一种基于RGB-D 相机的语义地图构建方法∗
2024-01-23郭旭达宋勇磊
郭旭达 宋勇磊
(南京理工大学 南京 210094)
1 引言
智能机器人在陌生环境中进行同时定位和建图(SLAM)的课题已经被持续研究了几十年,并且学者门提出了许多卓有成效的SLAM 算法框架。SLAM 技术广泛应用于扫地机器人、服务机器人、巡检机器人、厂房运输机器人等场景。
SLAM 技术主要基于激光雷达和视觉摄像机两类感知设备,由于单目相机、双目相机和RGB-D相机相对较低的硬件成本,近年来视觉SLAM 逐步成为研究热点。图像存储了丰富的纹理信息,可同时用于其他基于视觉的应用,如语义分割、目标检测等。当前视觉SLAM 算法的框架通常由特征提取前端、状态估计后端、地图构建和回环检测等几个基本模块组成。一些具有代表性的SLAM 算法已经取得了令人满意的性能,如MonoSLAM[1]、ORB-SLAM2[2]、LSD-SLAM[3]等,这些方法主要侧重于优化机器人的位姿估计。在机器人对周围环境进行地图构建方面的研究,传统的SLAM 方法大多仅建立包含稀疏特征点的地图或只具有几何信息的三维地图[4]。机器人执行高级别任务时需要理解物体的语义信息与周围的场景进行交互。随着深度学习技术的发展,一些神经网络模型[5]在语义分割方面取得了良好的性能。因此,可以尝试将神经网络模型与SLAM 结合构建语义地图,从而提高机器人的环境描述能力。
语义信息作为物体的外在属性,对于机器人理解周围环境可以起到至关重要的作用。SLAM++[6]利用物体级别对象辅助SLAM 中的相机定位,并增量构建面向物体级别对象的三维语义地图。但他们的方法需要提供物体的几何模型,并且需要提前建立物体几何信息数据库,因此算法只能检测在数据库中出现的物体,无法提供整个场景的密集语义标注。SemanticFusion[7]基于ElasticFusion[4]跟踪相机位姿并建立面元(surfels)地图,在该过程中同步进行回环检测优化整个地图。利用卷积神经网络(CNN)模型输出RGB 图像的像素级语义分割结果后,基于贝叶斯概率更新surfels 的语义类别标签。Co-fusion[8]同样基于ElasticFusion[4]提出物体级别语义SLAM 方法,该算法基于运动分割和语义分割进行运动物体的检测,使用多种模型拟合方法跟踪物体并重建物体形状,最终维护一个背景模型和多物体模型。
DS-SLAM[9]基于ORB-SLAM2[2]提出了动态环境中的语义SLAM 框架,结合语义信息和移动一致性检查来滤除每一帧中的动态物体,从而提高位姿估计的准确性。能够减少动态环境下,移动物体对于位姿估计的影响,最后构建稠密的3D 语义八叉树地图。但也存在不足,语义分割仅能识别20 种物体类别,并且只认为人是移动的类别。文献[10]提出了一种适用于无人机平台的轻量级、实时语义SLAM 框架。该方法将视觉/视觉惯性里程计(VO/VIO)信息与从检测到的语义对象中提取的平面几何信息相结合。创建由质心和法线方向以及类标签和平面类型(即水平或垂直)表示的平面组成的稀疏语义地图。
本文提出一种将语义信息结合到SLAM 过程中的新方法并最终构建三维语义地图。算法整理流程如图1 所示。首先使用语义分割模型对RGB-D 相机输入的RGB 图像进行语义信息提取,然后进行时间序列上的语义分割结果关联对比,将存在误差的分割结果过滤后,与深度图像进行数据关联生成带有语义标签的点云数据,最后通过增量融合的方法集成当前帧的点云数据,构建基于TSDF的三维语义地图。
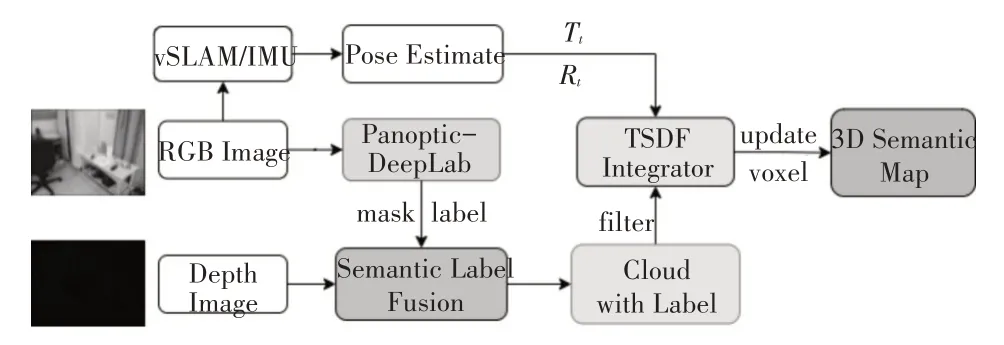
图1 三维语义地图构建流程
2 语义数据关联
2.1 语义信息提取
近年来,深度学习在目标检测与图像分割领域的研究成果层出不穷。Bowen Cheng等提出的Panoptic-DeepLab[11]模型是目前全景分割研究方向的佼佼者,性能和实时性基本可以满足SLAM 的需求。并且在COCO 数据集上训练的模型可以识别大约130 个事物和种类,因此选择Panoptic-Deep-Lab用于本文方法的语义信息提取模块。
通过实验发现,在连续多帧图像进行分割时,往往会出现某一两帧图像中会有物体被识别为错误的语义类别。针对此问题,本文提出一种新方法进行错误数据过滤。
相机的输出频率为30Hz,相邻两帧间的位移差很小,因此可以借助帧间关联对比过滤错误的识别。在得到当前帧的识别结果Lt后,本文方法选择与之前四帧的分割结果Lt-1、Lt-2、Lt-3和Lt-4进行关联对比计算,如式(1),只保留五帧中相同的语义标签,如果不同则删除,经过上述处理后,得到语义标签的交集。
2.2 数据关联
本文最终目的是建立完整的带有语义信息的三维地图。因此,需要使点云图中的每一个点具有相应的语义类别。本文所使用的模型可识别种类数量约为130 种,而8-bit 灰度图像的灰度值范围为0~255。因此,可以将0~255 的灰度范围值与语义类别一一对应建立LUT 表。在将深度图转为点云时,与LUT表结合,将语义类别关联到点云中。
由于彩色图像与深度图像尺寸大小不同,因此需要根据相机的内、外参计算深度图像中每一个像素对应中的语义类别值。首先根据相机的外参计算彩色图像到深度图像的旋转矩阵R 和平移向量T。外参矩阵由一个旋转矩阵和一个平移向量构成,彩色和深度摄像头的旋转矩阵分别为Rrgb和Rdepth,平移向量分别为Trgb和Tdepth。那么根据式(2)和式(3)即可得到旋转矩阵R和平移向量T。
为将深度图像中的每一个像素匹配到对应的语义标签,则需要通过相机的内参矩阵、彩色图像到深度图像的旋转矩阵R 和平移向量T 进行关联计算。通过式(4)计算得到深度图像中某点Pxy的对应的语义类别lxy。
Pxy=(x,y,z)为某点的空间坐标值,z 为深度值,Irgb和Idepth分别为彩色相机和深度相机的内参矩阵。
通过以上公式就可以在将深度图像转为点云时进行数据关联,使每一个三维点都具有语义标签。
完整算法如Algorithm 1所示。
3 语义地图构建
本文选择以截断符号距离函数算法(Truncated Signed Distance Function,TSDF[12])为基础建立三维语义地图。本文在Voxblox[13]的启发之下,使用前端位姿估计的结果,将当前帧生成的带有语义信息的三维点云融合到全局地图中。
3.1 点云语义分组
TSDF通过存储每个体素(voxel)到最近物体表面的有符号距离sdf 来进行地图构建,体素在物体之外为正数,在物体之内则为负数。同时每个体素由一个权重w 来评估相应的距离。本文方法中,每个体素包含一个有符号16 位浮点型距离值sdf、一个无符号8位权重值w 和一个8位语义类别标签值l,共4个字节。
Voxblox[13]中提出了基于RayCasting[14]的分组射线衍射方法,将处于同一个体素中的点分为一组,计算组内所有点的平均坐标值作为体素的坐标,这样在保持精度的同时加快了地图构建速度。本文方法同样根据点的坐标将处于同一个体素voxelid(x,y,z)中的点points(m)={p1,p2,…,pm}分为一组。通过式(5)可以计算得到每一个点所在体素的坐标,ε为体素大小。
而与Voxblox[13]中分组射线衍射方法所不同的是,本文方法对于同一个体素中的点points={p1,p2,…,pm},分别计算各语义类别点的权重和,计算方式如式(6),选择权重和最大的作为当前体素的语义类别,将所选择语义类别点的坐标加权平均值作为体素的中心坐标值,如式(7)所示。
3.2 地图构建及体素更新
本文中采用Voxel Hashing[15]方法,只在相机测量到的物体表面划分体素,而不是将整个空间都划分成体素。在此基础之上将8×8×8 的体素划分为一个体素块(voxel block),通过式(8)即可计算得到体素voxelid所在的体素块坐标block(x,y,z),η为体素块大小。
将体素块的坐标值通过哈希函数(9)映射到一个哈希表中,方便体素块的查询,p1、p2、p3为常数,n为哈希表大小。
在将新的一帧点云数据融合到全局地图中时,通常是从传感器原点向点云中的每一点投射射线,在射线方向上计算每一个与之相交的体素的距离D 和权重W,从而构建TSDF。本文中使用RayCasting[14]方法将经过语义分组后的点云数据进行融合,Voxblox[13]提出了结合相机模型的权重计算方法,将相机测量的深度信息和点与表面的距离结合来计算权重。本文同样采取Voxblox[13]中的方法进行体素的距离D 和权重W 的更新,计算公式如式(10~13)所示。
p(x,y,z)为当前帧中的点,o 为传感器原点,v(x,y,z)为与之相交的体素中心坐标,d(v,p,o)为点p 与物体表面的距离,w(v,p)为当前点权重,δ、ε为截断距离阈值,δ=4s,ε=s,s为体素大小。
4 实验及分析
本文选择在数据集ScanNet(v2)[16]中进行实验,以验证所提出方法的有效性。ScanNet(v2)是一个用于室内场景理解的大规模数据集,它使用消费级RGB-D 相机进行图像数据采集。每个场景序列中包含采集的RGB 图像和深度图像、相机轨迹、每个场景的3D重建模型以及语义标注。
本文从ScanNe(tv2)中选择了多组场景数据进行实验,其中RGB 图像大小为1296×968,深度图像大小为640×480。所有的实验均是在一台配备英特尔i7-7800X 处理器、主频3.50GHz、64G 内存和一块Nvidia GeForce GTX 1080Ti 显卡,显存8GB 的计算机上进行的。
4.1 语义信息关联评估
由于目前语义分割模型的分割准确率达不到百分之百,部分物体可能会识别错误。或由于在数据采集过程中,某一时刻相机视角中物体重叠或光照影响,导致相机某一帧分割错误。如图2(b)中所示,语义分割模型将窗帘的某一部分错误的识别为人,将桌子的一部分错误的识别为柜子。如果不加以处理,直接与深度图像进行数据关联,就会产生错误数据,如图3(a)中所示,在建图时则会将错误的语义数据融合到地图中。

图2 语义分割结果

图3 语义点云对比
图2(c)为后续相机帧的正确识别结果,通过本文的方法,可以将窗帘和桌子识别错误的部分去除,只将正确的语义数据关联到点云中,如图3(b)所示。由于语义分割识别错误导致去除的环境信息将在后续相机帧中补充融合,结果如图3(c)所示,窗帘和桌子均完整准确的融合到地图中。直接使用Panoptic-DeepLab 的分割结果构建的地图如图4(b)所示,可以看到,存在多处错误的语义关联,本文方法所构建地图如图4(c)所示,可以看到,语义数据关联更加准确,去除了大多数错误分割数据。

图4 语义地图对比
4.2 语义地图构建评估
如图5 所示,(a)为ScanNet 数据集中场景scene0000_01,(b)为场景scene0000_01 的三维地图语义标注,(c)为本文的方法所构建的语义地图,深度图像转为点云数据后进行了体素降采样,降采样阈值为5cm。

图5 场景scene0000_01三维语义地图
由于目前没有可行的方法从量化角度对地图数据进行对比,因此在图6 和图7 中分别从多个角度将本文方法所构建地图与数据集中所标注的语义地图进行细节之处的对比。本文方法所标注语义类别颜色与数据集中所使用语义类别颜色不同。

图6 scene0000_01局部对比1

图7 scene0000_01局部对比2
如图6 所示,(a)、(b)为场景scene0000_01 中局部细节,(a1)、(b1)为数据集中对场景scene0000_01 标注的语义地图,(a2)、(b2)为本文方法所构建的语义地图。对比(a1)与(a2),(a1)对场景中的吉他、垃圾桶与厨房用具没有进行语义区分,而本文方法所构建地图中对垃圾桶与厨房用具均准确标注,由于所使用的语义分割模型没有将吉他识别,所以地图中缺少对吉他的标注,这个问题需要后期对分割模型进行优化。对比图(b1)与(b2),(b1)中的对桌子、书包与储物筐没有进行语义区分,而本文方法均进行了准确的标注。
如图7 所示,(c)、(d)为场景scene0000_01 中剩余细节,(c1)、(d1)为数据集中标注的语义地图,(c2)、(d2)为本文方法所构建的语义地图。通过对比可以看出,(c1)中虽然识别出墙上的钟表,但边界模糊,基本丢失几何信息,而本文方法构建结果要更加精确。(d1)中没有标注书柜中的书籍信息,而本文方法准确识别、分割出书籍信息,并融合到地图中。
5 结语
本文提出了一个使用RGB-D 数据进行三维语义地图构建的方法。相机中RGB 图像经过语义分割模型后得到其中物体的语义数据,通过前后帧关联将错误数据滤除,提高语义关联鲁棒性;与深度图像进行数据关联生成带有语义信息的点云数据,结合语义类别权重增量融合构建完整的三维语义地图,可用于机器人的导航和规划任务。综上所述,本文所提出方法具有较高的实用价值。
