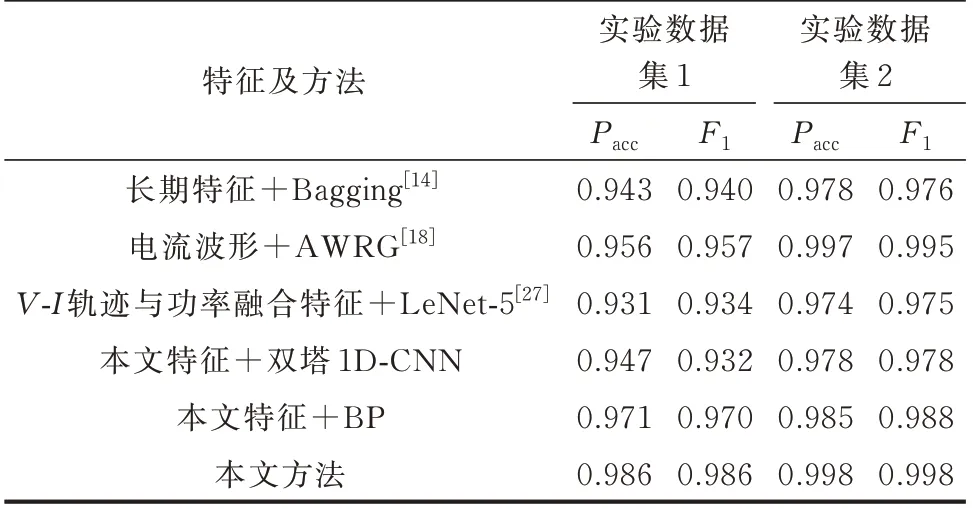
表2 识别准确率的实验结果Table 2 Experiment results of identification accuracy
以某笔记本电脑样本为例,利用GradCAM++方法,展示了本文模型对长短期特征的利用程度,并以此对模型特征提取、特征融合网络的效果进行验证与评价。图4(a)热力图中,色块的颜色鲜艳程度反映了该区域的特征重要程度,颜色越鲜艳的区域,表明对模型识别为笔记本电脑的贡献程度越高。由图4 可见,在短期特征中,本文模型既能够实现对V-I轨迹曲线的完整捕捉,也能着重关注到与其他类型负荷V-I轨迹的差异部分;在长期特征中,本文模型的识别一方面关注无功功率、功率因数等充分反映电力电子型负荷特点的特征指标,另一方面也关注有功功率方差、小波系数、尖峰数量等反映笔记本电脑与其他电子型负荷运行波动特性差异的特征指标。实验结果和模型解释性分析结果表明,本文提出的特征提取和融合网络对于负荷样本的短期特征和长期特征都能实现充分利用和挖掘,有效保证了模型的识别性能。
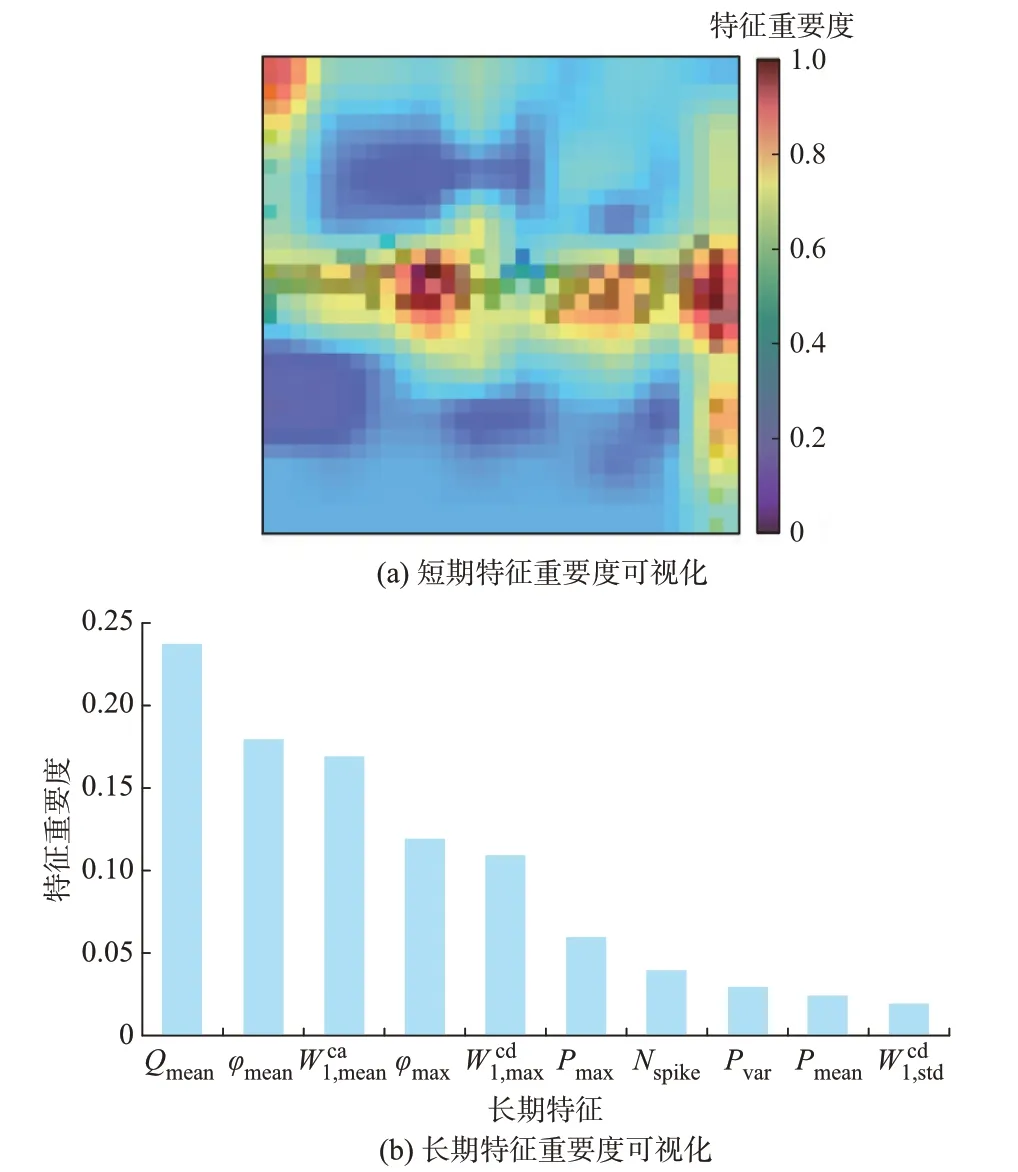
图4 笔记本电脑样本特征重要度可视化Fig.4 Feature importance visualization of laptop sample
4.4 识别泛化性对比实验
4.4.1 品牌泛化实验
泛化性问题一直是负荷辨识领域亟待解决的重要问题,而负荷的跨品牌识别效果又是检验辨识模型泛化性能的重要标准。跨品牌识别是指辨识模型在特定品牌的样本数据上完成训练后,在另一批新品牌的负荷样本中验证识别效果。同类型不同品牌的电器由于实现方式的不同,在外特性方面往往具有较大差异;而同品牌生产的功能相近的不同电器,也可能由于工作原理相近,而在负荷特性上呈现出较高的相似性。因此,跨品牌的负荷辨识目前仍存在较大的难度。本文利用不同电器的多种品牌开展泛化性对比实验。具体实验方法为:从每类负荷中分别随机提取一种品牌型号的负荷样本构成测试集,其余品牌型号样本作为训练集和验证集,训练集、验证集划分比例为4∶1;将以上过程重复10 次,形成10 个不同的实验数据集并依次输入识别网络进行训练和测试;取10 次实验结果的平均值作为各方法的最终结果。考虑到在实际工程应用中,模型对于未知电器的识别效果应保持稳定,增加了测试集方差作为模型稳定性的评价指标。模型在测试集上的方差越小,说明模型的稳定性越好。由于Blued 数据集中各类型负荷基本只有一种型号,不具备泛化性测试条件。因此,只选取数据集1 进行实验,最终得到品牌泛化实验结果如图5 所示。
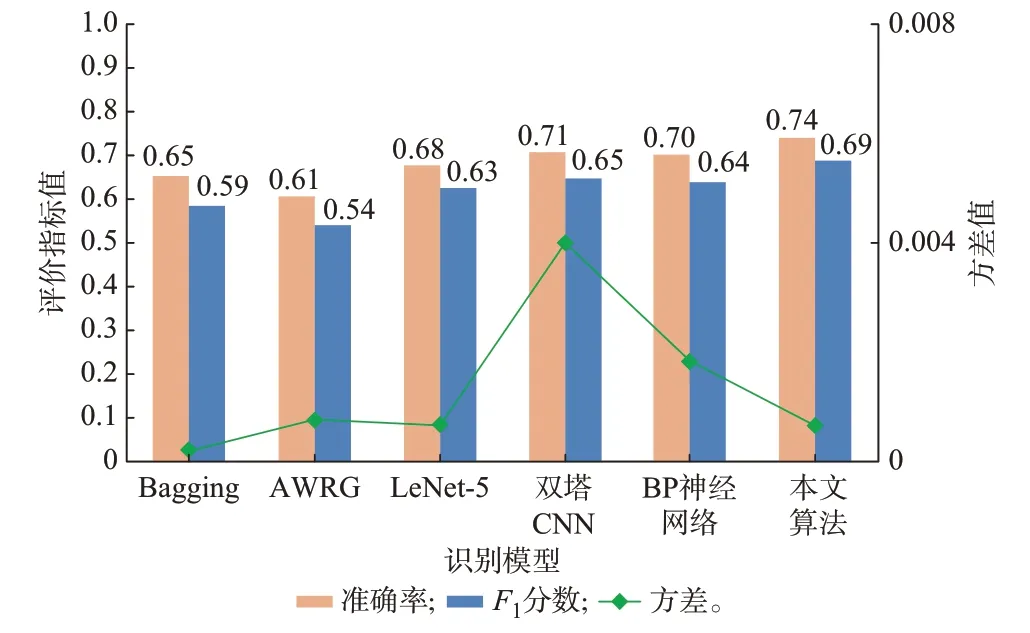
图5 品牌泛化实验结果Fig.5 Results of brand generalization experiment
由实验结果可见,多尺度特征相较于单一尺度特征,泛化识别能力得到了进一步提高。相较于文献[14]的长期特征识别方法和文献[27]的短期特征识别方法,本文模型泛化准确率分别提高了9%和13%。而与其他使用了多尺度特征的辨识模型相比,在保持更高的泛化准确率的同时,还具有更低的测试集方差,证明本文提出的特征处理与融合方法在充分利用多尺度特征的互补作用实现负荷辨识的同时,有效地降低了模型的过拟合程度,使得模型在面对未知负荷时也能具有稳定的识别效果。跨品牌泛化实验的具体分析见附录C。
4.4.2 用户泛化实验
在实际场景中,不同用户所使用的负荷类型之间往往存在较大区别,训练辨识模型所使用的负荷数据也可能与实际需要辨识的负荷类型之间存在出入。因此,模型将原有负荷类型的分类性能快速迁移到新类型负荷辨识中的能力,也是模型泛化性能的重要体现。本文参考文献[48-49],采用小样本迁移学习的方式开展用户泛化实验。具体实验方式为:利用实验数据集1 中显示屏、充电器等8 种负荷数据对本文模型进行训练;模型训练完成后,冻结其中的深层特征提取网络参数,并从实验数据集2 中冰箱、厨房辅助刀等5 种负荷中随机抽取少量样本构成小样本训练集,对模型的特征融合与分类网络参数进行训练微调;数据集2 中的其余样本作为测试集,用以验证微调后模型对新负荷类型的识别效果。本文设置小样本训练集中每类负荷样本抽取个数分别为5 和10,重复有放回抽取过程10 次,形成10 个不同的数据集进行实验。取10 次实验结果的平均值作为最终结果,得到用户泛化对比实验结果如表3 所示。
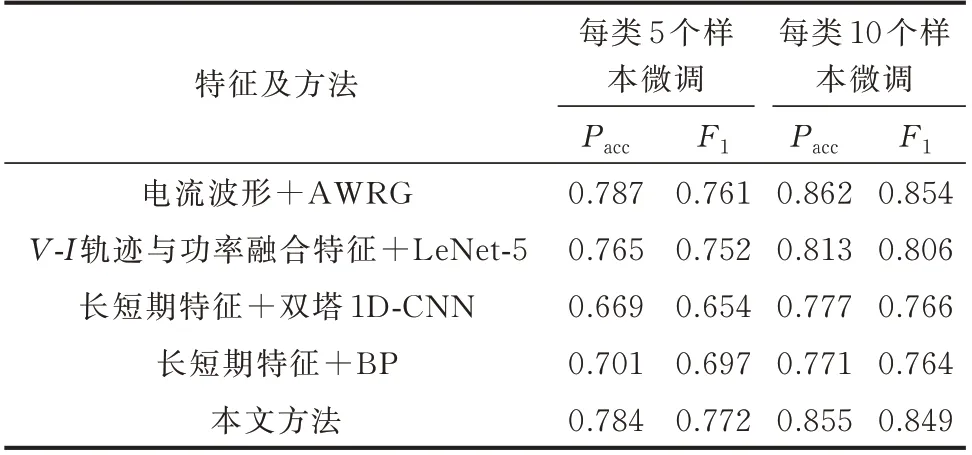
表3 用户泛化性实验结果Table 3 Results of user generalization experiment
由表3 可见,本文模型相较于其他神经网络模型普遍具有更高的用户泛化准确率,能够基于小样本数据实现负荷辨识能力的快速迁移,具有良好的用户适应性。同时,本文在用户泛化上的表现虽然略低于AWRG 模型,但相较于AWRG 模型66 万个的参数量和255 万个单次浮点运算量(floating-point operations,FLOPs),本文的参数量和单次FLOPs分别仅有14 万个和227 万个,具有轻量化、易部署的实用性优势。
4.5 消融实验
为充分验证本文利用可解释结果进行特征增强的策略和结合度量学习与注意力机制设计的负荷特征融合网络在噪声样本识别和跨品牌泛化识别中的作用,采取控制变量的思想,设计对照实验验证各模块实验结果的改进性能。本文按照表4 设置实验组和对照组,以4.3 节和4.4 节所述方法分别开展准确率实验和泛化性实验。

表4 消融实验实验组、对照组设置Table 4 Setting of experimental group and control group for ablation experiment
在准确率实验中,为测试本文方法面对噪声样本时的识别效果,对测试集样本的高频和低频信号随机进行以下任一种处理:1)高频信号加入均值为0、方差为0.1 的高斯噪声,低频信号加入均值为0、方差为1 的高斯噪声,模拟采样噪声;2)以不超过样本原始电气信号1/2 的数值叠加其他类型样本的电气信号模拟电器干扰时的基底噪声;3)对样本随机加入-10%~10%的抖动模拟电网电压波动;4)不进行加噪处理。
识别准确率实验和泛化性实验结果如图6 所示。从实验结果可以看出,本文利用可解释结果进行特征增强的策略有效强化了利于识别的重要特征,降低了无关特征对识别的影响,提高了模型的识别性能。而特征融合网络相较于常见的特征拼接方法,也能更好地挖掘和利用多尺度特征,使模型在面对噪声样本和跨品牌样本时具有更高的识别准确率和泛化性能。
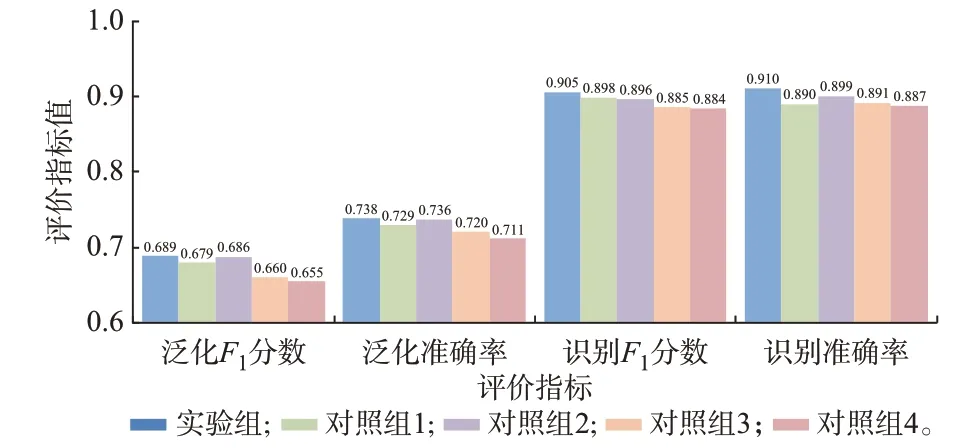
图6 消融实验结果Fig.6 Results of ablation experiment
以DELL P2210 型号的显示器样本为例,该样本在本文模型中准确识别为显示器,而在对照组4的模型中却被识别为USB 充电器。 利用GradCAM++方法将样本的短期特征重要性可视化,其结果如图7 所示。由图7 可见,本文所提负荷融合网络能够使模型准确捕捉到同类型负荷整体特征中的相似部分,避免了对照组4 中模型片面关注局部特征的问题,在面对噪声样本或新样本时不会因局部特征的改变而过度影响识别的结果,模型具有更高的鲁棒性和泛化性。
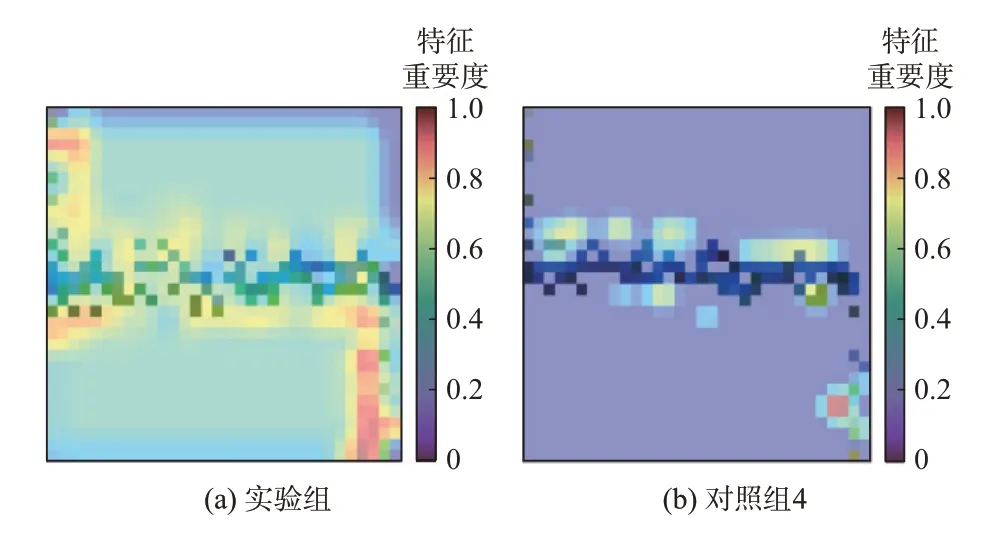
图7 模型对样本V-I 轨迹特征的利用情况对比Fig.7 Comparison of model utilization of sample V-I trajectory features
使用度量学习训练可以明显提升识别性能,其原因是模型训练中引入度量损失函数后,特征提取网络会聚集同类型负荷的样本特征,同时推远异类负荷,这也使得注意力层能够基于特征相似度快速融合更多同类型样本的信息,提高模型识别的精度。附录B 图B1 分别展示了是否使用度量学习训练的负荷深层特征经主成分分析降维后的二维可视化结果。由图B1 可见,使用度量学习训练的特征提取网络输出的各类负荷特征分布出现了明显的界限。
5 结语
本文针对现有负荷辨识模型鲁棒性、泛化性和解释性不足的问题,提出一种基于多尺度特征融合的负荷辨识及其可解释交互增强方法。首先,该方法由负荷高频数据生成彩色V-I轨迹特征,由中、低频数据提取负荷启动特征和运行特征,构建多尺度负荷特征体系。利用由自注意力和交叉注意力模块组成的特征融合网络深度挖掘多尺度特征的互补作用,进一步提高模型的泛化性能。然后,采用度量学习的训练方法,在提高特征融合效率的同时,拉近同类样本的特征距离,增强模型鲁棒性。最后,采用GradCAM++方法对模型识别依据进行解释性分析、特征增强和模型调优,可视化展示和验证了所提方法的效果。实验和解释性分析结果表明,相较于现有先进人工智能识别算法,本文方法具有更高的识别准确率、更强的泛化性能和可解释交互增强能力。
尽管如此,本文在模型持续自优化更新、低成本边端部署等方面仍存在不足。后续研究工作主要包括:1)深入构建多尺度、多类型、多品牌、多场景的负荷数据集,进一步验证、改进所提方法的识别性能;2)研究在嵌入式芯片上最小化性能损失且适应模型的部署优化方法,并结合硬件设备进行工程验证;3)研究基于新场景数据更新模型参数的泛化性提升方法[50-51]。
附录见本刊网络版(http://www.aeps-info.com/aeps/ch/index.aspx),扫英文摘要后二维码可以阅读网络全文。
