玉米中伏马毒素B污染高光谱快速检测模型研究
2023-10-18康孝存沈广辉徐剑宏马桂珍史建荣
康孝存, 沈广辉, 徐剑宏, 马桂珍, 史建荣
(江苏海洋大学1,连云港 222000) (江苏省农业科学院农产品质量安全与营养研究所;江苏省食品质量安全重点实验室-省部共建国家重点实验室培育基地;农业部农产品质量安全控制技术与标准重点实验室2,南京 210014)
伏马毒素(Fumonisin)是由串珠镰刀菌、层出镰刀菌等产生的一种水溶性次级代谢产物,广泛存在于玉米及其制品中,具有神经毒性、器官毒性、免疫毒性、致癌性等危害[1]。目前分离发现的伏马毒素有30余种,主要为A、B、C和P 4类,其中Fumonisin B(FB)是污染最为普遍、毒性最强的一类,且FB1被国际癌症研究机构(IARC)列为2B类致癌物[2]。鉴于FB的危害,多个国家和地区制定了最大残留限量标准(MRLs)。美国食品药品监督管理局规定,供人食用的玉米制品中的FBs(FB1+FB2+FB3)的含量最高为2~4 mg/kg[3],欧盟规定玉米中FBs(FB1+FB2)的MRLs为4 mg/kg[4],我国尚无相关限量标准。
常用的FBs检测方法有液相色谱[5]、薄层色谱[6]、液相色谱-串联质谱法[7]、酶联免疫吸附法[8]等,这些方法虽然检测精度高、重复性好,但存在样品前处理复杂,检测成本高等缺点,难以满足大量样品的快速分析。因此,急需要一种简便、低成本的快速检测方法。
高光谱成像作为一种新兴的无损检测技术,能同时获取样品的空间和微观尺度的光谱信息,不仅在农产品新鲜度识别[9]、产地溯源[10]、营养成分含量分析[11]等方面得到了广泛应用,在谷物霉变及真菌毒素污染的检测中也有相关报道,如殷勇等[12]利用高光谱成像技术结合特征波长筛选算法对6个霉变等级的玉米进行了快速鉴别,识别正确率高达98.6%;沈广辉等[9,10]基于高光谱成像技术不仅实现了小麦赤霉病瘪粒的快速识别,还对单个小麦籽粒中的呕吐毒素含量进行了定性和定量分析;He等[15]基于可见/近红外高光谱成像技术,通过融合光谱及纹理特征,实现了花生黄曲霉毒素B1的污染等级的快速判别。高光谱成像技术在谷物真菌毒素检测中具有巨大应用潜力,但将高光谱成像技术用于玉米FBs污染检测的报道十分有限。
高光谱数据维度高、数据量大、冗余信息多,玉米中FBs含量分布极不均匀,如何提取特征信息构建高精度分析模型有待研究。反向传播(BP)神经网络是一种多层前馈神经网络,具有优良的非线性映射能力,被广泛应用于光谱数据建模分析,但BP神经网络训练过程中,各神经元的权值和阈值是随机的,使得网络输出结果不稳定。麻雀搜索算法(SSA)是一种新型的群智优化算法[16],具有较强的局部和全局搜索能力,收敛速度快,可用来优化BP神经网络的初始权值和阈值,来增强网络的稳健性。因此,本研究将从特征变量筛选方法入手,使用SSA对BP神经网络进行优化,构建玉米中FBs污染的定性和定量分析的模型,并与偏最小二乘判别分析(PLS-DA)和PLS回归模型结果进行对比,以期为玉米中FBs污染的检测提供一种快速分析方法。
1 材料与方法
1.1 实验材料
从山东、吉林、贵州、河南、江苏等省份共采集玉米样品178份,清理去除杂质后用实验室研磨机进行高速粉碎,每个样品约2 min。将每个样品分为2部分,一部分用于高光谱数据获取,另一部分用于伏马毒素含量测定。
1.2 高光谱成像系统及数据采集
GaiaField-N17E近红外高光谱成像系统采用线扫描方式,波长范围为900~1 700 nm,配备InGaAs探测器,相机分辨率为320×256,光谱分辨率为5 nm,光源为2个卤素灯穹顶光源。将玉米粉混匀后取部分样品装入培养皿(d=5 cm,h=1 cm),刮平样品表面后置于高光谱设备检测位移平台,以4行×2列方式摆放,每次检测8个样品。仪器开机预热30 min,设置镜头与样品间距为30 cm,曝光时间21.8 ms,平台运动速度0.6 cm/s。样品扫描完成后,根据式(1)进行黑白校正,以消除暗电流和光源分布不均匀带来的噪声。
(1)
式中:I为黑白校正后的图像信息;I0为原始获取图像信息;B为黑色标定背景信息;W为白板标定图像信息。
1.3 玉米粉样品光谱提取
从每个样品的校正图像中心位置,选取70像素×70像素的方形区域作为感兴趣区域,提取区域内的4 900条光谱,计算平均值作为此玉米样品的光谱信息。原始样品光谱共256个波段(波长范围:900~1 700 nm),由于光谱两端噪声较大,因此截取第23到222个波段(波长范围:969~1 595 nm)用于后续数据分析。
1.4 伏马毒素含量测定
参考GB 5009.240—2016《食品安全国家标准食品中伏马毒素的测定》测定玉米样品中伏马毒素含量。
1.5 数据处理方法
1.5.1 数据分集
研究涉及玉米中FBs(FB1+FB2)污染水平的定性和定量分析两部分研究内容,在定性分析中,以欧盟限量标准为阈值,将玉米样品分为未超标和超标两类,其中未超标样品共79个,设置标签为1,超标样品99个,设置标签为2,然后采用K-stone方法将样品按照3∶1比例分为校正集和验证集;在定量分析中,按照浓度梯度法将样品按照3∶1比例分为校正集和验证集。
1.5.2 特征变量筛选算法
由于高光谱数据维度高,波段间相关性较强,使用全谱段构建分析模型时容易引入过多冗余信息,不仅增加模型计算的复杂性,还会影响模型分析精度。分别采用竞争性自适应重加权算法(CARS)[17]和连续投影算法(SPA)[18]对高光谱数据进行降维,筛选特征变量。CARS是一种基于蒙特卡洛采样构建偏最小二乘(PLS)回归模型的特征变量筛选方法。CARS通过指数衰减函数和自适应加权采样方法,去除PLS模型中回归系数权重较小的变量,然后通过交互验证选取最小验证均方根误差(RMSECV)对应的变量集。SPA是一种前向变量选择算法,运用向量投影选择最大向量,通过循环提取,获取共线性最小的变量组合,去除冗余信息。
1.5.3 BP神经网络
BP神经网络是一种多层前馈神经网络,具有很强的非线性映射能力[19]。BP神经网络包括输入信号正向传递和误差信号反向传递2个过程,使用最速下降法,通过反向传播不断调整输入层和隐含层、隐含层和输出层各神经元的权值和阈值,使网络误差减小。研究采用单隐含层神经网络(图1),输入层到隐含层采用S型正切传递函数tansig,隐含层到输出层采用线性传递函数purelin,训练函数为trainlm。在玉米FBs污染水平的定性分析中,输出层节点为2个,分别为类别标签1和标签2;在定量分析中,输出层节点数为1个,对应FBs的含量。但BP神经网络训练过程中,各神经元的权值和阈值是随机的,使得网络输出结果不稳定。

图1 BP神经网络结构图
1.5.4 SSA算法优化BP神经网络
SSA算法是受麻雀的觅食行为和反捕行为启发,提出的一种新型群智优化算法。其将群体分为发现者、加入者和预警者,通过三者间相互配合寻找最优值。由于SSA算法具有较强的局部和全局搜索能力,收敛速度快,因此,可用来优化BP神经网络的初始权值和阈值,增强网络的稳健性。SSA-BP神经网络计算具体步骤为:
数据归一化处理。将玉米样品原始光谱数据,判别分析标签或者FBs污染含量均归一化到0~1之间。
确定BP神经网络的拓扑结构。根据筛选出的高光谱特征变量数,确定输入层节点数(m)和输出层节点数(n),其中,定性和定量分析中输出层节点数分别为2和1;然后,根据式(2)计算隐含层节点数p的优化范围。
(2)
式中:α为1~10之间的整数。
SSA算法参数初始化。设定SSA算法初始种群规模为30,最大进化代数为50次,发现者比例为0.7,预警者比例为0.2。
计算个体适应度。根据初始权值和阈值训练BP神经网络,将训练集均方误差与测试集均方误差的平均值作为适应度函数,根据适应度的值找到全局最优解,确定其对应的位置。
麻雀位置更新。进行迭代计算,使用适应度较好的个体对发现者进行位置更新,同时对加入者和预警者进行位置更新。
迭代条件及适应度更新。计算位置更新后的个体适应度值,并与当前最优适应度值比较,达到最大迭代次数之后选择全局最优解;否则,再次进行迭代。将迭代计算获取的最优解作为初始权值和阈值,代入之前确定的BP神经网络进行训练,然后使用SSA优化后的BP神经网络进行预测分析。
所有数据处理均在Matlab 2014a中借助PLS_Toolbox 8.0和神经网络工具箱完成。
2 结果与讨论
2.1 玉米样品光谱分析
含有不同FBs污染含量的玉米粉样品的近红外反射光谱如图2所示,所有样品光谱均在990、1 200、1 465 nm附近具有明显的吸收峰,这些峰与玉米组成成分中的C—H、O—H和N—H基团伸缩振动的组合频和倍频吸收有关。其中,990 nm附近为O—H伸缩振动的二级倍频,能反映淀粉的吸收[20];1 200 nm附近为C—H伸缩振动的一级倍频或二级倍频,不仅与油脂的吸收相关,也能反映真菌细胞壁中几丁质的信息[21];1 465 nm附近与玉米中水和蛋白的吸收有关[22]。玉米中FBs污染水平不同,样品光谱反射率存在较大差异,整体上样品光谱反射率随FBs污染浓度增加而升高,但这种趋势并不是绝对的。结果表明,近红外光谱能反映玉米中FBs污染信息,但需要借助化学计量学方法进行深入分析。
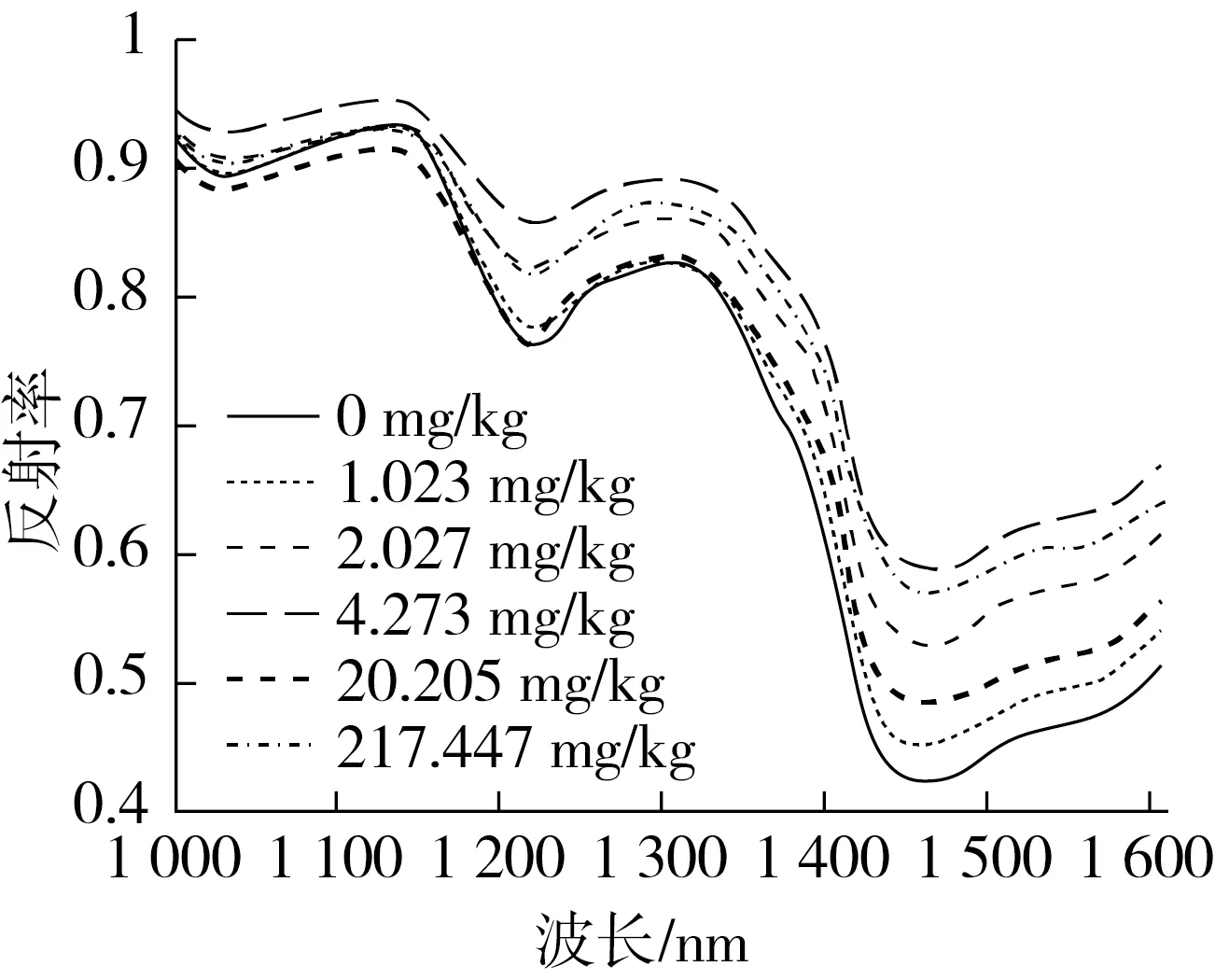
图2 玉米粉样品反射谱图
2.2 玉米样品FBs含量分析
研究共采集玉米样品178份,参考国家标准GB 5009.240—2016对样品中FBs含量进行分析,结果如表1所示。玉米样品中FBs的污染含量在0~217.45 mg/kg之间,平均值为24.78 mg/kg,其中有99个样品的FBs含量高于欧盟MRL,所有样品变异系数为173.50%,说明样品含量分布不均匀,大部分样品集中在低含量范围内。定量分析中验证集样品的含量范围包含在校正集样品中,说明分集合理。
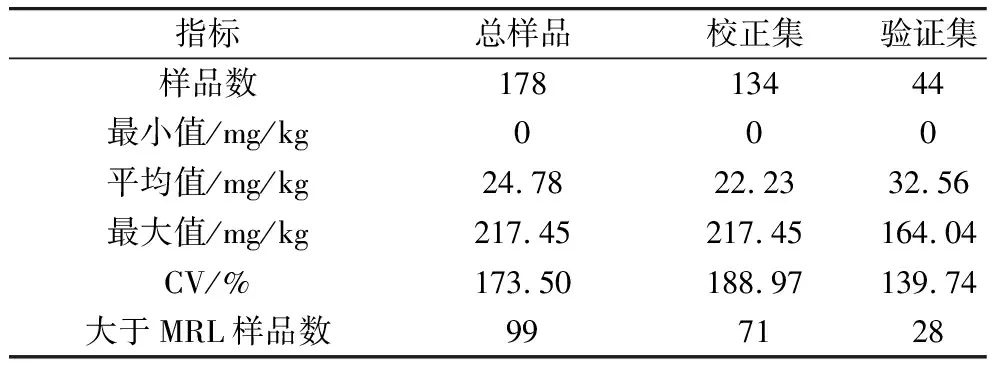
表1 玉米样品中FBs含量统计分析结果
2.3 玉米样品PCA分析
以欧盟MRL为阈值,将玉米样品分为超标和未超标2类,并通过主成分分析(PCA)探究基于玉米粉高光谱区分不同FBs污染程度的可行性。如图3所示,PCA前3个主成分的累积方差贡献率为99.94%,解释了原始光谱的绝大部分信息,超标(方块)和未超标(菱形)样品在主成分空间中具有明显的分类趋势,但并未完全分开,说明高光谱能反映玉米粉中FBs的污染水平,可进一步借助有监督模式的方法进行判别分析。
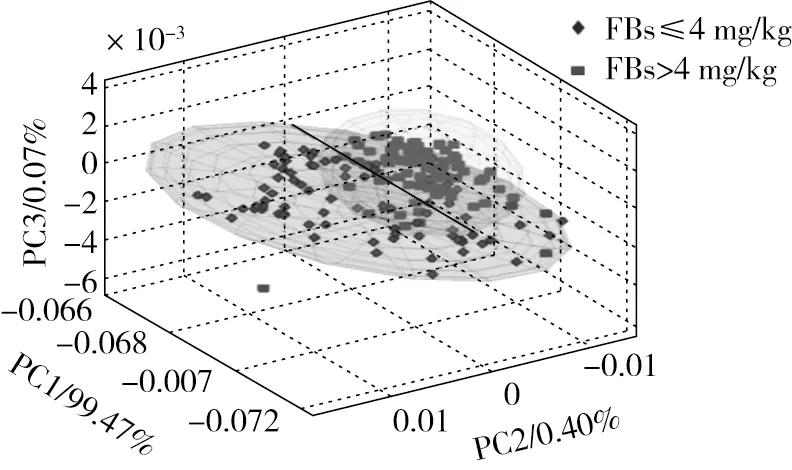
图3 主成分得分图
2.4 玉米中FBs污染水平判别分析
2.4.1 判别分析特征变量提取
为去除光谱中的冗余信息,降低模型计算的复杂程度,提高模型的稳健性,分别采用CARS和SPA两种算法提取特征变量,构建判别分析模型。CARS筛选特征变量时采用10折交互验证,提取的PLS最大主成分数为10,蒙特卡洛采样500次,重复进行10次,以交互验证均方根误差为评价指标,共筛选出12个特征变量,如图4a和表2所示。SPA算法筛选特征变量时指定变量数为5~30之间,共筛选出22个特征变量,如图4b和表2所示。通过对比可知,SPA算法筛选出的变量数比CARS算法多,其中975.3、1 009.9、1 594.8 nm为2种算法筛选出的相同特征波长,在1 418.7、1 447.0 nm处筛选的特征波长相邻,说明2种方法提取的与FBs污染程度相关的特征变量具有相似之处。
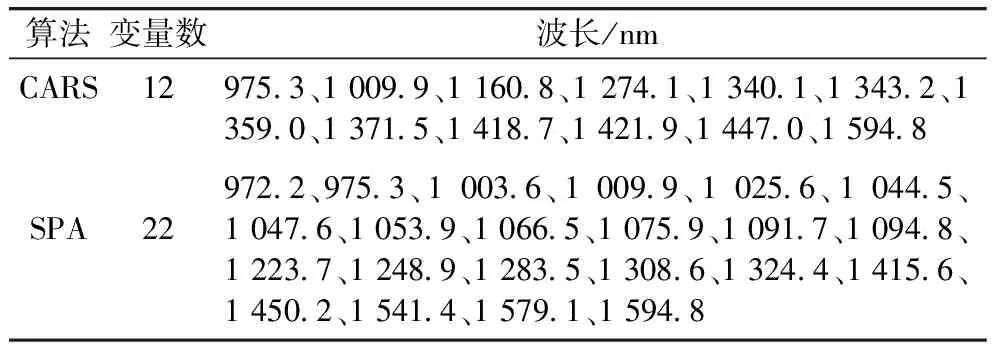
表2 判别分析中CARS和SPA算法筛选的特征变量

图4 判别分析中筛选出的特征变量点
2.4.2 判别分析模型结果对比
基于CARS算法和SPA算法筛选的特征变量,分别采用PLS-DA、BP和SSA-BP 3种不同的算法构建玉米中FBs污染水平的判别分析模型,并与基于全波段构建的Full-PLS-DA和Full-BP模型结果进行对比,结果如表3所示。Full-PLS-DA模型的样品总识别正确率为95.56%,经CARS和SPA提取特征变量后,构建的PLS-DA模型样品总识别正确率均为93.33%,与Full-PLS-DA模型识别精度相差不大,表明CARS和SPA算法均有效消除了原始光谱中的冗余信息。与Full-BP神经网络模型结果相比,CARS-BP和SPA-BP神经网络的模型总识别正确率分别由91.11%下降为88.89%和86.67%,其中,2种BP神经网络的超标样品识别正确数均为24,但未超标样品的误判数增多。使用SSA算法对基于特征变量构建的BP神经网络进行优化,并对外部验证集进行预测,CARS-SSA-BP和SPA-SSA-BP神经网络的样品总识别正确率分别为91.11%和95.56%,较基于特征变量的BP神经网络有较大的提升,SPA-SSA-BP神经网络仅用了原始光谱约1/10的变量,且其模型精度最高,并与Full-PLS-DA结果相同。结果表明,基于高光谱对玉米中FBs污染等级进行判别分析具有可行性,CARS和SPA两种算法均可有效消除冗余信息,降低计算复杂程度,且SSA算法具有通过对BP神经网络的初始权值和阈值进行优化,提升模型的稳健性,改善BP神经网络预测精度的能力。

表3 判别分析结果
2.5 玉米中FBs污染水平定量分析
2.5.1 定量分析特征变量提取
在定量分析特征变量筛选过程中,CARS算法采用10折交互验证,提取的最大主成分数为20,蒙特卡洛采样200次,重复进行10次,以交互验证均方根误差为评价指标,共筛选出31个特征变量,如图5a和表4所示。SPA算法筛选特征变量时指定变量数为5~30之间,共筛选出15个特征变量,如图5b和表4所示。通过对比可知,CARS筛选出的特征变量数是SPA算法的2倍多,其中,1 314.9、1 582.2 nm为2种算法提取的相同变量。在969~1 315 nm波长范围内,SPA算法筛选的大部分特征变量均可在CARS提取结果中找到相邻变量,而在1 315~1 595 nm范围内,2种算法筛选的特征变量差异较大。
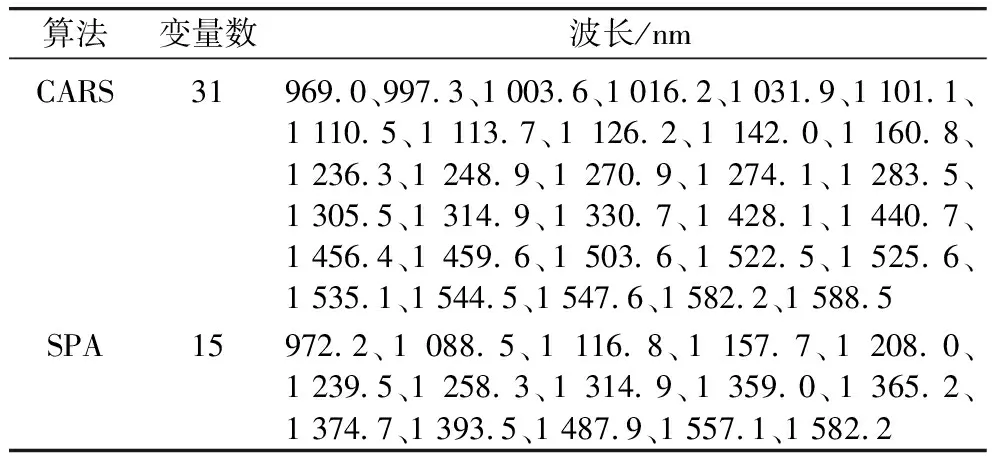
表4 定量分析中CARS和SPA算法筛选的特征变量
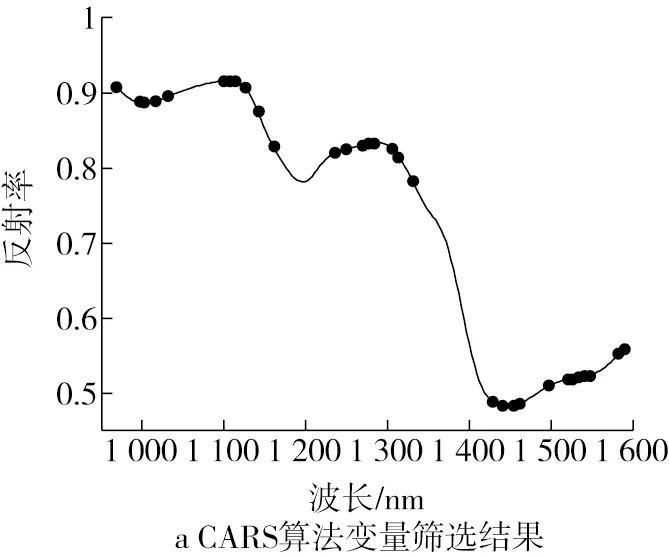
图5 定量分析中筛选出的特征变量点
2.5.2 定量分析模型结果对比
分别使用全波段和特征变量构建PLS和BP神经网络模型,对玉米中FBs污染水平进行定量分析,并使用SSA算法对基于特征变量构建的BP神经网络进行优化,通过决定系数(R2)、校正集均方根误差(RMSEC)、验证集均方根误差(RMSEP)以及验证集标准偏差和RMSEP的比值RPD对模型性能进行评价,各模型分析结果如表5所示。基于全波段构建的Full-PLS定量分析模型的Rp2、RMSEP、RPD分别为0.90、14.75、3.08,CARS-PLS和SPA-PLS模型的Rp2、RMSEP、RPD分别为0.91、14.96、3.04和0.88、16.01、2.84。CARS-PLS模型预测精度高于SPA-PLS模型,且在仅使用31个特征变量的情况下,预测精度与Full-PLS模型相当,表明CARS算法能有效提取原始光谱中的特征信息。基于全谱段构建的Full-BP神经网络的Rp2、RMSEP、RPD分别为0.89、15.84、2.87,预测精度略低于Full-PLS模型,经CARS和SPA算法提取特征变量后,CARS-BP和SPA-BP神经网络模型的RPD分别升高为3.27和3.40,且优于CARS-PLS和SPA-PLS模型结果。使用SSA算法对CARS-BP和SPA-BP神经网络进行优化,CARS-SSA-BP神经网络的RMSEP由13.91降低为12.41,RPD由3.27升高为3.64,但SPA-SSA-BP神经网络的预测精度变化不大。在所有模型中,CARS-SSA-BP神经网络模型预测精度最高,SPA-SSA-BP模型次之。结果表明,在基于高光谱对玉米FBs污染水平的定量分析中,CARS算法和SPA算法仅降低了PLS模型计算复杂程度,预测精度并未得到改善,但特征变量的提取既能缩短BP神经网络计算时间,也能提升模型预测精度,SSA算法通过对BP神经网络初始权值和阈值进行优化,可进一步提升BP神经网络预测能力。
3 结论
研究使用高光谱成像系统获取玉米粉样品图谱信息,通过CARS和SPA筛选高光谱特征变量,结合化学计量学算法对玉米粉中FBs的污染水平进行定性和定量分析。
不同FBs污染水平的玉米粉样品在主成分空间具有明显的分类趋势,且随污染水平的不同,样品光谱反射率存在较大差异,表明样品高光谱能够获取玉米粉中FBs的污染信息。
在玉米FBs污染水平的判别分析中,基于特征变量构建的BP神经网络模型总识别正确率低于PLS-DA模型,但经SSA算法优化后,BP神经网络模型识别正确率提高,CARS-SSA-BP和SPA-SSA-BP神经网络的总识别正确率分别为91.11%和95.56%,与原始光谱模型识别精度相当。
在玉米FBs污染的定量分析中,基于特征变量构建的BP神经网络模型RPD均高于PLS模型,且经SSA算法优化后,CARS-SSA-BP和SPA-SSA-BP神经网络的RPD进一步分别升高为3.62和3.46,预测精度优于原始光谱模型。
CARS算法和SPA算法都能有效提取样品高光谱特征变量,去除冗余信息,降低模型计算复杂程度,且通过SSA算法优化BP神经网络,能提高预测模型的稳健性和精度,研究可为玉米中FBs污染提供一种快速检测方法。
