航段截尾油耗数据的区间估计方法
2023-11-03陈静杰梁国栋刘家学
陈静杰,梁国栋,刘家学
(1.中国民航大学 电子信息与自动化学院,天津 300300;2.中国民航大学 中国民航环境与可持续发展研究中心(智库),天津 300300;3.中国民航大学综合交通大数据应用技术国家工程实验室,天津 300300)
0 引 言
国际民航组织要求飞机运营人聘请第三方核查上报油耗数据的合理性,第三方可采用区间估计方法筛选出合理性较高的数据,然而,随着油耗数据基数增大,区间外的截尾油耗数据量也随之升高,且其分布的稀疏性及非正态性导致传统的油耗区间估计方法[1,2]不再适用,因此,有必要建立针对航段截尾油耗数据的核查方法。
飞机油耗估计是建立相关核查方法的基础。当前,国内外学者对飞机油耗估计的研究主要有两个方面,其一,针对特定飞行阶段的油耗估计,如滑行[3]、爬升[4]、巡航[5]、下降[6]等。其二,基于飞行数据驱动飞机性能模型[7,8]、深度学习模型[9,10]的全航程油耗估计。特定飞行阶段的油耗估计方法较难直接应用于油耗数据核查,而将全航程油耗估计方法应用于油耗数据核查的难点在于:特征选择和建立快速、准确的估计模型。传统的飞行特征选择方法以经验分析、相关性系数为主,具有局限性,其它特征选择及改进方法包括:卡方检验[11]、最小冗余最大相关性(mRMR)[12]、基于树的方法[13]等,主要是单独衡量数据集中每个特征与目标值相关性的大小。然而,存在某些特征在样本集整体上与目标值的相关性较弱,但在样本集局部上却与目标值表现出较强的相关性。因此,常规的特征选择方法容易遗漏重要的局部特征。此外,诸多全航程油耗估计方法对于飞机处在正常运行条件范围内的估计效果较好,但航段截尾油耗数据分布于低油耗和高油耗区间,其运行条件相对特殊,传统油耗估计方法对该类数据的估计准确度不高。
针对上述问题,本文提出了基于分类和沙普利加性解释(classification and Shapley additive explanations,C-SHAP)的改进分位数回归森林区间估计方法(quantile regression forest,QRF),可提高估计区间质量。
1 基于分类和SHAP模型的特征选择
由于航段截尾油耗数据的特殊性,基于单因素的油耗估计方法难以对该部分数据的合理性做出正确判断。因此,需考虑其它与油耗相关的飞行特征,建立基于多因素的油耗估计方法,进而从多个角度核查该部分数据,而选择合理的输入特征集对估计方法至关重要。本文提出通过对特征、样本集分类并结合SHAP模型的方法筛选出最优的飞行特征集。
SHAP模型[14]计算特征重要性的核心思想来源于博弈论,即确定各输入特征对估计结果的贡献程度。设:M维的初始特征集为F={x1,x2,…,xM}, 其中,xi代表飞行特征i的值,SHAP通过一种加性特征归因方法解释模型的估计值
(1)
式中:f(x) 是模型的估计值;g是解释模型;z′∈{0,1}M, 即当输入特征xi存在时z′i为1,反之为0;φ0是训练样本中目标变量的平均值,本文的目标变量是油耗;φi是特征i的SHAP值,SHAP值的具体计算步骤如下:
(1)根据初始候选飞行特征集F构建其幂集S,M维的特征集F共有2M个幂集。
(2)在所有幂集S上训练基线模型,由于本文采用的油耗估计模型是分位数回归森林,因此,其基线模型是随机森林回归。可得到在幂集S上的估计fS,fS∪{i}是在该幂集中引入新的特征i而构建的新幂集上的估计。进而计算特征i在该幂集模型上的边际贡献fS∪{i}(xS∪{i})-fS(xS), 其中,xS是该幂集S的所有特征值。
(3)特征i的SHAP值φi是所有可能边际贡献的加权均值

(2)
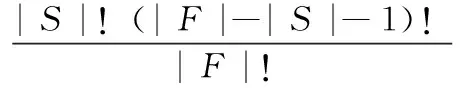
(4)根据SHAP模型的核心思想,具有较大SHAP值的特征更为重要,特征i的重要性(FI)表示为
(3)
式中:n为训练样本的数目。
C-SHAP方法进行特征选择的步骤如下:
(1)首先,将候选飞行特征按其性质分为全航程和飞行阶段油耗影响特征两类。由于全航程特征与飞机油耗间具有明确的强相关性,全部予以保留。
(2)其次,将样本集按航段分类。采用SHAP模型分别在各航段样本子集上选择给定阈值数量下的飞行阶段特征子集。
(3)再次,将各航段的飞行特征选择结果取并集,计算各特征的权值,并进行重要性排序,进一步选择出给定阈值数量的最优飞行阶段特征子集。
(4)最后,综合全航程特征集与最优飞行阶段特征子集获得最优输入飞行特征集。
2 随机过采样重构样本
对航段截尾油耗数据进行区间估计时,由于样本集中的航段截尾油耗样本相对较少(注:本文将每个航段油耗样本集中小于0.05分位、大于0.95分位油耗值的样本定义为航段截尾油耗样本),而QRF进行估计的原理如图1所示,需通过Bootstrap抽样方法得到多个样本子集以建立不同的决策树,进而构建森林。在这种情况下,每棵决策树叶子中的航段截尾油耗观测样本数目进一步减少,导致QRF模型对该类数据的估计结果偏高或者偏低。因此,本文采用在解决高维样本类别不平衡问题中相对有效的随机过采样算法[15](random oversampling,ROS)重构样本集,即增加训练集中航段截尾油耗样本的权值,以提高模型在面向航段截尾油耗数据估计时的准确性。
由于训练集中航段截尾油耗样本相对较少,需使用较高的过采样率,然而随着过采样率的增大,会引入噪声,造成过拟合问题,因此,在尽可能提高航段截尾油耗样本权值的同时要确定最大过采样率。本文提出基于网格搜索的过采样率寻优方法,其原理如图2所示,其核心思想在于通过遍历网格中的过采样率,不断重构训练集进行区间估计和评价,在保证满足可靠性的前提下寻找最大过采样率。

图2 网格搜索确定最大过采样率原理框架
3 基于QRF的油耗区间估计模型
本文在采用C-SHAP方法进行特征选择、随机过采样方法重构训练集的基础上,建立了QRF航段截尾油耗区间估计模型,通过输入飞行特征数据,估计该航班油耗的条件分位数,进而构建一定置信度的油耗估计区间。
3.1 QRF算法原理
QRF由随机森林结合分位回归理论发展得到,可获得因变量的全部条件分布信息,相较于深度学习模型具有运算速度快、鲁棒性强等优点。
随机森林算法可看作是一个适应性近邻分类和回归的过程。设:训练集 {Xi,Yi},i=1,2…n, 其中,Xi=[Xi,1,Xi,2,…,Xi,M] 是M维的输入飞行特征向量;Yi是在该飞行特征条件下的油耗目标值;n是样本量;随机森林由k棵决策树构成,本文采用的决策树是CART回归树;θ是决定森林中每棵树生成的参数向量,则该决策树可表示为T(θ); 其叶子节点为。 当给定新的飞行特征输入向量x,按照T(θ) 的划分规则,可确定唯一的叶子节点(x,θ), 该叶子中每个观测样本的权重为
(4)
式中:R是该叶子节点对应的特征空间。对于森林而言,每个观测样本在k棵树上的权重均值为
(5)
随机森林对条件期望E(Y∣X=x) 的估计是由k棵树上相应叶子中观测样本的加权平均近似
(6)
类比随机森林对条件期望的近似过程,目标值y的条件分布估计可表示为
F(y∣X=x)=P(Y≤y∣X=x)=
E(1{Yi≤y}∣X=x)
(7)
利用观测样本的权重均值来逼近目标值的条件分布,其分布函数为
(8)
由此,QRF对α分位下的条件分位数估计为

(9)
3.2 模型结构
航段截尾油耗数据区间估计方法流程如图3所示。利用航班QAR(quick access recorder)数据作为初始数据源,获得油耗及相关的飞行特征数据。首先通过C-SHAP方法选择给定阈值数量的输入飞行特征集。随后,通过对航段截尾油耗训练样本随机过采样以增加该类样本在训练集中的权重,并通过网格搜索法确定最大过采样率。

图3 航段截尾油耗数据区间估计方法框架
QRF模型通过估计给定上、下限油耗条件分位数构建估计区间,基于重构训练集,通过网格搜索和k-折交叉验证的方法获得模型的最优超参数,完成航段截尾油耗数据区间估计模型的建立。
最后,基于航段截尾油耗测试数据得到各航班油耗的估计区间,并采用相应的评价指标对估计区间质量进行评价。
4 评价指标
采用估计区间可信度(estimation interval coverage probability,EICP)、估计区间归一化平均带宽(normalized mean estimation interval width,NMEIW)以及综合指标(coverage width based criterion,CWC)[16]评价模型的估计性能。
(1)估计区间可信度
EICP指真实值落入估计区间的概率,是估计区间可靠性的表征
(10)
(11)
式中:Ui和Li是估计区间的上、下限;n为测试集的样本量。
(2)估计区间归一化平均带宽
如果仅追求EICP,估计区间的上下包络线将接近极值,那么得到的估计区间对决策者毫无意义。在相同的EICP下,较窄的估计区间质量更高,为此,引入NMEIW来衡量估计区间的宽窄
(12)
式中:R为测试集的变化范围,用于对平均带宽做规范化处理。
(3)综合指标
区间估计的目标是较高的EICP和较窄的NMEIW,然而从理论上看,这两个目标相互矛盾,因为一旦NMEIW减小,EICP理应随之减小,为合理评价估计区间的质量,引入综合指标定量表示二者的权衡情况。
CWC=NMEIW×(1+γ×e(-η×(EICP-μ)))
(13)
(14)
式中:μ表示置信度,本文取μ=0.9;η用于EICP小于μ时施加的惩罚量,本文取η=50;γ判断是否需要对当前估计区间惩罚。
5 实验分析
5.1 实验数据
本文使用某飞机运营人2012年、2013年A330机型共8152次航班的QAR数据作为初始数据源,使用其提取、计算油耗及相关的飞行特征参数见表1。由于滑行阶段、离场起飞阶段、着陆滑跑阶段的飞机油耗占比相对其它飞行阶段较少,对油耗总量影响不显著。因此本文未考虑这些阶段的飞行特征。候选飞行特征选取原则是:从飞机性能、运行方式以及飞行环境等角度尽可能多提取与油耗相关的特征。
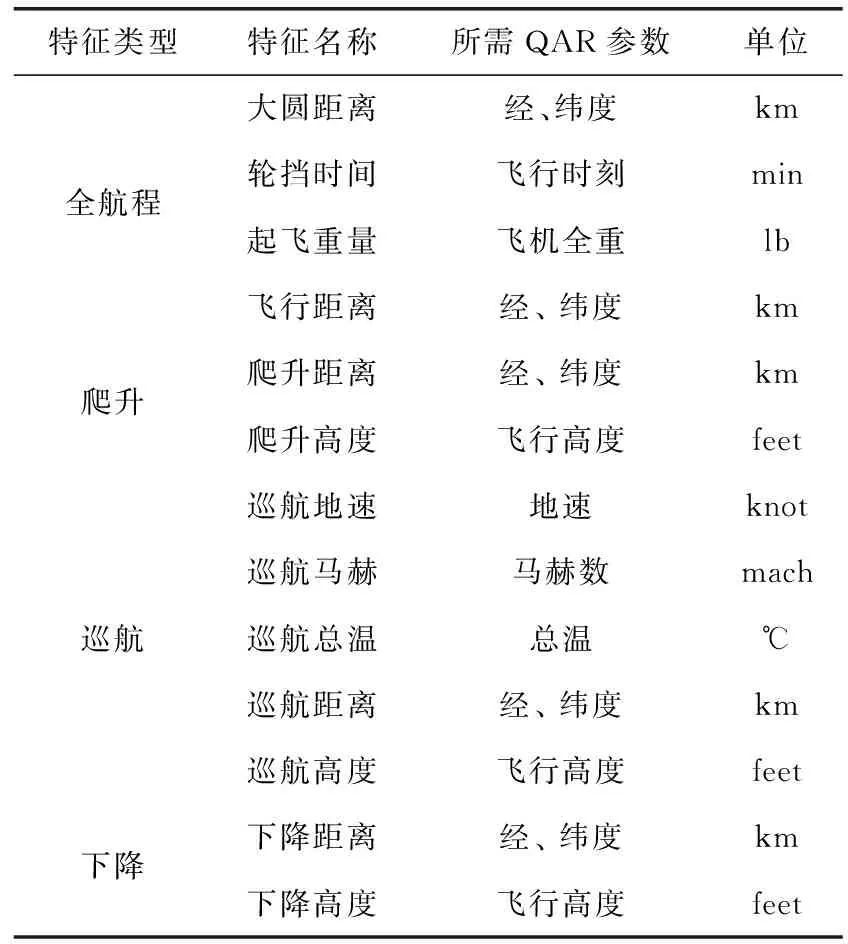
表1 候选飞行特征及计算该特征所需的QAR参数
将油耗及初始候选飞行特征集按大圆距离划分为不同航段子集,分别取每个航段中小于0.05分位和大于0.95分位油耗值的数据作为航段截尾油耗样本集,并取其20%作为测试集,共116次航班,测试集外的其余数据作为训练集,共8036次航班。
5.2 C-SHAP特征选择结果
SHAP模型的基学习器为随机森林,其参数设置为:决策树数目为100;随机特征数为输入特征数的平方根;叶子尺寸为1。C-SHAP方法对飞行阶段特征的重要性排序如图4所示。
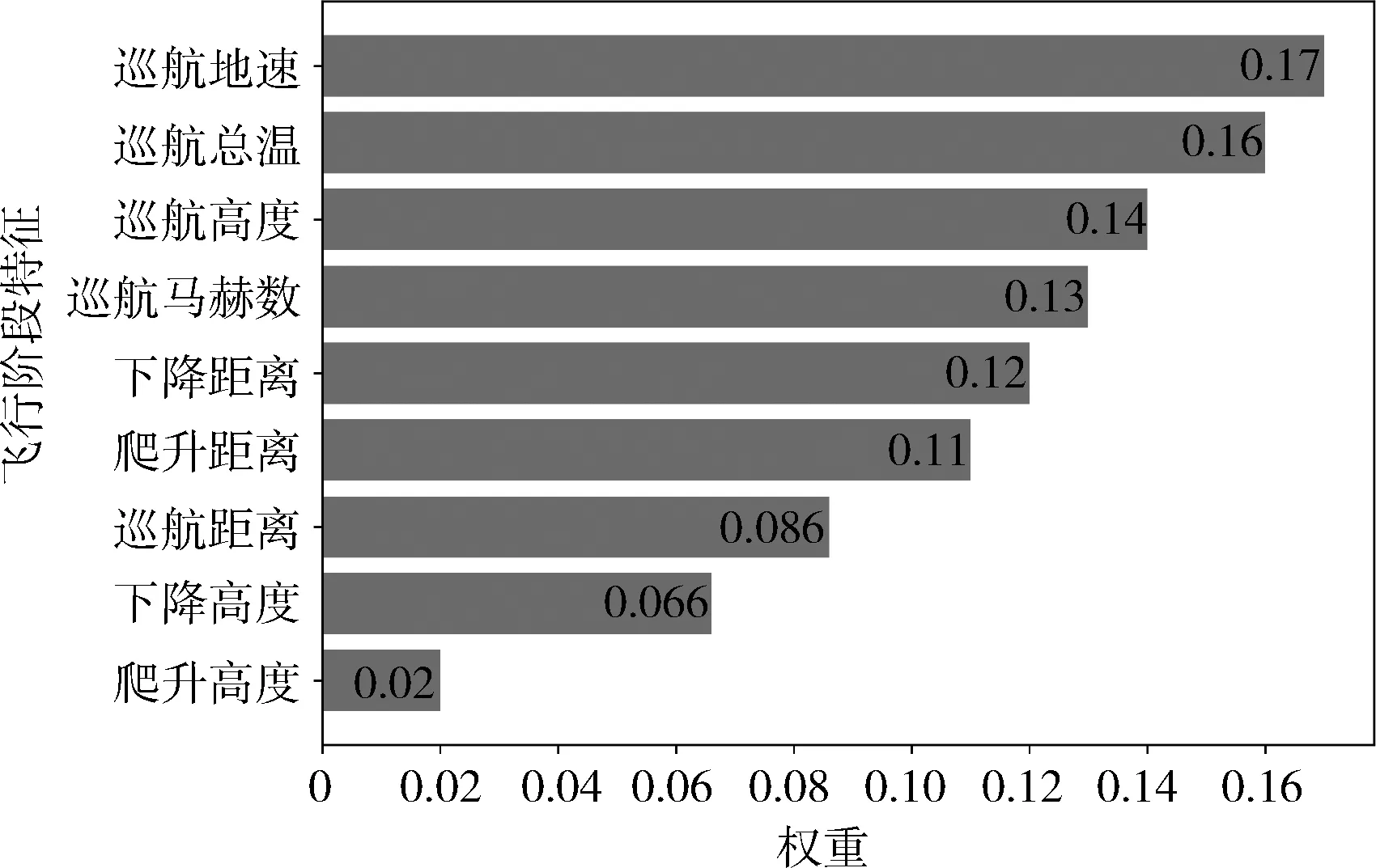
图4 飞行阶段特征重要性排序
设置飞行阶段特征选择的重要性阈值为6,再综合全航程飞行特征,则基于C-SHAP方法得到的最优特征子集为:大圆距离、轮挡时间、起飞重量、飞行距离、巡航地速、巡航总温、巡航高度、巡航马赫数、下降距离、爬升距离。
5.3 随机过采样结果

基于网格搜索确定的最大过采样率为3,即生成2511个航段截尾油耗样本,其余油耗样本数目不变,则重构训练集共包含9730个样本。
5.4 实验参数设置
为了得到估计性能较好的QRF模型,需寻找相对较优的主要超参数组合:决策树数目、随机特征数目和叶子尺寸。随机特征数目一般按经验设置为全部特征数的平方根;其余较优的超参数通过网格搜索和5-折交叉验证获得,且将CWC作为交叉验证的评价指标,超参数网格设置见表2。

表2 超参数网格设置
得到较优的超参数组合为:决策树数目是500;随机特征数是3;叶子尺寸是5。90%置信度的估计区间下限、上限的分位点设置为:0.05、0.95。
5.5 对比验证
在90%置信度下,本文所提方法基于航段截尾油耗测试集的区间估计结果如图5所示,为了清晰展示油耗区间估计结果,将航段截尾油耗测试样本按油耗值升序排列。
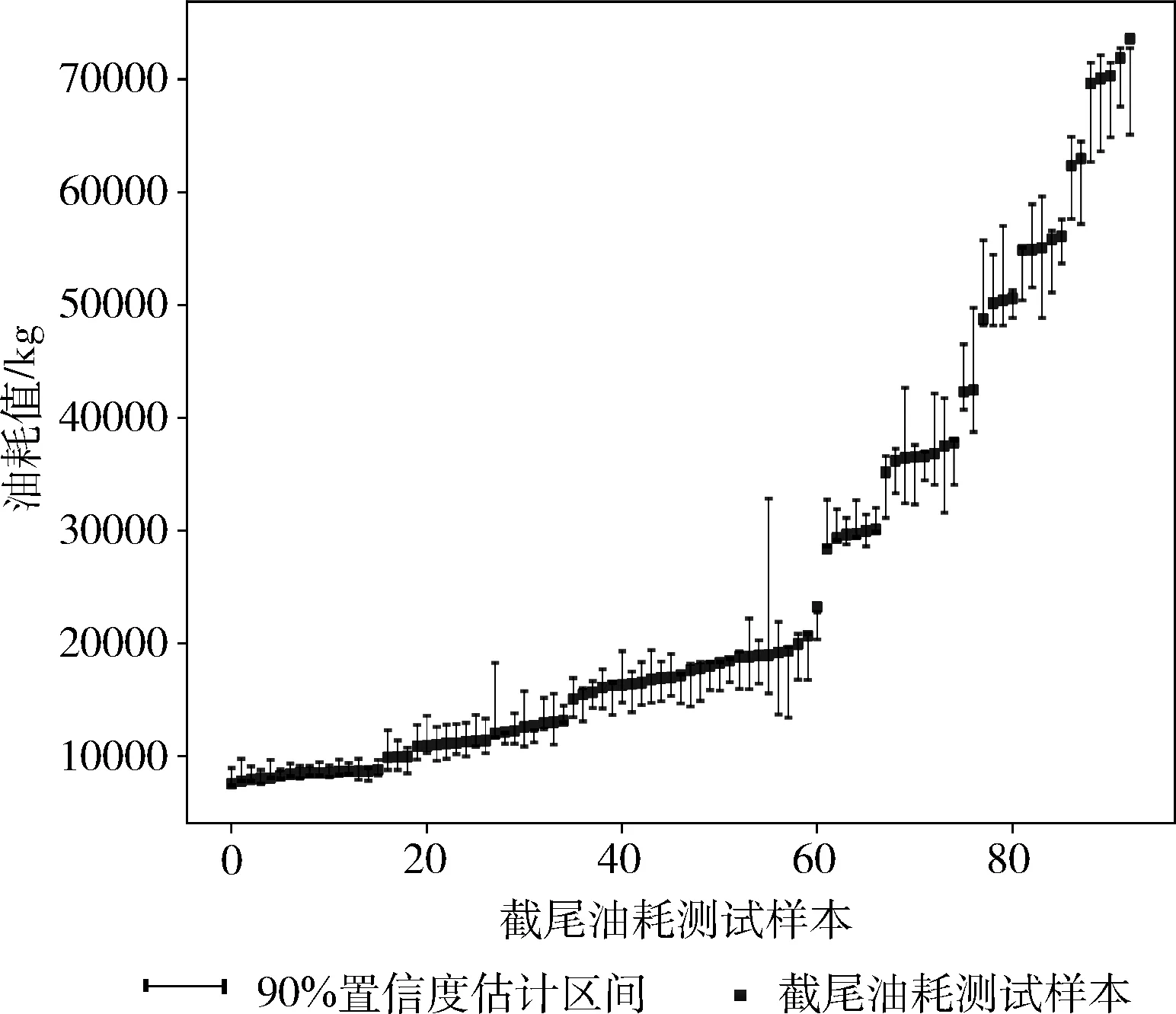
图5 区间估计结果
为验证本文所提方法的有效性,另选取常规的特征选择方法:斯皮尔曼秩相关系数(Spearman)、最小冗余最大相关性(mRMR)、随机森林(RF),在给定特征阈值数目为10的条件下进行特征选择,结果见表3。

表3 各方法的最优特征选择结果
然后,结合QRF方法构建3种航段截尾油耗区间估计对比方法,即Spearman-QRF、mRMR-QRF、RF-QRF,以验证本文所提特征选择方法的有效性。在使用随机过采样方法重构训练集前,通过测试集得到各方法的估计区间评价结果见表4。

表4 重构训练集前各方法的估计区间评价结果
表4显示,3种对比方法的EICP均低于90%置信度,造成相对较高的CWC,估计区间质量较差,本文方法的EICP高于90%置信度,虽然NMEIW相对较高,但具有相对较小的CWC,估计区间质量较好。究其原因,是对比模型的特征选择不够合理造成,从表3可以得知,各种特征选择方法均选取了所有全局特征,这是由于全航程特征对航班油耗影响显著且各特征间没有冗余,然而,在飞行阶段特征的选择上却不尽相同,一个显著的区别在于巡航地速,3种对比方法认为巡航地速特征的重要性较小,而C-SHAP方法认为巡航地速对油耗影响显著。可直接应用航段截尾油耗测试集来分析模型进行估计时巡航地速特征对其影响情况。对于一个航段内的测试样本,巡航地速特征与其SHAP值的关系如图6所示,具有较强的线性相关性,其值越小,SHAP值越大,对模型估计结果起正向作用,即模型的油耗估计值越大,而其值越大,SHAP值越小,对模型估计结果起负向作用,即模型的油耗估计值越小,验证了巡航地速特征对模型估计及飞机油耗量具有重要影响。
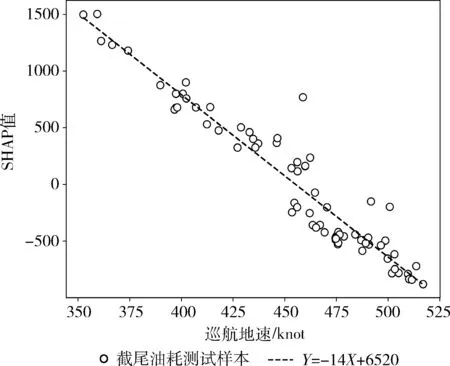
图6 巡航地速与其SHAP值关系
巡航地速对油耗的影响也可从理论上进行说明,如图7所示,根据飞机的地速、空速、风速的矢量三角关系,在巡航过程中,飞机的空速会稳定在一个定值附近波动,这时如果飞机顺风,地速相对较高,完成一定的地面距离时油耗较少,如果飞机逆风,则地速相对较低,完成一定的地面距离油耗较高。因此,巡航地速可谓是间接反映了飞机飞行过程中受风的影响情况,与油耗密切相关,这也说明了采用C-SHAP方法进行特征选择的合理性。
利用随机过采样方法重构训练集后,基于航段截尾油耗测试集得到各方法的估计区间评价结果见表5。

表5 重构训练集后各方法的估计区间评价结果
从表5可以看出,经过随机过采样处理后,缩小了4种方法的估计区间宽度,并且3种对比方法的EICP并未因此减少,从而在一定程度上降低了CWC,而本文方法的EICP虽有所减少,但可保证大于90%置信度,在满足估计可靠性的前提下,缩小了区间宽度,提高了估计区间质量。
6 结束语
(1)本文首先针对飞机油耗估计中存在特征选择不够合理的问题,提出了C-SHAP特征选择方法,相较于传统以及改进的特征选择方法,可识别出重要的局部特征。其次,利用随机过采样方法在数据层面上改进了QRF模型,使该模型的估计更有针对性。
(2)C-SHAP方法适用于特征集和样本集可分类的特征选择问题上。基于随机过采样改进的QRF方法可应用于非正常情况下目标值的区间估计问题。
(3)目前,采用随机过采样方法处理高维类别不平衡样本相对有效,也可研究其它更为精确的采样方法。
