基于语义的互联网医院评论文本情感分析及应用
2017-03-27夏东杰刘少霞
夏东杰+++刘少霞


摘要:基于如何能够更好地利用互联网医院的评论信息,使其能够有利于指导医院改進提高,让人们能够更好地了解以往患者就诊的情况,同时探讨更好的提升文本情感分析效果的方法。该文首先使用python爬虫爬取乌镇互联网医院的评论信息,其次在hownet词典的基础上,构建新的情感词典、否定词典、程度副词词典以及连词词典,构建了相应的情感分析规则。同时,根据评论信息分词后的词频数据运用R语言进行数据的可视化分析。得出使用情感词典和语义规则对互联网医院评论信息进行分析是有效的结论,同时指出了评论者关注点主要在态度、效果、耐心、治疗、预约、病人、时间等方面上。
关键词: 互联网医院;文本分析;情感分析;情感词典;语义规则
中图分类号:TP18 文献标识码:A 文章编号:1009-3044(2017)03-0180-04
随着我国互联网的高速发展,越来越多的传统业务借助互联网实现业务的转型升级。加上我国医疗改革的呼声日益高涨,互联网医院开始悄然兴起。互联网医院是代表医疗行业发展的新方向,它对解决我国现在医疗资源严重不平衡以及人们日益增加的医疗资源的需求之间的矛盾具有巨大的推动作用,是目前我国卫生部门积极引导及推动的医疗发展新模式[1]。
互联网医院除了将传统的挂号、疾病咨询、处方等流程搬到互联网上[2],还为患者或患者家属提供了向互联网医院传达医院服务水平、表达自己在医院服务感受的平台,即面向大众的互联网评论。患者及患者家属可以通过平台对互联网医院的服务环节、具体环境、资源分配等各个方面发表自己的看法,一方面向医院传递医院值得肯定的地方及医院需要改进的环节等信息,从而提升患者的体验,另一方面给想要了解互联网医院服务状况的患者及患者家属提供了良好的信息通道。由于互联网医院评论数量非常多,而且多为一百字以内的语句级短文本,如何能够快速准确地从这些语句级评论中分析出评论者的关注点以及对互联网医院的服务的正负向评价从而给医院的改进提供方向,成为了亟须解决的研究课题。
1 相关研究情况
本文是对互联网医院评论的文本信息进行分析和研究,根据评论信息判定其情感的倾向性及关注点内容。就文本情感分析而言,目前学术界已经有许多专家和学者研究如何快速高效的进行情感的倾向分类。根据是否训练学习可以将情感分类的方法分为基于语义规则的情感分类和基于机器学习的情感分类[3]。根据文本的处理粒度的大小不同,则可以将文本情感分类分为篇章级分类、语句级分类、词语级分类[4]。本文采用的是基于情感词典与语义规则的语句级分类方法进行分类。
对于基于情感词典与语义规则方面的研究,徐琳宏、林鸿飞等通过计算待分类文本词汇与知网中已标注词汇之间的相似度,选取倾向性明显的词汇作为特征词,采用SVM及语义规则相结合的方法,提高对文本褒贬的识别强度[5]。赵鹏、赵志伟等提出了基于语义的TriPos模式的分类方法,将统计分析与语义分析相结合,提高了主客观分析的准确率、召回率和F值,取得了良好的效果[6]。吴江、唐常杰等通过Apriori方法对金融文本属性进行抽取,然后使用语义规则的分析方法对web金融文本进行情感分析[7],取得的结果优于ku[8]的算法结果。杨立公、樊孝忠等提出了最大限度地综合利用各种语言的词典信息,对候选词进行情感语义归类,适用于没有其他知识背景的情况,具有一定的实用价值[9]。王志涛、於志文等根据微博的特性,对微博的不同语言层次制定不同的语义规则,结合微博文本的粒度和表情符号,对微博文本进行情感分类,并验证了该方法的有效性[10]。赵天奇、姚海鹏等则通过把微博表情引入情感加权的方式,使得微博情感分类有了一定程度的提高[11]。陈国兰在已经标注的微博语料的基础上,构建包括程度副词、关系连词、否定词的词典,使用SVM分类,取得了较好的效果[12]。杨佳能、阳爱民构建了表情符号词典和网络用语词典,并使用依存句法分析构建情感表达树,并制定语义分析规则计算微博文本情感强度进行情感分类,证明了加入表情符号和网络用语有助于情感分类[13]。
2 评论文本的获取与处理
2.1 评论文本的获取
本文是选取乌镇互联网医院(挂号网)中的复旦大学附属中山医院的患者的评论信息作为研究对象进行文本情感分析。作者通过借助Python爬虫完成挂号网账号的登录、验证码的识别、评论信息的下载等任务,共获取4315条评论信息。
2.2 评论信息的预处理
1)由于评论信息中存在同一个评论者连续评论多次,且每次评论的内容都相同的情况,所以需要对多余的评论信息进行删除处理。
2)对评论信息进行中文分词处理。目前分词工具比较多,使用较多的有jieba分词、中科大的NLPIR系统分词、庖丁解牛分词等等,本文使用中科大的NLPIR系统进行分词。该分词方法在分词、词性标注等方面取得较好的效果,同时方便添加词典。
3 相关词典的构建
3.1 网络用语情感词典的构建
由于目前网络信息非常多且更新的非常快,每时每刻都会产生新的网络用词代表使用者的情感倾向,比如“然并卵”、“日了狗”、“猴赛雷”等等。这些词在使用者使用时是作为一个完整的词来表达他们特定的情感,但是由于分词系统并不能及时将这些新的词纳入到分词词典中去,从而导致在分词的过程中,将一个完整的词拆分为若干部分,如“日了狗”被拆分为“日”、“了”、“狗”,“猴赛雷”被拆分为“猴”、“赛”、“雷”,从而失去了原来的意义,不利于评论者情感倾向的分析。
本文认为在同一句内,如果分词后的若干个词一起连续出现的次数超过一定的较小的阈值但又同时小于一个较大的阈值,则可以初步判断若干词连续组合起来有可能形成一个新词。例如“日了狗”作为一个网络用词可能会有较多的评论者在评论时用到,但是对整个评论的数量而言,仍然是少数的,同时,“听了”、“好了”等一些常见的一起出现的组合却不应该作为一个新词对待。根据该原则,本文构建获得新词的算法通过以下伪代码实现:
[算法3.1 查找新词\&输入:\&\&\&评论信息\&\&阈值下限n\&\&阈值上限N\&输出:\&\& \&新词\&
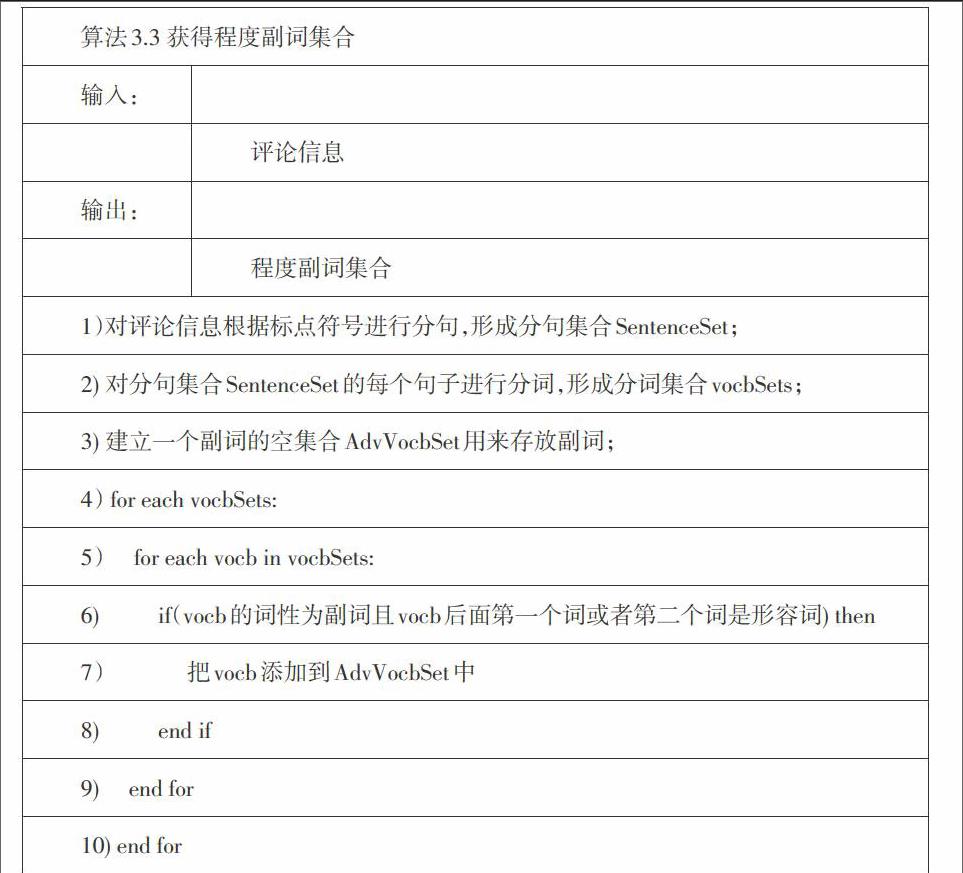
1)对评论信息根据标点符号进行分句,形成分句集合SentenceSet;\&2) 对分句集合SentenceSet的每个句子进行分词,形成分词集合vocbSets;\&3)建立一个词频集合FreqSet{vocb,freq},其中vocb代表词,freq代表该次出现的频率,初始化为0;\&4) 建立一个新词的集合newVocbSet用来存放新词;\&5) for each vocbSets:\&6) for each vocb in vocbSets:\&7) if(([vocbi]+[vocbi+1])没有出现在FreqSet中) then \&8) FreqSet中([vocbi]+[vocbi+1])对应的频率为1\&9) elseif(([vocbi]+[vocbi+1])出现在FreqSet中) then\&10) FreqSet中([vocbi]+[vocbi+1])对应的频率再加1\&11) end if\&12) end for\&13) end for\&14) for each freq in FreqSset:\&15) if(freq的值>n and freq的值 17) end if 18) end for\&19) 手动将不是新词的组合删除,并对新词进行倾向性分类形成网络用语情感词典\&] 算法3.1可以根据每相邻两个词的组合构建网络用语,由于部分网络用语词典是有多个词组成的,所以本文还针对相邻三个词、相邻四个词分别做了相同的处理,得到更为全面的网络用语情感词典。通过该方法,本文共获得了“点赞”,“牛逼”,“狂顶”,“白跑一趟”等53个新词,其中褒义的有32个,贬义的有21个。 3.2 基于HowNet的情感词典的构建 3.2.1 情感词的相似度计算 HowNet(知网)是一个以汉语和英语的词所代表的概念为描述对象,揭示概念之间及概念的属性之间的关系为基本内容的知识库[14]。在HowNet中,词语与词语之间的相似度是通过义原之间的距离加权计算得出。刘群、李素建等提出了通过如下方式来计算语义相似度的公式[14]: [sim(p1,p2)=αα+dist(p1,p2)] (1) 其中,α表示一个正的可变参数,dist(p1,p2)则表示义原的距离。但是这种方法并不完善,例如“漂亮”和“美丽”的意义基本一样,在通过该公式计算后相似度最大值为1,而“美丽”和“丑陋”两个词的意义是相反的,但是通过该公式计算两个词的其他基本义原的相似度也是1,所以这个方法不太准确。江敏、肖诗斌等针对以上算法提出了新的基于HowNet的改进的语义相似度的计算方法[15],公式如下: [][sim(p1,p2)=α(depth(p1)+depth(p2))α(depth(p1)+depth(p2))+dist(p1,p2)+|depth(p1)-depth(p2)|] (2) 其中depth(p1)表示p1距离根节点的层次,dist(p1,p2)表示义原之间的距离,α表示一个正的可变参数。同时,具有以下规定:①如果p1,p2两个义原具有相反意义,则他们的相似度记为-1;②如果p1,p2两个义原路径中存在相反意义的关系,则他们的相似度记为-1*sim(p1,p2) ′。其中sim(p1,p2) ′是将距离p1,p2最近的一对具有相反意义的义原节点看作同一个节点,然后通过(2)式计算得出。 3.2.2 情感词的倾向性计算 情感词倾向性可以通过计算待分类情感词语与基准情感词的相似度的大小来判断。本文先人工选取并确定两组强度很强的基准词,一组是褒义的,一组是贬义的,分别有43个词,其中褒义的倾向值强度为1,贬义的倾向志强对为-1。然后通过以下公式计算待分类情感词的倾向性[16]: [orientation(word)=1ni=1nsim(word,seed1i)-1mj=1msim(word,seed2j)] (3) 其中seed1i为褒义的基准词,seed2j为贬义的基准词,如果结果为正数,则可以判定该待分类词应该为褒义的,同时加入到褒义词中,如果结果为负数,则可以判定待分类词为贬义的,同时加入到贬义词中去,其中,orientation(word)的值作为word的倾向值强度。 3.3 修饰词词典的构建 3.3.1 程度副词词典的构建 在评论信息中,许多情感倾向词前带有程度副词作为修饰,来表达评论者的情感的强弱,但是一般不改变情感的极性。由于中科大分词系统在分词过程中,能过对各个词进行词性标注,因此可以根据分词后的词性标注获得程度副词集合,进而组成程度副词词典。本文获得程度副词采用的算法如下: [算法3.3 獲得程度副词集合\&输入:\&\&\&评论信息\&输出:\&\& \&程度副词集合\&1)对评论信息根据标点符号进行分句,形成分句集合SentenceSet;\&2) 对分句集合SentenceSet的每个句子进行分词,形成分词集合vocbSets;\&3) 建立一个副词的空集合AdvVocbSet用来存放副词;\&4) for each vocbSets:\&5) for each vocb in vocbSets:\&6) if(vocb的词性为副词且vocb后面第一个词或者第二个词是形容词) then \&7) 把vocb添加到AdvVocbSet中\&8) end if\&9) end for\&10) end for\&11) 对AdvVocbSet进行Set集合运算,去掉重复的词,最终获得非重复的副词集合\&]
然后对程度副词集合进行人工筛选和进一步补充,并对其修饰程度赋予权值,从而组成程度副词词典。本文将修饰程度分为4个等级,具体如表1所示:
表1 程度副词表示及权值
3.3.2 否定词词典的构建
鉴于否定词的数量较少,且比较好搜集,本文通过搜集、整理,一共得到了25个否定词,如:“不”、“非”、“没”等,并将它们加入到否定词词典中去,否定词典的词的权值都为-1。
3.3.3 连词词典的构建
由于有些评论者的评论信息中会含有连词,而不同的连词可能有不同的作用,如“而且”作为递进关系的连词表示情感极性的强化,“但是”作为转折关系的连词则表示情感极性的反转。鉴于连词对整个句子的情感强度具有加强或者削弱等作用,本文按照算法4.3的方式,只是将“副词”改为“连词”,获得较多的连词,经过进一步的人工筛选和补充,并赋予权值,具体如表2所示:
表2 连词表示及权值
4 语句的情感极性分析
本文对评论信息中的词语组合进行倾向值计算,从而判断该词语组合的倾向性,具体的规则如下:
规则一:在每个分句中,如果出现情感词前面五个词中出现否定词但是没有副词,则计算否定词的数量,如果否定词的数量为奇数,则初步判定该词组合与情感词的倾向相反,强度为情感词强度*-1;如果否定词的数量为偶数,则初步判定该词组合与情感词的倾向相同,强度为情感词强度*1;如果不出现否定词,则情感词的倾向性和强度不变。
规则二:情感词之前出现了程度副词,则该词组的情感倾向与情感词的倾向一致,情感强度为程度副词的权值*情感词的强度。例如“刘医生的态度非常差。”,其中“非常”的权值为最高级5,“差”的情感强度为-1,所以“非常差”的情感倾向为负,即贬义,情感强度为-5。
规则三:情感词前同时出现否定词和程度副词,则需要考虑副词和否定词的位置。如果副词在否定词之前,则表示侧重副词对否定词起作用,规定副词+否定词的情感强度为副词的权值*-2;而否定词在副词之前,则表示侧重否定词对副词起作用,规定否定词+副词的情感强度为副词的权值*-0.5。然后将程度副词和否定的组合当做新的程度副词对待。例如:“不太好”和“太不好”,都表示“不好”的意思,但是明显“太不好”表示的强度比“不好”的强度更强,而“不太好”的情感强度比“不好”的情感强度要弱。
规则四:每个分句如果出现了连词,则该句的情感强度要在以上规则计算基础上乘以连词的权值来计算得出。
规则五:每条完整的评论信息的情感强度值由各个分句的情感强度值相加得出。
如果用a表示情感值强度,ad表示程度副词权值,n表示否定词个数,c表示连词权值,用g表示组合后的情感强度,以上规则的情景可通过表3表示:
表3 情感强度计算方法
5 实验与分析
5.1 评论信息关注点分析
本文对评论者评论关注点获取方式是基于关键词的频数。通过对所有的评论信息进行分词,然后引入停用词词典,将存在停用词词典中的词删除,对剩余的所有词计算词频,取前300个词及词频,通过R语言的wordcloud包对词和词频进行可视化,具体如图1:
图1
从图1可以很容易看出关键词依次是:态度、医院、效果、耐心、治疗、预约、病人、时间等等。可见评论者对医院医生的态度、是否耐心、治疗的效果,预约的便捷性以及看病排队的时间是比较关注的。对于医院而言,也可以有方向地针对这些关键点,着手改进和提高,从而提升患者的看病体验。
5.2 语句倾向性效果分析
本文通过爬虫的方式,从乌镇互联网医院(挂号网)共爬去4315条数据,然后使用本文提到的方法构建词典,其中新词词典共有词汇121个,褒义词有76个,贬义词有45个,情感词典共有词汇12624个,褒义词有7342个,贬义词有5282个,程度副词有219个,否定词25个,连词47个。然后用既定的规则对评论信息分析情感倾向性的强度值。本文规定,如果整个语句的情感倾向性强度值大于0.15,则判定为褒义的;如果整个语句的情感倾向强度值小于-0.15,则判定为贬义的;如果整个语句的情感倾向强度值介于-0.15-0.15之间,则判定为中性的。对性能的评估,本文使用查准率(Pecision)、查全率(Recall)和F值来评估:
Pecision = 提取出正确的信息条数 / 提取出的信息条数,
Recall = 提取出正确的信息条数 / 样本中的信息条数,
F = (2*Pecision*Recall)/(Pecision+Recall)。
本文分别计算了基础的情感词典、基础情感词典+新的情感词典、基础情感词典+新的情感词典+语义规则来计算查准率、查全率和F值,具体如表4所示:
表4 實验方法效果对比
通过实验验证,在基础情感词典的基础上加上新的情感词典以及使用语义规则的方法能够较大的提高准确率和F值,即该方法取得了较好的效果。
6 结论
本文通过在现有情感词典的基础上,构建新的情感词典、否定词典、程度副词词典以及连词词典,并对词典的词赋予一定的权值,从而能够根据规则计算评论信息的强度值,方便对其进行情感极性的分类。同时,本文对中性评论的强度指定了一个范围,从而能够更好地对评论信息的极性进行分类,更符合实际情况。根据指定语义规则分类,最后取得较好的效果。本文还根据评论信息分词后的词的频率,找出了关键词,并进行了可视化,从而方便直观地看出评论者的关注点,对医院的改进和提高有借鉴意义。但本文还有较多的不足之处,大致包括以下几点:
1)本文的词典构建主要依赖于Hownet,比较单一,而目前已经有较多的情感词典可供参考,从而从多个角度计算情感词典的强度,这样更为理想。
2)本文标注、测试的文本数量只有4315条,数量相对较少,获取的新词也不够多,对较大数量的文本,获取新词的成本会比较高。
3)对语句的分析类型还不够,可以增加反问句、疑问句、正话反说等等的句式以及更多其他的搭配,从而能够更加符合评论的实际情况。
总体来说,评论信息的文本情感分类的研究还不是十分的完善,仍然需要相关方面的专家和学者不断提高分类的效果。
参考文献:
[1] 刘新. 互联网医院,来了![J]. 互联网经济,2015(5):16-19.
[2] 閆龑. 聚焦互联网医院[J]. 现代养生,2016(10):6-7.
[3] 马力,宫玉龙. 文本情感分析研究综述[J]. 电子科技,2014(11):180-184.
[4] 杨立公,朱俭,汤世平. 文本情感分析综述[J]. 计算机应用,2013(6):1574-1578+1607.
[5] 徐琳宏,林鸿飞,杨志豪. 基于语义理解的文本倾向性识别机制[J]. 中文信息学报,2007(1):96-100.
[6] 赵鹏,赵志伟,陶新竹,等. 基于语义的TriPos模式的中文主客观分析方法[J]. 计算机应用研究,2012(9):3285-3288.
[7] 吴江,唐常杰,李太勇,等. 基于语义规则的Web金融文本情感分析[J]. 计算机应用,2014(2):481-485+495.
[8] KU LW, LIANG Y T, CHEN H H. Opinion extraction,summarization and tracking in news and blog corpora[C]//Proceedings of the 2006 AAAI Symposium on Computational Approaches to Analysing Weblogs. Menlo Park: AAAI Press,2006:100-107.
[9] 杨立公,樊孝忠,朱俭. 利用语义词典的情感词快速识别[J]. 计算机工程与设计,2013(8):2978-2982.
[10] 王志涛,於志文,郭斌,等. 基于词典和规则集的中文微博情感分析[J]. 计算机工程与应用,2015(8):218-225.
[11] 赵天奇,姚海鹏,方超,等. 语义规则与表情加权融合的微博情感分析方法[J]. 重庆邮电大学学报:自然科学版,2016(4):503-510.
[12] 陈国兰. 基于情感词典与语义规则的微博情感分析[J]. 情报探索,2016(2):1-6.
[13] 杨佳能,阳爱民,周咏梅. 基于语义分析的中文微博情感分类方法[J]. 山东大学学报:理学版,2014(11):14-21,30.
[14] 刘群,李素建.基于 “知网” 的词汇语义相似度计算[C]//第三届汉语词汇语义学研讨会论文集.台北,2002:59-76.
[15] 江敏,肖诗斌,王弘蔚,等. 一种改进的基于《知网》的词语语义相似度计算[J]. 中文信息学报,2008(5):84-89.
[16] 李永忠,胡思琪. 基于HowNet和PAT树的网购评语情感分析[J]. 图书情报研究,2016(3):66-70,65.
