基于改进YOLOv5s的道路行人与车辆检测算法
2023-12-25秦忆南施卫张驰皓陈程
秦忆南 施卫 张驰皓 陈程


摘要:针对在城市街道中检测目标因为相互遮挡、尺寸小、密集分布等问题导致检测困难,检测目标丢失,提出一种改进的YOLOv5s算法。首先通过将CA注意力模块与C3模块相结合加入C3CA注意力模块;其次加入SPPFCSPC空间金字塔池化模块代替SPPF,进一步扩大感受野,提升模型的精度。最后改变Neck结构变为Slim-Neck结构,通过替换Conv模块为GSConv模块,并将Slim-Neck中的C3模块中的Conv模块替换为GSConv模块。实验使用优化后的KITTI数据集。实验结果表明,改进后的算法与YOLOv5s相比在平均精度值上提升了2.3%,小目标漏检的情况也有了明显改善。
关键词:目标检测;YOLOv5s;CA注意力模块;空间金字塔;Slim-Neck
中图分类号:TP18 文献标识码:A
文章编号:1009-3044(2023)31-0005-04
开放科学(资源服务)标识码(OSID) :
0 引言
随着科技发展与城市道路规划的推陈出新,对自动驾驶的要求也越来越严苛。如何能够更快更加精准地进行目标检测一直是自动驾驶汽车所需要解决的关键问题。
对目标准确检测主要包括两方面:一方面是在复杂的道路环境下识别出检测目标的信息,并用边界框将其在图片或影像中标识出。另一方面则是通过深度学习等模拟人思维的决策对边界框中的目标进行识别检测,确定类别与名称以及置信度。这个过程中由于环境的复杂性和行人状态的多样性以及行人行为的不可确定性,需要自动驾驶拥有模擬人的思维做出相应的对策。机器学习、深度学习可以帮助行驶车辆在不同的场景环境下学习并识别各种物体,并通过识别的结果做出相应的对策,这就使得机器学习、深度学习显得尤为重要。
目前的深度学习主要分为二阶段和一阶段这两大类[1]。二阶段的代表算法有R-CNN[2]、Fast R-CNN[3]、Faster R-CNN[4]等,二阶段算法这一类的算法是先生成候选框,然后对这些选框进行分类。两阶段目标检测为了追求高精度,增加了复杂性,降低了检测速度。相较于两阶段目标检测,一阶段直接通过卷积后在图像上直接生成预测目标的位置和分类,大大降低了运算的复杂性,提升了速度,但在提升速度的同时,也牺牲了一定的精度。这一类代表的算法有SSD[5]、YOLO系类[6]等。在自动驾驶中检测速度和检测精度一样重要,一阶段目标检测因为速度与精度都有涉及,而广泛用于自动驾驶。
在自动驾驶中行人检测因其不确定性,状态复杂性一直是目标检测的难点,行人检测的难点主要存在小目标漏检,密集行人漏检以及遮挡目标漏检。为了降低行人目标检测过程中误检、漏检,本文以YOLOv5算法为基础模型,提出了一种城市街道场景中目标检测的改进YOLOv5算法。首先加入Coordinate Attention (CA) [7]注意力模块,增加检测精度;之后将SPPF[8]池化金字塔与CSP结构相结合生成SPPFCSPC模块,扩大感受野,降低误检、漏检;最后通过GSConv[9]卷积替换Conv降低模型参数量,提高速度。通过上述网络结构调整后,使本文的算法能够更好地适应城市街道,获得较好的检测效果。
1 YOLOv5网络模型改进
针对在城市街道中检测目标因为相互遮挡、尺寸小、密集分布等问题导致检测困难,检测目标丢失,对YOLOv5算法进行改进。首先加入C3CA注意力模块,通过将CA注意力模块与C3模块相结合,在增加长距离关系提取能力,拥有横向与纵向位置信息提取能力的同时,单独降低加CA的计算量、参数量。其次加入SPPFCSPC空间金字塔池化模块代替SPPF,进一步扩大感受野,提升模型的精度。最后在Neck层加入GSConv模块代替Conv模块,通过降低计算量的方法来提升速度,并替换Neck层中使用Conv的C3,使Neck层变为Slim-Neck。
1.1 注意力添加-CA模块
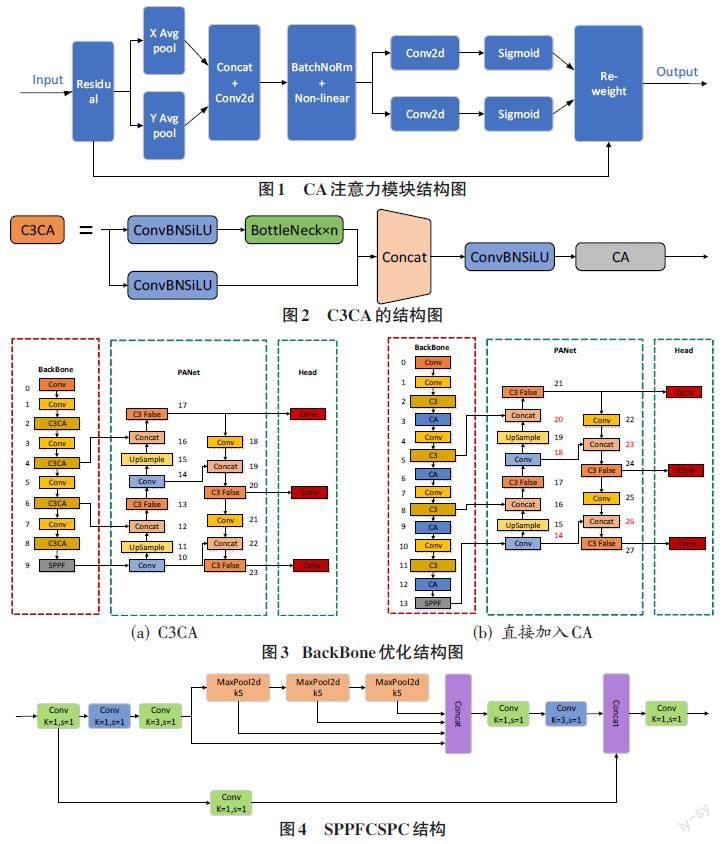
YOLOv5s在对目标进行检测时,某些小目标或者被遮挡的目标往往会漏检,导致检测效果不佳。因此,本文将Coordinate Attention(CA)注意力模块与C3模块相结合,在不改变Backbone网络主体架构的情况下加入注意力模块。如图1为CA注意力模块结构图。
开始时没有使用全局平均池化,而是分别向X水平轴方向和Y垂直轴方向进行平均池化。这样能够允许在捕捉单方向上的长距离关系的同时,保留另一个方向上空间的信息,帮助准确定位目标。通过两个方向池化过后,会得到两个单独方向的特征图,将这两个特征图进行拼接并用1×1大小的卷积核进行卷积,生成过渡特征图。通过批量归一化以及线性回归的操作后再次将过渡特征图拆分成单独方向的特征图,并再次使用1×1大小的卷积核进行卷积,获得与输入时相一致的通道数。通过激活函数,分配其权重比并与开始的通道输入值相乘获得最后的输出值,从而达到强化特征的目的。
C3CA模块是在C3模块内部的最后添加了CA注意力模块。本文没有选择直接在BackBone网络中加入CA模块,而是选择在Bottleneck C3中加入CA模块。如图2所示是C3CA的结构图。
如图3(a)是在Bottleneck C3模块加入CA的网络结构图和图3(b)CA模块直接加入BackBone网络结构图。可以看出,在Bottleneck C3模块加入CA后,整个YOLOv5s的框架并不会发生改变,而在BackBone网络加入后,因为是完整地插入了一个新的层,所以后面的层要往后推一个位置。虽然因为输入的关系,上下两层会自己调节,但有4个Concat还额外接受其他层的信息,而它所接受的C3层和Conv层因为CA模块的加入需要进行调节。当CA直接加入BackBone网络后,整个网络结构发生了改变。当其被训练时,会因为结构与预训练权重中结构不符合而增加多余的训练量。同时因为无法找到结构中对应的位置,YOLOv5s.pt中的权重将不再采用,map值将会从很低的值开始运算,大大增加了训练时间和训练次数。
1.2 空间金字塔池化SPPFCSPC
在复杂场景中,会出现目标遮挡漏检或者小目标漏检。为了满足在增大感受野的同时加快运行速度,本文提出了将SPPF与CSP结构相结合而成的SPPFCSPC模块,如图4所示。
SPPF是在SPP空洞卷积的基础上提出的,能在计算量不变的同时降低FLOPS。SPPF的作用是增大感受野,通过5、9、13、1这4种不同尺度的最大池化获得4种不同的感受野,来区分大小目标。
CSP結构将原输入分为2个分支。一支通过1×1的卷积降维使通道数减少,另一支通过1×1卷积降维后升维来降低计算量并进行SPPF模块处理。最后两者再相结合并通过1×1的卷积升维,实现输入与输出维度一致。
通过SPPF模块与CSP结构结合后的SPPFCSPC与SPPF相比较,获得更高的精度和感受野,与SPPCSPC相比,速度方面得到了提升。
1.3 Neck网络轻量化改进
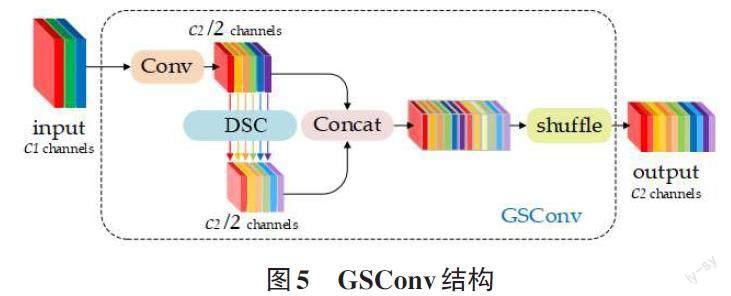
在自动驾驶中因为目标的复杂性和场景的实时性,对检测算法的准确性和速度都有比较高的要求。标准卷积SC在卷积过程中因为卷积核的通道与图片通道相同,所以可以直接得到卷积结果,并且可以保留各通道之间的隐藏连接。而深度可分离卷积DSC先是将图片的各通道分别卷积得到3个通道数,而后再通过一个pointwise核将这3个数卷积。由于行人检测的复杂性,需要在图片上提取众多的属性,此时DSC相较于SC可以节省很多的参数,提升了预测的速度。但DSC由于通道分开卷积的原因属于稀疏卷积,丢失了各通道之间的隐藏连接,直接导致了精确度的下降。
本文采用GSConv卷积来代替一部分Conv卷积,在降低计算量提升预测速度的同时提高精度。GSConv卷积中融合了深度可分离卷积DSC与标准卷积SC。如图5所示,通过分组卷积,一半使用SC,一半采用DSC并将两者进行Concat。之后使用shuffle将SC生成的密集卷积操作信息融入DSC生成的信息中,如图5所示。
GSConv尽可能地保存了这些连接,同时因为调用了DSC也降低了运算的参数量。但如果所有的卷积Conv都用GSConv来代替,只会导致网络升度的进一步加深,计算量参数量的增大只会增加推理时间。对于驾驶中的汽车来说,速度与准确同样重要,所以GSConv替换的最好方式就是仅在Neck中使用。当GSConv仅在Neck中运行时可以将自身所产生的冗余信息降到最小,同时可以让加入的注意力CA效果更好。
轻量化Neck层使其变为Slim-Neck就是替换掉其中的Conv,用更加轻量级的GSConv代替。GSConv计算成本大约只有标准卷积的60%~70%,但精确度毫不逊色。除了Neck中的Conv以外,还能够更改Neck中同样由Conv组成的C3模块变成VoV-GSCSP。通过对比VoV-GSCSP与C3模块,发现前者的FLOPs降低了20%。
2 实验设置与结果分析
实验环境配置基于Windows 10操作系统,CPU为AMD Ryzen 5 5600X 6-Core Processor 3.70 GHz,GPU 为NVIDIA GeForce RTX 3060 Ti,深度学习框架为PyTorch 1.12.1搭建网络模型,Python 3.9编译代码。
2.1 数据集
本文所使用的数据集是KITTI数据集,KITTI数据集是著名的交通场景分析数据集,该数据集主要包括行人与车辆在不同的交通场景下的现实图像数据,图像素材大小为1 224×370。原数据集包括Car、Van、Truck、Pedestrian、Pedestrian(sitting)、Cyclist、Tram和Misc这8种类别。对原始数据集进行种类重划分以及格式转换。由于Cyclist和Misc在整个数据集中数量较少且识别度不高,所以去除这2类。将Car、Van、Truck、Cyclist、Tram合并为Car这一类,将 Pedestrian和Pedestrian(sitting)合并为Pedestrian一类。处理过后获得7 481张图片,包含Car和Pedestrian两种类别作为实验数据,按照8∶2的比例划分出5 885张图片作为训练集,1 596张图片作为验证集。
2.2 消融实验
为了验证改进部分对YOLOv5模型的影响,对上述的改进方法进行消融实验。评估指标包括多类别平均精度(mAP50/%、mAP50:95/%)、计算量(FLOPS)和参数量(Params),实验结果如表1所示。
表1结果说明,直接加入CA注意力模块虽然在mAP上会有所上涨,但Params以及FLOPS都会上涨不少,而融合过后的C3CA的mAP提升了0.9%,同时Params以及FLOPS几乎没有什么变化,证明了C3CA模块优于直接加入CA模块。Slim-Neck通过替换Conv为GSConv的操作,每个卷积可以节约70%的计算量,在mAP提升0.7%的同时降低了1.3个GFLOPS。最后替换SPPFCSPC金字塔模块因为本身的模型复杂程度大于SPPF增加了不少计算量,但同时也增加了0.7%的mAP值,总体上mAP50/%涨了2.3%,mAP50:95/%上涨了5%。
2.3 检测结果
本文采用训练完成的YOLOv5权重以及改进过后的权重对从测试集中选取的四组图片进行检测,检测结果如图6所示。
由图6可以看出,通过改进后的算法相较于原始的YOLOv5在目标检测方面,置信度更高,漏检误检率下降,一些漏检测的小目标也在改进后的算法检测中被检测到。
3 结论
本文提出了一种YOLOv5的改进方式,主要用于降低被检目标由于目标小、重叠等于原因出现漏检、误检的问题。首先加入C3CA模块代替C3模块,相较于直接添加CA注意力模块,不仅使mAP值有了一部分的提升,在速度和计算效率方面也大大降低了计算量(FLOPS)和参数量(Params);之后将原SPPF与CSP结构相结合设计出SPPFCSPC池化金字塔模块,拥有了更大的感受野,降低目标漏检情况;最后使用GSConv模块代替原始的Conv卷积模块,每一个GSConv都只需要Conv的70%计算量。通过卷积模块的替换,Neck网络变为Slim-Neck网络,在轻量化网络模型的同时,进一步提升算法的平均精度。将改进的算法与原始YOLOv5作对比,在检测精度方面改进后的算法提升了2.3%,在检测速度方面因为SPPFCSPC的加入,总体参数量变多,计算量相较于YOLOv5还相对减少了一些。
参考文献:
[1] 刘颖,刘红燕,范九伦,等.基于深度学习的小目标检测研究与应用综述[J].电子学报,2020,48(3):590-601.
[2] GIRSHICK R,DONAHUE J,DARRELL T,et al.Rich feature hierarchies for accurate object detection and semantic segmentation[EB/OL].[2022-06-20].2013:arXiv:1311.2524.https://arxiv.org/abs/1311.2524.pdf.
[3] GIRSHICK R.Fast R-CNN[C]//2015 IEEE International Conference on Computer Vision (ICCV).IEEE,2016:1440-1448.
[4] REN S Q,HE K M,GIRSHICK R,et al.Faster R-CNN:towards real-time object detection with region proposal networks[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1137-1149.
[5] 侯庆山,邢进生.基于Grad-CAM与KL损失的SSD目标检测算法[J].电子学报,2020,48(12):2409-2416.
[6] BOCHKOVSKIY A,WANG C Y,LIAO H Y M.YOLOv4:optimal speed and accuracy of object detection[EB/OL].[2022-06-20].2020:arXiv:2004.10934.https://arxiv.org/abs/2004.10934.pdf.
[7] HOU Q B,ZHOU D Q,FENG J S.Coordinate attention for efficient mobile network design[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).IEEE,2021:13713-13722.
[8] HE K M,ZHANG X Y,REN S Q,et al.Spatial pyramid pooling in deep convolutional networks for visual recognition[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,37(9):1904-1916.
[9] LI H L,LI J,WEI H B,et al.Slim-neck by GSConv:a better design paradigm of detector architectures for autonomous vehicles[EB/OL].[2023-02-20].2022:arXiv:2206.02424.https://arxiv.org/abs/2206.02424.pdf.
【通聯编辑:唐一东】
