基于深度学习的电商用户评论情感分析
2023-12-25崔滕
崔滕


摘要:随着我国移动互联网和互联网金融的快速发展,为更好地让商家和用户理解与分析电商平台上的用户评论,为了获取商品评论中的情感特征并捕捉更多的情感信息,可以使用深度学习技术来构建模型。文章提出构建BERT-BiLSTM-CRF模型,该模型将深层语言模型BERT与双向长短记忆网络和条件随机场模型(BiLSTM+CRF) 相结合建立新模型,运用BERT模型的嵌入层对句子进行分割,将其转为词向量后传递到BiLSTM模型中,从而获得文本中的属性和情感词,并使用条件随机场来解决远程依赖关系无法识别的缺陷。实验结果表明,通过国际语义评测大会提供的数据集,实验验证了本模型在文本情感分析精度方面的优越性。
关键词:情感分析;深度学习;双向长短时记忆模型;BERT
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2023)31-0034-04
开放科学(资源服务)标识码(OSID) :
0 引言
情感分析技术(sentiment analysis)[1]是一种能够对主观性文本或句子中所包含的情感色彩进行分析、处理和抽取的技术,是一种重要的自然语言处理技术,应用广泛,如方面级情感分析可以用于舆情分析、个性化推荐和搜索等领域中。在方面级情感分析中,方面是指句子中被描述、显式或隐式提及的实体或概念,而情感则是对方面的描述或评价。方面情感分析可以分为方面提取和方面情感分析两个子任务。方面提取的目標是从文本中识别出句子中的方面,而方面情感分析则是对提取出的内容进行情感判断。 在方面情感分析中,术语是指特定领域中常用的词汇或表达方式,可以帮助识别和描述方面的情感。通过对句子中的术语进行分析,可以更准确地判断方面的情感。 方面情感分析的结果通常以方面类别和情感极性两个维度进行描述。方面类别是对方面进行分类,常见的类别包括产品特征、服务质量、用户体验等。情感极性则是对方面的情感进行判断,通常分为正面、负面和中性。如今,在互联网技术的快速发展下,人们可以通过网络对已购买的商品或感兴趣的事物进行评论[2],这些评论数据对于企业和舆情相关部门都具有十分重要的价值。通过对产品的评论数据进行情感分析,企业可以更好地了解客户需求,进行个性化的销售,提高收益。同样的,舆情相关部门可以通过分析事件评论进行舆情分析和观点挖掘等,快速做出反应,控制和引导舆论,避免重大的舆情问题的发生。情感分析的早期方法也就是第一阶段主要是基于情感词典的匹配方式,需要人为构建情感词典。虽然这种方法在文本情感分类方面具有一定的灵活性,但是随着时代的发展,文本中的情感信息不易显现,使用情感词典的方法进行情感分析已经达不到预期的效果。第二阶段是基于机器学习的情感分类方法,使用朴素贝叶斯、随机森林和支持向量机等算法进行分类。虽然相对于第一阶段的方法,基于机器学习的方法能够带来不错的效果,但是它仍然存在局限性,只适用于小型结构化或标记化的数据集。第三阶段是现在广泛使用的深度学习,使用卷积神经网络、循环神经网络和注意力机制等深度学习技术,能够更好地处理大规模非结构化数据集,有效提高情感分类的准确性和效率。对于情感分析的历史,在1995年,Picard R W提出情感分析的概念,开始了相关研究;2002年,Turney P等人提出基于无监督学习方法的文本情感分析模型,但此模型方法输入的特征需要手动设计,这是一大缺点;随后,深度学习的概念被提出,后广泛应用于情感分析中;2015年,Le P等人提出了一种名为树形长短期记忆(Tree-LSTM) 模型的方法。该模型可以增强从单词层面到整个句子层面的特征合成能力,从而提高自然语言处理任务的性能。虽然情感分析的模型被越来越优化,但其结果仍受情感词典质量和判断情感规则的影响[3]。目前,研究上多采用Word2vec、BERT等基线模型的方法获取文本向量,但以上方法有着忽略词的上下文联系等方面的缺陷。因此,本文提出使用混合模型BERT-BiLSTM-CRF的方法提取向量来解决问题。
1 基于BERT-BiLSTM-CRF模型的情感分析
1.1 循环神经网络
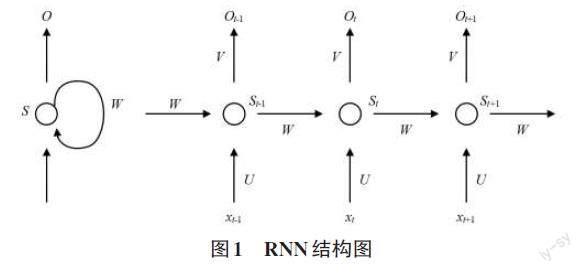
循环神经网络(Recurrent Neural Network) [4]是一种神经网络,能够发掘序列数据中的语义信息,因此在自然语言处理等领域应用广泛。与传统的前馈神经网络不同,RNN增加了循环结构,使得网络能够记忆先前处理过的信息,并将其应用于后续的输入数据中。这种设计能够有效地处理可变长度的输入序列,并在文本分类、机器翻译等任务中取得很好的表现。使得隐藏层不仅可以受到当前输入的影响,还可以接收上一时刻隐藏层的影响。
循环神经网络的核心思想是通过循环地传递信息来处理序列数据。在循环神经网络中,每个神经元的输出不仅依赖于当前输入,还依赖于上一时刻的输出。因此,循环神经网络可以更好地处理序列数据中的时序信息和长期依赖关系,从而提高模型的性能和准确性。
具体来说,循环神经网络将每个时刻的输入和上一时刻的输出作为输入,通过隐藏层中的循环结构来保留并传递上下文信息。这样,循环神经网络可以有效地挖掘出特征中的语义信息,从而提高模型的性能和泛化能力。在自然语言处理等领域,循环神经网络已经被广泛用在翻译、语音识别、情感分析等领域。循环神经网络设计展开如图1所示。
1.2 BERT
Devlin[5]等人提出基于Transformer的模型BERT,BERT是一种预训练的语言模型,其与传统模型不同,它采用了遮挡语言模型(Masked Language Model, MLM) 生成深度的双向语言表征。BERT模型对自然语言处理领域有着很大的提升与改善。传统模型使用单向训练或将两个单向训练相结合,而BERT则使用了多层的Transformer结构,以将句子转化为词向量,从而对语境进行更加透彻的分析。BERT-base的Encoder由12层结构相同的Transformer Encoder结构构成。虽然这些Encoder在结构上相同,但其之间的权重不可以共享。这意味着每个Encoder都具有独立的参数,可以对不同位置的输入进行不同的处理,从而进一步提高模型的性能。总之,BERT模型是一种基于深度双向语言表征的预训练语言模型,在自然语言处理领域中具有广泛的应用前景。通过使用多层的Transformer结构,BERT模型能够更好地对语境进行分析,提高模型的性能和泛化能力。BERT结构如图2所示。
1.3 Bilstm模型
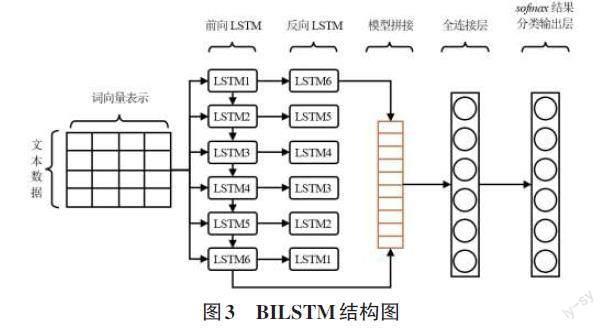
在自然语言处理中,单词的顺序对于句子的含义影响很大,但传统的深度神经网络模型并没有考虑输入数据的顺序。为处理这种现象,Zaremba[6]等提出RNN模型的概念,然而RNN模型存在梯度消失与爆炸的问题。为了更好地处理长序列数据,Hochreiter等提出了LSTM模型,LSTM模型引入三个门控单元,从而控制信息流动,使得模型可以学习哪些信息需要记忆、哪些信息需要遗忘,并能够捕捉较长距离的依赖关系。但LSTM模型只涉及由前到后的信息,无法获得当前位置后的信息。因此,BiLSTM模型被推出 ,该模型由双向LSTM组成,可以同时编码从前向后和从后向前的信息。BiLSTM模型在自然语言处理任务中经常被用于建模上下文信息,它能够更好地捕捉双向的语义依赖关系。BILSTM结构如图3所示。
1.4 CRF模型
CRF是自然语言处理领域中常用的基础模型,适用于分词、命名实体识别和词性标注等任务。CRF是一个无向概率图模型,用于将序列数据进行标记。CRF模型采用了全局归一化的随机场模型和条件随机场模型的优点,从而可以获得全局最优的标记结果。在训练过程中,为了简化模型,CRF仅训练正确选择相邻标签情况下的单个标签决策,以最大程度地减少误差。这种简化的训练方法可以提高训练效率,并在实践中表现良好,这种基于局部标签决策的方法被称为“随机场自动回归”(CRF-AR) ,其核心思想是通过建立每个标记对应的概率分布来确定最优标记序列。
1.5 本文构建的基于BERT-BiLSTM-CRF的模型
基于BERT-BiLSTM-CRF[7]的文本情感识别方法。首先,通过BERT作语义信息表示,继而将BERT编码以后的词向量通过双向长短期记忆网络学习上下文特征,得到隐藏层向量,然后通过CRF层学习相邻标签之间的依赖关系,得到全局最优的句子级标签序列,最终依据该标签序列对方面词进行抽取。文本情感模型如图4所示。
综上所述,基于BERT-BiLSTM-CRF算法模型的情感分析的步骤主要有以下4步:
1) 数据预处理:对文本数据进行清洗、分词等处理,得到符合模型输入要求的格式,送入BERT模型。
2) 模型训练:使用BERT-BiLSTM-CRF模型对预处理后的数据进行训练。
3) 模型预测:使用训练好的BERT-BiLSTM-CRF模型对新的文本数据进行情感分析。对于每个输入文本,模型会输出一个标注序列,其中每个标注表示该位置的字符的情感类别,例如正向情感或负向情感。
4) 结果后处理:对模型输出的标注序列进行后处理,例如去除无意义的标签、合并相邻的相同标签等,得到最终的情感分析结果。
2 实验结果分析
2.1 数据集预处理
在方面级情感分析领域,常用的数据集主要包括SemEval(国际语义评测大会)数据集。本文采用的数据集来自2014年国际语义评测大会(SemEval-2014) Task4提供的数据集:Res-14和Laptop-14,以及2015年国际语义评测大会(SemEval-2015) Task12提供的数据集Res-15:
1) SemEval-2014Task4数据集,由3000条左右餐厅评论、1800条左右笔记本评论组成,一部分划为测试集,其余作为训练数据集。去除有冲突情感极性或没有方面项的数据后,餐厅类训练样本2021个,测试样本606个。笔记本类训练样本1488,测试样本422个。
2) SemEval-2015Task12数据集由2000条左右餐厅评论组成,去除有冲突情感极性或没有方面项的数据后,训练样本1315个,测试样本685个。由于本章是对评论中给定的方面词进行情感极性判别,所以剔除数据集中不含有方面词的评论文本。为保证数据源的公平性,还对两个Res数据集进行平均,最终得出关于Res和Laptop两个对象的评论情感分析结果。
数据集相关统计信息如表1所示。数据集中方面的情感极性分为三类,分别为Positive、Negative和Neutral,每条评论都至少包含一个方面词。表中SN表示评论数量,AN表示方面词数量,Pos表示方面情感极性为Positive的标签数量,Neg表示方面情感极性为Negative的标签数量,Neu表示方面情感极性为Neutral的标签数量。
文本预处理的过程[8]为:去除多余无用符号:如HTML标签、特殊符号等;纠错处理:对文本中的拼写错误、语法错误等进行检查和纠正,以便于后续处理和分析;剔除无意义单词:可以使用自定义停用词表和删除特殊符号的方法。自定义停用词表可以剔除文本数据中那些频繁出现但无实际意义的单词;删除特殊符号可以通过使用正则表达式把文本中的特殊符号删除,以便于后续处理和分析;提取句子主干,使用SentenceBERT等模型提取句子主干,以削减冗余信息,避免句子过长无法训练的问题;索引長度标准化,对处理后的文本数据进行索引和标准化,以便于后续模型的训练和应用,如表2所示。
2.2 实验配置
硬件环境:64位系统,AMDRyzen75800HwithRadeonGraphics处理器,16.0GB内存,amdradeon(TM)graphics显卡。
软件环境:Python3.6,TensorFlow1.14.0。
Transformer设为12层,隐藏层的维度设为768,注意力机制的头数设为12。模型总参数大小为110MB。特征提取层主要由BILSTM构成。
模型训练方面:设置批次大小为64,最大序列长度为512,隐藏层个数为13,epoch为4,batchsize设定为256,优化器选用lamb,dropout率为0.5。
2.3 实验评价指标
实验分析数据[9]是消极还是积极,若预测结果为积极,则标记为1,反之标记为0,如表3所示。
表3中,TP含义:预测是积极,实际是积极;FP:预测是积极,实际是消极;FN:预测是消极,实际是积极;TN:预测是消极,实际是消极。而对于研究中的评价指标,本文有以下几种:
1) 召回率(Recall score) :表示模型的实际为1的样本,预测也为1的概率,计算公式如下:
[R=TPTP+FN]
2) 精准率(Precision score) :在所有预测为1的样本中,实际上有多少个样本真的为1,其计算公式为:
[P=TPTP+FP]
3) F1值(F1-score) :是对以上两个指标进行加权平均的结果,其计算公式为:
[F1=2PRP+R]
2.4 实验结果分析
本文将准确率、召回率和F1值[10]三个方面作为评价指标。其中,准确率衡量了分类器对负样本的区分能力,召回率衡量了分类器对正样本的识别能力,而F1值是综合考虑准确率和召回率的指标,能够全方面地反映出分类性能。用F1值分析评估分类器时,如果分类器性能越好,则其值(F1值)越接近于1。所以本文将F1值作为主要的评价指标。
本实验在对比模型上,样本分别选取了BERT、BILSTM、CNN模型进行训练与结果比较。具体描述如下。
1) BERT:首先使用预处理模型使参数与之前预设的参数一致,利用预训练文本特征后输入BERT情感分类。
2) BILSTM:定义参数的大小同2层BILSTM模型的结构一样,使用全连接层,最后通过Sof Max分类器得出结果。
3) CNN:使用TensorFlow中的CNN,调整input与卷积核参数,迭代次数为100,epoch次数为5,词向量的维度为20。
由表4的整体结果分析可知,BERT-BILSTM-CRF模型精度与BERT、BILSTM和CNN精度相比分别提高了3.32%、9.1%和4.35%。BERT-BILSTM-CRF模型相对于传统文本模型在进行情感分析上可以获得更好的结果。
3 结论
针对网络评论文本中包含丰富的情感信息,通过详细介绍文本情感分析领域中常用的情感分析方法和算法,本文设计了基于BERT-BiLSTM-CRF的模型,对电商平台的评论文本进行情感分析。在BERT模型的基础上,加入BiLSTM+CRF模型。首先,通过BERT作语义信息表示,继而将BERT编码以后的词向量通过双向长短期记忆网络学习上下文特征,得到隐藏层向量,然后通过CRF层学习相邻标签之间的依赖关系,得到全局最优的句子级标签序列,最终依据该标签序列对方面词进行抽取。结果证明,基于BERT-BiLSTM-CRF混合模型用于文本的情感分析,在提高情感分析的精确性方面具有优越性。
参考文献:
[1] ZHANG X J,HUANG S,ZHAO J Q,et al.Exploring deep recurrent convolution neural networks for subjectivity classification[J].IEEE Access,2018(7):347-357.
[2] 王鹏岭,应欣慧,梁家瑞,等.网购评论情感分析:以某化妆品为例[J].电脑知识与技术,2022,18(13):21-23.
[3] 康月,薛惠珍,华斌.面向深度学习网络的细粒度商品评价分析[J].计算机工程与应用,2021,57(11):140-147.
[4] 郭佳怡,唐矛宁,宋涛,等.旅游景区印象分析系统V1.0:2022SR0471334[P].2022-04-14.
[5] DEVLIN J,CHANG M,LEE K,et al.BERT:pre-training of deep bidirectional transformers for language understanding[EB/OL].[2022-10-20].https://arxiv.org/abs/1810.04805.pdf.
[6] ZAREMBA W,RAY A,SCHNEIDER J,et al.Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World[2021-10-12].https://arxiv.org/abs/1703. 06907.
[7] 赵宏,傅兆阳,赵凡.基于BERT和层次化Attention的微博情感分析研究[J].计算机工程与应用,2022,58(5):156-162.
[8] 王美荣.基于卷积神经网络的文本分类算法[J].佳木斯大学学报(自然科学版),2018,36(3):354-357.
[9] 赵富,杨洋,蒋瑞,等.融合词性的双注意力Bi-LSTM情感分析[J].計算机应用,2018,38(S2):103-106,147.
[10] 石文华,高羽,胡英雨.基于情感倾向和观察学习的在线评论有用性影响因素研究[J].北京邮电大学学报(社会科学版),2015,17(5):32-39.
【通联编辑:谢媛媛】
