基于机器学习算法的超重/肥胖患者减重效果预测模型构建及影响因素分析▲
2023-11-07赵冉冉邓志杰杨榕桂黄丽婵孙桂丽
赵冉冉 邓志杰 杨榕桂 黄丽婵 孙桂丽
[1 南宁市第二人民医院(广西医科大学第三附属医院)临床营养科,广西南宁市 530031; 2 俄亥俄州立大学教育和人类生态学院营养系,美国哥伦布市 43210]
WHO报告,2020年的全球肥胖人口较1975年增加两倍[1],中国肥胖人口目前位居全球第一[2]。与肥胖相关的疾病如2型糖尿病(type 2 diabetes mellitus,T2DM)、心脑血管疾病等的发病率也随之增加,这不仅对人们的健康造成巨大威胁,也给社会带来沉重的医疗负担[3]。因此,预防超重/肥胖,以及降低超重/肥胖患者的体重是亟待解决的公共卫生问题。全生活方式管理是一种较为经济、方便的减重方式,主要包括饮食管理、行为干预和体育锻炼。饮食管理在临床上又被称为医学营养管理,是一种有效的减重方式[4],但其减重效果受环境、个体肥胖程度、遗传及疾病状态等多种因素的影响[5-8]。建立超重/肥胖患者减重效果的预测模型,寻找影响减重效果的重要因素,并针对相关影响因素采取有效措施,对于提高超重/肥胖患者的减重效果,改善其健康状况具有重要意义。
机器学习是人工智能的分支,也是人工智能的核心之一。随着计算机技术和数据科学的不断发展,机器学习算法已被广泛应用于医疗领域,在疾病的诊断、治疗和预后评估中发挥越来越重要的作用[9],但鲜有机器学习算法在减重效果评估领域中的研究报告。本研究应用Logistic回归、K近邻、决策树、随机森林、支持向量机和朴素贝叶斯 6种机器学习算法模型预测超重/肥胖患者的减重效果,探索人工智能技术在减重效果评估领域中的应用价值和可能性,并分析与超重/肥胖患者减重效果密切相关的因素,为提高患者减重效果提供参考。
1 资料与方法
1.1 临床资料 回顾性分析2018年9月至2022年9月在南宁市第二人民医院临床营养科接受减重干预的680例超重/肥胖患者的临床资料。纳入标准:年龄≥18岁;体质指数≥24 kg/m2,且男性腰围≥85 cm、女性腰围≥80 cm。排除标准:妊娠期或哺乳期妇女;合并严重的肝、肾、消化道、心脑血管疾病,以及糖尿病等内分泌代谢性疾病的患者;合并传染性疾病、精神性疾病和恶性肿瘤等慢性消耗性疾病的患者。680例超重/肥胖患者中男性31例、女性649例,年龄18~64(32.93±6.07)岁。所有研究对象对本研究知情并签署知情同意书。本研究已获得南宁市第二人民医院医学伦理委员会批准(批准号:20190101)。
1.2 建立数据集 本研究以一般信息(性别和年龄)、疾病诊断、减重时长、干预前体格测量指标、干预前体成分分析指标等80个指标作为基本特征变量,以减重效果作为结局变量,建立数据集。根据《中国超重/肥胖医学营养治疗指南(2021)》[4],将体重下降≥5%判定为减重效果良好,体重下降<5%判定为减重效果不佳。其中,T2DM和多囊卵巢综合征的诊断分别参照《中国2型糖尿病指南(2020年版)》[10]和《多囊卵巢综合征诊断:WS330-2011》[11]中的相关标准;采用人体成分分析仪(InBody公司,型号:InBody 770)检测人体成分分析指标。
1.3 筛选特征变量 采用基于随机森林算法的10折交叉验证递归特征消除算法筛选特征变量。递归特征消除是根据模型的准确率选择特征变量的递归过程。在每次重采样迭代中,计算每一种变量的权重值,消除权重值绝对值最小的变量,对剔除后的特征集进行10折交叉验证,并计算随机森林模型的性能指标(准确率),重复递归过程。选择模型性能最优的特征集合作为特征变量,然后采用R语言(Version 4.0.3)caret包的nearZeroVar函数筛选接近零方差的变量并予以删除。本研究中,剔除接近零方差的变量(性别、合并脂肪肝、合并高血压和合并高脂血症等)后,最终纳入38个特征变量(模型准确率最高的特征集合,准确率为0.873),见图1。
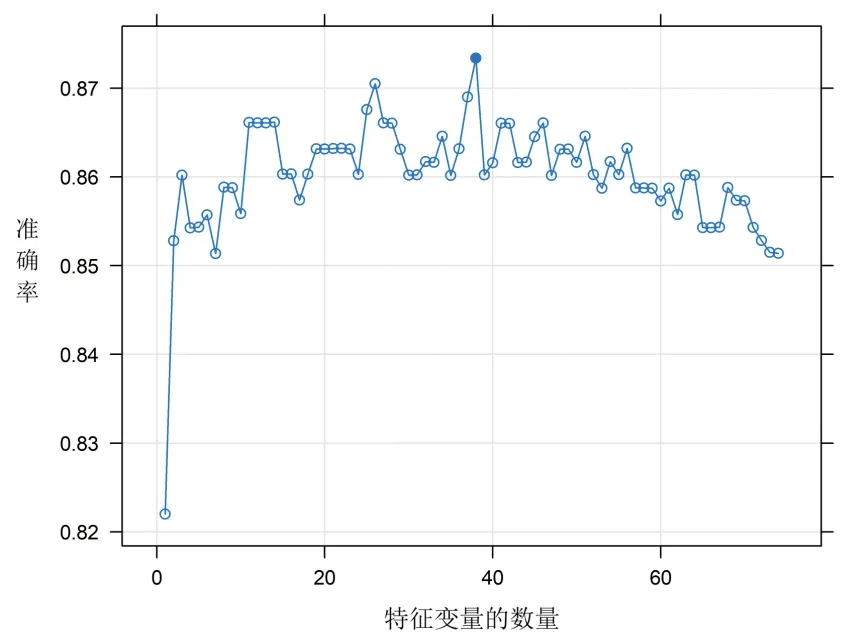
图1 基于10折交叉验证递归特征消除算法筛选的特征变量图
1.4 机器学习算法预测模型的构建和评价
1.4.1 数据切分:采用分层随机抽样法(以减重效果为分层标准),将680例患者按近似7 ∶3的比例分为训练集(475例)和验证集(205例)。
1.4.2 建模:在训练集中,以减重效果为因变量,以筛选得到的38个特征变量为自变量,分别应用Logistic回归、K近邻、决策树、随机森林、支持向量机和朴素贝叶斯6种机器学习算法构建预测模型。Logistic回归、K近邻和支持向量机在建模前将所有连续型变量进行Z-score标准化。对于有参算法(K近邻、决策树、随机森林、支持向量机和朴素贝叶斯),采用重复10次的5折交叉验证和网格搜索对训练集的数据进行优化,使用优化后的数据构建模型;对于无参算法(Logistic回归),则直接使用训练集的数据构建模型。
1.4.3 模型评价:把验证集数据分别导入6个预测模型,根据受试者工作特征(receiver operating characteristic,ROC)曲线下面积(area under the curve,AUC) 、准确率、精确率、召回率和F1分数评价模型的预测效能。
1.4.4 特征变量重要性分析:自变量的重要性可以反映自变量与因变量的关系,有助于解释每个自变量对预测模型预测效能的贡献大小。为了评估每个预测模型中特征变量的相对重要性,本研究采用R语言(Version 4.0.3)caret包的varImp函数计算特征变量的重要性,并采用R语言(Version 4.0.3)tidyverse包对每个预测模型中重要性排名前10的特征变量进行可视化。
1.5 统计学分析 采用R语言(Version 4.0.3)进行统计学分析和构建机器学习算法预测模型。正态分布的计量资料以(x±s)表示,组间比较采用两独立样本t检验;非正态分布的计量资料以[M(P25,P75)]表示,组间比较采用Wilcoxon秩和检验。计数资料以例数表示,组间比较用χ2检验。采用Delong检验比较不同预测模型的AUC。以P<0.05为差异具有统计学意义。
2 结 果
2.1 训练集和验证集的结局变量、特征变量的比较 训练集和验证集的结局变量,以及38个特征变量差异无统计学意义(P<0.05),说明两个数据集的变量分配均衡,见表1。
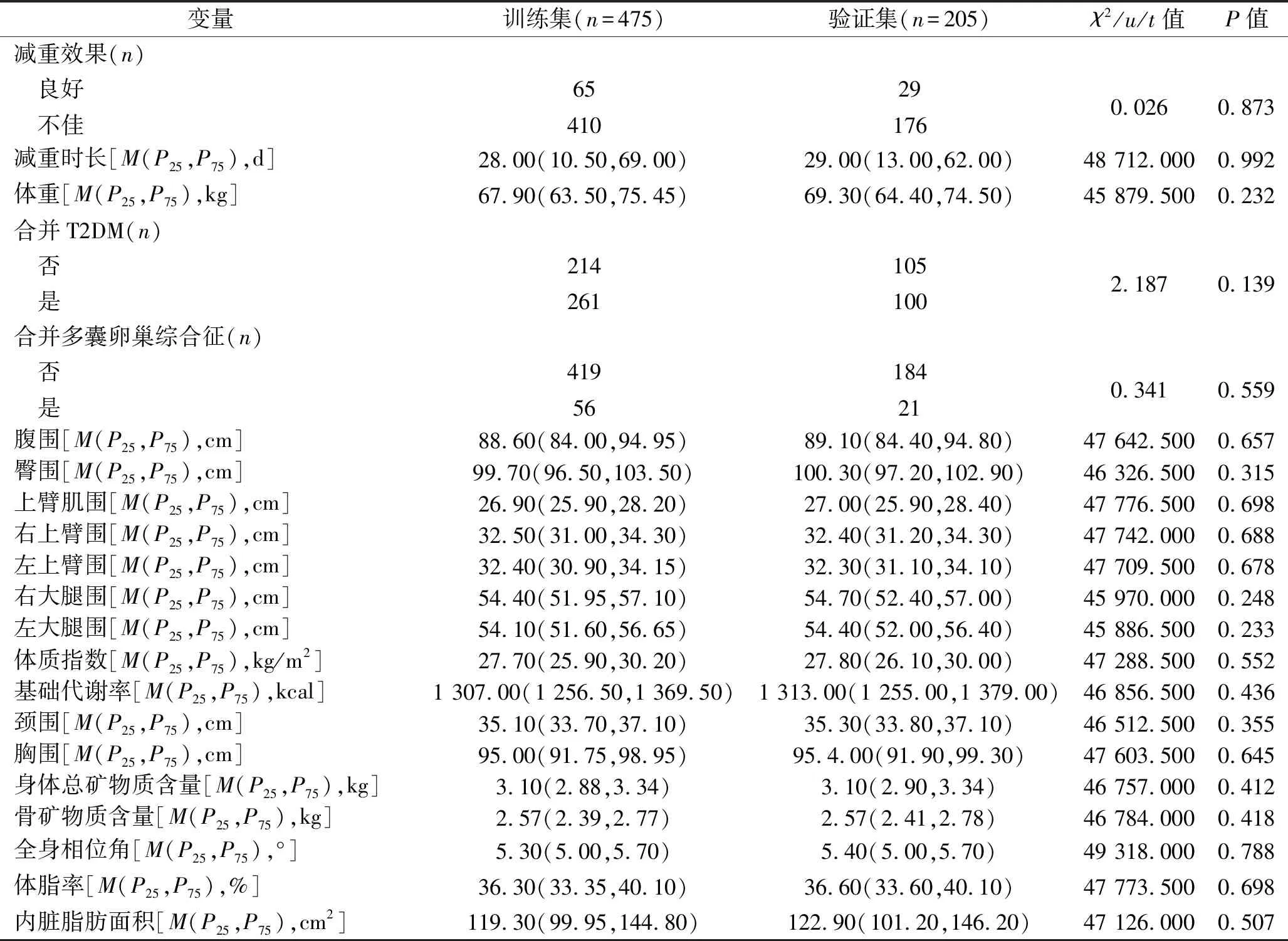
表1 训练集和验证集的结局变量、特征变量的比较
2.2 不同机器学习算法的预测模型评价结果 所有预测模型的AUC和准确率均>0.8,精确率在0.440~0.667之间,随机森林预测模型的AUC及精确率均最大;决策树预测模型的召回率和F1分数分别为0.621和0.610,其他预测模型的召回率和F1分数均<0.5。Logistic回归预测模型、决策树预测模型、K近邻预测模型、支持向量机预测模型和朴素贝叶斯预测模型的AUC(验证集)分别与随机森林预测模型的AUC(验证集)比较,差异无统计学意义(P>0.05),见表2、图2、图3。

表2 不同机器学习算法预测模型的预测效能指标

图2 训练集的ROC曲线图 图3 验证集的ROC曲线图
2.3 特征变量重要性的分析结果 减重时长在6种机器学习算法预测模型中的重要性均占首位,在Logistic回归预测模型中,其与合并多囊卵巢综合征的重要性并列首位。颈围、躯干脂肪含量百分比、右臂脂肪含量百分比在5种机器学习算法预测模型中的重要性均位列前10,全身脂肪含量、左上臂围、右上臂围在4种机器学习算法预测模型中的重要性位列前10,见图4。

图4 减重效果预测模型的特征变量重要性排名(前10位)图
3 讨 论
机器学习算法已经被广泛应用于医疗卫生领域并逐渐成熟,然而,鲜有基于机器学习算法预测超重/肥胖患者减重效果的研究。鉴于超重/肥胖可对人体健康造成一定的威胁,因此采用机器学习算法预测超重/肥胖患者的减重效果并探索其影响因素具有一定的临床价值。本研究采用Logistic回归、决策树、K近邻、支持向量机、朴素贝叶斯和随机森林6种常见的机器学习算法预测超重/肥胖患者的减重效果,所有预测模型的AUC和准确率均>0.8,提示其具有较好的预测性能。虽然其余5种机器学习算法预测模型的AUC与随机森林预测模型的AUC差异无统计学意义(P>0.05),但是随机森林预测模型的AUC最大,因此其预测性能相对更好。
本研究还进一步对纳入6种机器学习算法预测模型的特征变量的重要性进行分析,结果显示减重时长是影响减重效果的首要因素。减重时长受减重者依从性的影响,而减重依从性又受肠道激素、代谢适应、心理因素等多种因素的影响[12-14]。在多项采用饮食管理进行减重的研究中,研究对象的失访率均较高,依从性差异较大[15-17]。Sumithran等[18]对50例重度肥胖患者进行为期10周的极低能量饮食干预并随访52周后发现,重度肥胖患者在第10周时的体重平均减轻13.5 kg,在第62周时的体重平均减轻7.9 kg,其饥饿程度及进食欲望均有所增加,体重有所反弹,外周血中厌食性肠道激素肽YY、胆囊收缩素、淀粉样蛋白、胰岛素和瘦素水平显著下降,而胃饥饿素、抑胃肽和胰多肽水平升高,且在整个研究期间失访率高达32%。静息能量消耗占人体一天总能量消耗的60%~70%,其主要由身体成分决定,当非脂肪质量伴随着体质量的减少而有所损失时,静息能量消耗也随之降低,这种现象称为代谢适应[12]。有学者发现,在接受代谢手术的减重者和未行代谢手术的减重者中都存在这种代谢适应[19],且代谢适应持续时间可长达1~2年,使减重者丧失自信,终止减重[20]。此外,减重者的心理因素在减重依从性中也起着至关重要的作用,食欲调节涉及饥饿感、饱腹感、自我奖励和认知控制等多种心理感受[21],这些心理感受由外界环境和中枢神经生物学相互作用而产生[22]。积极愉悦、消极悲伤的心理感受都可以引发肥胖患者对享受食物的渴望,促使其摄入更多的食物[23],尤其是能量密度高的食物[24]。以上研究说明肠道激素、代谢适应、心理因素可通过刺激食物摄入或抑制能量消耗,导致减重者体重反弹,从而降低其减重动力和依从性,中断减重干预,进而影响减重效果。
本研究结果显示,躯干脂肪含量百分比、右臂脂肪含量百分比、全身脂肪含量也是影响超重/肥胖患者减重效果的重要因素,说明脂肪含量与减重效果有一定的关系。研究显示,限制饮食可以减少体内脂肪含量和非脂肪含量(或瘦体重)[25]。但是在减重人群中,减少的非脂肪质量仅占体重减少总量的20%~30%,这类人群的减重更多是减少脂肪质量[25-26]。与肥胖男性相比,肥胖女性减重往往能够减掉更多的脂肪质量,尤其是在减重早期[27],可能是因为女性的脂肪含量比男性更高。已有多项研究表明,无论采用何种膳食模式或者运动方式进行减重,脂肪的减少量远多于瘦体重或者非脂肪含量[28-30]。但是也有研究显示,在减重早期(4~6周)减掉的体重中,瘦体重的占比更大,脂肪占比不足瘦体重的一半,但随后脂肪减少量占比逐渐增加,直到24周以后,减掉的体重几乎全部来自脂肪[31]。有学者发现,减重过程中脂肪量的减少可能与瘦素水平、甲状腺状态和交感神经系统的活动有关[32-34]。
颈围、左上臂围、右上臂围是人体成分的围度指标,在本研究中三者也是影响超重/肥胖患者减重效果的重要因素。颈围作为中心性肥胖的人体测量指标,是识别超重/肥胖患者的简单指标[35-37],颈围越大,肥胖程度越高。但目前鲜有颈围与超重/肥胖患者减重效果的相关性研究,或许今后可以通过分析肥胖程度与减重效果的关系探索颈围对减重效果的影响。研究显示,不同肥胖程度人群的减重效果存在差异可能与其体内慢性炎症状态有关[38-39]。严重肥胖患者的肥胖相关并发症发生率和病死率较正常体重人群或超重者更高,而且血液中的炎症因子水平也更高,减重效果更差[38,40]。有学者采用针灸方法对1 528 例合并高脂血症的肥胖患者进行减重干预,结果显示轻度肥胖患者的减重效果最佳,而重度肥胖患者的体脂率和血脂水平改善效果最明显[41]。但是也有研究表明,肥胖程度越高的患者,减重的成功率越高,减重效果维持时间也越长[42-44]。由此可见,在以往的研究中,肥胖程度对减重效果影响的结论尚不一致,且颈围与减重效果的关系仍不明确。上臂围与上臂和全身的脂肪含量显著相关[45]。尽管有研究显示上臂围与肌肉含量存在相关性,但是这种相关性仅存在于非重度肥胖和非浮肿的男性中[45-46]。目前有关上臂围的研究主要集中在老年人营养不良或肌肉衰减上,关于其与超重/肥胖患者减重效果的研究较少。
本研究存在一定的局限性:性别、脂肪肝、高脂血症和高血压等特征变量在本研究中均为零方差变量,未纳入预测模型,未能分析它们对减重效果的影响。虽然预测模型的准确率较高,但是召回率偏低,说明预测模型正确识别减重效果差异的总体性能较好,但是正确识别减重效果良好的性能较低,今后仍需纳入更多的特征变量优化当前的预测模型。
综上所述,采用6种机器学习算法构建的预测模型对超重/肥胖患者减重效果均具有一定的预测效能,其中随机森林预测模型的预测效能相对更优,可辅助应用于超重/肥胖患者的医学营养管理。减重时长、身体脂肪含量(躯干脂肪含量百分比、右臂脂肪含量百分比、全身脂肪含量)、颈围和双侧上臂围等指标与超重/肥胖患者的减重效果密切相关,临床上可针对上述因素制订相应干预措施,以提高患者的减重效果。
