基于预训练模型及条件随机场的中医医案命名实体识别
2023-10-09吴佳泽李坤宁陈明
吴佳泽,李坤宁,陈明
(北京中医药大学中医学院,北京 102488)
中医医案是中医临床医师实施辨证论治过程的文字记录,是保存、核查、考评乃至研究具体诊疗活动的档案资料[1]。诚如章太炎先生所言:“中医之成绩,医案最著。欲求前人之经验心得,医案最有线索可寻。[2]”作为中医学的重要组成部分,中医医案不仅是中医师临床诊疗疾病的第一手资料,而且在临证经验及学术思想传承的过程中发挥着不可替代的作用。自2 000 多年前西汉淳于意写就《诊籍》始[3],历代医家所著医案汗牛充栋,仅清朝就存有医案专著200 余种,个案则不计其数[4]。不同于现代医学的病历,中医医案专注于四诊资料的采集和对病因病机的分析,蕴理、法、方、药于其中[5],并以辨证思路为核心,夹录夹论[6]。综上,中医医案作为中医理论与实践的重要载体,其中蕴含着丰富的理论价值与研究价值,亟待梳理与挖掘,但因历代医案数量众多、医家著录有其个人特点,缺乏规范化与标准化[7]、传统机器学习方法难以处理自然语言等原因,目前对中医医案的数据挖掘研究尚少[8]。
对纷繁复杂的中医医案进行数据挖掘需首要解决的便是命名实体识别(named entity recognition, NER)问题。 NER 是自然语言处理(natural language processing,NLP)领域中的一项重要任务,其目的是识别出文本中表示命名实体的成分并对其进行分类[9]。近年来,随着神经网络的发展,对NER 的研究愈来愈多,识别效果也越来越好,但对中医医案的NER 研究甚少,大多采用基于传统机器学习的条件随机场(CRF)、支持向量机(SVM)等方法,或者基于神经网络的双向LSTM-CRF(BiLSTM-CRF)方法[10]。在对文本的表征能力方面,LSTM神经网络虽然强于传统机器学习方法,但其结构尚简,训练集规模及训练时间尚不足,效果欠佳,仍需继续优化。本文基于预训练模型BERT 的变体RoBERTa 及CRF 构建神经网络,并通过迁移学习在中医医案训练集上进行微调(Fine-tune)以处理下游任务NER,可较大提升中医医案命名实体识别的效果。
1 材料
1.1 预训练模型
BERT(bidirectional encoder representation from transformers)是由Google 于2018 年提出的一种预训练模型,其基于Transformer,主要用于解决NLP领域的效率难题[11]。BERT提出之前,NLP领域多使用前馈神经网络语言模型(feedForward neural network language models, FFNNLM)[12],循环神经网络语言模型(recurrent neural network language models, RNNLM)[13]以及 ELMo(embeddings from language models)[14]。FFNNLM 中的嵌入层通过CBOW 或Skip-Gram[15]的方式将文本转为词向量,然后将前n-1 个词的词向量作为表征去预测第n 个词,并以此训练神经网络得到词向量权重,进而解决NLP 问题。FFNNLM 解决了自然语言稀疏性的问题,同时模型也具有一定的泛化能力,但FFNNLM 并未充分考虑文本的上下文语义,也未考虑文本的时序问题;RNNLM 同样使用嵌入层将文本转为词向量并进行训练,但其通过时序神经网络解决了文本的时序问题,效果较FFNNLM 更优。经典RNN 在训练时容易产生梯度消失或梯度爆炸问题,因此后续又诞生了其改进型LSTM(long short-term memory)神经网络[16]。无论是经典RNN 还是LSTM 神经网络,二者都未充分考虑文本的上下文语义,并且都是单一时序,即通过前n-1个词的词向量去预测第n个词,未考虑后续文本,这与人类认知不符,因此训练而得的词向量权重也有所偏颇;在FFNNLM 和RNNLM 的基础上,又提出了ELMo,ELMo 使用前向和后向两个彼此独立的多层LSTM 提取文本特征,最终的文本表征由词向量和末层LSTM 通过平均加权共同决定,因此可获得上下文浅层相关的文本语义。但是ELMo 的双向LSTM 是由两个LSTM 通过浅层拼接而成,前向和后向LSTM 之间彼此独立,没有联系,所以ELMo 只能提取上下文的浅层信息,并未完全利用到上下文的深层信息。无论是FFNNLM、RNNLM 还是ELMo,均为有监督学习,其训练集都需进行人工标注,这决定了其采用的语料及训练规模不会很大,相当程度上限制了其文本表征能力。
BERT 是第一个采用无监督、深度双向机制的NLP 预训练模型。BERT 整体是一个自编码语言模型(auto-encoding language models),即预训练表征模型,其不同于FFNNLM、RNNLM 和ELMo 采用单向神经网络或双向神经网络浅层拼接的方式进行训练,而是采用新的MLM(masked language model)和NSP(next sentence prediction)训练方式,以生成深度双向的文本表征。BERT 主要使用Transformer 的编码器(Encoder)部分,舍弃了解码器(Decoder)部分,并且采用双向Transformer,故其特征融合方式较ELMo 采用的浅层拼接双向LSTM 的方式更优。除此之外,Transformer还可通过自注意力机制(self-attention)实现并行计算,计算速度较RNNLM 和ELMo 更快[17]。同时,由于是无监督学习,BERT 可采用海量语料构建超大规模的训练集,故其对文本的表征能力远超RNNLM 和ELMo。预训练后的BERT 仅需微调就可应用于各种下游任务,可大大提高神经网络模型在NLP 领域的性能。
后续BERT又衍生出了诸多变体,如ALBERT[18]和RoBERTa[19]等,各自从不同角度对BERT 进行了优化。ALBERT 通过采用跨层参数共享、易NSP 为SOP(sentence order prediction)、嵌入参数分解三项策略,在基本保持性能的同时,大大简化了模型结构,使预训练模型更加实用;RoBERTa 通过采用精细调参、易静态掩码为动态掩码,使用全长度序列(full-sentences)、取消NSP 等策略,并以更大的批处理量(batch size)在更大规模的语料上训练更长时间,获得了对文本更强的表征能力。
1.2 条件随机场
条件随机场(conditional random field,CRF) 是在一组随机输入变量条件下另一组随机输出变量的条件概率分布模型[20]。
在NER 任务中,LSTM 或BERT 等预训练模型可通过神经网络的非线性拟合能力于上下文中学习文本语义,最后计算出每个字符(token)所对应命名实体标签的概率,而CRF是通过统计归一化的条件状态转移概率矩阵预测命名实体标签的概率,因此CRF可以学习到标签间的依赖关系[21]。如B-NAME 标签后通常紧跟INAME标签,而不是I-AGE或其他标签,又如每个命名实体都是由B-X起,以I-X结束,反之则误。LSTM或BERT等预训练模型对命名实体标签间的依赖关系感知较弱,故可通过CRF对命名实体标签间的转移关系建模以弥补神经网络的不足,进一步提升模型性能。
2 模拟实验
首先通过预处理对医案中的命名实体进行人工标注后导出数据集,并划分训练集和验证集;然后依据NER 任务调整预训练模型的输入层和输出层以构建神经网络,之后将训练集经分词器(Tokenizer)输入神经网络进行微调;最后通过验证集对模型进行评估。实验步骤见图1。

图1 实验步骤
2.1 数据集
数据集选自《刘渡舟临证验案精选》[22],原因有二,其一是刘渡舟教授治学严谨,辨证准确,且善于抓主证,用药不蔓不枝,所录医案具有代表性;其二是该书编著精良,所录医案分属疾病类别达131 种之多,分布广泛,并且记载详略得当、简明扼要,用词精当切要,文笔隽永流畅,主诉、症状、舌脉等四诊材料及所用方药记录齐全、规范、标准,适宜作为NER研究的原始文本。
2.2 预处理
首先使用ABBYY FineReader[23]通过OCR 技术将不可编辑的医案PDF文件转为可编辑的Word文件;然后对照原始文本,人工校正转换后的Word 文件,将遗漏、乱码等错误之处更正;最后将校正后的文件导入label-studio 以“BIO 三元标注法”进行命名实体标注。共标注10 类命名实体,分别为姓名(NAME)、性别(GEND)、年龄(AGE)、症状(SYM)、舌象(TON)、脉象(VEI)、辨证(PAT)、治法(TRE)、方剂(FOR)、中药及用量(MED),其中B-X 为命名实体起始,I-X 为命名实体中间或结束,O为非命名实体。本实验共选取100则医案,经数据清洗后共整理出568 条人工标注文本,为避免模型训练时发生过拟合,按8∶2 比例划分为训练集和验证集。见图2。

图2 命名实体人工标注
2.3 神经网络模型
本实验采用BERT、RoBERTa 和ALBERT 作为预训练模型来评估其在中医医案命名实体识别中的性能表现,其中BERT 和RoBERTa 选用哈工大讯飞联合实验室的预训练模型[24],ALBERT 选用UER 团队[25]和CKIPLab团队的预训练模型。
模型由输入层、预训练模型、全连接层及CRF层构成。输入文本会由预训练模型的分词器添加“[CLS]”“[SEP]”标识符,并转为词向量作为神经网络的输入;输入向量经预训练模型和全连接层后输出各字符对应命名实体标签的发射分数;CRF对发射分数建模并提取标签间的特征关系,最终解码出各字符最佳对应的命名实体标签,完成命名实体识别任务。BERT 及其变体的模型规模见表1;基于BERT 及其变体构建的神经网络模型见图3。
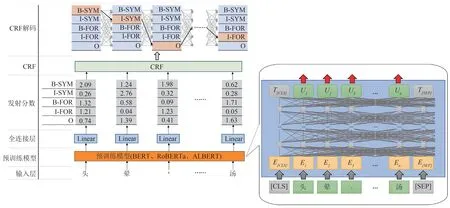
图3 神经网络模型
CRF 是处理序列标注问题的经典方法,从张汝佳等[26]对中文命名实体识别的研究来看,CRF 已广泛应用于各种NER 模型。除传统机器学习外[27],在深度学习中也通常将LSTM、GRU、Transformer 等与CRF 结合以提高模型性能。BERT 提出后,也有研究将BERT 与CRF 相结合,但模型性能提升并不大[28],甚至还会降低,究其原因,在于预训练模型与CRF 的学习率不对等。BERT 等预训练模型经大规模语料长时间学习后,其拟合能力远胜LSTM 等神经网络,在针对下游任务进行微调时,模型通常只需很小的学习率,经过2~3 个epoch 后就能收敛到最优,若CRF 以同样学习率进行训练,则不能收敛到最优,故其对模型性能的提升贡献不大。对于此问题,可通过分层设置学习率的方法解决,BERT 等预训练模型应用较小学习率,CRF 应用较大学习率,以达到最佳拟合效果。图4 所示为当BERT-wwm 应用学习率5 × 10-5,CRF 应用不同学习率训练时NER的准确率,可以看出,当CRF学习率为5 × 10-3时(与BERT-wwm学习率相差100倍),准确率开始有较大提高,当CRF 学习率为5 × 10-2时(与BERT-wwm 学习率相差1 000 倍),准确率达到最高。结果表明,增加CRF 层并设置恰当的分层学习率,可在BERT 等预训练模型极强拟合能力的基础上弥补其不足0。
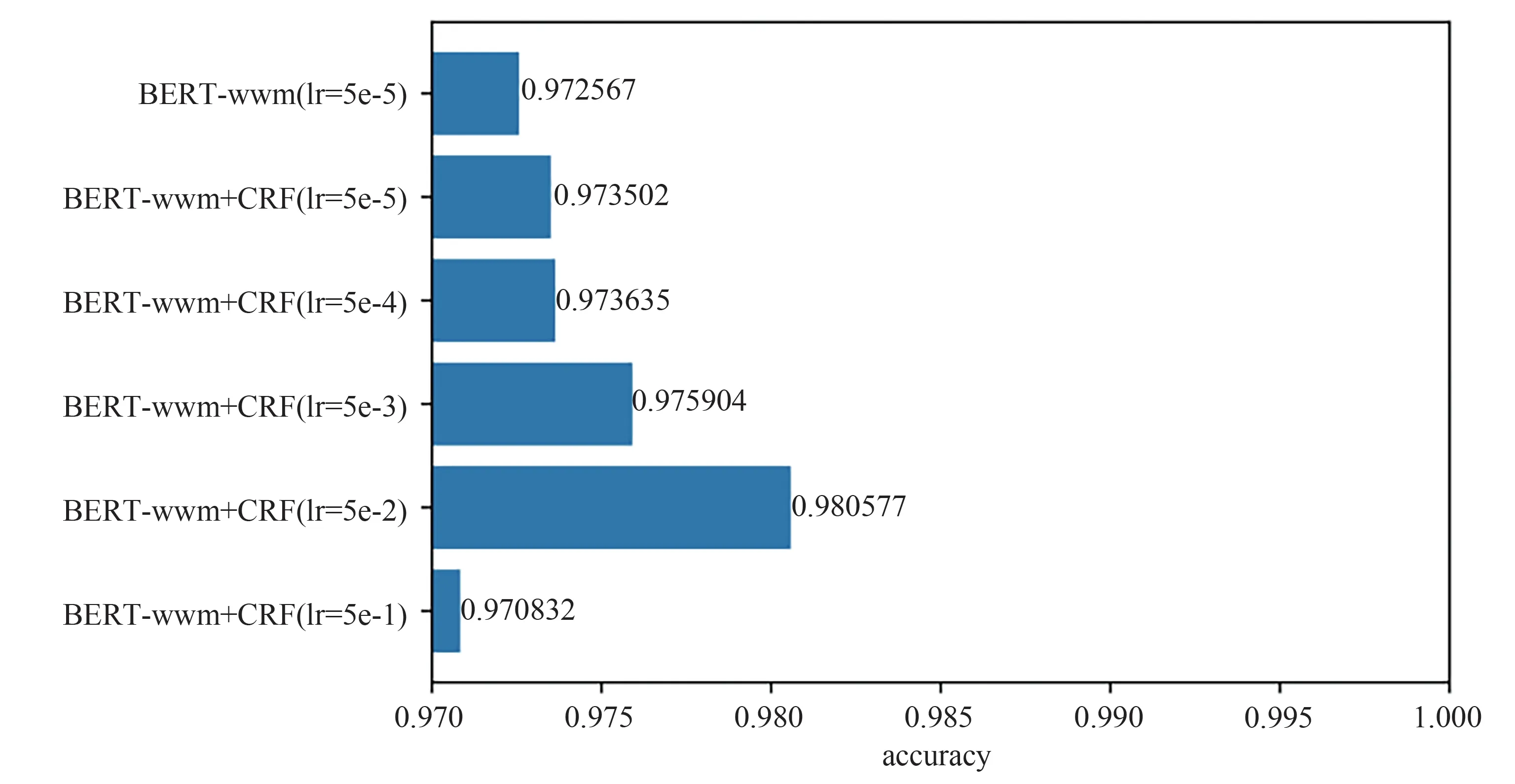
图4 CRF应用不同学习率训练时NER的准确率
3 结果
本实验的评价包含准确率(Accuracy, 2)、精确率(Precision,3)、召回率(Recall,4)、F1 分数(F1 score,5)四项指标,公式如下:
基于CRF 及不同预训练模型的各神经网络对NER 的四项整体评价指标。可以看出,对于各预训练模型,使用CRF 后,四项指标均有不同程度的提高,特别是ALBERT-base-chinese,提高幅度最大,尤以精确率为甚,提高了44.14%,而RoBERTa-wwm-extlarge 则只提高了2.20%。表明CRF 可以较好地学习到命名实体标签间的依赖关系,纠正标签间的错误排列顺序;同时也表明BERT、RoBERTa等结构更复杂、语料规模更大、训练时间更长的预训练模型对文本特征的提取能力更强,CRF 对其性能的提升较微,但对于ALBERT 等结构较简单的预训练模型有较好的优化效果。见图5和表2。
表2 样本预测集合

图5 各神经网络及CRF有无对NER的四项整体评价指标
在BERT、ALBERT 和RoBERTa 三类预训练模型中,RoBERTa 的评价最优,特别是RoBERTa-wwmext-large,在CRF 的加持下,其准确率比ALBERTbase-chinese 高5.71%,精确率高10.47%,召回率高11.85%,F1 分数高11.16%,表明RoBERTa 采用的训练方式更优,参数更佳,对于下游任务有更强的泛化能力,同时更大的数据批处理量和更大规模的语料也大大强化了其性能。
各命名实体的F1 分数是对基于CRF 及不同预训练模型的各神经网络评估而得,可以看出,BERTwwm、 BERT-wwm-ext、 RoBERTa-wwm-ext、RoBERTa-wwm-ext-large 的 F1 分 数 接 近 ,ALBERT-base-chinese-cluecorpussmall、ALBERTbase-chinese 的F1 分数接近,且后者对于SYM(症状)、PAT(辨证)、TRE(治疗)和FOR(方剂)命名实体的F1 分数大幅低于前者。BERT 和RoBERTa 对于NAME(姓名)、GEND(性别)、AGE(年龄)、TON(舌象)、VEI(脉象)、TRE(治疗)和MED(中药及用量)命名实体的F1 分数较高,尤其是RoBERTawwm-ext-large,对各命名实体的识别均为最优。见图6。
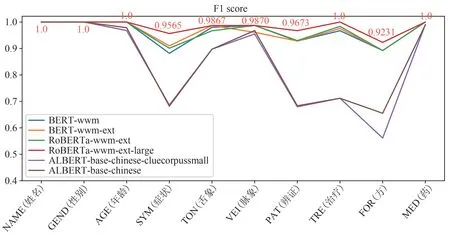
图6 各命名实体的F1分数
4 讨论
命名实体识别对于中医医案的数据挖掘具有重要意义。作为中医学术的一次文献,中医医案不仅是疾病治疗过程的再现,而且蕴含着医家的学术思想和辨证论治艺术,在文献学、方法学及临床方面均有重要意义[29]。但中医医案同样也有数量众多、个性化与非标准化、自然语言属性难以量化等问题存在[30],因此对中医医案命名实体的识别就成了首要任务,也是对其进行高价值数据挖掘的前提。与图像、语音等信息不同,同属人类认知范畴的自然语言因没有明显的抽象分层及难以表征等问题存在,若想取得较好效果,根本上就需要层次更深的神经网络,以及规模更大的训练集[31]。因此,本文提出利用预训练模型及CRF 构建结构更复杂的神经网络,预训练模型是在大规模语料上长时间训练而来,故其对文本的上下文语义特征提取能力极强,同时使用CRF处理命名实体标签间的依赖关系。
本文通过BERT、RoBERTa、ALBERT 三类六种预训练模型及CRF 对中医医案NER 实验后的结果表明,通过设置恰当的分层学习率,在迁移学习中CRF 就能较好地与预训练模型融合以提取命名实体标签特征,或多或少地优化模型性能,尤其是对于层次相对较浅的ALBERT,其F1 分数至多可提高44.14%,由于BERT 和RoBERTa 结构本就复杂,文本特征提取能力较强,故CRF 对其模型优化效果不明显。在预训练模型中,RoBERTa-wwm-ext-large 的性能最优,其准确率可达99.33%,精确率可达98.24%,召回率可达98.51%,F1 分数可达98.38%,对于10 类命名实体,其对NAME(姓名)、GEND(性别)、AGE(年龄)、TRE(治疗)、MED(中药及用量)的识别最优,F1 分数可达100%,其次是TON(舌象)、VEI(脉象)、PAT(辨证),F1分数分别为98.67%、98.70%、96.73%,对SYM(症状)和FOR(方剂)的识别略差,F1 分数分别为95.65%、92.31%。通过分析结果可以得出,RoBERTa通过精细调参、利用更加充分的训练过程及更大规模的训练集等措施,大大提升了模型性能[32]。
本文提出的神经网络模型与既往研究的对比见表3。高佳奕等[33]单纯使用CRF 进行命名实体识别研究,F1 分数仅为85.56%,远低于本文的98.38%,且CRF无法处理文本的上下文语义及序列较长的命名实体,而RoBERTa 通过Transformer 以及全长度序列训练模式解决了该问题,因此其效果大幅优于单纯使用CRF。除此之外,高氏等仅对肺癌医案中的症状进行了命名实体识别研究,这导致医案和命名实体类别较单一,模型泛化能力较弱;羊艳玲等[34]和高佳奕等[35]均基于BiLSTM-CRF 神经网络进行命名实体识别研究,其F1分数分别为82.32%和85.94%,高佳奕等采用了Peephole 机制,故其模型性能相比羊氏等的模型较优,但二者均不及本文提出的RoBERTa-CRF 神经网络。此外,羊艳玲等的模型F1分数不及前者高氏等单纯使用CRF,究其原因,在于高氏等对数据的预处理较为细致,去除了冗余信息,特征较为单一,仅包含症状(名)、(症状)程度、(症状发生)部位。再者,二者均可识别多个命名实体,模型泛化能力较单纯使用CRF 也有所提升;胡为等[36]基于BERT-BiLSTM-CRF 神经网络进行命名实体识别研究,其F1 分数为90.04%,并且可识别六类命名实体,可见预训练模型对神经网络性能的提升是巨大的,而本文的实验结果表明,将BERT 改为RoBERTa,并调整恰当的分层学习率,可再将F1 分数提高8.34%。并且RoBERTa 是对BERT 各项改进而来,其训练规模远超BERT,并且Transformer 的上下文特征提取能力强于LSTM,因此LSTM 对RoBERTa 的性能提升微乎其微,在本文构建的神经网络中,顾及计算资源和训练时间,遂将其舍去。

表3 本文提出的神经网络模型与既往研究情况对比
5 结论
本文探讨了BERT、RoBERTa、ALBERT 三类六种预训练模型及CRF 对中医医案命名实体识别的性能表现,结果表明,对于ALBERT这类结构相对简单的预训练模型,CRF 能有效地处理命名实体标签间的依赖关系,大幅提升模型性能,而对于BERT和RoBERTa这类结构相对复杂的预训练模型则收效甚微;并且得益于训练方法的改进和训练规模的扩大,RoBERTa 对文本的表征能力较BERT 更强。通过与既往研究的对比,本文构建的神经网络对中医医案命名实体识别的F1 分数高达98.38%,比效果最好的方法提高了8.34%,并且可识别10 类命名实体,解决了中医医案命名实体识别效率一般的问题,为后续对中医医案的高价值数据挖掘奠定了坚实基础。
预训练模型虽然性能强大,但其训练过程需耗费巨量计算资源及时间,门槛较高,不利于科研人员训练自己的预训练模型,因此需进一步探寻如何在保持模型性能的前提下降低训练门槛[37]。后续研究应着眼于对本文神经网络的优化,进一步提高对症状(SYM)、辨证(PAT)和方剂(FOR)命名实体的识别效果,同时还需扩大样本量,利用数量更多、类别更广泛的医案训练数据识别更多的命名实体,进一步提高模型的泛化能力。
