基于代码相似性的测试用例重用及生成方法
2023-11-03刘巧韵杨秋辉刘美英刘盈盈
刘巧韵,杨秋辉,洪 玫,刘美英,刘盈盈
(四川大学 计算机学院,四川 成都 610065)
0 引 言
针对代码重用现象[1-3],引入测试用例重用技术[4],通过普遍存在的测试用例相似现象,将现有测试用例信息重用到测试用例生成等领域中,以加快测试用例设计,减少后续测试用例编写工作量,提高测试效率和质量。然而,现有测试用例重用主要提供重用建议,且忽略了代码间的语义相似信息;另外,大部分测试用例生成工作都需要人工介入。
本文提出了一种基于代码相似性的测试用例重用及生成方法,包括相似性代码检索、测试用例重用及生成两大步骤。首先使用基于文本和基于度量的代码相似性检测技术检索被测代码的语法和语义相似代码,并将结果划分为4种相似类型;然后针对不同相似类型,使用更名重用、补充重用两种重用策略。在更名重用中,采用抽象语法树信息替换方法对现有测试用例基本信息进行修改以生成新测试用例。在补充重用中,使用GumTree算法对现有测试用例补充测试语句,生成新测试用例。本文提出的方法能更有效地利用现有测试用例信息,自动化生成测试用例,从而提高测试效率,减少测试工作量。
1 相关工作
近年来,软件测试重用技术发展愈加成熟,国内外已有大量研究成果。其中,面向测试过程中的代码重用技术是最主要的重用技术之一。
Mathias等[5]提出一种自动生成携带测试预言的测试克隆方法,并实现了工具TestClone通过提取使用相同逻辑的测试代码,将现有测试用例进行转换生成新的测试用例。Gang等[6]提出AppFlow测试系统,可用于合成健壮性强且可重用的UI测试。Werner等[7]提出一种自动化测试推荐方法,通过构建Junit测试文件储存库创建测试用例搜索引擎,可自动索引WEB开源项目中的测试用例。Yunwei等[8]提出一种基于测试覆盖率准则的测试可重用性评价方法,通过研究测试用例的可重用性、重写模式和测试覆盖率之间的关系,总结了程序修改后的重写模式,并研究了此类模式在修改程序测试中的作用,得出影响测试用例可重用性的覆盖率准则。Ducasse等[9]提出了一种基于测试的可重用性特征组合重用测试的方法,该方法针对代码中不同继承层次结构中的类定义了测试方法的特性,根据不同特性组合测试用例形成新的测试类重用到测试过程中。Suriya等[10]实现了易于开发和进化的通用测试用例库以用于测试用例重用,通过Android平台框架项目中测试用例普遍存在的重复现象,总结了重复模式并使用通用形式表示,以便进一步重用测试用例。Robert等[11]设计了抽象框架RASHID,利用二部图表示不同源码、测试用例之间的关系,为开发人员推荐可重用的测试。Mostafa等[12]介绍了利用克隆检测技术进行测试用例推荐模板实现方法,使用程序当前上下文挖掘储存库中相似代码并为此推荐相匹配的单元测试用例。
本文提出了一种基于代码相似性的测试用例重用及生成方法,通过代码相似性检测得到可重用测试用例,在进行一系列处理的基础上生成新测试用例。该方法改进了现有测试用例生成方法的生成效率,节约了时间成本;同时,在代码相似性检测上,突破了已有测试用例重用技术仅考虑语法相似的局限,综合了语法、语义等多个代码相似因素,提升了代码相似性检测的准确性,扩大了测试用例重用范围。
2 方法描述
本文提出了一种综合语法和语义信息检索相似代码,并采用抽象语法树信息替换算法和GumTree算法修改现有测试用例的测试用例重用及生成方法。整体流程如图1所示。

图1 方法流程
2.1 相似性代码检测
相似代码也称为克隆代码[13],即忽视源代码中的注释,只要连续代码序列相似性达到一定阈值,便形成克隆关系。具有克隆关系的两个代码段称为一个克隆对,多个代码段称为一个克隆类。
代码相似类型主要分为两类[14]:语法相似性和语义相似性。进一步细分,可分为4种类型[14-16]:属于语法相似的Type-1、Type-2、Type-3和属于语义相似的Type-4。其中,Type-1是精确克隆类型,指两个相似代码片段在代码级别上没有差别,互为精确副本;Type-2是改名克隆类型,指两个相似代码片段在代码级别上存在变量名等名称修改情况;Type-3是近距克隆类型,指两个相似代码片段共用同样的语法结构,但存在语句增加或修改的情况;Type-4是语义克隆类型,指两个相似代码片段的语法结构可能不同,但语义和功能是相同的。
相似性代码检测根据相似度在源代码中找到相似源码,并以克隆对或克隆类的形式反馈结果。本文分别使用基于文本和基于度量的技术检测不同类型的相似代码。
2.1.1 基于文本的代码相似性检测
基于文本的代码相似性检测技术不受编程语言的限制,主要用于检测代码的语法相似性。
首先,对源代码进行预处理。删除源代码中的注释、空格、空行等,给定粒度级别(如方法级别)进行片段提取,生成候选克隆代码序列;对提取出的代码片段进行句法形式过滤或抽象,如对代码片段中的声明语句进行过滤,对表达式进行抽象等,并表示为字符串形式。该过程的目的在于提取有效数据,消除代码中特定声明或表达式等带来的影响。
然后,进行克隆代码的比较分析。首先选择一个预处理后的代码片段作为参照,然后对与其在给定差异大小范围内的所有代码片段进行聚类,并对代码片段进行成对线性比较,找到每对的最长公共子序列。该过程使用了优化的最长公共子序列算法(LCS)[17]。
最后,计算候选克隆对的唯一子序列项百分比(UPI)[18]。如果UPI值低于设定的阈值,则认为该代码对是彼此的克隆副本。设定不同阈值以区分不同相似类型,检测Type-1、Type-2和Type-3。UPI计算公式如式(1)所示
(1)
式中:TotalItems表示总子序列数量;UniqueItems表示两个字符串序列中不属于最长公共子序列子串的子序列。
待比较类中所有代码片段分析完成后,选择下一个参照代码段,重复该步骤,直到处理完所有候选代码。
2.1.2 基于度量的代码相似性检测
基于度量的代码相似性检测技术能忽略代码的语法信息,主要用于检测代码的语义相似性。
首先,对源代码进行预处理并构建代码指纹库。使用Java环境命令生成源代码的字节码形式,以减少对语法结构的关注;使用松弛化的指纹提取方法[14]提取字节码文件中的Java类名和方法名,并分别归入类指纹库和方法指纹库。
然后,分别使用语法模式匹配和语义内容匹配构建相似性度量。将两个指纹库中的指纹利用基于Semantic Web的技术进行模式匹配。该技术的思想是利用指纹顺序判断模式相似性,即分别判断类指纹顺序和方法指纹顺序,如果指纹顺序相同,则认为模式相似。这一过程可产生类模式相似性和方法模式相似性两个度量准则。
同时,为了减少模式匹配中的假阳性结果,继续进行内容匹配。使用Jaccard指数衡量两个方法块之间的内容相似性。Jaccard指数计算公式如式(2)所示
(2)
式中:S1和S2分别表示两个代码片段的类指纹集合和方法指纹集合。这一过程可产生类内容相似性和方法内容相似性两个度量准则。
最后,结合上述4个度量准则计算两个代码片段的总体相似性,此处使用Keivanloo等[14]提出的计算公式,如式(3)所示

(3)
其中,Ca、Cb表示两个候选克隆代码段;ti、mi分别表示两个代码片段的类指纹集合和方法指纹集合;queryx表示对第x个模式相似值进行查询,模式相似值的个数上限为q;Js函数表示两个片段Ca和Cb在类级别或方法级别上的Jaccard值的布尔表达式;φ和ω分别为Java类内容相似度阈值和方法内容相似度阈值,如Js(ta,tb,φ) 为真则表示ta、tb在类内容上相似度大于φ。根据该公式,若两个代码片段在4个度量上都有同一表现,则被视为互为克隆副本,否则丢弃。
2.2 测试用例重用及生成
测试用例重用及生成主要包含两种方法:更名重用和补充重用。更名重用针对Type-1、Type-2及Type-4类型,该3种类型无语句增删情况,仅需要对测试用例的参数类型等属性进行修改即可;而补充重用则针对包含语句增删情况的Type-3类型,即在更名重用的基础上,还需对测试用例缺失语句进行补充。
对Type-1、Type-2及Type-4,使用更名重用方法。提取被测代码的抽象语法树(AST),从AST中抽取源代码的类名、方法名和参数类型,对现有测试用例的相应属性进行修改,实现AST信息替换,生成新测试用例。该算法伪代码如下:
算法1:抽象语法树信息替换算法
输入:要解析的Java源文件路径sourcepath,现有测试用例文件TC及其路径TCPath
输出:新测试用例
Class JavaASTparser{
procedure GeneASTparser(sourcepath)
//获取被解析文件
bindingKeys ← {"class", "interface",
"arraytypes", "primitive types", "field"}
result ← createASTs(sourcepath, encodings,
bindingKeys)
}
Class VisitAST{
procedure visit(field.node, type.node, method.node)
//访问源代码参数、类和方法属性
fieldlist ← ("FieldName" = field.node.name)
typelist, fieldlist ←
("ClassName" = type.node.name)
methodlist ←
("MethodName" = method.node.name)
SimAST ← fieldlist + typelist + methodlist
//存储属性
procedure GetTCInfo(TC)
//获取测试用例AST中的信息
GeneASTparser(TCpath)
visit(field.node, type.node, method.node)
tcinfo ← fieldlist + typelist + methodlist
GeneTCFromSimAST()
}
Class GeneTC{
procedure GeneTCFromSimAST()
//根据AST替换测试用例信息
if tcinfo.fieldname = tcinfo.typename
then oldtc.fieldname ← simAST.typename
else tcinfo.fieldname = tcinfo.classname
then oldtc.fieldname ←
simAST.classname
newtc ← oldtc //获得新测试用例
}
对判断为Type-3的类型,使用补充重用方法。按源代码与被测代码的相似性由高到低排列测试用例得到测试用例序列,选择序列中相似性最高的测试用例进行更名重用,得到候选测试用例。然后使用GumTree算法[19]将测试用例序列中的其它测试用例分别逐一与该候选测试用例匹配,该过程对候选测试用例中缺失的语句进行补充生成新的测试用例序列。最后选择生成序列中覆盖率最高的测试用例作为生成的新测试用例。
3 实验验证
3.1 实验对象
选择Java开源数据集Defects4j中的3个项目:JFreeChart、Apache Commons Lang以及Apache Commons Math,每个项目都包含其不同迭代版本的源代码及测试用例等信息,见表1。

表1 实验项目信息
3.2 评估指标
评估指标选择重用召回率和重用精度。重用召回率用于衡量测试用例成功重用的能力。如果生成的测试用例可以成功执行,则认为该测试用例被成功召回,为有效测试用例。召回率越高表明测试用例重用效果越好。其计算方式如式(4)所示

(4)
其中,可重用测试用例数量表示通过代码相似性检测后的所有相似源码对应的所有可重用测试用例数量。
重用精度用于衡量测试用例的重用质量。如果生成测试用例的覆盖率大于或基本等于项目中人工编写的测试用例的覆盖率(差值不超过1%),则认为该测试用例的质量较好,为正确测试用例。其计算方式如式(5)所示

(5)
3.3 实验设计
验证方案可行性,表明本文方法能够成功对现有测试用例进行重用,生成有效测试用例。在语法相似性检测中,根据已有研究[18],分别取UPI为0.0、0.1和0.3检测Type-1、Type-2和Type-3;在语义相似性检测中,根据文献[20]对重用精度和重用召回率的研究结果,将式(3)设置阈值q=20、φ=1.9、ω=5.3,进行测试用例重用及生成。
验证方案有效性,表明本文方法有更好的重用效果,测试用例生成质量更高且成本更低。首先,与现有测试用例重用方法比较测试用例重用效果:分别将本文方案与LANDHUSSER等提出的方案[5]、Mostafa等提出的方案[12]重用结果进行比较,计算重用召回率和重用精度;然后,与现有测试用例生成方法比较测试用例生成效率:分别将本文方案与目前广泛使用的测试用例自动生成工具Randoop[21]、Evosuite[22]进行比较,在本文方法所需时间限制下,分别使用Randoop和Evosuite进行测试用例生成,比较3种方法在相同时间内生成测试用例的覆盖率。
3.4 实验结果与分析
本文方案重用召回率见表2。
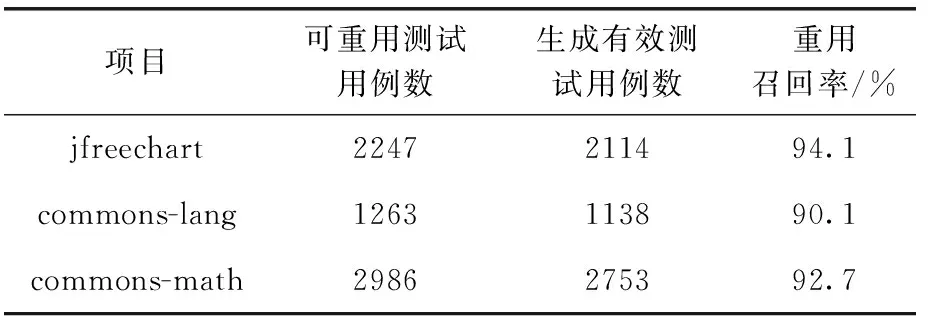
表2 测试用例重用召回结果
由表2可知,3个实验项目的重用召回率均超过90%,其中最高的是JFreechart,生成有效测试用例2114个,重用召回率达到94.1%;最低的项目Apache Commons Lang也生成了1138个有效测试用例,重用率也达到了90.1%。
这说明本文方法能对现有测试用例进行有效的重用及生成。但也有少部分重用生成后的测试用例执行失败,究其原因主要是某些被测类的参数过于复杂并且要求非空参数数量较多导致新生成的测试用例不能成功执行。例如测试类PeriodAxisLabelInfoTest中的testEquals()方法需要声明参数info1=new PeriodAxisLabelInfo(c1,df1,sp1,lf1,lp1,b1,s1,dp1),需要非空参数8个,而新测试用例只生成了6个参数,导致测试用例执行失败。
本文生成的测试用例与人工编写的测试用例覆盖率及重用精度见表3。

表3 测试用例重用精度结果
由表3可知,3个实验项目的重用精度均达到84%以上,其中最高的是Apache Commons Math项目,包含2423个正确测试用例,重用精度达到88.0%;最低的项目JFreeChart也生成了1776个正确测试用例,重用精度达到84.0%。这说明本文方法能生成大于等于人工编写的测试用例覆盖率的正确测试用例,达到了较高的重用精度。
本文方法与文献[5]及文献[12]方法的重用召回率及重用精度见表4。

表4 3种测试用例重用方法的重用效果对比结果/%
由表4可知,本文方案在重用召回率和重用精度上都有更好的表现。在3个数据集上,与文献[5]方法相比,本文的重用召回率提高了4.6%~10.2%,重用精度提高了2.5%~6.2%;与文献[12]方法相比,本文的重用召回率提高了18.7%~23.1%,重用精度提高了17.3%~28%。实验结果更佳的原因,一是本文方法考虑了语法、语义等多种代码相似因素,而文献[5]和文献[12]都只考虑了语法相似一种因素;二是本文使用了两种重用方法,对4种相似类型的测试用例均进行了重用生成,而文献[5]只能对Type-1、Type-2的测试用例进行重用生成,文献[12]只能对Type-1的测试用例进行重用生成。综上所述,与现有测试用例重用方法相比,本文方法具有更好的重用效果。
本文方法与Randoop及Evosuite在相同时间成本下生成的测试用例覆盖率结果见表5。
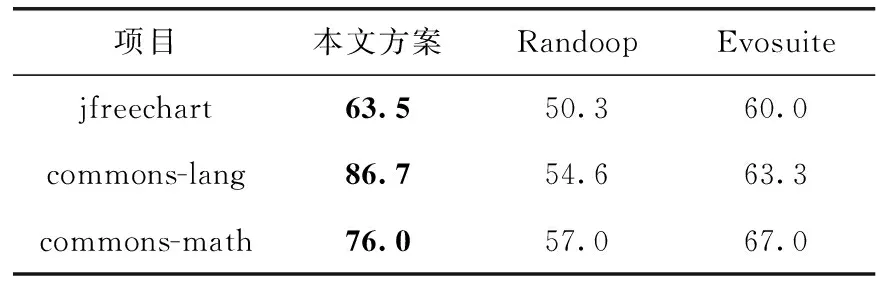
表5 3种测试用例生成方法的测试用例覆盖率对比结果/%
由表5可知,在相同时间成本下,本文方案生成的测试用例覆盖率更高。与Randoop相比,本文方法的测试用例覆盖率提高了13.2%~32.1%;与Evosuite相比,本文方法的测试用例覆盖率提高了3.5%~23.4%。实验结果更佳的原因是,本文直接使用现有测试用例进行重用,提高了生成效率;而Randoop采用随机生成技术,短时间内只能为少部分被测类生成测试用例,导致生成的测试用例覆盖率较低;Evosuite采用基于遗传算法的搜索生成技术,其测试用例生成过程需要较长的搜索时间和一定的迭代次数,这也致使在相同时间内该工具仅能为部分被测类生成测试用例。综上所述,在相同时间成本下,相比现有测试用例生成方法,本文方法能生成质量更好的测试用例,降低了测试时间成本。
4 结束语
为减少测试工作量、节省测试成本,本文提出了基于代码相似性的测试用例重用及生成方法。该方法将代码重用技术应用于测试用例生成,且对代码相似性检测方法进行了适应性改进。实验结果表明,本文方法能有效生成测试用例,降低生成成本,且比现有方法在重用召回率和精度上、生成效率上均有明显提升。
本文方法的进一步工作是:在相似性检测阶段,本文只使用了两种检测技术,未来可探究使用其它技术对本文方法效果的影响;在测试用例重用及生成阶段,本文方法生成的测试用例有一部分不能很好地适应包含复杂参数的被测代码,未来可改进生成算法以针对这些被测代码;本文所选实验数据集并不能完全代表工业中的实际项目,未来可在更多真实的大型工业项目中进一步验证本文方法。
