基于深度学习的工业零件识别与抓取实时检测算法
2024-01-16吕张成张建业陈哲钥刘浩
吕张成,张建业,陈哲钥,刘浩
(1.天津工业大学机械工程学院,天津 300387;2.天津工业大学天津市现代机电装备技术重点实验室,天津 300387)
0 前言
现在工厂使用的机械臂多以人工示教为主,控制机械臂以固定的流程和位置进行作业。这种方式存在累计误差,长时间使用可能造成机器人抓取位置发生偏差。随着机器视觉的发展,使得机器人的控制方式发生了改变。机器视觉的原理是将摄像头采集到的图像进行实时处理,将处理结果作为控制机器人抓取的依据,其主要的处理过程包含:图像预处理、目标位置检测、目标空间三维坐标计算和抓取位置标定等。
文献[1-2]中介绍了传统的视觉抓取方案,需要人为进行特征图的提取和输入,受主观影响较大。传统的视觉抓取局限很多,往往只能针对单一形状的目标进行算法设计,与生产中多类别、形状多样的情况不相匹配。同时,人工提取的特征受外界环境的影响,外部光照、摆放位置、拍摄角度等原因都会造成机器人抓取的失败。深度学习在2006年被HINTON和SALAKHUTDINOV[3]提出之后,基于人为特征提取的图像处理算法的优势越来越小。传统的图像处理大部分工作在人工提取目标特征的过程,特征提取的好坏决定了算法的好坏。深度学习训练的本质就是图像特征提取的过程,通过大量的数据进行模型学习提取特征,大大减小人为特征提取带来的影响以及解决特殊场景特征对比困难的问题。文献[4]针对RGB-D图像进行处理并提出了一种两步级联的检测系统,获得了很好的实验效果。文献[5]介绍了一种基于点云的位姿估算法,在3D神经网络PointNet中进行位置估算,但是实际应用受到物体遮挡的影响。结合深度学习和机械臂进行分类抓取的研究非常具有实际意义和使用价值,它可以对不同种类、不同尺寸的物品进行准确的处理。此外,利用机械臂对工厂零件进行分拣以代替人工作业,对于降低工作强度、提高工作效率和增加工作时长具有重要的意义。
针对上述问题,本文作者提出一种基于深度学习的多目标工业零件抓取位置检测算法,在零件分类、剔除和筛选方面具有很好的实用性。在目标检测模块使用现有的YOLOv5l深度神经网络算法进行训练,提取工业零件特征。YOLOv5l采用端到端的处理方式,能够实现实时处理任务的目标,完成工业零件目标识别。将YOLOv5l处理好的目标识别结果传入改进的生成抓取卷积网络(GG-CNN)进行最佳抓取位置的检测。在GG-CNN网络的基础上进行改进,添加4个残差模块进行特征的多次平层提取,提高抓取位置检测的准确性。当目标被检测识别之后,进行最佳抓取位置的识别,配合使用深度相机使得系统可以获取目标物体抓取位置的三维坐标。最后基于ROS系统搭建ABBIRB120机器人的抓取实验平台,其中各个模块之间通过ROS节点进行通信,利用ROS Master管理所有的变量和数据。
1 目标检测
YOLOv5算法是CNN卷积网络的一种变种,算法本身去除了卷积神经网络的池化层和全连接层,整个运算过程采用卷积进行计算。通过对每个阶段图片进行分割形成感受野,分阶段进行大、中、小目标检测。在算法内部形成13像素×13像素、26像素×26像素、52像素×52像素3种不同的预选框,其中13像素×13像素形成的大感受野进行大目标的检测,26像素×26像素和52像素×52像素分别进行中等目标和小目标进行检测。YOLOv5还采用One-stage的方式极大地提高算法的精度和识别速度[6]。
1.1 目标检测模块
YOLOv5网络结构由输入端、Backbone、Neck、Prediction四部分组成,如图1所示。输入端采用Mosaic进行数据增强,提高对小目标的检测能力[7]。运用自适应锚框计算和自适应图片播放提高神经网络的检测速度,并对原始图片进行标准尺寸处理。Backbone部分包含Focus结构和CSP结构,其中Focus结构主要用于切片操作,通过3层下采样卷积的改进,不仅速度有所提高而且减少了数据信息的丢失。文中选用的YOLOv5l模型经过Focus结构和第一次卷积操作产生的特征图大小为304像素×304像素×64像素,第二个卷积操作产生的特征图大小为152像素×152像素×128像素,第三次卷积操作产生的特征图大小为76像素×76像素×256像素,第四次卷积操作产生的特征图大小为38像素×38像素×512像素,第五次卷积操作产生的特征图大小为19像素×19像素×1 280像素。在YOLOv5中设计了2种不同的CSP结构,其中CSP1_X用于Backbone,CSP2_X用于Neck模块中[8]。CSP结构借鉴了CSPNet的设计思路,主要将基础层的特征映射划分为两部分,然后通过跨阶段层次机构合并的方式优化梯度信息重复的问题,减少计算量。为了更好地进行特征融合,Neck模块采用FPN+PAN结构,结合CSP2结构增强特征融合的效果[9]。输出端则使用CIOU_Loss作为Bounding box的损失函数,以及DIOU_nms作为预测框的筛选,最终输出目标图像。系统结构及算法流程如图2所示。

图1 YOLOv5算法模型结构Fig.1 YOLOv5 algorithm model structure

图2 系统结构及算法流程Fig.2 System structure and algorithm flow
1.2 目标检测模块损失函数计算
在目标检测部分,采用CIOU_Loss的损失函数计算各预测框与实际标注框之间的差距,用于模型不断学习和更新权重[10]。与最初的IOU计算方法相比,CIOU的计算考虑到了重叠面积、中心点距离和长宽比,计算得到的预测框和真实的标注框之间的差距使得模型权重更新更为准确[11]。DIOU_nms是在多个预测框之间进行选择,比较预测框之间的概率大小,选取数值最大的预测框。此部分NMS采用DIOU为主的检测标准,当多个目标重合时也能更准确地检测出全部目标物体。
(1)
(2)
(3)
其中:D2表示预测框与标准框之间的欧氏距离;DC表示最小对角矩阵的对角线距离;ν为引入的预测框与标注框之间的长宽比系数;Wgt、hgt分别为标注框的长、宽;WP、hP分别为检测框的长、宽。
2 抓取位置检测
此部分在GG-CNN神经网络的基础上构建了三层卷积、4个残差和3个卷积转置网络。采用n通道输入图像信息并生成像素级抓取,通过三层卷积层的向下采样提取特征卷积层从输入图像中提取特征;然后在卷积层的输出中引入4个残差层,使用残差层能够跳过全连接以更好地学习标识函数。图像通过卷积和残差层后,其大小减小到56像素×56像素,为了在卷积运算后更容易解释和保留图像的空间特征,使用卷积转置运算对图像进行上采样。因此,在输出端输出与输入端大小相同的图像。
2.1 改进的网络结构

(4)
经过四层残差层后,随着层次的递增,特征的提取精度提高,并且解决了深度网络造成的梯度消失问题。残差网络会跳过全连接的方式,实现权重信号的跨层传输,改善梯度消失的状况,解决网络无法实现信息反向传播的问题。残差网络如图3所示。改进的GG-CNN算法模型结构如图4所示。
图3 残差模型结构Fig.3 Residual model structure
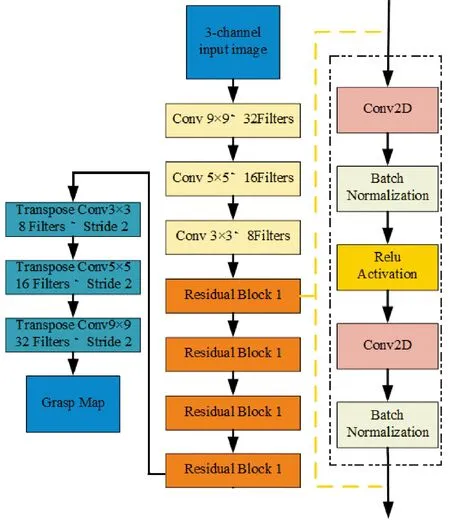
图4 改进的GG-CNN算法模型结构Fig.4 Improved GG-CNN algorithm model structure
2.2 抓取位置检测模块损失函数计算
在抓取框检测阶段采用了全新的矩阵框度量方式,与传统的五参数矩阵框表示方法相比,新的矩阵框将无用的height参数取代为一个权重,用来比较预测抓取框的权重大小,并且增加了抓取框的中心位置的z方向坐标[12]。表达式如下:
Pf=(x,y,z,θf,Wf,Q)
(5)
其中:x、y为抓取框的中心位置;z为抓取深度;θf是相机相对于Z轴需要转换的角度;Wf为抓取的宽度;Q为此抓取框的权重。
采用齐次坐标变换矩阵,将图形上的坐标转换为末端执行器的坐标位置,在世界坐标下控制机械臂抓取目标。
Pr=T2(T1(Pf))
(6)
其中:T1为图像的坐标信息转换为相机的三维坐标信息;T2为在世界坐标系中将相机的坐标最终转化为末端执行器的坐标[13]。
此部分的神经网络采用Huber损失函数来进行权重优化。Huber函数是MAE函数和MSE函数的综合体,使Huber函数在鲁棒稳定性上有了很高的提升。使用Huber Loss作为激活函数,对离群点有很好的抗干扰性,如公式(7)所示[14]:
L(Pfk,Plk)=
(7)
其中:Pfk代表预测框信息;Plk代表标注框的信息。
3 实验结果与分析
3.1 目标检测
文中对模型训练采用的是Ubuntu系统,配置参数为:GPU:GTX2070,CPU:inteli9 10980XE。模型训练设置超参数:基础学习率base_lr为0.001;学习率衰减步长为60 000;学习率的变化比率Gamma为0.01;训练迭代次数为50 000。
目标检测数据集采用自标注的零件数据图,通过数据增强的手段制作了3 000张数据图,其中大目标包含30%,中目标包含30%,小目标包含40%。目标检测数据集分为20个类目,包含工业中常见零件,其中20种分类分别命名为:optic-axis光轴、pedestal支撑座、belt pulley同步带轮、coupling联轴器、bearing轴承、pin销钉、gimbal-joint万向节、fixed clip固定夹、bolt螺栓、nut螺母、gasket垫片、trapezoidal-nut梯形螺母、connector连接件、rectangular-piece直角件、connecting-plate连接板、gear-belt齿轮带、key键、aluminium-product铝型材、linear-bearing直线轴承、flange法兰。
经实验证明,在使用YOLOv5l模型和CIOU_Loss损失函数计算损失值的情况下,多目标重合时模型能够很好地被识别出来。其效果如图5所示。
综合比较YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x不同深度和网络宽度神经网络的识别时间和计算效果,选取YOLOv5l作为文中算法的识别模型。对比结果如表1所示。
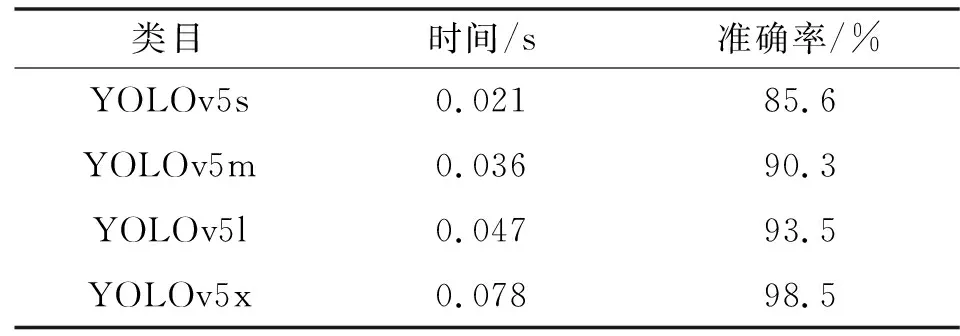
表1 YOLOv5不同模型在数据上识别结果Tab.1 Recognition results of YOLOv5 different models on data
3.2 抓取位置检测
最佳抓取位置运用更加轻量的网络结构,并与2019年的GG-CNN网络进行对比,在速度和准确度上有了较大的提升。文中在GG-CNN的基础上加入了残差结构,使得特征提取更加细致,对于小目标的识别和框取有着更高的准确性。实验表明:改进后的神经网络比GG-CNN网络在抓取精度上提高了15%,在计算时间只是增加了5%左右,更好地提高了时效性。该方法以目标物体的多模态特征作为训练数据监督训练阶段,使用反向传播算法对整个网络进行监督微调。此部分数据集使用的是Cornell抓取数据集以及Jacquard数据集。Jacquard数据集有240种不同的标本,共计1 336张图片,在每种图片上都标注了多个抓取位置;Cornell抓取数据集则包含了正负样本用于对照。文中衡量标准为抓取点偏差小于5像素,抓取角度偏差小于30°,抓取宽度比小于0.8。相较于常用的预测框与标准框的贴合面积达到75%,预测框的抓取角度与标注框的抓取角度小于30%的衡量标准更加精确[15]。仿真实验结果如图6所示。

图6 改进的GG-CNN多零件抓取结果Fig.6 Improved GG-CNN multi-part grasping result
对不同模型的训练数据进行统计,分别对Cornell抓取数据集以及Jacquard抓取数据集上的结果进行分析,如表2所示。
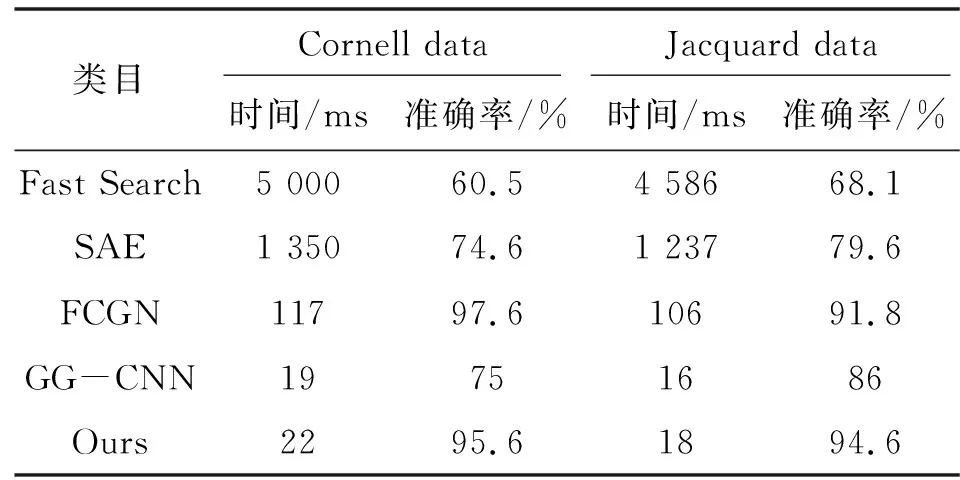
表2 不同模型在抓取数据集上识别结果对比Tab.2 Comparison of recognition results of different models on the captured data set
3.3 零件抓取实验检测
实验平台的搭建用到的硬件包括计算机、ABBIRB120机器人实体、IRC5紧凑型控制柜、TP-Link路由器、摄像头和多根超五类网线。基于ROS平台进行系统搭建,建立平台基础[16]。在系统搭建中,TP-Link路由器是构建局域网的重要组成部分,通过TP-Link路由器的LAN口可以将计算机、IRC5紧凑型控制柜和机器人连接在一起,并且可以通过TP-Link路由器的WAN口连接互联网,提供网络服务,下载实验平台搭建所需要的依赖插件等必要的软件。实验平台连接示意如图7所示,抓取实验过程如图8-10所示。
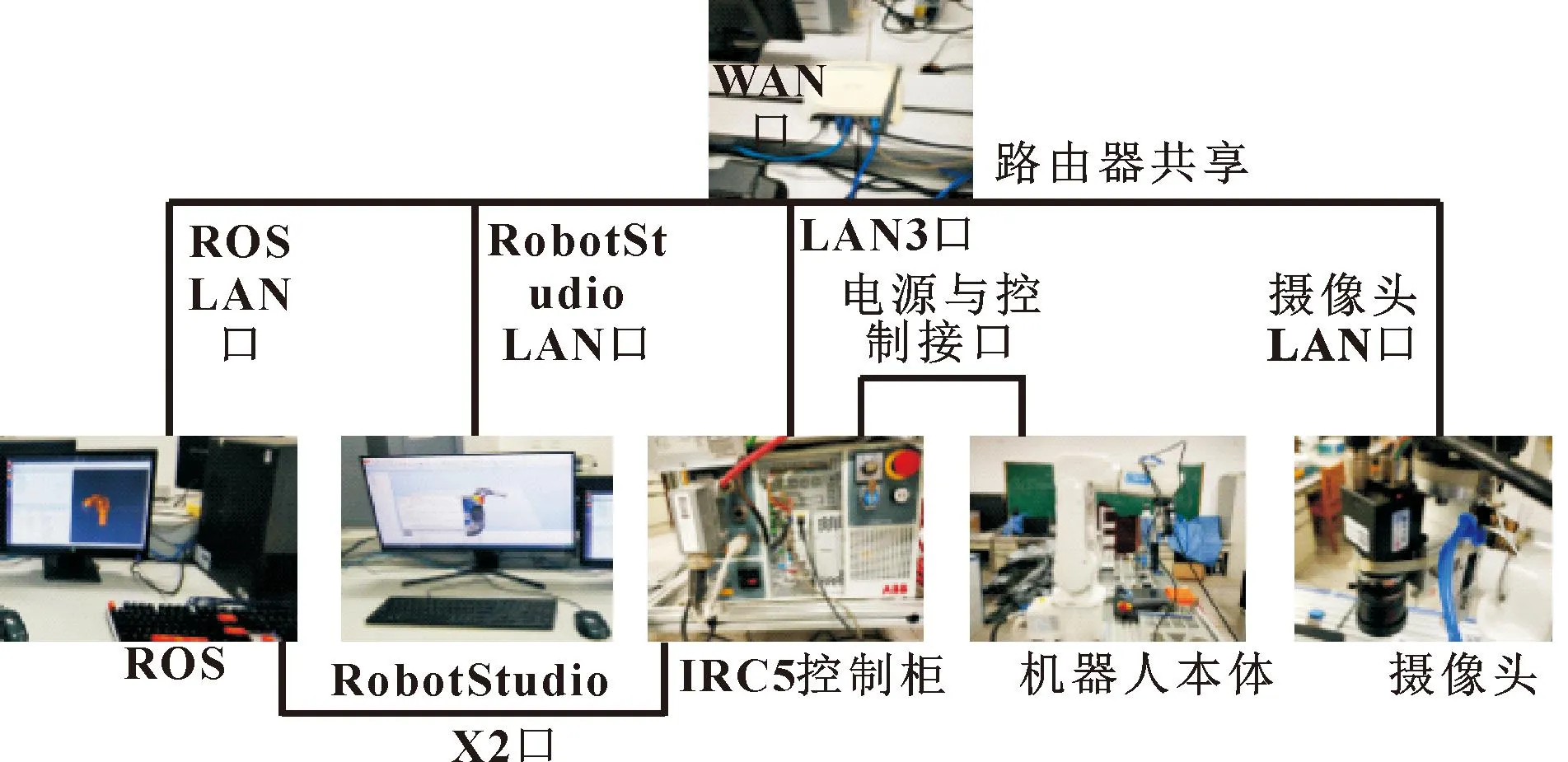
图7 实验平台搭建硬件串联示意Fig.7 Experimental platform construction hardware series

图8 相机获取工业零件图像信息Fig.8 Image information of industrial parts acquired by camera

图9 工业零件抓取机器人实物Fig.9 Entity of industrial parts grabbing robot

图10 抓取实验过程Fig.10 Process of grabbing experiment:(a)obtain the image information;(b)grab the object;(c) move the object;(d)put in the specified location
4 结论
综上所述,文中基于YOLOv5l神经网络和GG-CNN神经网络,提出了一种多目标物体分类和目标抓取位置检测方案,增强机械臂在复杂场景抓取的鲁棒性。对不同尺寸、不同种类的工业零件进行分类和抓取,通过实验证明了目标检测和抓取位置检测算法的有效性。
随着工业机器人学的发展和硬件设备水平的提升,更加复杂、智能的算法应用可以更精确地优化此系统和控制模型。
