基于机器学习的卫星导航系统全球定位性能评估方法研究
2023-12-01王迪王茂磊杨宇飞李海航葛条
王迪,王茂磊,杨宇飞,李海航,葛条
( 1. 北京卫星导航中心, 北京 100089;2. 北京开运联合信息技术集团股份有限公司, 北京 100020;3. 北京工业大学, 北京 100124 )
0 引言
GNSS 是指能在地球表面或近地空间的任何地点为用户提供全天候三维坐标和速度以及时间信息的空基无线电导航定位系统[1].目前全球有四大卫星导航系统:美国的GPS、俄罗斯的GLONASS、欧盟的Galileo 和中国的北斗卫星导航系统(BeiDou Navigation Satellite System,BDS).BDS 经过“三步走”发展战略,实现服务性能大幅提升.根据BDS 公开服务性能规范(3.0 版)定义,定位、导航和授时(positioning,navigation and timing,PNT)服务精度包括定位精度、测速精度、授时精度和服务可用性等[2].
近年来,机器学习技术在多个领域得到了广泛应用,在GNSS 方面也有一定的研究进展.Hsu[3]采用机器学习的方法探讨了多路径效应检测;Linty 等[4]根据机器学习决策树算法研究了GNSS 中的电离层闪烁;周相兵[5]利用城市出租车GNSS 数据,采用智能聚类学习算法对数据进行了分类,为城市道路规划和路网更新提供了新方法;Xia 等[6]研究了基于混合机器学习系统的车辆GNSS 观测异常检测.上述研究均为利用机器学习实现了对GNSS 数据进行分类或聚类.此外,也有学者基于机器学习,对观测结果或某种现象进行预测.如Kiani[7]将机器学习方法应用于GNSS 时间序列研究,对地面沉降或隆起进行了预测;骆黎明[8]基于树模型反演了GNSS-R 海面风场.尽管机器学习在上述方面的应用百花齐放,但基于机器学习的无源定位导航服务性能评估却鲜有人研究.
众所周知,传统数理方法的GNSS 性能评估是基于大地测量与导航测绘原理开展,其所有数据依赖于地面测站的观测与传输,导致地面测站的布局对定位精度的评估、预测存在一定的关联性和局限性,而机器学习可以较好地挖掘这方面的信息,通过对大量数据进行筛选、特征提取、模型训练、归纳总结等,探索研究机器学习在导航定位服务中的应用效果.
本文利用机器学习算法,结合大地测量和导航测绘原理,以与定位精度有关的数据作为特征,对定位精度进行拟合,为定位性能的评估与预测提出了一种新方法和思路.即运用特征提取工程模块自动提取并合理筛选出影响定位精度的相关数据特征,然后将上述特征输入机器学习工程模块进行模型训练和性能测试,通过特征数据拟合定位精度真值,实现定位精度预测,使用定位精度预测值对服务性能进行大致评估.同时,本文工作本身更多的是基于“传统统计方法”获得的定位精度结果进行模型训练的,则传统方法中存在的各种“关联性和局限性”问题在建立的模型中只会放大而不会消失.因此,本文更多的是提供一种新的研究思路,即利用机器学习的思想结合GNSS 理论实现对定位精度的评估和预测.
1 数据集构建与特征工程
1.1 原始误差数据集
本文选用武汉大学国际GNSS 服务(International GNSS service,IGS)网站2020—2021 两年全球测站的观测文件和每日广播星历作为原始数据.选用BDS B1I 频段信号,以每30s 的时间间隔对测站位置进行单点定位,并与测站位置参考值进行对比,获得东(east,E)、北(north,N)、天顶(up,U)三方向上的定位误差σE、σN、σU.
1.2 标签值获取
本文将测站实际定位精度作为标签值,用于给机器学习模型得出的预测值提供参考.
定位精度是一段时间内定位误差的统计值.在2.1 节中描述了计算E、N、U 三个方向上的定位误差的方法.接着,经过下面两步的处理将三个方向上的定位误差转换为水平、垂直方向定位精度.
首先将三个方向的误差转换为水平、垂直两个方向上的定位误差,转换方法如下:
式中:σH、σV为水平方向误差与垂直方向误差;σE、σN、σU为E、N、U 三个方向上的误差.
其次,将得到的垂直方向、水平方向定位误差按一定采样时长进行分段,使用均方差公式对每段时间内的定位误差进行统计,得到的统计值作为每日不同时间段内的垂直方向、水平方向定位精度.
在本文中,主要采用1h 和3h 的采样时长进行分段统计.对于采样时长为1h 的数据集,一天内共有24 组统计值,代表24 个时间段内的定位精度.对于采样时长为3h 的数据集,一天内共有8 组统计值,代表8 个时间段内的定位精度.
1.3 特征值选取
考虑到定位精度可能受到天气、地理位置等因素的影响,将卫星几何构型、信号传播段和信号用户段等对应数据作为重要特征值,将其按时间顺序添加到数据集中,与标签值一一对应.
卫星信号在传播时会受到传播路径上多种因素的干扰,传播段上的主要影响因素为电离层状态和对流层状态:对于电离层总体状态,主要受太阳活动与地球地磁活动的影响,因此考虑可反应地球地磁活动情况和太阳活动情况的数据作为特征值;局部的电离层状态则与当地太阳光照情况有关,可由当地时间间接反应,因此考虑将定位时间作为特征值.在本文中,地球地磁活动情况和太阳活动情况主要通过德国地磁中心提供的地磁指数文件获得,选取文件中的地磁指数Ap、太阳黑子数SN、太阳射电辐射通量F10.7作为特征值.时间特征值则通过将各个标签值对应的时间分解为定位时间的年积日(day of year,DOY)以及当日小时数(hour of day,HOD)来获取.此外,通过对国际全球连续监测评估系统(international GNSS Monitoring&Assessment System,iGMAS)网站提供的电离层文件在时间与空间上线性插值,可以直接得到不同定位时间下测站上方的电离层电子总含量(ionospheric total electron content,TEC)值.上述选取特征都直接或间接地反应了电离层状态;对流层状态与气象情况相关,如定位地点周边温度T、大气压Po、相对湿度U等,由于气象参数的获取受到气象站分布的限制,许多测站无法获取周边准确气象参数,故不作为特征值考虑;而用户段的影响包括接收机钟差、接收机噪声等,由于不同接收机型号对定位精度评估受人为技术影响较大,故此处不作为特征值考虑.
此外,定位时的卫星几何构型也将影响定位精度,使用定位时的可见卫星位置计算三维位置精度因子(position dilution of precision,PDOP),并作为一种特征值,可以通过数值大小定量反应卫星的几何构型的情况.
综合考量,将卫星几何构型和信号传播段的主要因素作为本文机器学习的特征值,具体为PDOP、测站上方的TEC、地球地磁指数Ap、每日太阳黑子数SN、太阳辐射通量F10.7、定位时间DOY 与HOD.
1.4 数据集构造与预处理
基于GNSS 数据处理具有数据计算量大、数据关系耦合多、计算类别复杂等特点,采取将数据集高维度原始空间投影到低维度特征空间方式,保持样本类别区分性,降低计算量,减小参数估计误差从而避免过拟合问题.在获取特征数据与定位精度数据后,需要将该测站数据按时间拼接起来,构成可供机器学习模型使用的数据集.
将数据输入机器学习模型之前,需要对数据做预处理,以获取最佳性能.本文采用周期性数据编码和数据标准化的处理方式.周期性数据编码主要使用sin、cos 函数对HOD、DOY 两种具有周期性的特征进行处理,使得模型可以学习到其周期性.数据标准化则使用以下公式:
式中:为标准化后的第i类数据中的第j个数据;Xij为第i类数据中的第j个数据;µi为第i类数据的均值;σi为第i类数据的标准差.
通过计算不同数据的均值与方差,并使用上式依次进行处理,可以根据不同数据的分布,将所有输入输出数据的分布转化为正态分布.这有助于加速模型收敛速度并提高模型预测准确率.
2 定位精度评估方法
2.1 机器学习模型选取
梯度提升决策树(gradient boosting decision tree,GBDT)[9]、支持向量回归(support vector regression,SVR)[10]和多层感知机(multilayer perceptron,MLP)[11]均具有较强非线性拟合能力,且较为常见.其中GBDT是一种具有很强泛化性能的机器学习模型,具有非线性拟合能力,并适用于所有规模的数据集,在多个领域得到广泛的应用,本文优选GBDT 模型进行定位精度拟合.
GBDT 通过构建多个弱学习器组合得到有较强预测性能的强学习器,其中,弱学习器指预测效果较差的模型,GBDT 采用的弱学习器为回归决策树.图1展示了一个用于回归任务的GBDT 示意图,其由M棵回归决策树组成.
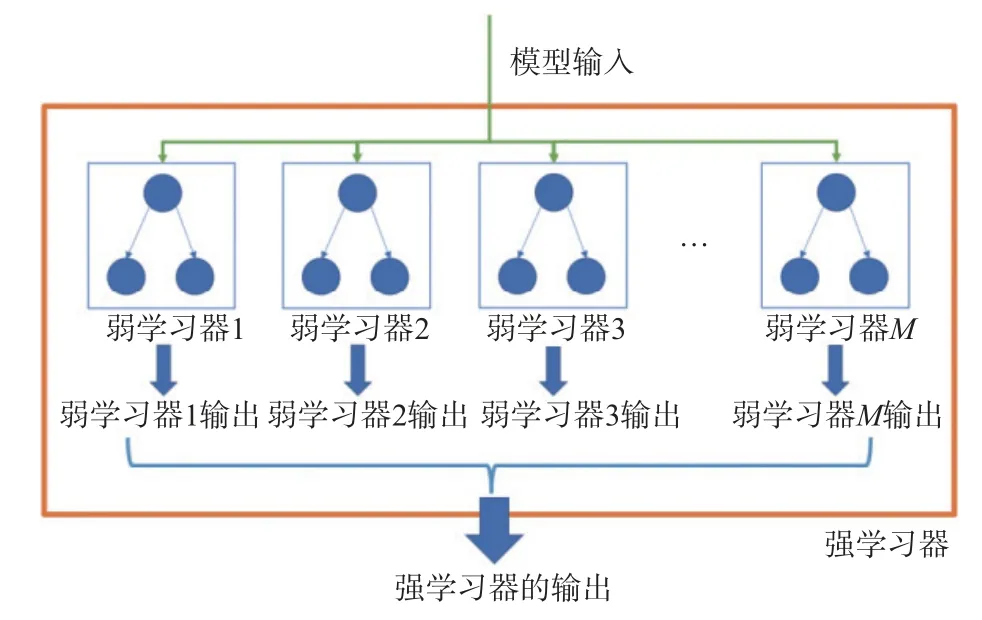
图1 GBDT 示意图
对于图1 中展示的GBDT 模型,其输出y的表达式为
式中,βm和Tm(x)分别为第M棵决策树的输出权重与输出值.
GBDT 在训练时,通过多次迭代逐一生成回归决策树并加入到模型中,不断提高模型预测能力.对于一个由M棵回归决策树组成的GBDT 模型来说,需要进行m次迭代生成回归决策树.在其中的第m次迭代时,由前m-1 步得到的m-1 棵决策树组成的强学习器fm-1(x)为
式中,βi和θi分别为第i棵决策树的权重与参数.此强学习器的预测结果与训练集中的标签值的偏差用损失函数L(y,fm-1(x))表示.而对于本次迭代需要生成的决策树T(x;θm),需要将损失函数L(y,fm-1(x))的负梯度γm作为拟合目标
对于GBDT 回归模型来说,使用的损失函数L(y,fm(x))为均方差函数
则负梯度rm可以进一步化为
即第m次迭代拟合的决策树需要以上一个强学习器的预测值与标签值的差值作为拟合目标.
在得到第m次迭代产生的决策树T(x;θm)后,将其加入强学习器中
通过重复以上迭代过程,不断生成新的决策树并加入强学习器中,直到强学习器中的决策树数量满足设定的数量,即完成了整个模型的训练.
GBDT 完整训练流程可表示为:
1)初始化强学习模型f0(x)为训练集标签值的均值.
2)对m=0,1,2,···,M.
a)根据标签值和上一个强学习器的预测值计算每个训练集样本残差rmi=yi-fm-1(xi),i=1,2,···,N;
b)用残差训练回归树,得到T(x;θm);
c)更新当前强学习器fm(x)=fm-1+βmT(x;θm);
3)得到最终的模型fM(x).
2.2 GBDT 模型训练
将上述数据集,按一定比例分为没有交集的训练集与验证集.其中训练集用于GBDT 模型的训练工作,验证集则用于验证在未知数据下模型的预测表现.
在训练开始前,需要进行预处理.对训练集使用的预处理方法有:针对时间等周期性数据,使用cos、sin 函数映射;对于非数值型数据进行独热编码;对所有数据进行标准差标准化.
在训练时,需要进行超参数的确定,确定模型在数据集上表现最佳的超参数.本文使用网格搜索的方法确定GBDT 在训练集上的最佳超参数.首先对整体性能影响最大的决策树个数进行搜索,在最佳决策树个数基础上,对最大树深、叶子节点最小样本数等决策树参数进行搜索,最后在上述最佳超参数基础上对划分时考虑的特征数、下采样率和学习率进行搜索.确定超参数后,使用最佳超参数创建模型,并使用训练集进行训练.
2.3 GBDT 模型测试
为了验证GBDT 模型可实施性与评估性,需要对GBDT 模型进行测试.首先使用训练集参数,对验证集进行标准化处理.然后将验证集中的特征部分输入训练好的模型中进行预测,获取模型预测值.此处以ENAO 测站水平精度为例阐述模型预测值生成过程.
1)准备输入特征:根据时间和跟踪站的经纬高,分别获取输入特征Ap、SN、F10.7、TEC、HOD、DOY和PDOP,演示样本的输入特征如表1 所示,其中DOY 与HOD 已经过sin、cos 函数映射处理.并使用式(3),根据每类特征的均值与标准差对进行数据标准化,ENAO 训练集中每类特征的数据分布如表2 所示.根据式(3),对表1 中的每类特征分别减去每类特征对应的均值并除以标准差,最终得到的标准化后的输入特征如表3 所示.

表1 演示样本的输入特征

表2 ENAO 的训练集分布

表3 处理后的输入特征
2)使用模型预测:加载ENAO 的水平定位精度模型,并获取预测值.模型使用实验中最佳模型GBDT 训练得到.对于GBDT 模型,其由若干决策回归树构成.GBDT 的预测过程就是将其中所有的决策回归树的输出乘以一定权重后累加的过程.对于演示模型,ENAO 的水平精度预测模型而言,其由400 个决策回归树构成,这里挑选其中第1 个、第200 个、第400 个决策回归树,来演示GBDT 模型中的详细预测过程.第1 个、第200 个、第400 个决策回归树的结构如图2~4 所示.
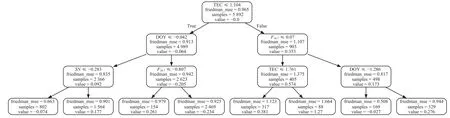
图2 第1 个决策树的结构
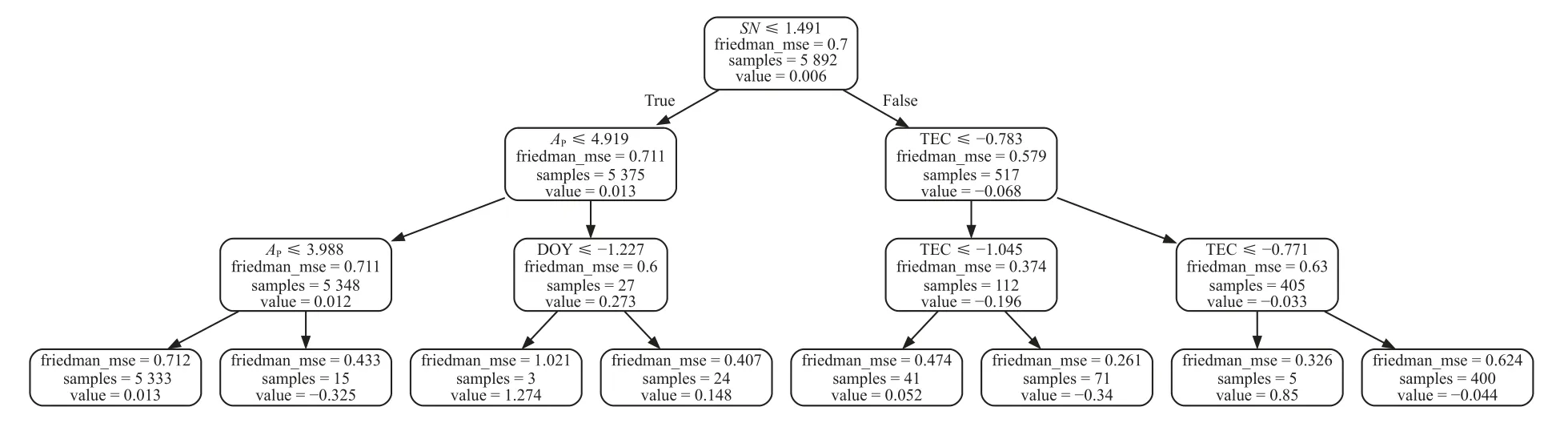
图3 第200 个决策树的结构
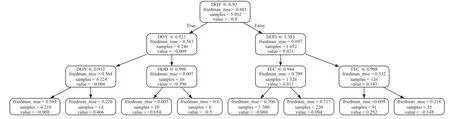
图4 第400 个决策树的结构
将样本输入决策树后,根据树中每个结点的条件和样本的数据,将满足条件的样本分至左节点,不满足条件的分至右节点.不断重复此过程,直至样本落入叶子节点.最后以叶子节点上的值value 作为此样本的预测值输出.对于上述的三个决策树,将三个样本分至叶子节点的过程如图5~7 所示.图中红色、绿色、蓝色箭头的路径分别代表样本1、样本2、样本3 落入叶子节点的过程.
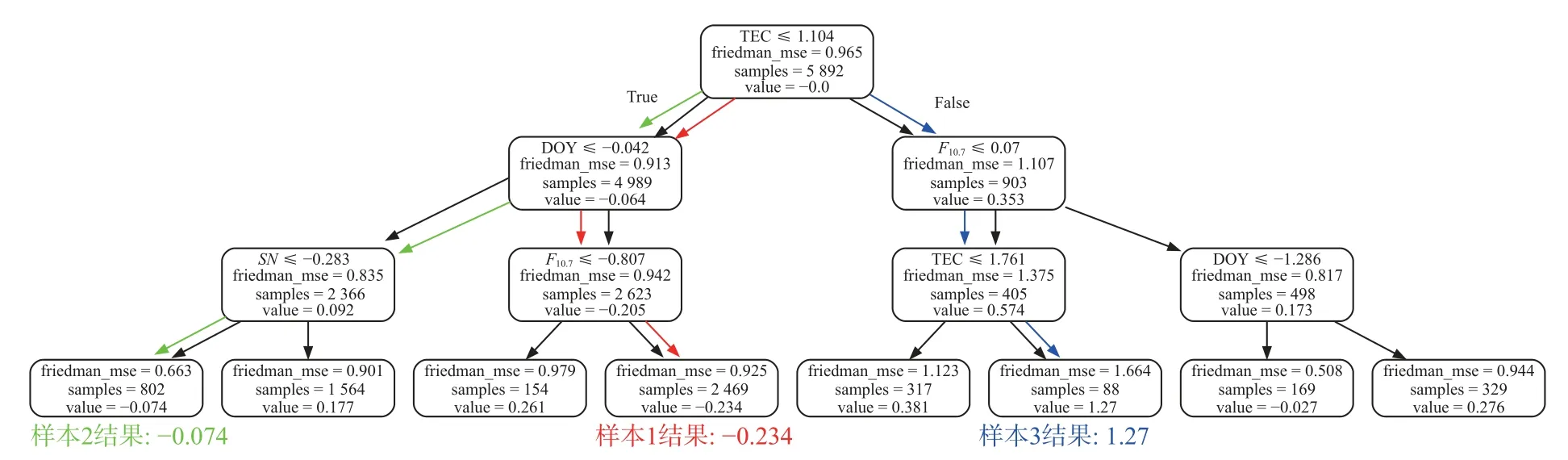
图5 演示样本在第1 个决策树上的输出过程
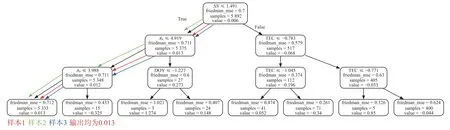
图6 演示样本在第200 个决策树上的输出过程
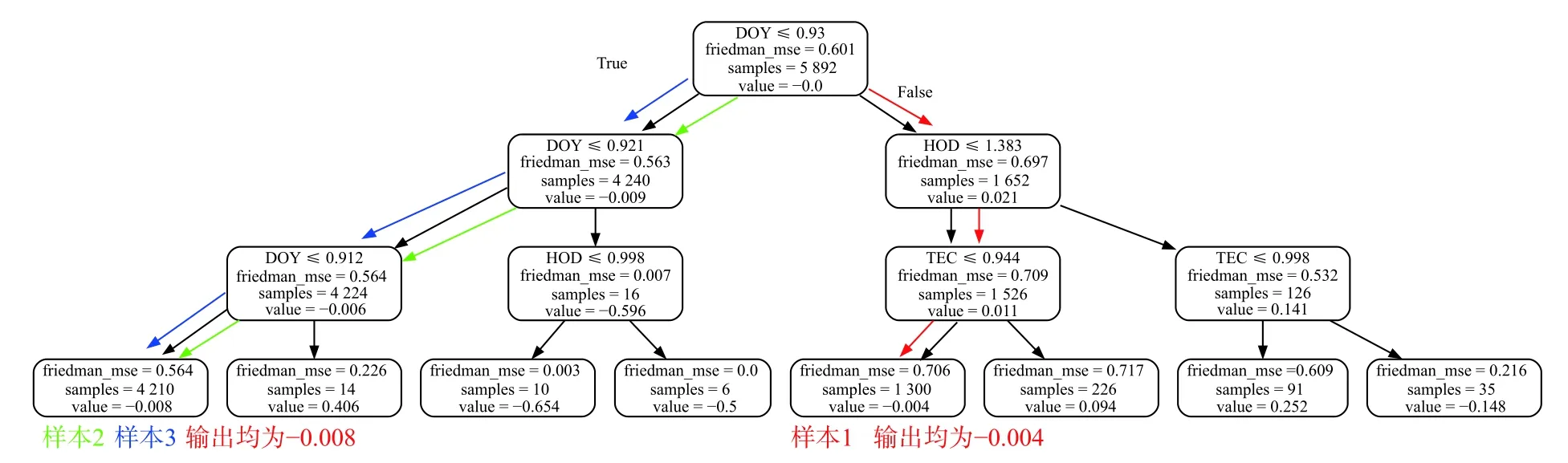
图7 演示样本在第400 个决策树上的输出过程
将每个树的输出值乘以权重后进行累加,即可得到GBDT 的最终输出.GBDT 模型参数中的学习率即为权重.演示模型的学习率为0.1,其输出即为400 个树的结果累加后乘以0.1.
假设模型仅由展示的三个决策树组成,则结果为:
样本1:0.1×(-0.234+0.013-0.004)=-0.0225
样本2:0.1×(-0.074+0.013-0.008)=-0.0069
样本3:0.1×(1.27+0.013-0.008)=1.275
此结果为3 个演示样本在假设模型上的输出值.
3)处理输出值:模型上的输出值并不能直接作为定位精度的预测值,需要进一步恢复成未标准化时的数值,这个过程称为反标准化.这是由于模型在训练时拟合的都是标准化后的标签值.为了进行反标准化,需要得知数据平均值与标准差,并将数值乘以标准差后再加上平均值.对于演示模型来说,训练集中水平定位精度平均值为0.902,标准差为0.165.则对于上述三个预测值来说,其反标准化结果为
样本1:-0.0225×0.165+0.902=0.8982
样本2:-0.0069×0.165+0.902=0.9008
样本3:1.275×0.165+0.902=1.1123.
此结果为3 个样本在假设模型上对水平定位精度的预测值.预测值将从机器学习模块中返回.
为了评估模型的预测性能,本文主要使用1-MAPE作为模型预测准确率.其中MAPE 代表平均绝对百分比误差,其计算公式为
式中:ylabel为样本的标签值;ypred为样本的预测值.
MAPE 主要衡量误差绝对值与真实值之间的比值,反应预测值与标签值之间的不符合程度,其值域为(0,∞).标签值与预测值越相符,误差越小,则MAPE 越接近0;反之,越不相符,误差越大,MAPE越接近正无穷.
而使用1-MAPE 作为模型预测准确率指标,可以直观反应预测值与标签值之间的符合程度,其值域为(-∞,1).标签值与预测值越接近时,预测准确率1-MAPE 越接近1;反之越接近负无穷.
在评估性能时,首先计算所有测试样本的MAPE的平均值作为模型的MAPE 指标值.其次计算1-MAPE作为模型的预测准确率.
3 实验结果与分析
3.1 数据集分类与实验环境
将测站数据分为训练模型学习能力的训练集和评估模型泛化能力的验证集.训练集和验证集的数据划分原则:在数据集中按一定比例随机抽取,但需保证训练集和验证集两个数据集合互斥.
实验环境:计算服务器配置为i9-12900K 和RTX3090 显卡,利用Python 语言在数据分析处理包Pandas 上进行数据集加载、划分等,在机器学习包scikit-learn 进行模型创建、数据标准化、模型训练与测试、模型保存等.
3.2 不同机器学习模型比对结果
使用ABMF、JFNG、MKEA 等11 个测站数据组成的小型数据集,对数据集上的水平定位精度进行拟合计算与评估,从而比较GBDT、支持向量回归(support vaetor regression,SVR)和多层感知器(multi-layer perceptron,MLP)在本任务中的性能.其中,由于MLP对数据量要求较大,使用的是采样时间为1h 的数据集,GBDT 和SVR 使用的是采样时间为3h 的数据集.将数据集按8∶2 的比例分为训练集与验证集,根据验证集中样本预测准确率指标的直方分布图比较模型性能.三种模型的测试结果如图8~10,其中横坐标代表预测准确率,纵坐标代表相应样本数量,上方数字代表验证集的数据量.
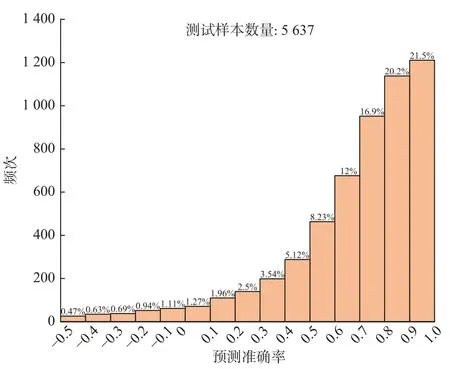
图8 GBDT 测试结果
如图8 所示,GBDT 的测试结果如下: 预测准确率处于0.9~1 的测试样本占总样本的21.5%,处于0.8~0.9 的测试样本占20.2%,处于0.7~0.8 的测试样本占16.9%.如图9 所示,SVR 处于0.9~1 的测试样本占总样本的20.8%,处于0.8~0.9 的测试样本占18.2%,处于0.7~0.8 的测试样本占16%.如图10 所示MLP 处于0.9~1 的测试样本占总样本的18.4%,处于0.8~0.9 的测试样本占16.8%,处于0.7~0.8 的测试样本占14.3%.
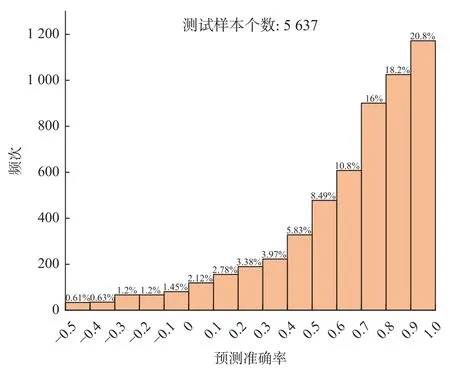
图9 SVR 测试结果
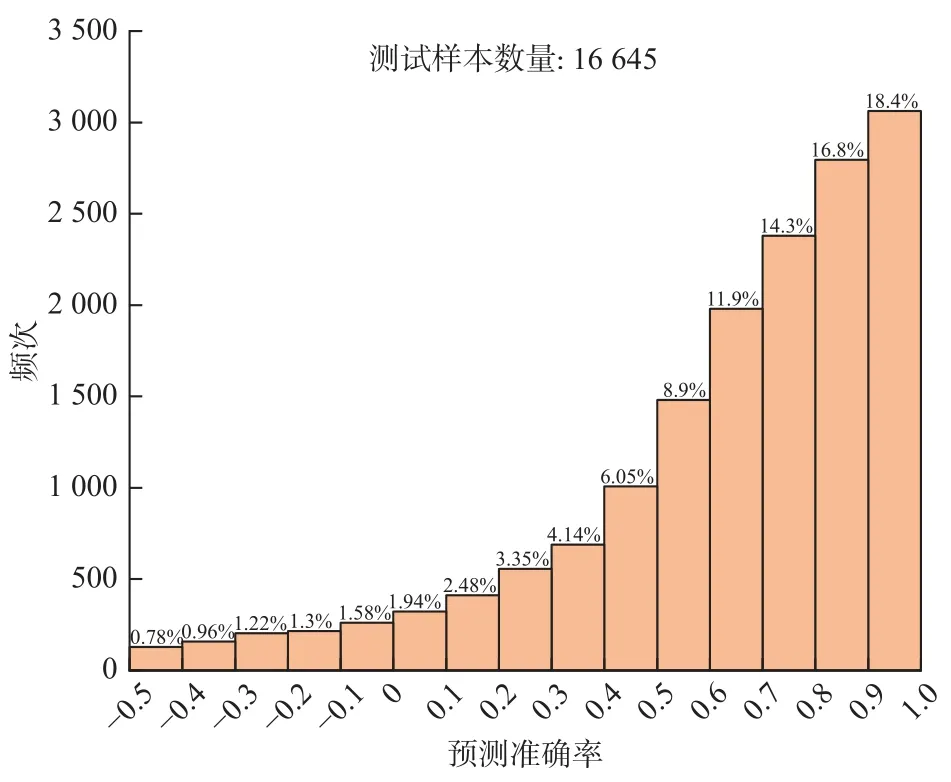
图10 MLP 测试结果
预测准确率的值越接近1,代表样本的预测值与标签值越接近.因此,预测准确率值越靠近1 的测试样本在总测试样本中的占比越大代表预测效果越好.上述结果表明,三种模型对定位精度预测性能的排名为GBDT>SVR>MLP.另外,模型训练时间排序为SVR>GBDT>MLP.综合考虑预测性能与训练时间,结果表明本文所选GBDT 模型最适合定位性能评估任务.
3.3 单站模型验证与结果分析
使用GBDT 模型对DGAR、MIZU、JFNG、CUSV等140 余个测站数据集,分别对单测站完成建模,将每个测站的数据集按9∶1 的比例分为训练集与验证集,得出训练结果如下.
在所有测站中,中国及周边区域12 个测站模型模拟定位精度预测准确率1-MAPE 为92.36%,最差为PTGG 站,预测准确率1-MAPE 为89.26%,全球范围120 个测站模型模拟定位精度预测准确率1-MAPE 为86.59%,最差为SCOR 站,预测准确率1-MAPE 为81.46%.图11 为测站评估结果.
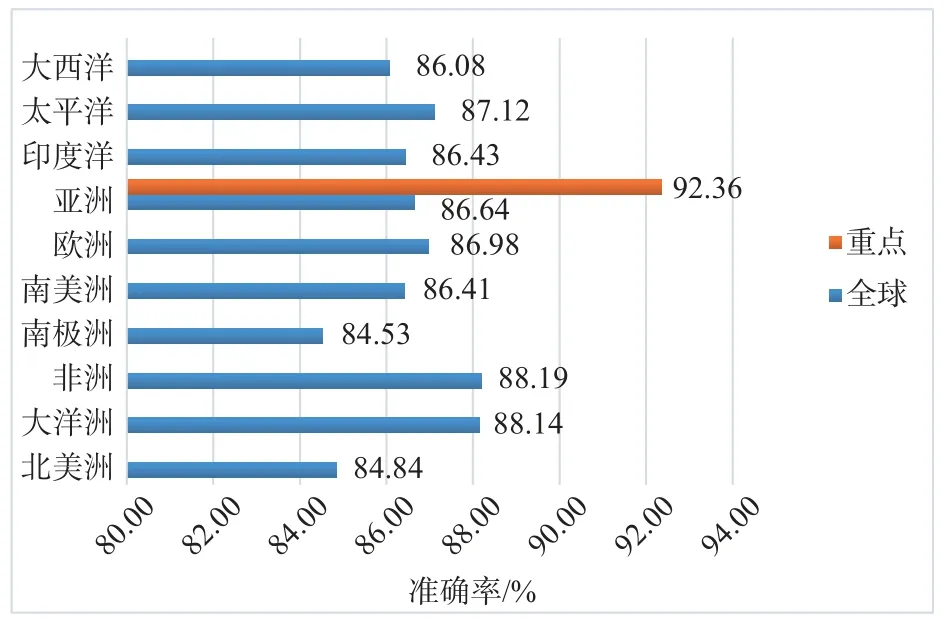
图11 测站GBDT 模型评估结果
结果表明,GBDT 模型用于卫星导航全球定位精度评估效果与传统数理统计框架下得到的实测值较为吻合,该方法可为后续研究机器学习在基于时间和空间条件下对全球定位性能评估问题提供理论基础和经验.
4 结论与展望
本文提出了一种基于机器学习模型评估卫星导航系统定位性能的方法,主要通过模型对定位精度实现高准确率预测,进而评估定位性能.在相同数据集上,选取三种常用于非线性拟合的机器学习模型进行训练,得到了GBDT 模型更适合卫星导航定位性能评估的结论.同时,对全球共140 余个测站分别进行了单独建模,结果表明:机器学习拟合得出的导航定位精度评估效果与实测值较为吻合,说明基于机器学习模型评估卫星导航定位性能的方法可行有效,为下一步对定位性能在时空域的预测提供了技术基础.
但是,本文采取的方法还存在诸多不足.如特征值只充分考虑了传播段,对用户段和空间段考虑不足;模型超参数搜索方法较为简单等.后续将进一步增加对GNSS 数据相关特征选取方面的研究,以提高评估和预测性能;改进模型超参数搜索方法,使用如遗传算法(genetic algorithm,GA)等方法寻找模型最佳超参数,避免在超参数搜索时因手动进行网格搜索带来人为引入的局限性.
