基于自适应记忆长度的多尺度模态融合网络
2024-01-20李晓航周建江
李晓航,周建江
南京航空航天大学 雷达成像与微波光子技术教育部重点实验室,南京 211100
不论是道路交通管理还是机场航路交通管理,自动驾驶的技术都会为智能交通和自主决策带来革命性变革。在道路/航路交通环境中,传感器通过实时感知道路/航路、车辆/飞机或者行人等的状况,通过路径规划提高行驶效率,减少人为操作失误带来的风险。在民航领域,智能驾驶技术可以有效提升机场飞机的转运效率,尤其是大型民用机场,智能驾驶技术可以应对更复杂机场航路状况,降低安全风险,提高航班正点率。
近年来,随着地面道路和空中航线越来越复杂,以及任务的多元化,单一传感器已经逐渐无法适应决策和操作的需求,因此融合多传感器技术备受瞩目。点云和光学图像能够为环境感知提供互补信息。点云由大量的三维点集构成,描述物体的空间立体结构;而图像则能够提供出色的色彩饱和度和细节纹理信息。因此,融合这2 种模态的特征,能够更准确地掌握环境状况,提高自主决策和路径规划的能力[1]。
为了融合不同类别的特征,多模态网络需要使用一种或多种语义分割模型。DeepLab 系列[2-4]是点云语义分割的经典网络,采用编码-解码架构逐步恢复空间信息以捕捉清晰的目标边界。该网络首次提出空洞卷积的概念,并使用Atrous Spatial Pyramid Pooling(ASPP)的多膨胀率支路捕获多尺度信息,从而有效增强网络读取上下文的能力。SalsaNext[5]也是基于编码-解码结构,由多个残差块、dropout 层和池化层构成编码器,并使用像素拖拽层代替了SalsaNet[6]中的转置卷积完成上采样。点云和图像特征形式的不同使它们难以直接在同一网络下训练,因此需要特殊的方法来提取和融合这2 种数据的特征。FusionNet[7]是一种有名的双模态网络结构,以光学图像为导向辅助点云完成深度补全,并对局部信息和全局信息加权求和。但该网络有多处交叉相融导致数据重复计算,对于大尺度和高分辨率数据特征,模型的内存消耗较大。Laser-Net++[8]分别使用独立的CNN 网络训练点云和图像,融合由CNN 提取的特征,并传递到Laser-Net 中,实现网络端到端的训练。TITAN-Net[9]将4 个神经网络模块化,分阶段处理单模态和多模态特征,将点云语义特征转化为图像语义特征,通过生成式网络融合点云和图像的初级分割结果。这些流行的多模态融合网络直接将光学图像特征合并到点云特征上,或在解码器后将分割结果简单地中和,没有将两模态的互补优势融合在网络训练中。即使在训练中融合了多模态特征,也往往需要较复杂的网络结构,繁琐的交叉融合导致信息重复计算,增加网络复杂度。因此,需要设计一种简单的多模态融合模型,减少数据的重复计算,并通过分析模态特征优势设计高效的融合模块。
对于网络参数的更新和计算,经典的优化算法是随机梯度下降法(Stochastic Gradient Descent,SGD)[10],通过迭代优化,以逐渐逼近或最小化损失函数。但是在下降过程中会遇到山谷震荡和鞍点停滞的问题。为了解决这些问题,Adaptive Moment Estimation(Adam)算法[11]利用惯性保持和环境感知,自适应调整学习率,同时在一阶矩估计和二阶矩估计中采用指数衰减平均计算累积梯度和累积平方梯度,并利用融合滑动窗口求平均的思想衰减不同时间长度下的贡献。AdamBound 算法[12]使用自适应上限约束学习率,抑制了不稳定和异常的学习率。Adam-Mod 算法[13]增加了一个新的超参数来度量记忆的长短,逐元素削减学习率,避免出现高学习率。但是在这些算法中,对时间记忆的把控是基于同一窗口长度,没有考虑到不同梯度更新幅度下对窗口长度的需求可能不同,因此需要考虑不同梯度更新幅度下对窗口长度的需求,以进一步提高算法的精度。
语义分割任务要求对像素级别的准确分类,可以实时生成具有语义信息的地面和空中视角的标签表示,通常需要使用多种损失函数来优化网络参数。交叉熵损失[14]是最常用的损失函数之一,它能够逐个比对每个像素点并得出平均损失值。平衡交叉熵[15]和Focal Loss[16]是在交叉熵损失的基础上发展而来,分别解决了数据集中类别不平衡和难易样本不平衡的问题。虽然这些损失函数已经被广泛应用于实际网络训练中,但在多模态网络中,损失函数通常只针对某个模态支路单独使用,对不同模态下的损失进行简单求和,无法充分利用不同模态之间的互补优势。因此,在多模态网络中,需要设计新的损失函数,以有效整合不同模态的信息。
针对上述问题,提出了一种双模态语义分割网络,将光学图像与点云特征相融合。首先,使用SalsaNext 和ResNet34[17]对2 个模态进行并行编码。其次,改进了一种可自适应改变滑动窗口记忆长度的优化器。然后,在不同编码阶段使用残差映射和膨胀点注意力机制的思想多次进行特征加权融合。同时,使用多尺度的密集像素采集模块增强上下文联系,并通过瓶颈结构降低模块参数量。最后,提出了一种基于交叉熵损失的协同差异损失函数Differ Loss,能够有效整合不同模态的信息,判别模态间的感知差异,结合Focal Loss 和Lovász-Softmax Loss[18]一起作为网络的总损失值。
1 网络结构和算法介绍
1.1 双模态并行网络结构
本文提出了一种双模态并行编码-解码的语义分割网络(Merge Network,MerNet),旨在融合点云特征和光学图像特征以完成驾驶环境的像素级分类任务。MerNet 的网络结构如图1 所示,由5 部分组成:①主干框架:SalsaNext 是一种相对轻量化的编码器-解码器架构的网络模型,能够实现可靠的语义分割性能。在文献[19]的语义分割任务对比中,ResNet 作为解码器明显表现出比其他解码结构更强的性能,结合对网络计算量的权衡,ResNet34 最适用于本文光学图像的编码任务。因此,本文使用SalsaNext 作为点云特征支路的语义分割主干网络,ResNet34 作为图像特征支路的编码器网路,解码器采用双线性插值进行上采样。② 优化器:Adam 和SGD 都是常用的优化器,SGD 具有简单的实现和更少的计算量,在图像特征的网络训练中优先选择SGD 这种经典优化器。然而点云特征具有更多的噪声影响,融合了图像特征后,点云支路的特征具有高复杂性,Adam 在梯度下降中考虑了惯性保持和环境感知,更适用于点云支路模型。因此,对于点云特征支路,以Adam 优化器为基础,本文提出了一种自适应历史记忆长度的(AdamWin)优化算法,对于图像特征流,则使用经典的随机梯度下降法(SGD)进行优化。③融合模块:在每个编码阶段,将光学图像特征通过融合模块单向映射在点云特征上,得到融合输出作为点云流的下一编码阶段的输入继续编码,从而实现点云和光学图像特征的融合。④ 多尺度上下文模块:在点云流的编码器和解码器之间提出了一种多膨胀尺度密集点云采集的上下文模块。⑤ 损失函数:提出了一种基于交叉熵的双模态协同差异损失,通过比对2 种模态在驾驶环境下的感知差异,并结合Focal Loss 和Lovász-Softmax Loss 优化网络参数。
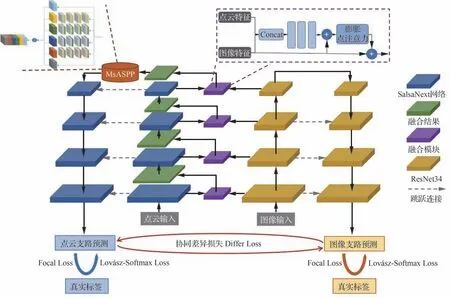
图1 双模态语义分割网络MerNet 的总体网络结构Fig.1 Overall network structure of MerNet,a dual-modal semantic segmentation network
1.2 基于自适应历史记忆长度的AdamWin 优化算法
在神经网络的训练过程中,优化算法寻找模型表征空间中评估指标最优的模型是至关重要的。对于光学图像特征流,本文采用基于迭代计算的SGD 优化算法,使用随机梯度更新权重。SGD 采用随机单个参数损失梯度近似平均梯度的方法,公式为
式中:θ为模型参数;α为学习率;∇L(θ)刻画了参数为θ时模型的损失梯度。SGD 用随机的单个参数损失梯度近似平均损失梯度,公式为
式中:f代表了模型的实际输出;x和y分别代表模型的输入和输出。这种运算可以大大提高收敛速度,在实际训练中,为了提高迭代的稳定性,采用小批量的梯度下降法(Mini-Batch Gradient Descent,MBGD),利用矩阵运算同时处理若干组数据,公式为
式中:m为每个批次中的样本数量,本文训练中设置为4。
Momentum 在SGD 中引入惯性保持的物理概念,解决山谷震荡和鞍点停滞的现象。公式为
式中:vt表示当前时刻的动量;γ表示衰减系数,可以解释为物理概念上的阻力;gt表示第t时间步的梯度。使用动量刻画梯度变化的惯性,震荡方向的梯度可以在累加的过程中因为符号的相反性被抵消,只有损失衰减方向的梯度逐渐累加,从而实现更快且更稳定的收敛。
SGD 算法使用同样的步长更新参数,但不同参数的更新频率不同,对于密集的特征参数,需要减小步幅;对于稀疏的特征参数,需要增大步幅。因此AdaGrad 采用历史梯度平方来优化学习速率的自适应性,衡量不同特征参数的稀疏性。将历史梯度平方作为分母系数自适应调整梯度更新步幅,公式为
式中:ε是为防止分母为零的很小的常数;gk为k时刻的梯度向量;gt的系数由初始设定的α优化为加了历史经验的自适应学习速率。
Adam 优化算法综合了Momentum 和AdaGrad 的思想,使用一阶矩记录梯度的惯性保持特性,使用二阶矩记录环境感知特性,消除梯度震荡对更新造成的隐患并自适应调整更新步幅。历史梯度的累加提供了经验性的判断,但也产生了一定的隐患,累积梯度估计的公式为
累积平方估计的公式为
因此,随着梯度和梯度平方的累加,代入式(6)中的学习速率,分母逐渐增大使得gt的调节作用逐渐衰弱。加持在一阶矩和二阶矩的滑动窗口可以利用衰减系数降低远距离梯度对当前计算的贡献度,公式为
式中:β1和β2分别为累积梯度和累积平方梯度的衰减系数。衰减系数可以看作对一阶矩和二阶矩使用滑动窗口,滑动窗口的大小在整个训练期间取固定时间长度。
图2(a)是损失函数随训练轮数的变化趋势,可以发现,损失函数的下降速度逐渐趋于平缓。图2(b)假设在任意时刻对历史梯度计算采用固定窗口长度L1,这表明在不同的梯度变化趋势下采用同样的记忆时间长度,最近邻时刻的梯度始终在整个衰减过程中呈现出同等价值的贡献。但在实际梯度运算中,由于损失函数变化趋势的不同,gt1-L1对gt1的影响要明显大于gt2-L1对gt2的影响。为了解决不同梯度变化趋势下历史记忆长度对当前梯度的影响,图2(c)在早期损失中取S1点,在晚期损失中取S2点,显然S1点对应的梯度变化更加剧烈,S2点对应的梯度变化比较平缓。分别在这2 点取长度为L1和L2(L1>L2)的2 个滑动窗口。S1由于梯度变化速度快,远距离记忆点的梯度值对当前时刻的贡献更大,S2由于梯度变化速度慢,远距离记忆点对当前时刻的贡献小。因此在当前时刻的梯度计算中,为了更好地调节历史梯度的贡献值,应该随着梯度变化趋缓而增大最近邻时刻的梯度贡献值,同时减小远记忆时刻对当前时刻梯度的影响权重,相当于缩小图2 中滑动窗口的大小。

图2 自适应历史记忆长度随梯度变化趋势的变化Fig.2 Variation of adaptive historical memory length with gradient trend
为了实现这一目标,本文使用了2 个记忆系数来调节滑动窗口的大小,记忆系数对衰减系数的调整公式为
式中:σ1是累积梯度对应对记忆系数;e为网络训练的轮数。累计平方梯度中记忆系数对衰减系数调整的公式为
式中:σ2是累积平方梯度对应对记忆系数。记忆系数σ1和σ2是略小于1 且极度接近1 的值,每进入新的一轮训练衰减系数β除以一个逐渐减小的记忆系数,因此β随着轮数的增加呈现缓慢增大的趋势,等价于逐步增大近邻时刻的梯度权重,衰减远记忆时刻的梯度权重。
点云特征支路的训练使用这种随梯度变化趋势自适应调整历史记忆长度的AdamWin 优化算法,具体计算流程如算法1 所示。其中:t是时刻;θ0是初始参数向量;f(θ)是带参数的随机目标函数;ε是为防止分母为零的常数,取默认值1×10-8;λ表示权重衰减系数;mt是一阶矩;vt是二阶矩。

自适应调整历史记忆长度的优化算法不仅考虑了历史梯度,还考虑了梯度在不同变化趋势下对当前梯度运算的贡献变化。通过引入记忆系数,自适应调整远记忆时刻的贡献权重,使梯度关注贡献值更大的近邻点,避免在变化缓慢时被远距离记忆点分散计算注意力。
1.3 基于膨胀注意力机制和残差映射的融合
在双流网络的并行编码中,特征的语义信息随着编码的降采样逐渐变得粗糙,在编码结束后或预测阶段的后融合结构难以充分将融合特征引入到网络的训练中,因此本文在编码阶段就将图像特征通过融合模块单向融入点云特征流中,使图像的感知优势充分参与点云的训练过程。因此融合模块考虑了不同阶段的语义变化特点,使用残差连接将原始点云输入映射到初步融合结果,再通过膨胀点注意力模块为特征点分配权重。融合模块的结构如图3 所示,其中Clidar和Ccamera分别表示点云和图像特征的通道数;H表示特征高度;W表示特征宽度。
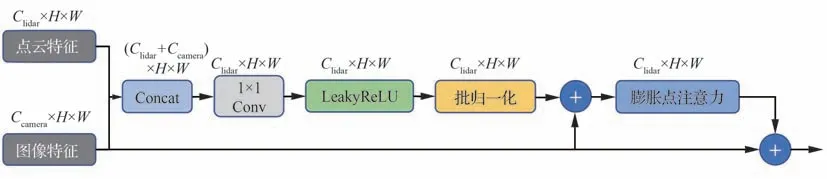
图3 融合模块Fig.3 Fusion module
首先将点云特征和图像特征进行拼接,通过3×3 的卷积使通道数降为点云的通道数,接着使用非线性激活函数LeakyReLU,并进行批归一化。膨胀点注意力模块结构如图4 所示。采用点注意力机制[20]结构,通过2 次3×3 的卷积、批归一化、非线性激活函数ReLU,再通过Sigmoid 进行激活,与输入的特征对应点相乘实现点特征注意力的分配。注意力分配需要判断各特征点的重要性,因此上下文关系有利于判断特征点在附近区域的价值权重。

图4 膨胀点注意力模块Fig.4 Expanding point attention module
由于数据采集视野的开阔性,特征点的判断需要充分考虑邻近特征的信息,因此在点注意模块的2 个3×3 卷积中,为了扩大卷积核的感受野,在保持输入特征尺寸不变的情况下,使用扩张率为2 的膨胀卷积,在卷积核的每2 个元素之间插入一个空洞,使得注意力计算的过程结合更大范围的上下文内容为特征点分配权重。为了充分利用不同语义粗糙程度的图像特征,在网络的4 个编码阶段均使用一次融合模块,完成图像特征单向与点云特征融合,并将融合结果作为点云特征流的下一编码阶段的输入参与点云特征的训练。
1.4 多尺度感受野的上下文模块
感受野是指卷积神经网络中输出层的每一像素点在输入层上的映射区域,小的感受野通常用于描述局部细节信息,而大的感受野则通常用于描述全局信息。为了提高语义信息的上下文感知能力,本文在点云特征支路的编码器之后设计了一种多尺度感受野的上下文模块(MsASPP),该模块将不同卷积层的结果统一到同一尺寸融合输出,结构如图5 所示。
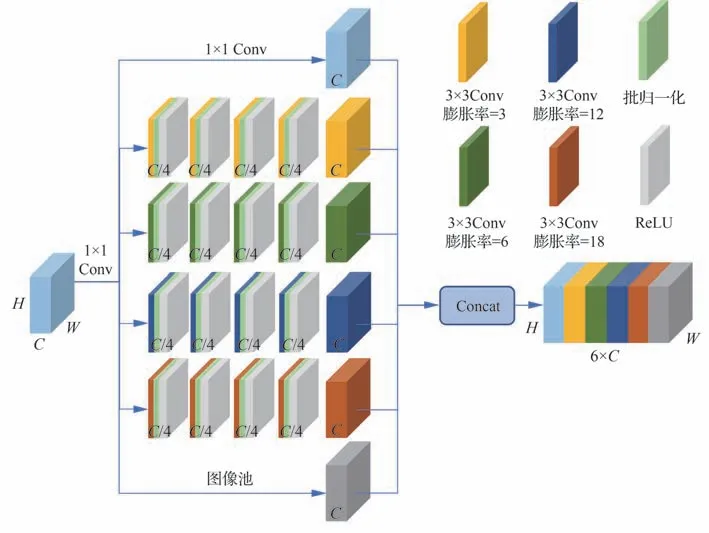
图5 MsASPP 网络结构Fig.5 Architecture of MsASPP network
MsASPP 模块共包含6 条并联支路。其中,1×1 的卷积用于缓解膨胀率过大造成有效权重降低的问题。同时,使用图像级的池化层捕获全局语义信息。其余4 条并联支路通过卷积操作的不同扩张率来调整感受野。MsASPP 模块的输入特征尺寸为16×64,因此可以继续沿用经典ASPP[3]中的(6,12,18)的扩张率,为了得到更多的细节语义信息,还增加了扩张率为3 的并联支路,因此MsASPP 模块中总共包含了4 个扩张率对应的感受野。
虽然多膨胀支路可以提供不同的感受野,但是膨胀卷积会使部分有效信息被遗忘。因此,在各膨胀支路中,采用4 次级联卷积来覆盖更多区域,以获得密集的像素采集。
然而多膨胀率支路需要大量的计算资源来处理不同感受野下的同类型数据,因此需要高效的算法和网络结构来提升这一模块的计算效率。卷积层的参数量只与网络结构有关,与输入数据无关,因此本文在各膨胀支路中采用瓶颈结构[21]来压缩特征尺寸,如图6 所示。

图6 瓶颈结构的膨胀支路Fig.6 Bottleneck-based dilated branch structure
卷积计算参数量的公式为
式中:k是卷积核的尺寸;Cin是输入通道数;Cout是输出通道数;bias 是偏置,默认设置为1。瓶颈结构通过1×1 的卷积将通道数降为1/4,并在输出前使用1×1 的卷积恢复通道数。如表1 所示,使用瓶颈结构后,每一条膨胀支路的卷积参数降低了69.40%。

表1 膨胀支路使用瓶颈卷积的参数量比较Table 1 Comparison of parameter amount of dilated convolutional branch with bottleneck convolution
相对于传统的ASPP 模块,MsASPP 增加了一条并联空洞卷积支路,并且每条支路级联了4 次膨胀卷积,仍然缩减了参数量和计算量,如表2 所示。其中,参数量降低了64.89%,计算量降低了67.09%。
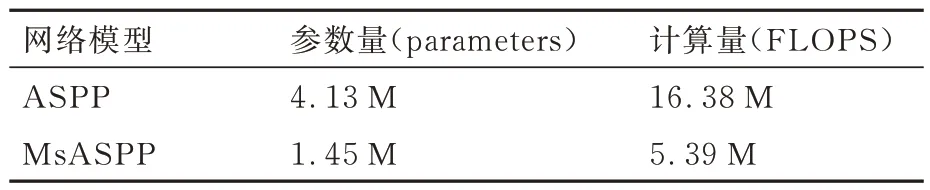
表2 MsASPP 和ASPP 参数量和计算量对比Table 2 Comparison of parameter amount and computational complexity between MsASPP and ASPP
1.5 多任务损失函数
在点云和图像的语义分割任务中,需要对每个点都进行分类预测,并对所有点的损失值求平均,以求得整个点云和图像的损失。MerNet 的损失函数由3 部分组成,分别是Foccal Loss、Lovász-Softmax Loss 和用于计算2 种模态之间感知协同差异损失的Differ Loss。
式中:Lf表示Focal Loss 计算得出的损失值;Ls表示Lovász-Softmax Loss 计算得出的损失值;Ld表示Differ Loss 计算得出的损失值;η1、η2、η3表示平衡3 个损失函数在模型总损失计算中比重的平衡系数。
Focal Loss 基于二分类交叉熵损失,通过一个动态缩放因子平衡难易样本。它的前景的预测概率公式为
式中:p∈[0,1]表示模型属于前景的概率。二分类交叉熵的公式为
平衡交叉熵引入平衡因子解决正负样本不平衡的问题,公式为
式中:αt∈[0,1]表示平衡因子,本文取0.75。
Focal Loss 在平衡交叉熵损失的基础上增加调制因子解决难易样本平衡的问题,公式为
式中:φ∈[0,5]为表示难易样本的调制因子。Focal Loss 被分别用于点云和图像支路,并将2 种模态的损失值相加作为整体模型Focal Loss计算的损失总和,公式为
式中:Lf表示Focal Loss 计算出的损失总和;FLl表示点云支路的Focal Loss 损失值;FLc表示图像支路的Focla Loss 损失值。
Lovász-Softmax Loss 是对语义分割指标IoU 直接进行优化的损失函数,公式为
式中:C表示种类数;ΔJc表示第c类的Jaccard 系数;m(c)表示第c个类的误差向量。
Lovász-Softmax Loss 被分别用于点云和图像支路,并将2 种模态的损失值相加作为整体模型Lovász-Softmax Loss 计算的损失总和,公式为
式中:Ls表示Lovász-Softmax Loss 计算出的损失总和;LSl表示点云特征支路的Lovász-Softmax Loss 损失值;LSc表示图像特征支路的Lovász-Softmax Loss 损失值。
点云和图像在自动驾驶环境感知中具有不同的优势,点云在空间的立体结构判断上表现更优,而图像在色彩和细节纹理上表现更优,因此2 种模态支路的网络预测结果有所差异。本文通过Differ Loss 交叉传递softmax 层的预测概率分布,旨在减小模态间的预测差异,利用一种模态下的感知优势降低另一种模态在劣势场景下的预测误差。Differ Loss 基于交叉熵损失,在本文的网络结构中解决多分类多标签任务,在一个batch 中,交叉熵损失的计算公式为
式中:B表示batch size(单次训练抓取的数量);n表示类别数;y表示真实标签;表示softmax 层的预测概率。交叉熵损失将每个像素类别的预测结果分别与真实标签进行比较,得出损失值,并对所有像素点损失值求平均。
为了计算2 种模态的感知差异,本文采用一种逐像素比较的方法。具体而言,将真实标签替换为另一模态的预测概率分布,Differ Loss 逐个检查每个像素点,依次比对2 种模态下的每个概率分布。其中,以点云支路为基准模态,图像支路为对比模态,感知差异损失的计算公式为
以图像支路为预测基准,点云支路为对比标签,感知差异损失的计算公式为
协同差异损失总和是分别以点云和图像为基准模态时的损失和,计算公式为
点云特征为语义提供了更精准的空间信息,图像特征为语义提供更多的色彩和细节信息,2 种模态的感知能力互补,但并不是完全对立。因此,在协同差异损失中,应当考虑2 种模态对语义判断的贡献,增加平衡系数调整不同模态的损失占比,公式为
式中:ρ1和ρ2分别表示平衡以点云和图像为基准模态的协同差异损失值的平衡系数。
本文通过枚举实验得出ρ1和ρ2平衡系数为1.0、2.4,且3 种损失函数在总损失中的平衡系数η1、η2、η3分别为1、1、0.5 时网络的语义分割性能最佳。
2 实验结果和分析
2.1 实验数据和参数设置
1)实验平台:本文采用Ubuntu 20.04.01 操作系统,搭配NVIDIA GeForce RTX 3090 的图像处理器(GPU),内存为24 G,cuda 版本11.6,torch 版本为1.12.1。
2)数据集:为了评估2 种模态特征融合的效果,使用公开多模态数据集SementicKITTI[22]。该数据集共包含19 个语义类别,其中包括静态类别目标如道路、植被、栅栏、建筑、路标等,以及动态类别目标如汽车、摩托车、卡车、行人等。驾驶环境包括市中心、郊区、乡村、高速公路等。数据集采集的场景共包含22 个数据包,序列分别为00-21,每个数据包中都包含点云和图像数据。其中00-10 包含数据真实标签,本文使用序列为08 的数据包作为验证集,其余00-10 内的数据包作为训练集。
3)参数设置:使用Pytorch 框架实现,点云和图像支路分别以Salsanext 和ResNet34 作为主干网络。使用了AdamWin 和SGD 这2 种优化器,设置学习率预热(warm_up)为1 轮,学习率设为0.000 1,并采用余弦衰减。共进行了30 轮训练,同时设置了4 个线程,batch size 设为4。
4)评价指标:为评估本文提出的网络结构和算法的优越性,采用平均交并比(mean Intersection over Union,mIoU)来作为语义分割结果的衡量标准。该指标是对数据集中每一种类别的网络预测与真实标签的交并比的平均,是语义分割领域的标准度量。
2.2 整体网络效果
为了评估本文提出的网络结构和优化算法,在性能比较中与其他流行的单模态和多模态网络结构进行了对比。其中,单模态网络包括SqueezesegV3、RangeNet53++、SalsaNext等,多模态网络包括KPRNet 和HiFANet。具体语义分割结果如表3[5,23-30]所示,最优分割结果用粗体表示。在与单模态和多模态网络分割结果对比中,可以明显观察到本文提出的Mar-Net 双模态网络在分割性能上具备优势,并相比于双模态网络KPRNet 和HiFANet 分别有0.6%和1.7%的分割优势。MerNet 结合了注意力机制和多模态感知的优势,在自动驾驶环境中对移动灵活、危险系数高的目标给予更大的计算注意力,并在单个类别的分割上也表现出较好的性能。从表3 中可以看出,尽管静态目标的性能没有达到最优水平,但与其他网络相比,并没有显著的性能差异。仅有一个明显的分割劣势出现在“other-ground”类别上。在SemantiKITTI 数据集的论文中,“other-ground”被解释为“当人行道和地形之间的区别不明显时选择此标签”。因此,这个类别被视为无法明确分类为其他道路归属类型时的选择。在本文的网络训练中,该类别以40.3%的概率分类为“sidewalk”,而其余的概率分布在其他道路类型和静态物体之间。这样的分类结果不会对驾驶时的决策产生额外的安全风险,特别是将更多的计算注意力集中在危险系数更高的动态目标物上,这更符合对安全性判断的需要。因此,静态目标微弱的性能劣势是可以接受的。图7 通过混淆矩阵的形式描述了动态高危险性目标的分割精度,将数据集中的静态目标统称为“static”。可以看出,MerNet 在动态目标的分割上表现出良好的性能,一定程度上增加了自动驾驶的安全性能。然而,图7 的结果显示,motorcyclist 类别有94%的概率被分类为bicyclist,这2 个目标具有非常相似的特征。在文献[22]中,SemanticKITTI 数据集未明确考虑骑摩托车或自行车的骑手类别,因此motorcyclist 被识别为bicyclist 是正常现象,并且在实际的驾驶环境中需要对motorcyclist 和bicyclist 做出的决策判断几乎相同,因此不会增加更多的安全隐患,这样的分类结果是可以接受的。

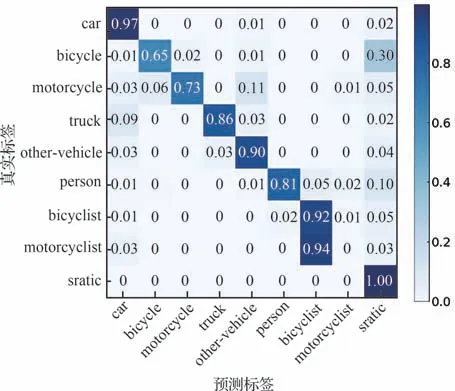
图7 动态目标的混淆矩阵分析Fig.7 Analysis of confusion matrix for dynamic object detection
为了更直观地描述MarNet 的分割效果,图8展示了MarNet 在几个经典分割场景中的表现。通过可视化的分割图,可以观察到MerNet 在光线条件不良的树荫区域、快速运动的车辆、行走的路人、目标物堆叠造成遮挡的情况、停车位上的车辆和警示牌等目标物的分割中,都能展现出较好的效果。

图8 MerNet 在经典场景中的语义分割性能表现Fig.8 Semantic segmentation performance of MerNet in classic scenes
2.3 消融实验
为了验证提出的每一种网络结构和优化算法的有效性,进行了消融实验。表4 中的消融实验结果分别展示了各模块对MerNet 的贡献。表中:AdamWin 表示点云支路使用提出的自适应记忆窗口长度的优化算法,否则使用通用的Adam优化算法;融合模块是使用膨胀点注意力机制和残差映射的融合,否则只对点云和图像特征直接拼接;MsASPP 是指提出的多尺度感受野的上下文模块;Differ Loss 是指使用了提出的协同差异损失函数,否则网络中只有Focal Loss 和Lovász-Softmax Loss。从消融实验结果可以看出,各模块对整体网络的语义分割性能都产生了提升效果。图9 展示了MerNet 中各模块的消融实验语义分割性能表现。

表4 各模块的消融实验结果Table 4 Ablation experiments on each module
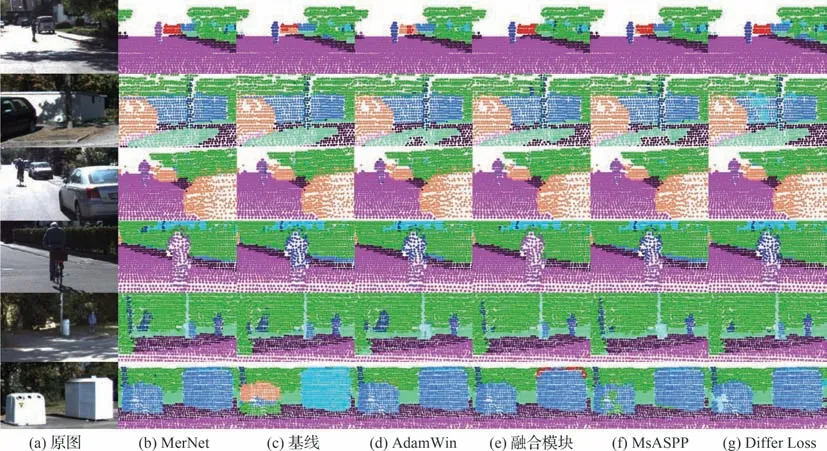
图9 各模块和算法消融实验的语义分割性能表现Fig.9 Semantic segmentation performance analysis of each module and algorithm in ablation experiments
此外,为了验证提出的融合模块中每个网络结构的有效性,同样对注意力机制的使用、残差映射和膨胀点注意力做了消融实验,结果如表5所示。表中:简单融合指融合模块只进行了初步的特征拼接和卷积;注意力是指在初步融合后引入了点注意力机制;残差映射表示在点注意力模块前连接原始点云残差连接;膨胀注意力表示在点注意力中的2 个3×3 卷积处使用了扩张率为2 的膨胀卷积。消融实验结果显示,融合模块中的3 个结构设计都对融合效果有着性能提升的作用。
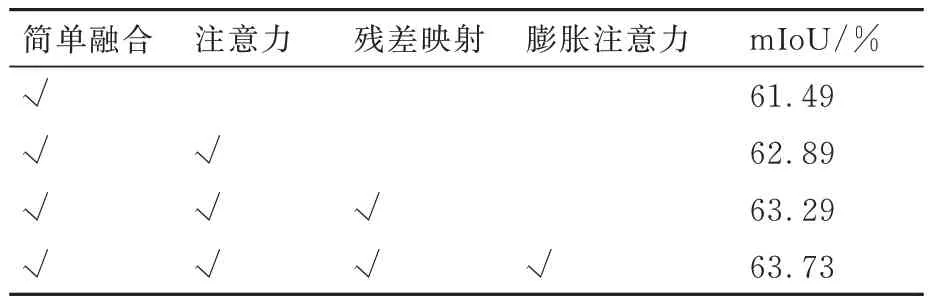
表5 融合模块各结构的消融实验结果对比分析Table 5 Comparative analysis of ablation experiments on various structures in fusion module
3 结论
1)采用SalsaNext 和ResNet34 分别作为点云和光学图像的主干网络并行处理特征。
2)基于Adam 改进了一种自适应历史记忆长度的AdamWin 优化算法,能够根据梯度变化趋势改变历史梯度的记忆权重,在梯度趋缓的过程中增强近距离点对梯度计算的贡献值。
3)基于残差映射和膨胀点注意力的融合模块被用于每一个编码阶段,加强了点云训练分支对更精细细节和纹理信息的提取。
4)基于ASPP 改进了上下文模块MsASPP,增加的并联膨胀支路以及级联空洞卷积,增强了点云的上下文感知信息能力,各支路采用瓶颈结构降低网络参数量。
5)基于交叉熵损失的多模态协同损失函数,交叉传递不同模态间的预测标签,增强了不同模态在特定环境下的感知优势,避免了单一传感器的感知劣势使结果产生较大误差。
本文主要改进了网络结构、优化算法和损失函数,实验结果表明这些改进都提高了网络的语义分割性能。然而,多模态网络往往会伴随着模型复杂度较高的问题,因此本文在上下文模块MsASPP 中考虑了压缩参数量,并将在未来的工作中考虑对网络的整体结构进行轻量化处理。
