BIC与MCMC基准剂量估计模型的比较研究*
2023-10-18彭雯洁王青青周小林余红梅
彭雯洁 崔 靖 张 婷 王青青 张 超 袁 苗 周小林△ 余红梅,4△
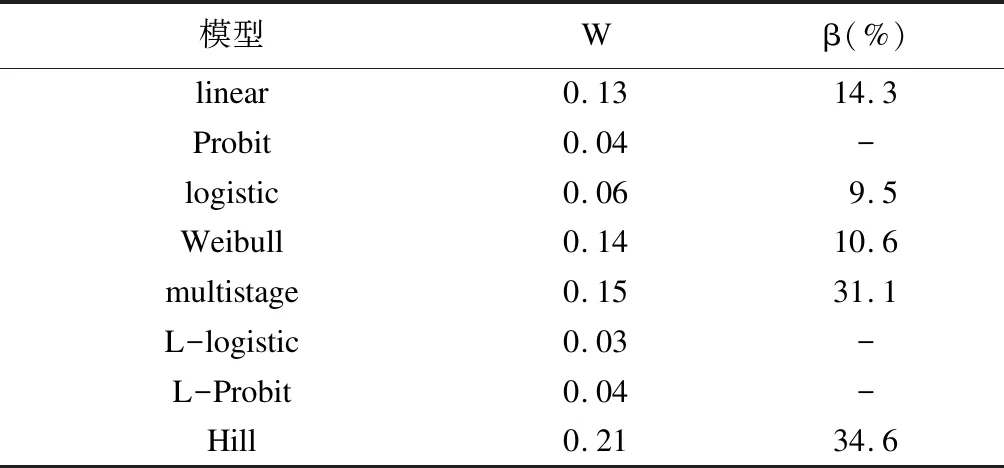
【提 要】 目的 比较BIC估计法与MCMC近似法两种后验概率法在贝叶斯基准剂量估计中的稳健性,并为山西省洪洞县儿童羟基代谢物可接受剂量的制定提供参考建议。方法 首先介绍基于BIC估计法和MCMC近似法计算后验权重的原理,模拟研究选用Integrated Risk Information System数据库中不同剂量-反应数据集共30个,分析比较两种方法的优劣,并在实例研究中采用权重法进行数据整合。结果 模拟研究结果显示在所研究的30个数据集中BIC估计法在BMR为0.01时有4个数据集出现BMDL预测失败的情况,在BMR为0.001时有1个数据集出现BMD预测失败的情况,以及6个数据集出现BMDL预测失败的情况。MCMC近似法计算的BMD/BMDL在每一种模型都有70%以上的数据集高于BIC估计法得到的BMD/BMDL。实例分析表明符合洪洞县儿童体内羟基代谢物剂量-反应关系的模型有linear(P=0.13,β=14.3%)、logistic(P=0.06,β=9.5%)、Weibull(P=0.14,β=10.6%)、multistage(P=0.15,β=31.1%)、Hill(P=0.21,β=34.6%)。在BMR为0.001的情况下,洪洞县儿童体内八种羟基代谢物(2-OHN、1-OHN、9-OHF、2-OHF、2-OHphe、1-OHphe、1-OHBaP、3-OHBaP)的可接受剂量(μmol/mol)依次为0.577 μmol/mol、1.546 μmol/mol、8.135 μmol/mol、0.359 μmol/mol、0.120 μmol/mol、0.098 μmol/mol、0.044 μmol/mol、0.003μmol/mol。结论 MCMC近似法在BMD估计中具有较好的稳定性和鲁棒性。
基准剂量(benchmark dose,BMD)是计算在有害物质背景值的基础上引起基准反应(benchmark response,BMR)不良健康效应的剂量,是危害表征的指标之一[1]。同时BMD是有毒有害化学物质在某一特定环境中可接受的最高界值,若环境中有毒有害化学物质超过这一界值就会造成人群健康寿命年的降低。BMDL(the lower confidence limit of BMD)是在规定了置信区间之后BMD的下限,它为环境工作者在制定界值范围时起到了规范作用,是经济卫生领域提高效益-收益的指标之一。1984年美国环境保护署(environmental protection agency,EPA)提出了最优模型法,即在提出的所有模型中选择赤池信息量(akaike information criterion,AIC)最小的模型计算BMD[2]。随着计算机的发展和贝叶斯算法的出现,1986年Crump提出了贝叶斯基准剂量[3](bayesian benchmark dose,BBMD),BBMD是利用贝叶斯框架提供了一种通过模型参数的先验分布来整合先验信息的方法。这对于提高低质量数据的剂量-反应建模的可靠性具有很大的潜力。同时BBMD也克服了传统方法对试验时间、试验样本和试验剂量的高要求性,从而计算出在特定要求下的BMD[4]。但有时在处理低暴露弱相关数据时,单一模型并不能完全阐明数据剂量-反应特征,若要选取最优模型,就会不可避免地放弃其他模型提供信息的可能,从而导致估计模型的不确定性[5]。为充分考虑模型的不确定性,2018年Khao将模型平均法应用在贝叶斯基准剂量中,提出了贝叶斯模型平均法(bayesian model averaging,BMA)的思想[5]。BMA是一种在BBMD方法的基础上以模型的后验概率为权重,将备选模型的不确定性考虑在内的统计学方法。它能够综合考虑不同的备选模型的权重,使分析更具有科学性和完整性[6]。BMA得以应用的关键在于计算每个模型所占的权重,目前的研究方法有基于贝叶斯信息准则(Bayesian information criterion,BIC)和马尔可夫链蒙特卡洛(Markov chain Monte Carlo,MCMC)两种[7]。本文主要目的在于比较这两种方法的优劣,并计算山西省临汾市洪洞县儿童羟基内暴露的可接受范围,为环境管理部门制定相关标准提供理论依据。
原理与方法
1.贝叶斯基准剂量估计模型
基准剂量估计首先要确定所研究的剂量-反应数据类型和基准反应,对于不同的数据类型,EPA介绍了不同种类的模型,本次着重于二分类数据的研究,主要涉及的模型包括以下八种:
linear模型:f(d)=a+(1-a)×[1-exp(-b×d)]
Probit模型:f(d)=Φ(a+b×d)
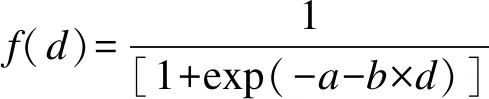
Weibull模型:f(d)=a+(1-a)×[1-exp(-b×dg)]
multistage模型:f(d)=a+(1-a)×[1-exp(-b×d-c×d2)]

Log-Probit模型:f(d)=a+(1-a)×Φ[b+g×log(d)]

其中:d为剂量(dose);a,b为单个模型的斜率和截距参数:0≤a≤1,b≥0;g为背景参数。
对定性数据基准反应的确定,一般选取额外风险或附加风险反应类型。由于额外风险在应用中不容易受到背景值的影响,表现更加稳定,所以在毒理学研究中一般选取BMR=0.01的额外风险计算,但应用于人群数据时BMR则取值更低,一般为0.001。
BMRadd=f(BMD)-f(0)
其中:f为二分类剂量-反应模型;f(BMD)为当前值;f(0)为背景值。
2.贝叶斯模型平均法
BMA就是使用BIC和MCMC计算后验分布,得到模型后验预测P值和后验权重。利用模型后验预测P值筛选出可能的多个模型,以后验权重对单一模型加权整合,最后得出所求的BMD。
BICK=-2LK+pKlog(N)
3.权重法
多环芳烃羟基代谢物属于低暴露弱相关数据,虽能够造成人体血液系统的损害,但目前没有单一代谢物与血液指标一一对应的关系,所以本次采用权重法进行数据整合[8]
统计分析均采用R 3.6.3,基准剂量估计采用BMD和BBMD软件进行计算。
4.模型的验证与评价
研究分为模拟研究和实例研究两个部分,模拟研究分别计算出两种方法的BMD以及BMDL值,设置BMR为0.01和0.001。本次研究借鉴Shao[5]等人的评价指标观察两种方法中BMD/BMDL,来评价基准剂量估计方法的可靠性,比值越低表明模型的参考区间越精确,说明其方法的精确性和可靠性越高。同时观察两种方法中数据集预测失败的例数,失败例数越低则鲁棒性越高。
模拟研究
1.数据来源
选用Integrated Risk Information System数据库(https://www.epa.gov/iris)中不同剂量-反应数据集共30个,分别采用基于BIC估计法与MCMC近似法计算BMD并做单一模型的比较。
2.两种模型评价
使用BIC估计法与MCMC近似法分别计算30个数据集中的BMD和BMDL。由表1可知,30个数据集中BIC在BMR为0.01时出现4个数据集BMDL预测失败的情况,分别为Weibull、L-logistic和Hill模型。在BMR为0.001时出现1个数据集BMD预测失败的情况,以及6个数据集BMDL预测失败的情况。MCMC近似法在两种BMR的情况下均未出现预测失败的情况。剔除预测失败的数据集之后,计算每个模型在两种方法中得到的BMD/BMDL,表2显示每一种模型都有70%以上的BIC估计法得到的BMD/BMDL高于MCMC近似法得到的BMD/BMDL(原始结果见https://github.com/motobndr/penny)。

表1 MCMC与BIC法对30个数据集计算BMD与BMDL的成功个数

表2 MCMC法对预测成功的数据集计算BMD/BMDL的合格率
实例分析
1.数据来源
选取2016-2018年山西省临汾市洪洞县焦化厂周围居住范围在2km以内的5~12岁的全部儿童。最终收集到408名合格儿童的血常规和尿中羟基代谢物(2-OHN、1-OHN、9-OHF、2-OHF、2-OHphe、1-OHphe、1-OHBaP、3-OHBaP)。
2.分析结果
对所测得的八种羟基代谢物浓度进行正态性检验,得出八种羟基代谢产物浓度均不符合正态分布(P<0.001),以中位数所占百分比代表每种代谢物浓度对血液系统影响,其权重依次为:0.053、0.142、0.747、0.033、0.011、0.009、0.004、0.0003(表3)。按权重计算408名儿童的综合羟基代谢物浓度,得出泛化的剂量-反应关系并按总人数等分为10组(表4)。

表3 洪洞县儿童尿中不同羟基代谢物在综合剂量中的权重

表4 洪洞县儿童在不同剂量组下血常规异常人数
选取EPA所提供的所有二分类模型,设置MCMC中迭代次数为30000,选取一条马尔可夫链条,以50%的样本量作为预热。计算模型符合的后验预测值(W),随机种子数设置为82063。以0.05 图1 五种入选模型的剂量-反应关系 表5 不同模型的后验预测值和对应权重 为了得到更加安全的BMD,设置BMR=0.001,计算单一模型和平均法模型的BMD与BMDL(表6)。按权重分别计算各个羟基代谢物的内暴露可接受剂量(表7)。 表6 单一模型和BMA计算综合内暴露可接受剂量(μmol/mol) 表7 八种羟基代谢物内暴露可接受剂量(μmol/mol) BMD估计目前有参数法、非参数法、半参数法和模型平均法四种类型。其中参数法分为频率论参数法和贝叶斯参数法,频率论参数法最为简单而且效率高,但在多个模型的比较中若AIC都比较接近时就会出现选择最佳模型而忽略其他模型可能性问题,即模型的不确定性的问题[9]。非参数法和半参数法虽然不拘泥于模型的选择而且可以更精准地拟合剂量-反应关系[10],但非参数建模相关的狄利克雷先验法以及半参数建模相关的概率核和三次B样条,其计算方式复杂,检验效率低,而且有较高的过拟合风险,所以非参数法和半参数法一直作为参数法的补充方法,最关键的是目前没有一种成型非参数或者半参数算法可以广泛地为环境工作者所用。BMA是贝叶斯参数法的衍生方法,其采用后验概率计算参数模型的权重,既解决了单个参数模型不确定性的问题,同时也保留了效率高的优点。更重要的一点是BMA在理解和计算上要优于非参数和半参数模型,对于环境专业的工作者具有很强的实用性。 利用BIC估计法对30个数据集进行计算时,在BMR为0.01时出现4个数据集的BMDL估计失败的情况。在BMR为0.001时出现1个数据集的BMD估计失败的情况以及6个数据集的BMDL估计失败的情况,即随着BMR的降低,BIC估计法会出现更多无法估计的情况,同时也会降低BIC估计法在低暴露弱相关数据中的应用范围。目前EPA提出[8]BMR的最小取值为0.001,本次研究表明在不同剂量-反应关系下MCMC近似法并没有出现BMD或BMDL值估计失败的情况,这与Shao的研究一致[11]。BMD/BMDL比值经常用于基准剂量模型估计效果的评价,通常BMD/BMDL越低,表示模型的稳定性和可靠性越好[5]。模拟结果显示,MCMC得到的BMD/BMDL在总体上要低于BIC得到的BMD/BMDL,所以MCMC在实际应用中具有较高的参考价值。 洪洞县隶属于山西省临汾市,地处山西省南部,临汾盆地北端。其特点是工业产业聚集,特别是焦化业。2018年央视新闻报道,洪洞县有以三维集团为首的焦化厂常年违规排放污水、废气造成严重的环境污染,也对工厂周围的村民造成了一定程度的危害[12]。相关研究表明儿童可能对这些暴露更为敏感。在空气污染浓度相同的情况下,儿童较弱的新陈代谢能力会导致其体内羟基代谢物水平更高[13]。多环芳烃不仅对儿童智力发育、行为和免疫功能有影响,而且可能与儿童情绪烦躁、易怒、记忆力降低以及注意力缺乏有关[14-15]。因此,了解污染区儿童羟基的内暴露风险十分重要。本次研究采用基于五种函数建立MCMC贝叶斯平均法模型估算羟基代谢物内暴露对应的BMD,得出在BMR为0.001时八种羟基代谢物,以期为当地环境部门制定相关安全剂量提供参考。


讨 论
