基于改进多智能体PPO的多无人机协同探索方法
2024-01-15安城安周思达
安城安, 周思达
(云南民族大学电气信息工程学院,昆明 650000)
0 引言
无人机可应用于未知环境探索,当其不断收集环境信息时,如何规划机器人的最优路径成为需要解决的问题[1]。无人机在未知环境中进行探索时,会遇到定位不确定性较大、决策时间长、探索速率慢和鲁棒性差等困难。多智能体系统将问题拆分成若干小问题分配给单个智能体,智能体间进行信息共享、互相配合以找到复杂问题的解决方案。其与单智能体系统相比,提高了系统可靠性、鲁棒性与高效性,但也为系统的部署增加相当大的负担。当机器人规模增大时,集中式组织架构中央单元承受更多的计算负荷,分布式组织架构部署困难,增加了协调方法的设计难度,而存在多个分布式管理单元的混合式架构方法设计与架构部署难度过大,难以应用于现实场景,且多智能体之间通信能力有限,也成为一大难题。另外,非结构环境是一种难以提取特征的复杂环境[2],启发式方法难以形成合理有效的边界点。常见的启发式未知环境探索的原理为在已探测环境选择最好观测点作为目标点并驶向该目标点,多次迭代,完成对整个工作环境的遍历[3]。传统RRT方法具有盲目探索的问题,机器人会生成大量无关分支路径[4],需大力提升算力。
强化学习(RL)是机器学习领域中与监督学习、无监督学习并列的第3种学习范式,其与环境进行交互来学习,最终实现累积收益最大化[5]。深度强化学习最早将强化学习中的 Q-Learning 方法与神经网络结合,形成了 DQN(Deep Q Network)方法。然而,DQN方法存在一定的局限性,其只适用于离散动作空间的应用场景。LILLICRAP等[6]提出了DDPG(Deep Deterministic Policy Gradient)方法,该方法采用演员-评论家框架,可应用于连续动作空间;唐超等[7]使用DDPG方法实现了蛇形机械臂在2D平面对目标物的快速精确逼近。
周翔等[8]对 DDPG 方法进行改进求解微网优化调度问题;申怡等[9]在此基础上提出基于自指导动作选择的近端策略优化算法。近年来,多智能体深度强化学习得到了发展;LIN等[10]用MADDPG方法通过联合优化任务分层卸载和资源分配来最大化处理效率;蔡新雷等[11]提出了基于改进K-means和多智能体深度确定性策略梯度(MADDPG)算法的风储联合系统日前优化调度方法;李波等[12]将MADDPG应用于多无人机协同任务决策;YU等[13]提出了MAPPO方法。强化学习结合深度学习,可减少系统的负担,降低系统运行的算力要求,且深度强化学习可通过不断训练实现测试效果的提升,而启发式方法大多取决于选取的边界点是否合理。综上所述,多无人机多线程未知环境协同探索是多架无人机在合理的时间内、在不干扰彼此任务进度的前提下获得尽可能多的关于周围的信息,以达到覆盖未知环境的过程。为了更真实地模拟多无人机在未知环境协同探索,开发了一种多无人机多线程二维探索仿真环境,模拟创建初始非结构化地图并在该地图上创建多架仿真无人机,通过给每架仿真无人机创建对应的线程,并控制各架仿真无人机在对应的线程飞行,将每架无人机的当前探索数据输入到多智能体深度强化学习方法模型中,生成二维探索地图,以实现多架无人机在同一幅初始地图中进行多线程探索。
本文针对MADDPG方法与非共享网络 MAPPO方法在使用连续动作学习时训练后期学习效果下降,以及多线程仿真环境经验池容量随智能体数量增加而增加的问题,多智能体之间的关系主要包含合作、竞争、利己主义者以及合作-竞争混合型4种。其中,合作型已经应用于机器人[14]、分布式[15]、交通[16]、网络智能[17]、无人机编队控制[18]等领域。上述共享MAPPO方法采用合作型关系。另外,为解决幕内(in-episode)记忆的问题,本文通过引入循环神经网络中的LSTM(Long Short Term Memory)技术,使每幕的奖励总和得到了提升。本文搭建了二维多无人机多线程非结构仿真环境,多线程用来更真实地模拟无人机航行,与常见的多智能体深度强化学习算法进行了对比。
1 二维多无人机多线程非结构仿真环境
本文以小型固定翼无人机为研究对象。为实现强化学习训练,搭建典型无人机模型的二维多无人机多线程仿真环境。
固定翼无人机的机翼位置、后掠角等参数是固定不变的,与旋翼、扑翼等无人机不同,由于其具有飞行距离长、巡航面积大、飞行速度快、飞行高度高、可设置航线自动飞行和可设置回收点坐标自动降落等优点,被广泛应用于物流、救灾等行业。二维多无人机多线程非结构仿真环境分为仿真系统与奖励系统,其中,仿真系统基于固定翼无人机飞行动力学实现,奖励系统基于探索目标以及多智能体关系实现。为搭建仿真环境,对固定翼无人机飞行动力学进行建模,采用图1所示固定翼无人机动力学模型。
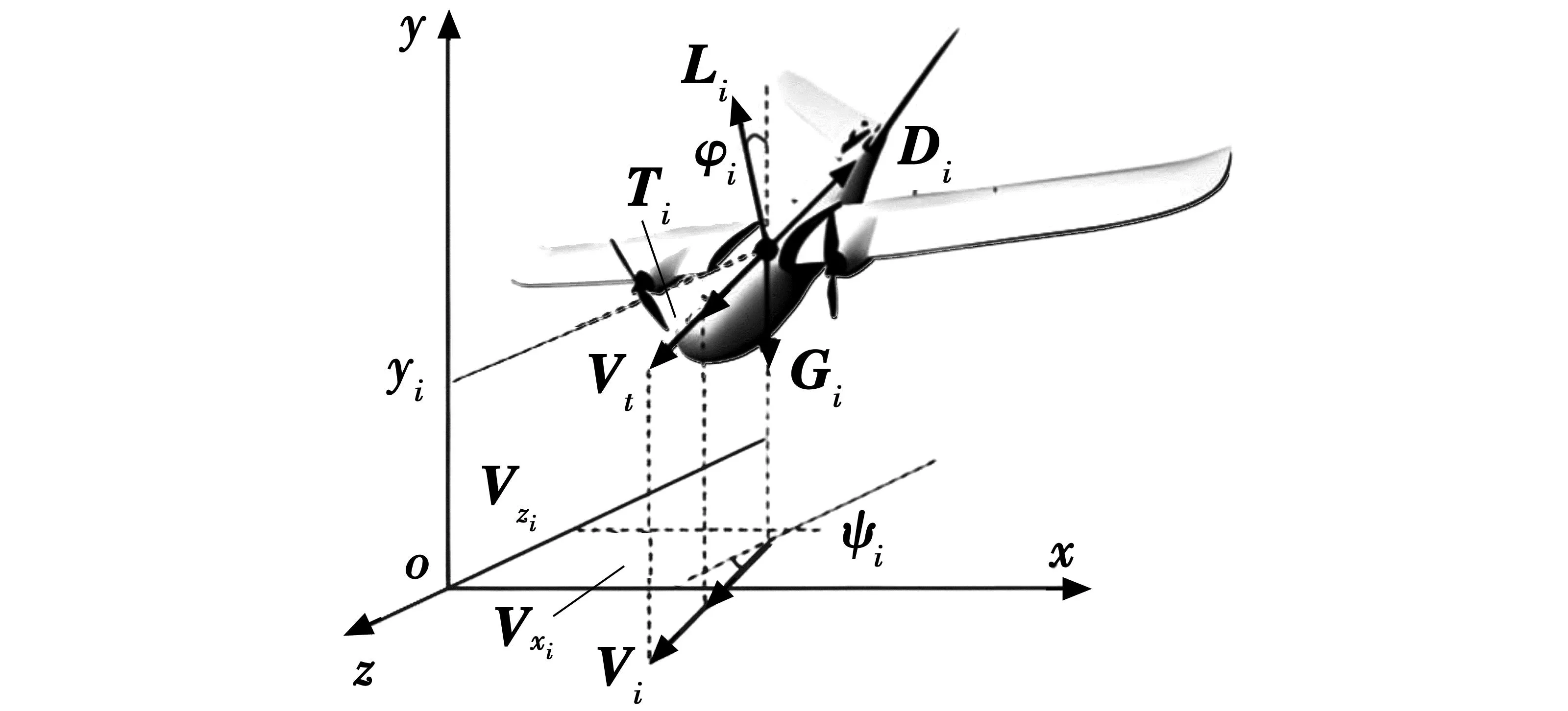
图1 固定翼无人机动力学模型
图1中:Vi为对地速度;Vxi是x轴方向的速度;Vzi是z轴方向的速度;Ti为前向航行力;Di是后向航行力;yi是无人机的高度;Li是升力;φi为俯仰角;ψi为水平偏转角;Gi为重力。
参考文献[19]的数学模型,可得
(1)
(2)
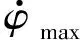
(3)
(4)

本文针对未知环境下多无人机协同探索的连续动作强化学习多线程训练问题进行研究。未知环境本质上是指并未被探索的环境,无人机在环境中不断探索使未知环境不断变成已知环境。多无人机探索时,系统的复杂程度会提升,而在真实场景中,每架无人机的航行任务应该是独立的,因此引入多线程训练技术使每架无人机的航行任务相互独立。图2为多线程航行的模拟示意图。
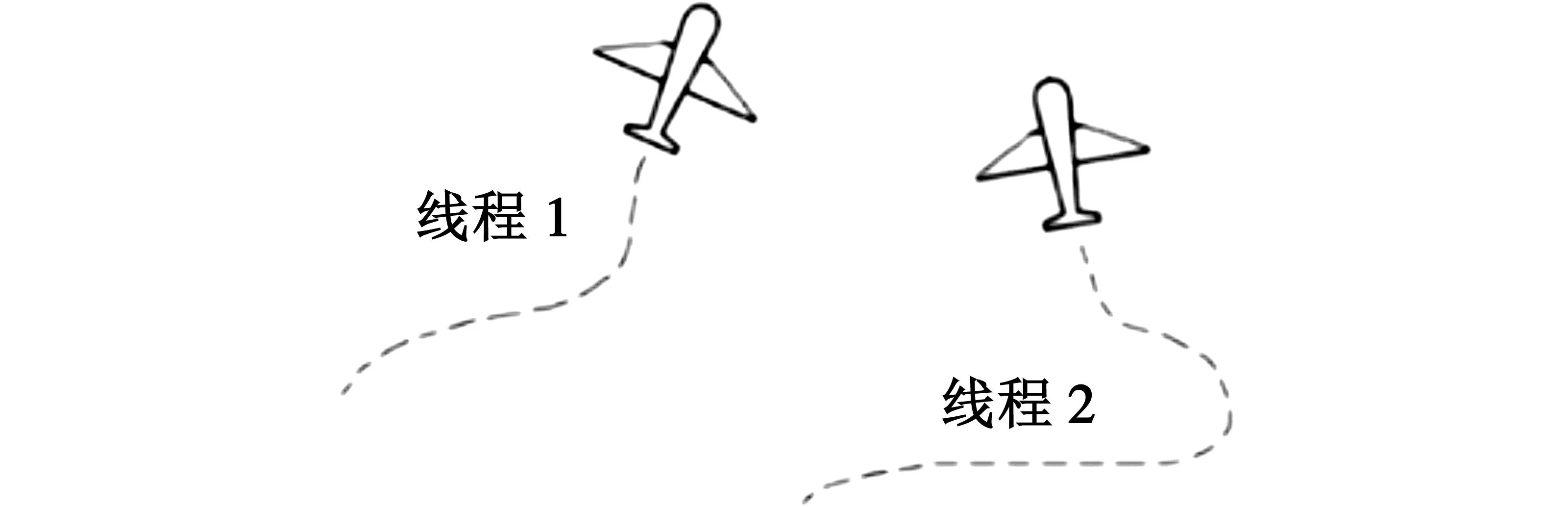
图2 多线程航行示意图
二维多无人机多线程仿真环境通过指定随机种子生成特定二维非结构环境地图,该地图可以模拟高原山地环境的非结构特点。在仿真环境中,黑色区域代表障碍物区域,白色区域代表可行区域。首先,根据指定的随机种子创建随机数矩阵;其次,将随机数矩阵中的数值大于0.503的元素赋值为1,代表不可航行区域,小于或等于0.503的元素赋值为0,代表可航行区域;然后,将计算好的矩阵输入到预置的滤波器中,生成粗地图;最后,在粗地图上创建探索层,生成初始探索地图。探索层由一层灰色的同等大小的矩阵模拟,当无人机进行探索时,对应的灰色区域会变白。图3为探索示意图。

图3 探索示意图
多智能体深度强化学习方法常采用集中式训练与分布式执行相结合的方法。每个智能体共享彼此的动作与获得的信息[20],以此实现共同学习。其中,动作的共享可以由算法实现,以此共享策略以稳定收敛。而信息的共享通过仿真环境全局变量实现。
图3(c)为智能体的局部观测获得原理,在全局信息中找到无人机所在的位置与位姿,根据固定翼无人机飞行动力学模型,其在二维环境中的观测可以模拟成一个扇形区域的内容,在对应的局部信息中找到扇形区域对应的区域。
与单架无人机的模拟仿真不同,有时两个或多个无人机的扇形区域会发生重叠现象。在有限通信环境下模拟仿真这部分的短距离通讯。
在用来表示扇形区域的矩阵中重叠区域的数值会经过计算后变成特殊的数值,原本扇形区域中禁飞区域表示成1,灰色未探索区域表示成0.6,已探索区域表示成0。经过
Y=nDown(x-0.6)+x
(5)
计算后,重叠区域会根据重叠程度的不同得到不同的数值。式中:Y为重叠区域的最终表达数值;n为该点重叠的扇形区域数量;Down(·)函数功能为向下取整;x为原始区域数值。设置这样的转换函数可以使禁飞区、灰色未探索区域的数值不会发生变化,而使重叠的已探索区域发生变化。
为了避免无人机数量过多导致因最大可重叠扇形数而引起的Y值在数轴负方向发生的数值增加,可以对其进行归一化,即
Y′=Y/n
(6)
式中,Y′为Y小于0时的最终输入。为得到更有实用价值的实验结果,仿真环境可以输入连续的动作进行模拟,连续动作体现在每一步的偏航角上,离散动作则是将偏航角平均拆分几份根据价值或概率选择动作方向,图4为连续动作与离散动作的示意图,其中,-0.437表示神经网络输出的连续动作,取值范围[-1,1]。
强化学习的训练离不开奖惩函数的设计,在二维非结构多线程多无人机仿真环境中,固定翼无人机探索未知环境的优化目标需要考虑两个因素:1) 当前步新探索的区域大小;2) 无人机是否坠机。与单无人机未知环境探索仿真相比,当前步新探索区域大小的计算需要考虑重叠区域,在合作型探索情况下,奖励的处理要增强重叠区域的影响。无人机坠机则给予值为-1000的惩罚。得到奖励函数为
(7)
式中:Rpoint为新探索的区域像素点数量;state为当前状态;done代表坠机;Rbase为这一步的奖惩数值,Rother在发生重叠时取这一步与之重叠的智能体的base奖励乘以数值为10%的权重,当没有发生重叠时取0。
基于文献[21]的仿真系统,多无人机协同探索需要考虑彼此航行的安全性,为避免合作型无人机彼此之间航行过于紧密,每架无人机均设置了威胁区。当两个无人机威胁区交点过于接近阈值时,则获得值为-100的惩罚Rthreat。图5为威胁区的设置与相交示意图。
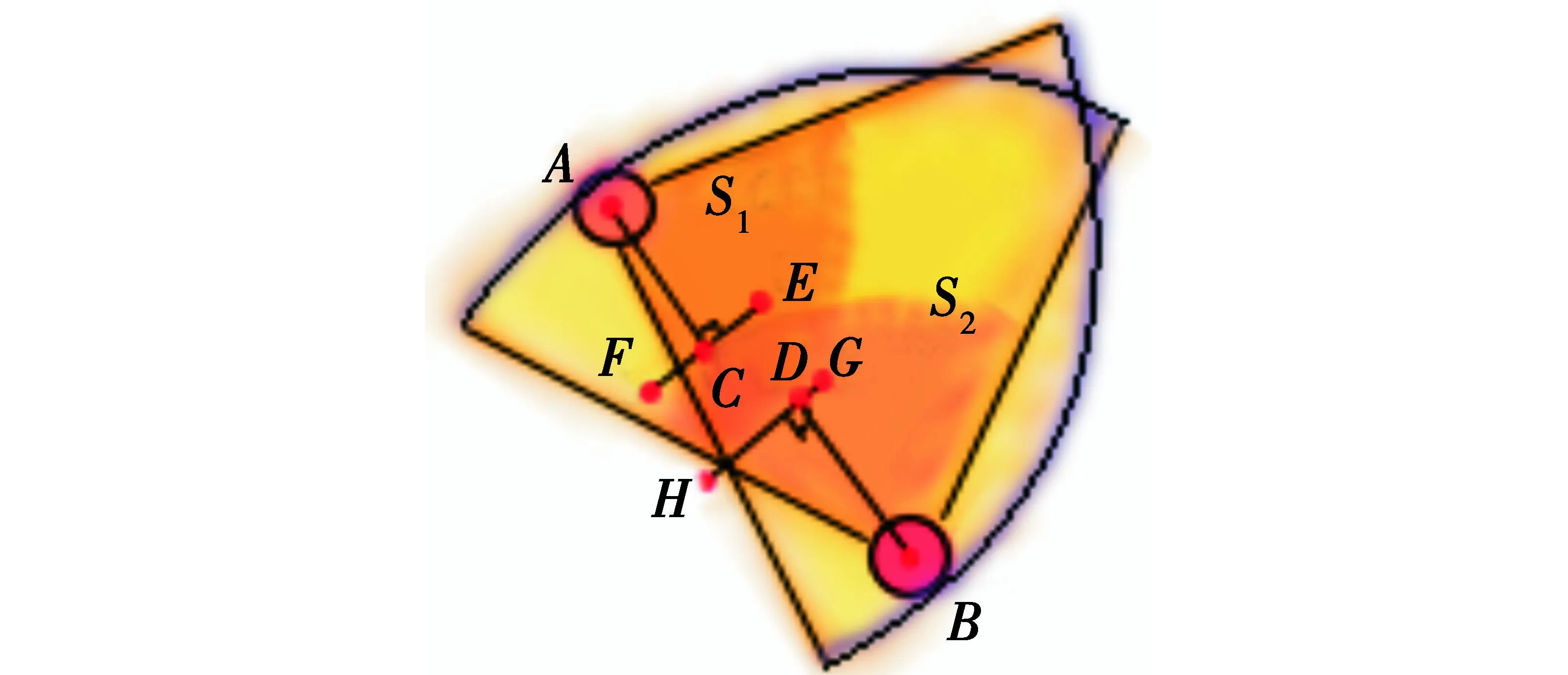
图5 威胁区的设置与相交
图5中:S1,S2分别是两架位于A,B点的无人机形成的威胁区;C,D点为威胁点;线段EF是威胁区S2在C点针对AC形成的切线;线段GH是威胁区S1在D点针对BD形成的切线。对于位于A点的无人机来说,当AC的值越小,生成的惩罚越大。同样,对于位于B点的无人机来说,惩罚项也是随着BD的减小而增大。因此最终的奖惩函数为
R=Rbase+Rthreat。
(8)
2 共享MAPPO方法
PPO是一种on-policy方法,但其可通过重要性采样技术(Important-Sampling)实现离线更新。与DDPG方法采用时间差分框架来实现不同,其使用蒙特卡罗框架。
图6描述PPO方法是如何进行神经网络更新的,每一幕通过当前神经网络与环境进行交互得到样本数据。

图6 PPO原理图
采用Actor-Critic框架的PPO方法与TRPO方法都采用了surrogate计算方法,即
(9)
(10)
(11)
2021年YU等[13]提出了MAPPO方法,该方法与多智能体深度强化学习常采用的MADDPG方法一样采用全局的Critic来减少值函数的方差,通过中心值函数考虑全局信息,其前身为完全分散式的PPO方法。与MADDPG以及DDPG方法采用批量标准化(Batch Normalization)机制不同,MAPPO方法采用PopArt的Value Normalization机制以解决多智能体强化学习方法的不同任务遇到的问题,方法还通过改良全局状态信息输入到Critic网络,以保证更好的训练效果。YU还说明个别环境可以通过避免使用mini-batch来减少数据重复利用的次数,以及设置某些动作无法执行以加速训练,智能体如果死亡可以在智能体特性中用0来描述,这些设置令MAPPO方法可以取得优于MADDPG方法的效果。
由于非共享网络MAPPO方法与MADDPG方法在处理连续动作时,训练后期会造成动作在可选动作空间边界来回震荡的不良现象,故本文采用共享网络MAPPO方法。由于本环境中模拟的无人机种类相同,故每架无人机训练时可以共享神经网络共享策略,将神经网络的输入顺序对应好本无人机和其余无人机的观测、动作等顺序,设置Critic网络保留了PPO方法没有输入动作的特点,只输入每架无人机的观测,以保证训练后期不会出现动作取边界值。
使用MAPPO方法的每个智能体可以用同一种策略网络,也可以独自学习。为了便于学习到合适的策略,同时方便共享策略。而在多线程训练环境下,由于每个智能体的航行任务相互独立,因此如果用传统的多智能体深度强化学习方法进行训练,每个智能体都存储经验会导致所有经验池的总需求容量会随智能体数量增长而增大。解决方法是,指定0号智能体为经验存储智能体,每个智能体均可共享其存储的经验。同时,受文献[21]的训练方法启发,在训练时,神经网络输入的信息除了包含局部信息外,还包含已探索的全局信息,局部信息与全局信息是数值为0~255的灰度图矩阵。
长短时记忆(LSTM)神经网络由输入门、输出门和遗忘门3个门组成。多个LSTM神经元组成完整的功能结构。图7为LSTM网络神经元示意图,其中,Ct-1代表上一神经元的状态,ht-1代表上一神经元的输出,Ct代表当前神经元的状态,ht代表当前神经元的输出,Xt代表神经元的输入。
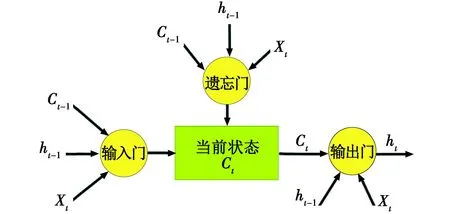
图7 LSTM网络神经元示意图
通过遗忘门和输入门,LSTM可以决定信息的记忆,保留有用的信息。
循环神经网络减少了需要学习的参数量,但是很难捕获较长序列之前的信息,可能会出现梯度消失和梯度爆炸的问题。LSTM网络适用于处理和预测时间序列中间隔和延迟非常长的重要事件。
本实验在单台主机上进行,配置为系统主机Ubuntu20.04,内存16 GiB,硬盘1 TiB,CPU i7-TS80S,显卡T400。
首先比较不同多智能体深度强化学习算法MADDPG与MAPPO方法在连续动作下的运行效果,得到每幕奖励值随幕数变化的曲线。由于多线程训练时同样的随机种子也会产生不同的训练结果,因此采用3次训练结果取平均值方案得出数据。得到实验结果见图8。
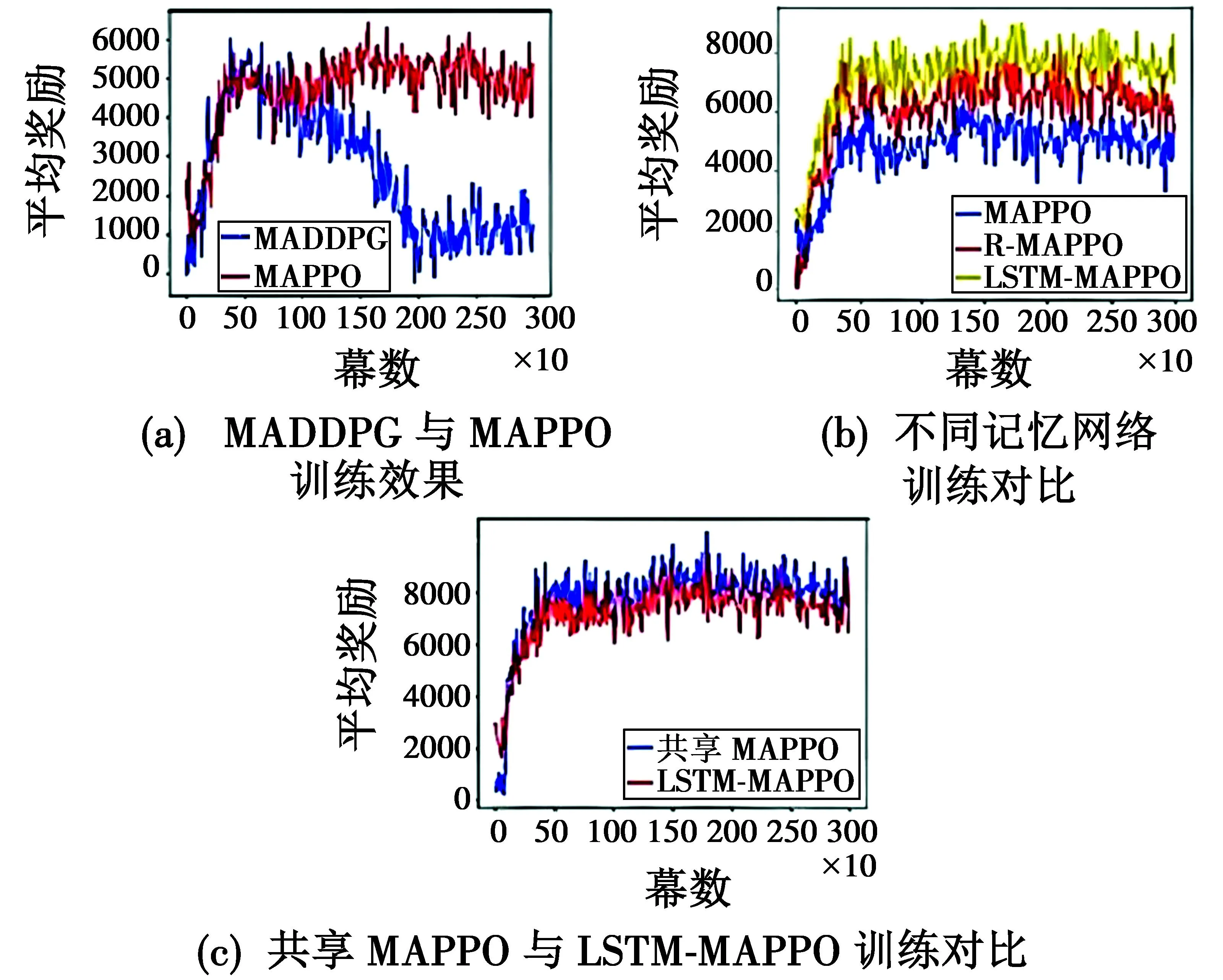
图8 实验结果
在图8(a)的实验过程中,调节参数如表1所示。

表1 参数设置
分别比较结合循环神经网络和LSTM神经网络的MAPPO的训练效果,前者简称R-MAPPO,后者为LSTM-MAPPO。由图8(b)可见,结合了LSTM的长短时记忆网络训练效果得到了提升,最高平均奖励优于循环神经网络以及MAPPO。最后,引入全局观测边界信息,使无人机探索能力得到提升,将结合了全局观测边界信息的LSTM-MAPPO方法定义为共享MAPPO方法。
由图8(c)可知,共享MAPPO方法训练时平均奖励可以稳定在5000以上。将训练好的网络用来测试,3张地图每张用3架无人机运行3次得到测试结果见图9。

图9 网络测试结果
通过分析探索的像素可知,在多线程多无人机未知环境探索仿真环境下,3张测试地图中每张地图都可达到70%以上的未知环境覆盖。
3 结束语
本文研究了多无人机多线程仿真环境下无人机协同探索问题,用一个二维栅格地图构建非结构化环境,且针对非共享网络MAPPO以及MADDPG方法因Critic网络结构所造成的训练后期智能体频繁选择连续动作边界的不良现象,提出了一种结合LSTM-MAPPO与全局边界信息的适应多线程仿真环境的多无人机多线程协同探索方法,该方法可以在没有人为指导的情况下使无人机能自主学习探索二维未知环境。使用LSTM网络和全局边界信息可以有效提升探索效果,而且提出的共享MAPPO方法有效解决了多线程环境下经验池容量爆炸的问题。与LSTM-MAPPO方法相比,平均每幕获得的奖励值更高。在接下来的研究中,将尝试三维仿真环境下的多无人机多线程连续动作协同探索,并考虑更多复杂环境因素下的训练策略设计。
