基于SVM的产品评论情感分析系统的设计与实现
2017-01-12彭德焰胡欣宇
彭德焰++胡欣宇


摘 要:各大电商的产品留言体现了消费者对商品的主观情感,海量的评论信息要用人工来收集和处理是不可能完成的任务,因此需要利用专门的情感分析技术来帮助解决这些问题,文中将属性词词典,情感词词典以及程度词词典和否定词词典作为基础,通过SVM分类法对属性词和程度词的搭配进行识别,以此构造一个产品评论文本分析系统,测试表明系统对产品评论的情感分析具有较高的准确率。
关键词:产品评论;SVM;搭配识别;情感分析
中图分类号:TP393 文献标识码:A 文章编号:2095-1302(2016)11-00-04
0 引 言
随着Web技术和电子商务的发展,越来越多的人在各大电商上对自己买过的产品发表评论,这些信息绝大部分代表着发布者的观点或主观情感。商家如果能够得到用户的这些反馈,将有助于商家的下一步生产和销售决策。而其他准备购买该商品的顾客也可以根据这些反馈来更好地帮助自己决定该商品是否值得购买。因此对这些情感信息进行有效的自动分析并构建相应系统成了当今的热门研究问题之一。
产品评论的挖掘分析主要是基于句子级别的情感分析,其主要任务有识别并获取产品的特征或属性,定位用户的主观性评论,抽取评论搭配,判别用户评论的褒贬[1]。本文构造的系统以属性词词典,情感词词典以及程度词词典和否定词词典为基础,通过SVM分类法对属性词和程度词的搭配进行识别,进而分析评论的褒贬。
1 相关研究
Probst等[2]利用监督学习技术抽取属性词—评论词关系对。Yohan等[3]基于LDA模型提出SLDA模型。实验表明,该类方法在抽取产品特征中有一定的效果。栗春亮等[4]利用百度百科和分词后相邻的词语同现比例来识别专业领域内的生词,在中文产品评论语料中设计词性组合模板来得到候选属性词集,然后利用一定的规则对其过滤。Qiu[5]等通过研究评价词和评价对象间的关系模式,提出用一种双向传播算法进行抽取。本文对产品属性词的抽取主要借鉴文献[4]中提到的方法,得到1 500个属性词,作为属性词词典。情感词典的构建方式主要有人工和基于词典两种。目前主要使用的词典有董振东和董强编撰的HOWNET情感词典和台湾大学编撰的NTU情感词典。Hassan等[6]使用马尔科夫随机游走模型计算词语的情感权值。柳位平等[7]在中文词语相似度计算方法的基础上提出了一种中文情感词语的情感权值计算方法,并以HOWNET情感词语集为基准,构建了中文基础情感词典。阳爱民等[8]选用若干个情感种子词,利用搜索引擎返回共现数,通过改进的PMI(Pointwise Mutual Information,PMI)算法计算情感词的情感权值。李寿山等[9]借助机器翻译系统,结合双语言资源的约束信息,利用标签传播算法(LP)计算词语的情感信息。本文主要根据文献[8]提出的方法,构建一个在产品评论分析中使用的情感词典,部分词如图1所示。程度词和否定词词典使用王文华等[10]提出的相应词典。
词集 极性 情感词
P_set 正向 著名,好,积极,和谐,青春,成熟,善良,文明,出色,舒服,纯真,得体,美丽,创造力,宽容,昌盛,感激,优秀,美好,灿烂,诚实,给力,帅呆,霸气,淳朴,漂亮,美妙,辉煌
N_set 负向 罪恶,诅咒,暴殄天物,郁闷,傻逼,变态,惨不忍睹,痛苦,垃圾,失败,委屈,毛病,扭曲,诡异,畸形,悲惨,崩溃,弱爆,狠毒,假冒,水货,粗暴
对属性词和情感词的搭配识别可以看成是一个分类问题,常用到的分类算法包括朴素贝叶斯分类器(Naive Bayesian Classifier)、基于支持向量机(Support Vector Machine,SVM)的分类器、k-最近邻法(k-Nearest Neighbor,kNN)、决策树(decision tree)分类法、最大熵模型(Maximum Entropy, ME)等,本文使用SVM作为搭配识别的分类器,搭配规则使用文献[10]中提到的8条规则。
2 情感分析系统的需求分析和设计目标
2.1 需求分析
产品评论情感分析系统用来对电子商务网站上的产品评论进行搜集分析。
(1)该系统首先对某个站点进行页面抓取、内容提取,得到用户对产品的大量评论信息;
(2)进行分词、关键信息抽取;
(3)对这些评论信息进行分析,挖掘出用户对产品各种属性的情感倾向以及对整个产品乃至商家的褒贬倾向;
(4)将结果进行展示,从而有效辅助希望购买产品的用户进行合理的消费判断,同时也能够帮助产品生产商做下一步生产和销售决策。
根据这些需求,可以对本系统做出如下需求分析:
(1)能够抓取产品评论页面并能对页面中的评论内容进行提取。
(2)能够从评论文本中抽取情感信息。
(3)能够有效搭配识别分类。
(4)能够准确进行属性情感极性分析和文本情感的倾向判断。
(5)预留开发接口,能方便的对搭配识别分类算法进行更改。
(6)能够将结果以用户易于理解的方式展示出来。
由此可以得出图2所示的产品评论情感分析系统的工作流程。
2.2 设计目标
通过需求分析,可以将系统功能划分为网页抓取及页面内容提取模块、情感信息提取模块、情感分析模块。
(1)网页抓取及页面内容提取模块实现网页抓取及页面文本提取的功能。
(2)情感信息提取模块负责从抓取到的页面或者用户自定义的文本中抽取出关键情感信息。
(3)情感分析模块对情感信息提取模块抽取出的关键情感信息进行情感分析,得出结论。
对中间信息以及最后的结论信息进行存储,并通过用户容易理解的方式进行结果展示。一个优秀的软件系统首先要实现系统需要的各个功能模块,其次要达到系统的性能指标,最后还要为用户提供高可靠性的服务。所以,系统设计时应当考虑到如下几个方面:
(1)功能性。本系统该实现需求分析中提出的各项功能。
(2)有效性。能够对产品评论进行有效的情感分析。由于使用现有语料进行的封闭性测试比直接采集互联网信息所得的结果低一些,因此系统对产品评论文本进行情感分析后的准确率要比算法设计过程中的测试结果高。
(3)易用性。系统应该操作方便,使用简单,展示的结果容易理解。
(4)可维护性。系统应该能够方便的对内置情感分析算法进行替换、维护,以便将来对算法进行改进。
(5)健壮性。系统应该运行稳定,出现意外后退出能重新启动。
3 情感分析系统的设计与实现
根据上节对系统进行的需求分析和目标设计,本节对整个系统的功能进行了划分,得出了图3所示的系统功能模块图。
图3将产品评论情感分析系统划分成评论信息获取模块、信息预处理模块、情感分析模块。
3.1 页面抓取
页面抓取模块主要用一个网络爬虫来完成。使用Apache的HTTP客户端开源项目HttpClient,HttpClient提供HTTP的访问主要通过GetMethod类和PostMethod类来实现,它们分别对应HTTPGet请求与HttpPost请求。具体抓取操作流程如图4所示。
3.2 页面内容提取
页面内容提取的方法很多,有基于统计的、基于规则的、机器学习的,还有基于DOM树的。基于DOM树的方法将页面中的内容和结果看成是一棵树。Java有一个非常实用的开源工具包HtmlParser,主要靠Node、AbstractNode和Tag等数据结构来构造HTML的树形结构,包括RemarkNode和TextNode。单个页面内容提取的流程图如图5所示。
在不同的网站中,页面内容的HTML标签不同,因此需要对不同网站设计不同的提取模板。在这里用正则表达式来区分不同的网站,首先将同一个页面提取模板的一组URL构造成一个或多个正则表达式,然后判断网页的URL与正则表达式是否匹配,进而选择页面提取模板。
3.3 分词模块
中科院计算所开发的ICTCLAS(Institute of Computing Technology,Chinese Lexical Analysis System)分词系统是目前世界上较好的中文分词系统,本文使用其Java版本ICTCLAS4J。使用MyLexicon类描述分词模块,该模块的成员如图6所示。
addDictionary(fileName)方法使用ICTCLAS4J提供的ICTCLAS50类的ICTCLAS_ImportUserDictFile(usrdirb, n)方法,该方法返回导入用户词语个数,第一个参数为用户字典路径,第二个参数为用户字典的编码类型。textProcess(str)方法使用ICTCLAS50类的ICTCLAS_ParagraphProcess()方法分词。对得到的字符串按照空格分开,读取存放属性词典和情感词典的资源文件,对分割好的的每一个词与资源文件中的词语进行对比,提取出属性词和情感词,构成属性词集attrset和情感词集sentset。
3.4 分析预处理
分析预处理模块工作过程如下:
(1)在分词的基础上形成属性词集合和情感词集合;
(2)将两个集合作笛卡尔乘积得到形如<属性词,情感词,情感权值>若干三元组;
(3)根据8条搭配分析规则,形成原始模板;
(4)得到带有原始模板的扩展三元组。
用Preprocess类来描述分析预处理模块,该模块的成员如图7所示。
属性词集合、情感词集合、三元组、原始模板都用数组来描述,getTriple()、getPattern()为私有方法,该类只对外提供getNewtriple()方法。
3.5 搭配识别模块
这里使用林智仁等开发的libsvm软件包,在系统中,将该子模块封装成Classifier类,主要提供模型的训练和对新文本进行搭配识别的分类功能。该类的成员如图8所示。
libsvm的数据格式为:<类别标签> <索引序号 1>:
使用SVM分类器对文本进行分类,若返回值为1表示搭配,则将newtriple保存,用于下一步的情感分析判断;若返回值为-1则表示不搭配。precise(datapath, percent)函数用来对算法的准确度进行测试,包含datapath和percent两个参数。datapath表示训练数据所在路径,percent表示训练数据占总数据的比例,默认的percent取0.5,即随机取一半的数据作为训练,另一半数据进行测试。返回值为分类的准确率。
3.6 情感分析判断
根据节文本情感倾向判断过程进行的描述,得到图9所示的情感分析判断流程。
用Analysis类来描述情感分析判断模块。该类的成员如图10所示。
judge()方法用以判断sentiment的值,大于0为正向情感,小于0为负向情感。
4 结 语
整个系统操作界面由评论提取部分、输入(导入)评论部分和情感分析部分组成。用户在输入框中输入产品评论的地址,点击“提取评论”按钮后,系统自动将产品评论页面抓取下来并将评论提取出来,保存到默认路径下的文件中。点击“保存”按钮可以手动选择路径和保存的文件名。 用户要想对提取的评论进行分析时,可以点击“导入”按钮,选取指定的评论文件,此时文件中的内容将显示在文本框中,输入评论后,点击“情感分析”按钮即可将产品评论文本情感分析的结果显示出来,如图11所示。
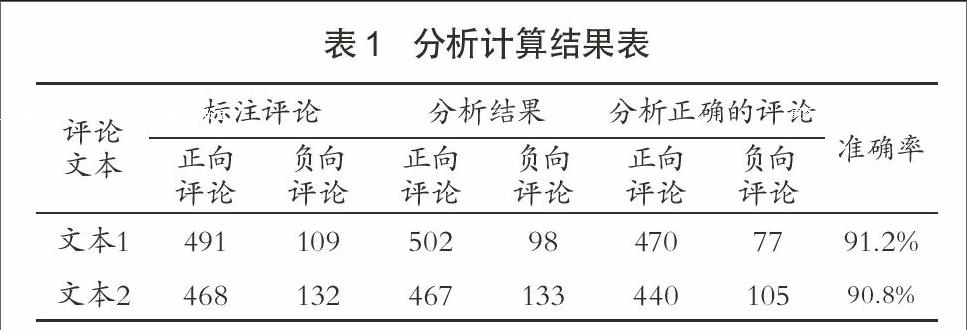
对系统的准确性进行测试验证,选取两款不同的手机评论进行分析。分别从京东商城网站上的手机评论页面抓取评论,从中各选出600篇评论进行人工情感倾向判断,然后与系统的分析结果进行比对,统计分析正确的正负评论与计算准确率。计算结果如表1所示。
根据以上对两款不同手机的评论进行分析统计的结果可知,准确率分别为91.2%和90.8%,满足系统设计目标的准确性要求,表明系统能够对产品评论进行有效的情感分析。
参考文献
[1]魏,向阳,陈千.中文文本情感分析综述[J].计算机应用,2011,31(12):3321-3323.
[2]Probst K, Ghai M K R, Fano A. Semi-supervised Learning of Attribute- value Pairs from Product Descriptions[A]. IEEE Press, 2007, 2838-2843.
[3]Yohan Jo, Alice Oh. Aspect and Sentiment Unification Modelfor Online Review Analysis[A]. 2011.
[4]栗春亮,朱艳辉,徐叶强.中文产品评论中属性词抽取方法研究[J].计算机工程,2011,37(12):26-28.
[5] Liu G, Bu J, Chen C, et al. Opinion Word Expansion and Target Extraction Through Double Propagation[J]. Computational Linguistics, 2011, 37(1): 9-21.
[6]Hassan A, Radev D. Identifying text polarity using random walks [C]. Proceedings of Annual Meenting of the Association for Computational Linguistics(ACL-2010), Uppsala, 2010: 395-403.
[7]柳位平,朱艳辉,栗春亮,等.中文基础情感词词典构建方法研究[J].计算机应用,2009,29(10):2875-2877.
[8]阳爱民,林江豪,周咏梅,等.中文文本情感词典构建方法[J].计算机科学与探索,2013,7(11):1033-1039.
[9]李寿山,李逸薇,黄居仁,等.基于双语信息和标签传播算法的中文情感词典构建方法[J].中文信息学报,2013,27(6):75-81.
[10]王文华,朱艳辉,徐叶强,等.基于SVM的产品评论属性特征的情感倾向分析[J].湖南工业大学学报,2012,26(5):76-80.
