基于层次注意力机制的源代码迁移模型
2023-10-17李征徐明瑞吴永豪刘勇陈翔武淑美刘恒源
李征 徐明瑞 吴永豪 刘勇 陈翔 武淑美 刘恒源


摘 要:针对源代码迁移模型存在的迁移代码语义一致性问题,在词符注意力机制的基础上引入了语句注意力机制,提出了一种基于层次注意力机制的源代码迁移模型HPGN(hierarchical pointer-generator network),设计了状态传递机制。HPGN在迁移过程中,语句注意力机制对齐源代码语句和迁移代码语句的特征,词符注意力机制从对齐的代码语句中提取词符,状态传递机制传递相邻迁移代码语句的特征,从而提升了迁移代码的语义一致性。在真实项目数据集的实验结果表明,HPGN比最佳对比模型提高了3.4个总体分值,同时有着更少的模型参数量。此外,消融实验验证了状态传递机制和HPGN层次架构的有效性。
关键词:代码迁移;代码语句;机器翻译;注意力机制
中图分类号:TP311.5 文献标志码:A 文章编号:1001-3695(2023)10-031-3082-09
doi:10.19734/j.issn.1001-3695.2023.03.0093
Source code migration model based on hierarchical attention mechanism
Li Zheng1,Xu Mingrui1,Wu Yonghao1,Liu Yong1,Chen Xiang2,Wu Shumei1,Liu Hengyuan1
(1.College of Information Science & Technology,Beijing University of Chemical Technology,Beijing 100029,China;2.School of Information Science & Technology,Nantong University,Nantong Jiangsu 226019,China)
Abstract:To address the semantic consistency problem of migrated code in the source code migration model,this paper introduced the statement-level attention mechanism based on the token-level attention mechanism,proposed a source code migration model HPGN based on the hierarchical attention mechanism,and designed state feeding mechanisms.During migration,the statement-level attention mechanism aligned the features of source code statements and migrated code statements,the token-level attention mechanism extracted tokens from the aligned code statements,and the state feeding mechanism passed the feature of adjacent migrated code statement,thus improving the semantic consistency of migrated code.Experimenting on a real project dataset,the results show that HPGN improves the overall score by 3.4 over the best comparison model while having fewer model parameters.In addition,ablation experiments validate the effectiveness of the state feeding mechanisms and HPGN hierarchical architecture.
Key words:code migration;code statement;machine translation;attention mechanism
0 引言
随着计算机软硬件的快速更新,编程语言也在不断发展与迭代。为了适应新的软硬件环境,传统的业务系统需要采用新的编程语言重写代码,这一过程称为代码迁移。然而,现代工业项目的代码规模庞大,实现代码迁移既耗时又容易出错[1]。因此,研究人员尝试研究源代码迁移技术来解决这一问题,期望在不改变程序语义的情况下,将源代码转换成目标代码,从而减轻开发人员的负担。最初的研究采用基于规则的方法迁移源代码[2]。这种方法需要开发人员为不同编程语言提供正确且完整的转换规则,导致源代码迁移模型的开发流程低效且容易出错。为了自动构建源代码迁移模型,研究人员受到自然语言翻译研究工作的启发,提出了基于统计机器翻译(statistical machine translation,SMT)的源代码迁移模型[3~5]。然而此类方法受限于模型的理解能力[3],需要人工定义语法规则或迁移模板的方式辅助模型生成迁移代码[4,5]。随着神经机器翻译(neural machine translation,NMT)模型的快速发展,研究人员开始采用NMT模型实现自动化的代码迁移工作[1,6,7]。这些研究通常采用序列到序列模型,把代码文本作为模型的输入,让模型学习不同编程语言的迁移规则。然而,一些研究表明此類模型忽略了代码结构特征,让模型难以有效地理解源代码的语义[8,9]。因此,当前研究面临的难点是如何使模型从源代码中获取特征,并将其转换为语义更准确的目标代码。
为了解决该问题,有研究提出使用翻译模型翻译源代码结构特征实现源代码迁移。例如,Chen等人[10]提出了一种基于解析树的树到树(tree-to-tree)翻译模型,通过注意力机制对齐源代码的抽象语法树(abstract syntax tree)并转换为目标代码的抽象语法树。该实验证明注意力机制能对齐源代码和目标代码抽象语法树的节点,提升代码迁移的准确性。然而,该方法受限于解析树本身存在的不足:a)抽象语法树会忽略某些语义节点,例如“+”“>”“≤”和其他一些符号会被抽象化为BinOpSub节点[11],这样的解析树不适合用于代码迁移;b)具体语法树(concrete syntax tree)包含源代码中每个词的结构特征,但其语义节点较多,增加了模型理解和生成代码的难度。另一个可行的策略是对大量模型参数的注意力机制神经网络进行预训练,然后在代码迁移任务上微调至最佳效果。这种方法的有效性得益于深度Transformer模型的理解和生成能力[12]。但许多研究[1,6,7,13]仍把代码文本作为模型输入,忽略了代码结构特征。除此之外,基于对已有源代码迁移工作的分析可以发现,这些工作通常从解析树和模型的角度提升迁移代码的精度,很少关注迁移代码的语义一致性问题,导致迁移代码和源代码的语义存在差异。
为了解决上述问题,本文提出在代码迁移过程中,引导模型关注代码语句的语法和语义特征,以提升代码迁移的语义一致性。Hindle等人[14]证明了编程语言是重复性高、可预测性强的语言,并且比自然语言更有规则。Zhang等人[15]通过实验证明代码语句的语法具有规则性,并且代码语句序列也具有顺序依赖关系。这些研究说明了代码语句的语法是可预测的,并且代码语句间存在上下文联系。此外,通过分析代码迁移数据集可以发现,许多语义相似的源代码和目标代码的语句中有着相似的关键字、标识符和运算符等词符特征。因此,在源代码转换为目标代码的过程中,可以通过注意力机制对齐并转换源代码和目标代码语句级别的语法和語义特征,从而进一步提高代码迁移的精度。
基于上述研究的启发,本文在词符(token)注意力机制的基础上,引入语句(statement)注意力机制,提出了基于层次注意力机制的代码迁移模型HPGN(hierarchical pointer-generator network)。该模型由层次编码器(词符编码器和语句编码器)和层次译码器(词符译码器和语句译码器)组成。HPGN的源代码迁移流程主要包括:首先,层次编码器编码源代码语句序列,提取源代码语句内的语法和语义特征以及语句间上下文特征;其次,语句译码器通过语句注意力机制译码目标代码的语句特征,并对齐源代码语句;最后,词符译码器通过词符注意力机制,从对齐的源代码语句中提取词符,并依据目标代码语句特征生成完整的目标代码语句。
基于上述流程,本文为HPGN设计了残差和门控两种状态传递机制,并用指针生成网络(pointer-generator network)设计了新的损失函数。状态传递机制让层次译码器捕获相邻语句的上下文特征,提升译码质量。损失函数采用新的惩罚机制,以惩罚不均衡的语句级别和词符级别注意力分布。
本文提出了基于层次注意力机制的源代码迁移模型HPGN,该模型在词符注意力机制的基础上引入了语句注意力机制,从而更好地在代码迁移过程中保持语义的一致性;设计了两种状态传递机制,使层次译码器在译码时能够获取更丰富的相邻代码语句上下文特征,进而提升译码质量。
1 相关技术
1.1 门控循环单元
综上所述,指针生成网络能用注意力机制生成或提取词符。HPGN采用该网络注意力机制,有助于对齐源代码语句和提取语句中的关键字、标识符和运算符等词符,保持迁移代码的语义一致性。
2 基于层次注意力机制的源代码迁移模型
本文把源代码迁移任务转换为源代码语句到目标代码语句的翻译任务,即在不改变源代码语义情况下把源代码语句序列转换成目标代码语句序列。
该任务包括三个子任务:
a)理解源代码每条语句的语法和语义特征以及语句序列的上下文关系,进而提取源代码特征;
b)依据源代码特征和源代码每条语句的特征,通过对齐源代码语句的方式预测目标代码的语句特征;
c)从对齐的源代码语句中提取词符,并依据目标代码的语句特征生成符合目标代码语法的语句。
为实现源代码迁移,本文引入语句注意力机制,提出基于层次注意力机制的源代码迁移模型HPGN,其架构如图2所示。该模型由层次编码器和层次译码器组成。层次编码器用于实现子任务a),层次译码器用于实现子任务b)和c)。
此外,本文设计的状态传递机制作用于层次译码器,以捕获更丰富的相邻语句的上下文特征。本章将详细介绍数据预处理方法、层次编码器、层次译码器以及状态传递机制。
2.1 数据预处理
不同的编程语言的编程格式并不一样,而神经网络从格式不统一的代码中提取特征较为低效。为了解决该问题,本文设计了三个步骤,把代码格式化为统一风格的代码语句序列:a)格式化并划分代码语句;b)训练分词器,分割语句词符;c)规范化语句的格式。
为了划分出统一格式的代码语句,本文首先采用了格式化工具Astyle(http://astyle.sourceforge.net/)对所有代码片段格式化。格式化后的代码片段划分成语句序列,使得代码文本具有语句级别的顺序关系。为了对源代码分词,本文采用了Tokenizers(https://huggingface.co/docs/tokenizers/index)工具训练了字节对编码(Byte-pair encoding,BPE)分词器。该分词器能够从数据集的代码语句中学习词符的合并规则,并建立子词(subword)单词表,使得代码中不常见的标识符能映射至多个词符,而不是被替换为未知词符〈unk〉。例如,标识符“addAll”可能会被映射成词符“add”和“All”。字节对编码分词器不仅保留了源代码的语义,还解决了不常见的标识符导致的OOV(out-of-vocabulary)问题。
最后,规范化代码语句的序列和格式。为了使词符译码器能够生成有限长度的代码语句,输入序列首尾分别插入词符〈s〉和〈/s〉用于引导词符开始预测和结束预测。同理,本文定义了语句序列[〈s〉,〈Sart〉,〈/s〉]和[〈s〉,〈/Sart〉,〈/s〉]用于引导语句开始预测和结束预测。为了让层次译码器预测未来的输出,语句序列和词符序列向前移动一个位置作为层次译码器输出的目标。此外,为了将长度不一致的语句并行地输入给网络,本文设计了两种长度规范化操作:
a)对于限制长度以内的语句,使用词符〈pad〉对序列进行填充,直至达到限制长度。
b)对于超过限制长度的语句,则按照限制长度对语句进行截断;随后以词符〈line-break〉为首,拼接上语句的剩余部分作为下一条语句。
如图3所示,本文对源代码语句进行了如下操作。对于长度在限制范围内的原语句1、3和4,直接采用a)操作,即在末尾填充〈pad〉;对于长度超出限制的原语句2,先采用b)操作,即根据限制长度截断该语句,并用〈line-break〉拼接剩余部分,然后再采用a)操作对剩余部分进行填充。
数据预处理完成后,词嵌入网络将语句序列的每个词符映射成可训练的h维表征向量。这些向量输入到层次编码器和层次译码器中,模型开始进行训练和更新。
2.2 层次编码器
层次编码器包含词符编码器和语句编码器,用于编码代码词符序列和代码语句序列以获得代码的特征向量。为了更好地表征源代码,该网络旨在理解每条源代码语句的语法和语义特征,以及语句间的结构和上下文。具体而言,首先词符编码器将词符表征向量编码为语句上下文向量,然后语句编码器将语句上下文向量编码为源代码上下文向量。
2.2.1 词符编码器
如图2左下角所示,词符编码器是一个双向的GRU神经网络,用于理解源代码语句的語法和语义特征。词符编码器编码代码语句S为上下文向量CS和隐藏状态HS。其中,CS是由双向GRU的两个最终隐藏状态经全连接网络映射得到的。对于一组词符序列表征向量Xi=[Xi1,Xi2,…,Xim],语句上下文向量Cxi和隐藏状态HXi的计算公式如下:
其中:Concat是将多个维度相同的向量按元素级别拼接的操作;Dense是全连接网络,它将输入向量映射为h维的向量。通过词符编码器对代码语句进行表征,语句上下文向量CXi包含代码语句Xi的语法和语义特征,隐藏状态HXi包含代码语句中每个词符的上下文特征。
2.2.2 语句编码器
语句编码器与词符编码器具有相同的架构和类似的功能,但它用于从代码语句上下文向量的序列中获取代码语句间的结构特征和上下文特征。具体而言,语句编码器从一组代码语句上下文CX=[CX1,CX2,…,CXn]获取语句的隐藏状态H和代码上下文向量C,其公式表示为
2.3 层次译码器
层次译码器由语句译码器和词符译码器组成,并结合了词符编码器。在这里,词符编码器协助层次译码器预测目标语句特征的特征,而层次译码器通过对齐源代码语句及其词符来预测目标语句。当层次编码器完成源代码的表征,层次译码器利用层次编码器的特征(代码上下文向量C、语句隐藏状态H和词符隐藏状态HXi)和来自词符编码器的语句上下文向量Yi预测目标代码语句。
2.3.1 语句译码器
语句译码器的架构与指针生成网络的译码器架构类似,但它的目的是预测下一条目标代码语句的上下文向量,并用语句注意力机制来对齐源代码语句。为了消除不相关语句的注意力分布,增强两种语言相关语句的对应关系,同时减少计算量和加快训练速度,本文设置了语句注意力机制,使其对齐源代码中最相关的k条语句。为了进行预测和对齐操作,语句译码器使用语句编码器的输出(代码上下文向量C、语句隐藏状态H),并在词符编码器协助下进行预测:
其中:S0是代码上下文向量C;Ci+1是目标代码下一条语句的上下文向量;CoverageAttention是带有覆盖机制的注意力机制;TopK输出注意力分布ai相同维度值最大的k个元素的索引;Gather是按索引聚集向量操作;Mi+1是与目标语句相关的前k条源代码语句的加权隐藏状态,包含了对齐语句的语法特征和语义特征。
2.3.2 词符译码器
词符译码器和指针生成网络的译码器架构相同。该译码器进一步理解目标代码语句上下文向量,同时通过词符注意力机制从对齐的源代码语句提取表示关键字、标识符和运算符等词符,生成符合目标代码语法的语句。词符译码器获取目标代码的语句上下文向量Ci+1后,通过Pointer和Generator预测目标词符yi,j+1:
其中:SYi0是目标语句上下文向量C*i+1;依据指针—生成器机制描述,Pointer是指针概率分布计算操作;Generator是生成器概率分布计算操作;Pgen合并以上两者的概率分布。
此外,本文还为HPGN设计了新的损失函数。由于层次译码器采用了带有覆盖机制的注意力机制CoverageAttention,所以需要对语句级别和词符级别不均衡的注意力分布进行惩罚。本文在指针生成网络损失函数的基础上进行了改进,并引入超参数λ1和λ2来调整损失函数在语句级别和词符级别的权重:
2.4 状态传递机制
为了使语句译码器捕获更丰富的上下文特征,本文提出了状态传递机制,将相邻语句的最终词符隐藏状态传递给语句译码器。本文设计了残差和门控两种不同状态传递机制,使得相邻语句的隐藏状态CYi+1及其最终词符隐藏状态SYi+1m更新至语句译码器隐藏状态Si中。
2.4.1 残差状态传递机制
残差状态传递机制的架构如图4所示。该机制基于残差网络,能自动对词符译码器隐藏状态SYi+1m和语句译码器隐藏状态Si做残差运算,公式如下:
其中:SY1m是零向量;式(32)的结果代替Si作为语句译码器第t时刻的隐藏状态。
2.4.2 门控状态传递机制
门控状态传递机制架构如图5所示。该机制基于门控网络,能够在向量元素级别上调整词符译码器隐藏状态SYi+1m和语句译码器隐藏状态Si:
其中:SY1m是零向量;Zfeedi是h维的权重向量;式(34)的结果代替Si作为语句译码器第t时刻的隐藏状态。
3 实验设置
3.1 研究问题
RQ1:本文模型在代码迁移任务中表现如何?
RQ1的目标是评估基于层次注意力机制的源代码迁移模型HPGN在两个迁移任务(Java到C#和C#到Java)中的表现。为了评估模型,实验选择具有状态传递机制的HPGN和对比模型进行对比,其中对比模型在3.4节中进行了介绍。为了方便表示,具有残差状态傳递机制(如2.4.1节所描述)的模型称为ResNet-HPGN,具有门控状态传递机制(如2.4.2节所描述)的模型称为Gate-HPGN。
RQ2:状态传递机制对模型的性能有怎样的影响?
RQ2的目标是为了探究2.4节所描述的状态传递机制对HPGN性能的影响。为此,实验对比了无状态传递机制的HPGN(表示为Base-HPGN)与ResNet-HPGN以及Gate-HPGN的代码迁移精度。
RQ3:与基于词符注意力机制的模型相比,基于层次注意力机制的模型有什么优势?
RQ3是为了探究基于层次注意力机制的源代码迁移模型HPGN在代码迁移过程中的优势。如第2章所描述,HPGN拓展于基于词符注意力机制的指针生成网络,引入了语句注意力机制。比较HPGN和指针生成网络可以更好地评估层次架构的有效性。
3.2 数据集
本文选择源代码迁移研究广泛使用的C#-Java数据集CodeTrans[7]。该数据集来源于开源项目Lucene、POI、JGit以及Antlr。这些项目最初基于Java语言开发,后迁移至C#语言。CodeTrans数据集通过挖掘迁移前后两个版本中相似目录下的相似函数代码的方式完成收集,随后基于抽象语法树和数据流清除长度短、无内容以及无数据流形式的函数,最终整理划分获得的训练集、验证集和测试集大小分别是10 300、500和1 000。数据集中的C#和Java的代码在函数声明语句、函数调用语句、变量声明语句、分值控制语句上相似,但是在标识符名称、匿名数据类型关键字、函数体异常处理语句、父类构造函数调用语句、增强for循环语句以及内置函数调用语句等内容存在较大的文本差异。因此神经机器翻译模型需要理解源代码的语法和语义特征,将其转换为语义一致的目标代码。
本文采用字节对编码分词器和具体语法树解析工具tree-sitter(https://tree-sitter.github.io/tree-sitter/)对代码分词,其中字节对编码分词器单词表大小为4 176。代码分词后的统计结果如表1所示。可以发现Java代码中93.9%的语句词符量少于20,94.0%的代码语句数量少于15;C#代码中94.4%的语句词符量少于20,93.5%的代码语句数量少于15。此外,C#代码的平均长度长于Java代码,并且具体语法树的词符量要远多于代码片段。为此,实验设置C#和Java的最大语句长度为35,设置语句内词符最大数量为20。
3.3 评测指标
实验采用了已有研究广泛使用的评测指标[10,20,21]评估代码迁移模型[6,7,13]。a)BLEU[12,22,23],用于计算生成的序列和参考序列的n-gram重叠率,并返回0~100%的分值,BLEU值越高,表示生成的序列越接近参考序列;b)精确匹配(exact match,EM)在早期的代码迁移任务中用于评估生成的代码是否与参考代码相同;c)CodeBLEU[7]采用BLEU的n-gram匹配算法,并通过代码解析工具引入了抽象语法树和数据流匹配算法,CodeBLEU根据代码的文本、语法和语义特征来评估代码,给出0~100%的分数,CodeBLEU值越高,代码生成的质量越高;d)总体分值是综合性能评测指标,本文依据文献[7]提供的模型对比方式,把两个迁移任务平均CodeBLEU值作为总体分值,该指标可用于评估单个代码迁移技术在执行多个迁移任务时的总体性能。
3.4 对比模型
本文实验把具有不同架构的模型作为对比模型。最新的基于Transformer模型的研究可以在代码迁移任务中取得更好的实验结果,但这些研究是从外部数据集预训练的模型[1,6,7,13]。为了消除预训练模型使用外部数据集的干扰,实验选择不同架构的非预训练模型作为对比模型:
a)Naive模型是常用的对比模型[6,7,13],该模型把输入作为输出;b)基于短语的统计机器翻译模型PBSMT(phrase-based statistical machine translation)[3]将序列分解成短语,并经统计模型选取由这些短语译文组合成的最佳序列;c)解析树翻译模型tree-to-tree[10]首先把解析树解析为“左孩子右兄弟”的二叉树形式,然后经二叉树编码器和二叉树译码器翻译源代码的解析树;d)Transformer模型是目前代码迁移任务中非预训练的最佳模型[7]。有研究表明模型参数量越多效果越好[12]。
本文复现了tree-to-tree和Transformer神经网络模型。依据文献[7]描述,Transformer模型网络层和隐藏层大小设置为12和768,并使用格式化后的数据集进行实验。此外,tree-to-tree模型的输入和输出均采用具体语法树,其输出树的叶子节点序列作为代码文本,以排除无关因素的干扰。
3.5 实验参数设置
本节将介绍训练策略和超参数设置。在训练阶段,模型采用自回归策略训练层次译码器。自回归训练策略意味着译码器的第t个时刻的输入来自第t-1个时刻预测的词符,可以提高网络的泛化能力[24]。
超参数和实验细节设置如下:a)epoch设置为20,batch大小设置为40;b)为了提升语句对齐质量并加速训练,语句译码器指针top-K的k值设置为10;c)网络嵌入层和隐藏层设置为64,编码器译码器设置为1层;d)依据指针生成网络实验设置[19],损失函数的超参数λ1和λ2都设置为1;e)模型的梯度范数裁剪值设置为4,并应用学习率为10-3的Adam优化器更新模型参数;f)为了复现tree-to-tree模型,本文依据设备规格设置了超参数,其中隐藏层和嵌入层设置为128,epoch设置为50;g)实验环境为Intel i9 9900k的CPU和RTX 2080Ti 的GPU服务器。每个实验大約运行30 h。
4 结果分析
4.1 RQ1:本文模型在代码迁移任务中表现如何?
实验模型和对比模型在BLEU、精确匹配(EM)和CodeBLEU指标上的评估结果如表2所示。可以看出,Gate-HPGN总体表现优于最佳的对比模型。虽然Transformer模型取得了最高的EM值,但是在BLEU和CodeBLEU指标上,Gate-HPGN表现更好,在Java到C#任务分别提升了2.57和0.73,在C#到Java任务分别提升了8.08和6.06。在总体分值方面,Gate-HPGN的性能相比于最佳的对比模型提升了3.4。从译码器架构角度分析EM结果,Transformer得益于模型参数量和自注意力机制,译码性能更优;而Gate-HPGN译码时受GRU长程依赖问题的影响,使得模型对译码器端代码的理解存在性能损失[25]。此外,该实验依据了Chen等人[10]的建议设置tree-to-tree模型超参数,然而该模型性能表现不佳。从表1的数据集词符统计可知,该模型输入和输出的具体语法树的词符数量远多于代码文本的词符数量。这表明尽管具体语法树包含了源代码的结构特征,但其过多的词符使得模型难以理解并生成具有复杂结构特征的代码。
此外,从评测指标的角度对表2结果进行分析。在代码迁移研究领域中,BLEU指标评估了输出代码和目标代码的相似程度,没有考虑代码的语法和语义特征;EM指标严格判断输出代码和目标代码是否一致,却忽略了相同语法和语义特征下的不同代码;CodeBLEU指标采用了代码解析工具,通过对比输出代码和目标代码的解析树特征,从文本、语法和语义方面评估输出代码。例如,一些代码语句的功能相似,但词符形式不相同,这导致EM指标不能有效评估代码语义特征。因此从结果表明,tree-to-tree模型性能与PBSMT相当,而HPGN在代码语义迁移的性能优于最佳的对比模型。
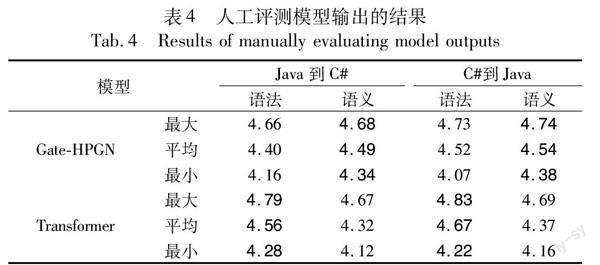
为了深度分析HPGN和Transformer源代码迁移性能,本文召集了五位有项目开发经验且未参与研究的志愿者对输出结果进行人工评估。为了保证评估结果的公平性和准确性,本文随机抽取了与表2结果相近的100条数据,并定制了评测的指标和打分标准,如表3所示。“语法”指代码语法完整度,“语义”则依据变量、类型、标识符和表达式等角度评估输出代码和源代码功能相似度。人工评估结果如表4所示,展示了每个模型在两个指标下的最大、最小的平均得分。可以发现,Gate-HPGN在语义上的性能优于Transformer,在语法上和Transformer相当。从模型架构上分析,Transformer得益于模型参数量和自注意力机制,能减少输出代码的语法错误;HPGN得益于层次架构,能更准确地关注到源代码语句的语法和语义以及语句间的上下文特征,生成语义相关的代码。
表5给出了HPGN和对比模型输出样例。样例1中源代码包含简短的函数调用语句。Transformer模型输出的代码在语义上发生了改变;tree-to-tree模型输出的代码不能准确表达源代码的语义;Gate-HPGN生成的代码最接近参考代码,但多出了额外的符号。在这里,Transformer模型不能有效地理解源代码的标识符和函数的实参列表;tree-to-tree模型没有为源代码中的词符设计迁移架构,造成语义缺失;Gate-HPGN能理解源代码的语法和语义特征。样例2中源代码有着复杂的代码语句,所有模型的输出存在语义偏差的问题。Transformer模型的输出脱离了源代码语义。通过对训练集的分析,本文认为这是因模型很少学习该迁移模式,使得模型凭借训练时的“记忆”背出最可能的代码片段。tree-to-tree模型输出的代码中有两条语句的语义也发生了改变,这是因为模型难以理解复杂代码语句所对应的具体语法树。Gate-HPGN输出代码中第二条语句复制对应源代码语句的实参列表并自制了一个offsetmin函数,最大程度地保留了源代码语义。
本文比较了HPGN和最佳对比模型Transformer的模型参数量。如表6所示,本文模型在参数量上显著地少于最佳的对比模型,这意味着该HPGN可以以较少的计算资源实现较好的迁移性能。该结果反映了Transformer模型需要大量的模型参数来取得理想的迁移性能,而HPGN能更高效地迁移源代码。
RQ1总结:在代码迁移任务中,本文提出基于层次注意力机制的源代码迁移模型HPGN相较于最佳的对比模型,在模型参数量较少的情况下具有最佳迁移性能。
4.2 RQ2:状态传递机制对模型的性能有怎样的影响?
表7展示了Base-HPGN与Gate-HPGN以及ResNet-HPGN的对比结果。Gate-HPGN的结果在三个指标的分值优于其他模型,而ResNet-HPGN在Java到C#代码迁移任务中三个指标的分值均低于Base-HPGN。这样的结果表明状态传递机制是有助于层次译码器捕获相邻语句上下文特征,而门控状态传递机制性能更好。从模型角度分析,这是因为门控状态传递机制能细致地更新语句隐藏状态向量的每个元素,使得门控网络生成的隐藏状态比残差网络融合成的隐藏状态所包含的特征更丰富。
[14]Hindle A,Barr E T,Gabel M,et al.On the naturalness of software[J].Communications of the ACM,2016,59(5):122-131.
[15]Zhang Jian,Wang Xu,Zhang Hongyu,et al.A novel neural source code representation based on abstract syntax tree[C]//Proc of the 41st International Conference on Software Engineering .Piscataway,NJ:IEEE Press,2019:783-794.
[16]Cho K,Van Merriёnboer B,Gulcehre C,et al.Learning phrase representations using RNN encoder-decoder for statistical machine translation[C]//Proc of Conference on Empirical Methods in Natural Language Processing.Stroudsburg,PA:Association for Computational Linguistics,2014:1724-1734.
[17]Schuster M,Paliwal K K.Bidirectional recurrent neural networks [J].IEEE Trans on Signal Processing,1997,45(11):2673-2681.
[18]Bahdanau D,Cho K,Bengio Y.Neural machine translation by jointly learning to align and translate[C]//Proc of the 5th International Conference on Learning Representation.2015.
[19]See A,Liu P J,Manning C D.Get to the point:summarization with pointer-generator networks [C]//Proc of the 55th Annual Meeting of Association for Computational Linguistics.Stroudsburg,PA:Association for Computational Linguistics,2017:1073-1083.
[20]Li Zheng,Wu Yonghao,Peng Bin,et al.SeTransformer:a Transformer-based code semantic parser for code comment generation[J].IEEE Trans on Reliability,2023,72(1):258-273.
[21]Yang Guang,Liu Ke,Chen Xiang,et al.CCGIR:information retrieval-based code comment generation method for smart contracts[J].Knowledge-Based Systems,2022,237:107858.
[22]Cho K,Merrienboer B V,Bahdanau D,et al.On the properties of neural machine translation:encoder-decoder approaches[C]//Proc of the 8th Workshop on Syntax,Semantics and Structure in Statistical Translation.Stroudsburg,PA:Association for Computational Linguistics,2014:103-111.
[23]Papineni K,Roukos S,Ward T,et al.BLEU:a method for automatic evaluation of machine translation[C]//Proc of the 40th annual meeting of the Association for Computational Linguistics.Stroudsburg,PA:Association for Computational Linguistics,2002:311-318.
[24]Zhang Wen,Feng Yang,Meng Fandong,et al.Bridging the gap between training and inference for neural machine translation[C]//Proc of the 57th Annual Meeting of the Association for Computational Linguistics.Stroudsburg,PA:Association for Computational Linguistics,2019:4334-4343.
[25]Bengio Y,Simard P,Frasconi P.Learning long-term dependencies with gradient descent is difficult [J].IEEE Trans on Neural Networks,1994,5(2):157-166.
[26]Luong T,Pham H,Manning C D.Effective approaches to attention-based neural machine translation[C]//Proc of Conference on Empirical Methods in Natural Language Processing.Stroudsburg,PA:Association for Computational Linguistics,2015:1412-1421.
[27]李洪政,冯冲,黄河燕.稀缺资源语言神经网络机器翻译研究综述 [J].自动化学报,2021,47(6):1217-1231.(Li Hongzheng,Feng Chong,Huang Heyan.A survey on low-resource neural machine translation[J].Acta Automatica Sinica,2021,47(6):1217-1231.)
[28]Sennrich R,Haddow B,Birch A.Improving neural machine translation models with monolingual data[C]//Proc of the 54th Annual Meeting of the Association for Computational Linguistics.Stroudsburg,PA:Association for Computational Linguistics,2016:86-96.
[29]李亞超,熊德意,张民.神经机器翻译综述[J].计算机学报,2018,41(12):2734-2755.(Li Yachao,Xiong Deyi,Zhang Min.A survey of neural machine translation[J].Chinese Journal of Computers,2018,41(12):2734-2755.)
收稿日期:2023-03-13;修回日期:2023-05-09基金项目:国家自然科学基金资助项目(61872026,61902015)
作者简介:李征(1974-),男,河北清苑人,教授,博导,博士,CCF会员,主要研究方向为软件测试、源代码分析和维护;徐明瑞(1998-),男,重庆人,硕士,主要研究方向为代码表征学习和代码迁移;吴永豪(1995-),男,江西宜春人,博士研究生,主要研究方向为软件测试和错误定位;刘勇(1984-),男(通信作者),湖南常德人,副教授,硕导,博士,主要研究方向为源代码分析、变异测试和错误定位(lyong@mail.buct.edu.cn);陈翔(1980-),男,江苏南通人,副教授,硕导,博士,主要研究方向为软件维护和软件测试;武淑美(1997-),女,山东济宁人,博士研究生,主要研究方向为错误定位和Web测试;刘恒源(1997-),男,河南周口人,博士研究生,主要研究方向为软件测试、代码表征学习和错误定位.
