基于改进YOLOv3的安全帽佩戴检测算法
2024-01-16张旭董绍江胡小林牟小燕
张旭,董绍江,胡小林,牟小燕
(1.重庆交通大学机电与车辆工程学院,重庆 400074;2.重庆工业大数据创新中心有限公司,重庆 404100;3.重庆工业职业技术学院,重庆401120)
0 前言
目前,社会安全问题越来越受到重视,但是工业生产中相关安全事故仍不断发生。安全帽作为许多行业的关键防护工具,许多企业都明令要求员工在施工环境下必须佩戴[1]。但是由于相关企业监管不利,员工工作期间不佩戴安全帽的现象仍屡禁不止,致使相关安全事故频频发生。目前常通过安全员巡检或者视频监控等方式监管员工是否佩戴安全帽[2]。通过人工进行巡检的成本高并且效率低下,而视频监控最终也要依靠人力长时间观看监控视频。所以将机器视觉算法应用在检测工业环境中相关员工是否佩戴安全帽具有极其重要的研究价值。
目标检测是机器视觉领域的重要分支,它的出现为自动识别物体开辟了一种创新方式。它具有精确、迅速、可靠等优点,在安防、智能监控、人脸识别[3]、人机交互、机器人视觉、自动驾驶等诸多领域有极大的研究价值和应用前景,受到了学者们的广泛关注。目标检测算法的网络体系结构一般分为两大类:一类是以R-CNN[4](Region-Convolutional Neural Network)、Faster R-CNN[5]为代表的基于候选框提取的两级目标检测算法;另一类是以YOLO[6](You Only Look Once)、SSD[7](Single Shot multibox Detector)、RetinaNet[8]等为代表的基于回归的一级目标检测算法。两级目标检测算法包括两个检测阶段:第一阶段使用候选区域生成网络得到一个可能含有目标的候选框;第二阶段使用卷积神经网络完成对候选框内目标的类别预测以及位置预测。一级目标检测算法是端到端的算法,直接在卷积神经网络中提取特征预测目标的分类和位置信息,而不使用候选区域生成网络 (Region Proposal Network,RPN)。
在诸多目标检测算法中,YOLOv3算法受到研究人员的青睐。例如胡硕等人[9]提出了一种基于深度学习的多车辆跟踪算法;李泽辉等[10]提出基于改进YOLOv3的纹理瓷砖缺陷检测。这些针对特定场景优化后的YOLOv3算法均取得了较好的检测效果。同时,检测安全帽佩戴的识别算法也有相关研究,例如许凯、邓超[11]提出基于改进YOLOv3的安全帽佩戴识别算法,优化了YOLOv3算法,提高了安全帽识别的精确率,但其检测速度相对较慢。本文作者针对工业现场员工佩戴安全帽检测任务中存在目标尺度小、背景环境复杂以及实时性要求高等问题,基于YOLOv3算法提出了一种改进网络模型。首先优化YOLOv3的主干网络,优化原有的Darknet-53、降低网络复杂度以提高检测速度;再引入空间金字塔池化模块充分提取复杂环境下目标的特征;之后将CIoU损失函数作为定位损失函数以提高预测目标与真实目标框的拟合效果;最后通过增加第四尺度融合目标特征提取,以提高模型检测小目标的能力,针对安全帽数据集聚类出特有的先验框。通过以上改进来提高YOLOv3算法在安全帽佩戴检测应用中的精确度与检测速度。
1 YOLOv3算法介绍
YOLO系列网络直接对图像中的目标进行回归检测,因此对比目标检测中两级目标检测算法其检测速度相对较快。通过对比YOLOv1-YOLOv3网络的优缺点得出:第一代网络YOLOv1的检测精度低;YOLOv2在YOLOv1的基础上添加了多尺度的训练、高分辨率的分类器、批量标准化三处,使它在YOLOv1的基础上达到识别对象更多、速度更快以及预测更加准确的效果;YOLOv3基于YOLOv2添加了多尺度融合预测的方法、替换了骨干网络、将单标签分类改进为多标签分类。YOLOv3基本体系结构包括 3 个主要部分:特征提取主干网络层(Darknet-53)、检测层和分类层。
特征提取网络层为Darknet-53的特征提取算法,它由Convolutional以及Res unit模块组成,如图1所示。Convolutional模块中引入Batch Normalization(BN)算法进行数据归一化,加快了模型训练时的收敛速度,使得模型训练过程更加稳定,避免梯度爆炸或者梯度消失。并且起到一定的正则化作用,几乎代替了Dropout。采用Leaky ReLU激活函数在负轴保留了非常小的常数leak,使得输入信息小于0时,信息没有完全丢掉,进行了相应的保留。其公式如式(1)所示:
(1)
残差叠加的每个主体赋予不同的系数,分别为 1、2、8、8、4。残差叠加完成之后,将特征映射输出到下一个残差体,继续进行特征提取操作。加入残差网络,一方面,残差网络1×1的卷积减少了参数量以及计算量,总共将尺寸减少了32倍;另一方面,保证网络在更复杂的情况下仍然保持收敛。使网络结构可以更加深入从而得到更好的特征表达,有效提高了分类检测的效果,尤其对于小目标的识别检测。
检测层一共提取3个特征图,分别位于Darknet-53的中间层、中下层以及底层。最小输入尺度的特征图仅在检测层处理,另外2个尺度的特征图在被输入到检测层之前,先与处理过的较低维映射拼接,然后输入检测层。
分类层是以检测层生成的多尺度融合特征为输入,经过卷积之后输出特征,最后一层的通道数如式(2)所示:
δFilters=3⊗(4+1+δclasses)
(2)
式中:3表示不同大小的预测尺度13像素×13像素、26像素×26像素、52像素×52像素,其中13像素×13像素对应着较大尺寸目标,26像素×26像素用于中等目标的检测,52像素×52像素对小目标进行检测;4和1分别表示最终输出检测目标类别归一化后的中心坐标(x,y,w,h)以及置信度;δclasses代表检测目标类别数。此研究中检测类别为Person以及Hat 2个类别,因此δFilters为21。YOLOv3网络结构如图2所示。

图2 YOLOv3网络结构Fig.2 YOLOv3 network structure
2 YOLOv3网络的改进
2.1 改进YOLOv3的主干网络
原YOLOv3网络的Darknet-53包含了多个残差模块,导致其模型相对复杂,深层次的网络可以提取更多的特征信息,但是复杂的模型实时检测时速度会更慢。而安全帽以及人的特征信息并不丰富,因此复杂的网络模型反而对此类特征信息较少的目标检测任务效果并不是很好。针对这一问题,文中将YOLOv3主干网络中部分残差模块进行裁剪,从而降低其模型复杂度,裁剪之后的主干网络最终保留3个残差模块以获取足够的特征信息。为了保证4个分类层的特征输出,在主干网络中引入4个池化层。裁剪后的主干网络(Backbone)如图3所示。

图3 改进后的BackboneFig.3 Improved Backbone
2.2 空间金字塔池化模块
不同监控场景下人员分布不均、远近不同导致图像的尺度变化较大,难以对目标特征进行全面提取。针对上述问题,文中引入空间金字塔池化[12](Spatial Pyramid Pooling,SPP)模块进一步提升网络提取特征信息的能力。SPP是HE等为解决不同图像尺寸输入神经网络之后无法较好地提取特征,影响最终检测结果而提出的一种方法。SPP先对图片进行分块池化,并保证从不同模块中提取的特征图维度一致,以解决尺度不统一和信息丢失的问题。同时,因为特征图中的通道数被扩展为三通道,所以引入SPP之后可以使YOLOv3网络获取更为有效的全局信息,不仅解决了检测层中输入特征图尺度变化的问题,还使得特征图的全局特征以及局部特征得以更好融合。SPP模块的结构如图4所示。
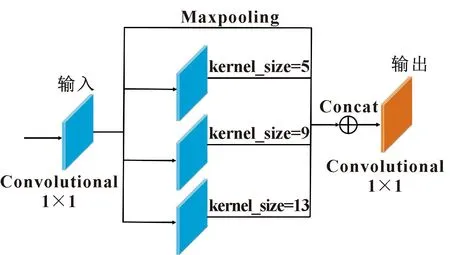
图4 SPP网络结构Fig.4 SPP network structure
2.3 定位损失函数
IoU是目标检测中最重要的性能指标之一,表示真实标注目标框与预测目标框的交并比,其计算公式如式(3)所示:
(3)
其中:Ppred表示目标预测框;Ptrue表示目标真实标注框。δIoU的大小反映了目标的检测效果。但是如果目标预测框与真实目标框没有交集,IoU则无法反映此时真实框与目标框的距离,导致无法计算传播梯度。为解决这一问题,文中引入CIoU损失函数。CIoU损失函数不仅考虑了重叠率以及目标与Anchor之间的距离,还考虑了尺度以及惩罚项,从而使目标框回归变得比IoU更稳定。CIoU损失函数不会出现无法计算梯度的情况,并且CIoU对尺度变换敏感,收敛速度比IoU更快。CIoU损失函数计算公式如式(4)所示:
(4)
式中:ρ2(B,Bgt)为真实框和预测框中心点的欧氏距离;a为权重参数;v为衡量长宽比一致性的参数;c为同时包含真实框以及预测框的最小矩阵区域的对角线距离,如图5所示,图中d=ρ2(B,Bgt)。a和v的计算公式分别如式(5)(6)所示:
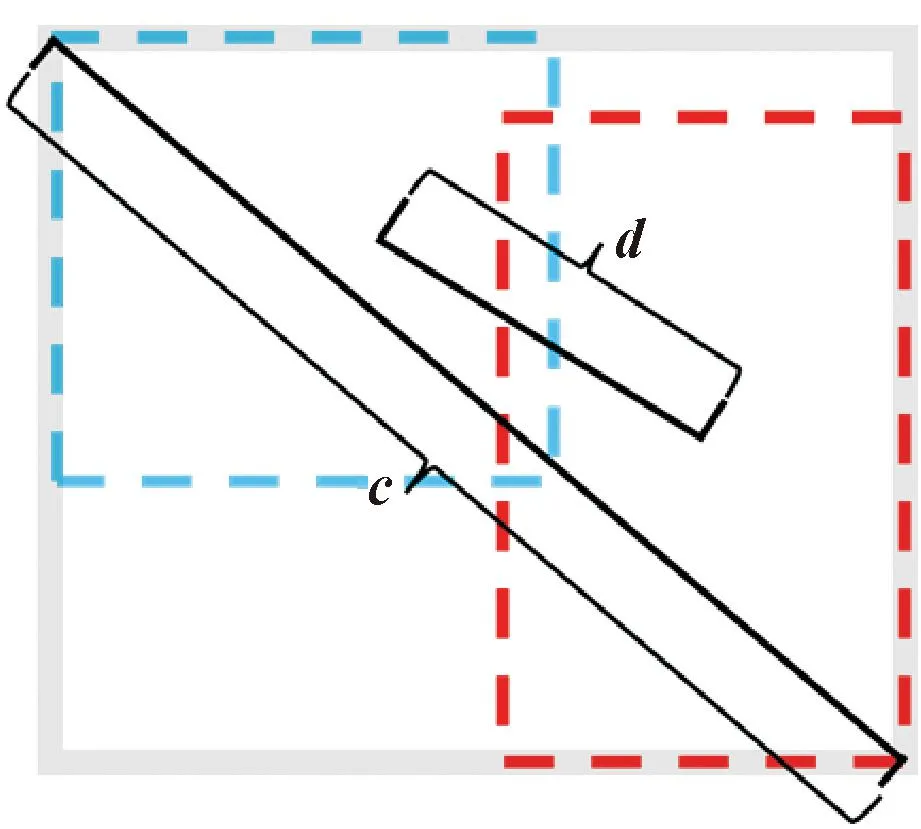
图5 CIoU计算示意Fig.5 CIoU calculation
(5)
(6)
式中:ωgt和ω、hgt和h分别代表真实框和预测框的宽、高。
2.4 K-means聚类算法
K-mean聚类算法内容如下:随机选取k个聚类质心,μ1,μ2,…,μk∈Rn,计算每个样例i所属的类:
(7)
重新计算每一个类j的质心:
(8)
重复式 (6)和 (7)直到收敛。
YOLOv3利用Anchor Boxes对边界框进行定位预测。由于数据集中目标图像之间尺度变化较大,所以需要根据数据集先聚类出其特有的Anchor Box。因为此研究最终有4个尺度的输出,所以经过K-means聚类后总共生成了12组先验框,各组先验框的大小分别为(5,10)、(6,12)、(7,16)、(8,13)、(8,17)、(10,21)、(14,25)、(18,31)、(24,42)、(34,58)、(51,88)、(92,157)。
2.5 多尺度融合目标特征提取
目标特征的提取是目标检测的基础,YOLOv3通过Darknet-53主干网络进行特征提取,再通过上采样以及同维拼接最终输出3个特征尺度对目标进行预测,3个尺度的大小分别是13像素×13像素、26像素×26像素、52像素×52像素。多尺度输出的特征图特点不同,低层级特征图语义含义不够丰富但精度高,高层级特征图语义含义丰富但精度低。特征图越大对应输入图像中每一网格区域越小。由于小目标的目标区域相对较小,经过多层卷积和下采样之后可能造成有效特征信息的丢失,从而导致检测精度下降。针对此问题,文中在原始YOLOv3 三个特征尺度的基础上扩展一个104像素×104像素的多尺度融合特征,对小目标进行预测。改进后的YOLOv3网络会提取出4个尺度的图像特征,然后分别在4个尺度特征层上进行目标检测。改进后的YOLOv3网络结构如图6所示。其中Big Target、Medium Target、Small Target、Super Target分别对应13像素×13像素、26像素×26像素、52像素×52像素、104像素×104像素4个特征尺度。
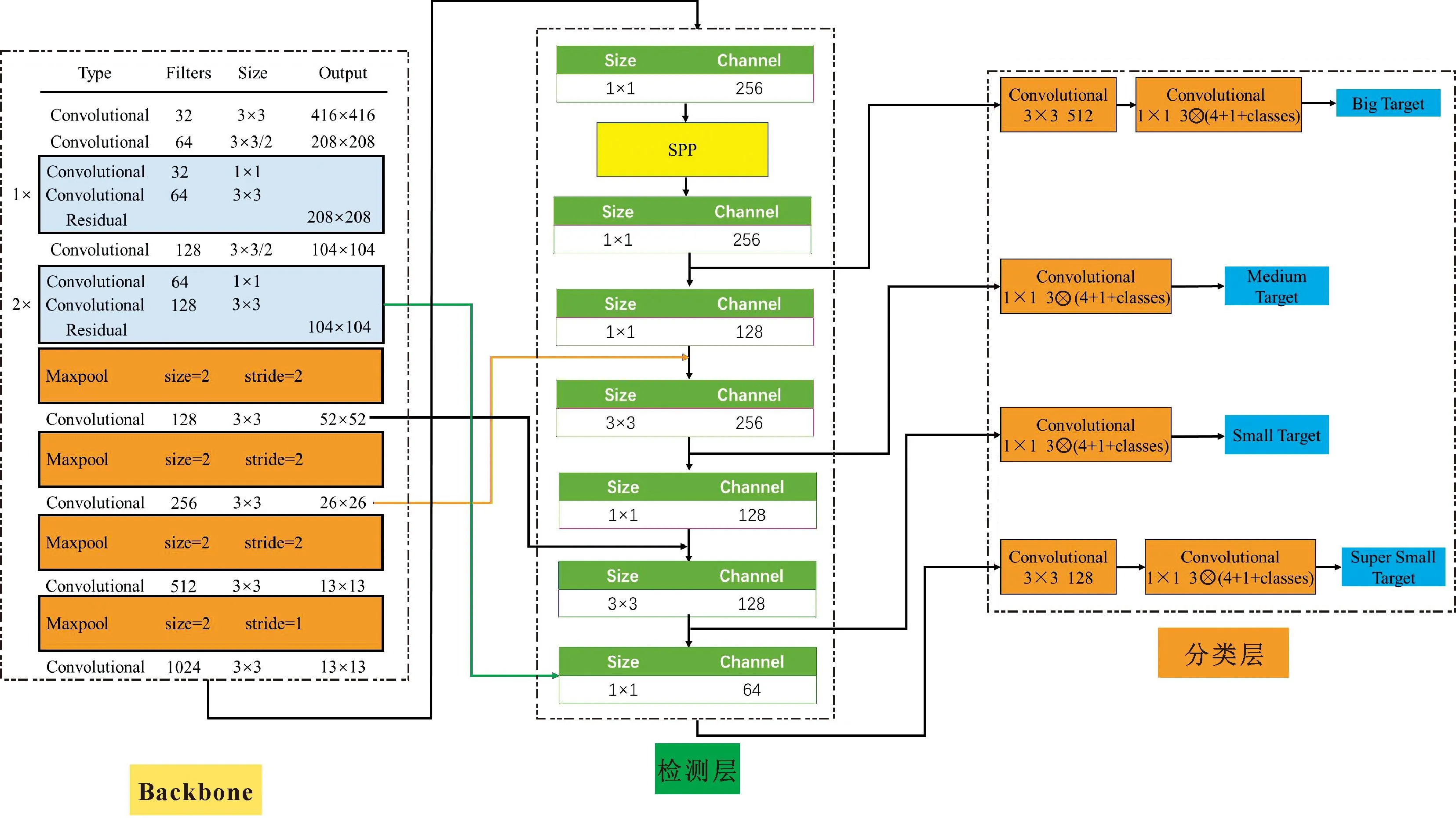
图6 改进后的YOLOv3网络结构Fig.6 Improved YOLOv3 network structure
3 实验结果及分析
3.1 实验环境
实验环境为Windows操作系统,11th Gen Intel(R)Core(TM)i5-11400F(CPU),16 GB随机存取内存(RAM),RTX 3060(GPU),12 GB显示内存,深度学习为Pytorch。数据集分为佩戴安全帽的工人(Hat)和未佩戴安全帽的工人(Person)2个类别,共计6 721张图片,其中验证集和训练集的比例为1∶9。网络训练采用带动量的随机梯度下降算法,初始学习率为0.01,动量因子为0.9,学习率衰减策略为Steps,批量大小为12,输入图片大小为416像素×416像素,训练轮数150。
3.2 评价指标
文中选择目标检测中常用的评价指标平均精度mAP(mean Average Precision)以及检测速度FPS对模型进行评价(FPS是指每秒能检测图像的数量,是衡量模型检测速度的重要指标)。最终检测结果分为4类:真正例(TP)、假正例(FP)、真负例(TN)和假负例(FN)。
精确率P以及召回率R是计算mAP的重要指标,其中精确率表示模型真实预测目标总数和预测结果的目标总数的比值,召回率表示真实预测目标总数与数据集中实际目标总数的比值。计算公式如下:
(9)
(10)
以精确率为横轴、召回率为纵轴可以得到精确率召回曲线,称为P-R曲线。每一类识别对象的P-R曲线与坐标轴围成的面积为该类的精度值(AP),mAP则是所有AP的平均值。AP与mAP的计算公式如下:
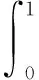
(11)
(12)
式中:N为2,表示2个目标类。
3.3 实验结果及分析
文中将YOLOv3剪切之后集成SPP结构以及改进的CIoU损失函数模型(YOLOv3-tiny-SPP-CIoU,YOLOv3-tsc),在YOLOv3-tiny-SPP-CIoU引入第四检测尺度的模型(YOLOv3-tiny-SPP-CIoU-obj4,YOLOv3-tsco)以及在YOLOv3-tiny-SPP-CIoU-obj4基础上改进主干网形成的最终网络(YOLOv3-tscox)与原YOLOv3进行对比实验。实验结果如表1所示。
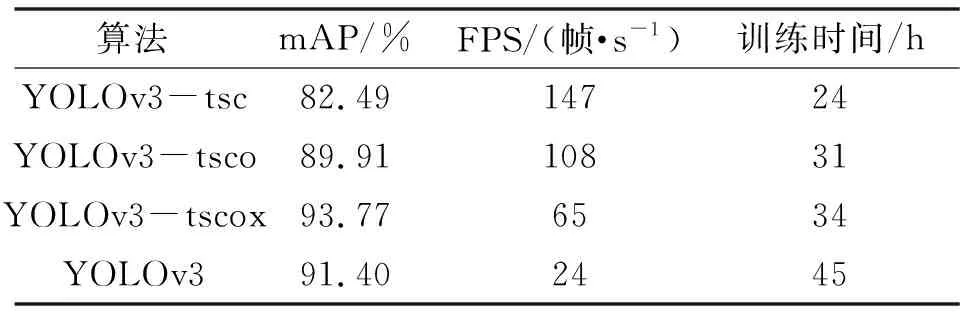
表1 改进的YOLOv3和原YOLOv3对比结果Tab.1 Improved YOLOv3 and YOLOv3 comparison results
从表1中可以看出:YOLOv3-tsc模型因为模型相对简单、网络参数量很少,所以识别速度最快,每秒可识别147帧并且其训练时间也相对最短,但是其mAP只有82.49%,无法满足实际需求;文中最终模型YOLOv3-tscox相对YOLOv3精度提高了2.37%,其检测速度能达到每秒识别65帧,比YOLOv3更快,检测速度提升了2.7倍。分析结果表明了文中对YOLOv3的改进是有效的,不仅提高了YOLOv3的识别精度,而且还使其FPS得到了较大的提升。
为进一步验证所提出的模型在安全帽佩戴检测上要优于其他目标检测算法,使用相同的安全帽佩戴数据集对Faster R-CNN、SSD、RetinaNet以及YOLOv3-tscox等目标检测算法进行安全帽佩戴检测任务的训练与测试,实验结果如表2所示。
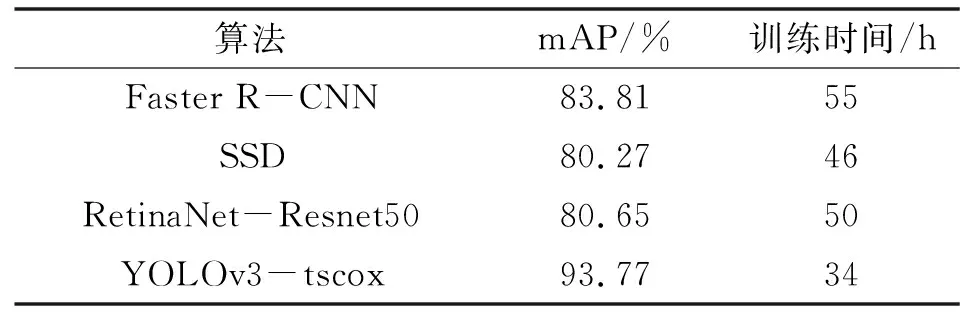
表2 不同检测算法结果对比Tab.2 Results comparison of different algorithms
从表2中可以看出:无论是单级检测器SSD还是两级检测器Faster R-CNN,其平均准确率均低于改进模型,并且训练时间更长。证明了改进的YOLOv3在安全帽佩戴检测上相比于其他目标检测网络检测效果更好。
3.4 图片检测效果
分别选取工厂室内复杂环境、工地室外复杂环境、模糊干扰环境以及目标较为密集4种不同环境下的4张图片进行测试,结果如图7所示。

图7 检测结果Fig.7 Test results:(a)indoor complex environment; (b)outdoor complex site environment;(c) fuzzy interference environment;(d)target more dense environment
对比图7(a)可以看出:在工厂室内复杂环境中进行检测时,图7(a1)中出现了将其他物体误检为头盔,而图7(a2)准确识别出3个目标对象;图7(b1)中在室外复杂的工地环境下漏检了一个目标,图7(b2)完全识别出4个目标;图7(c1)在相对模糊并具有干扰的环境YOLOv3也出现了漏检的情况,而改进的网络则检测无误;图7(d)为密集环境下进行目标检测,此时图7(d1)不仅出现了漏检还将戴有头盔的工人误检成了未戴头盔,而图7(d2)则识别无误。分析以上检测结果可以得出:此研究中的模型降低了安全帽识别的漏检率以及误检率,模型检测效果明显优于原YOLOv3。
4 结论
针对目前通用目标检测算法在工业环境下的安全帽检测上精确度低、误检率、漏检率高以及检测速度慢的缺点,作者提出了基于YOLOv3的安全帽佩戴检测方法。首先将原YOLOv3进行裁剪,改进之后大大提高了检测速度,但是精确度降低了很多;为了提取更多的特征信息,在裁剪的YOLOv3基础上引入了空间金字塔池化结构,使浅层与深层的特征信息更好地融合;通过增加第四融合尺度提高小目标的识别精度,解决了小目标漏检问题;同时使用CIoU替换IoU提升了目标预测框与真实目标框的拟合效果。结果表明:改进的网络模型对安全帽佩戴的检测有更高的检测精度以及更快的检测速度,并且相对于原网络的训练时间也更短。下一步工作将研究基于YOLOv3改进算法的MES系统在复杂工厂环境下的实际应用,以网络摄像头实时检测代替人眼目视检查。
