基于双支网络协作的红外弱小目标检测
2023-11-27王强吴乐天李红王勇王欢杨万扣
王强, 吴乐天, 李红, 王勇, 王欢, 杨万扣*
(1.东南大学 自动化学院, 江苏 南京 210096; 2.东南大学 复杂工程系统测量与控制教育部重点实验室, 江苏 南京 210096;3.江苏自动化研究所, 江苏 连云港 222061; 4.南京理工大学 计算机科学与工程学院, 江苏 南京 210094)
0 引言
当前主流的目标探测系统可分为3类: 基于可见光图像的目标探测、基于热红外图像的目标探测和雷达信号的目标探测系统。其中,热红外探测系统只对目标的温度与本身的材料特性敏感,使得其在3类探测系统中脱颖而出,具有显著优势[1-2]:1)不依赖光照条件,可以全天时工作;2)非主动发射探测波方式,隐蔽性好;3)穿透能力强,基本不受环境因素如灰尘、云层等的影响,可以更好地识别虚假的伪装目标。上述优势使得基于热红外图像的目标探测系统成为传统基于可见光图像与基于雷达信号的目标探测系统的有效补充。
鉴于此,红外弱小目标检测具有广泛的应用,常用于军事领域,例如跟踪、防御及预警等[3]。除了军事领域以外,它在其他多个领域都有着应用价值,如在医学成像病理分析、海上救援等任务中,红外弱小目标检测技术有助于获取很多用信息。因为检测方法的效果极大地影响这些应用系统的性能,所以检测的准确性至关重要。
然而,红外弱小目标检测面临诸多挑战。红外图像一般由背景、目标和噪声3部分组成。一方面,红外图像的信杂比低,由于距离远和大气对红外辐射的影响,红外弱小目标信号通常非常微弱,且与背景差异不明显,极易淹没在背景中;另一方面,红外弱小目标尺寸非常小、缺少结构性特征[3-7],增加了在实际应用中检测红外弱小目标的难度。
深度学习方法极大地推动了红外图像处理领域的发展,包括红外检测任务。通常红外弱小目标检测方法分为直接目标检测方法和图像语义分割方法。娄康[8]提出一种基于生成式对抗神经网络的红外目标检测算法,并通过Gabor核函数实现对红外图像降噪处理。黄乐弘[9]针对空中红外目标图像的固有特点,在YOLOv3模型[10]的基础上改进了边缘损失函数,从而提高了检测定位精度。杨其利等[11]通过在网络中增加递归和残差模块来提升检测效果。在红外弱小目标检测领域中,若直接使用通用的目标检测或语义分割网络,则检测效果不理想,原因有:
1)红外弱小目标的特点[12]:
①目标信号弱。目标和背景之间的对比度很小,导致目标容易被背景淹没而抹去。
②目标尺寸小。目标的尺寸很小,通常低于9×9个像素,因此其结构特征很少。深度卷积神经网络(CNN)通常都是采用卷积、池化等方法来提取目标的特征,通过堆叠多个卷积层、池化层或其他的下采样层来提取浅层和深层特征,然后根据特征图进行上采样恢复。在此过程中图像的分辨率会降低,红外弱小目标特征几乎可以忽略不计,甚至完全消失,容易导致下采样过程中的小目标丢失,因此上采样也无法恢复。在训练过程中,网络在靠后的特征层中失去了小物体的特征信息,因此会造成检测性能的下降。
2)扩大网络感受野带来的问题。原因1进一步导致红外弱小目标的结构特征非常少,局部来看,弱小目标与噪声和背景干扰极为相似,需要借助全局分析来区分。在深度学习中表现为需要更大的感受野,在深度卷积网络中,一般通过不断降低特征图像的分辨率来提高感受野,然而,这一过程一定程度降低了目标定位精度。
3)占空比不均衡问题。红外图像中,目标少且稀疏,绝大部分是背景区域,目标和背景的占空比极不均衡,导致一般语义分割网络模型会倾向于关注背景像素识别为目标像素的错误,忽略目标像素识别为背景像素的错误,导致目标欠分割,甚至丢失。
此外,已有的基于图像语义分割的红外弱小目标检测方法只设计了一个网络,难以同时保持低虚警率和漏检率。
本文针对红外弱小目标图像特点,提出一种基于两支网络协作的红外弱小目标检测模型(DualNet模型)。DualNet模型包含两个分别针对红外弱小目标检测虚警率和漏检率任务的子网络,通过对两个子网络的结果进行融合输出,进一步提高红外弱小目标检测的准确性。
1 图像语义分割相关工作
图像语义分割任务是输入一个图像(多通道或单通道),然后输出与源图像分辨率相同的图像,每个像素点带有分类标签。图像语义分割的基本算法思想是给出一张图像I,将问题转化为函数求解,从I映射到掩码Mask,分割出物体的轮廓。
1.1 基于图像块的分割方法
针对一个像素,使用该像素为中心的邻域图像块作为输入用于神经网络的训练和预测[12-14],其缺点有:
1)占用内存量大。以图像块的大小为11×11为例,每次滑动窗口将得到一个分类结果,随着滑动次数的增加,消耗的存储量将不断上升。
2)冗余计算。相邻的图像块只在边缘部分存在差别,因此针对每个图像块进行计算会有大量重复,导致计算效率较低。
3)图像块的大小限制了感受野大小。以全局观来看待图像较局部图像块来判别分类更加准确,因此图像块的大小限制了分类的性能。
1.2 基于全卷积网络的图像分割
全卷积网络(FCN)用全连接层得到特征向量,再进行判别分类。FCN的输入不受尺寸限制,将分类网络的全连接层用卷积层替换,对最后一个特征图进行反卷积操作。因此网络输出的图像分辨率与输入图像保持一致,将每个像素当成一个样本进行训练,从抽象的特征图中得到判别结果,同时保留输入图像中的空间结构信息。最后,在网络输出的特征图上实现像素级的分类操作,得到输出结果。经典CNN结构和FCN结构如图1和图2所示。

图1 经典CNN结构Fig.1 Classic CNN network structure

图2 FCN结构Fig.2 FCN simulation structure
1.3 基于U型网络(U-net)的图像分割
U-net采用对称网络结构[15-16],形状如U形。下采样过程称为编码器,它用来提取特征,得到深层和浅层特征,上采样过程称为解码器,它结合了浅层相同分辨率的特征图和深层信息,跨联之后作为上采样过程的输入,因此逐级提升图像精度。与FCN网络特征拼接不同的是,U-net按照通道的维度进行拼接,在同样大小的分辨率处形成更厚的特征。FCN融合时将对应像素点相加,特征维度不变。U-net 结构如图3所示。

图3 U-net结构Fig.3 U-net simulation architecture
2 基于DualNet协作的红外弱小目标检测方法
由于第1节中3类网络模型包含较多的下采样结构,导致网络用于红外弱小目标检测的性能不佳。网络设计中一个关键性的挑战是在红外图像的漏检率和虚警率之间找到一种平衡,尽可能地降低二者。然而这二者在一定程度上是对立的关系,通常在实验中是采取相反的策略去减小二者的大小,正如传统的图像处理方法的最后一步是选取合适的阈值来进行图像的二值化:为了降低虚警率,增大阈值;为了降低漏检率,减小阈值。针对CNN框架固化图像全局阈值的缺陷,本文将整个红外弱小目标检测任务划分成两个子任务来进行,提出了一种兼顾漏检和虚警的图像分割网络DualNet。
2.1 网络结构
传统深度CNN方法使用单个网络同时降低漏检率和虚警率。与传统的网络训练不一样,本文将整个图像语义分割任务分成两个子任务,即采用两个子网络来完成图像语义分割任务。子网络分支1的目的是降低目标的漏检率,即学习较低的阈值,使网络具有较高的召回率,子网络分支2的目的是在降低目标的虚警率,即学习较高的阈值,使网络具有较高的精确率,最后采取一定的比例将两个网络输出的结果融合得到分割结果。DualNet的整体结构设计如图4 所示。

图4 DualNet结构Fig.4 DualNet architecture
DualNet分为两个子网络,红色框标记为子网络分支1,绿色框标记为子网络分支2,两个网络的输入均为图像I,分别经过多个模块得到网络分支1的输出为S1,网络分支2的输出为S2,网络最终的分割结果为S。S由S1和S2经过加权融合得到。为了更清晰地了解DualNet结构设计,图5和图6分别显示了网络分支1和网络分支2的详细结构,说明了各模块的选取原因,从理论上阐明了网络设计的合理性。
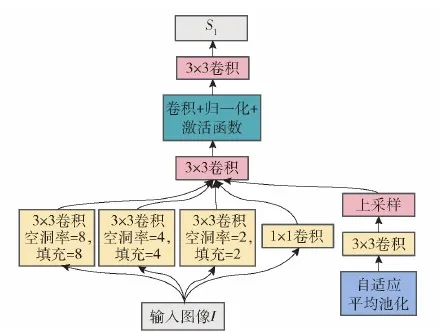
图5 网络分支1结构Fig.5 Architecture of SubNetwork 1
2.2 网络分支1结构

图6 网络分支2结构Fig.6 Thearchitecture of SubNetwork 2
网络分支1设计原则包含两点:1)为了避免池化模块可能丢失小目标,本文舍弃了池化模块与标准卷积模块,而是使用了空洞卷积,不仅保证了特征图的空间分辨率,同时也保证了图像的感受野[17-20];2)由于空洞卷积可能造成“棋盘”效应,网络添加了空洞空间金字塔池化(ASPP)模块[19],通过使用不同空洞率的卷积来提取不同感受野下的信息,高效利用了整张图片信息。
记输入图像标记为I,分割结果标记为S1,网络分支1对应的函数为F1,则网络输入到输出之间的映射记为
F1(I)=S1
(1)
为了实现降低目标的漏检率的目的,本文基于平滑的绝对值损失(Smooth L1),构建网络分支1的损失函数:
(2)
MD1=SmoothL1Loss(S1,G)·G
(3)
FA1=SmoothL1Loss(S1,G)·(1-G)
(4)
Loss1=λ1MD1+FA1
(5)
式中:MD1和FA1分别代表网络分支1的漏检率和虚警率;G代表输入图像的真值;λ1是MD1的权重参数。
2.3 网络分支2结构
语义分割模型大多是类似于U-net这样的编码器——解码器形式[15],先进行下采样,再上采样到与原图一样的尺寸。设计思想包含3点:1)为了避免下采样过程中小目标消失,防止上采样过程中无法恢复,采用空间金字塔池化(SPP)模块[21-23]来构造空间池化层,使特征图的浅层特征和深层特征得到有效融合;2)依据经典的编码器—解码器架构,构建对称网络结构,将对应层的特征图按通道级联,充分的结合低层级精确的位置信息与高层级的高语义信息[22];3)标准卷积无法精确的学习不规则形状的目标特征,因此在输出部分舍弃了标准卷积,采用可形变卷积,通过学习偏置量使卷积的区域实现变形,从而挖掘更为准确的目标的形状和尺寸信息,而标准卷积的卷积核则无法做到这一点[24-27]。
网络分支2设计模块如下:
1)通道注意力模块[28],特征图的尺寸由C×H×W变换为C×1×1,其中C、H、W分别代表特征图的通道数、高度和宽度。通过卷积激活函数等运算得到对应掩码,与原特征图按通道相乘,从而分配给了每个通道不同的权重。
2)空间注意力模块[29],与通道注意力模块类似,特征图的尺寸由C×H×W变换为1×H×W,经过激活函数后添加到原始的特征图中,对原特征图的每个像素点分配了不同的权重。
3)将通道注意力与空间注意力模块并联,目的是得到具有更强语义信息的特征图。在编码解码的过程中,每个块后面均添加通道—空间注意力模块,从而提高了网络提取图片内部语义信息的能力,使得分割的结果更加精确。
4)ASPP模块[21],通过将不同尺寸的池化层并联,有效地提取了图像的多尺度信息。ASPP模块将图像的局部特征和全局特征高效融合,有效地提取了特征图的上下文信息。
5)可形变卷积[24],可形变卷积通过对特征图的每个位置学习一个偏移量,使卷积核具有变形的效果。
记输入图像标记为I,分割结果标记为S2,网络分支2对应的函数为F2,输入图像到输出图像之间的变换记为
F2(I)=S2
(6)
同样地网络分支2为了达到降低目标的虚警率的目的,本文也基于Smooth L1,构建网络分支2的损失函数,如式(7)~式(9)所示:
MD2=SmoothL1Loss(S2,G)·G
(7)
FA2=SmoothL1Loss(S2,G)·(1-G)
(8)
Loss2=MD2+λ2FA2
(9)
式中:MD2和FA2分别表示网络分支2分支的漏检率和虚警率;λ2为FA2的权重参数。
2.4 两支网络融合
两个网络独立训练,即分别按照各自定义的损失函数完成训练,获得各自网络的最优参数。为了使二者在整个分割任务中有机结合起来,需要设计让网络信息在二者之间协作合作,统一地抵近真实结果,采用式(10)融合二者分割结果:
S=αS1+βS2
(10)
式中:α和β为超参数,根据实验效果取α=0.1,β=0.9最佳。
上述融合策略将网络分支1和2的结果作线性加权,虽然简单,但却能充分利用两支网络的互补优势。从表2实验中的可视化结果观察发现,网络分支2的弱小目标识别能力(识别真假目标)强于网络分支1,虽然会存在目标的欠分割,例如目标有3个像素,只分割出1个,但较少出现虚假目标;而网络分支1的定位能力(检测定位真目标)则强于网络分支2,即网络分支1虽容易检测出了一些虚假目标,但真实目标都能全部检测出来,并且分割较为完整。为此,加权融合策略可以一定程度上避免网络分支2的目标欠分割、抑制网络分支1输出的虚假目标。
3 红外弱小目标检测结果与分析
3.1 红外弱小目标检测数据集
由于缺少红外弱小目标检测领域的标准数据集,本文在仿真合成的红外图像数据集上验证算法的有效性。该数据集包括2类包含弱小目标的数据集,分别记为All Seqs和Single,其中All Seqs数据集包含504张图像,Single数据集共有100张图像。这里对数据集进行了扩充,从原本的图像中随机抽样128×128的图像块作为输入,依此将训练集中图像的数量扩充到10 000幅图像。相关合成用于训练的红外图像部分样本如图7所示。

图7 红外弱小目标检测数据集中的典型训练样本Fig.7 Samples of the training set
3.2 评价标准
由于本文将弱小目标检测看成目标分割问题,目的是将图像分为目标和背景,采用二分类模型的评价标准,即精度Precision、召回率Recall和F1测量F1-measure:
(11)
(12)
(13)
式中:TP、FP和FN分别为正确检测出的目标像素个数、虚检的像素个数和漏检的像素个数。Precision被定义为被正确预测的目标数据占所有预测为目标数据的比例;Recall被定义为被正确预测的目标像素占全部目标像素的比例。由于Precision和Recall之间存在一定的矛盾性,单独看Precision和Recall这两个指标均有局限性,衡量目标分割算法的有效性应该注重F1-measure的大小。
3.3 实验设置
本文实验硬件环境为8 GB RAM、1.8 GHz Intel i7 CPU和Tesla P40 GPU;软件环境为Ubuntu 18.04系统、Python语言和Pytorch深度学习开发软件框架。实验相关参数设置为:λ1=100,λ2=10,α=0.1,β=0.9;学习率每10次迭代降低20%,一共训练30个周期。两个网络分支独立训练,分别按照各自定义的损失函数完成训练,获得各自网络的最优参数后进行融合。
3.4 实验结果与分析
本文实验与当前基于深度学习的优势方法进行对比,包含FCN-RSTN[30]、cGAN[31]、U-net[15]、DeepLab-v3[19],实验结果如表1所示。表1显示了在All Seqs和Single数据集上Recall、Precision以及F1-measure指标的大小,三者的数值均为越大越好,通过F1-measure平衡了Precision和Recall单一度量的局限性。由表1可以看出,本文DualNet方法在两个数据集上均获得了最高的F1-measure值,在保证召回率在可接受的条件下有着较高的精确率,这显示了DualNet方法具有更好的检测效果,在像素级别使得漏检率和虚警率达到了最优的平衡。
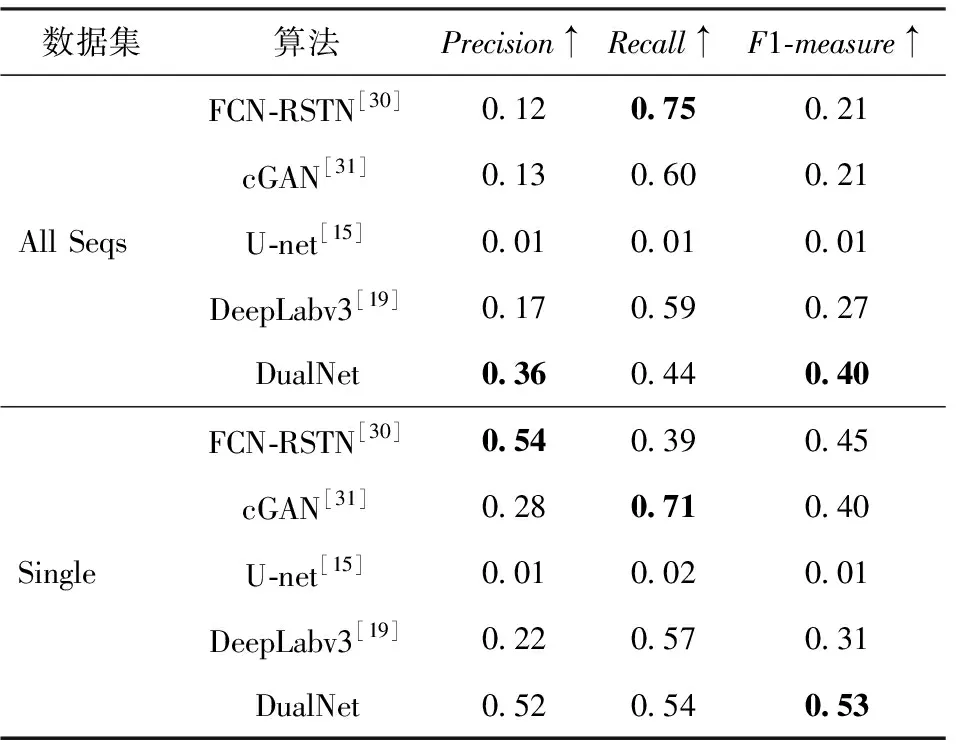
表1 不同方法的结果对比Table 1 Experimental results using different methods
DualNet方法的检测效果见表2,表2每一行为一组,从左往右分别为输入红外图像、真实标签图、网络分支1检测结果、网络分支2检测结果和最终融合结果。由表2可以看出,网络分支1为了达到漏检率较低的要求,会将部分背景噪声当作目标分割出来,继而提高了目标的召回率,但同时也增加了虚警率。网络分支2为了达到降低虚警率目的,导致其输出的结果中目标对比度降低,没有网络分支1中目标与背景的对比度明显,最后通过加权融合这一协作操作较好地缓解了两个网络的各自缺点,从而提升了整体网络的精度。
本文实验分析了DualNet各个模块的影响,DualNet各个模块的消融实验如表3所示,包括空洞卷积Dilated-Conv、ASPP模块、PPM模块、注意力模块scSE以及可形变卷积DCNv2。根据实验结果:在网络分支2不变的情况下,网络分支1添加ASPP模块相较于直接使用空洞卷积时,F1-measure值更高,分割效果更好;在网络分支1不变的情况下,网络分支2添加SPP模块要优于添加PPM模块[32];在网络编码模块中添加注意力机制达到了最高的分割精度,针对本文实验中的红外图像数据集,将可形变卷积DCNv2应用于网络输出部分无明显的提升效果。

表2 DualNet方法的分割效果

表3 DualNet方法的消融实验
进一步分析可知,空洞卷积是在不增加网络参数的前提下用于扩大卷积操作的感受野。SPP模块用于多尺度特征提取,ASPP模块则是将空洞卷积与SPP模块相结合,同时扩大感受野和提取多尺度特征。在本文的模型中,网络分支1专注于避免漏检,需要局部信息来尽可能地检测和定位目标,因此其感受野不需要太大;而网络分支2专注于避免虚警,需要较大的全局上下文信息来鉴别目标,因此需要较大的感受野(使用空洞卷积)。此外,无论网络分支1和网络分支2,都需要在各自的感受野范围内提取多尺度信息,故两支网络都需要采用SPP(或ASPP)模块用于提取多尺度特征。
本文分析了式(10)中权重参数α和β对DualNet性能影响,对比结果如表4所示。通过合理分配权重,可以获得最佳的融合效果。表4中,根据α和β的变化可以看出网络分支1的分割结果所占的比例较低,网络分支2的分割结果所占的比例较高时,分割的精度更高。因为网络分支2旨在降低图像的虚警率,用它的分割结果去定位网络分支1的分割结果,即二者比例分配为2高1低时,效果较好。

表4 不同权重对DualNet方法影响Table 4 Influence of α and β on DualNet method
本文对比了配置不同损失函数DualNet的性能,如表5所示,其中包括Focal Loss、L1 Loss、L2 Loss、Smooth L1 Loss和Balanced L1 Loss。表5中,实验比较了5种损失函数的分割效果,其中目标检测中多分类场景中使用的Focal Loss[33-34]、L1 Loss和Balanced L1 Loss在本文实验中没有效果,这可能与损失函数中的参数选取有关。根据表5中数据比较,实验最终选取了Smooth L1 Loss函数。其中损失函数公式定义为
L1 Loss:loss=abs(pred-target)
(14)
(15)
Balanced L1 Loss:

(16)
(17)
Focal Loss:loss=-(1-p)γlog2(p)
(18)
式中:pred和x为预测值;target为标签值;p为预测类别概率;其余为网络训练中可调节的参数。

表5 不同损失函数的DualNet方法效果Table 5 Influence of different loss functions on DualNet method
表6给出了参数λ1和λ2在选取不同值时的性能比较结果。实验表明取λ1=100和λ2=10时,模型在两个数据集上均达到最好性能。
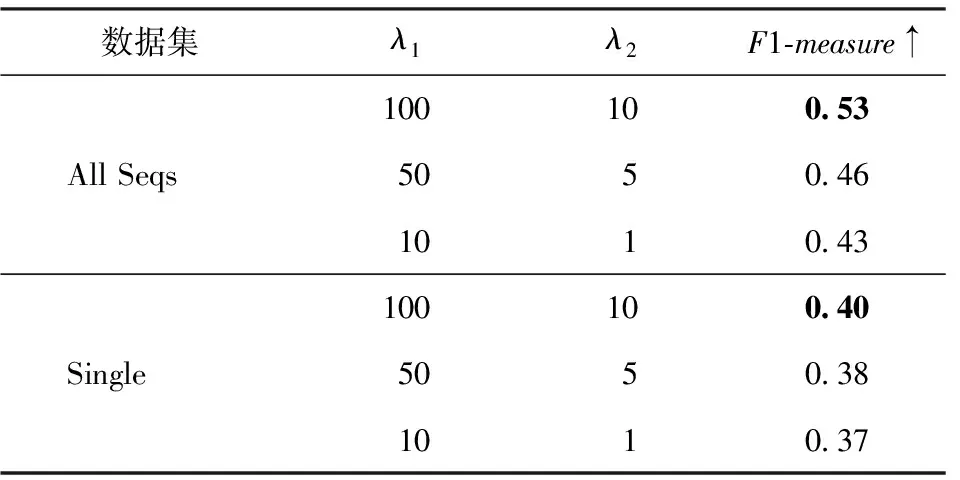
表6 参数λ1和λ2的不同选取对性能的影响Table 6 Influence of different values of λ1 and λ2
DualNet的模型大小以及在GPU上对单张图像的检测速度如表7所示。表7显示DualNet模型非常小,速度很快,利于部署。
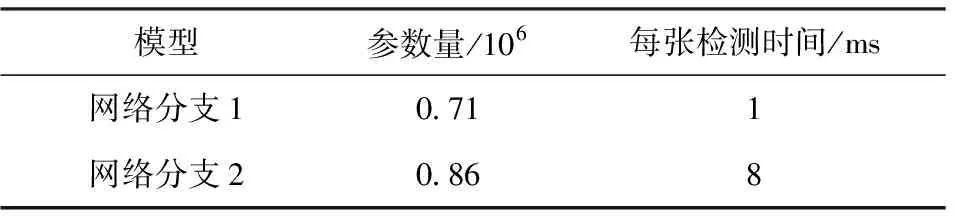
表7 DualNet模型的参数量以及检测速度Table 7 Speed and model size of DualNet model
表2直观显示了DualNet的侧重点,网络分支1旨在降低图像的漏检率,所以为了防止目标被滤去,网络分支1的输出结果中会包含少许背景噪声,相当于图像进行二值化分割时选取了较低的阈值;而网络分支2旨在降低图像的虚警率,所以为了防止将背景噪声误认为是目标,网络分支2的输出结果会尽可能地减少虚警,因此可能会导致目标欠分割,相当于图像二值化分割时选取了较高的阈值。最终融合两支网络结果时,通过调整合适的融合比例,达到较高的融合效果。即:网络分支2关注虚警的消除,给出的结果提供了较高的目标定位准确性,但也会存在目标的欠分割问题;网络分支1 避免漏检的产生,给出的结果中提供了目标较为完整的分割结果,但会存在一些虚警;融合模块将两者很好的结合,能在定位准确的基础上进一步保证目标分割的准确性,达到更好的检测效果。图8 表明两支网络的损失函数都随着训练轮数的增加而稳定地降低,最终都达到收敛。
由表1可以看出,直接使用通用的目标检测网络和语义分割网络来实现红外弱小目标检测任务,效果往往不佳,而经过设计后的DualNet方法提升了红外弱小目标检测的准确性。
表3显示了本实验的模块设计对分割效果的影响,根据实验数据,最终的DualNet结构设计为:网络分支1:ASPP结构+空洞卷积;网络分支2:参考U-net结构实现特征图跨联+SPP结构+注意力机制。
表4显示了实验中不同融合方式对分割效果的影响,根据表3中数据,可以得出网络分支1的比重较低,网络分支2的比重较高时,融合的效果较好。需要注意的是,网络分支1权重比较低并不意味着网络分支1没有意义。当进一步降低网络分支1权重,提高网络分支2权重,即权重系数组合为(0.05,0.95)时,模型处理效果反而比系数组合(0.1,0.9)更差,在AllSeqs和Single数据集上F1-measure分别从0.4降到0.38,以及从0.53降低到0.51,由此可见,网络分支1是有作用、有意义的。
表5显示了实验中配置不同损失函数对分割效果的影响,根据表5中数据,复杂设计的损失函数对红外弱小目标检测任务无甚效果,相反选取较为简单的距离损失函数L2 Loss和Smooth L1 Loss函数效果更好,其中Smooth L1 Loss用于网络的学习性能更为显著。此外,对于All Seqs和Single两类数据集,DualNet对于Single数据集中红外图像样本更有效果,而All Seqs数据集中背景噪声与目标更为相似,其网络性能指标不如Single数据集。
最后,为了进一步验证本文提出的新模型在真实数据集上的泛化能力,在近期公开发布的真实数据集SIRST上进行测试。测试遵循该数据集评测指标,即交并比IoU、检测率Pd和漏检率Fa,这3个指标的计算方式分别为
(19)
(20)
(21)
式中:pre为预测的二值标签图;Label是真实的二值标签图;Tcorrect为检测正确的目标的数量;Tall为所有目标的数量;Pfalse为检测错误的目标的数量;Pall为整张图片的像素大小。判断检测是否正确的方法是计算预测的目标的中心点坐标与真实的目标的中心点坐标之间的像素偏差小于阈值(2个像素)。
将所提模型与已发表的在该数据集上测试过的基于顶帽变换(Top-Hat)方法、基于最大中值滤波(Max-Median)方法、基于加权增强局部对比度度量(WSLCM)方法、基于三层窗口的局部对比度度量(TLLCM)方法、基于红外块分解(IPI)方法、基于非凸秩近似最小化(NRAM)方法、基于重加权块图像张量(RIPT)方法、基于张量核范数部分和(PSTNN)方法、基于多子空间学习和时空块张量模型(MSLSTIPT)方法、基于非对称上下文调制(ACM)方法、基于漏检与虚警的生成对抗网络(MDvsFA-cGAN)方法这11种方法进行了比较。具体试验步骤如下,先使用10 000幅仿真数据训练本文模型得到预训练模型,然后使用SIRST的训练集对模型进行微调10个epoch,最后使用其测试集测试模型。从表8中可以看出,DualNet方法的IoU指标排第1、Pd指标排第1、Fa指标排第3。综合起来看,本文方法的性能指标要明显高于多个代表性的传统方法,也高于两个基于深度卷积网络的弱小目标检测方法ACM和MDvsFA-cGAN。同时,表9给出了DualNet、MDvsFA-cGAN和ACM方法对SIRST数据集中4幅代表性图像的可视化检测效果,不难发现,较MDvsFA-cGAN和ACM方法,DualNet方法的结果更接近真实标签图。

表8 SIRST数据集上泛化性能测试Table 8 Generalization capability tests over SIRST dataset

表9 可视化检测结果比较
4 结论
本文分析了通用深度CNN直接迁移到红外弱小目标检测任务的局限性,指出红外弱小目标检测任务的难点。针对单个网络对红外弱小目标特征提取的有限性,基于通用的目标检测网络和语义分割网络模型,提出DualNet模型。与以往单个网络模型不同,DualNet将整个任务划分成两个子任务:一个网络用来学习低阈值分割,负责降低漏检率;另一个网络用来学习高阈值分割,负责降低虚警率。最后将两个网络的输出结果进行加权融合,以取得最佳的分割效果。得出主要结论如下:
1)本文通过将红外弱小目标检测任务划分为两个子任务,有效地兼顾了红外弱小目标的漏检率和虚警率。
2)相比于传统方法和通用语义分割检测方法,本文方法获得的检测结果更准确、鲁棒性更强;在自建数据集上,相比于FCN、DeepLabv3、cGAN以及U-net语义分割网络模型,本文方法的F1-measure提高了8%;在SIRST公开数据集上,本文方法的检测性能也显著超过了基于深度学习的红外目标检测模型ACM、MDvsFA-cGAN和多个经典的非深度学习红外弱小目标检测方法。
3)在红外弱小目标检测任务中,本文方法能有效的提高目标检测的精度。
