基于轻量化卷积神经网络的多肉植物种类识别研究∗
2024-01-26孙公凌云张靖渝连俊博宁景苑刘伟立王国振陆诗怡时鹏辉楼雄伟
孙公凌云,张靖渝,连俊博,宁景苑,刘伟立,刘 权,王国振,陆诗怡,时鹏辉,楼雄伟
(浙江农林大学数学与计算机科学学院,浙江 杭州 311300)
多肉植物是一种根、茎、叶三种植物营养器官中有一处或多处呈肥厚多汁状态且具有能储藏大量水分功能的植物,其作为一类观赏性植物具有很高的国民热度[1]。目前多肉植物产业在我国发展较快,市场前景广阔,分布区域广泛,“肉肉”爱好者数量众多,多肉植物在国内的大街小巷随处可见,其具有繁殖能力强、造型多变、地理分布广、适应性强等优势,经常用于盆栽观赏、公园庭院绿化、屋顶花园、多肉花镜花台等绿化造景当中[2]。但多肉植物品种繁多,很多品种长相差异也较小,并且由于养护环境、养护手法、季节等因素的影响,如浇水的频率、浇水量多少以及光照情况等,同一株多肉植物的外貌形态也会存在较大差距,如图1 所示。上述因素都为人工辨别多肉植物品种带来了困难,这间接导致当前在多肉植物市场中,不良商家以次充好、坑骗消费者的现象频频发生,不利于多肉植物产业的健康发展,如何实现对多肉植物的精准分类成为一个亟待解决的问题。

图1 蓝石莲不同时期的形态
随着深度学习和人工智能图像识别技术的发展,深度学习方法逐渐在图像识别领域中呈现出无可比拟的优势。Krizhevsky 等[3]在2012 年提出AlexNet 模型成为了深度学习热潮开始的标志,其加深了网络结构,引进非线性激活函数改善了梯度消失问题,利用Dropout 方法避免过拟合。Simonyan 等[4]在2014 年提出了VGGNet 系列模型,进一步证明了网络层次加深的作用。同年,Szegedy等[5]提出GoogleNet(也被称作Inception-V1)模型,在加深网络结构的同时增加网络的宽度,从而提高网络的表达能力。随后,Inception-V2[6]网络和Inception-V3[7]网络等被相继提出。但是梯度消失和梯度爆炸等问题很可能会伴随着网络层次的增加而产生。ResNet 模型的提出克服了以上难题,并且其中提出的残差块可以将数据信息传输到更深层次[8],为复杂网络的设计提供了有效思路。由于卷积神经网络在图像识别上的优势,已广泛应用于植物图像分类的研究中。郑一力等[9]提出了使用基于迁移学习的Alex Net 网络、Inception V3 网络进行植物叶片图像识别研究,该方法实现了对ICL 数据库中包含220 种植物叶片样本的有效识别,准确率分别达到了95.31%、95.40%。张雪芹等[10]提出了P-AlexNet 模型进行植物识别,基于迁移学习方法对AlexNet 模型进行了改进,训练得到验证集精度达到86.7%。李立鹏等[11]改进了ResNet101 模型结构对数据扩充后的野生植物数据集进行训练,优化后的模型较原模型识别准确率增加约7 个百分点,达到85.6%。裴晓芳等[12]以ResNet18 为基础模型提出了一种基于注意力的残差结构改进方法,在Oxford17 和Oxford102 两个花卉数据集中正确率分别为99.26%以及99.02%,适用于花卉细粒度图像分类。深度学习在图像识别领域中的优势推动了我国植物相关产业的发展,对我国国民经济和人民生活水平的改善起到了十分重要的促进作用。
由于多肉植物品种难以辨别,对其进行图像分类工作面临着巨大的挑战。目前,国内外有部分学者对多肉植物种类的识别进行过研究。王守富等[13]提出一种以颜色特征和纹理特征组成的复合特征作为输入的WPA-SVM 多肉植物分类识别模型,对原创的5 类多肉植物数据集识别准确率和误判率分别为99.42%和0.58%。Suteeca 等[14]利用CNN 建立了一个准确率为79.36%的多肉种类识别模型并部署在web 系统中。刘俨娇[15]基于AlexNet融合特征与微调的方法对原创的20 类多肉植物和9 类生石花数据集进行分类,分类正确率分别为96.3%和88.1%,平均每幅图片测试用时8s。黄嘉宝等[16]利用微调网络GoogLeNet 对原创的10 类多肉植物数据集进行了强监督分类训练、测试,精准率为96.7%。
上述研究中都实现了对多肉植物种类的识别,识别精度较好,但是目前的研究在以下几方面还是存在一定的不足:使用强监督方法完成细粒度分类任务需要对样本图片的特征区域进行标注,通常会消耗大量的人力和时间;算法模型太大难以在部分移动设备以及嵌入式设备中进行部署;选取的多肉植物种类较少对模型挑战不足。为了能够更好地认识和识别多肉植物,本研究基于轻量化网络MobileNet V3,针对13 种不同种类的多肉植物制作了多肉植物图像数据集,对多肉植物的品种进行种类识别研究。本研究方法不需要对图像样本的特征区域进行标注,且轻量化模型所占内存空间小,针对多肉植物市场发展火热的现状,其适合部署到部分移动设备以及嵌入式设备,方便人们的使用。
1 数据集的建立
1.1 数据采集
由于缺乏现成的多肉植物图像数据集,本研究采用自制数据集。试验搜集了13 种国内常见的景天科多肉植物的图片样本制成多肉植物图像数据集,共计13632 张,每张样本图片中包含一株或多株相关的多肉植物。样本图片分别来源于网络、实地拍摄与相关的专业书籍。来自网络部分的样本图片来源于百度图片、百度贴吧、小红书、多肉联萌等网络平台,均由人工筛选后下载;来自实地拍摄部分的样本图片,分别拍摄于山东省济南市和浙江省杭州市的多肉大棚;来自专业书籍部分的样本图片,则分别来源于«多肉植物图鉴»[17]与«景天多肉植物图鉴»[18]。
考虑到目前国内多肉植物市场中,存在商家自主杂交培育成本低、俗名繁多等原因而导致的部分多肉植物品种混乱且存在争议的问题,为了保证样本数据的准确性,本研究参考了目前国内权威植物品种数据库——“植物智”信息系统。“植物智”信息系统录有植物物种介绍、图像、地理分布等信息,本研究选取的多肉植物试验种类均可在“植物智”信息系统中搜索到。数据集中的13 种多肉植物图像样本的基本信息和具体数量情况如表1 所示。表中第二列为多肉植物的植物学名信息,通常情况下一种植物若为栽培植物,则品种名使用半角单引号括起并且单次首字母大写。

表1 多肉植物图像样本详细情况
1.2 数据处理与数据增强
将本研究的数据集中13 632 张图像样本按8 ∶2的比例划分为训练集和测试集,其中训练集样本数量为10 911,测试集样本数量为2 721。
对图像样本进行数据处理,将所有样本图片中非JPG 格式的图片统一转换为JPG 格式,对测试集图像样本统一进行压缩并调整为大小是224×224像素的图像。
在数据处理后对训练集图像样本进行在线数据增强,每轮训练过程前进行如下操作:将图像样本统一进行随机裁剪并调整为大小是224×224 像素的图像;将图像样本统一进行概率为0.5 的随机水平翻转;对图像样本统一进行概率为0.2、纵横比范围在2/100 到1/3 之间的随机遮挡。
最后对图像样本统一进行归一化处理,由于本研究使用Imagenet 数据集预训练权重进行迁移学习,因此使用Imagenet 数据集的均值与标准差对图像样本做归一化处理。图2 所示为对图像进行归一化操作的结果展示。

图2 图像归一化
2 相关原理
2.1 Focal Loss 损失函数
损失函数是用来估量模型的预测值与真实值的偏离程度的函数。在模型训练过程中,图像难易样本不平衡对模型性能会造成一定影响。Focal Loss损失函数[19]是一个动态缩放的交叉熵损失函数,在交叉熵函数基础上进行了改进,通过调节系数动态减小易分类样本的权重,增加难分类样本的权重,达到平衡各类别权重的目的,从而解决难易样本影响模型性能的问题,其公式为:
式(1)[20]中:αt为权重因子,调节正负样本损失之间的比例;pt为某个类别的类别分数;(1-pt)为调制系数,调节不同难易样本的权重,当pt趋近于1 也就是(1-pt)趋近于0 时,样本置信度高代表易分类样本,反之代表难分类样本;γ为聚焦参数,(1-pt)γ调节难易样本在模型中的权重。本研究搜集了13个种类的多肉植物图像,由于多肉植物具有类间相似度高、形态易变的特点,因此进行多肉种类识别时,往往会出现相似的难分类样本,分类难度较大,故使用Focal Loss 损失函数来解决样本不平衡的问题,从而提升模型的性能。
2.2 MobileNet V3 模型
MobileNet V3[21]于2019 年被提出,其包括两个版本,分别为MobileNet V3 Large 和MobileNet V3 Small,两个版本的层数不同,是MobileNet 系列网络最先进的研究成果。MobileNet V3 添加了SE 模块,更新了激活函数,并且保留了MobileNet V1[22]中的深度可分离卷积和MobileNet V2[23]中的线性瓶颈倒残差结构。
①深度可分离卷积
深度可分离卷积包含深度卷积(Depthwise Convolution,DW)和逐点卷积(Pointwise Convolution,PW)两部分,其中深度卷积对单个通道进行卷积,而逐点卷积将卷积核设定为1×1 尺寸进行卷积,如图3 所示。

图3 深度可分离卷积
以图3 中流程为例,输入特征图通道数为CIN=3,高度HIN=224,宽度WIN=224;输出特征图通道数COUT=256,高度HOUT=220,宽度WOUT=220;深度卷积为3 个深度为1 的卷积核,卷积核大小K=5。逐点卷积为256 个3×1×1 的卷积核。设深度可分离卷积的乘法运算总次数为X,其计算方式如式(2)所示;设深度可分离卷积需要的权重参数数量为Y,其计算方式如式(3)[22]所示:
②具有线性瓶颈的倒残差结构
线性瓶颈的倒残差结构即模型中的Bottleneck层,具有两个逐点卷积层和一个深度卷积层,如图4所示,图中“⊗”表示在此处进行点乘操作。

图4 具有线性瓶颈的倒残差结构
倒残差结构对图像的维度处理首先会采用逐点卷积升高图像维度,然后通过深度卷积,深度卷积对单通道卷积的特性决定了计算量不会过高,最后再使用逐点卷积降低图像维度。
③注意力机制
注意力机制(Attention Mechanism)模仿了人类大脑所特有的大脑信号处理机制,其目标是从当前所有信息中提取重要特征信息。MobileNet V3 在Bottleneck 结构中加入了注意力机制,被称为SE 模块[24]。SE 模块主要包括压缩(Squeeze)和激励(Excitation)两部分。SE 模块的计算步骤,设深度卷积层输出通道为C,首先在深度卷积层后设置了全局池化层将特征图压缩为C×1×1 的向量,实现压缩操作;随后设置了两个1×1 全连接层,第一个全连接层节点个数是输入特征通道数的1/4,第二个全连接层输出尺度因子尺寸与输入通道数一致,应为C×1×1,两个全连接层共同实现了激励操作[21];经过两个全连接层后得到新向量的每个元素与对应的输入特征通道相乘,得到新的特征数据,作为输出特征。
SE 模块的压缩操作通过平均池化实现,由于最终的尺度因子作用于整个通道,所以将输入特征的每一个通道通过平均池化得到一个均值,基于通道的整体信息实现尺度因子的计算。SE 模块的激励操作通过在平均池化层后设置两个逐点卷积层训练来实现,经过两次逐点卷积得到尺度因子,然后通过乘法逐通道加权到之前的特征上,完成在通道维度上对原始特征的重标定。SE 模块利用两个全连接层的输出值来实现输入数据中关键特征的增强,并抑制不重要特征,提高了模型的性能。
2.3 改进的MobileNet V3 模型
本研究采用MobileNet V3 Large 作为特征提取网络。MobileNet V3 Large 模型中Bottleneck 模块前六层以及SE 模块中采用ReLU 激活函数,但是ReLU 函数输入为负时,其梯度就会为0。LeakyReLU 函数是基于ReLU 函数开发的用于解决梯度消失问题的激活函数,本研究将MobileNet V3 Large 模型原有的Re-LU 激活函数替换为LeakyReLU 激活函数[25],优化后的SE 模块如图5 所示。

图5 优化后的SE 模块
试验在全连接层中添加了Dropout 层[26]随机停止一部分网络节点以减轻过拟合的产生,增强网络在训练学习时的鲁棒性;迁移[27]在Imagenet 数据集中进行预训练的MobileNet V3 Large 参数权重,对整个网络进行训练;使用Focal Loss 损失函数来评估真实值与预测值之间的差距。改进后的网络结构如图6 所示,其中HS 代表H-Swish,RE 代表ReLU,LR代表LeakyReLU。

图6 改进后的模型结构
网络结构参数如表2 所示,包括输入输出、相应操作、是否使用SE 模块以及步长。

表2 网络结构参数
3 试验与结果分析
3.1 试验环境
本研究使用的进行试验的计算机操作系统为64 位的Windows 10 操作系统,搭载的处理器为12th Gen Intel(R)Core(TM)i5-12600KF 3.70 GHz,显卡型号为RTX 3080,使用Pythorch 1.10.2 深度学习框架在Pycharm 2021.1.2 开发环境中进行试验,使用的编程语言为Python 3.6.5。
3.2 参数设置
学习率设置为0.0001,使用AdamW[28]作为优化器,余弦退火方法作为学习率调整策略,可以加快模型收敛并且不容易陷入局部最优解;训练的Epoch 设置为100,Batch Size 设置为16;输入图像为RGB 图像,输入尺寸为224×224×3。
3.3 评估标准
为了评价多肉植物种类识别模型的识别效果,本研究采用的评估标准为 Top-1 准确率(Accuracy)、Top-5 准确率(Accuracy)[29]、精确率(Precision)、召回率(Recall)[30],除此之外还会考虑模型所需存储空间大小这一项因素。Top-1 准确率指输出的概率向量中最大概率所代表的多肉植物种类与正确的多肉植物种类一致的概率;Top-5 准确率指输出的概率向量中前五种概率所代表的种类中包含有正确种类的概率;精确率指全部预测为正的多肉植物图像样本中正确预测的图像样本的概率;召回率指全部实际为正的多肉植物图像样本中预测为正的图像样本的概率。
计算公式如下:
式中:TP、TN、FP、FN 分别表示真阳性、真阴性、假阳性、假阴性。
3.4 不同激活函数的效果比较与分析
为验证LeakyReLU 激活函数对多肉植物图像识别的优势,以及其在Bottleneck 模块和SE 模块中的不同作用,本研究设置了4 组不同激活函数对比试验以及4 组消融试验进行对比分析。
4 组不同激活函数对比试验如表3 所示,按照编号分别为将MobileNet V3 Large 模型原本采用的ReLU 激活函数与使用GeLU、ReLU6、LeakyReLU 三种激活函数做对比。表3 中的试验结果表明LeakyReLU 激活函数由于保留负值信息的特点,更适合多肉植物种类的识别。

表3 不同激活函数对比试验
4 组消融试验如表4 所示,按照编号分别为在Bottleneck 模块和SE 模块中激活函数不改变的模型、将Bottleneck 模块前六层的ReLU 激活函数换成LeakyReLU 激活函数的模型、将SE 模块的ReLU 激活函数换成LeakyReLU 激活函数的模型、将Bottleneck 模块前六层和SE 模块中的ReLU 激活函数换成LeakyReLU 激活函数的模型。表4 中的试验结果表明,将LeakyReLU 激活函数同时应用于Bottleneck 模块前六层与SE 模块,模型的性能优于单独采取一种策略的模型性能。

表4 消融试验
3.5 不同损失函数的效果比较与分析
为验证Focal Loss 损失函数对多肉植物图像识别效果的影响,使采用交叉熵损失函数的MobileNet V3 Large 模型与采用Focal Loss 损失函数的MobileNet V3 Large 模型对多肉植物图像数据集分别进行训练,对13 种多肉植物的精确率结果进行对比分析,如表5 所示。可以看出,Focal Loss 损失函数的表现整体优于交叉熵损失函数的表现。Focal Loss 损失函数虽然小幅度牺牲了广寒宫、丽娜莲、熊童子等易分类样本的精确率,但使静夜、蓝石莲、女雏等难分类样本的精确率得到提高,同时使模型整体的准确率得到提高。

表5 不同损失函数对比试验
3.6 不同分类模型的效果比较与分析
为客观评价本研究改进的网络模型的识别效果,在所搜集的数据集下,分别训练和测试了本研究改进的 MobileNet V3 Large 模型与未改进的MobileNet V3 Large 模型,以及其余两种较常见的深度学习模型,分别为ShuffleNet V1[31]和VGG16,以上模型均在Imagenet 数据集中进行过预训练。
试验结果的测试准确率曲线和训练损失值曲线与如图7 所示,图7(a)代表测试集准确率变化过程,图7(b)代表训练集损失值变化过程。
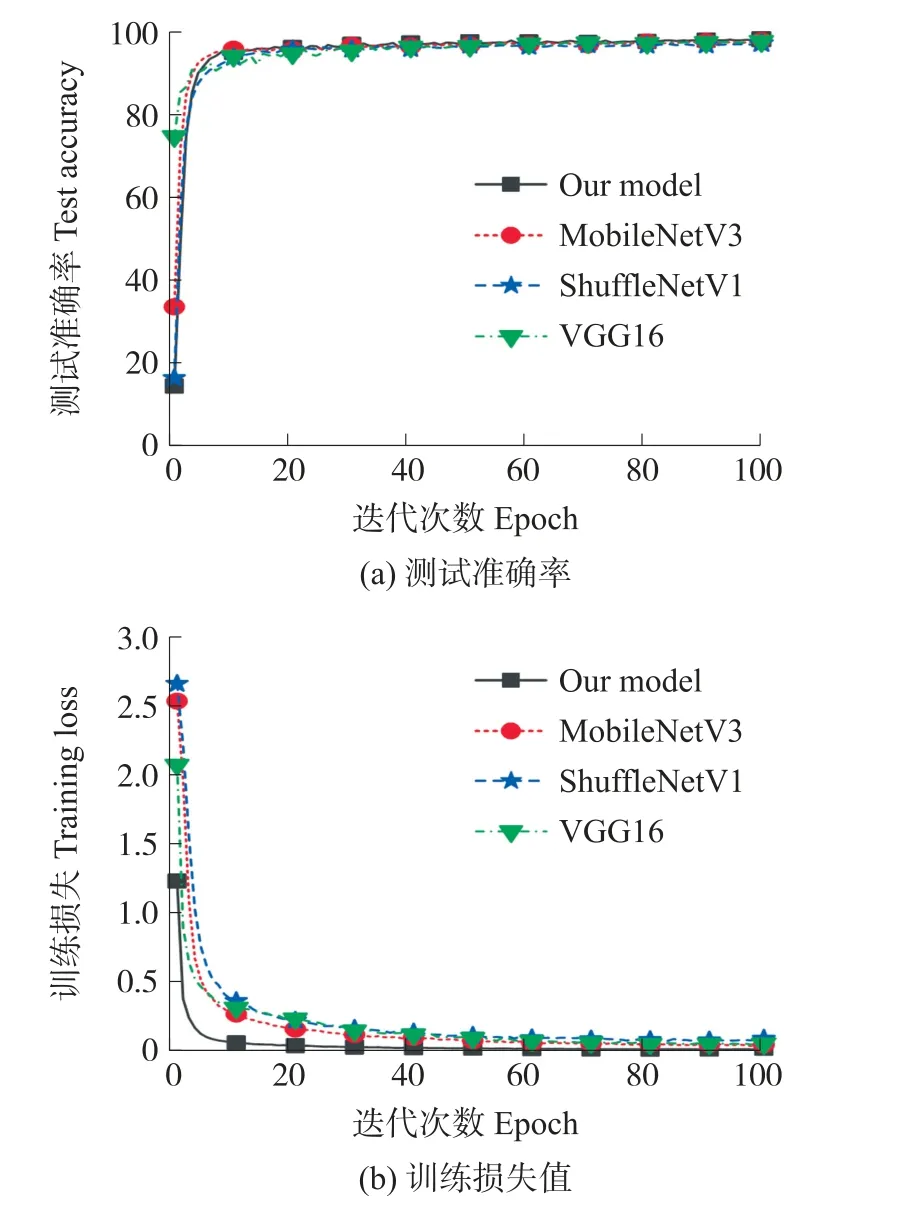
图7 不同模型准确率与损失值对比图(0~100 次训练)
由图7 中可以看出四个对比模型在第二十次训练过程后开始收敛,为了更清楚地展示本研究改进的MobileNet V3 Large 模型的优越性,选取四个模型在第二十次到第一百次的训练过程绘制测试准确率曲线和训练损失值曲线,如图8 所示。图8(a)代表测试集准确率变化过程,图8(b)代表训练集损失值变化过程。
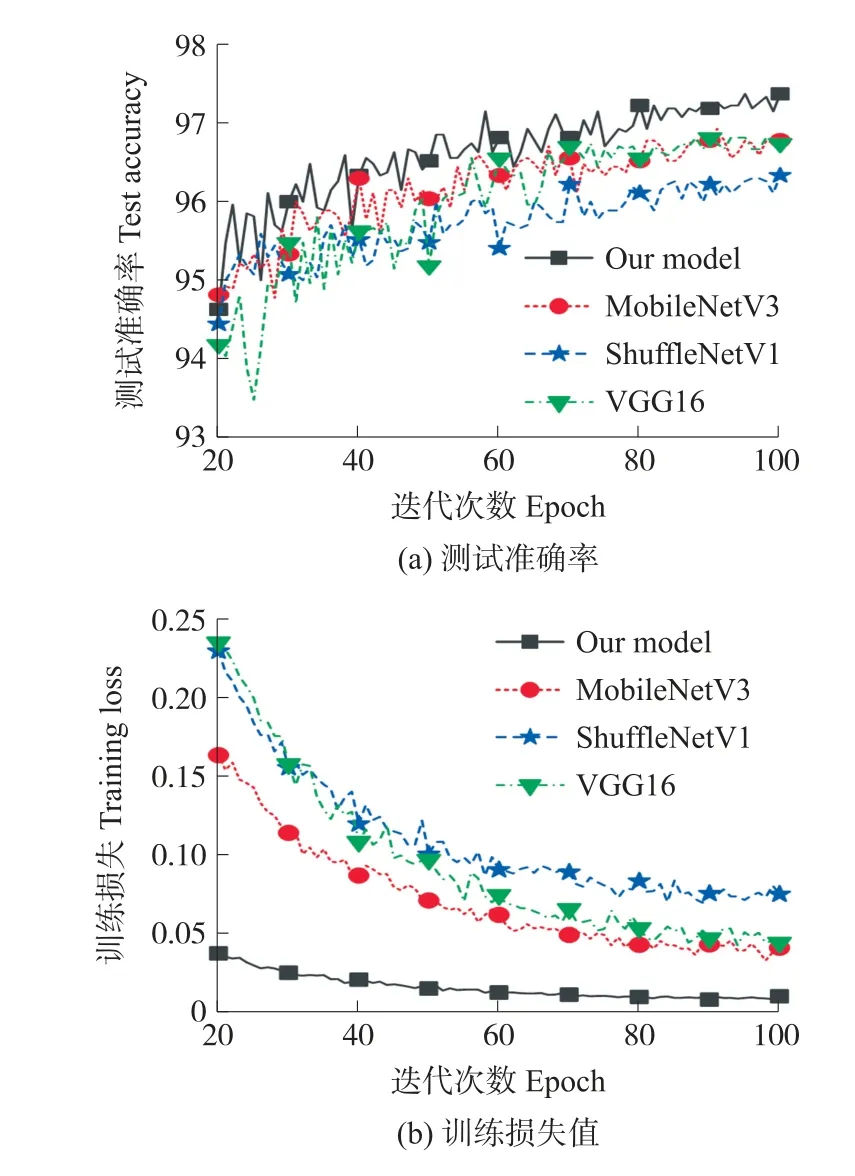
图8 不同模型准确率与损失值对比图(20~100 次训练)
表6 为不同模型的评价指标。由表6 可以看到,本试验提出的改进MobileNet V3 Large 网络的准确率优于 MobileNet V3 Large、ShuffleNet V1、VGG16。改进的MobileNet V3 Large 网络准确率相对于未改进的MobileNet V3 Large 提升了0.44%,改进后的模型性能得到了提高。与其他模型进行比较,ShuffleNet V1 同样也是轻量化模型,改进的MobileNet V3 Large 网络准确率相对于ShuffleNet V1 略高1.03%;改进的MobileNet V3 Large 网络准确率相对于VGG16 略高0.55%,但是VGG 16 模型的大小需要占1GB 的存储空间,而改进的网络模型仅占48.2MB 的存储空间,比VGG 16 模型小了21 倍左右;综合来说,改进的MobileNet V3 Large 是相对优越并且适合部署在系统中使用。

表6 不同的网络识别效果评价
混淆矩阵展示测试集预测值各类归对、归错的个数,其中的横坐标代表真实值,纵坐标代表预测值;主对角线的数字代表被正确预测为其对应种类的图像样本数量,其他位置的数字代表被错误预测为其对应纵坐标种类名称的图像样本数量。为了进一步展示改进后MobileNet V3 Large 模型的性能,为测试集样本数据,绘制以上4 个模型的混淆矩阵,混淆矩阵如图9 所示。

图9 混淆矩阵
图中图9(a)代表改进后的MobileNet V3 Large的混淆矩阵,图9(b)代表未改进的MobileNet V3 Large 模型的混淆矩阵,由图9(c)代表ShuffleNet V1 的混淆矩阵,图9(d)代表VGG16 的混淆矩阵。图9 中可以看出,改进后的MobileNet V3 Large 模型对多肉植物种类识别结果最好。
3.7 网络可视化
网络卷积层包含了大量语义信息,网络可视化可以更好地展示模型效果[32]。梯度类加权激活映射(GradCAM)是一种用于分析分类网络的可视化工具,采用反卷积和导向反向传播实现网络的可视化。使用梯度类加权激活映射输出各层网络提取到该层输出的类激活图,从而可以看出图像中响应值最高的区域来验证网络的关注点是否合理。
在多肉植物的生长过程中,由于养护环境、养护手法、季节等因素的影响,如浇水的频率、浇水量多少以及光照情况等,多肉植物形态会随着生长条件的改变产生变化。例如在浇水没有充足光照的条件下,多肉植物大都会出现徒长、变色的迹象;在冬季尤其是莲座状外形的多肉植物大都会呈收敛状,而在夏季莲座状外形的多肉植物大都会呈分散状。虽然多肉植物形态易变,但是多肉植物的芯部位一般会保持其形态特点(虽然多肉植物的颜色也会产生变化,但是多肉植物的颜色依然存在每个品种特有的变化范围,并且在多肉植物的芯部位,颜色的变化相对稳定,所以颜色依旧是重要的判断条件)。改进的MobileNet V3 Large 网络模型的类激活图可视化如图10 所示。

图10 类激活图可视化
图10 展示了网络最终输出的类激活图,可以看出图像响应区域覆盖范围大,并且响应值最高的区域集中在多肉植物的芯部位,说明芯部位是本文模型判断多肉植物图像所属种类的重要区域,模型学习到了关键特征。
为了进一步展示改进的MobileNet V3 Large 网络模型中卷积层发挥的作用,将模型每一层网络输出的类激活图也进行展示,如图11 所示。图11 体现了模型每一层网络的学习过程,可以看出经过训练模型学习到了多肉植物的关键特征。
将改进Bottleneck 模块前六层与SE 模块后的模型与原模型的类激活图做对比,如图12 所示。在替换激活函数后,图像响应值高于原模型,并且覆盖的区域范围比原模型更加合理。

图12 改进模型类激活图可视化对比
改进的MobileNet V3 Large 网络模型部分特征图可视化如图13 所示,包含模型输入特征图与前六层网络输出特征图。

图13 模型特征图可视化
3.8 模型性能验证
为了进一步比较本研究方法的有效性,将数据集分别按照上文中使用的比例划分5 次训练集、测试集,每次得到的训练集、测试集各不相同。对训练集和测试集使用不同的模型分别进行5 次试验得到的试验结果如图14 所示,平均准确率如表7 所示。可以看出,经过多次不同试验,本模型在多肉植物种类识别中依然有较高的准确率,说明本模型具有较强的鲁棒性。

表7 不同模型的5 次训练平均准确率

图14 不同模型的5 次训练模型准确率
4 结论
本研究立足于复杂生活环境下的多肉植物种类识别任务,针对多肉植物具有类间相似度高,以及在不同环境和不同养护手法下形态多变等特点,分析MobileNet V3 Large 原始模型并加以改进。本研究以奥普琳娜、白牡丹、广寒宫、静夜、吉娃娃、蓝石莲、丽娜莲、女雏、钱串、特玉莲、熊童子、雪莲、玉蝶等13 种多肉植物为研究对象,构建多肉植物图像数据集(13 632 张),以Pytorch 为深度学习框架,在经典MobileNet V3 Large 基础上,将Bottleneck 模块前六层与SE 模块的ReLU 激活函数换成LeakyReLU 激活函数,使用AdamW 优化算法更新梯度并嵌入了余弦退火方法衰减学习率,添加了Dropout 层提高模型的泛化性,使用Focal Loss 代替交叉熵损失函数,最终准确率达到了97.35%,使模型可以实时稳定地对多肉植物图像进行分类。本研究改进后的模型与前人研究相比,省去了人工标注数据集的步骤,同时提高了运算速度及准确率。与其他轻量化网络架构进行对比,改进模型具有更高效的识别准确率、更平稳的收敛过程;与经典卷积神经网络架构相比,改进模型具有更少的参数内存,能够满足多肉植物种类识别模型部署于各种移动设备和嵌入式设备的要求。
研究结果表明,利用MobileNet V3 网络对多肉植物进行种类识别具有一定的可行性。不过,改进后的模型依然存在不足之处,模型性能尚存在优化空间,本研究制作的多肉植物图像数据集也存在扩充空间。在未来的研究中,将增加新的多肉植物种类,扩充数据集,并继续优化模型性能,以便于将其部署于设备中进行多肉植物的种类识别。
