基于Flink 框架的K-means 算法优化及并行计算策略∗
2024-01-23李召鑫孟祥印肖世德胡锴沣赖焕杰
李召鑫 孟祥印 肖世德 胡锴沣 赖焕杰
(西南交通大学机械工程学院 成都 610031)
1 引言
进入到新世纪以来,伴随着科学技术的飞速发展,在各个领域每时每刻都在产生成千上万的数据,如何能高效地从这些海量数据中提取出有应用价值的信息已成为当前的研究热点。K-means 是数据挖掘技术中解决海量数据聚类问题的经典算法[1],因其存在执行快速、易于并行化等优点故在许多领域都得到了广泛的应用。但同时存在一些不足:需指定聚类中心数;初始聚类中心的选取策略是完全随机,这可能会影响到最终聚类结果的准确率及计算速度。这两种缺点严重限制了K-means算法聚类效果和计算效率的提高。
针对传统K-means算法存在的不足,许多研究人员都提出了各种改进算法,主要是对于聚类中心数的确定及聚类中心的选择策略的优化。杜佳颖等[2]提出了一种基于K-means++算法优化初始中心点选择的改进算法,通过计算平均轮廓系数来指定K 值,该算法有效提高了计算效率;李淋淋等[3]提出了一种基于Spark 平台的SBTICK-means 算法,针对传统K-means算法在大规模数据计算时存在的瓶颈,引入Canopy 算法和三角形不等式定理,显著提高了聚类结果速度及准确率,并具有良好的扩展性;梁彦[4]提出了一种基于Spark 平台的并行K-means算法和Canopy K-means算法,该算法并行化后具有较好的聚类效果,相比于Hadoop 平台,具有更高的效率;许明杰等[5]提出一种Spark 并行化的PSOK-means 算法,将PSO 算法与K-means 算法相结合,利用改进后的PSO 算法提高K-means的全局搜索能力,并在Spark框架上进行了实现,通过疾病检测数据进行聚类实验来验证所提出算法的效率;王义武等[6]提出了一种OCC K-means 算法,采用最大最小距离算法和UPGMA 来筛选初始中心,并基于Spark 框架进行实现,有效提高了聚类精度及和计算速度。王美琪等[7]提出一种APMMD 算法,通过近邻传播算法获取候选中心点,然后利用最大最小距离算法再选取k 个初始中心点,该算法有效减少了迭代次数。
Apache Flink[8~11]是近年来新兴的一个大数据处理框架,与Hadoop不同,Flink是一个集批处理和流处理于一体的计算框架,具有同时支持高吞吐、低延迟、高性能的优点,现在的绝大部分聚类算法并行化研究大都基于批处理框架,如Hadoop、Spark[12~13]等,而基于Flink 实现的聚类算法研究较少。基于以上预研究,本文综合上述聚类优化算法的优点,充分利用Flink框架在计算方面的优势,提出一种基于Flink 框架对K-means 优化算法进行并行化加速的方案,有效提升了K-means算法的聚类速度。
2 相关理论和技术
2.1 K-means算法
K-means 算法[14](又称为K-均值算法)是Mac-Queen在1967年提出的一种基于划分的聚类算法,因其算法思想简单且易于实现被广泛应用于数据挖掘领域。该算法的作用将数据集S中的n个点划分到K 个类中,具体操作步骤如下:先从数据集S中随机抽取K 个点作为初始聚类中心C(C1,C2,…,Ck),然后计算数据集中每个样本点X 到每个聚类中心的距离(一般采用欧式距离[15]式(1)作为度量)。
其中:d 表示两个样本点间的距离,n 为数据集的维度数量。
以此作为分类依据,按照最近距离公式将数据集中的各个样本点X 分配给距离最近的聚类中心C(C1,C2,…,Ck),随即更新每个聚类中心的值,设为其类别所有样本的平均值,这个过程会不断迭代直到达到迭代次数或聚类算法的误差达到设定的阈值。
在聚类算法中,我们通常使用SSE(The sum of squares due to error)即误差平方和来表示聚类的误差大小,根据此值的大小来决定迭代是否结束。其公式如下:
其中:K 为聚类类别数,X 为数据集中的一个数据点,p为一个聚类中心。
2.2 Aphche Flink
Flink是Apache基金会旗下的一个开源的分布式计算框架,可同时支持流处理和批数据处理。Flink 和Spark 在架构上有一定的相似性,都是基于Master-Slave 架构,并且支持内存计算。Flink 的数据流执行图包含以下三个阶段(如图1 所示):Source、Transformation 和Sink。其中,Source 阶段的作用是用来加载数据集,Transformation阶段的作用是利用各种算子对数据流进行相应处理,主要包括map、flatMap、keyBy、reduce 等算子,Source 和Transformation 的并行度可以通过setParallelism 函数进行自定义设置。Sink 阶段负责数据处理结果的输出,其并行度为1。
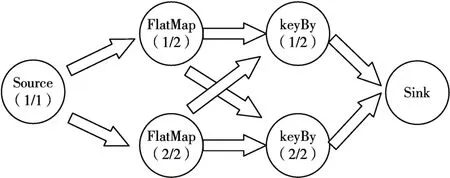
图1 Flink框架工作架构图
3 基于Flink 的K-means 算法优化策略
3.1 聚类类别K值的确定
K-means 算法需要指定聚类类别数K,K 的取值将直接影响到最终的聚类结果及准确率,所以预先得到合适的K 值显得尤为重要。Canopy 算法[16]是McCallum 在2000 年提出的一种聚类算法,该算法目的是将整个数据集粗略地划分为不同的类别,优点是不用预先设定K值就可以完成粗聚类,因此可用于K-means聚类之前,将粗聚类结果的结果作为K-means 的参照,避免了K 值选择的盲目性,从而提高聚类速度。其流程如图2所示。
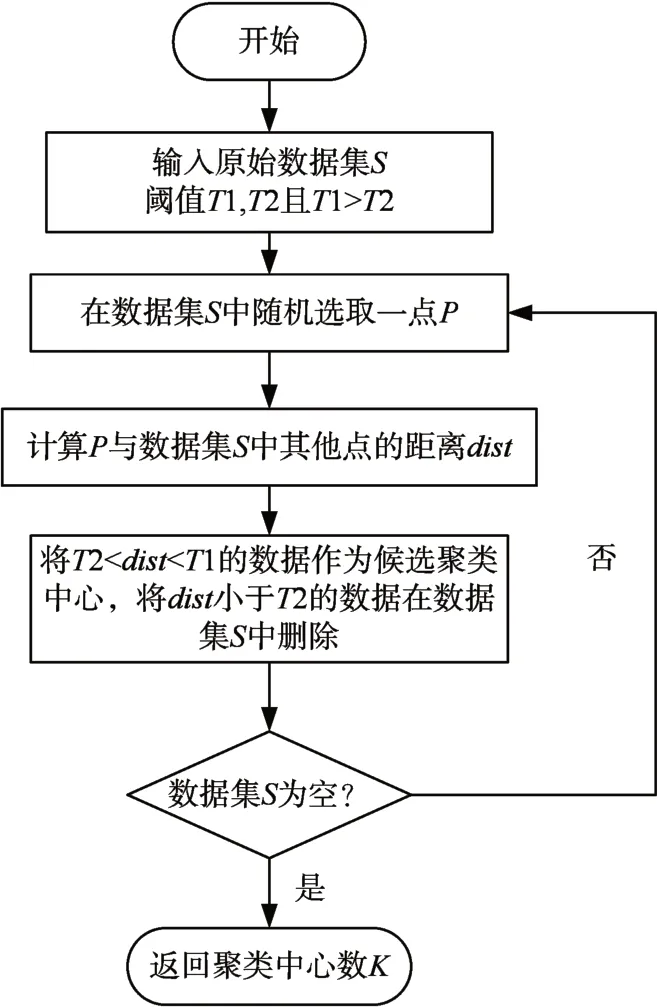
图2 Canopy算法确定K值流程图
3.2 初始聚类中心的确定
初始聚类中心的理想状态是分布尽量分散,这样可以降低聚类结果陷入局部最优的概率,而且可以提高计算效率。本文关于聚类中心的指定是基于最大距离算法进行实现的,其基本思想如下,先输入数据集和类别数量K,然后随机选取一个数据点作为聚类中心,在选取剩下的K-1 个聚类中心时,通过比较数据集中的数据与已被选取的聚类中心的距离来找到最大距离dmax所对应的数据点,然后将该点加入聚类中心,最终得到所有的聚类中心。这种方法可以解决K-means 算法随机选取聚类中心时聚类中心过于邻近的问题,从而减少迭代次数,有效提高算法效率。算法流程如图3所示。
土地深松作业效果显著。从2011年开始,河南省农机深松整地工作由点到面,稳步推进。目前,全省累计开展农机深松整地8300多万亩,其中安排作业补助资金近7亿元,累计补助作业面积2700余万亩。各地农机部门在技术模式、保障手段、监督管理等方面开展了有益探索。通过示范带动,调动了广大农民的土地深松积极性;通过技术培训,培养了一大批掌握农机深松整地作业技术、带头实施深松作业的农机人员;经过试验研究,建立了适应河南土壤特点、种植结构的农机深松整地作业技术模式和机具配置模式;根据基层实际,探索总结了组织作业、面积确认、质量管控和资金兑付的行之有效的工作措施。
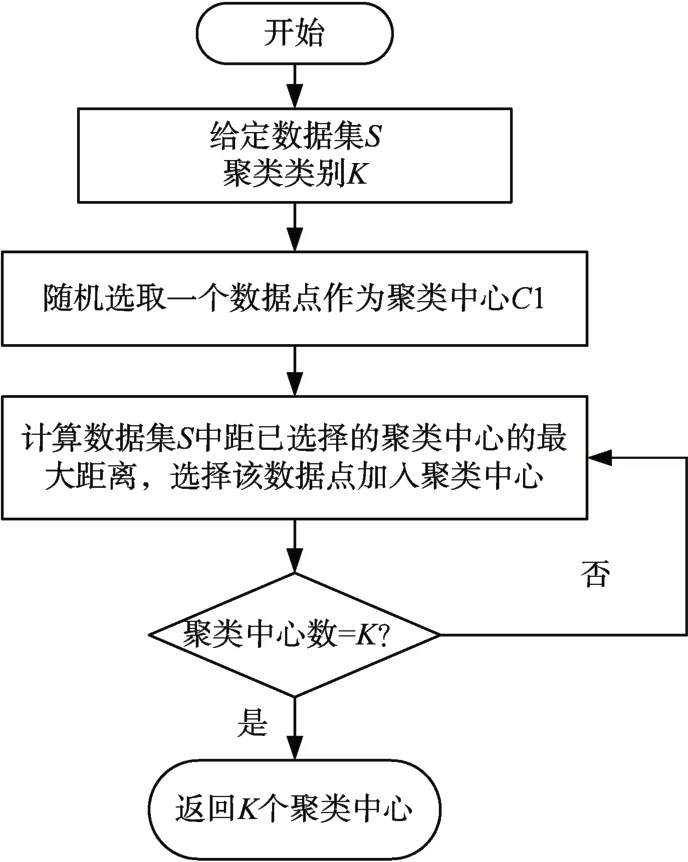
图3 最大距离算法确定聚类中心流程图
3.3 基于Flink的K-means优化算法并行化实现
Flink 计算框架本身支持并行计算,其并行度指的是同时运行的线程的个数,通常一个Flink 程序由多个任务组成,这根据用户设定的分组及并行度来确定。Flink 集群中的每个TaskManager 都包括多个slot,每个TaskManager 所拥有的slot 数量代表了该TaskManager 具有的并发执行能力,此参数可以通过taskmanager.numberOfTaskSlots 参数来进行设置,通常与该节点CPU 可用核数成正比。Flink 在某些条件下可以减少节点之间通信的开销,是基于一种叫做任务链的技术来进行实现的,当多个算子设置了相同的并行度,而且是one to one 操作,这样相连的算子可以链接在一起形成一个task,算子之间通过本地转发(local forward)进行连接,其逻辑视图、并行化视图、优化后视图如图4所示。

图4 Flink任务链示意图
本文算法所采取并行化策略如下,首先,在JobManager节点获取到数据集之后,将其广播到每个TaskManager 节点,采用最大距离算法逐次选取K 个初始聚类中心,再通过withBroadcastSet 函数将初始聚类中心的信息广播到各个TaskManager 节点,在节点上迭代执行K-means 算法,最后根据设置的迭代次数或者损失函数SSE 来判断是否结束聚类过程。Flink 程序分为Source、Transformation、Sink三个阶段,其中Source和Transformation阶段是可以实现并行化的,通过并行化来减少数据加载及数据计算的过程,从而提高Flink 程序整体的运行速度。JobManager主节点的作用是获取数据集,并通过广播分发至每个TaskManager,然后TaskManager迭代计算聚类中心到数据集中每个点的距离,将每一个数据点都归类到一个类别,最后将计算结果返回给JobManager,完成聚类结果的输出。
4 实验环境与结果分析
4.1 实验环境与数据集
本文实验平台采用开源Flink 分布式框架,分别安装在5 台虚拟机上,由一台JobManager 和4 台TaskManager 组成。每一台机器的配置都是:内存2GB,硬盘20G,操作系统均为Centos 7.4。每一台机器的软件环境如表1所示。
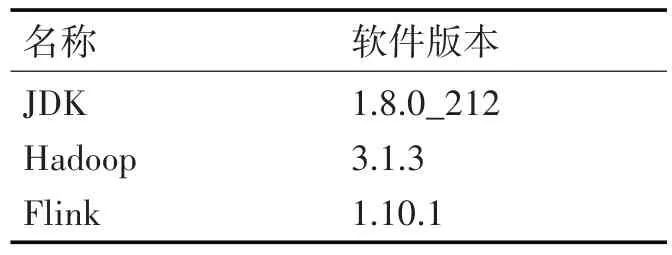
表1 集群主要软件环境详情
本文实验采用的数据集是从加州大学UCI 实验室提供的机器学习数据库中下载的iris、glass 和wine数据集,数据集详情如表2所示。
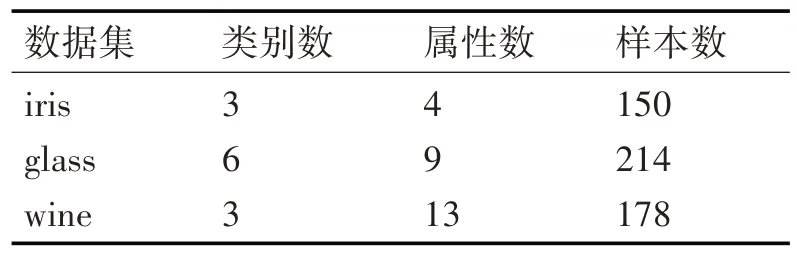
表2 数据集相关信息
4.2 实验结果分析
4.2.1 准确率实验
为了对比传统K-means 算法和本文算法的准确率,本文通过对3 个不同属性的数据集进行聚类测试(对每种算法进行20 次随机实验取平均值),并统计聚类效果,聚类结果如表3 和表4 所示。从表3 和表4 可以看出,本文改进算法在求解iris、glass 和wine 数据集时相比传统K-means 算法的准确率都有一定的提升,这表明本文基于Canopy 算法和最大距离算法的K-means 优化算法减少了聚类过程的迭代次数,对计算效率有一定的提升。

表3 K-means算法与本文改进算法准确率对比

表4 K-means算法与本文改进算法迭代次数对比
加速比是衡量并行化程序性能好坏的重要指标,该指标指的是同一个计算任务在单机环境和并行环境运行消耗时间的比值,一般来说,加速比的值越大,代表算法并行加速的性能越好。为了测试本文算法在Flink 框架下的并行化能力,本文采用了synthetic_control数据集来进行实验验证,该数据集含有600 个样本点,因为原数据集数据量较少,所以本文对原数据集进行了扩展,分别生成了含有3×10^5、3×10^6 和3×10^7 个样本点的数据集,测试了不同节点数的加速比,实验结果如图5所示。
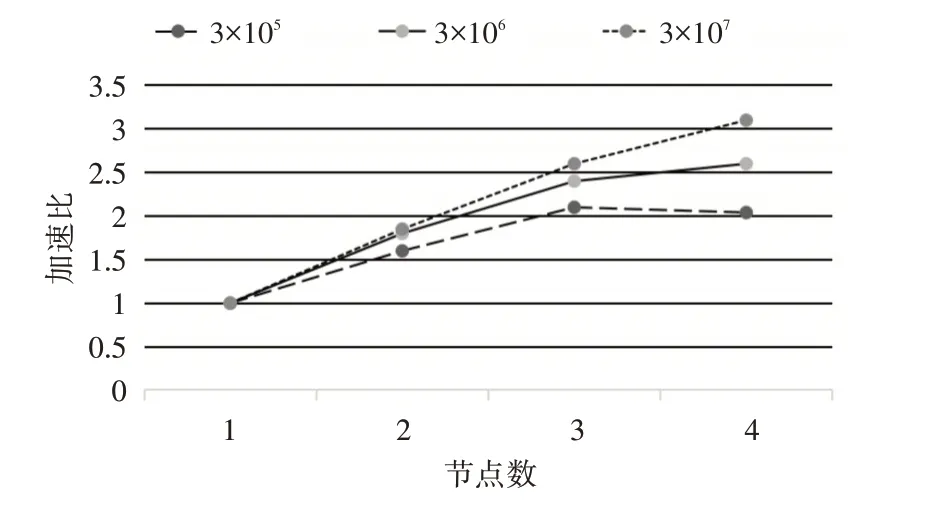
图5 基于Flink框架的改进K-means算法的加速比
由图5 可以看出,当数据量比较小时,随着节点数的增加,加速比折线趋于平缓,因为当数据集的规模较小时,计算时间比较短,如果节点数增加到一定数量后,会使得节点间的数据传输和任务调度等其他方面的时间开销变大,进而降低算法效率。相反,当数据集达到一定规模后,加速比与节点数近似呈线性关系,实验可以表明本文算法在处理大规模的数据时具有较高的计算效率。
5 结语
本文针对传统K-means 算法在处理海量数据的过程中在选取初始聚类中心时存在的易陷入局部最优解和计算速度较慢等问题,提出一种基于Flink 框架并行化的K-means 优化算法。该算法采取Canopy 算法来计算K-means 算法输入所必需的K 值,并利用最大距离算法优化初始聚类中心的选择,最后,基于Flink并行计算框架进行实现。实验结果表明,相比原算法,本文算法在聚类准确率和计算效率方面都有一定程度的提升,并且验证了在大规模数据背景下并行化实现的高效性。
