基于报文匹配与GRU-ATT模型的协议逆向分析方法
2024-01-11付饶袁丁刘琦史晓桢李丹奇




摘 要: 针对未知网络协议逆向分析中的报文分类问题,提出了一种基于报文交互匹配与GRU-ATT模型的未知网络协议逆向分析方法MemProRe,结合多序列比对和深度学习方法,采用基于注意力机制的CNN-GRU-Attention网络,在客户端与服务器端交互报文集合之间的一致性约束条件下,将双端报文分类的结果进行特征融合,从而实现未知网络协议的报文分类.实验结果表明,MemProRe方法能够有效解决报文分类的冗余问题,提升了报文分类的精确率约10%以上.
关键词: 协议逆向分析;多序列比对;报文交互匹配;门控循环单元;注意力机制
中图分类号:TP391"" 文献标志码:A"""" 文章编号:1673-4807(2024)06-076-07
收稿日期: 2023-11-14"" 修回日期: 2021-04-29
基金项目: 国网江苏省电力有限公司科技项目(J2022014)
作者简介: 付饶(1987—),男,高级工程师,研究方向为电力调度自动化、网络安全.E-mail: 19952190332@139.com
引文格式: 付饶,袁丁,刘琦,等.基于报文匹配与GRU-ATT模型的协议逆向分析方法[J].江苏科技大学学报(自然科学版),2024,38(6):76-82.DOI:10.20061/j.issn.1673-4807.2024.06.012.
Protocol reverse analysis method based on message matching and GRU-ATT
FU Rao, YUAN Ding, LIU Qi, SHI Xiaozhen, LI Danqi
(State Grid Xuzhou Power Supply Company,State Grid Jiangsu Electric Power Co. Ltd., Xuzhou 221000, China)
Abstract:Aiming at the problem of message classification in unknown network protocol reverse analysis, we propose an unknown network protocol reverse analysis method based on message interaction matching and GRU-ATT model, named MemProRe. Coupled with multiple sequence alignment and deep learning methods, it adopts CNN-GRU-Attention network based on attention mechanism. Under the condition of consistency constraint of the interaction message set between the client and the server, the features of the double-end message classification results are fused to realize the message classification. The experimental results demonstrate that the MemProRe can effectively solve the problem of redundancy of message classification and improve the accuracy of message classification more than 10%.
Key words:protocol reverse analysis, multi sequence alignment, message end-to-end matching, gate recurrent unit, attention mechanism
计算机网络与通信技术的不断发展和广泛应用,使得网络结构变得日益复杂,工业控制网络、车联网等物联网的出现则使网络形态更具多样化,随之而来的则是大量的未公开的、专用的网络通信协议不断涌现.然而,网络安全分析需要精确地理解网络协议规范,协议逆向分析技术(protocol reverse analysis, PRA)能够从未知网络协议中抽取协议规范和格式,因而得到了深入地研究.
近年来,自动化网络协议逆向技术已逐渐取代了效率较为低下的人工协议分析方法,涵盖了协议规范推断到协议行为理解等阶段.协议逆向分析方法根据数据来源主要分为两类:基于指令序列的分析方法和基于网络流量的分析方法[1-2].前者将指令执行轨迹作为分析对象,但依赖协议实体,整体适用性较差;后者根据网络流量的协议数据单元集合进行推断,其时效性更强,适用性也更好.因此,文中重点关注基于网络流量的协议逆向分析方法研究.
基于网络流量的协议逆向分析方法主要采用基于序列比对、基于概率统计以及基于频繁项集挖掘等协议格式推断方法.协议信息学(protocol informatics,PI)方法[3]将序列比对算法引入未知协议逆向分析中,实现报文字段标识.Netzob[4]在报文序列比对和报文格式聚类阶段增加了协议语义信息,得到了更为完整的协议分析结果,但由于报文序列更具多样性和复杂性,因而将报文比对和聚类算法应用于协议逆向分析过程的效率较低.
GramMatch[5]和RelaNet[6]采用基于概率统计的方法,实现报文的聚类,但在其聚类过程中利用了多个关键字段,从而导致聚类结果的冗余.NEMETYL方法[7]提出了一种基于特征向量连续值比较的字段相似性度量方法,利用Hirschberg对齐和DBSCAN聚类算法对协议字段和报文格式进行推理,但忽略了协议逆向不同阶段的相互影响和报文交互的关联性,导致错误传播.
深度学习以其特征学习和分层表示等能力,近年来被逐渐应用于协议逆向分析领域.文献[8]提出了一种基于共享学习的协议逆向分析方法,基于共享学习实现关键词抽取和报文聚类的协同优化,在一定程度上解决了协议逆向分析过程中存在的错误传播问题.文献[9]提出了一种基于深度学习的二进制协议报文格式抽取方法,利用图像语义分段与孪生神经网络技术,实现了报文字段特征的抽取与报文边界的标识.
鉴于当前网络协议逆向分析方法存在的上述不足,提出一种基于报文交互匹配与CNN-GRU-ATT模型的网络协议逆向分析方法(protocol reverse analyzer based on message end-to-end matching,MemProRe),结合多序列比对和深度学习方法,在预处理阶段将报文根据客户端和服务器端进行分组,根据客户端请求报文集合应与相应的服务器端应答报文集合相对应的原则,将对齐分段后的报文分别输入基于注意力机制的CNN-GRU-Attention网络,通过双端联合训练得到关键字段位置,最后根据关键字段完成报文分类并得到协议关键词,进而推断出协议格式和状态机.实验结果表明,MemProRe方法具有较高的报文字段标识与报文分类精度.
1 问题描述
当前绝大部分的自动化协议逆向分析方法均遵循着“报文字段标识→报文分类→协议状态机推理”的顺序分析过程,在对报文的关键字段进行标识的基础上,对报文根据相似性进行聚类.然而,当不同类型报文相似度较高时,会导致聚类结果不够准确,例如在Notzob和Discover[10]等方法中,若聚类精度不高,则会产生与协议规范不符的冗余报文分段.
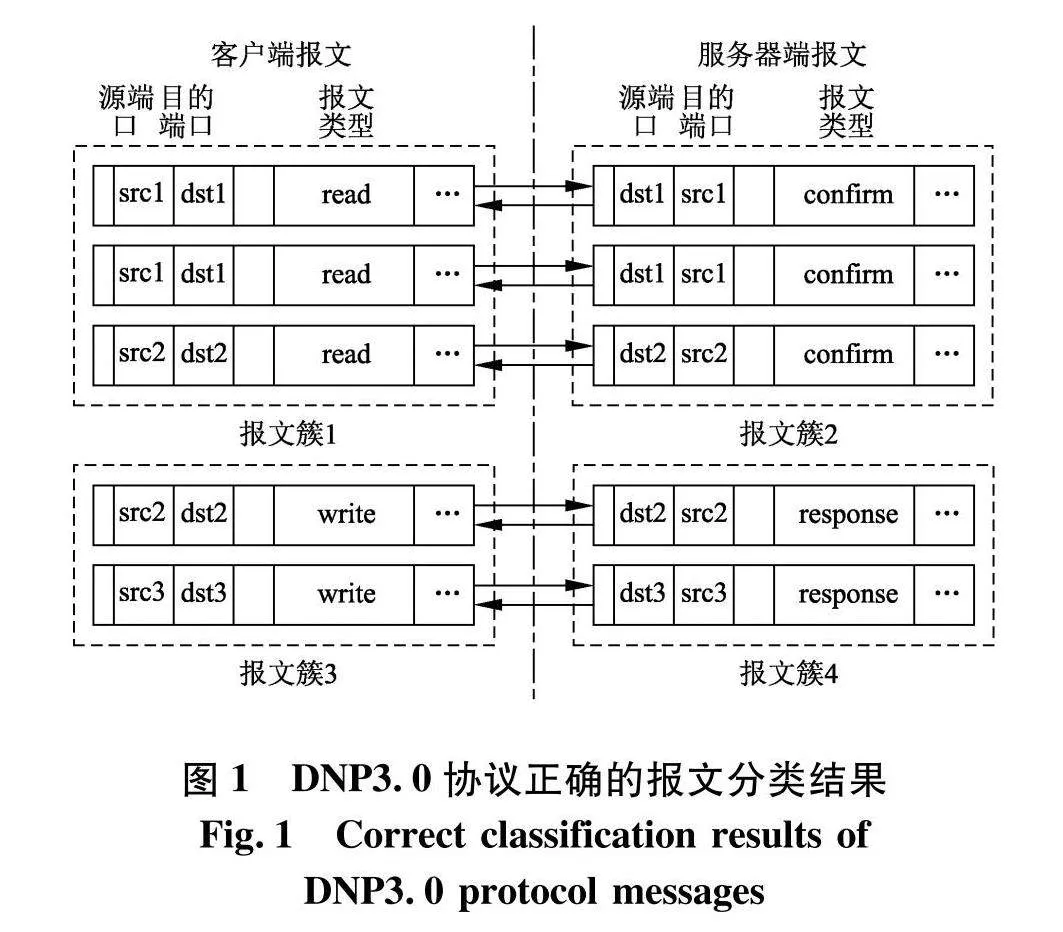
同时,在协议的状态迁移过程中,客户端的请求报文与服务器端的应答报文之间存在着一定的匹配关系.以DNP3.0协议为例,观察其报文交互过程和分类结果.DNP3.0协议正确的报文分类结果如图1.
由图1可见,在报文分类正确的情况下,根据报文类型形成的报文簇1和3分别是客户端同类型报文的集合,而报文簇2和4则分别是服务端同类型报文的集合.显然,客户端报文与服务器端报文通过聚类形成的报文簇存在着一定的对应关系.然而,仅根据相似度对报文进行分类,而未考虑客户端与服务器端报文的关联性,则可能将报文簇2中的报文错误地划分到报文簇4中,从而出现服务器端和客户端报文不匹配的情况.
2 基本思想
未知网络协议逆向分析的关键是将相同类型的报文进行分类.在协议的报文交互过程中,客户端或服务器根据报文中的关键字段确定报文类型,并据此作出相应的操作.若在协议逆向分析过程中,能够推断出报文中表示关键字的字段,并据此对报文进行分类,避免冗余现象的产生,并提高报文分类的准确性.
由于报文交互序列具有时序性,因此报文中的关键字段查找和报文分类过程可以视为对时序数据的分类,而门控循环单元(gate recurrent unit,GRU)[11]能够通过门控机制来控制信息的流动,能够更好地捕捉时序数据中的长期依赖关系.因此,利用GRU网络学习分段后的协议报文数据,能够获得更为准确的报文关键字段与分类结果.
网络协议通常根据关键字段来确定报文类型,在GRU网络中引入注意力机制(Attention)[12],使得GRU网络更为关注关键字段,可以在一定程度上提高报文分类的精度.
鉴于网络协议中客户端与服务器端报文之间存在着对应关系,因而在报文分类过程中增加客户端与服务器端报文簇之间的一致性约束,将双端报文分类的结果进行特征融合,可以进一步提升报文分类的准确性.
综上所述,文中提出了一种基于报文交互匹配与GRU-ATT模型的未知网络协议逆向分析方法MemProRe,以提高未知网络协议逆向过程中报文分类的准确性.
3 方法实现
3.1 系统架构
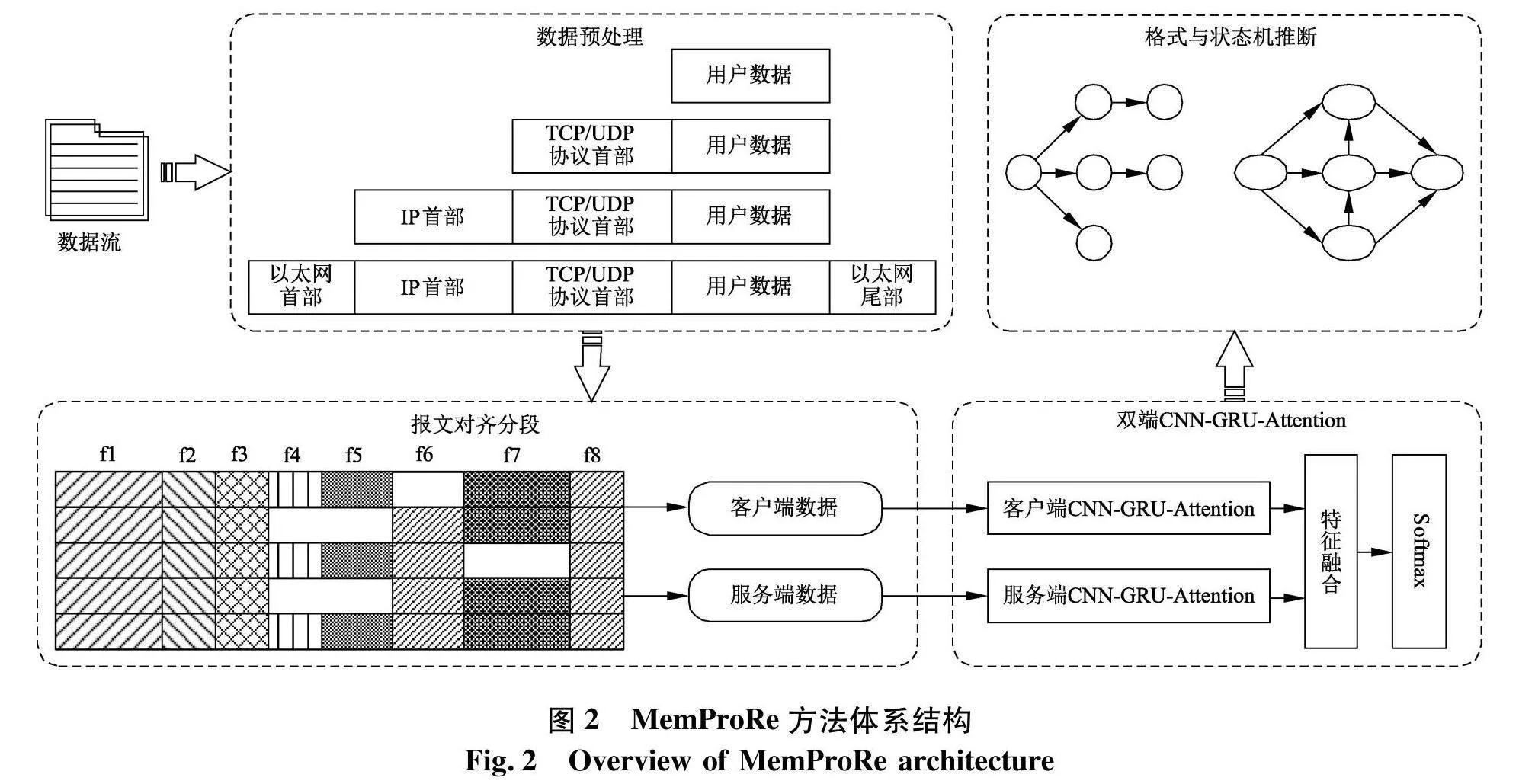
基于报文交互匹配与CNN-GRU-ATT模型的未知网络协议逆向分析方法MemProRe包含4个组成部分:数据预处理、报文对齐分段、双端CNN-GRU-Attention网络和格式及状态机推断.MemProRe方法体系结构如图2.
数据预处理主要用于获取网络流量数据,并进行预处理,以得到单一网络协议的流量数据;报文对齐分段首先对报文进行对齐,识别字段边界,进而形成报文分段并定位关键字段;双端CNN-GRU-Attention网络利用基于注意力机制的深度神经网络,在客户端与服务器端报文簇之间的一致性约束条件下,实现报文分类;格式与状态机推断确定报文字段格式,进行语义推断,在此基础上,根据会话和协议格式序列推理协议状态机.
3.2 数据预处理
3.2.1 数据获取
为了保证协议分类和后续报文序列处理的准确性,需要保证获取的网络数据具有多样性和完整性.采用Wireshark工具截获网络流量,并进行会话分组.在不同时间段截获网络数据,可以确保有足够多的会话分组来保证数据内容多样性;在程序运行的完整时间段内对数据进行截获,可以确保用于报文分类的网络数据不会缺失.
3.2.2 报文预处理
利用Wireshark工具在实际环境中截获网络数据包,可以获得包含多种协议的网络流量数据.Wireshark工具截获网络数据的示意图如图3.
由图3可见,Wireshark工具截获的网络数据包含了多种协议报文数据.因此,需要按照协议类型对报文进行预处理和分类.MemProRe根据报文中的时间戳、IP地址和端口等信息,以及客户端与服务器端的报文方向对报文进行分组.另外,专用协议等未知协议通常为应用层协议,需要对分组进行解封装,得到所需的报文数据.
3.3 报文对齐分段
为了实现对报文的分类,需要对报文中的字段边界进行判定,即报文分段.对于复杂的协议,报文序列可能具有不同的结构.若报文中部分字段长度可变,会导致同类型报文中相同的字段在不同报文中的位置发生变化,从而影响报文结构的分析,因此首先需要对报文进行对齐.
MemProRe采用序列比对方法,首先将报文对齐,然后根据对齐的报文在识别字段边界后进行分段,通过报文分段获取关键字段,并根据关键字段对报文进行分类.
对于固定长度的报文字段,具有相同值的概率较高.以文本协议为例的报文对齐结果如图4.
图4中报文2对齐后的空隙使用“-”进行填充.可见,报文对齐后,两个报文序列具有相同的固定字段值GET、HTTP和具体字段信息.
协议逆向分析所涉及的报文数量众多且均需要进行比对,MemProRe方法采用渐进式多序列比对方法(multiple sequence alignment,MSA)进行报文的比对,利用MAFFT序列比对工具[13]实现.在采用MAFFT工具进行报文对齐后执行分段操作,从而将报文字段分为固定长度(静态)和可变长度(动态)字段.
3.4 双端CNN-GRU-Attention网络构建
将报文进行对齐和分段之后,需要根据关键字段对报文进行分类.
由于网络报文数据具有时间序列特征,可以结合深度学习中的时间序列分类模型来进行报文分类操作.同时,在协议报文中通常由关键字段决定报文类别,而注意力机制可以通过改变对不同信息的注意力,侧重关键字段忽略边缘信息来完成序列分类.
因此,MemProRe方法结合注意力机制,采用在时间序列分类任务中表现较好的CNN-GRU-Attention网络来处理报文分类,其中,卷积神经网络(convolutional neural networks,CNN)[14]提取报文序列特征输入到GRU网络中训练后经过注意力层优化输出,最终完成对报文序列的分类.
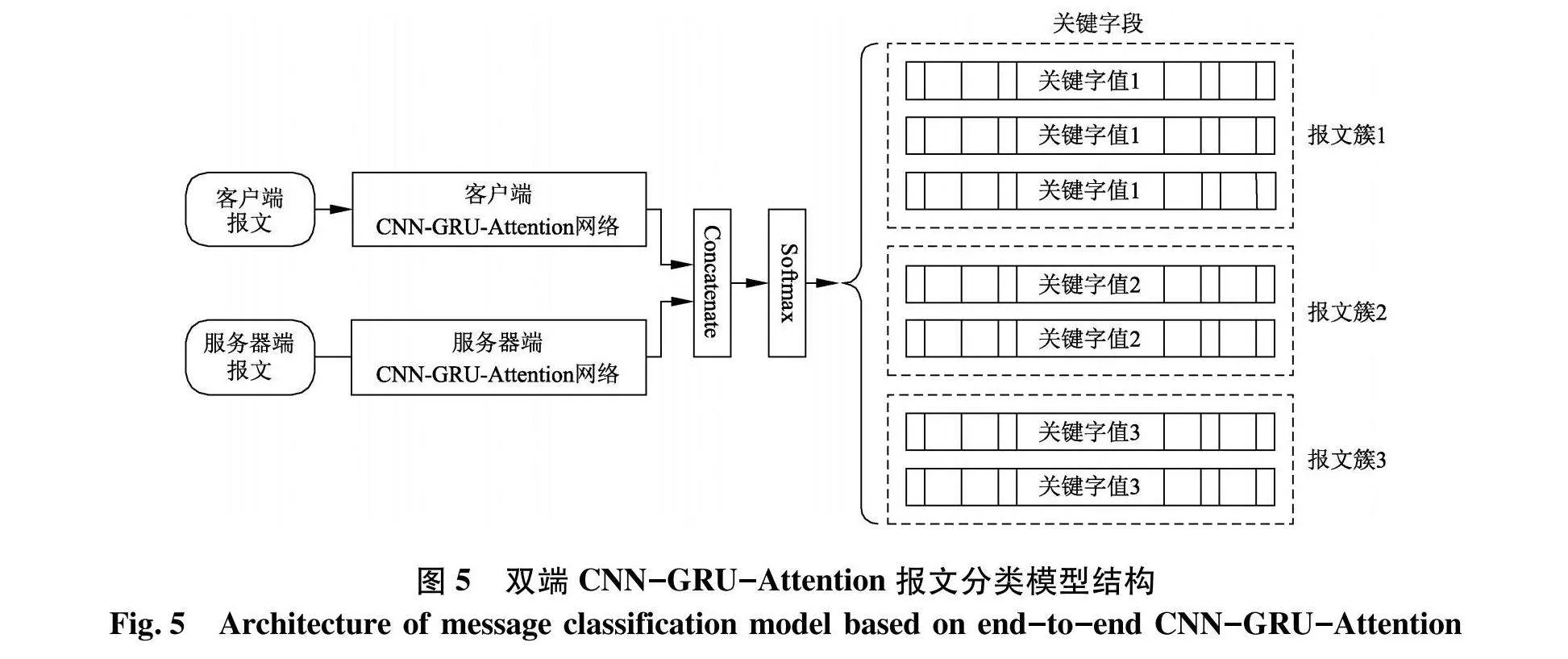
针对客户端与服务器端报文的一致性约束,即在客户端和服务器端分别属于相同报文簇的报文具有相互匹配对应关系.针对上述要求,MemProRe方法提出了一个客户端与服务器端报文匹配的双端CNN-GRU-Attention报文分类模型,其结构如图5.
为了能够同时提取客户端与服务器端报文信息的特征,在预处理阶段将报文按照服务端和客户端进行分组,服务端和客户端的报文数据分别输入对应的CNN-GRU-Attention网络,使用Concatenate层对服务器端报文序列和客户端报文序列的特征进行融合,将双端的匹配交互关系加入到网络中优化分类结果,最后输入到Softmax层完成多分类.CNN-GRU-Attention网络主要分为CNN层、GRU层和Attention层,其网络结构如图6.
CNN层主要对输入的序列进行特征提取,其结构包含卷积层、池化层和全连接层,卷积层选择一维卷积来提取报文序列特征,激活函数选择ReLU函数来提取局部报文序列的特征,池化层选择最大池化方法来提高训练效率,而全连接层则使用Sigmoid激活函数.经过卷积层和池化层的处理后,报文序列信息被映射到隐藏层的特征空间,通过全连接层输出,得到报文序列的特征向量.CNN层提取的报文特征序列作为单层GRU的输入进行时序建模和学习,获取报文字段的变化规律.
在注意力机制实现中,将注意力层放在GRU层之后能够得到更好的结果.注意力机制的输入为经过GRU层处理的隐藏层输出信息,根据分配原则计算不同时刻不同关键字段位置对应的概率权重,提高隐藏层对字段特征提取质量,得到精确的报文分类结果.注意力机制使用压缩-激励(squeeze and excitation,SE)模块实现,SE模块主要由压缩、激励和标定操作组成.
4 实验结果分析
4.1 实验环境与评价指标
实验环境为Ubuntu 20.04操作系统,硬件环境为Intel Corei5 13400 4.60 GHz、16 GB内存,编程语言采用Python语言,版本为Python3.9,以Pytorch为深度学习框架,版本为Pytorch11.3.1.
实际局域网络环境下使用Wireshark工具截获20 000条报文,其中80%作为训练集,20%作为测试集.数据集中包含4种常见类型的网络协议报文来模拟未知协议报文,分别是域名解析协议DNS、网络时间协议NTP、动态主机配置协议DHCP和网络文件共享协议SMB,对于每个协议选取1 000个报文,并选取其前500位作为实验数据.
设置批训练大小batch_size为128,迭代轮次epoch为20.训练时经过多轮迭代,若迭代轮数或损失函数达到预先设置的停止条件,则认为算法收敛,训练过程结束.
为了评价MemProRe方法的报文分类结果,使用了分类任务中常用的评估指标:精确率(Precision)和召回率(Recall),并将MemProRe方法的实验结果与Netzob和Discover方法进行比较分析.
4.2 实验结果分析
4.2.1 报文分段结果对比
为了验证MemProRe方法对于报文对齐分段结果的准确性,对报文对齐分段进行了实验与结果分析.表1给出了DNP3.0协议的部分协议格式.
在对DNP3.0协议报文对齐分段后,推断的报文分段结果如表2.其中,S表示静态字段,D表示动态不可变长字段,V表示动态可变长字段, K表示关键字段.
由表2可见,MemProRe方法能够较为准确地推断大部分的字段边界,并成功地将功能码所在字段判定为关键字段,这说明根据关键字段进行报文分类结果的正确性.
同时在表中也出现了字段划分过细的情况,在第8-11字节和12-15字节处进行了额外的划分.但是,MemProRe方法虽然在字段内部错误地划分了边界,但在字段两侧的边界划分结果与真实情况相同,不会影响对关键字段的判断.
实验结果表明,MemProRe方法能够正确地对报文边界进行划分.
4.2.2 报文分类结果分析
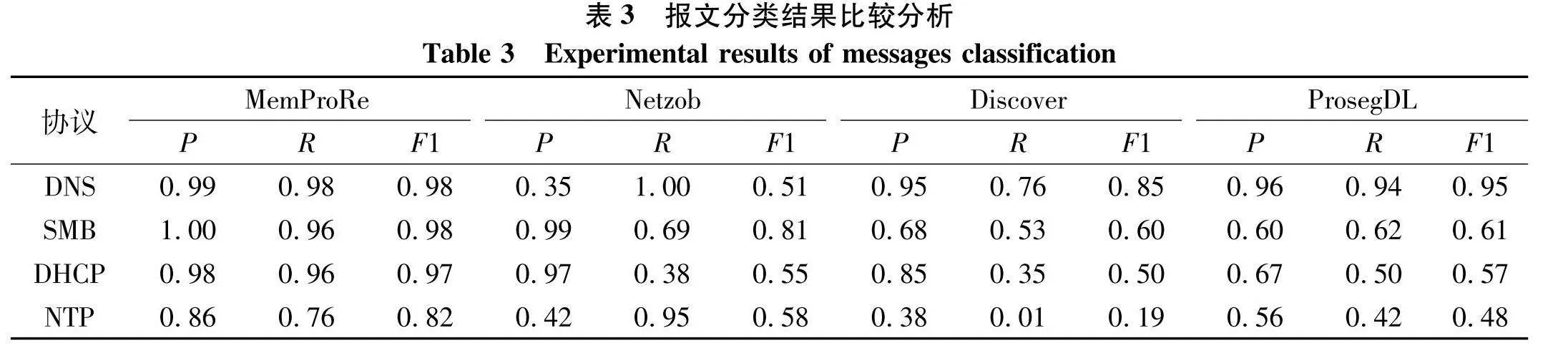
为了验证MemProRe方法对报文分类的准确性,针对4种类型的协议,将MemProRe方法与经典的Netzob[4]与Discover方法[10]以及基于深度学习的ProsegDL方法[9]进行了比较分析.报文分类结果比较分析如表3.
表3中准确率P代表是否成功将相同类型报文进行分类,而召回率R则可看作报文分类中的正确报文数,在一定程度上代表了报文分类结果的冗余程度,F1代表精确率和召回率的调和平均值.
由表3可见,Netzob算法虽然获得较高的分类准确率,但导致召回率偏低,意味着Netzob算法在对报文进行分类时产生了较多的类型冗余.Discover算法则侧重于语义分析,在报文分类方面尤其是二进制协议表现较差.采用图像语义分段的ProsegDL算法的分类精度与前两种方法相比略有提升,但由于其在字段标识过程中仅考虑字段内部与边界之间的图像差异,而未考虑不同报文类别之间的差异.MemProRe方法在DNS、SMB、DHCP协议上均有较好表现,说明使用关键字段对报文进行分类能够有效解决冗余问题;同时MemProRe方法采用深度学习,对大量数据进行训练,可以得到正确的关键字段位置和精确的分类结果.
4种报文分类算法在NTP协议的分类结果均差于其他协议,这是因为NTP协议的关键字段为比特级别而非其他协议的字节级别,例如,NTP协议首个报文,其关键字段所在的字段值为“00100100”,但其真实的关键字段应为“100”,使得算法对关键字段的判断出现错误,导致使用关键字段进行报文分类对NTP协议的表现较差.
实验结果表明,将深度学习中时序分类的方法应用于协议逆向分析中是可行的,并且引入服务器端和客户端报文交互匹配的思想可以提升报文分类的效果,MemProRe方法可以通过学习已知协议字段,实现与真实情况近似的报文分段与分类结果.
5 结论
(1) 针对未知网络协议逆向分析问题,提出了一种基于报文交互匹配与CNN-GRU-ATT模型的协议逆向分析方法MemProRe.基于客户端请求报文集合应与相应的服务器端应答报文集合相对应的原则,在报文分类过程中建立客户端与服务器端报文集之间的映射关系.
(2) 算法融合序列比对方法与采用门控循环单元和注意力机制的深度学习方法,利用结合注意力机制的双端CNN-GRU-Attention网络实现具有时序特征的网络报文分类.实验结果表明,MemProRe方法进行报文分类的精确度较高,报文分类结果接近真实情况.
(3) 报文语义推理和状态机推断是未知协议逆向分析的重要内容,在后续的工作中,将在文中研究的基础上进一步研究报文语义推理方法,通过报文语义推理获取交互报文的语义信息,为构建未知协议网络报文的协议状态机模型奠定基础.
参考文献(References)
[1] 王占丰, 程光, 马玮骏,等. 基于网络轨迹的协议逆向技术研究进展[J].软件学报, 2022, 33(1):254-273.
[2] KLEBER S, MAILE L, KARGL F. Survey of protocol reverse engineering algorithms: Decomposition of tools for static traffic analysis [J]. IEEE Communications Surveys amp; Tutorials, 2019, 21(1):526-561.
[3] HUANG Y Y, SHU H, KANG F, et al. Protocol reverse-engineering methods and tools: A survey [J]. Computer Communications, 2022, 182:238-254.
[4] BOSSERT G, GUIHERY F, HIET G. Towards automated protocol reverse engineering using semantic information [C] ∥9th ACM Symposium on Information, Computer and Communications Security. Kyoto: ACM, 2014:51-62.
[5] MA B L, YANG C, CHEN M Z, et al. GramMatch: An automatic protocol feature extraction and identification system [J]. Computer Networks, 2021, 201:108528.
[6] TANG T, LAI Y X, WANG Y P. Relational reasoning-based approach for network protocol reverse engineering [J]. Computer Networks, 2023, 230:109797.
[7] KLEBER S, VAN DER HEIJDENR W, KARGL F. Message type identification of binary network protocols using continuous segment similarity [C] ∥2020 IEEE Conference on Computer Communications (INFOCOM′20). Toronto: IEEE, 2020:2243-2252.
[8] ZHANG W Y, MENG X Y, ZHANG Y J. Dual-track protocol reverse analysis based on share learning [C]∥2022 IEEE Conference on Computer Communications (INFOCOM′22). London: IEEE, 2022:51-60.
[9] ZHAO S, WANG J F, YANG S G, et al. ProsegDL: Binary protocol format extraction by deep learning-based field boundary identification [C] ∥30th International Conference on Network Protocols (ICNP′22). Lexington: IEEE, 2022:9940264.
[10] CUI W D, KANNAN J, WANG H J. Discoverer: Automatic protocol reverse engineering from network traces [C] ∥16th USENIX Security Symposium. Berkeley: USENIX, 2007:1-14.
[11] YAMAK P T, LI Y, GADOSEY P K. A Comparison between ARIMA, LSTM, and GRU for time series forecasting [C] ∥2nd International Conference on Algorithm, Computing and Artificial Intelligence (ACAI′19). Sanya:ACM, 2019:49-55.
[12] MA Q L, YU L H, TIAN S, et al. Global-local mutual attention model for text classification [J]. IEEE/ACM Transaction on Audio, Speech and Language Processing, 2019, 27(12):2127-2139.
[13] KATOH K, ROZEWICKI J, YAMADA K D. MAFFT online service: Multiple sequence alignment, interactive sequence choice and visualization [J]. Briefings in Bioinformatics, 2019, 20(4):1160-1166.
[14] MENG X Y, WANG Y Q, MA R X, et al. Packet representation learning for traffic classification [C] ∥28th ACM" SIGKDD Conference on Knowledge Discovery and Data Mining(KDD′22). Washington:ACM, 2022:3546-3554.
(责任编辑:曹莉)
