基于TextRNN的医疗导诊模型设计
2023-12-25叶郅弈蔡莉莉
叶郅弈 蔡莉莉

摘要:随着经济的发展和生活水平的提高,人们对自身健康的需求日益关注。长期压力及不健康的生活习惯使得亚健康人群比例连年攀升。当身体出现某些不适症状时,人们迫切想要了解症状对应的疾病原因,以便尽快就医。为方便人们的线上导诊,该文提出基于TextRNN的医疗导诊设计,使用预训练模型将患者的自述病情逐词映射为词向量并输入模型,通过双向长短时记忆网络提取病情中的特征并学习,预测出患者需要就诊的科室,实现了智能导诊的功能。
关键词: 智能医疗导诊; TextRNN; 双向长短时记忆网络;特征学习
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2023)31-0082-03
开放科学(资源服务)标识码(OSID)
0 引言
就医问题一直是民生问题的一大热点,随着时代的发展以及互联网技术的应用与普及,线上医疗服务逐渐成为新的趋势,这给人们带来极大的便利。过去的传统就医模式,患者需要前往导诊台,经过护士的分诊工作后,才能了解自己所需的挂号科室。但由于疾病种类繁多等问题,医护人员可能无法及时分诊到每一位患者[1]。为此患者可以选择各大医疗网站推出的线上医疗服务,使用手机将自己的病情进行简单自述,然后发送到网站,具备相应医疗资历的专业人员会根据患者所提供的病情自述推荐就诊科室。相比传统就医模式,这种方式使得患者的就医效率有了明显提升,但也存在等候分诊的时间差。为了充分利用大数据的优势,基于深度学习的智能导诊系统可以根据患者的病情自述,智能地分类预测出需要就诊的科室,在第一时间为患者提供分诊信息,帮助患者选择与其病情对口的专项科室或特色科室,减轻普通科室的医生压力。同时也方便患者进一步了解自身的病情,提前准备相应的就诊材料,提高患者的就医综合体验。
智能导诊模型的设计思路属于自然语言处理领域的文本分类问题。文本分类是指使用计算机学习文本中的特征,并根据给出的标签对其进行分类学习,以帮助人们标注分类。文本分类问题中较为重要的工作就是将文字表示为计算机易处理的形式,常见的文字表示方法有词袋模型、向量空间模型以及词嵌入等。经过文字表示处理后,数据将通过分类模型进行分类学习。常见的分类模型有基于机器学习的决策树、K近邻、朴素贝叶斯分类器、支持向量机以及基于深度学习的TextRNN、TextCNN、Transformer等。在深度学习模型选择方面,传统的RNN模型可以很好的利用其独特的记忆能力,寻找词语在上下文的含义,但计算速度较慢。在处理较长文本时,存在有梯度消失问题[2],改进后的双向长短时记忆网络(BiLSTM) 文本分类模型能有效避免梯度消失问题。
1 数据与模型介绍
1.1 数据集介绍
先使用beatufulsoup、urlibPython等模块,爬取各大医疗网的数据。数据包括疾病的名称、疾病的典型症状、临床表现等总计18 886条数据,带有科室信息的医疗问答信息共计54 000条数据。爬取的原始数据中存在重复的问答语句以及与医疗领域无关的文本内容,因此需要对爬取的数据进行清洗,同时去除数据中存在的乱码数据和低于5个字符的无效数据。
再将患者的自述症状以及所携带的科室信息分类成27种不同科室,并为其标注上对应的0~27标签。科室分别为肛肠科、普通外科、神经脑外科、肝胆科、泌尿科、乳腺科、心血管科、心外科、胸外科、肿瘤科、神经科、内分泌科、消化科、呼吸科、肾内科、感染科、风湿免疫科、普通内科、男科、皮肤科、耳鼻喉科、儿科、妇产科、骨科、心理科、血液科、肝病科。每个科室拥有1 500条数据样本,总计4.5万条数据,并将这些数据按照1∶1∶8的比例分配成测试集、验证集、训练集。如图1为训练集的部分数据展示。
1.2 模型介绍
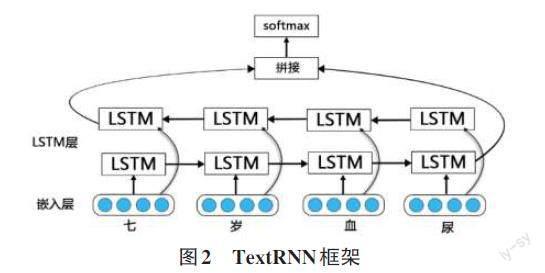
TextRNN模型由嵌入层、LSTM层和输出层构成。
1) 嵌入层
在数据输入模型之前,需要通过嵌入层将词语用低纬、稠密、连续的向量来表示,以转化为计算机可以处理的数据类型,其中每个纬度表示文本词语的一个潜在语法或者语法特征。在具体的医疗领域中,复杂的病情描述加大了上下文解读的难度。而预训练是指通过大量的中文文本数据进行预学习,以此得到能较好表达词语上下文含义的词向量,提高模型的上下文理解能力,达到更好的分类效果。本文使用的是LI S等[3]提出的开源预训练模型,此模型使用MIKOLOV T等[4]提出的Word2vec工具中的Skipgram模型对中文数据进行预训练。
2) LSTM层
LSTM层的作用是捕捉上下文之间隐含的相关性。常用模型有卷积神经网络、循环神经网络、递归神经网络、深层Transformer,本文使用的是基于循环神经网络(RNN) 的拓展模型BiLSTM。在处理文本语句时,传统的RNN有着天然的优势[5],它能按照句子的逻辑顺序,分别把字输入对应顺序的时间节点,在处理完一个时间节点后进行下一个时间节点的计算,当完成所有时间节点后,模型就能捕捉到上下文之间的相关性。但当文本语句过长时,RNN模型對上下文理解能力将会变差,同时由于RNN各个时间节点使用同一个权值矩阵,导致模型在反向传播过程中会出现梯度消失或者梯度爆炸等问题。
LSTM在RNN的基础上进行了改进,通过添加遗忘门、输入门、输出门提高了上下文的理解能力。在LSTM的基础上,BiLSTM通过建立一条反向LSTM,在正向与反向序列处理完后,将正反双向的LSTM结果整合起来,得到理解效果更好的输出结果[6]。
3) 输出层
输出层是模型的最后一层,用于预测分类结果,将LSTM层所表现出来的特征进行拼接后作为输入。常用模型包括:多层感知层(MLP) +Softmax、条件随机场、递归神经网络和指针网络,本文使用Softmax得到分类结果。图2是文本分类模型框架图。
4) 评判指标
常用评估指标包括严格匹配指标和宽松匹配指标,本文使用的是严格匹配指标,通过假阳性(FP) 、假阴性(FN) 和真阴性(TP) 的数量来计算精确度、召回率和F1值,如式(1) ~(3) 所示:
[Precision=TPTP+FP] (1)
[Recall=TP(TP+FN)] (2)
[F1-score = 2×Precision×RecallPrecision+Recall] (3)
2 模型测试与模型部署
2.1 模型测试
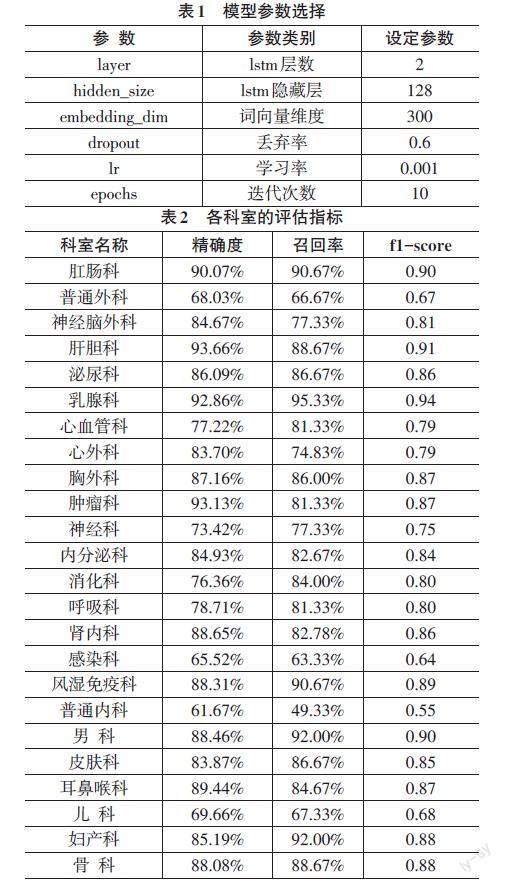
模型的主要思路是将患者输入的自述症状如“前段时间饮食睡眠不规律,生活压力巨大。连续3~4天肚脐下部隐隐作痛,几乎直不起腰来,大便正常。好像存在腹胀气,不确定症状”,通过预训练模型将症状映射为300维的词向量输入TextRNN网络,词向量经过计算和拼接后,经Softmax分类后得出预测的推荐科室。模型的参数选择如表1所示,经过10轮的迭代,模型的准确度可以达到82.26%,各科室评价指标如表2所示,证明该模型可以较好地将患者的自述病症进行分类。
根据表2的分类评估指标,对测试集进行评估,普通内科、普通外科、儿科、感染科等科室分类效果相对较差。在检查数据集后发现,感染科数据中存在与其他科室相似的交叉病症信息,如“被狗咬了一丝丝皮但是没出血,几个小时后发现身体酸痛发热”。“狗咬”与“出血”等关键词属于感染科范畴,而身体发热酸痛这类病症信息可存在于多个科室中,导致模型在分类时,无法很好地区分此类交叉多个科室的病症信息。此外,上述科室的患者自述病症多样,确诊的疾病类型众多,导致这类数据集出现过多特征,而验证集中的数据过少,存在样本分布不均等问题。相比分类效果较差的科室,病症信息较为明显的科室、数据质量较好的科室如肛肠科、男科等分类效果较好,f1值均在0.8以上。
2.2 模型部署
智能导诊模块的面向对象多为老年人群体或工作较为繁重的上班族,因此模型的部署需要做到快速、便捷、易上手等特点,并且上述群体对于微信及微信中的附加功能较为熟悉且在日常生活中使用频率较高。为此,选择将模型部署到微信小程序平台,通过小程序与服务器完成导诊工作。
部署模型的方法有很多,其中较为常见的有:通过将模型部署到服务器或云端上,使用请求和响应进行交互的在线部署方法;将模型打包直接部署到手机设备中的离线部署方法;使用开源的深度学习模型部署工具如 TensorFlow Serving、TorchServe、MMDeploy 等将模型部署到服务器或云端上的模型部署工具包。
由于模型框架规模较大,占用资源较多,对患者的设备要求较高,因此选择在线部署方式完成智能导诊系统设计较为合适。使用Python编写的flask框架将模型部署到服务器中,flask框架具有便捷、灵活、轻量化等特点,非常适合Web服务的开发。
微信小程序则用来收集患者的自述症状并向服务器发送请求,经过预测将推荐科室信息结果返回小程序界面,因此需要在小程序开发工具中设计可以接受患者输入的对话框,发送请求的查询按键以及显示科室信息的文本框。
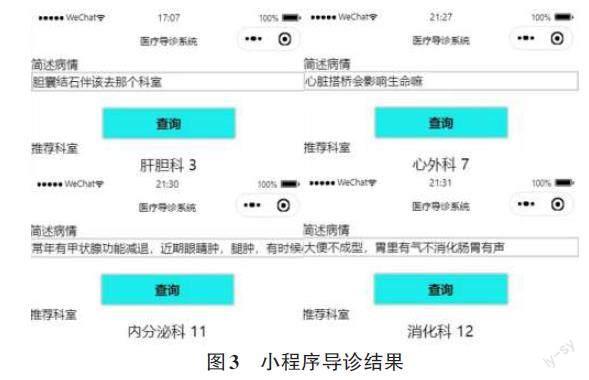
举例说明智能导诊模块的使用流程。患者通过点击简述病情下的对话框,输入自己的自述病症,点击查询按钮,小程序会将自述病症传入服务器并通过词嵌入输入模型,经过模型预测后,将与自述病症最相关的科室信息返回给小程序并显示出来,完成导诊工作。如图3所示为小程序导诊界面显示结果图。患者通过在病情简述框中输入“胆囊结石该去哪个科室”“心脏搭桥会影响生命吗”“常年有甲状腺功能减退,近期眼睛肿,腿肿”“大便不成形,胃里有气不消化肠胃有声”等症状分别给出了肝胆科、心外科、内分泌科及消化科的导诊建议,结果测试基本是符合预期的。
3 總结
导诊模块通过小程序收集患者自述病情,使用TextRNN模型进行科室分类,预测出推荐科室后,反馈到小程序实现患者的自主问诊。在模型的建立中,导诊模型应用了预训练词向量模型,经过验证与评估在科室推荐功能上具有一定的准确性。但在部分科室标签中,数据集存在问题。部分科室数据较少,病症特征较多且与其他科室存在相似的交叉病症信息,导致模型的分类能力较差。在模块的实际测试中,导诊模块对新型词汇诸如方言类的关键词或较为口头化的疾病症状分类不佳。同时,基于Word2vec的预训练模型无法表达同一词语在不同语境下的含义。动态词向量表示模型ELMO与BERT可以很好地解决此类问题,提升词语上下文含义的表示能力,提高模型分类的精度。在分类模型选择方面,GPU的大力发展提升了大规模计算的能力,但BiLSTM并未充分地利用GPU的并行计算能力,这使得BiLSTM在处理速度上处于劣势。随着深度学习的不断发展,添加注意力机制的CNN网络以及基于Transformer的深度学习框架能更好地分类出患者的疾病,同时提高模型训练的效率,更利于智能导诊系统的科室推荐功能。
参考文献:
[1] 戴甜甜,金冬.智能医疗APP导诊功能设计探究[J].设计,2020,33(5):137-139.
[2] BENGIO Y,SIMARD P,FRASCONI P.Learning long-term dependencies with gradient descent is difficult[J].IEEE Transactions on Neural Networks,1994,5(2):157-166.
[3] LI S,ZHAO Z,HU R F,et al.Analogical reasoning on Chinese morphological and semantic relations[EB/OL].[2022-06-20].2018:arXiv:1805.06504.https://arxiv.org/abs/1805.06504.pdf.
[4] MIKOLOV T,CHEN K,CORRADO G,et al.Efficient estimation of word representations in vector space[EB/OL].[2022-06-20].2013:arXiv:1301.3781.https://arxiv.org/abs/1301.3781.pdf.
[5] LIU P F,QIU X P,HUANG X J.Recurrent neural network for text classification with multi-task learning[EB/OL].[2022-06-20].2016:arXiv:1605.05101.https://arxiv.org/abs/1605.05101.pdf.
[6] 陈晓梅,肖徐东.基于集群辨识和卷积神经网络-双向长短期记忆-时序模式注意力机制的区域级短期负荷预测[J/OL].[2023-04-10].现代电力.https://kns.cnki.net/kcms2/article/abstract?v=LD-wYsOa3Djuwd0g-g0PymsD26hnTMxfzoGh Z0RMbQ4tG1YCm4VeGuporow3kE11GJ0rc0bJS7IgT6I6JoBYCFBTNJocxQBarj0B0r4cP_AZHNJMviUMTVI36cUUDBqDCk_ Jm4dC8mM=&uniplatform=NZKPT&flag=copy.
【通联编辑:代影】
