面向复杂图像分类的共享转换矩阵胶囊网络
2023-11-29文凯薛晓季娟
文凯,薛晓,季娟
面向复杂图像分类的共享转换矩阵胶囊网络
文凯,薛晓*,季娟
(重庆邮电大学 通信与信息工程学院,重庆 401520)( ∗ 通信作者电子邮箱1464090345@qq.com)
针对胶囊网络(CapsNet)在处理含有背景噪声信息的复杂图像时分类效果不佳且计算开销大的问题,提出一种基于注意力机制和权值共享的改进胶囊网络模型——共享转换矩阵胶囊网络(STM-CapsNet)。该模型主要包括以下改进:1)在特征提取层中引入注意力模块,使低层胶囊能够聚焦于与分类任务相关的实体特征;2)将空间位置接近的低层胶囊分为若干组,每组内的低层胶囊通过共享转换矩阵映射到高层胶囊,降低计算开销,提高模型鲁棒性;3)在间隔损失与重构损失的基础上加入L2正则化项,防止模型过拟合。在CIFAR10、SVHN(Street View House Number)、FashionMNIST复杂图像数据集上的实验结果表明,各改进均能有效提升模型性能;当迭代次数为3,共享转换矩阵数为5时,STM-CapsNet模型的平均准确率分别为85.26%、93.17%、94.96%,平均参数量为8.29 MB,比基线模型的综合性能更优。
胶囊网络;图像分类;注意力机制;共享转换矩阵;深度学习
0 引言
卷积神经网络(Convolutional Neural Network, CNN)在图像分类、目标检测、自然语言处理[1-3]等领域被广泛应用,但随着研究的深入,CNN的缺陷也逐渐显现,即无法学习不同特征之间的相对位置关系,导致它无法充分利用图像中的信息,因此CNN模型往往需要通过数据增广等技术扩充数据集,并通过海量数据训练提高模型的泛化能力[4],这种固有缺陷是由于CNN采用了降采样的池化操作。为了克服CNN的缺陷,2017年Sabour等[5]提出了新的神经网络架构胶囊网络(Capsule Network, CapsNet)。CapsNet模型使用向量神经元代替传统的标量神经元作为模型基本的计算单元,它的输入输出均为向量,具体的实体由向量的方向表征,向量的模长则表示属于某类实体的置信度,向量的每个维度表征了实体的具体属性,这是与CNN中用标量在不同隐藏层之间传递信息最大的不同;其次,CapsNet使用一种名为动态路由的算法代替CNN中的池化操作。文献[5]中的MNIST重构实验表明,CapsNet可以有效地识别手写数字图像中特定实体的各种属性,例如数字的旋转方向、笔画的粗细、位置等。其中,低层胶囊类似CNN中的前序隐藏层,用于刻画局部特征;而高层胶囊则类似CNN中的后序隐藏层,用于汇聚低层胶囊中的特征信息以表达整体抽象特征;动态路由算法替代了CNN中的池化操作,可以通过聚合低层胶囊信息去更新高层胶囊。文献[6-7]中通过实验证明,胶囊网络可以在训练次数和训练数据较少的条件下获得更好的解释性和更强的泛化能力。
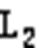
1 相关模型及关键原理
1.1 胶囊网络架构
胶囊网络主要由卷积层(Conv)、主胶囊层(PrimaryCaps)、数字胶囊层(DigitCaps)构成的编码器与重构网络构成的解码器两部分组成,其中编码器如图1所示。
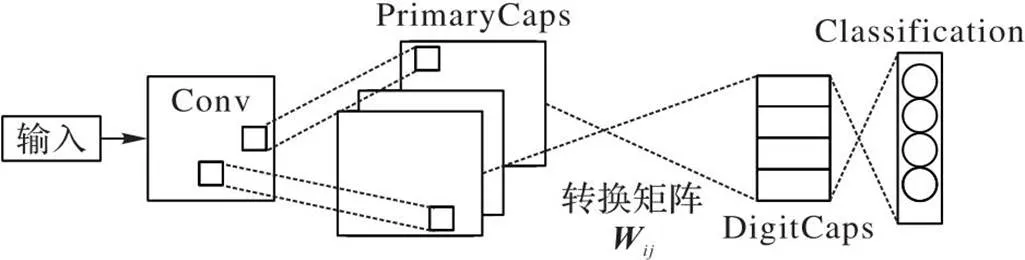
图1 胶囊网络编码器结构
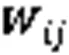
胶囊网络还有一个解码器结构(如图2),它可以利用输出向量中包含的实体属性信息来重构原始图像。解码器输入是数字胶囊层输出的10个16维向量,输出是与输入图像大小相同的重构图像。重构图像越接近原始图像,说明重构损失越小,重构损失作为总体损失的一部分。
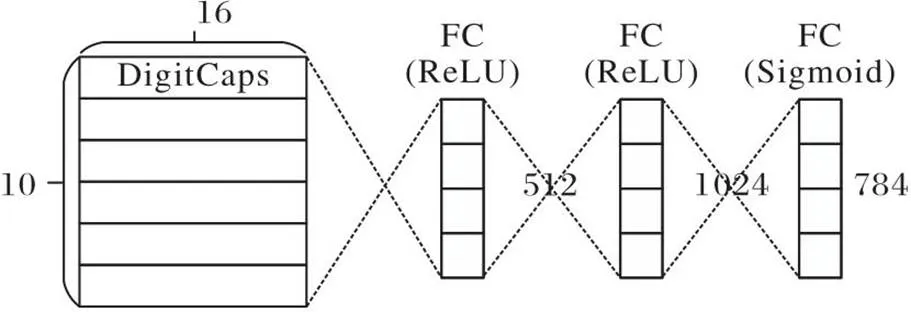
图2 胶囊网络解码器结构
1.2 动态路由算法
胶囊网络不仅根据抽象的特征分类对象,还考虑了特征之间的位置关系,从而更深刻地理解图像中的对象。如图3(a)显示了特征提取层识别出的三角形和矩形,图3(b)显示了胶囊网络对实体存在的判断。图3(b)中有12个胶囊,每个胶囊是一个向量。向量的长度表示检测到某个实体的概率,向量的方向表示实体的位置;实线箭头和虚线箭头分别表示三角形和矩形胶囊检测到的概率。只有当两个箭头都较长且方向一致时,才说明在某个位置上有较高概率存在某个对象。如果图像发生变换,如翻转、旋转或缩放,胶囊输出的向量长度不变,只是方向改变,这样就实现了同变性。


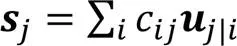
其中:为前一层的第个胶囊的输出向量和对应的转换矩阵相乘得出的预测向量;耦合系数是动态路由算法一个重要参数,高层胶囊j通过与低层胶囊i传递信息,表示低层胶囊对于高层胶囊投票抉择的一致性,是非负值的标量。此外,对于每一个低层胶囊i,与它所连接的所有高层胶囊j的耦合系数之和为1,即。是胶囊i连接至胶囊j的先验概率,初始值为0,通过事先确定的路由次数迭代计算,使低层胶囊和高层胶囊之间的连接是动态的,这一机制指出了哪些低层胶囊在反向传播过程中更应该被更新,同时也指出了图像中的哪些实体应该被关注,使低层胶囊更倾向于将信息传递给与它的耦合系数更大的高层胶囊。
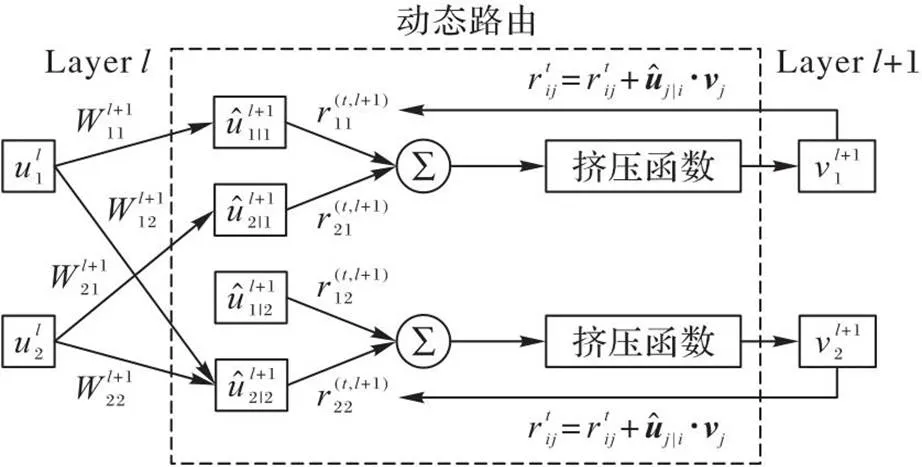
图4 动态路由算法执行过程
动态路由算法如算法1所示。
算法1 动态路由算法。
4) forin range(higher_level_capsules):
1.3 胶囊网络的损失函数
CapsNet可以处理多标签分类问题,即它能同时检测出图像中的多个目标,所以它不采用常用的交叉熵损失函数来衡量预测误差,而是采用间隔损失函数来优化模型,如式(4)所示:
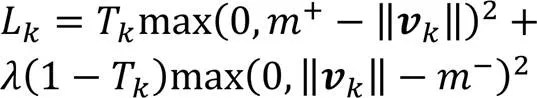
2 本文模型
经典CapsNet主要分为三部分:1)用标准的卷积层提取图像中的特征;2)数字胶囊层首先将卷积后得到的全部特征图展平,每个特征图对应位置的元素被选择出来并组合在一起,形成低层胶囊;随后这些低层胶囊通过与变换矩阵相乘计算与高层胶囊之间的关系,根据动态路由协议更新胶囊连接的权重;3)全连接胶囊层根据路由协议生成最终胶囊以及属于每个类别的概率。但CapsNet在包含复杂对象的数据集上的性能较差,因此本文提出一种新型的胶囊网络结构STM-CapsNet(如图5所示),改进工作如下:
1)在传统CapsNet的特征提取层引入注意力机制模块S‑Attention,使胶囊聚焦在图像中更重要的实体。
2)优化动态路由算法,利用共享转换矩阵获得胶囊的预测向量,大幅减少训练参数。
3)提出一种在局部范围拥有更大梯度的挤压函数e-squash来改善网络中梯度消失的问题,如式(5)所示:
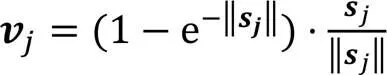
本文模型在卷积层和初级胶囊层之间增加了一层基于注意力机制的特征提取模块S-Attention,以筛选处理卷积层提取的特征信息,去除噪声;并对原始CapsNet使用的路由算法进行优化,不再对每个低层胶囊学习转换矩阵,而是多个低层胶囊共享一个转换矩阵对高级特征进行打分预测,选择性地激活高层胶囊。
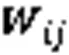
2.1 基于注意力机制的S-Attention
注意力机制是一种资源分配方案,将有限的计算资源用来处理重要信息,通过网络自主学习得到一组权重系数,并将系数与原始数据的对应位置加权,最终突出有用信息并抑制不相关信息,在图像识别等领域被广泛应用[17]。在计算机视觉领域中,注意力基于原有数据寻求信息间的联系,突出待处理对象的重要特征并捕捉图像感受野。文献[18]的分析证明了注意力机制能更好地学习信息表征,具有提取更高维度信息的优势。
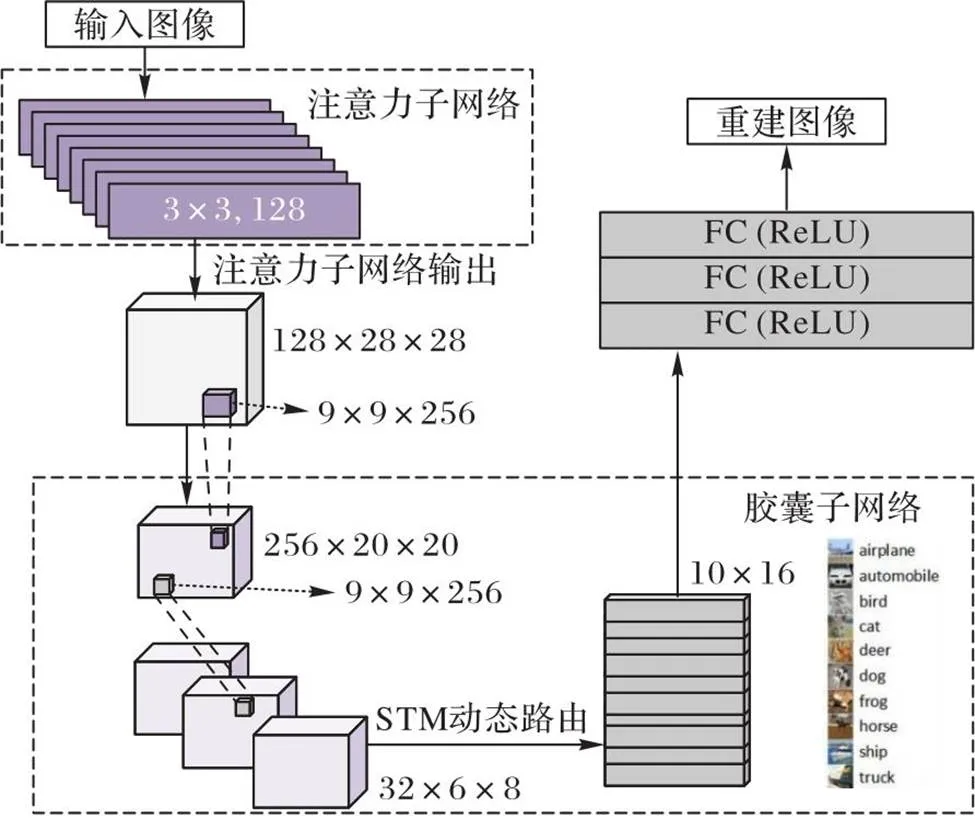
图5 STM-CapsNet结构
本文提出的S-Attention模块结构如图6所示,原理是将输入分别通过全局池化层和1×1的卷积层,输出的注意力图矩阵与原始特征图进行乘积运算,最后的注意力模块将逐渐学习如何将注意力特征图加在原始的特征图上,从而最终得到增加了注意力部分的特征图。该模块包括四个部分:①特征提取;②挤压(Squeeze);③激励(Excitation);④得到注意力特征图。

图6 S-Attention的结构
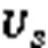
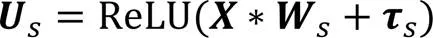
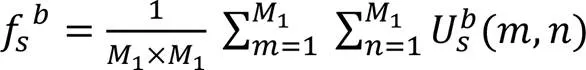
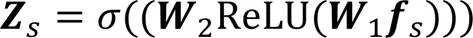

2.2 共享转换矩阵的动态路由算法

与原始胶囊网络中的动态路由算法相比,本文提出的动态路由算法最大的改动就是不再需要为每个低层胶囊学习映射到高层胶囊的转换矩阵,而是通过相近的低层胶囊共享转换矩阵达到减少参数、提高泛化能力的目的,具体的算法细节说明如下:
算法2 共享转换矩阵的动态路由算法。
//依次选择每组中的低层胶囊参与运算
8) end for
9) end for
10) end for
11) end for
//根据耦合系数计算低层胶囊与高层胶囊之间的对数先验概率
15) end for
19) end for
23) end for
24) end for
25) end for
2.3 挤压函数e-squash
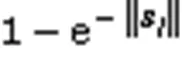
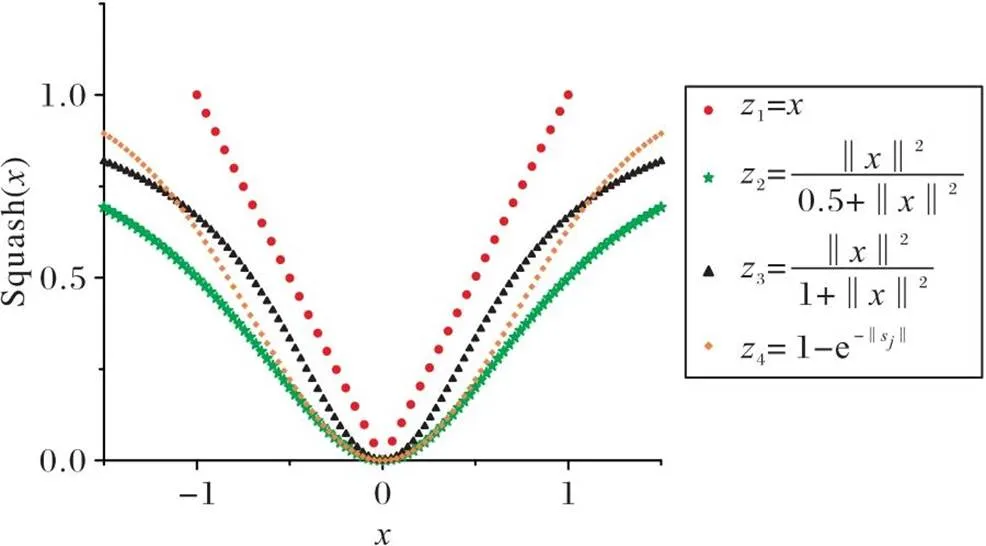
图8 挤压函数对比
3 实验与结果分析
3.1 实验平台与实验数据集
本文实验使用Windows 10(64位)操作系统,具体处理器为i5-1135G7,NVIDIA 3080显卡,16 GB DDR4L内存,CUDA9.0,cuDNN7,使用PyTorch搭建网络模型,Python3.7作为编程语言,在集成开发环境PyCharm上进行模型的训练和测试。
本文实验使用相较于MNIST更复杂的数据集CIFAR10[19]、FashionMNIST[20]、SVHN(Street View House Number)[21]来定性和定量评估所提网络的性能。
CIFAR10是绝大多数胶囊模型验证它们在复杂图像数据集上性能的关键数据集。该数据集包含6×104张真实RGB图像(32×32),其中5×104张用于训练,1×104张用于测试。它们被平均分成10个不相交的类别,每个类别有5×103张训练图像和1×103张测试图像。相较于MNIST数据集,CIFAR10在各方面都更具挑战性,如纹理、形状、色彩空间、背景噪声等。
SVHN数据集是由谷歌街景门牌号码构成的一个真实图像数据集,用于数字识别任务。该数据集中每张图像都包含一个经过裁剪的数字,背景和前景具有较高的自然场景复杂度,给数字识别带来了更大的挑战,也对识别模型提出了更高的要求。
FashionMNIST是一个由Zalando公司发布的图像分类数据集,用于服饰识别任务。该数据集包含10个不同类别的服饰图像,每个类别有6×103张训练图像和1×103张测试图像,共计6×104张训练图像和1×104张测试图像。所有的图像都是28×28的灰度图像。
3.2 实验结果与分析
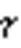

表1 不同路由次数下的准确率对比 单位: %
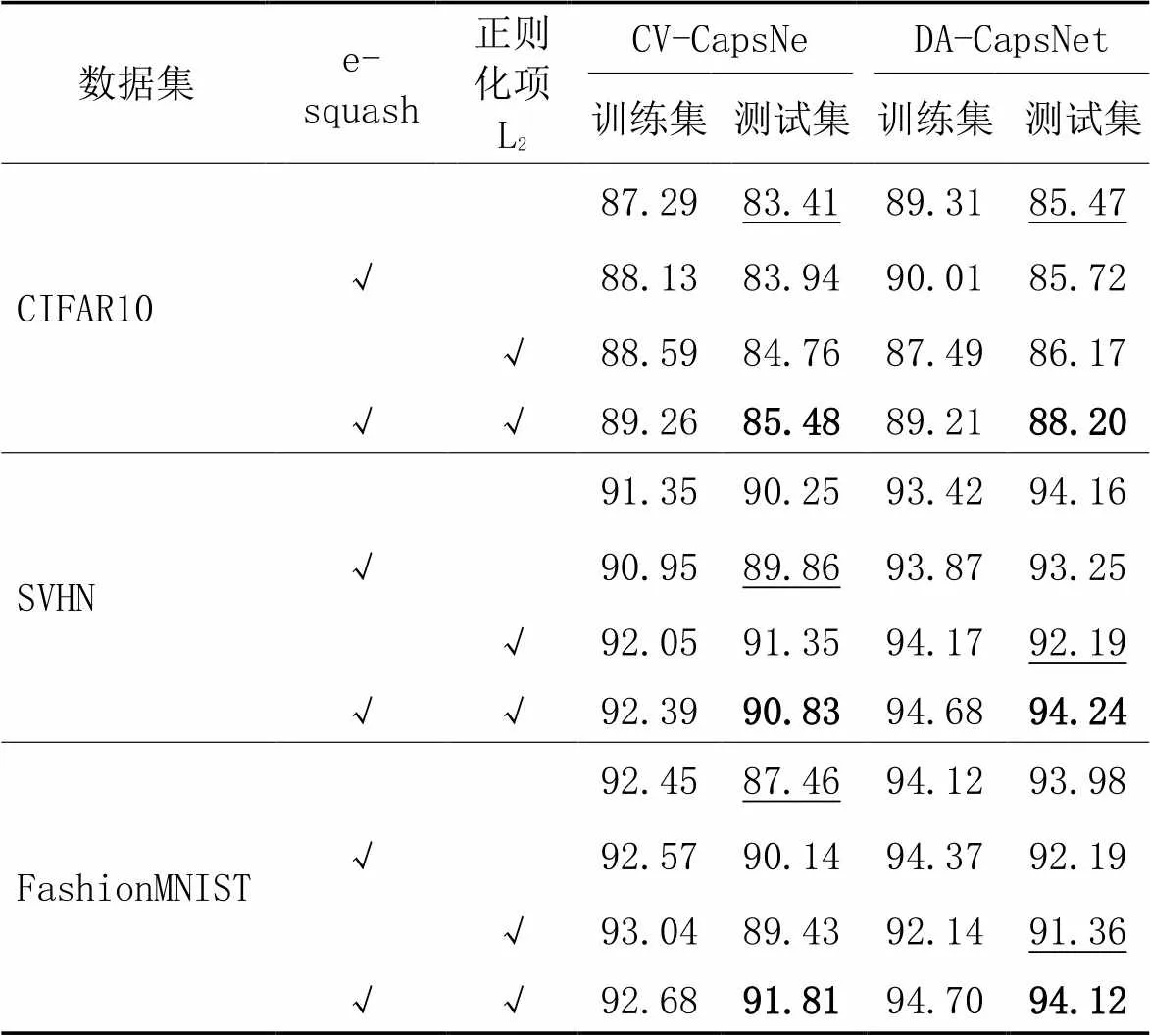
表2 消融实验准确率对比 单位: %
3.2.3不同模型的对比实验
平均参数量的说明:模型在不同的数据集上的参数量各不相同,为了方便表达,取3个数据集上参数量的平均值作为计算负载的指标。

表3 值对模型性能的影响
表4展示了本文模型与7个目前在复杂数据集上表现较好的改进胶囊网络在3个数据集上的分类准确率和平均参数量的对比。与DA-CapsNet[9]相比,本文模型STMCapsNet在数据集FashionMNIST、SVHN上的分类准确率分别高出1.19、0.14个百分点,平均参数量减少了3.46 MB。Zhou等[26]认为在多头自注意力(Mutil-head Self-Attention, MSA)机制中随着Transformer Block的增多,一部分头在堆叠多次特征构建模块后会学习到重复的特征信息,造成计算资源浪费和模型性能的衰退,根本原因在于注意力机制的输出动态取决于输入表示,即学习到的权重信息无法影响模型的学习偏好。这也是本文模型分类准确率高于DA-CapsNet的原因,DA-CapsNet中重复使用注意力模块使模型泛化能力低于本文模型。其次,本文模型对动态路由算法进行了优化,所以参数量低于DA-CapsNet。另外,与Quick-CapsNet[14]、DenseCapsNet[22]等注重降低模型复杂度的网络相比,除了在CIFAR10数据集上的准确率低于DenseCapsNet外,本文模型在其他两个数据集上的分类准确率上有较大的优势。值得说明的是,DenseCapsNet利用很少的参数量依然取得了有竞争力的表现,对比本文模型在参数量方面优势明显,这得益于密集连接充分的特征复用,在之后加深胶囊网络结构的方向上,可以考虑使用密集连接作为传统卷积层的替换。多尺度胶囊网络MS-CapsNet(Multi-Scale Capsule Network)[25]、CV-CapsNet等模型通过各自的改进方法,无论是加深模型的深度,还是优化路由算法,都取得了较高的准确度,虽然本文模型在准确度上与这些模型相比优势不大,但是参数量明显小于这些模型。
实验结果表明,在胶囊网络中引入注意力模块以提高它的特征编码能力是解决胶囊网络在复杂数据集上性能不佳问题的重要手段之一,而通过共享转换矩阵对路由算法进行优化也切实提高了胶囊网络的泛化能力、减少了计算负载。
4 结语
本文在CapsNet的基础上引入注意力机制,并通过共享转换矩阵优化动态路由算法:前者增强了模型的特征提取能力,每一个低层胶囊中能够携带更多与分类任务相关的特征信息;后者则降低了模型的复杂度,增强了模型的泛化能力。为了检验STM-CapsNet的性能,在3个复杂数据集上进行了测试,实验结果表明本文模型在一定程度上提高了网络的性能,超过大部分现有的相关算法。

[1] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6): 84-90.
[2] FAN Y, LI Y, WANG S, et al. Application of YOLOv5 neural network based on improved attention mechanism in recognition of Thangka image defects[J]. KSII Transactions on Internet and Information Systems, 2022, 16(1): 245-265.
[3] CAI J, LI J, LI W, et al. Deep learning model used in text classification[C]// Proceedings of the 2018 15th International Computer Conference on Wavelet Active Media Technology and Information Processing. Piscataway: IEEE, 2018: 123-126.
[4] RATNER A J, EHRENBERG H R, HUSSAIN Z, et al. Learning to compose domain-specific transformations for data augmentation[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 3239-3249.
[5] SABOUR S, FROSST N, HINTON G E. Dynamic routing between capsules[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 3859-3869.
[6] AFSHAR P, MOHAMMADI A, PLATANIOTIS K N. Brain tumor type classification via capsule networks[C]// Proceedings of the 2018 25th IEEE International Conference on Image Processing. Piscataway: IEEE, 2018: 3124-3128.
[7] MUKHOMETZIANOV R, CARRILLO, J. CapsNet comparative performance evaluation for image classification [EB/OL]. [2022-10-15]. https://doi.org/10.48550/arXiv.1805.11195.
[8] WANG K, HE R, WANG S, et al. The efficient-CapsNet model for facial expression recognition[J]. Applied Intelligence, 2023, 53: 16367-16380.
[9] HUANG W, ZHOU F. DA-CapsNet: dual attention mechanism capsule network[J]. Scientific Reports, 2020,10(1): Article No. 11383.
[10] JIA X, LI J, ZHAO B, et al. Res-CapsNet: residual capsule network for data classification[J]. Neural Processing Letters, 2022, 54: 4229-4245.
[11] CHENG X, HE J, HEA J, et al. Cv-CapsNet: complex-valued capsule network[J]. IEEE Transactions on Neural Networks and Learning Systems, 2021, 32(2): 829-839.
[12] MOBINY A, VAN NGUYEN H. Fast CapsNet for lung cancer screening[C]// Proceedings of the 2018 21st International Conference on Medical Image Computing and Computer Assisted Intervention, LNIP 11071. Cham: Springer, 2018: 706-714.
[13] RAJASEGARAN J, JAYASUNDARA V, JAYASEKARA S, et al. DeepCaps: going deeper with capsule networks[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2019: 10728-10737.
[14] SHIRI P, SHARIFI R, BANIASADI A. Quick-CapsNet (QCN): a fast alternative to capsule networks[C]// Proceedings of the 2020 IEEE/ACS 17th International Conference on Computer Systems and Applications. Piscataway: IEEE, 2020: 1-8.
[15] LI X, WANG L.-CapsNet: learning disentangled representation for CapsNet by information bottleneck[J]. Neural Computing and Applications, 2022, 33(1): 1-13.
[16] 尹春勇,何苗.基于改进胶囊网络的文本分类[J].计算机应用,2020,40(9):2525-2530.(YIN C Y, HE M. Text classification based on improved capsule network[J]. Journal of Computer Applications, 2020, 40(9): 2525-2530.)
[17] VASWANI A,SHAZEER N,PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 6000-6010.
[18] 任晓丽,李晓青,闫雨寒,等.注意力机制及其在医学视觉任务中的作用研究[J].影像技术,2023,35(1):76-80.(REN X L, LI X Q, YAN Y H, et al. Study on attention mechanism and its role in medical visual task[J]. Image Technology. 2023, 35(1): 76-80.)
[19] KRIZHEVSKY A, HINTON G E. Learning multiple layers of features from tiny images[J]. Handbook of Systemic Autoimmune Diseases, 2009, 1(4): 1201-1208.
[20] XIAO H, RASUL K, VOLLGRAF R, et al. Fashion-MNIST: a novel image dataset for benchmarking machine learning algorithms [EB/OL]. [2022-10-15]. https://arxiv.org/pdf/1708.07747.pdf.
[21] WEI X, YANG F, WU C. Deep residual networks of residual networks for image super-resolution[C]// Proceedings of the 2017 LIDAR Imaging Detection & Target Recognition, SPIE 10605. Bellingham, WA: SPIE, 2017: 1132-1140.
[22] SUN K, WEN X, YUAN L, et al. Dense capsule networks with fewer parameters[J]. Soft Computing, 2021, 25(10): 6927-6945.
[23] DELIÈGE A, CIOPPA A, DROOGENBROECK M V. HitNet: a neural network with capsules embedded in a Hit-or-Miss layer, extended with hybrid data augmentation and ghost capsules [EB/OL]. [2022-10-15]. https://arxiv.org/pdf/1806.06519.pdf.
[24] ROSARIO V M D, BORIN E, BRETERNITZ M, Jr. The Multi-Lane Capsule Network (MLCN)[J]. IEEE Signal Processing Letters, 2019, 26(7): 1006-1010.
[25] XIANG C, LU Z, ZOU W, et al. MS-CapsNet: a novel multi-scale capsule network[J]. IEEE Signal Processing Letters, 2018, 25(12):1850-1854.
[26] ZHOU D, KANG B, JIN X, et al. DeepViT: towards deeper vision transformer [EB/OL]. [2022-10-15]. https://arxiv.org/pdf/2103.11886.pdf.
Shared transformation matrix capsule network for complex image classification
WEN Kai, XUE Xiao*, JI Juan
(,,401520,)
Concerning the problems of poor classification performance and high computational overhead of Capsule Network (CapsNet) on complex images with background noise information, an improved capsule network model based on attention mechanism and weight sharing was proposed, called Shared Transformation Matrix CapsNet (STM-CapsNet). The proposed model mainly includes the following improvement. 1) An attention module was introduced into the feature extraction layer of CapsNet, which enabled low-level capsules to focus on entity features related to the classification task. 2) Low-level capsules with close spatial positions were divided into several groups, and each group of low-level capsules was mapped to high-level capsules by sharing transformation matrices, which reduced computational overhead and improved model robustness. 3) The L2regularization term was added to margin loss and reconstruction loss to prevent model overfitting. Experimental results on three complex image datasets including CIFAR10, SVHN (Street View House Number) and FashionMNIST show that, the above improvements are effective in enhacing the model performance; when the number of iterations is 3, and the number of shared transformation matrices is 5, the average accuracies of STM-CapsNet are 85.26%, 93.17% and 94.96% respectively, the average parameter amount is 8.29 MB, verifying that STM-CapsNet has better performance compared with the baseline models.
Capsule Network (CapsNet); image classification; attention mechanism; shared transformation matrix; deep learning
1001-9081(2023)11-3411-07
10.11772/j.issn.1001-9081.2022101596
2022⁃10⁃26;
2023⁃04⁃03;
文凯(1972—),男,重庆人,高级工程师,博士,主要研究方向:移动通信、计算机视觉; 薛晓(1996—),男,山西运城人,硕士研究生,主要研究方向:图像分类、目标检测; 季娟(1998—),女,四川广安人,硕士研究生,主要研究方向:图像去噪、图像分割。
TP391.41
A
2023⁃04⁃06。
WEN Kai, born in 1972, Ph. D., senior engineer. His research interests include mobile communication, computer vision.
XUE Xiao, born in 1996, M. S. candidate. His research interests include image classification, target detection.
JI Juan, born in 1998, M. S. candidate. Her research interests include image denoising, image segmentation.
