基于电力大数据的用户侧数据异常检测方法研究
2023-12-13李厚恩
李厚恩
深圳供电局有限公司, 广东, 深圳 518000)
0 引言
随着电网越来越智能化,数据量不断增长,数据类型越来越多样化,对数据处理和价值挖掘提出了越来越高的要求。在电力大数据中,用户侧电力数据占很大比例,反映了用户的实际用电需求,及时发现异常情况可以避免故障的发生。因此,研究电力大数据的异常检测方法对电网的发展和进步具有十分重要的意义[2]。查阅相关文献可以看出,现有异常检测方法主要有基于分类的检测方法、基于聚类的检测方法等[3-5]。但是,现有方法存在效率低、耗时长、判断不准确等问题[6]。基于此,本文提出一种将孤立森林算法和局部离群因子算法相结合的电力大数据异常检测方法,从全局和局部2个方面对电力大数据进行异常检测,提高电力大数据检测的优越性。
1 数据挖掘概述
对电力大数据进行挖掘,可以提取出在战略决策、故障检测、降低运营成本、促进电力企业长远发展等方面起着关键作用的数据[7]。数据挖掘由提出具体问题、数据预处理、数据挖掘、结果评价等组成。结构如图1所示。

图1 数据挖掘结构
2 异常检测方法
2.1 孤立森林
孤立森林(IF)算法是适用于连续数据的无监督异常检测方法[8]。在孤立森林中,采用递归方法对数据集进行随机划分。
检测由训练阶段和测试阶段2个阶段组成。训练阶段通过训练集构造孤立树,形成孤立森林;测试阶段是将样本点引入孤立树中,得到每个测试样本的异常得分。具体流程如下。
步骤1 给出一个数据集X={x1,x2,…,xn}(∀xi∈X,xi=(xi1,xi2,…,xid)),随机选择样本点,形成数据集X的子集X′。
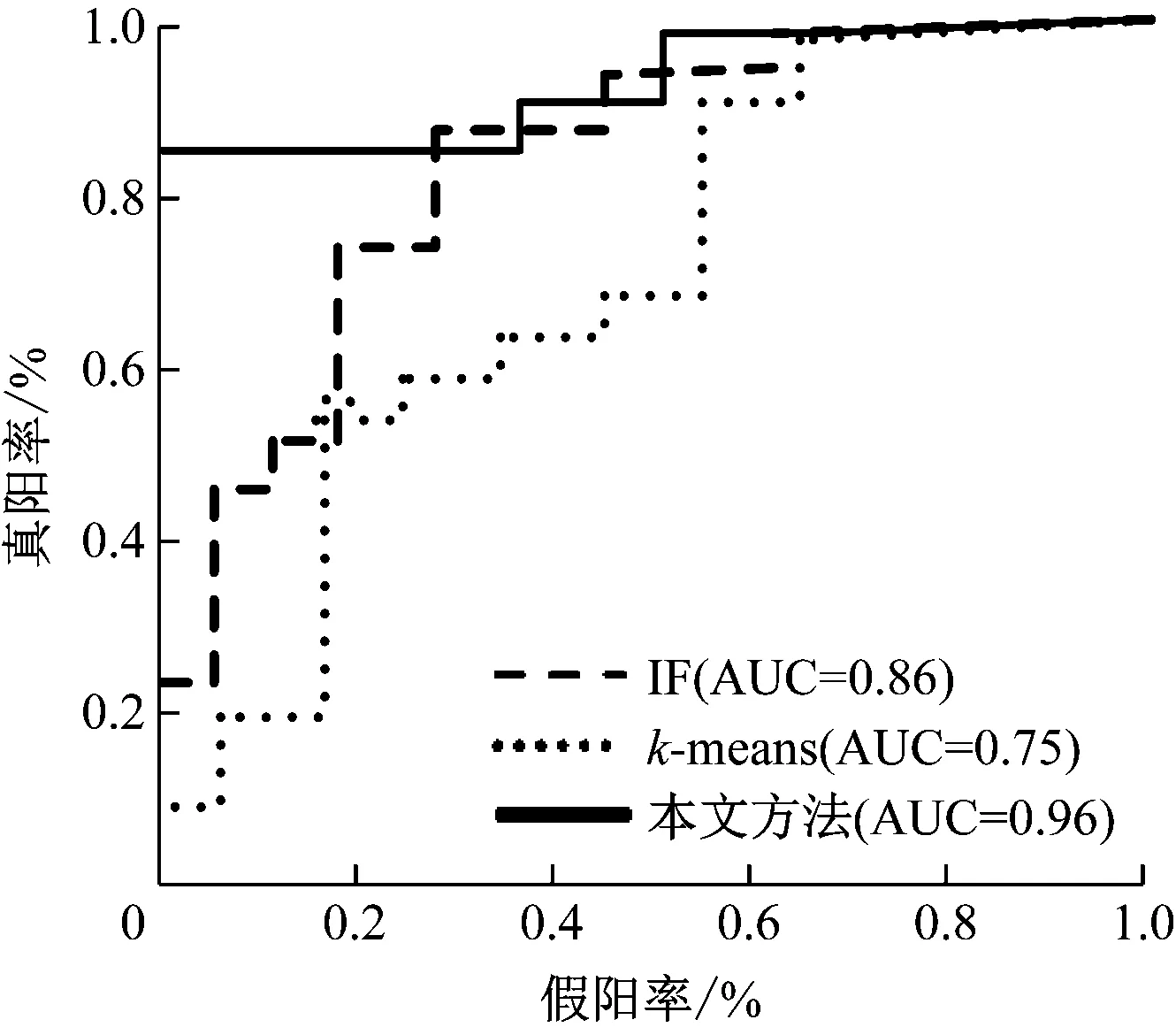
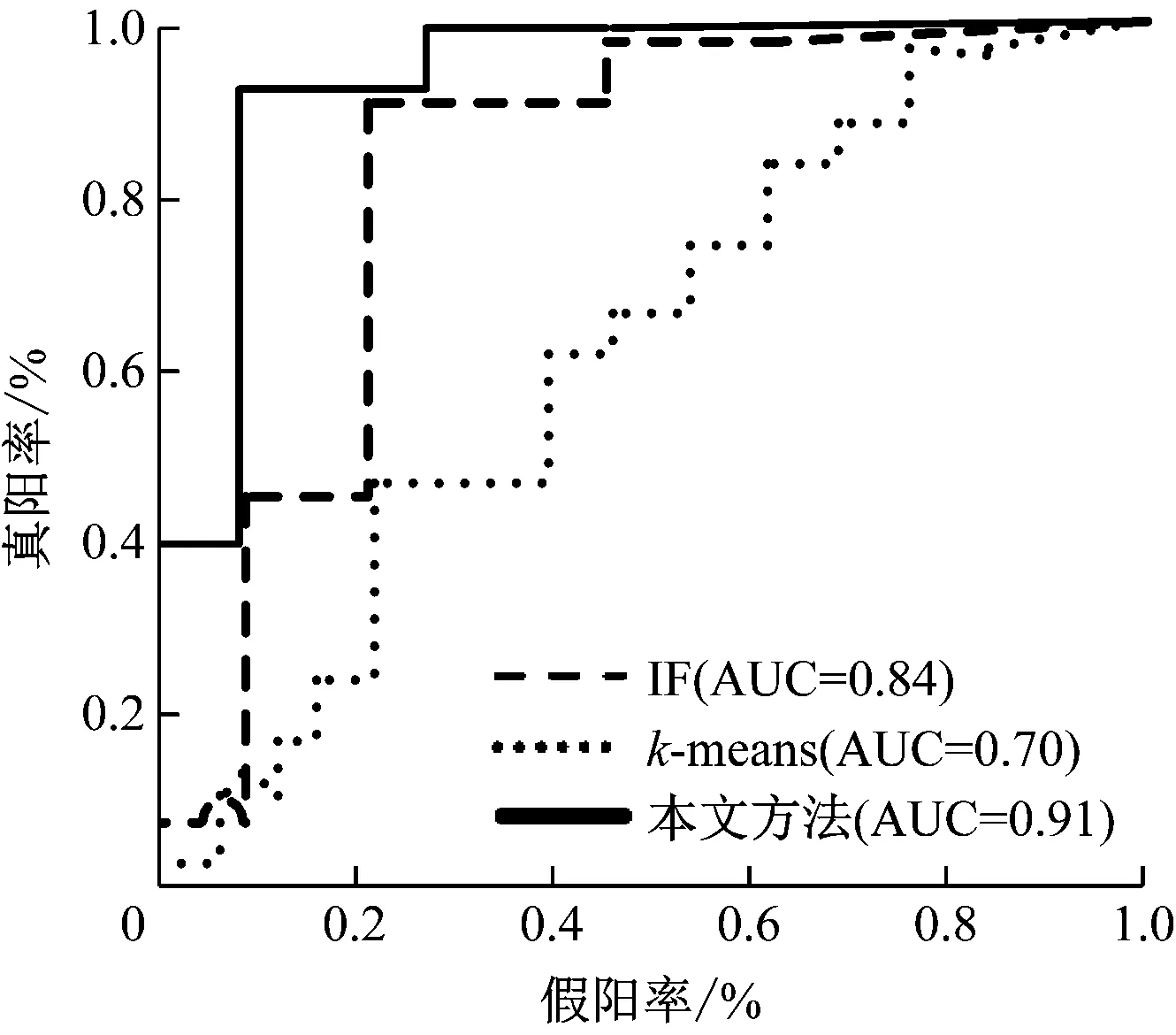
步骤2 从数据集k维中随机选择维度q,在允许范围内随机设置切点p,min(xij,j=q,xij∈X′) 步骤3 通过切点p划分形成超平面,维度大于p点放入右分支上,维度小于p点放入左分支上。 步骤4 是否继续分割,如继续分割,转到步骤2,否则执行下一步。 步骤5 重复步骤1至步骤4,直到生成t棵孤立树。 (2) 测试阶段 对于每个数据点xi,遍历所有孤立树(iTree),计算平均高度h(xi),对h(xi)进行归一化。最后,根据式(1)计算每个测试样本的异常得分[9]。 (1) 式中,C(n)为给定样本数n的平均路径长度,E(h(x))为样本x在孤立树中的期望路径长度,S(x,n)为样本x的特征分数。 孤立森林算法虽然不进行距离、密度等指标计算,大大加快了运算速度,但其无法检测局部用电异常,因此本文提出了一种将孤立森林算法和局部离群因子算法相结合的电力大数据异常检测方法。 局部离群因子(LOF)算法是有代表性的基于密度的离群点检测方法[10],其主要思想是为每个数据点分配离群因子LOFk(o),并通过离群因子的大小确定样本数据是否异常。算法步骤如下。 步骤1 输入数据集D,指定k值和尚未遍历的点o。 步骤2 根据式(2)计算点o到点p的第k可达距离[11]。 reach_dk(o,p)=max{dk(o),dk(o,p)} (2) 式中,reach_dk(o,p)为点o到点p的第k可达距离,d(o,p)为点o和点p之间的距离,dk(o)为点o的第k距离。 步骤3 根据式(3)计算点o的局部可达密度pk(o)。 (3) 式中,ρk(o)为平均可达距离的倒数(第k邻域内的点到点o)。如果该点o位于簇中,则该点o位于点p的k距离邻域中的概率较大。 步骤4 根据式(4)计算点o的局部离群因子LOFk(o)[12]。 (4) 将计算出的LOFk(o)值按降序排列,前n个放置的数据样本点即为异常点。 基于孤立森林和局部离群因子算法的电力数据异常检测思想是利用主成分分析对某一类电力用户的用电数据特征集进行降维,通过孤立森林过滤掉用电数据中的全部异常后的剩余数据作为局部离群因子算法的输入,以获得更精确的异常点[13]。本文用电数据异常检测方法的主要步骤如下。 步骤1 利用模糊C-均值对电力用户用电数据进行特征分类,并采用主成分分析法进行降维。 步骤2 初始化孤立森林算法参数,通过孤立森林算法进行全局异常值检测。 步骤3 通过孤立森林过滤掉用电数据中的全局异常后,使用局部异常因子算法进行二次异常检测,识别局部异常并获得用户离群度排序。图2为异常检测方法的流程图。 图2 异常检测方法流程 为了验证本文方法的性能进行仿真实验,仿真设备为联想PC,操作系统为Windows 10 64位旗舰版,Intel i52450m CPU,频率2.5 GHz,8 GB内存,Python 3.7环境[14]。本文采用某地区3234个用户半年的电力负荷数据进行采样,采样间隔为15 min,每天96点。 通过聚类得到四类用户。第一种有1179个用户,全天的用电都相对较低;第二类有737个用户,在夜间处于用电高峰;第三类有529个用户,是典型的双峰用户;第四类有741个用户,从上午9点和10点以及下午3点和4点,耗电量处于较高状态,而在晚上则很低。孤立树的数量设置为100,最佳样本数量设置为80,最近邻数量设置为150。异常数据如表1所示。 表1 不同类别异常数据 以ROC曲线、P-R为指标,将本文所提方法与孤立森林算法和k-means算法进行比较,验证本文方法在异常用电数据检测中的可行性。图3为不同类别在不同检测方法下的ROC曲线和相应的AUC值。 (a) 类别1不同方法ROC曲线 (b) 类别2不同方法ROC曲线 (c) 类别3不同方法ROC曲线 (d) 类别4不同方法ROC曲线图3 不同类别不同方法的ROC曲线 如图3可以看出,本文方法在异常用电数据检测中的AUC值大于0.90,高于IF算法和k-means算法,IF算法的AUC值高于k-means算法的AUC值。表2为不同类别中不同检测方法的P值、R值和AP。 表2 不同类别不同检测方法的P-R指标 从表2可以看出,本文方法的P值、R值和AP均高于IF算法和k-means算法。因此,本文方法比IF算法和k-means算法更适合于离群点较少的电力数据异常检测,验证了本文方法在异常用电数据检测中具有优越性和适用性。 本文提出了一种将IF算法和LOF算法相结合的电力大数据异常检测方法,从全局和局部2个方面对用电数据进行异常检测。结果表明,与IF算法和k-means算法相比,本文方法在ROC曲线、P-R指标上具有更高的效率和准确性。由于受当前实验室硬件和数据规模的影响,本文研究还处于起步阶段,仅检测了少量数据的异常。基于此,后期将对大量用电数据进行异常检测和分析,不断提高检测方法的性能和适应性。2.2 局部离群因子
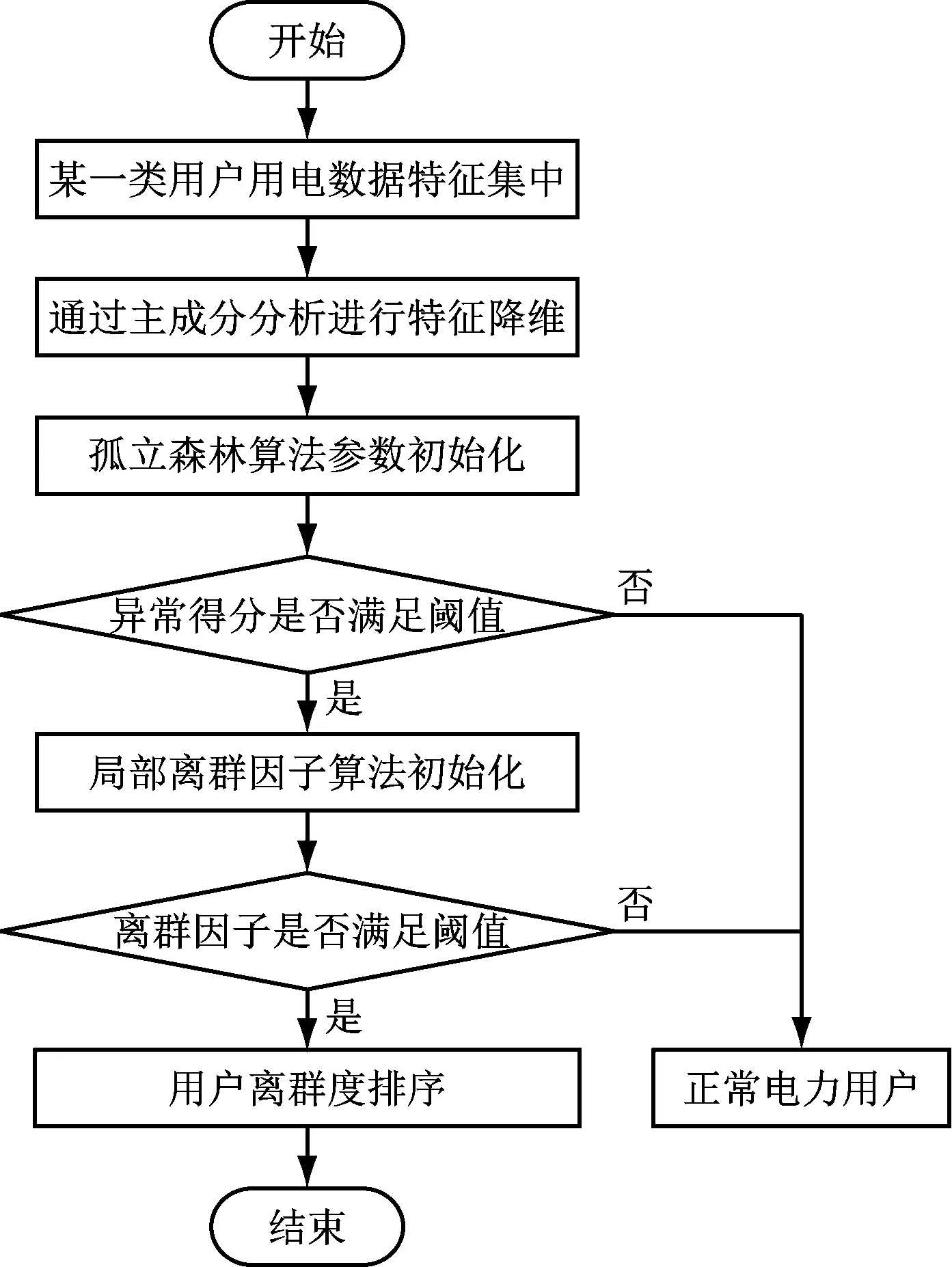
2.3 用电数据异常检测
3 仿真结果与分析
3.1 仿真参数

3.2 结果与分析



4 总结
