基于边缘强化的无监督单目深度估计
2024-01-16曲熠,陈莹
曲 熠, 陈 莹
(江南大学轻工过程先进控制教育部重点实验室, 江苏 无锡 214122)
0 引 言
场景的深度估计是计算机视觉中的经典问题,在自动驾驶[1]、三维重建[2]、同步定位与地图绘制(simultaneous localization and mapping,SLAM)[3]等研究任务中都起着重要作用。传统方法一般利用激光、结构光等在物体表面的反射来获取深度点云,进而获取高精度的目标深度信息,这种方法成本较高且精度受测量环境影响较大。通过计算多视角图像中的视差得到深度信息的多视图立体视觉的方法,计算量大且对于纹理稀疏的场景预测较为困难。相比之下,利用单张彩色图输入预测场景深度的单目深度估计方法,能够有效控制成本,可应用范围更广。
预测场景深度的单目深度估计方法,能有效控制成本,可应用范围更广。近年来,深度学习在目标检测[4]、目标识别与跟踪[5]、图像分类[6]等领域中展现出了良好性能,基于深度学习方法的单目深度估计也受到了研究人员的广泛关注。Eigen等[7]在2014年首次提出将深度神经网络用于单目深度估计任务,设计了一种包含粗细两种不同尺度的卷积神经网络结构,其中粗尺度网络用于估计图像的全局深度,细尺度网络用于优化局部特征,通过两个网络的叠加处理提取单目图像的特征,并进行深度估计。Laina等[8]提出了一种基于残差学习的全卷积网络框架,该框架使用了小卷积代替大卷积的方式提升了上采样效率,同时使用了Huber损失函数,实现了对L1损失和L2损失的平衡。Fu等[9]考虑到深度估计的不确定性随着深度值变大而变大,提出使用间隔增加的离散化(spacing-increasing discretization, SID)策略将深度估计这一回归问题转化为多个离散的二分类问题,同时使用空洞空间卷积池化金字塔(atrous spatial pyramid pooling, ASPP)网络融合多尺度信息,预测精度和同步收敛速度相比之前的方法都有明显提升。Yuan等[10]则提出了一种基于神经窗口全连接的条件随机场(conditional random fields, CRFs)模块的单目深度估计网络。该网络将输入图像分割为子窗口,并在每个窗口内进行全连接的CRFs优化,降低了高计算复杂度,同时使用多头注意力机制来捕获各窗口CRFs中的成对关系,从而实现对高分辨率密集深度图的准确预测。
上述有监督模型均以真实的深度信息作为标签进行训练,但深度信息很难获取,因此近年来涌现出大量无监督单目深度估计模型。Godard等[11]提出的Monodepth算法可看作是基于双目训练的无监督单目估计模型的开端,该算法只需在训练中使用右视图,在测试时输入左视图,就能生成左右视差图,进行深度估计,利用左右视差图一致性优化输出结果。受计算机视觉运动恢复结构(structure from motion,SFM)算法的启发,Zhou等[12]另辟蹊径,提出了一个端到端学习方法,在未标记的视频上进行训练,利用视图合成的任务来监督单视图深度估计。Godard等[13]提出Monodepth2算法,将基于单目视频和基于双目图像的深度估计结合起来,同时在输入分辨率下执行所有图像采样的多尺度外观匹配损失以减少深度伪影。Shu[14]等利用单视图重构来学习特征表示,并提出了一种用于自监督深度和自我运动估计的特征度量损失,以准确计算无纹理区域像素的光度损失。Lee等[15]提出了一种端到端的联合训练框架,该框架基于神经前向投影模块,同时使用单一实例感知的光度测量和几何一致性损失,减小运动模糊性对深度估计准确性的影响。
虽然无监督单目深度估计领域发展迅速,但目前的无监督单目深度估计方法仍存在浅层特征利用不足、深度边缘估计困难的问题。针对这一问题,Zhu[16]等考虑利用语义分割边缘指导深度边缘,提出一种测量分割和深度之间的边界一致性的方法,并将其最小化,以推动深度网络向更精确的边缘发展。叶星余等[17]提出将对抗生成网络(generative adversarial network, GAN)作为深度估计的网络框架,并将自注意力机制结合在深度估计任务中,以提高网络模型对场景细节、边缘轮廓的学习能力。然而,上述这些方法均需要使用额外的语义网络或判别辅助训练。
本文设计了一种即插即用的边缘强化模块,使用条状卷积聚合边缘附近的像素,充分利用上下文特征使深度边缘更加清晰;同时结合高斯拉普拉斯算子进行边缘增强,强化深度边缘信息,只需将其嵌入深度估计网络,即可实现对深度边缘的准确估计。
1 无监督单目深度估计网络原理
本文使用的是目前单目深度估计领域最常用的SFM框架,如图1所示,输入未标记的单目视频序列中连续的三帧It,t∈{-1,0,1},联合训练一个单视图深度网络模型Θdepth和一个姿态网络模型Θpose。单视图深度网络模型Θdepth以目标帧I0作为输入,输出预测深度图d;姿态网络模型Θpose用以估计目标帧I0与源帧It′之间的相对位姿T0→t′=Θpose(I0,It′),t′∈{-1,1}。
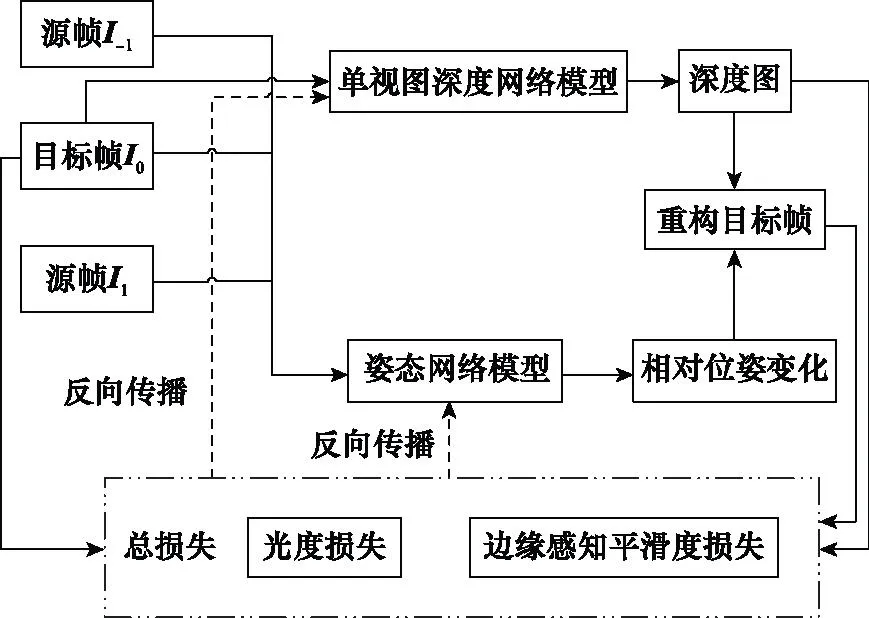
图1 无监督单目深度估计框架图Fig.1 Diagram of unsupervised monocular depth estimation framework
基于移动摄像机和静态场景假设,可以利用源帧It′,t′∈{-1,1}重构出目标帧I0,如下所示:
It′→0=It′[proj(reproj(I0,d,T0→t′),K)]
(1)
式中:K为已知的相机内部参数;[]表示采样操作;reproj表示返回t′时刻的三维点云;proj表示输出将点云投影到It′上的二维坐标。
2 本文方法
本节主要介绍了基于边缘强化的无监督单目深度估计网络的具体构建方法,针对目前方法中存在的深度边缘模糊的问题,本节对传统深度网络进行了改进,设计了一种能够增强边缘深度预测的模块,该模块使用条状卷积结合高斯拉普拉斯算子学习边缘信息,提高了网络预测深度边界的能力。
2.1 改进的单目深度网络
本文提出的网络模型如图2所示,由单视图深度网络和姿态网络两部分构成,均采用编解码结构。姿态网络模型以18层的深度残差网络(deep residual network, ResNet18)为骨干网络,以视频序列相邻的三帧作为输入,该网络编码器由7个步长为2的卷积层组成,解码器由4个步长为1的反卷积层组成。最后,将全局平均池化应用于所有空间位置的聚合预测,输出具有6自由度的相对姿态。
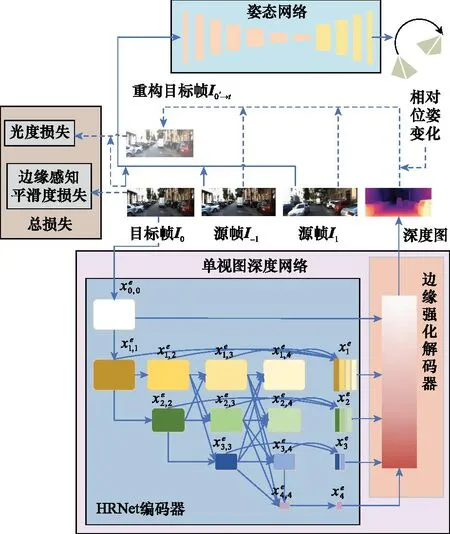
图2 深度估计网络结构图Fig.2 Depth estimation network structure

解码器采用U型架构[18],对编码器输出的特征进行上采样恢复维度,使用跳跃连接在上采样的过程中将不同尺度的特征融合,同时引入边缘强化模块增强对深度边缘区域的感知,最终依次输出4个分辨率递增的深度图。在训练中,来自4个尺度的深度图均参与损失函数计算;在测试时,模型只输出最大分辨率深度图。
2.2 边缘强化解码器
本节详细介绍了内嵌边缘强化模块的单视图深度网络解码器内部各节点的结构,分别介绍了边缘强化模块各组分的具体构建方法,并通过输出特征图分析各组分对深度图的影响。
2.2.1 解码器总体架构
解码器节点的具体结构如图3所示,其中节点Di,i∈{1,2,3,4}均有2个输入特征图i1,i2,对分辨率较小的i1进行采样操作后,与i2进行concat操作得到特征图F。然后,将特征图输入到一个通道注意力映射生成器,输出一维通道注意映射与特征图进行元素级乘法,得到特征图Fc。在乘法过程中,通道注意值沿着空间维度广播,这使得编码器能学习到不同通道的重要性,从而更好地完成跳跃连接。最后,将特征图Fc输入3×3卷积层,节点Di,i∈{1,2,3}输出相应尺度的深度图。

图3 单视图深度网络解码器结构及细节图Fig.3 Structure and details diagram of single-view depth network decoder
为了更充分地利用浅层特征的细节信息,提高深度边缘的准确性,节点D0添加即插即用的边缘强化模块MSE来提高边缘区域深度估计的精度,边缘强化模块MSE的定义为
MSE=ME(MS(Fi))
(2)
式中:Fi表示经过通道注意力处理的特征图;MS表示条状卷积处理;ME表示边缘增强处理。
图4(a)为经过通道注意力处理的特征图,其含有大量与深度信息无关的结构信息且在对象边缘区域存在大量伪影。如图4(b)所示,经过条状卷积处理后的特征图,边缘区域初步细化,但有效的深度信息很少。如图4(c)所示,经过边缘增强处理后的特征图,特征图的深度信息更加丰富,边缘信息更加精准明确。
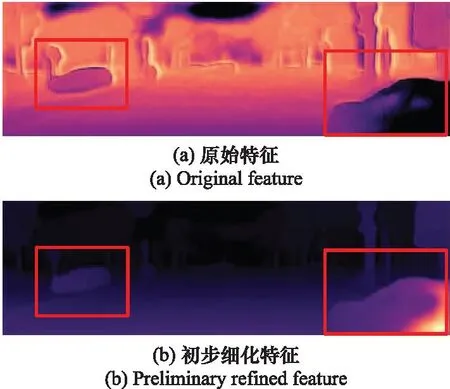

图4 边缘强化模块的作用Fig.4 Effect of the edge enhancement module
2.2.2 条状卷积
传统方法一般直接使用3×3或5×5的方形卷积来预测最终的深度[19],这种卷积层只对每个像素的局部特征进行聚合,不能充分利用边界和全局上下文特征,这限制了其在捕捉现实场景中广泛存在的各向异性背景时的灵活性[20]。如图5(a)所示,对于场景中离散分布的行人或者带状结构的车辆而言,使用方形卷积不可避免地会合并来自无关区域的信息,容易让深度预测出现局部混乱,导致深度边缘模糊不清。如图5(b)所示,条状卷积沿一个空间维度部署长条状的核,有助于捕获远距离依赖关系;沿其他空间维度保持窄的内核形状,有助于捕获本地上下文信息并防止不相干区域妨碍预测结果。条状卷积可以作为方形卷积的补充,帮助提取更精细的物体特征。因此,本文设计利用条状卷积在进行最终的深度预测前先明确边界附近的深度变化,并挖掘细节特征。

图5 条状卷积示意及细节图Fig.5 Schematic and details diagram of strip convolution
条状卷积具体细节如图5(c)所示。其中,a为11×3卷积层,b为3×11卷积层,令卷积a在水平方向、卷积b在垂直方向分别大范围聚合边界附近的像素,然后进行元素级的相加操作来融合两条状卷积提取的特征,为保证融合特征的多样性,条状卷积后不接激活函数。由于沿正交方向的全局上下文信息是指示相对深度的重要线索,通过该条状卷积处理可以更好地识别物体与其背景之间的深度变化。
2.2.3 边缘增强
经过上述条状卷积处理后,特征图深度边缘在一定程度上得到明确,但仍需进一步增强。拉普拉斯算子是具有旋转不变性的二阶微分算子,可以通过图像梯度来寻找边缘的强度和方向,在边缘检测中得到了广泛的应用,其计算公式为
(3)
由于二阶微分算子对噪声比较敏感,通常在拉普拉斯变换前先进行高斯平滑,以避免像素值的急剧变化。二维图像中各向同性的高斯形式为
(4)
由于输入的图像都是用离散像素表示的,需要找到离散的卷积核来近似高斯平滑和拉普拉斯变换,而卷积运算满足结合律,因此可使用高斯拉普拉斯算子一次性完成上述平滑和锐化两种处理[21],本文基于此算子进行边缘增强处理,其定义为
(5)
式中:σ为方差值,本文取值为1.1。
2.3 损失函数
本文通过光度损失Lp和边缘感知平滑度损失Ls[11,13]联合监督训练单视图深度网络和姿态网络。光度损失Lp是一个外观匹配损失,本文使用结构相似度项(structural similarity index measurement, SSIM)[22]结合L1范式计算目标帧和重构目标帧之间的相似性,光度损失函数定义为
(6)
式中:I0为目标帧;It′→0为重构目标帧;α为权值系数。
边缘感知平滑度损失Ls用来规范低梯度区域的深度,其定义为:
(7)

同时沿用了Monodepth算法[13]中引入的最小光度误差、自动掩蔽多尺度深度损失,最终的损失函数定义为
Lfinal=min(Lp)+βLs(d),t′∈{-1,1}
(8)
式中:β为光度损失Lp和边缘感知平滑度损失Ls之间的加权系数。
3 实验结果与分析
本节验证了本文提出的模型能够输出边缘精确的深度图,在KITTI数据集[23]上通过消融实验验证了本文各项改进的作用,同时与近年来一些先进的深度估计方法[13,24-33]进行比较,具体如下。
(1) Li等[24]和Akada等[25]:均采用真实的深度标签进行训练监督。其中,Li等[24]提出了一种软加权和推理方法,减少了量化误差的影响,提高了模型鲁棒性;Akada等[25]则应用领域不变特征学习方法借助更容易产生的合成图片训练深度估计模型。
(2) 文献[26]:将HRNet引入单目深度估计,设计了一种结合了多分辨率特征融合和空间注意力机制的新型深度网络,弥补了编码器和解码器特征映射之间的语义差距,本文以此为基础进行改进。
(3) 文献[27]和文献[28]:采用有监督的语义分割和自监督的深度估计进行互利跨域训练,利用语义信息区分和处理场景中潜在的动态物体。
(4) 文献[29]:重新设计了跳跃连接并提出了特征融合-压缩激励块,实现了多尺度的高分辨率特征融合,帮助网络预测更清晰的边缘。
(5) 文献等[30]:提出使用Sobel算子和高斯模糊在下采样的过程中提取并保留边缘信息,并引入基于纹理稀疏性的自适应加权损失来解决遮挡和纹理稀疏性问题。
(6) 文献[31]:引入遮挡感知蒸馏模块,充分结合立体深度估计算法和单目深度估计算法的优点,提升深度估计网络性能。
(7) 文献[32]:提出了几何一致性损失,惩罚相邻视图之间预测深度的不一致,同时使用一个自发现掩模以屏蔽由于物体移动产生的无效点。
(8) 文献[33]:提出一种新的尺度感知框架,使用惯性测量单元(inertial measurement unit, IMU)光度损失和跨传感器光度一致性损失,以解决单目深度估计中的尺度模糊问题。
3.1 数据集
KITTI数据集是一个自动驾驶数据集,包含来自农村地区、城市、高速公路等394个道路场景的灰色、彩色和地面真实深度图像。本文使用Eigen等[7]拆分出的39 810个连续帧用于进行训练,使用697张图像进行测试。为了简化训练过程,假设不同场景中所有帧的摄像机的固有矩阵都是相同的。为了得到这个通用的内在矩阵,将相机的主点设置为图像中心,并将焦距重置为KITTI中所有焦距的平均值。
3.2 实施细节
本网络使用具有24G运行内存的RTX3090Ti显卡对模型进行训练,使用Adam优化器[34]训练单视图深度网络模型和姿态网络模型20个训练轮次,默认测试系数β1、β2分别为0.9和0.999,批量大小为8,分辨率为640×192和1 024×320。设置前14个训练轮次的初始学习率为10-4,将剩余训练轮次的学习率微调为10-5。在式(8)的最终目标函数Lfinal中,令SSIM权值α=0.85,边缘感知平滑权值β=1×10-3。
3.3 评估指标
基于之前的工作[11],本文采用平均相对误差(absolute relative error, Abs Rel)、平方相对误差(square relative error, Sq Rel)、均方根误差(root mean square error, RMSE)、对数均方根误差(root mean square logarithmic error, RMSE log)、阈值精度5个指标对改进的模型进行量化度量。上述指标公式如下:
平均相对误差(absolute relative error, Abs Rel):
(9)
平方相对误差(square relative error, Sq Rel):
(10)
均方根误差RMSE:
(11)
对数均方根误差RMSE log:
(12)
域值精度满足条件:
(13)
式中:d为某一像素的真实深度值;d*为某一像素的预测深度值;T为真实深度图中可获取的像素总数;log底数为e。
3.4 实验结果分析
为证明本文所提改进方法的有效性和先进性,在KITTI数据集上将本文方法的实验结果与近年来其他先进的无监督单目深度估计方法进行对比,对比结果如表1所示。

表1 在KITTI数据集上的测试结果对比Table 1 Comparison of experimental results on the KITTI dataset
从表1可以看出,与其他先进的无监督模型甚至是有监督模型相比,本文提出的模型误差指标低,预测准确率高,在1 024×320及其近似分辨率下,本文模型的所有指标均优于其他模型。Liu等[30]提出的模型和本文改进的模型均考虑使用传统边缘检测方法强化边缘信息。在1 024×320分辨率下,本文提出的模型在Abs Rel、Sq Rel、RMSE以及RMSE log上相较于前者分别提高了10.6%、8.6%、3.9%和5.0%。实验结果表明,在不同分辨率下,本文提出方法的所有评估指标几乎全面优于先前方法,能够实现深度估计质量的整体提升。
3.5 消融实验
为了验证本文提出的边缘强化模块对提升边缘深度预测能力的有效性,以640×192分辨率为例,通过消融实验进行对比,分析了该模块各组分的贡献以及边缘强化模块位置对深度预测结果的影响,结果如表2所示。

表2 验证各组分作用的消融实验结果Table 2 Results of ablation experiment on the verification of the effect of each component
在Baseline上添加条状卷积层后,虽然网络的参数量和计算量均小有增加,但由于网络对边缘信息提取能力增强,对边缘附近的上下文特征聚合更充分,对该区域的深度变化感知更深刻,从表2可以看出,网络在精度上也有了一定的提高,Sq Rel达到了0.754,比之前提升了2.4%,说明对深度边缘的细化有助于提升深度预测的准确性。此外,单独使用高斯拉普拉斯算子进行边缘增强处理,也能在一定程度上增强网络对于边缘区域信息的利用,使精度小幅提升,且该处理不涉及参数量和计算量的增加,最大程度地实现了精度提升和计算成本之间的平衡。在使用条状卷积和边缘增强处理组成的边缘强化模块后,网络对边缘信息的提取和整合能力最大化,更大程度地发掘了网络的潜能,几乎所有指标均高于先前实验结果,其中Sq Rel相较基准模型提升了3.6%,Abs Rel提升了1%,保证了深度估计的准确性,又维持了预测的速度。实验表明,本文设计的边缘强化模块的每一组分对于网络的最终精度提升都是有效的,且两者结合的效果更好。
由于浅层网络感受野较小,感受野重叠区域也较小,所以其提取的特征分辨率高,能够包含更多的细节信息。因此对来自编码器浅层特征图的边缘信息进行强化,有利于提高边缘区域深度预测的精准度。从表3可以看出,在图3中的D0节点,也就是输出最大深度图的解码器节点中嵌入边缘强化模块能够在最大程度上优化边缘深度估计,相较在其他位置应用边缘强化模块,Sq Rel最高提升了6.1%,Abs Rel最高提升了1.5%。另外,对于条状卷积而言,过短或过窄会妨碍网络对于边缘区域上下文信息的捕捉,过长或过宽则使网络易受到无关区域信息干扰。从表4可以看出,本文所选用的11×3的条状卷积层最有利于其发挥细化作用,提升网络精度。

表3 边缘强化模块位置的消融实验结果Table 3 Results of ablation experiment on the location of edge enhancement module

表4 条状卷积形状的消融实验结果Table 4 Results of ablation experiment on the shape of strip convolutions
为了更直观地表明本文改进模型的效果,图6给出了一些可视化的结果,其中图6(a)为测试图像,图6(b)为没有添加边缘强化模块的模型输出的深度图,图6(c)为含有边缘强化模块的模型输出的深度图。从图6可以看出,本文提出的边缘强化模块能够使输出的深度图边界更清晰准确,细节更完整。对于图6(a)的左图来说,改进的方法将栏杆与后方的树冠进行了明确区分,分别进行了准确估计。对于图6(a)的右图来说,改进的方法不仅将电线杆与后方的树冠进行了明确区分,还对交通标识和行人的细节进行了精确还原。

图6 可视化结果对比Fig.6 Comparison of visualization results
从上述各项实验指标和可视化结果对比中不难看出,本文改进的模型能够充分利用细节信息,精准估计边缘深度,有效提高预测精度,与此同时,并没有大幅增加模型的参数量和计算量,可以说即保证了深度估计的准确性,又控制了模型的时间和空间成本,满足实际应用场景的需要。
4 结束语
为解决目前无监督单目深度估计方法中存在的深度边缘估计不准、细节缺失的问题,本文提出了一种基于边缘强化的无监督单目深度估计网络模型,该模型的核心是一个即插即用的边缘强化模块,通过条状卷积细化深度边缘区域,通过高斯拉普拉斯算子提取出准确的边缘信息,最终在两者的共同作用下充分挖掘图像中的边缘信息,对深度边缘区域递进式强化,精准估计边缘深度值。在KITTI数据集上的消融实验证明了每个提出的改进在网络性能上的增益。与之前的方法相比,本文提出的方法性能优越,有效增强了网络对边缘区域的预测能力,输出的深度图边缘更细致、细节更准确,整体预测精度更高。
