面向Kubernetes 的容器混合伸缩方法∗
2024-01-23柳雪妍蔡志成
柳雪妍 蔡志成 徐 建
(南京理工大学计算机科学与工程学院 南京 210094)
1 引言
云计算的弹性伸缩能力,使得用户可以按需地从云计算资源池中获取或释放计算资源[1],并且仅需为所使用部分付费,大幅度降低了企业的成本,同时还满足用户快速部署微服务应用的需求。因此,越来越多的互联网企业将它们的微服务迁移到云数据中心中。然而,在实际应用中,为了应对实时波动的微服务请求负载,大多数用户采用预先给应用分配过量资源的方法,造成了大量的资源浪费和高昂的成本开销[1]。针对微服务系统负载动态变化的特点,设计并实现高效的云计算资源调度算法,自动增加或减少分配给应用的资源,从而在保证用户服务水平协议(SLA)的前提下,最小化云计算资源的成本,一直是云计算领域的关键问题和严峻挑战。
传统的云计算架构以虚拟机为基本单元进行资源调度,这种大粒度的资源调度存在资源利用率低、虚拟机启停缓慢等问题[4]。容器技术的出现,引发了云计算资源管理的新革命[1]。相较于虚拟机架构,容器云采用轻量级虚拟化技术,可以快速创建容器和部署应用[3]。以容器为单位进行资源分配和调度,降低了由虚拟机启动缓慢而导致的资源调度延迟,进一步提高了云计算平台的性能[2]。
目前,研究人员已提出大量基于虚拟机的动态资源调度算法。Chenhao Q对现有的云环境中虚拟机的动态调度算法进行了较为全面的分析和总结[1]。其中,基于规则的自动伸缩方法被工业界广泛采用,例如亚马逊的Amazon Auto-Scaling Service[5]。但是这种基于规则的自动伸缩方法缺乏对资源性能的准确估计,需要充分掌握应用的特征及专家知识以确定适当的阈值和操作。为了准确估计所需的资源能力,学术界基于排队理论建立了各种性能模型,例如李磊提出一种基于李雅普诺夫队列模型的任务和资源调度优化策略[2],Cai 采用具有到达率调节系数的排队模型作为前馈控制器以预测所需资源量[6]。另一部分研究者利用机器学习技术,动态构建特定负载下的资源消耗模型,例如Bitsakos C 使用深度强化学习来实现资源的自动伸缩[7],徐建中等使用反向传播神经网络建立一个基于需求预测的云计算弹性伸缩策略[8]。
然而,针对容器云的调度算法研究才刚刚起步。由于基于虚拟机的资源调度和基于容器的资源调度的核心需求是相似的,研究人员通常将基于虚拟机的弹性伸缩算法直接用于基于容器的系统。例如,杨茂等提出一种预测式与响应式相结合的水平伸缩算法[9],屠雪真等设计了一种基于Kubernetes的水平弹性扩缩容系统[10]。这类方法虽然简单快速,但未考虑到容器本身配置的调整,仅考虑了容器的水平扩展,忽略了容器的垂直扩展。这类方法难以设置恰当的容器资源配额,导致集群资源的浪费[11]。
因此,针对已有研究存在的不足,本文针对基于Kubernetes 的真实异构容器云环境,提出了一种基于排队、深度性能模型和快速启发式规则的容器资源混合伸缩算法MMHV。对比实验表明,本算法能够在保证微服务请求服务质量的前提下,使得容器资源配额随工作负载变化而动态调整,从而提高异构集群的资源利用率、有效降低云计算资源的成本。
2 Kubernetes容器云
Kubernetes[11]是Google开源的一个大型容器集群管理系统。其作为容器云的核心基础和事实标准,已经成为当今互联网企业的云基础设施核心要素。它可以为容器化的云原生应用提供部署、运行、服务发现、资源调度、扩缩容等功能。
如图1 所示,Kubernetes 集群由一个Master 和多个Node 组成。Master 是集群的控制节点,其上运行着Kubernetes API Server 等集群管理相关的关键进程。这些进程实现了整个集群的资源管理、Pod 调度、系统监控和纠错等自动化管理功能[12]。Node 是集群中的工作节点,其上运行着多个Pod,每个Pod 中运行着一个应用程序的一组(一个或多个)容器,一般场景中,每个Pod 只包含一个容器。Kubernetes 直接管理Pod 而非容器,Pod 是Kubernetes 中资源调度的基本单位。同一微服务的用户请求被Nginx Ingress Controller 分发到并行容器中。资源控制中心可以通过Kubernetes 提供的客户端接口采集集群的运行数据,实现应用性能的实时监控,并根据资源调度方法动态调整分配给应用的资源。
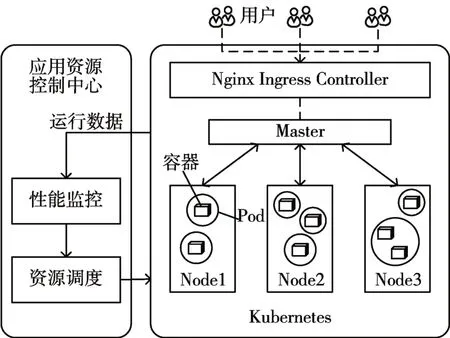
图1 Kubernetes中容器云的架构图
本文的目标是针对基于Kubernetes 的真实容器云环境,设计容器数量和配置自动伸缩算法,在保证满足用户请求响应时间上限约束(由SLA 指定)的同时,降低微服务的资源成本。
3 水平自动伸缩机制
Kubernetes 已有的水平自动伸缩控制器(HPA),可基于CPU 利用率实现Pod 数量的自动伸缩[13]。在使用HPA 时,用户需事先设定CPU 利用率的目标值。在每个控制周期,HPA 控制器根据Pod 的实时CPU 利用率与用户设定目标值的比例计算所需的目标副本数量,具体计算公式如下:
其中,Cr和Cv分别是当前副本数及当前CPU 利用率,Dr和Dv分别是目标副本数及目标CPU 利用率。当Pod 的目标副本数与当前副本数不同时,HPA 就向Pod 的副本控制器发起Scale 操作,调整Pod的副本数量,完成扩缩容操作。
尽管HPA控制器简单有效,但只是从Pod数量层面进行调整(水平伸缩),在实际应用中还需要对每个Pod 设置恰当的资源配额(CPU 和内存的大小),资源配额过大将导致集群资源的无谓浪费,过小则会导致应用性能不佳。然而,用户需要对应用程序有足够了解,并进行大量配置和试验,才能对Pod设置恰当的资源配额。
4 容器云混合伸缩算法
针对HPA 按CPU 利用率比例调整方法的不足,本文提出的MMHV 采用排队模型更加准确地描述目标响应时间和所需总处理能力之间的关系;同时利用深度神经网络建立高精度的单个容器处理能力和不同配置的关系模型;基于排队模型获得所需的总能力和深度性能模型,MMHV根据启发式规则能够更加快速准确地找到恰当的副本数量和资源配额,具体包括:1)基于M/M/1 排队模型和给定的服务响应时间约束计算当前负载下的目标总处理率;2)以真实的异构容器云的运行数据为基础,使用深度神经网络建立容器资源配置(CPU 和内存的大小)与请求处理率的关系模型;3)基于集群中异构虚拟机上剩余CPU和内存的大小,采用基于排序和二分搜索相结合的容器资源配置快速搜索方法,获得使处理率不小于目标值且成本最小的容器资源配置方案。
4.1 容器云排队模型
如文献[1]所述,对于单个微服务,可以将其用户请求处理过程抽象为一个排队模型。如图2 所示,一个微服务有n 个并发Pod。随机到达的用户请求进入Nginx负载均衡器维护的共享队列,Nginx以轮询的方式将请求转发给Pod进行处理。
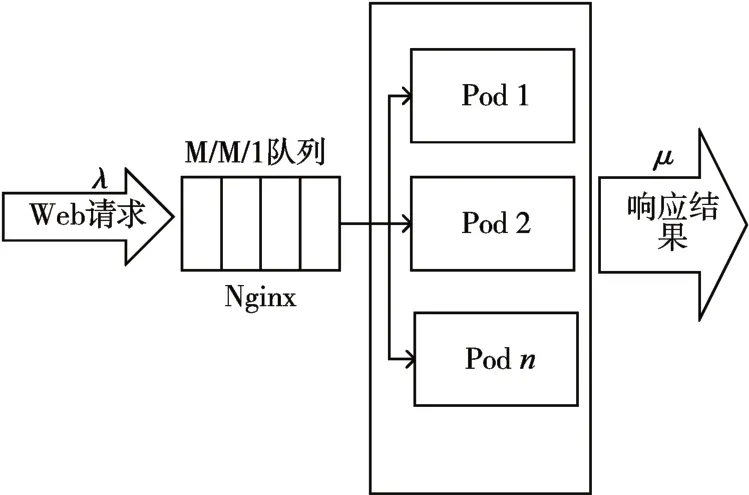
图2 用户请求排队模型
假设微服务的用户请求到达率为λ且时间间隔服从负指数分布,同时所有Pod 的请求处理率之和为μ且请求处理时间也服从负指数分布,则可以使用单队列等待制M/M/1排队模型建模。根据Little公式,可得到请求的平均响应时间[14]:
4.2 基于深度神经网络的性能模型
通过观察采集的样本数据,我们发现CPU、内存的资源量与请求处理率之间是一种非线性关系,因此我们选择了一种简单高效的非线性回归模型MLP(多层感知器)进行建模。MLP[15]是一种监督学习算法,它通过训练数据集学习一个函数f(∙):Rm→Ro,其中m 是输入的维数,o 是输出的维数。给定一组特征X=x1,x2,…,xm和一个目标y,它可以准确高效地逼近非线性函数。具体步骤如下:1)将一个微服务以容器的形式部署在Kubernetes 集群中;2)对运行微服务的Pod 分配不同的CPU 和内存(c,m),使用压力测试工具发送并发请求,并采集请求响应时间数据,进而得到当前资源配置(c,m)对应的请求处理率μ;3)使用深度神经网络构建性能回归模型,以CPU和内存的资源配置(c,m)作为二维的输入特征,以请求处理率μ作为目标输出,构建一个具有两层隐藏层、每层含有100 个神经元的深度神经网络,并按照80%和20%的比例将样本数据划分为训练集和测试集。图3 是我们实验中训练得到的模型,其在测试集上取得了0.985 的分数(分数越接近1 说明模型的拟合精度越高)。将CPU 和内存的资源配置(c,m)输入训练好的网络模型f(c,m),即可获得对应的请求处理率μ。

图3 训练得到的性能模型
4.3 异构环境感知的混合伸缩算法
基于上述排队模型和容器性能模型,本文提出一种异构环境感知的容器资源混合伸缩方法MMHV,正式描述如算法1所示。
首先,在每个控制时刻t,通过采集集群的运行数据获得集群中各个Node 节点i 上的可用资源量(ci,mi)、当前时刻t的请求到达率λt,以及请求的平均响应时间yt。如果yt>WSLA,说明资源配置不足需要增加资源;如果λt相较于上一次资源调整时的请求率λs下降超过10%,说明资源配置比较充足,可以减少资源。上述两种情况均会触发资源调整动作。
为了确定适当的资源配置方案,首先基于公式(3)计算出t时刻的目标处理率μo。接着将各节点i 的可用资源量(ci,mi)以CPU 的大小递增排序。令Pod 副本数r 从1 开始递增,且对于每一种情况,遍历各节点的可用资源量(ci,mi),将其输入训练好的深度性能模型f(c,m)→μ得到该配置方案对应的处理率μ,直到找到大于或等于目标处理率μo的配置方案(c',m')。若μ恰好 等于μo,计算该配置方案的成本,并将其与最小成本Costmin比较。若μ大于μo,此时虽然可以满足SLA,但资源可能存在冗余,因此令l=(0,0),ℎ=(c',m'),m=(l+ℎ)/2,以二分法搜索恰好使得μ大于μo的配置方案直到(ℎ-l)小于资源的最小调整量d,此时的Pod 资源请求量组合(c*,m*)及Pod 副本数r*即为最佳配置方案。最后,利用Kubernetes 的客户端接口调整Pod 的副本数及CPU 和内存的大小,完成资源调度。
算法1:异构环境感知的容器混合伸缩算法MMHV
5 实验验证
我们在真实的Kubernetes 集群上验证所提出的容器混合伸缩方法的性能,并与已有算法进行了对比。
5.1 实验环境与参数设置
本实验使用两台配置为Intel® Xeon® Silver 4210 40 核心CPU 和48GB 内存的服务器搭建了一个Kubernetes 集群,集群由5 台虚拟机组成:1 台具有4 核CPU、4GB 内存的Master 节点,2 台具有4 核CPU、4GB 内存的Node 节点,其余2 台为具有8 核CPU、4GB内存的Node节点。将一个计算序列累加值和集合查找的微服务应用以容器的形式部署在集群上,并使用JMeter 作为压力测试工具发送请求。
实验通过重放WikiBench 提供的用户访问维基百科的历史流量数据[16]进行压力测试。并设响应时间上限为WSLA=0.1s。实验参考阿里云通用型ecs.g6.large实例按量付费的定价,根据官方文档可计算得出CPU 的单价为每小时0.14 元/核,内存的单价为每小时0.0275 元/Gi。调度算法的控制时间间隔为300s。
5.2 实验结果与分析
本文从请求响应时间和资源成本两方面将MMHV 算法与HPA 算法[13]以及同样使用了M/M/1排队模型的UCM算法[6]进行了对比。
图4、图5、图6 分别显示了HPA 算法、UCM 算法和MMHV 算法的响应时间分布情况。可以看出,三种算法的大多数响应时间都小于WSLA,其中HPA 算法的响应时间波动性最小,MMHV 算法次之,UCM 算法波动性最大。这是由于UCM 算法以虚拟机为基本单位进行资源调度,在调度时刻虚拟机创建和启动延迟导致请求响应时间波动和SLA违反率变大,而HPA 算法和MMHV 算法以容器为单位进行调度,可以快速地创建启动容器完成资源调整动作,减少响应时间的波动及SLA违反率。
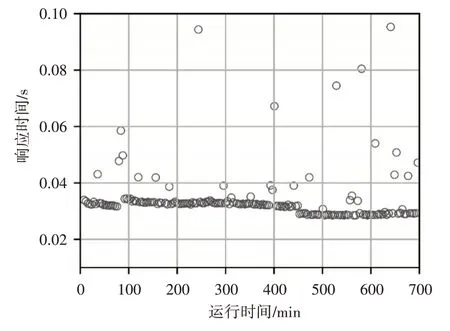
图4 HPA算法响应时间分布
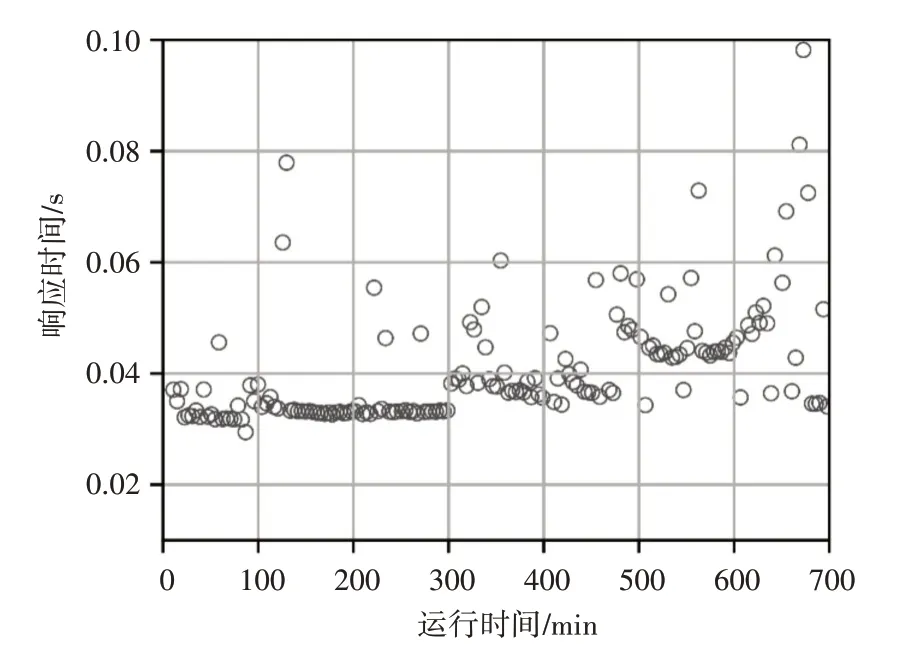
图5 UCM算法响应时间分布
图7 显示了三种算法的累计资源成本随时间的变化曲线,可以看出在相同的负载下,MMHV 算法所需的资源成本最低。UCM 算法以虚拟机为单位进行租赁,在某台虚拟机的利用率较低但又不能直接关闭的情况下,仍然需要为它付费,这种大粒度的租用方式必然导致资源成本最高。而HPA 和MMHV按照资源的使用量计费,因此它们消耗的资源成本相对较低。与HPA 算法动态调整Pod 的数量相比,MMHA 由于可以更加细粒度地调整Pod 的资源配额,使得容器资源供应量更加接近资源需求量,减少了不必要的资源开销,因此资源消耗成本最低。
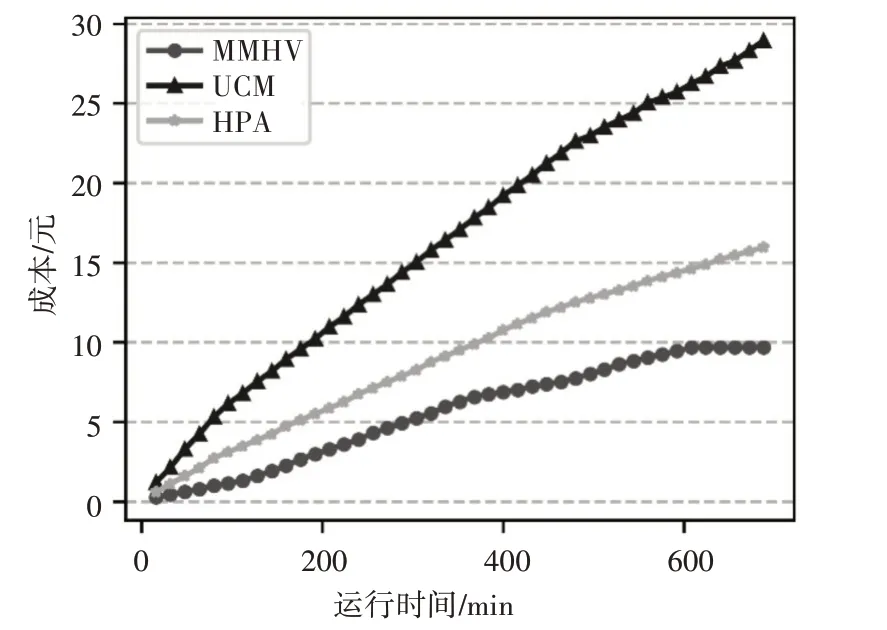
图7 三种算法资源成本对比
6 结语
已有的容器调度算法大多只在容器数量上水平伸缩,这种方法没有考虑底层物理资源的剩余情况,难以设置恰当的容器资源配额,导致集群资源的浪费。针对上述问题,本文提出了一种面向Kubernetes 的容器混合伸缩方法,该方法采用排队模型计算应用所需的处理能力,以基于深度神经网络的容器性能模型为基础,将处理能力映射为具体的容器混合伸缩配置方案。基于Kubernetes 集群上的实验结果表明,在保证服务水平协议(SLA)的前提下,该方法相较于Kubernetes 自带方法和其他方法资源消耗成本最低。
