基于数据挖掘的图书馆借阅量预测研究
2023-12-13邓敏卢宁
邓敏, 卢宁
(广东科学技术职业学院, a.图书馆, b.计算机工程技术学院(人工智能学院), 广东, 珠海 519000)
0 引言
图书借阅量是衡量馆藏文献利用率的重要指标,对评估图书馆业务、提升图书馆管理和服务水平具有重要意义,得到了国内外从业人员的广泛关注[1-3]。目前常用的图书馆借阅量预测方法为线性回归分析模型和灰色理论模型,其中线性回归分析模型以多元线性回归分析、指数平滑、滑动自回归等方法为代表,具有理论清晰和计算简单的优点,但是在面对图书馆借阅量这种复杂随机过程时,线性回归分析模型的预测精度较低[4-6]。灰色理论是以常微分方程为原型的一种统计模型,通过累加和累减运算将数据中隐含的规律提取出来,在小样本、贫信息条件下表现出了较强的适应性,但误差累积问题的存在导致灰色理论仅适合对数据进行短时预测[7-8]。
BP神经网络是一种经典的非线性、非平稳时间序列分析方法,能够高精度逼近于任意非线性函数,且具有自适应、自学习能力,被广泛应用于非线性估计领域[9-10]。文献[11]利用BP神经网络建立了图书馆借阅量预测模型,并对某高校图书馆2018年图书借阅量进行预测,结果表明BP神经网络能够较好地描述借阅量变化趋势,且预测精度较高,但是存在模型复杂、实时性较低的问题。
实际生活中,图书馆借阅量不仅与图书馆自身位置、馆藏图书情况有关,也与附近居民的年龄、专业、受教育程度等密切相关,是一种复杂的非线性、非平稳随机过程,直接对原始数据进行建模分析会导致模型复杂和过拟合等问题的发生[12-13]。因此,如何对历史数据进行分析,提取其中与借阅量密切相关的因素并剔除冗余信息,从而降低模型复杂度、提升预测性能是本文的关注点。
基于数据挖掘理论和思想,本文提出一种基于因子分析(FA)模型联合粒子群(PSO)优化BP神经网络的图书馆借阅量预测模型,首先利用FA对原始数据进行降维分析,提取与借阅量相关性较高的公共因子,然后将其作为BP神经网络输入进而建立预测模型,同时考虑到BP神经网络模型初值设置难题,提出改进的PSO算法对其全局寻优,提升预测性能。最后开展仿真实验对所提方法的预测性能进行评估,并将结果与传统方法进行对比分析。
1 FA-POS-BP理论模型
1.1 因子分析模型
因子分析(FA)是机器学习理论中一种经典的数据降维分析方法,通过线性变换的方式利用少数几个公共因子对原始高维数据进行描述,这些公共因子包含了原始数据中绝大部分的有用信息,因此利用FA在实现数据降维的同时不会造成信息损失。对于图书馆借阅量历史数据y=[y1,y2,…,yN]T,利用FA对其进行分析的数学模型可以表示为
yi=a1x1+a2x2+…+aKxK+εi
(1)
其中,xk(k=1,…,K)为K维公共因子,εi为噪声分量,ak(k=1,…,K)为因子系数。
将式(1)写为矩阵形式可以表示为
y=Ax+ε
(2)
其中,A∈RN×K为因子加载矩阵,x=[x1,x2,…,xK]T为公共因子向量,ε=[ε1,ε2,…,εN]T为噪声向量。
对于式(2)所示的FA模型,其求解过程如下。
计算历史数据与公共因子向量的协方差矩阵Σ:
Σ=cov(x,y)
(3)
其中,cov()为求向量协方差矩阵运算符。
对协方差矩阵进行特征分解,得到特征值和特征向量:
(4)
其中,λk(k=1,…,K)为特征值,uk(i=1,…,K)为对应的特征向量。
根据式(5)计算因子加载矩阵:
(5)
得到因子加载矩阵后,利用式(2)可以计算得到公共因子,从而将原始N维数据转化为K维(K≼N)低维数据。
利用Thompson回归法计算每个公共因子的得分:
s=ATΣ-1x
(6)
其中,s=[s1,s2,…,sK]T,sk为第k个公共因子的得分。
1.2 BP神经网络
BP神经网络是当前理论最为成熟、应用最为广泛的一种人工神经网络(ANNs)模型,采用多层前向反馈结构在输入和输出神经元之间建立任意非线性映射函数,因此适合对图书馆借阅量数据进行建模预测。
图1为典型的三层网络结构模型。第一层为输入层,其神经元的个数由所要描述的具体问题决定;第二层为隐含层,通常采用径向基函数将输入层神经元映射至输出层;最后一层为输出层,实现对输入神经元的响应。BP神经网络具有自适应和自学习能力,其网络迭代过程主要包括前向传播和反向传播2个阶段。前向传播指的是输入层神经元经隐含层神经元映射至输出层神经元的传播过程,反向传播指的是输出层神经元与预期输出之间的误差经隐含层神经元向输入层神经元传播时对权值修正的过程。
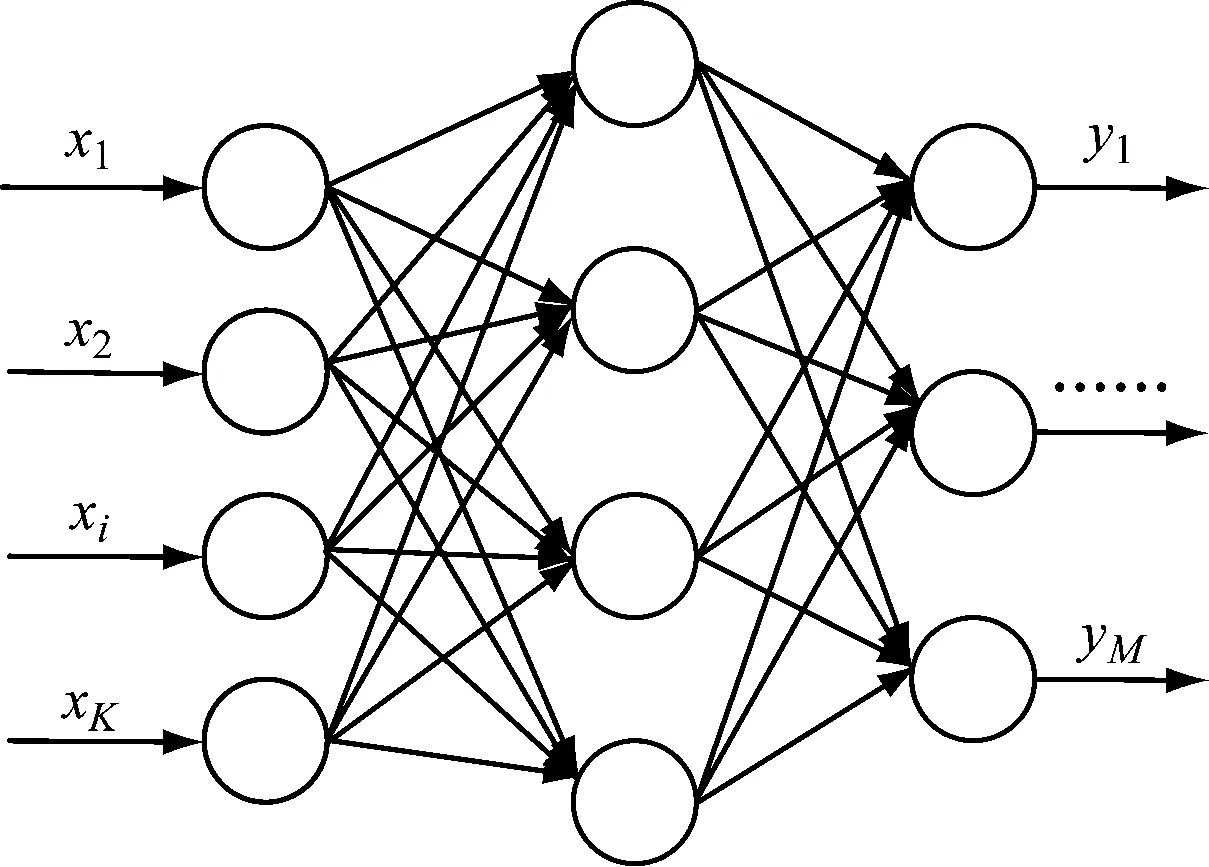
图1 三层BP神经网络结构
本文将通过FA得到的公共因子,作为BP神经网络的输入神经元,则输入层神经元向隐含层神经元映射的过程可以表示为
(7)
其中,wk为权值,θj为阈值,f()为径向基函数,其具体形式为
(8)
其中,c为变量中心,σ为节点宽度。
隐含层神经元进一步向输出层映射的过程可以表示为
(9)
其中,el(l=1,…,M)为输出层神经元,M为输出层神经元个数,ωl为对应的权值。
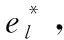
(10)
在式(10)的基础上,BP神经网络的反向传播采用梯度下降法,按照Δ减小的方向对权值wj、ωl和阈值θj进行更新。
1.3 PSO优化BP神经网络
虽然BP神经网络具有结构简单、运算效率高、对非线性问题建模能力强等优点,但是由于采用梯度下降法求解,其预测性能对模型参数初值选取依赖性较大,因此如何确定最优初值是BP神经网络面临的一个难题。PSO是通过对自然界中鸟群觅食过程进行抽象而得到的一种智能仿生优化算法。其基本思想是将鸟群中的每个个体抽象为具有位置和速度信息的运动粒子,群体中所有粒子能够共享信息。开始时,所有粒子的搜索方向都是随机的,之后的每次迭代粒子都按照特定速度向群体中当前处于最优位置的粒子靠拢。随着迭代的进行,整个群体由最初的无序逐渐向有序转变,最终获得最优解[14]。
PSO算法的搜索性能受惯性因子h影响较大,当h取较大值时,算法的全局搜索能力较强而局部搜索能力较弱,反之,当h取较小值时,算法的局部搜索能力较强而全局搜索能力较弱。传统方法采用固定惯性因子的PSO算法存在易早熟、易陷入局部最优的问题[15],因此本文对其进行优化改进,将h的取值与当前迭代次数关联,在初期迭代次数较小时,使h取较大值从而加快收敛速度,随着迭代的进行,迭代次数逐渐变大,使h取值逐渐减小从而保证算法精度。优化后的惯性因子h可以表示为
(11)
其中,hmin和hmax为h取值的最小值和最大值,max_it为最大迭代次数。
2 基于数据挖掘的借阅量预测算法流程
图2为基于数据挖掘的图书馆借阅量预测算法流程。主要包含以下几个步骤。
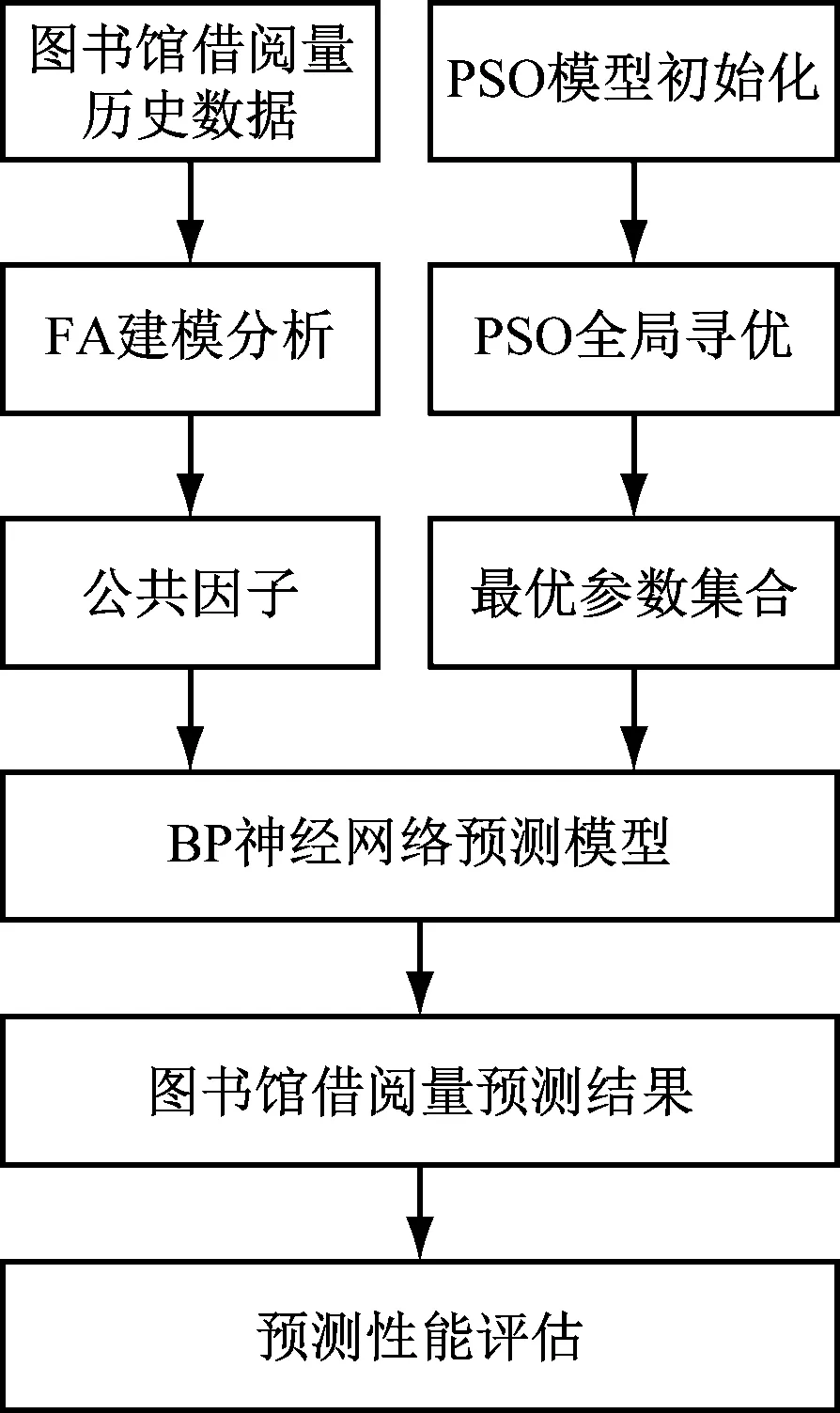
图2 基于数据挖掘的借阅量预测算法流程
步骤1 搜集图书馆借阅量历史数据,历史数据中包含借阅人性别、年龄、专业、受教育程度、婚姻状况、职业、距离、交通方式、图书馆馆藏数量、书本质量,借阅时间,借阅量等多种信息,并将其用1、2、3等数字量化表示。
步骤2 利用FA对历史数据进行建模分析,进而得到与借阅量相关性较大的公共因子。
步骤3 将FA获得的公共因子作为输入神经元,建立BP神经网络模型。
步骤4 初始化PSO模型,包含种群数量、最大迭代次数、参数取值空间等。
步骤5 利用PSO对BP神经网络模型初值进行全局寻优,得到最优参数集合。
步骤6 结合步骤3和步骤5得到的结果,建立最优BP神经网络预测模型,对图书馆未来借阅量进行预测。
步骤7 建立预测误差等指标对预测结果进行定量评估。
3 应用实例
3.1 实验数据
为了验证本文模型的有效性,选取某高校图书馆的借阅量数据作为研究对象,借阅量数据记录周期为1 d。实验时间内连续730 d的借阅量数据变化曲线如图3所示。
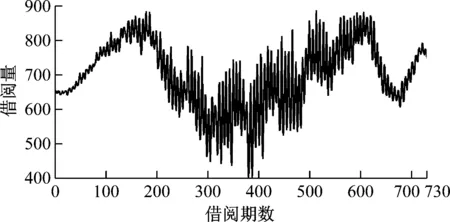
图3 借阅量数据曲线
由图3可以看出,该图书馆借阅量数据变化较为复杂,是一种典型的非线性、非平稳随机过程。实验中,将前365期数据作为训练样本用于实现预测模型训练,将剩余365期数据作为测试样本用于预测性能评估。表1为本文搜集到的与借阅量相关的11个维度历史数据,包括借阅人性别、年龄、专业、受教育程度、婚姻状况、职业、距离、交通方式、图书馆馆藏数量、书本质量和借阅时间,分别对其作出数值标号以便后续分析。

表1 借阅量相关维度
3.2 实验结果及分析
按照图2所示流程,首先利用FA模型对历史借阅量数据进行分析。图4为通过Thompson回归法计算得到的公共因子得分情况。由图4可以看出,借阅人受教育程度、距离和书本质量3项公共因子得分较高,表明其与借阅量相关性较高;而借阅人性别、年龄、婚姻状况、交通方式和借阅时间5项公共因子得分较低,表明其与借阅量不相关;剩余专业、职业和图书馆馆藏数量3项公共因子与借阅量具有一定的相关性。因此,将借阅人受教育程度、距离、书本质量、专业、职业和图书馆馆藏数量6项公共因子作为BP神经网络的输入层神经元,进而建立预测模型。
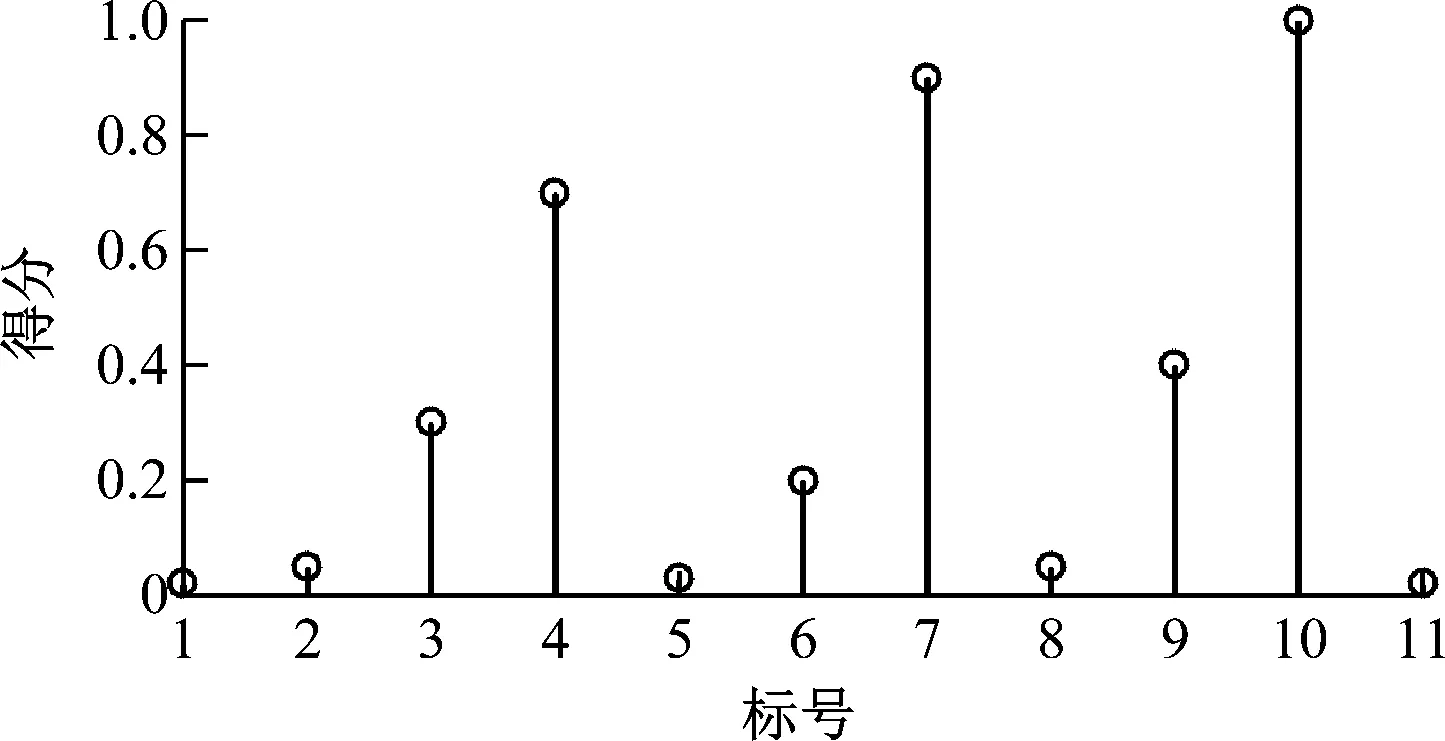
图4 不同因子得分
图5为利用改进PSO算法、传统PSO算法对BP神经网络模型初值进行全局寻优得到的最优参数变化曲线。由图5可以看出,传统PSO由于采用固定惯性因子,在迭代后期出现了振荡现象,经过21次迭代才实现收敛,而改进PSO将惯性因子与迭代步长关联,只需要7次迭代即实现了收敛,收敛速度提升了3倍。
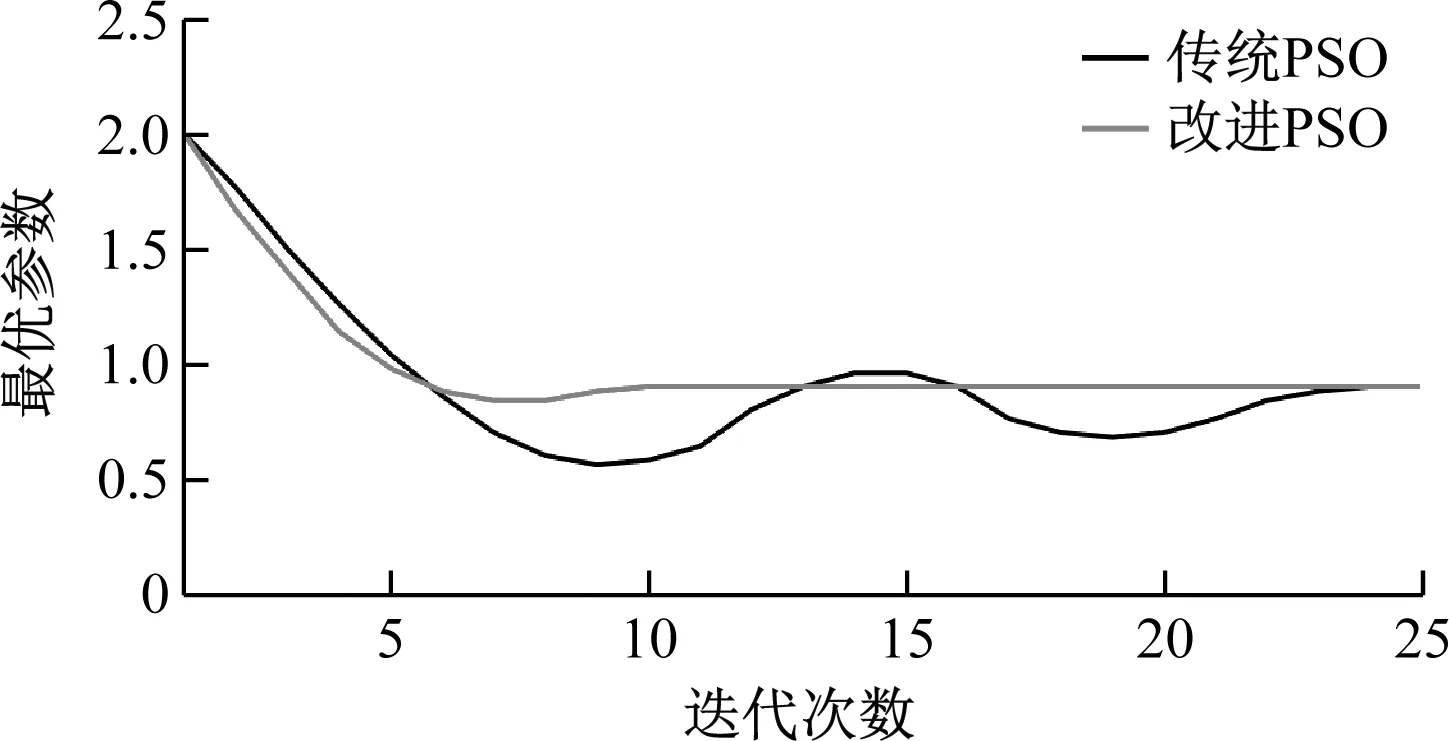
图5 最优参数变化曲线
图6为利用所提方法、文献[11]方法对365期测试数据进行预测得到的预测结果和误差曲线。由图6可以看出,本文方法得到借阅量预测结果变化曲线与实际借阅量较为一致,预测精度较高,而文献[11]方法在初期预测精度较高,但是随着时间的延长,预测精度逐渐下降。图7为以季度为单位的2种方法的预测结果对比。由图7可以看出,本文方法的预测精度均优于文献[11]方法。究其原因在于,文献[11]方法利用全部历史数据构建训练模型,然而如图4所示,历史数据中借阅人性别、年龄、婚姻状况、交通方式和借阅时间等信息与借阅量之间的关联性较低,不仅不会对提升预测性能带来帮助,反而会增加模型复杂度,降低预测性能。而本文方法通过FA分解提取相关性较高的公共因子,避免了冗余信息对预测模型的影响,因此预测精度较高。
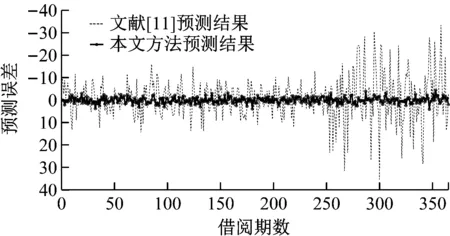
图6 不同方法预测结果
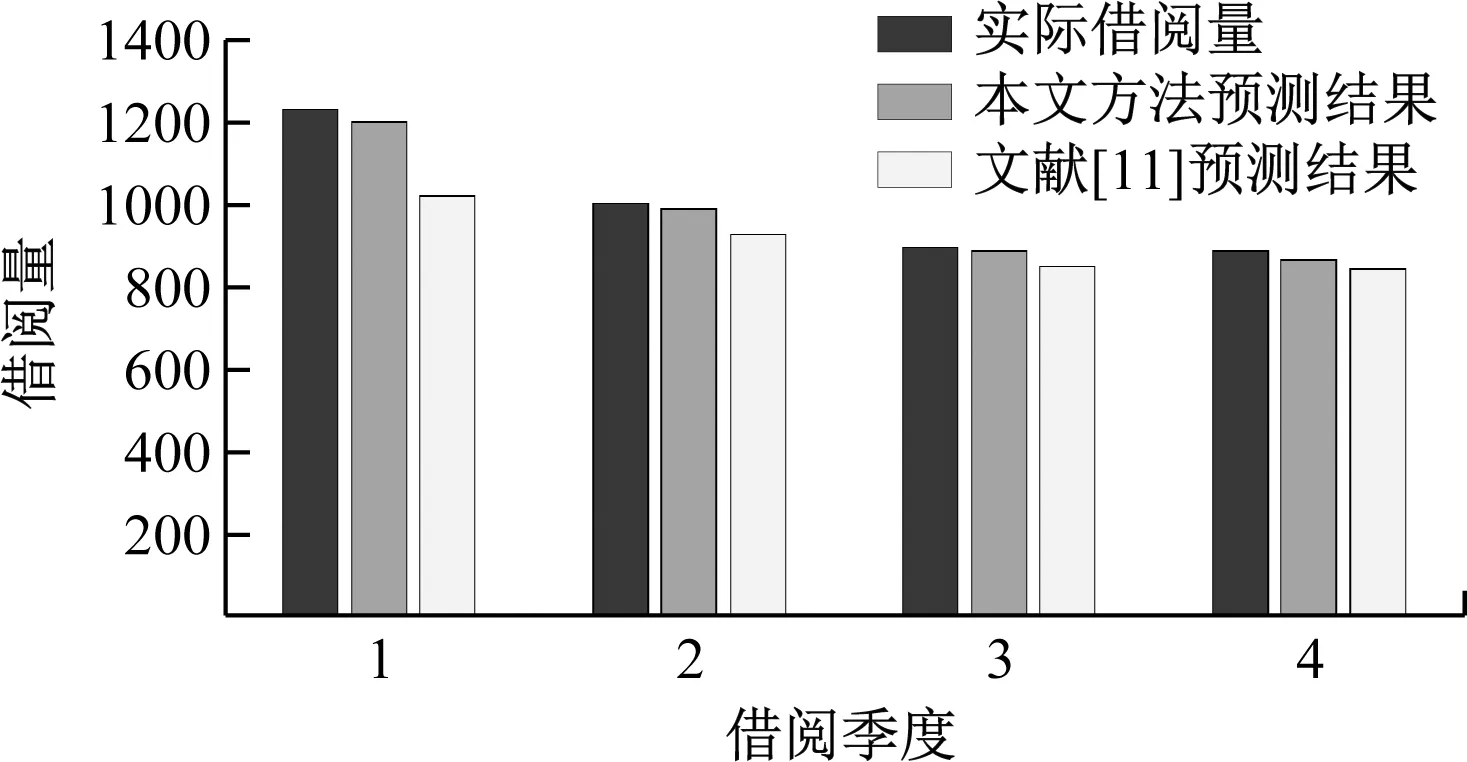
图7 不同季度预测结果
将图书馆中不同类别数据进行划分,并分类统计2种方法预测结果得到的预测误差,如表2所示。由表2可以看出,本文方法的预测误差均小于2.2%,且预测精度均优于文献[11]方法。而文献[11]方法对于体育和教育类图书借阅量的预测结果超过5%,进一步验证了本文方法的有效性。
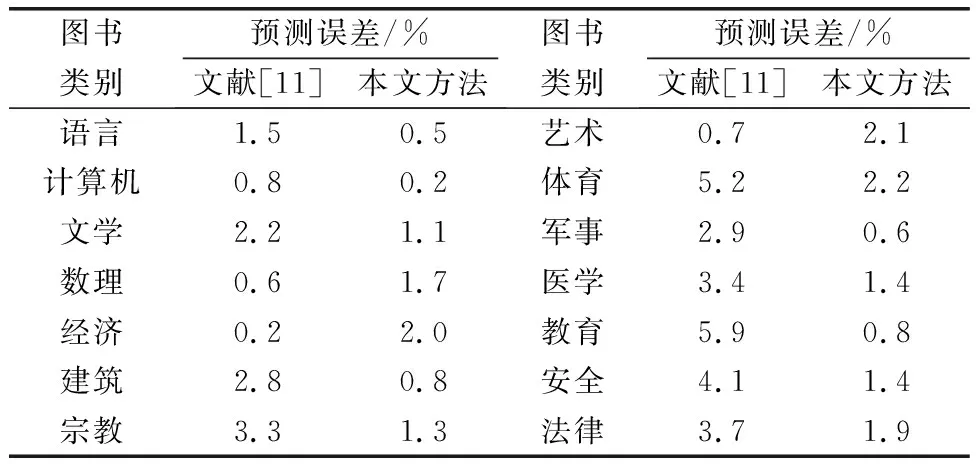
表2 不同类别图书预测误差
4 总结
图书馆借阅量数据具有非线性、非平稳和高维度特征,其变化趋势与借阅人受教育程度、专业、职业、距离、图书馆馆藏数量、书本质量等众多因素相关。由于传统基于线性回归和灰色理论的预测模型精度较低,本文将FA引入图书馆借阅量数据分析领域,利用FA提取与借阅量密切相关的6项公共因子,并将其作为BP神经网络模型的输入,进而建立PSO优化的BP神经网络预测模型对某高校图书馆借阅量数据进行建模分析。结果表明,本文模型不仅能够准确预测图书馆总借阅量,同时也可以对不同类别图书借阅量进行准确预测,相对于对比方法具有收敛速度快、预测精度高的优势,有利于支撑图书馆科学、高效和精细化的管理。
