面向国产高性能众核处理器的编程模型
2023-11-29陈虎周鹏灵
陈虎,周鹏灵
面向国产高性能众核处理器的编程模型
陈虎1,2,周鹏灵1*
(1.华南理工大学 软件学院,广州 510006; 2.广东省高性能计算重点实验室,广州 510033)( ∗ 通信作者电子邮箱1197615077@qq.com)
在国产高性能众核处理器上编程时,需要直接使用最底层的接口开发软件,这使编程和调试非常困难;并且各自平台的高性能软件编程模型较为基础,计算软件不能通用,造成了重复性开发。针对以上问题,实现了通用编程模型以及所对应的支撑库:一方面基于消息队列机制开发国产高性能众核处理器的线程级并行机制;另一方面基于单指令多数据流(SIMD)编程模型开发从核上的数据级并行性。首先,对国产高性能众核处理器体系结构进行抽象;其次,设计模型的消息队列机制,并为程序员提供一套异构并行编程接口,如系统参数接口、从核线程控制接口、消息队列接口、SIMD抽象接口;最后,在上述基础上形成全新的高性能计算软件开发模型和方法,方便用户开发基于国产高性能众核处理器的并行计算软件。性能传输测试结果表明,在国产众核处理器上,当启动核数较少时,所提模型的传输带宽普遍达到了峰值直接内存访问(DMA)带宽的90%;当启动的核数较多时,消息队列模型的传输带宽普遍达到了峰值DMA带宽的70%。在矩阵乘法实验中,与系统原语传输矩阵并计算的性能相比,所提模型的性能达到前者的90%;在口令猜测系统中,所提模型的代码性能与直接使用最底层的接口开发的代码性能基本持平。所提通用编程模型和支撑框架使高性能计算(HPC)软件开发更简易,并且具有更好的可移植性,可为促进国产自主HPC软件研发提供帮助。
国产众核处理器;单指令多数据流;并行编程模型;SW26010;消息队列模型
0 引言
为了在有限的芯片面积上提供更多的计算能力,我国研发的SW26010[1-2]和面向E级计算的异构融合加速器[3-4]等高性能众核处理器系统采用异构结构,即包含数量众多的较为简单的从核和少量复杂的主核。主核和从核通常具有不同的指令集,通过核中单指令多数据流(Single Instruction Multiple Data, SIMD)部件提升计算能力,通过不具有Cache一致性[5]的本地存储器和主核心交换数据。在软件层面,主核执行较为完善的操作系统,可以支持通用的多线程编程模型如OpenMP(Open Multi-Processing)[6]、pthread[7]等;但从核上仅能运行一个线程,而且从核的线程控制也是非标准化的编程接口。
国产高性能众核处理器在内存组织方面与传统对称多处理器(Symmetrical Multi-Processor, SMP)[8]和Cache一致性的统一存储器访问(Cache Coherent Uniform Memory Access, CC-UMA)[9]的结构有很大不同,而且从核多线程和SIMD指令的使用也与国际常见标准不同。这直接导致两个问题:1)软件开发困难,大多数情况下,在这些国产高性能众核处理器上进行软件开发只能远程连接到超算中心进行调试;2)不同国产高性能众核处理器的国产软件无法通用,因为在这些处理器上进行软件开发都直接选用平台最底层的接口,导致本就薄弱的国产应用软件研发力量变得更分散,造成大量重复性开发工作。
为此,本文提出一种面向国产高性能众核处理器的编程模型。一方面,基于消息队列机制开发国产高性能众核处理器的线程级并行机制;另一方面,通过SIMD编程模型开发从核上的数据级并行机制。该编程模型已经在x86微处理器[10]、SW26010处理器、面向E级计算的异构融合加速器这三种不同平台上实现。在此编程模型的支持下,用户可以首先使用基于x86平台上的模型开发和调试高性能计算(High Performance Computing, HPC)软件,再将应用软件移植到国产高性能众核处理器上,这样不仅可以有效降低开发难度,还可以在两种不同类型的国产高性能微处理器上快速迁移同一个软件,有效提升国产HPC软件开发和迁移的效率。基于本文模型的国产HPC软件开发流程如图1所示。
1 相关工作
1.1 多线程编程模型
OpenMP[6]是当前对称多处理器系统上的常见多线程编程接口,并得到了广泛支持。基于该标准开发的应用程序具有良好的可移植性。
Cilk++[11]是一种基于C++的并行编程模型。Cilk++使用了clk_for、cilk_spawn和cilk_sync这3个关键字对C++进行并行扩展,运行时应用分而治之的方法在工作线程之间调度任务,以确保多个线程负载均衡。
Voss等[12]提出了开源线程构建库(Threading Building Block, TBB),它以任务为调度单位,并在POSIX和Windows线程库上具有可移植性。oneAPI[13]的软件编程框架目标是为Intel各类计算架构,如CPU、GPU、现场可编程门阵列(Field Programmable Gate Array, FPGA)或者其他针对不同应用的硬件加速器等,提供一个统一编程模型和应用程序接口。oneAPI的核心是DPC++(Data Parallel C++)的编程语言,可以支持跨CPU和加速器上的数据并行和异构编程,目标是简化编程,提高代码在不同硬件上的可重用性,同时能根据特定的加速器调优。oneAPI提供了一个统一的编程模型和一组开发工具和库,可以使各种中间件和框架更轻松地利用CPU、GPU、FPGA等加速器,实现高性能计算;同时,oneAPI提供的DPC++使用户能够直接利用这些工具和库,无须了解底层硬件的细节。
1.2 SIMD编程模型
现代微处理器上已经广泛使用了SIMD指令,如SSE(Streaming SIMD Extensions)[14]、AVX(Advanced Vector eXtension)[15]、AVX-512[15]和SVE(Scalable Vector Extension)[16-17]等。为了充分使用这些SIMD指令,在软件系统中使用了以下方法:
1)直接书写汇编或使用针对特定处理器的内嵌原语。这种方法与特定的硬件平台绑定,性能较高但可移植性很差。
2)使用编译器自动矢量化[18-19]。在编译器自动矢量化方面,如OpenMP 4.0的#pragma omp simd语句可以将函数和循环标识为数据并行。编译器自动矢量化使应用软件具有较好的可移植性,但是效果取决于编译器的能力和软件书写的风格,性能往往较差。
3)采用较为通用的SIMD抽象层。例如,MAL(Macro Abstraction Layer)[20]使用了一组宏代替内嵌原语函数,并可以根据配置替换为SSE、AVX指令。Kretz等[21]提出的Vc库(Vc library)将SIMD内嵌原语封装在高级函数中,可以提供更高级别的抽象,库将确定目标硬件可以并行执行的向量的宽度;但如果仅需要部分的向量宽度时,必须使用额外的屏蔽操作来禁用向量通道。Wang等[22]提出的gSIMD(generic SIMD)库根据每个向量的通道数(fixed-lane)而非向量的字节长度(fixed-width)操作,程序员只需定义通道数,由该库将这些元素映射到基础SIMD向量宽度和硬件。目前,也仅支持Intel的SSE4.2以及IBM POWER7处理器的VSX指令。
4)在应用软件系统(如快速傅里叶变换(Fastest Fourier Transform, FFT)软件[23])中自行设计和使用SIMD抽象层,并按照不同硬件平台编译成特定的SIMD指令。这种方法在很多HPC软件上得到了广泛使用,但是每种HPC软件的抽象层定义不统一,难以推广。
5)使用C++等高级语言提供的库(如Click++库)。
可见,对于国际高性能软件编程模型来说,应用软件在不同硬件平台上的可移植性仍然是一个重要的特性。但是现有的编程模型难以直接在国产高性能众核处理器上使用,因为该处理器的体系结构和操作系统具有自己的特点;而且国产高性能众核微处理器的差异性阻碍了国产高性能软件的发展,使应用软件在国产高性能众核处理器之间不通用;同时,现有的SIMD编程模型也无法适用于国产众核处理器,例如自动矢量化的OpenMP和Cilk++方法需要编译器版本支持,而当前的SIMD抽象层比如Vc库和gSIMD方法,它们封装了SIMD指令,但支持的指令集仅仅包含SSE4.2以及IBM POWER7处理器的VSX指令等,十分有限;MAL也仅支持部分指令集架构(Instruction Set Architecture, ISA)中的宏,不能在国产众核处理器中使用。
本文研究的编程模型和支撑框架可以在“神威”“天河”和x86等不同体系结构上高效运行,有效提高应用软件的可移植性,能为我国HPC软件研发提供帮助。
2 编程模型设计
2.1 国产众核处理器的体系结构模型
我国自行设计和实现的SW26010处理器采用了异构多核处理器结构,由4个异构群构成,通过群间传输网络来实现4个异构群和系统接口总线的存储共享和通信。每个异构群都可以被当作一个单独的计算单元用于计算,它的结构如图2所示。
每个异构群包括1个主核和64个从核。每个异构群具有相同的存储器层次关系,它分为两部分:一部分为8 GB的异构群内存;另一部分为从核局部存储空间。
主核主频为1.5 GHz,L1 Cache大小为32 KB,L2 Cache大小为256 KB,采用4译码7发射超标量结构。从核主频为1.5 GHz,采用2译码2发射超标量结构,支持256 bit的SIMD指令集,每个从核局部存储空间大小为64 KB,指令存储空间为16 KB,从核可以直接离散访问主存,也可以通过DMA的方式批量访问主存。
面向E级高性能计算的异构融合处理器采用了异构融合架构,包含16个CPU、96个控制核心和1 536个加速核心:16个CPU组成一个通用区,96个控制核心和1 536个加速核心组成加速区,平均分为4个加速簇,如图3所示。每个集群有24个控制核、384个加速核,处理器结合了超长指令字(Very Long Instruction Word, VLIW)技术和加速阵列的微结构,每个加速核心以VLIW方式工作,每16个加速核和1个控制核组成一个加速阵列。
多核CPU采用硬件维护Cache一致性,包含512 KB的 L2 Cache。每个加速簇采用6 MB的全局共享存储(Global Shared Memory,GSM)、48 MB的HBSM(High Bandwidth Shared Memory)和32 GB DDR4(Double Data Rate Fourth Generation)多级存储结构。另外,在每个加速阵列上还包括了64 KB的私有标量内存(Scalar Memory, SM)和768 KB的私有阵列内存(Array Memory, AM)。最高支持1 024位的SIMD指令操作。通用区域中的CPU可以访问不同加速簇中的HBSM和DDR空间,而控制核心和加速核心只能访问它自己簇中的GSM、HBSM和DDR空间,不同加速簇的数据共享是通过CPU完成的。
SW26010和面向E级高性能计算的异构融合处理器具有以下共同的特点:
1)它们都采用了非对称的结构,即片上的处理器核分为少量的主控核和大量的计算从核。
2)从核上不具备多进程(线程)的操作系统支持,仅支持一个线程在从核上运行。不同的处理器具有不同的从核线程编程接口。
3)每个计算核都有独立的局部存储器空间,而且这些存储器空间不具备Cache一致性,需要程序员通过显式程序控制系统主存与各个计算核存储器之间的数据交换。
4)主核和从核之间的数据交换有两种方法:①从核直接访问主核的内存空间,延迟较长,仅仅适用于传递控制信息;②从核启动的DMA过程,可以传输规模较大的数据。
5)从核上支持SIMD指令,不同处理器的SIMD宽度各不相同。

图3 面向E级高性能计算的加速器芯片
本文提出了如图4所述的抽象结构描述这两种不同类型的众核处理器的特点。一个完整的处理器簇由一个主核和个从核构成:主核拥有片上Cache访问主存;从核具有独立的局部存储器,但不支持Cache一致性协议,主核和从核之间进行数据交换,可以通过从核DMA完成。每个从核上都具有SIMD指令系统。不同的处理器中,SIMD的数据宽度不一定相同。

图4 国产高性能异构处理器的体系结构抽象
为了降低并行程序编写的难度,将x86一个主线程当作主核,其他线程当作从核,在x86平台完成代码开发并利用x86上广泛使用的工具进行调试。表1给出了实验所用x86服务器、SW26010和面向E级高性能计算的异构融合加速器的主要体系结构参数。
2.2 编程模型
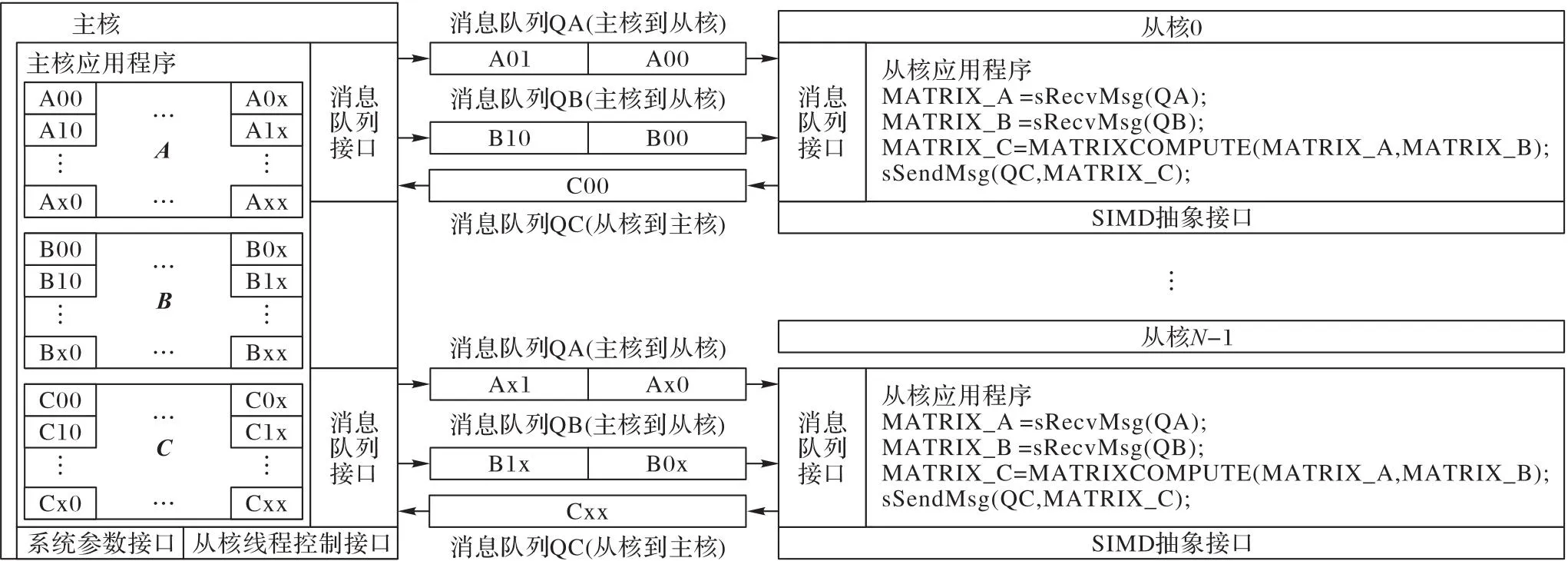
本文模型结构如图5所示,主要分为系统参数接口、从核线程控制、消息队列接口、从核上SIMD抽象接口等部分。主核和从核的应用程序通过系统参数接口获取从核数量、SIMD宽度、局部存储器容量等参数,并可以根据这些参数调整相应的算法和数据结构尺寸。主核通过从核线程控制接口启动和管理从核上的线程。主核和从核之间通过消息队列[24]交换数据,而不需要应用程序考虑不同众核处理器局部存储器的数据传输机制。从核上的应用程序可以通过SIMD抽象接口使用从核上的SIMD指令系统。

表1 国产高性能众核处理器的主要参数
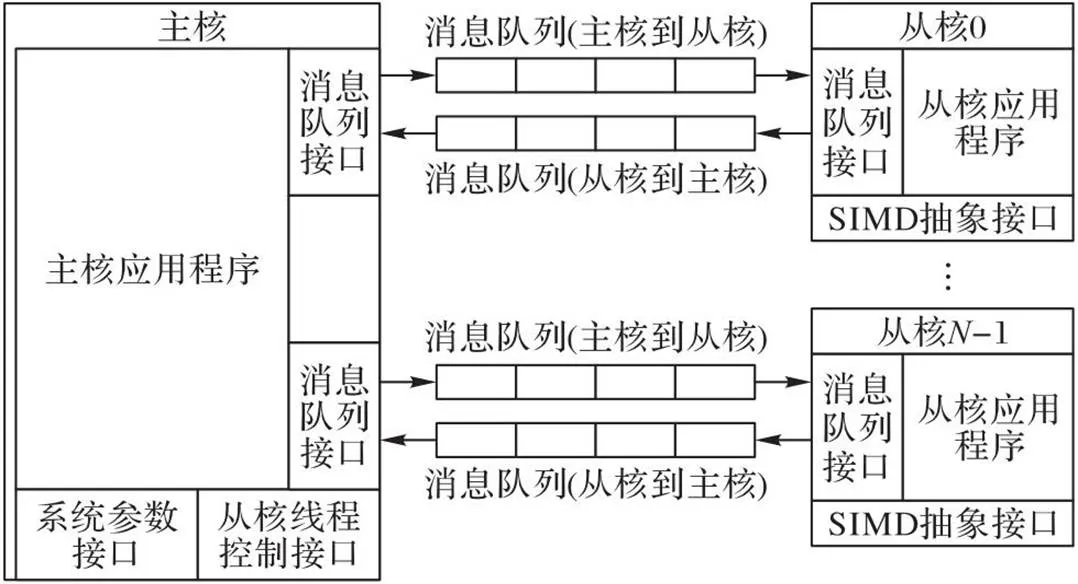
图5 针对国产高性能众核处理器的编程模型
2.2.1系统参数接口
系统参数接口主要用于标识当前高性能众核处理器的关键体系结构参数。在主核和从核上均可以获得从核数量、从核的局部存储器空间容量、从核SIMD数据宽度等信息,在从核上还可以得到该线程所处的从核编号(对于包含个从核的多处理器,从核的标号从0开始计数,直至-1)。
2.2.2从核线程控制接口
主核可以通过这个接口创建并启动从核线程组、等待线程组终止、关闭线程组,并查询特定从核上的线程是否活跃。
int sum_calc(int *a, int n) {
…
int cluster_id=1;
int cn=mGetSlaveCoreNum(cluster_id); //获取从核数量
ThreadID tid=mStartSlaveThreads(0, cn,
(void *)slave_sum_calc_by_slave_core, NULL); //开启从核线程组
…
mWaitSlaveThreads(tid); //等待线程组终止
mDestroySlaveThreads(tid); //关闭线程组
…
return sum;}
上述应用程序示例中,主核根据从核数启动从核线程,并等待从核线程结束,再销毁所有的从核线程。该接口完全屏蔽了国产微处理器私有的athread和hThread从核线程接口,同时还支持Linux上的pthread接口,使应用程序具有良好的可移植性。
2.2.3消息队列接口
消息队列是主核与从核之间交换数据的主要方式。在本文模型中,消息队列的方向分为主核到从核和从核到主核两类,不支持从核之间直接建立消息队列。在每个消息队列中,消息的大小固定。当发送方往一个队列发送多个消息时,接收方将按照发送方发送消息的顺序先后接收到消息。
在主核和同一个从核之间可以建立多个消息队列,以传输不同类型的消息。与消息队列相关的接口主要包括:
1)消息队列的创建和销毁。
在创建消息队列时,需要指定以下参数:消息队列的名称、从核的编号、消息的尺寸大小、消息队列在主核部分所能容纳的消息数量、在从核部分所能容纳的消息数量、消息队列的方向、主核消息队列的起始地址位置、消息队列在从核中所使用的存储器类型等。创建的每一个队列都拥有一个唯一的标识号。
队列是由主核创建,但会在主核和从核都产生一个新的队列句柄。在主核方面,将按照不同的从核编号分区设置句柄,(从核编号,句柄号)或者(从核编号,队列名称)可以确定一个唯一的队列实体。在从核方面,句柄号或者队列名称就可以标识唯一的队列实体。同一个队列在主核与从核上的句柄相同,即主核上(SlaveID, handle)对应的队列与第SlaveID个从核上对应的句柄为handle的队列为同一个队列实体。
例如,现在有一个主处理器和两个从核A、B,如果主处理器和从核A建立两个队列,名称分别为“MasterToA”“AToMaster”。主处理器和从核B建立了两个队列,名称分别为“MasterToB”“BToMaster”。所形成的句柄如表2所示。
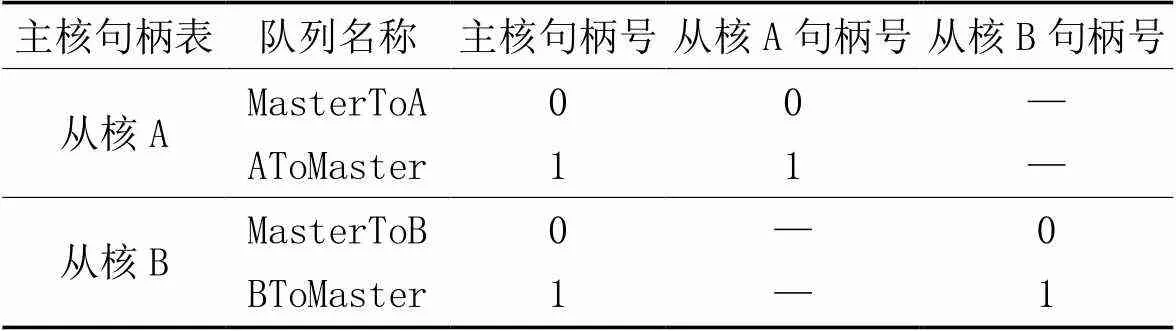
表2 队列句柄示例
2)消息队列的状态查询。
通过消息队列的标识号能够查询到特定消息队列的状态,主要包括队列是否存在、消息的尺寸、当前队列中消息的数量、消息队列方向等。
3)发送和接收消息。
主核或者从核可以向消息队列发送或接收消息,而且提供了阻塞版本与非阻塞版本。
从核的局部存储器容量非常有限,本文采用了应用程序直接访问消息队列中消息内容的方法,可以有效减少局部存储器中占用的空间,并避免不必要的内存拷贝。从核上消息访问接口有所不同。
int sum_calc(int *a, int n) {
int cn=mGetSlaveCoreNum(c_id); //获取从核数量
int sn=n/cn;
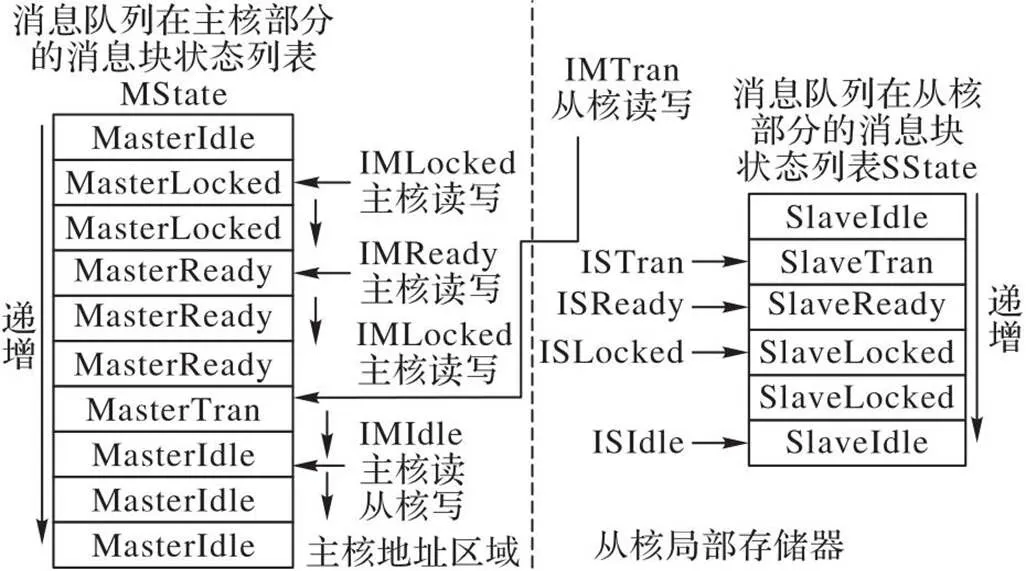
…
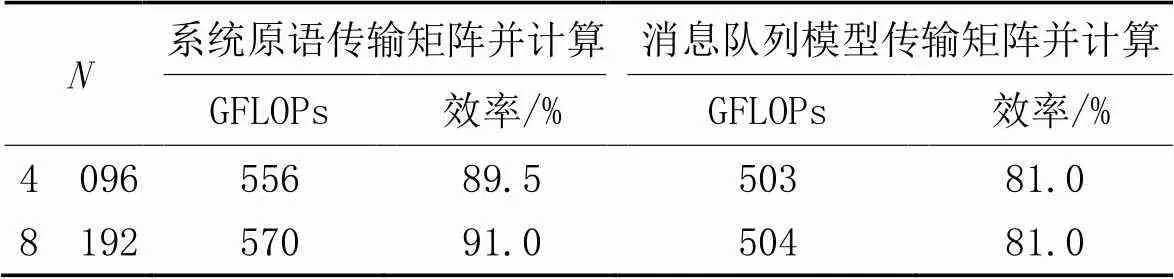
for (int i=0; i handle0=mCreateQueue(c_id, "Input" , i, M*sizeof(int), 1, 1, NULL, SlaveScalarMem, MasterToSlave, &err0); handle1=mCreateQueue(c_id, "Output", i, M*sizeof(int), 1, 1, NULL, SlaveScalarMem, SlaveToMaster, &err1); } … //主核发送消息程序 int *addr=(int *)mAllocateMsg(i,handle0,&err0); //分配消息内存 int len=((j+M) memcpy(addr, &a[i * sn+j], len); mSendMsg(i, handle0, addr, len, &err0); //发送消息 … //主核接收消息程序 int *ret_ptr; int sum_size; ret_ptr=(int *)mRecvMsg(i, handle1, &sum_size, &err1); //接收消息 … //处理消息 mReleaseMsg(i, handle1, ret_ptr, &err1);} //释放消息内存 上述例子中,主核首先针对每个从核建立了一对主核到从核和从核到主核的消息队列。主核程序在发送消息时将先使用mAllocateMsg()获得消息块的指针,再使用memcpy()填充消息块内容,最后使用mSendMsg()发送这个消息。从核程序使用sResvMsg()接收消息后,将获得这个消息块的指针并锁定这个消息,再直接访问消息块的内容,在使用完消息中的内容后再使用sReleaseMsg()向消息队列释放消息块。 2.2.4SIMD抽象接口 SIMD接口为应用程序提供了多种向量数据类型,例如:_VF32表示32位单精度浮点向量,_VU32表示32位无符号整数向量。在此基础上提供了常见的SIMD操作,主要包括数据设置、存储器读/写、单精度/双精度浮点的算术计算、整数的算术/逻辑/移位计算等。 本文模型还增加了预先定义的常量表示SIMD指令系统的通道数。例如_VF32_SIZE表示SIMD指令集中单精度浮点的通道数。在AVX指令集上,该值为256/32=8。使用通道数参数可以基于不同的SIMD指令系统构造应用程序。以下是一个具备良好可移植性的向量求和程序: void addv(float *a,float *b, float *c, int len){ int i=0; while((i+_VF32_SIZE) _VF32 va,vb,vc; va=_VF32_LOAD(a+i); //加载向量 vb=_VF32_LOAD(b+i); vc=_VF32_ADD(va,vb); //进行向量加法运算 _VF32_STORE(c+i,vc); //存储向量 } for(;i 在系统中,主核需要访问的消息队列的管理和控制信息都存储在主核存储器上。因为从核到主核和主核到从核的DMA数据传输的请求都只能由从核来发起,而且从核是单线程,从核可以访问到主存,所以当队列管理模块需要被主核访问时,需要建立在主存,可以由主核和从核共同访问。主核会存储它与所有从核的交互的消息队列信息。 系统主核主要的数据结构关系图6所示,箭头表示该表项结构体包含的指针。图6中,SlaveArgument表示表项数量为从核设备数量,每一项作为一个对应从核线程的结构体参数,该结构体中含有需用户指定的主核设备号、线程序号以及用户定义的传参,并均含有一个指向HMQTab线性表中对应设备表项的指针,它们指向同一个表项。 HMQTable表的每一项对应一个主核,并指向一个主核所对应的所有从核的消息队列入口表HMQLinkedListHead。HMQLinkedListHead表中每个表项对应一个从核,表项指向的HMessQueueNode表为该主核和从核之间的消息队列。SlaveArgument、HMQTable和HMQLinkedListHead表项数目与主核和从核的核心数目相关,可以根据不同的HPC平台灵活配置。 HMessQueue线性表表项数目则由用户代码创建的消息队列数量决定,可以通过前文所提到的句柄handle快速访问到表项。 图6 系统主核的主要数据结构 在系统中,因为从核访问主核数据会产生较长的时间浪费,所以主核与从核的消息队列的管理和控制信息分别存储在各自的存储器上,消息队列整体结构如图7所示。 图7 消息队列的组织 在本文模型中,1个主核和1个从核之间可以有多个单向消息队列。按照方向区分,可以分为主处理器到从处理器(MasterToSlave),从处理器到主处理器(SlaveToMaster)两种。主核和从核消息队列的管理和控制信息存储器在各自的存储器上。不过主核的存储器信息可以由主核和从核共同访问。两种类型的消息队列在主核和从核上都具有一块连续的存储空间(分别成为消息队列的主核部分和从核部分)存放消息内容。 HMessQueue线性表为主核的消息队列管理和控制信息,每个节点对应了一个消息队列,包含了计算核心的ID号、队列名称、句柄、状态、方向、队列在计算核心的地址类型、最长支持的消息字节数、主核部分的消息内容、主核部分的控制消息内容。 SMessQueue线性表为从核的消息队列管理和控制信息,在启动从核线程时,它由从核线程初始化相应信息,SMessQueue线性表每个表项与HMessQueue线性表的每个表项一一对应,除了HMessQueue线性表所包含的内容,还创建了本从核的消息内容,以及本从核的控制消息内容。 国产众核处理器采用了非对称的结构,包括少量复杂的主核和数量众多的较为简单的计算核,从核上不具备多进程(线程)的操作系统支持,仅仅支持一个线程在从核上运行,所以在进行主核与某个从核A之间的消息队列通信时,建立一个主核与某个从核A单独的消息队列,这个消息队列可以看作单生产者单消费者模型,而消息的存储采用环形缓冲队列,实现了不使用任何同步机制的传递算法。类似Lamport单生产者单消费者无锁队列[25],它证明了当队列由单个使用者和单个使用者同时访问时不需要锁,通过位置变量充当访问数组中的索引实现同步。 根据消息的传递方向不同,会有两种相关的消息结构设计:主核到从核方向消息队列的控制信息布局(图8[24]),及从核到主核方向消息队列的控制信息布局(图9)。 图8 主核到从核方向消息队列的控制信息布局 图9 从核到主核方向消息队列的控制信息布局 每个消息队列的控制信息分为两部分:位置索引和状态列表。状态列表中的每个状态与环形消息块的数据区域中的每个消息块一一对应。主核部分的消息块状态列表和从核部分的消息块状态列表(分别记为MState和SState)分别在主核地址区和从核本地存储中。 主核部分和从核部分分别有四个位置索引,用于指示当前状态消息块的边界。IMTran、IMLocked、IMIdle和IMReady为[0,MSize-1]中的整数;ISTran、ISLocked、ISIdle和ISReady的为[0,SSize-1]中的整数。 在主核发往从核的消息队列控制信息布局(图8)中,IMLocked和IMIdle存储在主核地址区域。IMTran、IMReady和其余4个位置索引均位于从核局部存储器。因为IMTran 、IMReady仅仅被从核读写,而不会被主核使用,可以放置在从核的局部存储器中。从核将尽可能地将为处于MReady状态的消息块启动DMA。这样的设计将主核不必要的变量放置在从核中存储,可以减少从核代码对主核变量的访问,从而提高模型的性能。初始化后,状态列表MState中所有的状态均为MIdle;状态列表SState中的所有状态均为SIdle,所有的位置索引均为0。 主核发往从核方面,消息在消息队列中的状态转移变化如图10所示,主核端消息的消息变化为MasterIdle>>MasterLocked>>MasterReady >>MasterTran>>MasterIdle,相应地从核端的消息状态变化为SlaveIdle>>SlaveTran>>SlaveReady>>SlaveLocked>>SlaveIdle。 图10 主核发往从核时消息队列中消息的状态 以将消息从主核发向从核的交换算法操作序列为例: 1)主核消息块的初始状态为MasterIdle; 2)在主核应用程序调用mAllocateMsg(),会将第一个MasterIdle状态的消息块分配给应用程序,将该消息块的状态转为MasterLocked; 3)主核应用程序设置完成该消息块内容后,调用mSendMsg(),将该消息块的状态转为MasterReady,表示该消息块内容已经准备好,等待从核接收; 4)从核消息块的初始状态为SlaveIdle; 5)当从核接收一个消息时,启动DMA传输,会将从核第一个SlaveIdle块改为SlaveTransfer态,并将获取主核第一个MasterReady的消息块,将主核消息块改为MasterTransfer态; 6)DMA传输结束时,主核消息块的MasterTransfer消息块状态又恢复到MasterIdle等待下次调用分配,从核SlaveTransfer消息块状态变为SlaveReady; 7)从核应用程序调用sRecvMsg()获取第一个SlaveReady状态的消息块,该消息块的状态转变为SlaveLocked态; 8)从核使用完毕后,应用程序调用sReleaseMsg(),将从核消息块SlaveLocked态设置为SlaveIdle状态。 从核发往主核的消息状态转移和消息队列控制信息布局都跟主核发往从核的不同,对于位置索引来说,如图9所示,IIMTran、ISTran、ISReady、ISLocked和ISIdle存储在从核局部存储器,其余3个位置索引均位于主核地址区域。在消息队列中,消息的状态转移变化为:主核端消息从MasterIdle>>MasterTran>>MasterReady>>MasterLocked>>MasterIdle,相应地从核端的消息状态变化为SlaveIdle>>SlaveLocked>>SlaveReady>>SlaveTran>>SlaveIdle。 国产高性能众核微处理器采用非对称的结构设计,主核与从核两者协同为具体的应用提供高效的计算平台。各个平台提供了各自的线程库的管理。 以SW26010、面向E级高性能计算的异构融合加速器为例,SW26010众核处理器提供一组athread库。使用设计程序可以更好地发挥SW26010下从核线程组的加速性能,并能够让用户方便、快捷地对核组内的线程进行创建和管理。主核调用加速线程库可以进行控制线程的初始化、启动、结束等一系列操作。每个线程都绑定到一个从核。而从核调用的加速线程库接口可以进行启动数据传输、执行核心计算等。 而面向E级高性能计算的异构融合处理器上使用了hThread多线程编程接口。该编程接口同样分为两部分,一部分为主核编程接口,另一部分为从核编程接口。主核编程接口除了包括线程管理外,还包含了设备管理、镜像管理等;从核编程接口主要包括并行管理接口、同步管理以及向量化函数接口。 本文模型通过宏定义的方式封装了pthread、athread和hThread这三种不同类型的线程库,形成一层更高级的抽象,提供给用户统一的接口,如:创建并启动从核线程组、等待线程组终止、关闭线程组、主核加载镜像文件到设备等;以下给出了等待线程终止接口的实现方式。在编译时,通过预先定义不同类型的宏,可以使用不同类型的线程库。 void mWaitSlaveThreads(int cluster_id, ThreadID t_id) { #if defined(SW5_VERSION) athread_join(); #endif #if defined(MT3_VERSION) hThread_group_wait(t_id.m_thread_id); #endif #if defined(AVX_VERSION) void *retval; pthread_t *tids=(pthread_t *)t_id.m_ptr; for (int i=0; i < t_id.m_num; ++i) { pthread_join(tids[i], &retval);} #endif} 抽象层的设计主要有两部分:一部分是SIMD数据类型即抽象向量类型;另一部分是对这些数据类型进行的一系列的操作。 1)向量数据类型和长度。针对SIMD指令中的基本数据类型(包括符号和无符号整数、浮点数等),本文定义了一系列向量类型。例如MMX指令集的__m64、SSE指令集的__m128i、AVX指令集的__m256i、__m512i等整数数据类型,都可以认为是32位无符号整数向量类型__VU32。编程模型还可以根据指令系统和基本数据类型指定每个向量的通道数(例如_VU32_SIZE表示了一个向量中的32位无符号整数的通道数)。除此之外,本文模型还可以描述SW26010和面向E级计算的异构融合加速器支持的SIMD数据类型。这两种处理器分别能处理256 bit和1 024 bit的向量类型,通过一条SIMD指令能分别进行4路和32路的32 bit的向量计算。 表3 典型的32位无符号整数向量操作指令 分别在SW26010处理器上和面向E级高性能计算的加速器芯片上进行测试,实验步骤如下: 1)初始化个元素的一维双精度浮点数组; 2)将数组个大小的数据作为一个消息,每个消息带上消息序号,拷贝到消息队列中,发送次,启动个从核接收消息; 3)每个从核利用消息序号对收到的数组进行验证,并累加收到的消息序号的值; 4)从核接收完所有消息后,返回给主核1个累加之后的值,主核验证是否完全收到消息。 采用了对比测试:一种为使用DMA原生接口进行传输的性能,它是理论上能达到的最高传输性能;一种为使用本文消息队列模型的传输性能,每次传输的的大小为16 KB的结果如表4所示。 在两种国产平台上,消息队列模型在从核数启动较少时,本文模型与单纯使用DMA接口的程序相比,消息队列模型的传输带宽普遍达到了峰值传输带宽的90%。在从核数较多时,消息队列模型的传输带宽普遍达到了峰值传输带宽的70%,因为部分控制信息是在主核中存储,从核访问与主核共享的数据是离散的从主存访问(非DMA模式),大量从核离散地访问主存,可能会影响DMA性能,而且主存带宽效率低,大量从核离散load/store访问的话,可能会产生阻塞,耗时会更长。 矩阵乘法[26]是科学计算的基础方法,利用众核处理器和并行化的特点提高它的效率也至关重要。本节根据消息队列模型与SIMD抽象层完成线性代数中重要的矩阵乘法的设计并实现,可以在多种众核处理器上高效并行。 传统的对称处理器在计算大规模矩阵乘法时,为了减少内存带宽的影响,会进行多级数据分块,分块大小围绕着各级缓存容量进行调整。而对于国产众核处理器如SW26010处理器,它能为每个计算核心提供私有的高速缓冲(Local Data Memory, LDM)且从核核组空间有限,一共为64×64 KB 的局部存储空间,无法容纳超过4 MB的数据,因此对于大规模的矩阵乘法,也必须对矩阵进行分块,将矩阵分为多个小矩阵,利用主从核传输接口传输小矩阵,从核多次接收主核分块小矩阵进行计算。 使用编程模型的矩阵乘法代码结构如图11所示,类似图5,代码在x86平台就可以完成软件开发和测试,然后再移植到多个国产众核平台。 表4 数据传输性能测试结果对比 图11 使用编程模型的矩阵乘法主核和从核的软件模块 SW26010处理器参数信息如表5所示,将代码移植到SW26010处理器首先要完成一个核组内的矩阵乘法基础计算代码MATRIXCOMPUTE。利用SW26010下SIMD指令与vldr/vldc和ldder/lddec指令(寄存器互相广播通信指令),达到高效的性能,最终在1个核组内以256×256规模计算矩阵的情况下,性能达到621 GFLOPs。 DMA传输占比矩阵计算时间过长,如果DMA传输和矩阵计算串行运行会显著降低矩阵乘法计算性能。而消息队列模型中利用了异步DMA传输双缓冲的思想,DMA传输启动后,软件系统无须等待DMA结束即可异步地进行其他工作,通过查询DMA结果即可得知DMA是否已经完成。当从核接收消息时,开始对主核部分中已经处于MasterReady状态的消息进行DMA传输(可能不止一个消息)。当从核部分具有两个或以上消息块,并且主核发送消息的速度比从核使用消息的速度快时,从核应用程序读取消息和DMA传输过程就可以并行完成。对于矩阵乘法的表现如图12所示,在主从核建立了3个消息队列QA、QB、QC,QA、QB队列均含有两个消息块表示为A0、A1、B0、B1,用于接收、小矩阵,只含有1个消息块用于返回结果小矩阵,MATRIXCOMPUTE表示矩阵计算,操作时序如图12所示,充分利用国产众核处理器可以异步DMA传输的特性,将DMA传输和矩阵计算并行起来,减少传输对矩阵乘法性能的影响。 最终想要移植矩阵乘法到国产众核处理器SW26010,将代码中矩阵的计算方法MATRIXCOMPUTE由x86下MKL库的cblas_dgemm方法改为SW26010处理器一个核组内的矩阵乘法计算代码并调整相应的传输数据,然后通过改变表6所述对应的编译选项便可以移植运行。矩阵乘法代码按照本文消息队列模型具有极佳的可移植性。 图12 双缓冲操作逻辑 表5 国产众核处理器SW26010配置 表6 不同平台的编译选项 本文模型提供了Makefile文件,在Makefile中修改表6所示的对应选项参数后,执行make命令将本文模型编译成主核与从核的链接库libMHMessQueue.a、libSHMessQueue.a。最后,将应用程序和本链接库编译链接后即可生成不同平台的应用程序。 本文使用两种传输接口分别进行了矩阵乘法性能测试,一种为使用系统原语DMA传输矩阵并计算的性能,另一种为本文的消息队列模型传输矩阵并计算的性能,如表7所示,该表为一个核组内以256×256规模进行分块传输计算的性能。使用系统原语DMA传输矩阵的代码同样使用了双缓冲技术,矩阵乘法的性能达到556 GFLOPs,为单纯进行矩阵计算性能的91%,剩下的一些消耗主要在每次小矩阵计算结束后传输从核小矩阵的传输开销。而利用消息队列模型进行矩阵计算的性能为504 GFLOPs,达到了系统原语传输矩阵并计算性能的88%,达到一个核组内256×256矩阵的性能的81%。主要因为从核访问与主核共享的数据是从主存离散访问,比如一些消息块的状态信息,对于这样频繁访存的应用会有一小部份的性能损耗。 表7 SW26010上的性能测试对比 随着集成电路技术水平的提高,单个微处理器所包含的内核数量持续增长,提高单个微处理器的性能是目前提升HPC系统整体性能的主要方法。我国自主开发了SW26010、Matrix 2000等一系列高性能众核微处理器,在这些处理器上编程由于众核处理器无Cache一致性等的结构特点,需要直接使用最底层的接口开发软件,编程和调试非常困难,各平台的高性能线程编程模型和SIMD指令集不能通用。 本文针对国产高性能众核处理器的线程编程库不统一的问题,提供了线程控制接口层,用于在多个平台下控制线程;针对每个计算核采用独立的存储器空间不具备Cache一致性,需要程序显式控制系统主存与各个计算核存储器之间的数据交换的问题,本文模型提供了消息队列模型;针对国产高性能众核处理器SIMD指令集不通用的问题,本文模型提供了SIMD抽象层。 模型应用在口令猜测系统之中,并将系统移植到在多个平台进行可移植性测试,比较了使用本文模型的代码性能与直接使用最底层的接口开发的代码性能的差异情况。实验结果表明,使用本文模型增加了可移植性,减少了重复性工作,但性能在线程数较多时会有所下降,未来有待继续改进。 [1] 刘鑫,郭恒,孙茹君,等.“神威·太湖之光”计算机系统大规模应用特征分析与E级可扩展性研究[J].计算机学报,2018,41(10):2209-2220.(LIU X, GUO H, SUN R J, et al. The characteristic analysis and exascale scalability research of large scale parallel applications on “Sunway ·TaihuLight” supercomputer[J]. Chinese Journal of Computers, 2018,41(10):2209-2220.) [2] FU H, LIAO J, YANG J, et al. The Sunway TaihuLight supercomputer: system and applications[J]. Science China Information Sciences, 2016, 59(7): No.072001. [3] LU K, WANG Y, GUO Y, et al. MT-3000: a heterogeneous multi-zone processor for HPC[J]. CCF Transactions on High Performance Computing, 2022, 4(2):150-164. [4] 刘胜,卢凯,郭阳,等. 一种自主设计的面向E级高性能计算的异构融合加速器[J].计算机研究与发展,2021,58(06):1234-1237.(LIU S, LU K, GUO Y, et al. A self-designed heterogeneous fusion accelerator for exascale high-performance computing[J]. Journal of Computer Research and Development, 2021,58(06):1234-1237.) [5] NAGARAJAN V, SORIN D J, HILL M D, et al. A Primer on Memory Consistency and Cache Coherence[M]. 2nd ed. Cham: Springer, 2020: 10-11. [6] DE SUPINSKI B R, SCOGLAND T R W, DURAN A, et al. The ongoing evolution of OpenMP[J]. Proceedings of the IEEE, 2018, 106(11): 2004-2019. [7] ABBOTT D. Appendix B — Posix threads (pthreads) application programming interface[M]// Linux for Embedded and Real-time Applications, 2nd ed. New York: Elsevier Science Inc.,2006: 275-286. [8] BARKER D J, STUCKEY D C. A review of soluble microbial products (SMP) in wastewater treatment systems[J]. Water Research, 1999, 33(14): 3063-3082. [9] CAROTHERS C D, PERUMALLA K S, FUJIMOTO R M. The effect of state-saving in optimistic simulation on a cache-coherent non-uniform memory access architecture[C]// Proceedings of the 31st Conference on Winter Simulation: Simulation — A Bridge to the Future — Volume 2. New York: ACM, 1999: 1624-1633. [10] GUPTA K, SHARMA T. Changing trends in computer architecture: A comprehensive analysis of ARM and x86 processors[J]. International Journal of Scientific Research in Computer Science Engineering and Information Technology, 2021, 7(3): 619-631. [11] ROBISON A D. Composable parallel patterns with Intel Cilk Plus[J]. Computing in Science and Engineering, 2013, 15(2): 66-71. [12] VOSS M, ASENJO R, REINDERS J. Pro TBB: C++ Parallel Programming with Threading Building Blocks[M]. Berkeley, CA: Apress, 2019: 3-31 [13] NOZAL R, BOSQUE J L. Exploiting co-execution with oneAPI: heterogeneity from a modern perspective[C]// Proceedings of the 27th International Conference on Parallel and Distributed Computing, LNTCS 12820. Cham: Springer, 2021: 501-516. [14] RAMAN S K, PENTKOVSKI V, KESHAVA J. Implementing streaming SIMD extensions on the Pentium III processor[J]. IEEE Micro, 2000, 20(4): 47-57. [15] AMIRI H, SHAHBAHRAMI A. SIMD programming using Intel vector extensions[J]. Journal of Parallel and Distributed Computing, 2020, 135: 83-100 [16] STEPHENS N, BILES S, BOETTCHER M, et al. The ARM scalable vector extension[J]. IEEE Micro, 2017,37(2):26-39 [17] ODAJIMA T, KODAMA Y, SATO M. Performance and power consumption analysis of ARM scalable vector extension[J]. The Journal of Supercomputing, 2021, 77(6): 5757-5778. [18] WANG D, ZHAO R, WANG Q, et al. Outer-loop auto-vectorization for SIMD architectures based on Open64 compiler[C]// Proceedings of the 17th International Conference on Parallel and Distributed Computing, Applications and Technologies. Piscataway: IEEE, 2016: 19-23. [19] TIAN X, SAITO H, SU E, et al. LLVM compiler implementation for explicit parallelization and SIMD vectorization[C]// Proceedings of the 4th Workshop on the LLVM Compiler Infrastructure in HPC. New York: ACM, 2017: No.4. [20] CEBRIÁN J M, JAHRE M, NATVIG L. Optimized hardware for suboptimal software: the case for SIMD-aware benchmarks[C]// Proceedings of the 2014 IEEE International Symposium on Performance Analysis of Systems and Software. Piscataway: IEEE, 2014: 66-75. [21] KRETZ M, LINDENSTRUTH V. Vc: a C++ library for explicit vectorization[J]. Software: Practice and Experience, 2012, 42(11): 1409-1430. [22] WANG H, WU P, TANASE I G, et al. Simple, portable and fast SIMD intrinsic programming: generic simd library[C]//Proceedings of the 2014 ACM SIGPLAN Workshop on Programming Models for SIMD/Vector Processing. New York: ACM, 2014: 9-16. [23] FRIGO M, JOHNSON S G. FFTW: an adaptive software architecture for the FFT[C]// Proceedings of the 1998 IEEE International Conference on Acoustics, Speech and Signal Processing, Volume 3. Piscataway: IEEE, 1998: 1381-1384. [24] 华南理工大学,广东省科技基础条件平台中心.基于局部存储器的主核与从核之间消息传递系统: 2023100756041[P]. 2023-06-23. (South China University of Technology, Guangdong Science and Technology Infrastructure Center. Message transfer system between master and slave cores based on local memory: 2023100756041.1[P]. 2023-06-23.) [25] MAFFIONE V, LETTIERI G, RIZZO L. Cache-aware design of general-purpose Single-Producer-Single-Consumer queues[J]. Software: Practice and Experience, 2019, 49(5): 748-779. [26] ALMAN J, WILLIAMS V V. A refined laser method and faster matrix multiplication[C]// Proceedings of the 32nd Annual ACM-SIAM Symposium on Discrete Algorithms. Philadelphia, PA: SIAM, 2021: 522-539. Programming model for domestic high-performance many-core processor CHEN Hu1,2, ZHOU Pengling1* (1,,510006,;2,510033,) Programming on domestic high-performance many-core processors has requirement of using the lowest-level interface to develop software, making programming and debugging very difficult. Moreover, the limitations of programming models for high-performance software on these platforms and the absence of common computing software are identified as factors that contribute to repetitive development work. Aiming at the above problems, a generalized programming model and corresponding support library were realized: on the one hand, the thread-level parallelism of domestic high-performance many-core processors based on the message queue mechanism was developed; on the other hand, the data-level parallelism on slave cores based on the Single Instruction Multiple Data (SIMD) programming model was developed. Firstly, the architecture of the domestic high-performance multicore processor was abstracted. Then, a message queue mechanism was designed for the proposed model, along with a set of heterogeneous parallel programming interfaces, including system parameter interface, slave core thread control interface, message queue interface, and SIMD abstraction interface. Finally, a new software development model and methodology for high-performance computing were formed on the basis of the above, which was convenient for users to develop parallel computing software based on domestic high-performance many-core processors. The results of performance transmission test show that the transmission bandwidth of the proposed model on domestic many-core processors generally reaches 90% of the peak DMA(Direct Memory Access) bandwidth when a few multi-cores are turned on; and that the transmission bandwidth of the message queue model generally reaches 70% of the peak DMA bandwidth when a large number of multi-cores are turned on. In matrix multiplication experiments, the performance of the proposed model reaches 90% of the performance of the system’s original primitives for transferring matrices and calculating them; in password guessing system, the performance of the proposed model code is basically the same as that of the code developed by using the lowest-level interface directly. The proposed generalized programming model and support framework make the High Performance Computing (HPC) software development easier and more portable, which can help to promote the development of domestic independent HPC software. domestic many-core processor; Single Instruction Multiple Data (SIMD); parallel programming model; SW26010; message queue model 1001-9081(2023)11-3517-10 10.11772/j.issn.1001-9081.2022101548 2022⁃10⁃14; 2023⁃04⁃22; 国家自然科学基金重点项目(U1836207); 广东省高性能计算重点实验室开放课题。 陈虎(1974—),男,江苏南京人,副教授,博士,主要研究方向:高性能计算、信息安全; 周鹏灵(1999—),男,湖北鄂州人,硕士研究生,主要研究方向:高性能计算、信息安全。 TP311.1 A 2023⁃04⁃24。 This work is partially supported by Key Project of National Natural Science Foundation of China (U1836207), Open Development Project of Guangdong Provincial Key Laboratory of High Performance Computing. CHEN Hu, born in 1974, Ph. D., associate professor. His research interests include high-performance computing, information security. ZHOU Pengling, born in 1999, M. S. candidate. His research interests include high-performance computing, information security.3 编程模型实现
3.1 主要数据结构

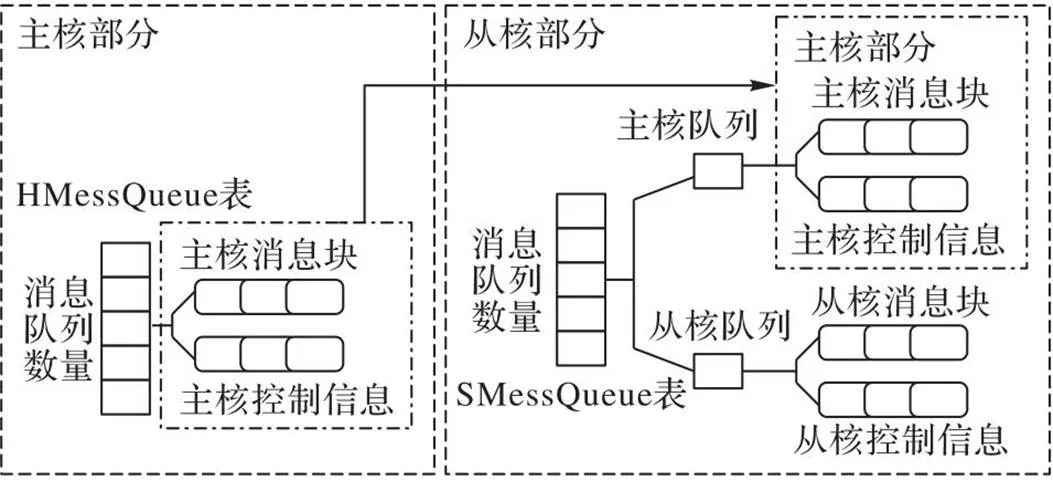
3.2 消息队列结构
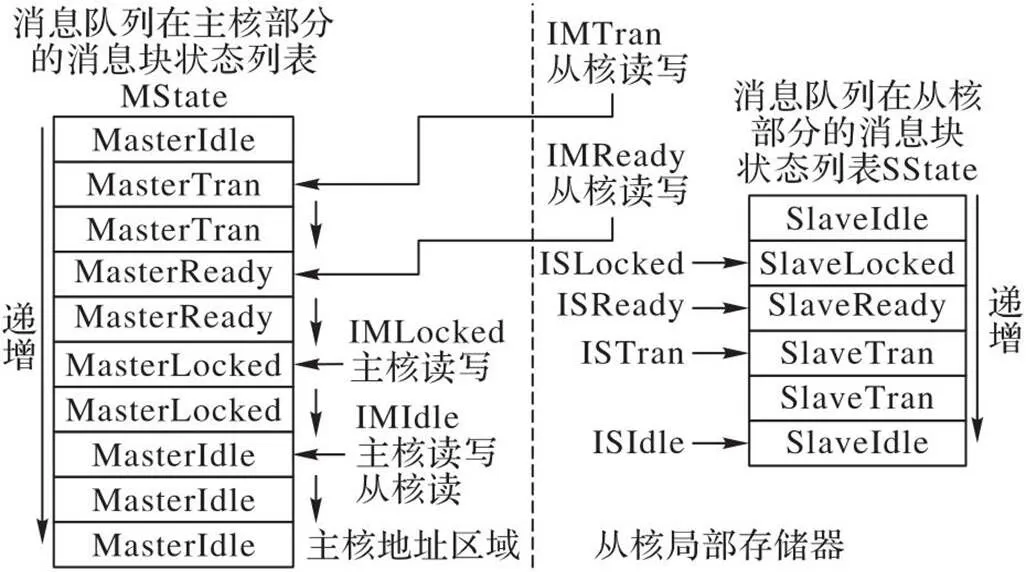
3.3 消息的状态结构设计和传递算法

3.4 从核线程库的实现
3.5 SIMD抽象设计与实现

4 实验与结果分析
4.1 数据传输测试
4.2 矩阵乘法应用






5 结语
