基于多传感器的不平衡数据轴承故障诊断
2023-10-17董逸凡文传博王正
董逸凡,文传博,王正
(上海电机学院 电气学院,上海 201306)
轴承是电动机的重要部件,对电动机的健康可靠运行有着极大影响[1],约40%大型机械系统,90%小型机械系统的故障可归因于轴承缺陷[2],因此,轴承故障诊断的研究具有十分重要的现实意义。近年来,基于数据驱动的故障诊断算法发展迅速,但其会遇到数据不平衡的问题,即不同类别的样本量差异非常大。在实际工况中,正常状态下收集到的数据远远多于故障状态下的数据,从而带来以下问题:1)少数类样本所包含的信息有限,导致少数类的识别率低;2)许多算法在存在不确定时往往倾向于把样本分类为多数类,这将极大地影响算法精度[3]。因此,解决不平衡数据所带来的影响是当前研究的热点。
目前,国内外学者试图从以下几个方面解决不平衡问题:
1)数据层面,研究主要涵盖了上采样、下采样以及数据增广。文献[4]提出一种二次数据增强以及深度卷积神经网络(Convolutional Neural Networks,CNN)的故障诊断模型,通过重采样构造平衡数据集,再利用一维CNN进行特征提取;文献[5]结合过采样和欠采样方法,提出了一种基于混合采样和支持向量机(Support Vector Machine,SVM)的诊断方法;文献[6]结合CNN设计了一种新的生成对抗网络(Generative Adversarial Networks,GAN)模型,使用CNN提取特征后再利用GAN将特征解码生成样本。
2)算法层面,主要是研究不平衡权重对模型的影响。文献[7]提出一种基于自适应增强算法(Adaptive Boosting,AdaBoost)集成加权宽度学习系统的不平衡数据分类方法;文献[8]提出一种自适应权重和多尺度卷积的提升CNN,对多尺度特征进行加权融合,增加重要特征的贡献度,减少非相关特征的影响。
3)损失函数层面,主要通过对少数类样本的损失进行加权从而使得算法更关注少数类样本[9-10]。
4)试验验证,通过大量试验将不平衡问题转换为样本的难易区分问题,从另一个角度解决不平衡问题[11-12]。
上述研究虽然考虑了数据不平衡问题,但并未考虑到实际工况下的数据源往往并不单一,而大量文献表明,使用多传感器数据将会加强诊断的可靠性和稳定性并大大提高诊断精度:文献[13]通过变分模态分解和改进深度自编码器实现了多域特征集的融合;文献[14]使用快速傅里叶变换将多传感器信号转为频域信号,使用CNN和动态路由算法进行故障诊断;文献[15]将每个传感器数据视为一个通道,使用一维CNN对信号进行特征提取。
综上,本文基于多传感器数据,从数据增强和损失函数2个方面对数据不平衡问题展开研究。首先,使用多传感器数据代替单传感器数据进行诊断,增强数据所包含的信息;然后,针对数据不平衡问题设计了一种基于多传感器的带辅助分类器的生成对抗网络(Auxiliary Classifier GAN,ACGAN),将少数类多传感器数据样本输入ACGAN生成足量的多维高质量数据;最后,提出了一种改进的均值焦点损失函数(m-Focal Loss),通过加入均值实时更新损失函数的调制系数,从而使得分类模型在训练时更专注于难分类的样本,进一步提高模型诊断效果。
1 理论分析
1.1 ACGAN
ACGAN是GAN架构的一个变体,特点是使用一个分类器对生成数据进行分类,若生成数据具有较高的分类准确率,即可认为所生成的数据具有高质量的特点。
如图1所示:ACGAN由生成器和鉴别器组成,同时在鉴别器的输出部分加入一个辅助分类器提高性能。将类标签和噪声输入鉴别器,生成假数据后送入鉴别器区分真假与类别,然后得到损失进行反向传播,当鉴别器无法区分所生成的假数据的真假并能够准确区分类别时,则说明网络具有生成高质量数据的能力。
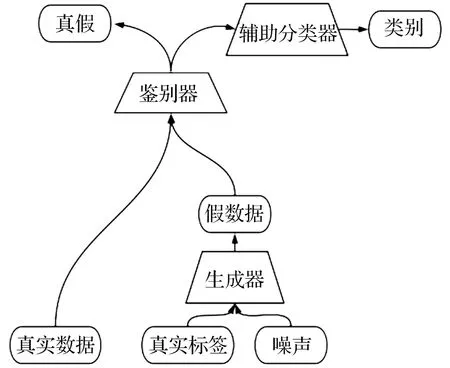
图1 ACGAN的结构
传统的ACGAN通常使用全连接层构建生成器和鉴别器,而本文加入卷积层和转置卷积层代替对应部分,不仅可以减少模型参数量,降低计算负荷,提高数据生成速度,而且可以生成多维数据,避免分别生成每个维度数据而造成的数据质量下降问题。如果将每种传感器视为一个维度,则可将所生成的多维数据用于扩充原多传感器数据集,从而缓解原数据集的不平衡对分类模型精度的影响。同时,ACGAN所特有的鉴定-分类结构可以生成高质量的数据,保证所生成数据对于模型训练具有正面作用。
生成器由4层一维转置卷积组成,一组一维的随机噪声输入生成器后输出生成多维的假数据。鉴别器和分类器共享3层的一维卷积进行特征提取,分别对输出进行一维卷积、全局池化,经过全连接层和激活函数Sigmoid得到鉴别结果并经过全连接层和Softmax分类器得到分类结果。
1.2 m-Focal Loss
以二分类为例,标准交叉熵损失(CrossEntropy Loss,CE)函数可表示为
(1)
式中:pt为预测样本属于1的概率;y为标签,取值为{0,1}。当y=0时,假如某个样本x预测为0这个类的概率pt=a,那么损失就是-loga。多分类以此类推。
对于标准交叉熵损失,根据样本比例加权虽然可以提高少数类样本的损失,但其本身也属于难分类样本,加权乘积后的效果并不好;另外,负样本数量太大,占总损失值的大部分,而且多是容易分类的。于是,在标准交叉熵损失前加上一个调制系数γ,通过减小易分类样本的权重使模型在训练时更专注于难分类的样本,即交点损失(Focal Loss,FL)函数[16],可表示为
LFL(pt)=-(1-pt)γlogpt。
(2)
交点损失函数将样本类别不平衡问题转化为样本的难易分类问题,在一定程度上提高了分类精度,但其难分类区间固定,不利于网络后期的训练。
统计不平衡数据早期训练中的结果概率并绘制成密度分布图,结果如图2所示。观察不平衡数据的早期训练结果概率密度分布可以发现,每次早期训练结果的概率可以近似看作双峰分布。将2个峰看作较易样本和较难样本的集合,以概率均值作为与CE的交点,根据每一次结果的概率分布情况放大或缩小难易样本的调制系数,就可以完成对调制系数的动态更新:因此,提出一种改进的均值交点损失(m-Focal Loss,m-FL)函数,可表示为
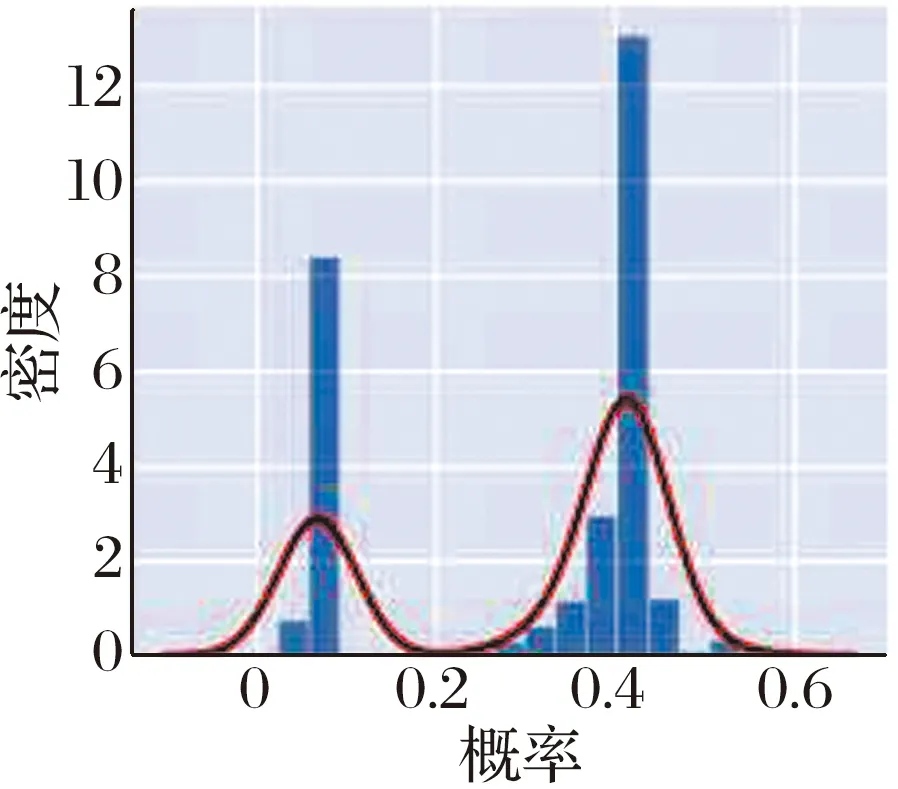
(a) 均值为0.301是
Lm-FL(pt)=-ka-ptlogpt,
(3)
式中:a为概率均值,随每次训练结果更新。相比标准交叉熵损失,均值交点损失值在均值a前放大且在a之后缩小。
3种损失函数在不同概率下的损失值曲线如图3所示:对于γ=5的FL曲线,难分类样本区间大概在0~0.3, 即当结果概率超过0.3则反向传播的梯度几乎为0,在训练后期易出现梯度消失;m-FL由于存在动态更新的调制系数,随着每次训练结果概率均值的不断变大,相对难分类样本区间也在变大,对整个训练过程具有良好的指导作用。

(a) CE与FL
2 模型结构与诊断流程
2.1 ACGAN模型结构
本文采用的生成器和鉴别器如图4所示:生成器由4层一维转置卷积组成,一组一维的随机噪声输入生成器后输出生成多维的假数据。鉴别器和分类器共享3层的一维卷积进行特征提取,分别对输出进行一维卷积、全局池化,经过全连接层和激活函数Sigmoid得到鉴别结果,经过全连接层和Softmax分类器得到分类结果。

(a) 生成器
ACGAN的生成器和鉴别器的模型参数见表1,其中n为传感器个数,即数据的通道数。随机生成一组一维长度100的数据送入生成器,输出一组n维长度512的数据;然后将生成数据送入鉴别器,经过特征提取得出鉴别结果和分类结果。

表1 生成器和鉴别器的结构及参数
2.2 故障诊断流程
本文所设计的故障诊断流程如图5所示:首先,将数据按比例划分为训练集、验证集和测试集并进行标准化;然后,训练ACGAN并分别生成每一类小样本,将生成数据与原始数据混合后送入1DCNN进行特征提取;最后,通过Softmax分类并使用m-FL对反向传播进行引导,在达到所设定的最大循环次数后结束训练。
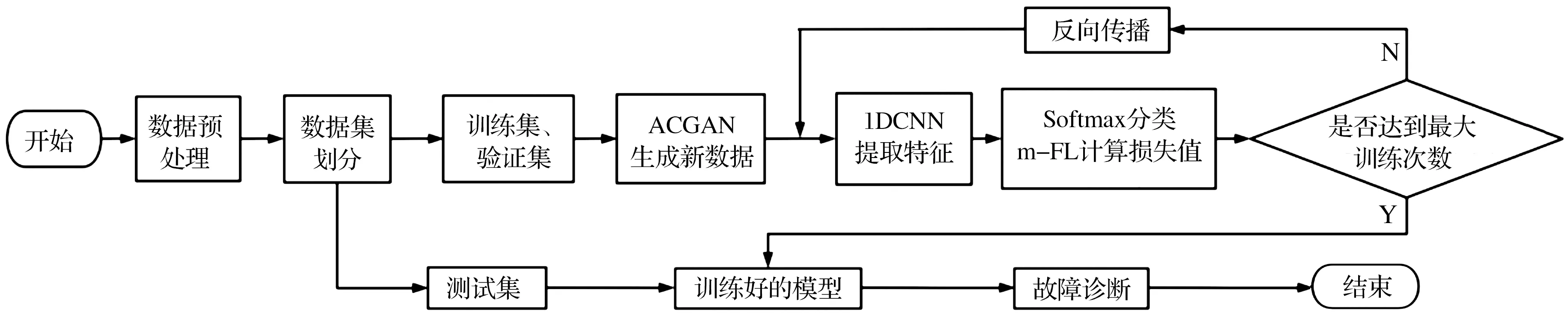
图5 故障诊断流程
3 试验分析
试验采用美国凯斯西储大学(CWRU)轴承数据集进行测试并以实验室数据集进行验证,利用Intel(R)Core(TM)i5-10400 CPU @ 2.90GHz 2.90 GHz + NVIDIA GeForce GTX 2060设备进行数据分析,并使用均值平均精准率(Mean Average Precision,MAP)衡量模型的测试结果。
平均精度(Average Precision,AP)是每类的精准率(precision)和召回率(recall)构成曲线的面积,其表达式为
(4)
(5)
(6)
式中:n为召回率的个数;ri为按升序排列的第i个召回率值;p(ri+1)为ri+1对应的最大精准率;TP为真正例;FN为假负例;FP为假正例。
均值平均精准率则定义为每类平均精度的均值,可表示为
(7)
式中:K为总类别数。
3.1 数据集介绍
选用CWRU轴承数据集中12 kHz,0 kW负载,1 797 r/min转速下在驱动端和风扇端采集的振动加速度信号。6205轴承的运行状态分为正常、内圈故障、外圈故障以及钢球故障,故障直径均包括0.178,0.356,0.533 mm这3种尺寸,总计10种状态。根据实际工况,设置正常状态下训练集、验证集和测试集的样本数为100/50/50。各故障状态的训练集、验证集和测试集样本数按1∶1,2∶1,5∶1,10∶1的不平衡数据比例分别等比缩为100/50/50,50/25/25,20/10/10,10/5/5,数据长度均为512。
实验室使用的电动机额定转速为1 420 r/min,轴承型号为6206-2RS,采样频率为10 kHz。轴承运行状态分为正常、内圈故障、外圈故障以及钢球故障。内、外圈故障为由砂轮机加工形成的条状磨损,故障深度为0.6 mm,钢球故障由机器挤压而成。由于0负载、25%负载以及50%负载对应的电动机实际转速不同,同类故障状态下振动信号的特征也不相同[17-19],因此细分为12种状态。试验数据由安装在电动机径向、横向和轴向的振动传感器和定子的三相电压传感器采集,共6通道。振动信号用于检测结构缺陷,电压信号用于测量故障期间电动机电源的波动,结合2种信号可以更全面地描述电动机状态。设置正常状态下训练集、验证集和测试集的样本数为100/50/50,各故障状态同样按1∶1,2∶1,5∶1,10∶1的不平衡数据比例划分训练集、验证集和测试集,数据长度均为512。
3.2 多传感器数据
使用多传感器数据验证本文所提方法,并与单传感器数据试验进行对比以验证多传感器数据对不平衡数据下模型精度的提升作用。试验结果见表2:在CWRU数据集上,使用多传感器数据,在不平衡程度从1∶1到10∶1的情况下,PmAP从0.979下降到了0.921,只降低了0.058,而使用单传感器数据时则从0.955降到0.871,降低了0.084;在实验室数据集上,使用多传感器和单传感器时PmAP分别下降了0.081和0.130;同时,在同一不平衡比例下,使用多传感器数据时的PmAP始终更高;试验结果充分说明使用多传感器数据可以有效抑制不平衡数据带来的精度下降,增强诊断结果的可靠性和稳定性。

表2 多传感器数据对不平衡数据故障诊断PmAP的影响
3.3 数据增强
使用ACGAN生成高质量多传感器数据,在不平衡程度分别为10∶1,5∶1和2∶1的情况下将数据补全为1∶1。多传感器下数据增强试验的PmAP折线图如图6所示:尽管无法将诊断结果还原成不平衡比例1∶1下使用原始数据时的精度,但数据增强后的PmAP有了巨大地提高,这说明本文所构造的ACGAN具有产生高质量多维数据的能力,使用ACGAN扩充数据集可在一定程度上遏制数据不平衡造成的精度下降问题。
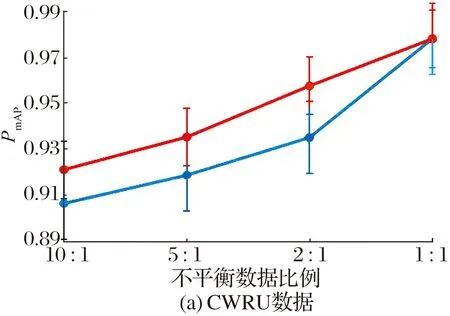
图6 多传感器下数据增强试验的PmAP
使用欠采样、随机偏度过采样技术(Random Skewness Oversampling Technique,RSOT)、人工少数类过采样法(Synthetic Minority Over-Sampling Technique,SMOTE)和GAN进行数据处理,对比验证本文模型在不平衡多传感器数据处理上的优势。各数据处理技术的结果如图7所示:欠采样方法效果最差,ROST和SMOTE这2种过采样技术与GAN的效果接近,但均不如本文所设计的ACGAN。欠采样减少了大样本数据从而使数据达到平衡,但同时也抛弃了大样本数据所具有的特征信息,导致样本难以区分,在小数据集中尤其明显;而ACGAN在数据生成时经过辅助分类器鉴定,其所携带的特征信息更明显,补充了数据集的同时也使其更容易被分类。

图7 各数据处理技术的PmAP
3.4 损失函数
分别使用CE,FL以及m-FL对不平衡状态下的轴承数据进行诊断,为使差异更明显,不使用ACGAN进行数据扩充,试验结果见表3:在不平衡比例为1∶1时,3种损失函数的效果接近,而在其他不平衡比例时m-FL均取得了更高的精度;在10∶1的不平衡比例下,CWRU数据集中m-FL的PmAP分别比CE和FL高0.015和0.029,实验室数据集中m-FL的PmAP则高出了0.037和0.059,说明m-FL动态调整调制系数从而放大难分类样本的概率,缩小易分类样本的概率,相比于CE和FL更有利于指导网络向少数类样本进行学习。
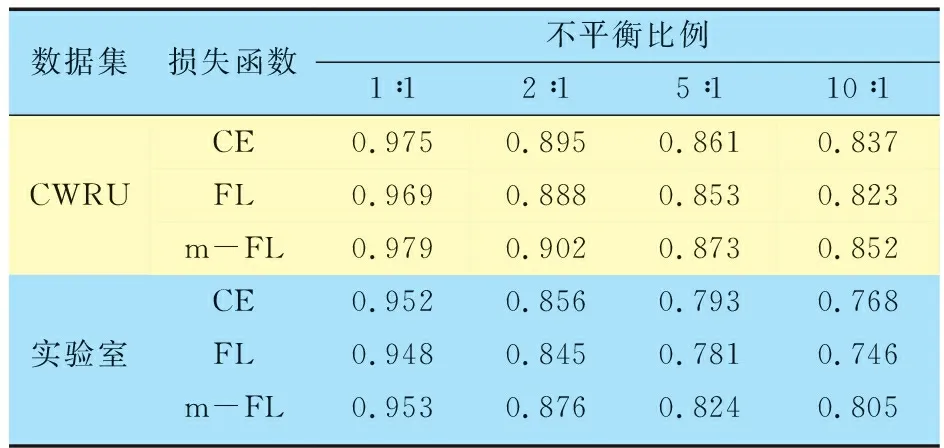
表3 不同损失函数在不平衡比例下的PmAP
3.5 网络调参
对于GAN网络,由于生成器输入、输出的尺寸固定,每层的卷积核参数需计算得到。因此,在3层结构鉴别器网络的基础上改变鉴别器的层数结构,通过观察鉴别器和生成器训练中的损失函数查看网络调参结果,如图8所示:2层的卷积结构使鉴别器偏弱,无法很好地指导生成器,鉴别器和生成器的损失值增加,且振幅比较大;而4层的卷积结构使得鉴别器过强,梯度消失,损失函数剧烈震荡;本文所提3层卷积结构的鉴别器和生成器的损失函数最终分别在0.75和0上下小幅振荡,具有较优的数据生成能力。
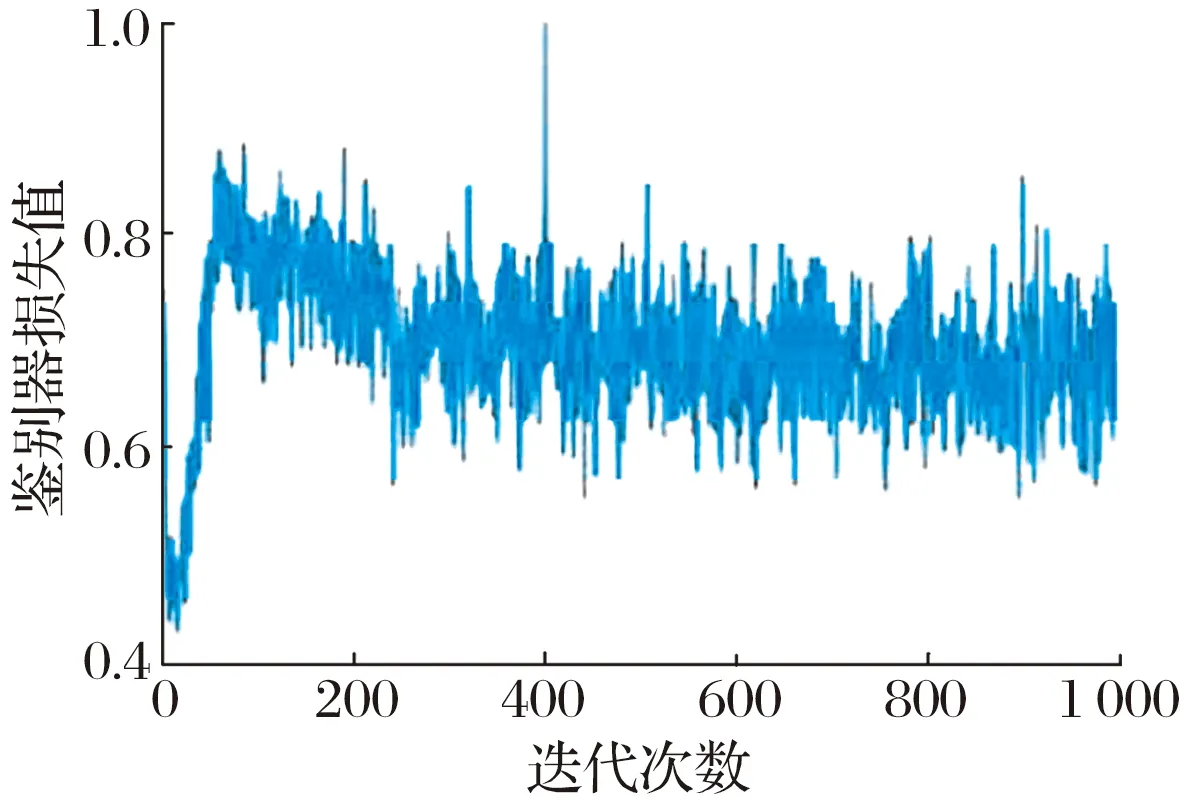
(a) 3层卷积结构
4 结论
针对不平衡数据影响故障诊断模型精度的问题,设计了一种基于多传感器的辅助分类对抗神经网络模型,并提出改进m-FL以加强损失函数对网络训练的指导能力,通过CWRU和实验室数据集对所提方法进行了验证,得到以下结论:
1)使用多传感器数据可以有效抑制不平衡数据带来的精度下降问题。
2)加入ACGAN所生成的样本可大大提高不平衡数据下轴承故障诊断模型的精度。
3)所提出的m-FL,可以带来比CE,FL等损失函数更高的PmAP。
