基于机器视觉的谷糙分界线检测方法
2024-01-29范吉军余南辉刘晓鹏
刘 浩 范吉军 余南辉 刘晓鹏 周 劲 牟 怿
(1. 武汉轻工大学电气与电子工程学院,湖北 武汉 430023;2. 武汉轻工大学机械工程学院,湖北 武汉 430023)
稻米加工过程一般需要经过原粮清理、砻谷、谷糙混合物分离、碾米等步骤,而谷糙混合物分离的优劣直接影响到稻米的加工效率,因此优化谷糙分离工艺是提高稻米加工效率的重要手段[1-3]。谷糙分离是根据稻谷和糙米的粒度、密度和分层特性进行分离的[4],这样会在稻谷与谷糙混合物之间形成一条谷糙分界线。分料装置能够将稻谷与谷糙混合物分隔开,进而完成分离。目前对谷糙分界线位置的获取主要依靠人眼识别的方式,并根据识别后的分界线位置手动控制分料装置(分料板)的移动。然而,主观判断所带来的误差会影响分离效率。
随着中国技术装备水平不断提升,稻米加工产业对精深加工的需求逐渐提高,很多稻米生产与加工环节正在进行智能化改造[5-6]。然而,现有的研究主要集中在谷糙分离装置的结构设计及机械参数上[7]。近几年机器视觉技术在国内外发展迅猛,已被广泛应用于生产领域[8-11]。它具有非接触性、精度高等优点,十分适合扬尘大、噪音强的大米加工现场。
为实现对谷糙分界线的精准识别,试验拟以谷糙分离状态图像为研究对象,将机器视觉应用到谷糙分离过程中,并提出一种基于直线边缘检测的谷糙分界线识别方法,以期为谷糙分界线的自动化检测提供总体方案,为分料装置的智能控制提供依据。
1 谷糙分界线检测系统总体方案
1.1 检测系统的总体框架
检测系统包括计算机、相机、环形照明装置以及连接相机与照明装置的三脚支架。相机为海康公司生产的面阵相机,型号为MV-CS050-10GC,单通道RGB相机(分辨率为2 448×2 048),帧率为24.2 FPS。镜头为海康公司生产的型号为MVL-HF0628M,FA镜头,最近拍摄距离为0.1 m。T5-40W环形荧光灯光源,灯管直径16.5 mm,外径273 mm。
通过相机拍摄获得位于出料口位置的谷糙分离状态图像,镜头距拍摄区域0.8 m,视野范围为655 mm×830 mm;采取动态采集的方式,采集图像间隔为5 FPS;经打光试验后,选用黄色面光源,该颜色光源能够增加黄色稻谷与白黄色糙米的区分度[12];将相机固定在环形照明装置中间,通过数据线与计算机连接。计算机中的软件包括可以运行图像采集、处理、分析于一体的程序,拟采用MATLAB2017a分析软件;采用所提出的谷糙分界线识别方法进行分界线检测,得到分界线的位置结果。图像检测系统布局如图1所示。
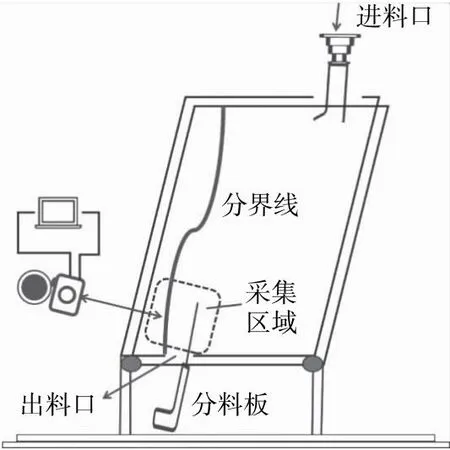
图1 检测系统图
1.2 检测流程
谷糙分界线检测流程主要包括3个模块:图像采集模块、预处理模块、检测模块。根据检测系统的总体框架,设置检测流程如图2所示。
2 谷糙分界线识别方法
调研发现,由于稻米种类和加工方式的多样性,不同工厂的谷糙分离状态图像呈现不同的颜色分布,同一工厂在不同时间段的图像颜色信息也区别较大,而相同灰度化处理方式并不能满足不同颜色信息的图像。针对此问题,提出一种图像模型匹配的方法,该方法能够预先对图像进行匹配分类,并根据不同的匹配结果完成图像灰度化。
由于谷糙分离装置的分料板是垂直于水平方向的,对谷糙分界线的识别结果需要拟合成直线,结合这一实际特点,提出一种基于滑动窗口的直线边缘检测算法,该算法不仅不需要对边缘进行直线拟合,而且解决了图像中大量伪边缘并存的问题。
2.1 图像模型匹配
HSI颜色模型是基于彩色图像描述的图像处理算法的理想工具,它将彩色信号表示为3种属性:色调、色饱和度和亮度,克服了通用RGB颜色模型中两者耦合的缺陷[13]。在对谷糙分离状态图像的研究中发现,位于图像左侧的稻谷区域颜色信息变化较大,基于传统的RGB彩色模型对图像进行灰度化处理的方法并不能很好地适用于所有谷糙分离状态图像。当稻谷与糙米的颜色较为接近时,采用传统灰度化方法的效果并不理想。然而,它们的色饱和度却较易区分,因为稻谷色饱和度更大,糙米经脱壳后黄色变浅,色饱和度变弱,符合视觉规律。因此,可将HIS和RGB颜色模型结合起来。
在此基础上,提出一种对谷糙分离图像进行模型匹配的方法,首先建立稻谷区域颜色信息的匹配条件,其次在图像左侧稻谷区域内选取待匹配模板Mask,并对Mask进行颜色信息匹配,最后根据匹配结果对图像采用相对应的灰度化处理方式。
图像模型匹配方法具体步骤为:
(1) 建立稻谷区域颜色信息的匹配条件。在图像的左侧区域即稻谷区域内选取一块大小为m×n的图像作为待匹配模板Mask,提取Mask内各像素点的三通道颜色分量,利用式(1)对Mask进行匹配,并将匹配结果存入矩阵M中。
(1)
式中:
f(x,y,1)、f(x,y,2)、f(x,y,3)——Mask内(x,y)点处的R、G、B颜色分量;
M(x,y)——Mask在点(x,y)处的匹配结果;
{t1,t2,t3,t4,t5,t6}——能够区分Mask颜色信息的参数集合(集合内元素取值范围为0~255)。
(2) 统计M内所有像素点的匹配结果,利用式(2)判断Mask的分类结果mode。
(2)
(3) 根据分类结果mode,对谷糙分离状态图像采用不同的灰度化处理方式。对匹配结果mode=mode1的图像直接采用RGB颜色模型的方法进行灰度化;对mode=mode2的图像,需将RGB颜色模型转换到HSI颜色模型后,再进行灰度化处理。图像的转换公式为:
(3)
(4)
(5)
(6)
式中:
R、G、B——图像中像素的红色、绿色、蓝色分量;
H、S、I——图像中像素的色调、饱和度和亮度分量。
mode=mode2时的灰度化处理效果如图3所示。由图3可知,由于谷糙分离图像中谷糙混合区仍有少量稻谷分布,图像对比度较低,直接运用RGB模型进行灰度化处理后图像的前景与背景很难区分,不利于图像二值化的阈值选取。通过试验方法,先对图像进行分类匹配,再利用S颜色模型进行灰度化处理后效果明显,较好地保留了分界线的边缘细节。

图3 灰度化转换结果
2.2 图像二值化
首先对直方图阈值图像分割、半阈值选择图像分割、迭代阈值图像分割、不变阈值图像分割和类间方差自适应阈值分割法进行综合评价。由于最大类间方差分割法耗时最短,根据图像的灰度特性,当类间方差最大时,阈值图像分割的误分类概率最小,一定程度上避免了部分前景被错分为背景的情况[14]。将灰度值大于阈值的像素点设置为255,将灰度值小于阈值的像素点设置为0。
谷糙分量图像二值化处理结果如图4所示。由于谷糙分离过程中稻谷与糙米的粒度、比重不同,稻谷颗粒的数量是从左往右逐渐减少的。从二值化处理后图像的水平方向上不难看出,白色像素点的数量具有从左到右依次递减的趋势,符合谷糙分离图像颜色渐变的特征。

白色像素点为稻谷颗粒位置,黑色像素点为糙米颗粒所在位置
2.3 分界线检测
边缘信息是重要的图像特征信息,边缘检测方法研究是图像分析和识别领域中一个十分引人关注的课题[15]。其中,Canny算子因其抗干扰性强、计算复杂度低等优点,成为当下边缘检测算法的首选[16-18]。谷糙分离图像的全局颜色信息是渐变的,而谷糙分界线的局部颜色信息是突变的。同时,由于二值化后图像右侧会有大量且散乱的白色像素点,直接运用Canny边缘检测算法会导致结果中出现许多的伪边缘。目前,在使用Canny边缘检测方法前,往往需要对图像进行开闭运算或连通域操作来去除伪边缘,这些操作需要人工选取参数如连通域面积去除的阈值等,参数的不确定性会丢失一部分边缘信息[19],不利于谷糙分界线的精确识别。
结合上述问题与特征,提出一种基于滑动窗口的直线边缘检测算法,该算法结合了谷糙分离状态图像全局渐变、局部突变的颜色信息特征和直线边缘特征,利用滑动窗口对二值化图像矩阵的每列像素信息进行分析筛选,得到目标边缘的位置信息。
(1) 滑动窗口扫描。建立大小为height×width的窗口C。对图像按水平方向扫描,扫描步长为1像素,每次扫描后,通过式(7)对窗口内的所有像素值进行求和。
(7)
式中:
C(i)——第i次扫描后窗口内的像素灰度值之和;
f2(x,y)——二值化后的图像;
k1、k2——窗口左、右两端的位置。
(2) 对窗口C进行灰度变换,保留大尺度波峰波谷点后得到窗口C1。为了快速找出C中突变与渐变部分,先生成C的灰度波动曲线,再对像素点进行一阶差分。
由于C的波动曲线并不平滑,直接对C一阶差分后数值波动较大,不利于准确、快速找出窗口灰度值突变部分。因此参照文献[20-21]中灰度波动变换的方法,先生成C的灰度波动曲线,然后利用标准差代替人为设定的阈值,自适应地去除曲线中小尺度灰度波动后得到C1。该过程具体描述为:遍历C中所有的极值点,如果存在ki、kj使得极值点对(pe(ki,C(ki)),te(kj,C(kj)))同时满足:
(8)
(9)
式中:
Pr(kpeak,C(kpeak))——大尺度波峰点。
同理,对波谷点进行搜索。C、C1的灰度波动曲线如图5所示。通过对C的波动曲线进行灰度变换,能够去除一部分噪声,在反映灰度波动曲线全局趋势信息的同时缩减信息量,具有一定的实时性。
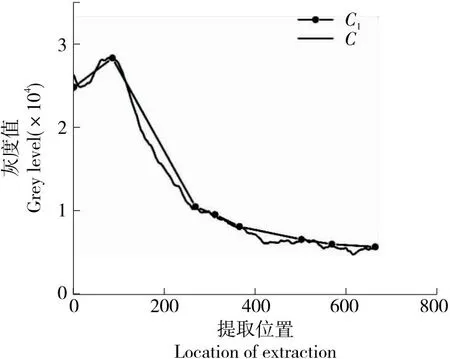
图5 灰度波动变换处理结果
(3) 对窗口C1进行第一次筛选得到C2。去除灰度值之和小于均值的窗口后得到C2,即
C2={C1(i)|C1(i)>mean(C1)}。
(10)
(4) 对窗口C2进行第二次筛选得到C3。对窗口C2一阶差分后,保留C2中一阶差分值最大的窗口C3,即
C3={C2(i)|max(diff(C2(i)))}。
(11)
最后,以图像左下角为原点,按照工厂筛板的实际长宽等比例缩小并建立坐标系,通过坐标转换计算出C3的位置坐标loc,该坐标loc即为谷糙分界线的实际位置。
3 结果与分析
3.1 对比试验结果与分析
以500张谷糙分离状态图像为试验样本,每组采样50张图像,共10组。每组采样间隔设定为1 h。为了测试该方法的自适应性,该样本包含两种颜色信息差别较大的谷糙分离状态图像(250组籼米图像和250组糯米图像),并与边缘检测算法中的Canny算法进行比较,测试该方法的可靠性。
图6中,第一行为糯米处理结果,第二行为籼米处理结果。Canny算法对分界线边缘细节保留较好,能够识别出边缘的轮廓信息,但会出现部分伪边缘,对分界线的定位产生干扰,不利于后续的直线拟合操作。伪边缘的频繁出现,是因为谷糙分离图像中的谷糙混合区仍存在分散的稻谷,二值化图像需去除连通域。然而,连通域分析中固定的阈值如面积阈值,需要根据最终结果手动调整。这种人工操作的不确定性会导致不连续的线段或噪声点,从而导致真正的边缘点的丢失。此外,当图像的目标和背景具有相似的灰度值时,应用Canny算法可能会导致过大的背景边界,从而使得所识别分界线的位置右移。

图6 不同算法对比试验结果
试验方法对谷糙边界线识别效果较理想,没有伪边缘的产生。由于试验方法是基于列梯度而不是像素梯度的,能有效减少具有相似灰度值的目标和背景的干扰。
此外,试验方法能直接识别出直线型的谷糙分界线,更大程度上保留了谷糙分界线的边缘信息,增加了试验方法的实时性与准确性。
3.2 位置误差结果与分析
为了在位置结果上验证试验方法得到的谷糙分界线位置的准确性,对人工判断的分界线位置和试验方法所识别的分界线位置进行评估。分别记录每组单幅图像中分界线在分离装置中的实际位置,并设定为分界线的真实值loc1,将基于Canny方法或基于该方法计算出的谷糙分界线位置设定为测量值loc2。因此,按式(12)、式(13)计算谷糙分界线位置的绝对误差∂1(绝对误差不带方向,只比较大小)与相对误差∂2。
∂1=|loc1-loc2|,
(12)
(13)
由于组内采样时间和每组采样时间间隔的设定,每组组内图像的灰度信息相似,那么获取的分界线位置也相近。且在对基于Canny和试验方法计算出的分界线位置结果初步对比后发现,二者差距较明显。因此,以组为单位对分界线的位置误差进行计算与比较。具体为先求出每组中所有图像的分界线位置的上述两种误差,再求取平均值,以验证试验方法的可行性。
每组谷糙分界线位置的误差见表1。
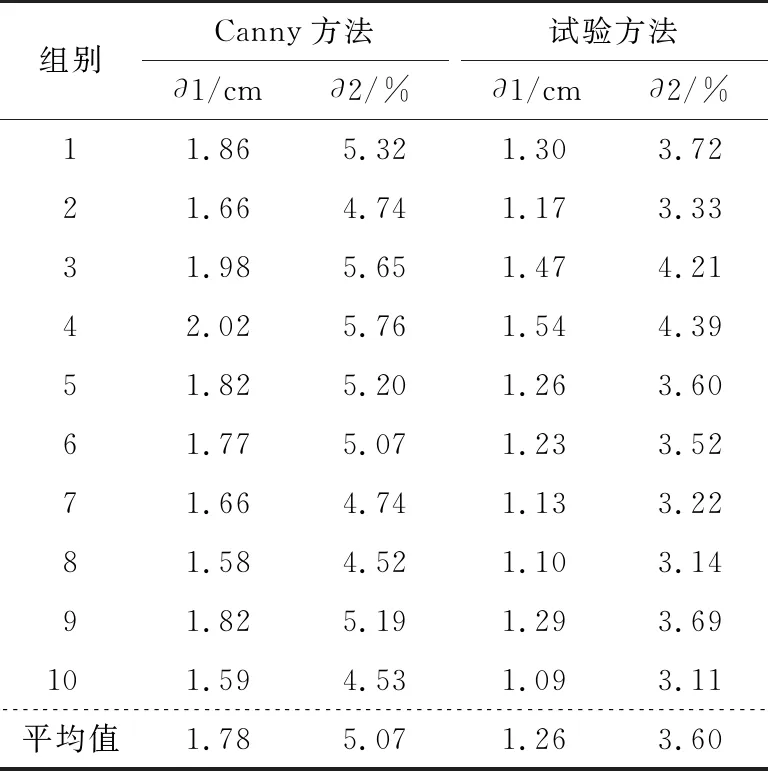
表1 谷糙分界线位置的误差结果
由表1可知,Canny算法对分界线识别的相对误差较大,分界线位置的绝对误差为1.58~2.02 cm,相对误差为4.52%~5.76%。试验方法处理后分界线的绝对误差为1.09~1.54 cm,而相对误差为3.11%~4.39%。综上,相较于Canny算法,试验方法能将分界线位置的绝对误差降低约0.5 cm,将相对误差控制在5%以内,一定程度上提高了谷糙分界线位置识别的精确度,说明试验提出的基于直线边缘检测的谷糙分界线识别方法是可行的。
对使用Canny边缘检测算法定位并不准确的现象,挑选出试验结果较差的图像,并按步骤测试,作出以下分析:首先,伪边缘的产生是导致分界线定位不准确的主要因素。由于Canny边缘检测是基于像素梯度的,相似灰度值的稻谷与糙米会导致该边缘检测算法不理想,若基于灰度图像进行边缘检测,则会产生大量伪边缘。因此,试验中采用基于二值化图像进行边缘检测,一定程度上削弱了伪边缘带来的影响。但伪边缘现象依然存在于少部分图像中,使得分界线的位置结果产生较大误差。其次,相似的灰度特征会使分界线区域更加模糊,所识别的分界线并不仅仅是一条线,而是由多条线段构成。最后,对分界线的直线拟合过程又会使误差增大。
试验使用Matlab-2017a在1.9 GHz的CPU上进行仿真,对比了不同算法的平均运行时间。由表2可知,Canny方法的运行时间较短,而试验方法由于增加了图像模型匹配和直线边缘检测的迭代运算,因此运行时间有所增加。试验方法能够检测1.5 s之前的图像的谷糙分界线,具有一定的实时性。
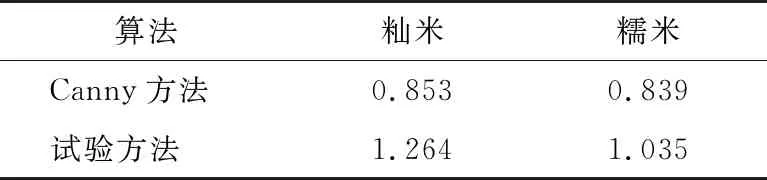
表2 计算时间对比
3.3 实际生产测试与分析
为验证方法的可行性,进行实际生产的对比试验,将传统方法、Canny和试验方法进行位置误差对比,并结合实际情况对这些误差规律进行分析。按照获取谷糙分界线的不同方式,共分为5个组进行测试。
第1组为参照组,作为准确的分界线位置数据,以评估其他组获得的分界线位置,同时对谷糙分界线进行现场观测和视频录制,现场观测时,初步记录分界线位置,并根据录制的视频对记录的分界线位置进行校正。第2、3组模拟人工检测不频繁的情况,第2组只观测初始位置,第3组为周期观测。第4、5组分别为试验方法和Canny方法得到的分界线位置,计算机检测周期为5 s,并采用检测系统框架,测试时间为1 h。
由图7可知,人工检测中的单次检测(组2,3)已跟不上实际分界线位置的变化(组1),检测效果不理想。试验方法(组4)能够实时地检测和跟踪分界线的位置变化,平均位置误差为1.37 cm。因此,基于图像处理技术的分界线检测方法能够在一定程度上替代人工检测的方法。
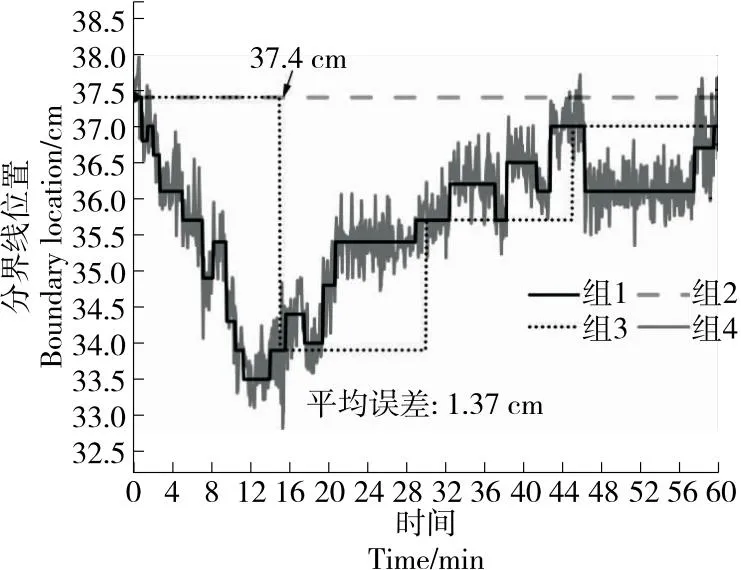
图7 各组分界线的位置分布
试验方法能够捕捉到实际分界线位置的快速波动变化,这是人工检测所无法达到的。然而,这种波动变化可能会对分料装置的自动控制造成影响。为了避免电机移动后分界线位置又发生变化,需要设定分界线的波动阈值或增加采样时间,以确保稳定的位置变化。
由图8可知,Canny方法的误差主要集中在-2.4~-1.2 cm,试验方法的误差更小,主要分布在-1.6~0.8。两种方法的误差结果主要为负值(测量值loc1>真实值loc2),即计算出的位置略微偏向实际分界线的右边,而这种现象在Canny方法中更加明显。虽然这种趋势可以通过人工测试进行补偿和校正,但仍需要进一步分析其规律。
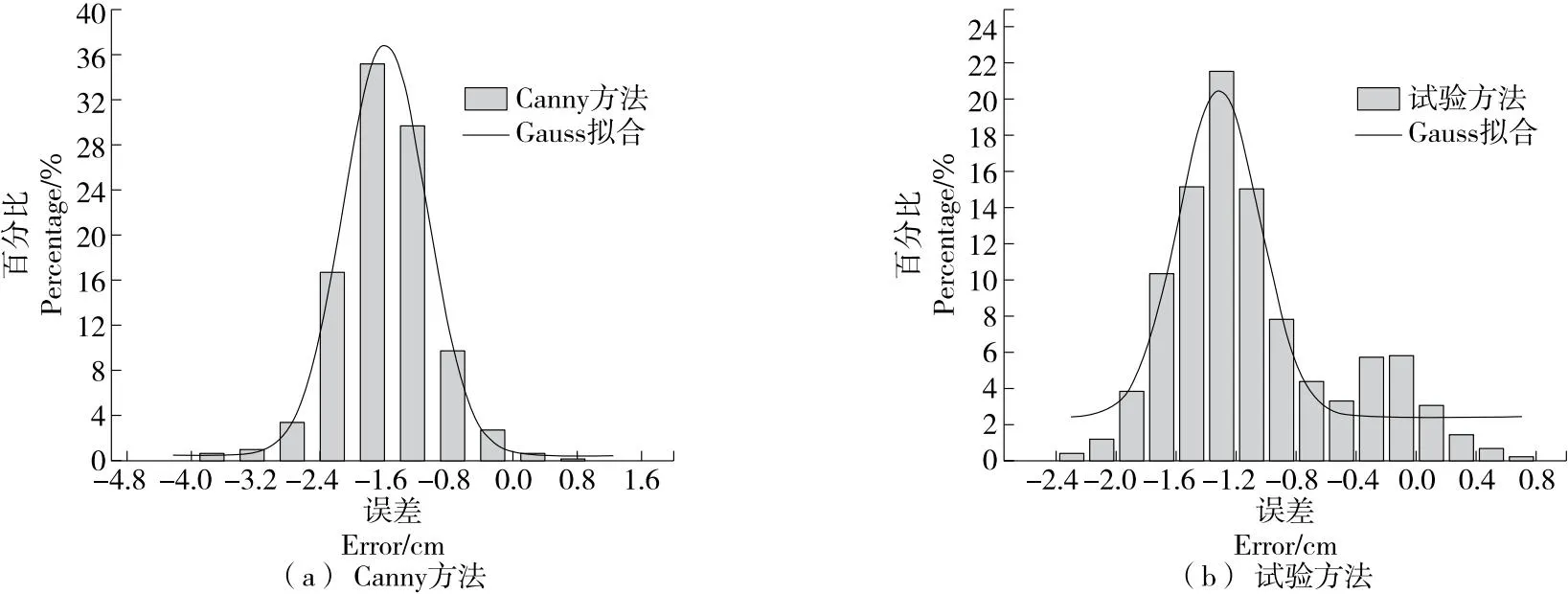
图8 误差频率分布直方图
就实际情况而言,所识别的谷糙分界线的上部分往往向右侧偏离,这是分离装置中的进料速度和筛面谷物厚度等机械参数导致的。为控制出料口的分料装置,人工确定分界线时会更多关注分界线末端部分。因此,建议收缩机器视觉的视野范围,以获得更理想的检测结果。
就算法而言,Canny方法的局限性在于形态学处理参数需要手动选择。对于具有低对比度的谷糙分离图像,需进行多次腐蚀操作,导致边界向右侧偏移。此外,图像的上部分倾斜边缘会在直线拟合时干扰下部分边缘,导致整个分界线结果偏右。相比之下,试验方法无需直线拟合和形态学处理,并且是基于列灰度梯度和极值点检测分界线,能够减弱伪边缘和噪声的干扰。但在提高算法鲁棒性的同时,仍会存在一定的检测精度下降。
模型匹配方法的实质是区分色饱和度较大的图像,并用HSI颜色模型对这些图像进行处理。在相机设备因功能或成本限制无法实现高光谱成像时,这是一个较为实用且简便的方案,同时也能够节约相机的处理时间[22-23]。不过,这可能会一定程度地降低识别精度。此外,式(1)中的分类参数t是通过试验样本得出的,因此在处理不同的试验样本时可能需要重新调整。对此,可以采样支持向量机的方法进行自动分割,以确定该分类参数。
4 结论
为了更加精确识别谷糙分界线,研究提出了一种基于直线边缘检测的谷糙分界线识别方法。首先根据图像颜色信息分类图像,再进行灰度化处理。随后采用直线边缘检测算法来解决伪边缘并存的问题。结果表明:相较于传统的Canny算法,试验方法不仅能够减小分界线的位置误差,而且在识别谷糙分界线时更加可靠。后续将结合机器视觉和谷糙分离设备的实际工作特点,设计分料装置的自动控制系统,使该系统能够识别谷糙分界线的位置,控制电机实现分料装置的运动,实现提升谷糙分离效率的目标。
