矩阵变换特征与码序列联合学习的卷积码识别方法*
2023-09-28尤红雨刘伟松黄知涛
王 垚,满 欣,尤红雨,明 亮,刘伟松,黄知涛,4
(1. 国防科技大学 电子科学学院, 湖南 长沙 410073; 2. 海军工程大学 电子工程学院, 湖北 武汉 430033; 3. 中国人民解放军92001部队, 山东 青岛 266005; 4. 国防科技大学 电子对抗学院, 安徽 合肥 230037)
为了提高信息传输的可靠性,信道编码被广泛应用于各类数字通信系统中。在实际通信中,收发双方需要事先约定所使用的编码参数,以实现通信接收端的正确译码。但在认知通信、非合作通信等领域,接收方往往缺乏译码所需的必要信息。此时,就需要通过信道编码盲识别技术,利用接收到的信息序列,对发送端所采用的编码参数进行分析识别。信道编码盲识别技术因其重要的理论和应用价值,受到了众多研究者的关注。
在信道编码中,卷积码具有结构简单、纠错性能优异等特点,是应用最为广泛的编码类型之一。卷积码盲识别技术的发展,对于当前众多通信链路逆向分析都具有重要的作用。针对卷积码盲识别问题,现有方法主要可分为卷积码参数分析和卷积码闭集识别,简称为卷积码识别。其中,针对卷积码参数分析问题,文献[1-3]基于秩亏(rank deficiency)性质对卷积码的参数进行提取,此类方法原理简单,但误码适应能力较差。文献[4]利用欧几里得算法,实现了对码率为1/n的卷积码的识别,该方法计算量小,但几乎不具备容错能力。文献[5-6]则引入了Walsh-Hadamard变换,该方法本质上计算了码字矩阵与所有二进制序列校验关系成立的可能性,因此具有较好的误码适应能力,但计算复杂度随卷积码记忆长度呈指数倍增加。
针对卷积码识别问题,传统方法主要基于卷积码校验关系,逐一验证候选集合中的编码参数。为了提高算法的误码适应能力,文献[7-8]分别引入对数似然比(log-likelihood ratio,LLR)和似然差(likelihood difference,LD),将二元域运算转为实数域运算,计算卷积码码字与校验矩阵之间正交关系成立的概率,算法的容错性能较好,但算法复杂度高。随着深度学习在机器视觉[9]、自然语言处理[10]等领域取得的突破性成果,学者们也开始将深度学习应用于信道编码识别领域[11-14]。文献[11]利用深度学习技术对信道编码类型及参数进行了识别,对比了残差网络(residual neural network,Resnet)、循环神经网络(recurrent neural network,RNN)、注意力机制在信道编码识别上的性能。文献[12]则利用1维注意力机制对信道编码类型进行识别,实现了多种不同类型、不同参数的信道编码序的识别。针对卷积码识别问题,文献[13]提出了一种基于时序卷积网络的识别方法,对低码率卷积码取得了较好的识别效果。文献[14]利用Resnet,实现了对17种不同参数卷积码的识别,并分析了网络深度、输入序列长度等参数对识别性能的影响,与传统方法相比,该方法计算速度更快,识别能力更强。
但是,现有的基于深度学习的卷积码识别方法通常直接将编码序列作为网络输入,试图利用网络的特征提取和分辨能力对编码器进行识别。这类思路导致神经网络规模不断增大,但识别性能提升并不明显,仍无法有效识别码率大于1/2的高码率卷积码。
本文针对现有基于深度学习的方法所存在的不足,对卷积码码字矩阵的相关性质展开研究,利用一个新的矩阵变换算法实现卷积码序列特征的提取,并在此基础上提出了一种基于多模态联合学习的卷积码识别方法。该方法将接收序列排列成矩阵形式,并利用解调软信息剔除可靠性较低的码字,通过新的矩阵变换方法对码字矩阵进行预处理得到特征矩阵。在识别时,将原始码字矩阵和特征矩阵分别输入网络中,通过网络完成特征融合及卷积码的分类识别。
1 卷积码基本原理
通常可以用C(n,k,m)来表示一个卷积码,其中n为输出通道数,k为输入通道数,m为编码约束长度,即生成多项式中最高幂次数。同时,卷积码的生成矩阵可表示为一个k行n列的多项式矩阵:
(1)
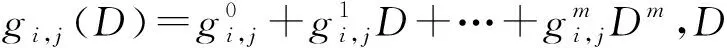
(2)

U(D)=[u1(D)u2(D) …uk(D)]
(3)
则编码过程可表示为:
C(D)=U(D)·G(D)
(4)
卷积码同时存在与生成多项式矩阵对应的校验多项式矩阵H(D),且满足:
G(D)·H(D)T=0
(5)
在实际应用中,接收到的序列通常为二进制向量,因此可以用二进制形式对生成多项式矩阵和校验多项式矩阵进行重写,分别记为生成矩阵G和校验矩阵H,二者均为半无限的二元域矩阵,分别可表示为:
(6)
(7)
其中
(8)
(9)
此时,卷积码输入信息与输出码字的关系可用下式表示:
c=uG
(10)
其中:u表示编码器输入的信息序列;c表示编码器输出的码字序列,且满足cHT=0。
2 基于深度学习的卷积码识别模型
在识别过程中,基于深度学习的卷积码识别方法与传统方法相比,具有数据量需求少、速度快等优势[11],现有方法的基本流程如图1所示[11-14]。

图1 现有基于深度学习的卷积码识别流程Fig.1 Existing convolutional code recognition process based on deep learning
从图1中可以看出,现有基于深度学习的方法通常将接收到的码字序列直接作为神经网络输入,未对接收序列进行预处理,完全依赖于神经网络的特征提取与识别能力。低码率的卷积码具有较为简单的编码结构,对应的码字空间较小,码字序列中包含的随机信息比例较低。因此,神经网络易于直接从码字序列中发现规律性的特征。但在高码率卷积码的码字序列中,信息比特占的比例较高,码字序列具有较强的随机性,此时只依靠神经网络难以提取不同卷积码之间的差异。因此,现有的基于神经网络的识别方法对高码率卷积码的识别性能往往较差。
为了提高对于卷积码的识别性能,本文提出了一种基于矩阵变换特征与码序列数据多模态联合学习的卷积码智能识别模型,其流程如图2所示。首先,将接收到的码字序列按照一定规则排列成矩阵形式,然后对该码字矩阵通过矩阵变换进行预处理,完成码字序列的特征提取。之后,将码字矩阵及提取出的特征矩阵分别输入神经网络中进行联合学习。该神经网络具有两个并行的特征提取模块和一个特征融合模块,能够完成两种模态数据的特征提取与融合,使所提方法最终具有良好的识别性能。具体的预处理方法与网络参数将在后文中给出。

图2 本文方法的卷积码识别流程Fig.2 Framework of the proposed method
3 基于联合学习的识别方法
3.1 码字序列预处理及特征提取
假设发送端发送的码字序列为c=[c1,…,cL],该码字为编码器C(n,k,m)的输出序列。可以利用下述规则构建包含l个元素的子序列:
(11)

同时,通过观察可知,矩阵G的构造具有一定的规律性。如果以n个列向量为一组,则从第m+1组开始,向量组均由前一组列向量补零获得。因此,可以在矩阵G上方,按此规律补充一定数量的行向量得到矩阵:
(12)
当t≡0(modn)时,进一步可得:
(13)

(14)

同时,根据最简行阶梯矩阵的唯一性可知,当t≡0(modn)时,对所有采用相同编码参数的C(l)进行消元化简,最终所得的最简行阶梯矩阵必定是相同的。但是,最简行阶梯矩阵中所有线性无关的行向量被集中于矩阵的前rl行,不利于网络进行特征的提取与识别。为了使码字矩阵变换后的结果更适合神经网络进行识别,本文利用了一种新的保留对角线元素的矩阵变换算法,即算法1。该算法将非零行的首个非零元素置于对角线上,这些非零元素的分布反映了码字矩阵秩的变化。文献[3]给出了,l=pn(p∈Z+)时,码字矩阵的秩rl随l变化的规律:
(15)
基于式(15)中矩阵秩的变化规律可知,算法1输出矩阵对角线上非零元素的分布同样与卷积码参数之间存在明确的约束关系。因此,算法1相较于GE算法,其结果能够直观地反映出更多的编码参数信息,不同卷积码对应的变换结果差异更加明显,因此更适于作为神经网络的输入。

算法1 保留对角线元素的矩阵变换算法Alg.1 Matrix transformation preserving diagonal elements
经过算法1变换后得到的矩阵M具有以下特点:
1)当对角线上的某个元素为1时,该元素所在列的其他元素均为0;
2)当对角线上的某个元素为0时,该元素所在行的其他元素均为0。
在无误码条件下,经过算法1变换后,不同卷积码序列所对应的输出矩阵具有不同的0/1分布。图3给出了当t≡0(modn)时,在无误码条件下,C(2,1,3)、C(4,1,3)和C(4,3,3)2卷积码码字矩阵在经算法1变换得到的矩阵取值示意图(卷积码具体参数见表1)。

(a) C(2,1,3)码字矩阵变换结果(a) Output for C(2,1,3)

(b) C(4,1,3)码字矩阵变换结果(b) Output for C(4,1,3)
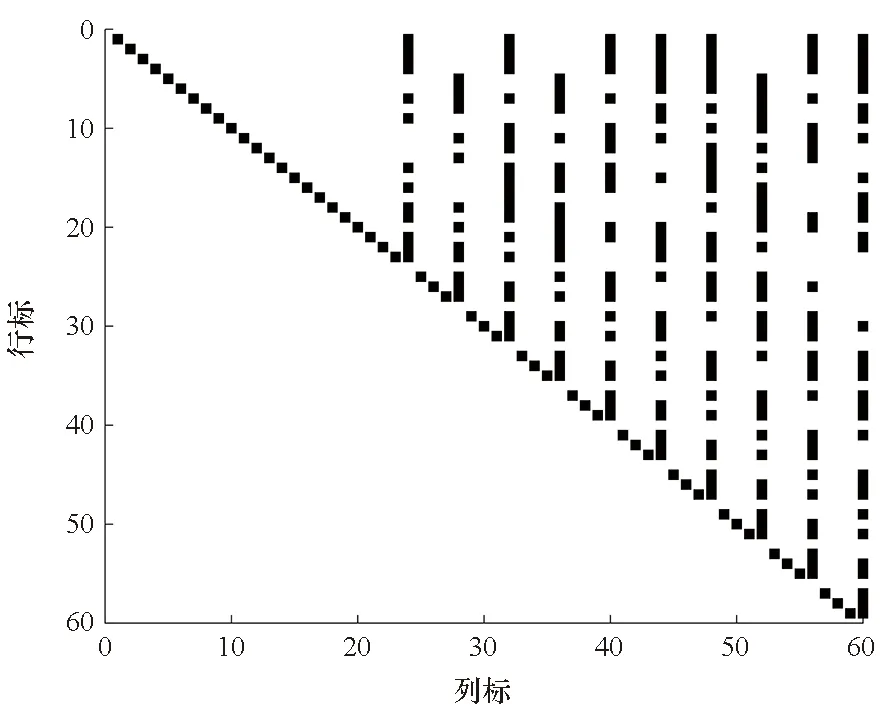
(c) C(4,3,3)2码字矩阵变换结果(c) Output for C(4,3,3)2图3 算法1输出矩阵取值示意图Fig.3 Output of the algorithm 1
图3中黑色点表示相应位置的值为“1”,空白表示相应位置的值为“0”。从图中可以看出,经过算法1变换后,不同参数的码字矩阵具有明显的差异,与前文分析一致,因此可利用算法1的输出作为卷积码的特征对卷积码进行识别。
3.2 基于软判决可靠性的数据筛选
由前文分析可知,当t≡0(modn)时,利用算法1对码字矩阵C(l)进行变换,所得上三角矩阵能够作为特征矩阵用于编码器的识别。但在实际应用中,由于受信道环境的影响,解调序列中不可避免地包含一定数量的误码。这些误码将在矩阵行变换的过程中扩散到其他没有误码的位置,使得算法1输出矩阵也将出现错误。
从信道编码参数分析的原理和发展过程出发,可以发现编码分析容错能力的提升往往得益于解调软信息的有效利用。下面,给出一种基于解调软信息的数据筛选方法。
为不失一般性,假设调制方式为二进制相移键控(binary phase shift keying, BPSK)调制,传输信道为加性高斯白噪声信道(additive white Gaussian noise channel,AWGNC)。记y和W分别为c对应的软判决和硬判决序列,满足:
yi=si+ni
(16)
其中:ni是均值为零,方差为σ2的高斯白噪声序列;si是BPSK调制符号,与原始码字ci之间满足
si=2ci-1
(17)
则对于某一个符号ci,其LLR可表示为:
L(ci)=L(ci|yi)=-2yi/σ2
(18)

(19)
3.3 网络模型
本文所设计的网络模型如图4所示。与现有方法不同,本文的网络模型采用了特征融合的设计思路,分别将原始序列构成的码字矩阵Y(l)和算法1输出的特征矩阵M作为网络的输入1和输入2。在全连接层之前,连接两个网络分支输出的特征向量,并通过后续网络层实现特征融合。这种设计能够从两种模态的数据中提取有效信息,使网络具有更强的特征提取和识别能力。

图4 网络模型Fig.4 Network model
具体而言,图4中“卷积层 64×7,3 ReLU”表示该卷积层采用的通道数为64,卷积核大小为7,步长为3,激活函数为ReLU。类似地,“平均池化层2,2”表示平均池化层,窗函数大小为2,步进为2。本文网络采用了与文献[14]类似的基于Resnet的骨干网络。不同的是,本文方法采用的是2维卷积神经网络(convolutional neural network,CNN),而文献[14]采用的则是1维CNN。网络的每个分支包含了2个卷积层、4个残差模块。4个残差模块中的具体类型见图5,其中输入1对应的激活函数为Leaky ReLU,输入2对应的激活函数为ReLU。最后,将两个分支输出的特征向量进行连接,再送入全连接层,完成特征融合。在全连接层之后,采用Softmax函数得到网络的最终输出。此外,网络采用Adam优化器,学习速率设置为0.001仿真中,批量大小(Batch size)为64。
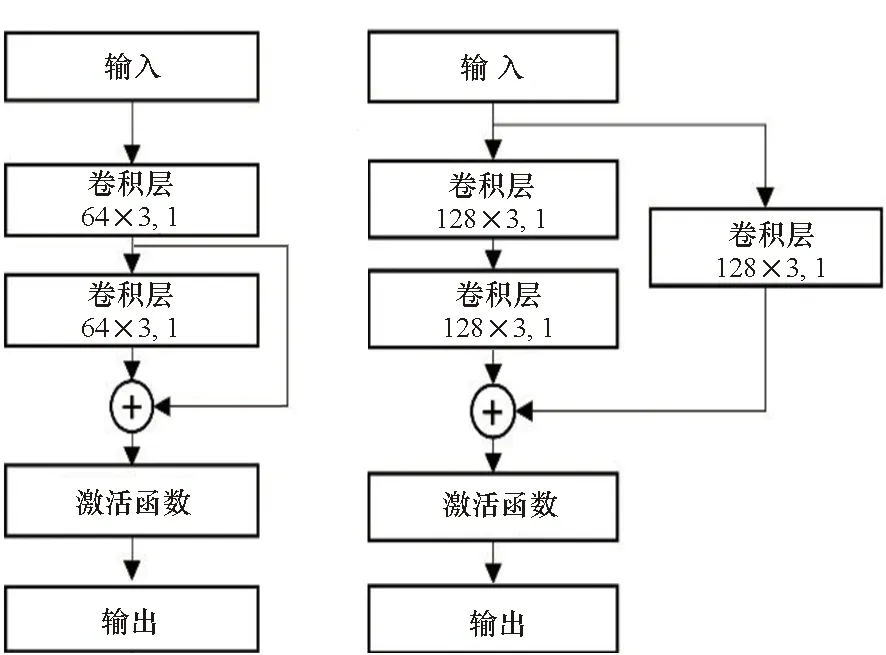
(a) 基本残差模块(a) Identity block(b) 卷积残差模块(b) Convolutional residual block图5 残差模块Fig.5 Resnet block
3.4 算法步骤
根据前文可知,构造的码字矩阵C(l)只有在满足t≡0(modn)时,算法1对其进行变换才能够获得期望的变换结果。因此,t可以取参数n所有可能取值的最小公倍数。综合考虑性能和资源需求,l取t的4~5倍即可。现将本文识别方法总结如下:
步骤1:生成采用C(n,k,m)卷积码编码的软解调输出及其硬判决序列。
步骤2:设定t=12,l=60,对码字序列进行分段,并利用软解调信息筛选数据,得到码字矩阵Y(l)和特征矩阵M。
步骤3:构建多模态联合学习神经网络,设置各超参数,利用数据样本对网络进行训练。
步骤4:完成网络训练后,利用测试集对模型性能进行评估。
本节分析比较参数α对本文算法检索性能的影响.在α有效范围内,50个查询在3个数据集m0、m1和k1中进行本文算法实验,其检索结果MAP值如图2至图4所示.其中,实验参数:ms=0.2,mc=0.8,Litem =2,minPR=0.1,minNR= 0.01.图例中, “t” 和“d”分别表示TITLE和DESC查询,“e”代表Relax值,表Rigid值,“A”代表PTAE_AWPNP算法,“C”代表PTCE_AWPNP算法.
4 实验与结果分析
4.1 数据集生成
为了验证本文对于卷积码的识别性能,本文在文献[14]所选择的17种不同参数的卷积码之外,增加了码率为2/3和3/4的卷积码,共计25种具有不同编码约束长度、生成矩阵的卷积码。表1给出了不同编码器生成多项式的八进制表示。

表1 卷积码编码参数列表Tab.1 Parameters of convolutional codes
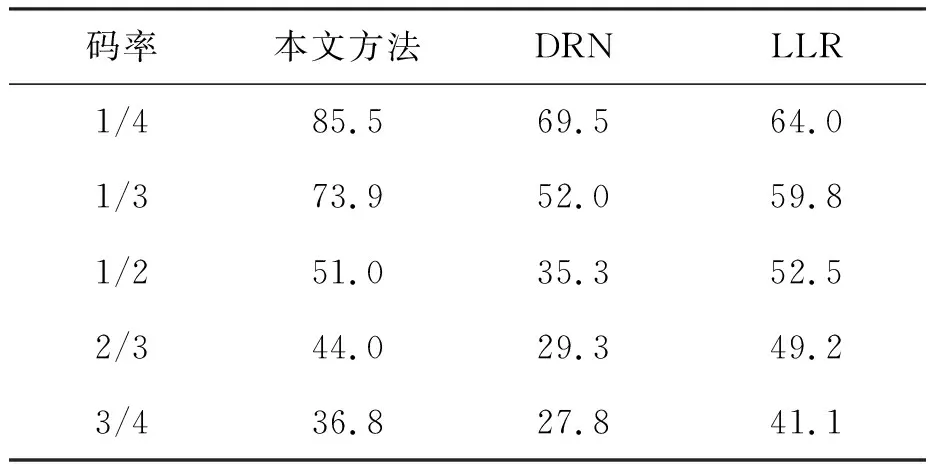
表2 不同算法的平均识别率Tab.2 Average recognition rate of different algorithms %
数据集的生成主要经过以下几个步骤,首先使用表1中的卷积码参数进行编码,然后对编码后的序列进行BPSK 调制,并经过AWGNC进行传输。最后,使用BPSK解调器对接收到的信号进行解调。设置t=12,l=60,完成数据筛选和码字矩阵的构建,并利用算法1对码字矩阵进行变换,得到码字矩阵Y(l)和特征矩阵M作为数据样本。
深度学习是一种数据驱动型方法,需要利用数据集完成模型参数的训练,受数据集的影响较大。通过实验,对比了本文方法在数据集初始信噪比为-1 dB、-5 dB、-10 dB时的识别性能,发现当数据集的初始信噪比为-1 dB时,所提方法的识别性能明显较弱。当数据集的初始信噪比为-5 dB时,所提方法的识别性能略低于-10 dB时水平。因此,在生成数据集时,设置AWGNC的信噪比(signal-to-noise ratio,SNR)取值范围为-10 dB至10 dB,间隔1 dB。
每个不同的参数生成1 000个样本,取其中80%的样本组成训练集,剩余的作为验证集。最终,共有420 000个训练样本,105 000个验证样本。
4.2 仿真分析
通过仿真,对本文方法的识别性能进行验证,同时考察输入序列长度、矩阵变换算法等因素对算法性能的影响,最后与现有的方法进行对比。实验环境为Windows10操作系统,CPU为Intel Core i7-9700K, GPU为英伟达GeForce GTX 2080Ti,运行内存32 GB,程序开发基于Pytorch框架。
4.2.1 编码约束长度和码率对识别性能的影响
接收序列长度L=16 384,信噪比范围为-10~10 dB,间隔1 dB。本文方法对于不同卷积码的识别效果如图6、图7所示。
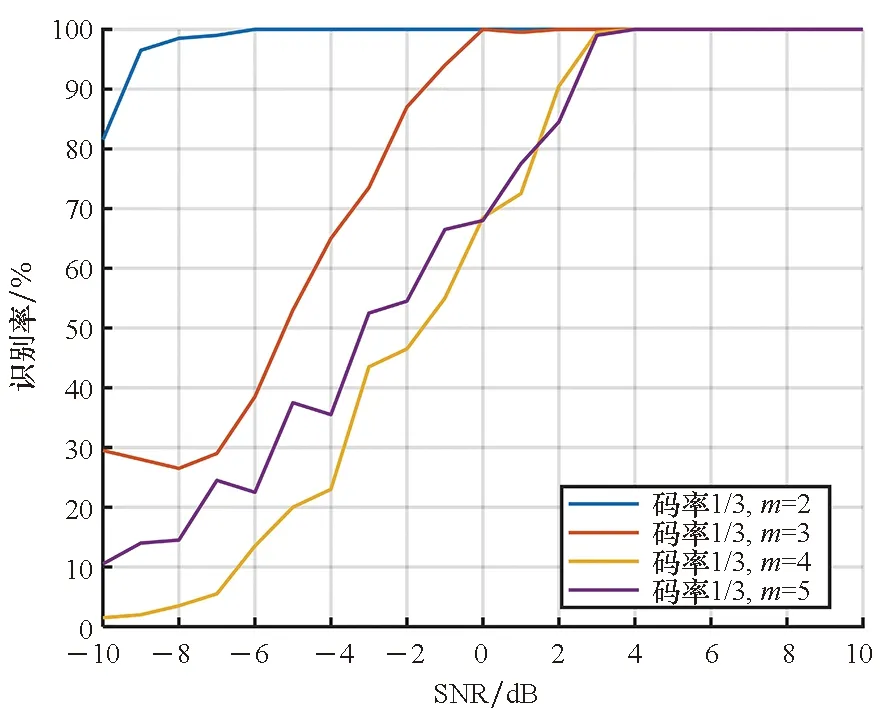
图6 算法对1/3码率卷积码的识别性能Fig.6 Recognition performance of algorithm for 1/3-rate convolutional codes

图7 算法对1/4码率卷积码的识别性能Fig.7 Recognition performance of algorithm for 1/4-rate convolutional codes
从图6可以看出,对于码率为1/3的卷积码,编码约束长度越短,识别性能越好。在信噪比为-6 dB时,对于编码约束长度为2的卷积码,识别率已经能够达到100%。而对编码约束长度为3的卷积码,此时的识别率仅有约40%,其他编码约束长度更长的卷积码的识别率则更低。从图7中也可以看出相同的规律。识别性能会随着编码约束长度的增加变差,这主要是因为编码约束长度越长的卷积码,前后时刻码字之间的关联性越强,其对应的码字空间的维度也就更大、结构更加复杂。相较于约束长度较短的卷积码码字,约束长度较长的编码器输出的码字序列表现出的随机性更强,增加了网络从中提取有效特征、完成识别的难度。
与此同时,从图6和图7的对比也可以发现,在相同编码约束长度的条件下,码率较低的1/4码率卷积码的识别率更高。这主要是因为,对于低码率的卷积码,码字中包含的校验比特更多,相应包含的随机信息也就越少。这种情况下,码字序列所表现出的随机性也就较低,识别难度降低,识别性能随之提高。
图8给出了本文方法在信噪比大于0 dB时,对所有25种不同参数的卷积码进行识别所得到的混淆矩阵。从图中可以看出,算法对1/3和1/4码率的卷积码所得的识别准确率最高。而对于码率较高的1/2、2/3和3/4卷积码,算法识别性能出现了下降。这和前文的分析是一致的,较高的码率和较长的记忆长度,都将提高卷积码结构的复杂性,编码后的码字序列也将表现出更强的随机性,显著提高了卷积码识别的难度。

图8 25种卷积码识别结果的混淆矩阵Fig.8 Confusion matrix of the recognition accuracy of 25 convolutional codes
4.2.2 数据长度对识别性能的影响
接收序列长度L的取值包括:4 096、8 192、16 384,信噪比为-10~10 dB,间隔为1 dB。
考虑到对于闭集识别算法而言,单独某一个目标的识别性能并不能说明算法的整体性能。因此,本节采用同一码率下的平均识别率作为性能指标,考察不同接收序列长度对识别性能的影响(见图9)。例如,对于1/2码率卷积码,本文以表1中C(2,1,3)、C(2,1,4)、…、C(2,1,9)等7种1/2码率卷积码识别率的平均值作为性能指标。
从图9中可以看出,信噪比小于1 dB时,接收序列长度L对识别性能几乎没有影响。信噪比在1~5 dB时,随着L的增大,识别性能显著提高。具体而言,L每增长1倍,识别性能增加约10%~15%。而当信噪比较高时,不同L的识别性能均能达到100%。这主要是因为,在信噪比小于1 dB时,序列中包含的错误信息较多,无法筛选出受误码影响较小的码字矩阵,因此无法得到可用于识别的有效特征矩阵。而随着信噪比的提升,数据筛选的作用开始体现,此时随着接收序列长度的增大,得到受噪声影响较小的码字的概率也就越高。在本文方法中,接收数据长度的变化并不影响最终输入网络的数据大小,因此在实际应用中,应利用尽可能多的数据,从中筛选出可靠性最高的序列构建码字矩阵,从而提高识别的准确率。
4.2.3 矩阵变换方法对识别性能的影响
通过仿真实验,同样采用同一码率卷积码的平均识别率作为性能指标,对比了GE算法和文中算法1分别作为特征提取手段时模型的识别性能。接收序列长度L的取值为16 384,信噪比为-10~10 dB,间隔为1 dB,结果如图10所示。

图10 不同矩阵变换方法下的算法识别性能Fig.10 Recognition performance of algorithm under different matrix transformation methods
从图10中可以看出,不论采用哪种变换算法,均能够在信噪比达到5 dB时,识别率上升至100%。同时,若采用高斯消元法对码字矩阵进行变换,最终的识别性能稍弱于算法1。这说明本文所提的识别框架能够较好地解决高码率卷积码识别的问题;算法1相较于传统的GE算法,更适合作为码字矩阵的预处理方法。
4.2.4 性能对比
对比了本文方法与现有方法的识别性能,如图11和图12所示。所采用的对比算法为当前识别性能最优的深度学习算法深度残差网络(deep residual network, DRN)[14],以及传统方法中具有代表性的基于平均LLR方法(简称LLR方法)[15]。接收序列长度L的取值为16 384,信噪比为-10~10 dB,间隔为1 dB。本节同样采用同一码率卷积码的平均识别率作为性能指标。

图11 不同算法对低码率卷积码的识别性能Fig.11 Recognition performance of different algorithms for low rate convolutional codes
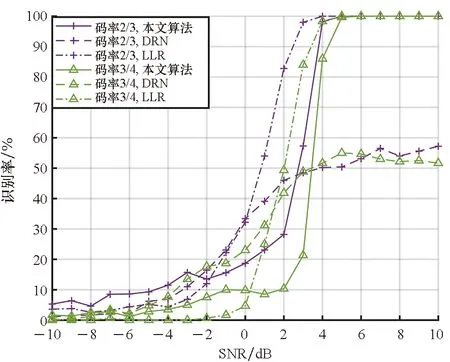
图12 不同算法对高码率卷积码的识别性能Fig.12 Recognition performance of different algorithms for high rate convolutional codes
图11和图12给出了三种方法对不同码率卷积码的性能对比。表2则给出了三种方法对不同码率卷积码的整体平均识别率。从上述图表中可以看出,本文方法较同样基于深度学习的DRN方法有较大的提升。而与LLR方法相比,本文方法对低码率卷积码的识别性能较好。但随着卷积码码率的增加,本文方法与DRN方法的性能下降要快于LLR方法。对于高码率卷积码,本文方法的性能略低于LLR方法。
这主要是深度学习方法和传统方法的原理差异造成的。对于深度学习方法,提取的是码字序列变化、数据分布的规律。当码率较低时,码字空间中随机的信息比特较少,神经网络能够对码字序列中存在的规律进行提取。即使是在低信噪比条件下,输入数据中仍以一定概率存在能够反映码字特征的片段。而此时,LLR方法的统计量受噪声影响严重,已经无法反映不同卷积码之间的差异。因此,本文方法能够在低信噪比条件下取得优于LLR方法的识别效果。
但随着码率的提高,编码器变得更加复杂,码字空间不断扩大,码字中各比特之间的约束关系增强,网络模型难以直接从码字序列中提取有效的特征。这也是现有基于深度学习的方法不能适应高码率卷积码的主要原因。与DRN方法相比,本文方法通过对码字矩阵的预处理,实现了编码序列特征的提取,并采用特征融合的思路,有效提高了对高码率卷积码的识别性能。此时,通过矩阵变换得到的特征在识别中起着主导作用。此外,矩阵变换过程中不可避免地会产生误码扩散的问题,与LLR方法相比更易受到误码影响,这导致本文方法对高码率卷积码的识别性能较LLR方法仍有1dB的差距。
5 结论
文章从卷积码的编码过程出发,对卷积码码字矩阵的性质进行了研究,利用一种新的矩阵变换算法对码字序列进行变换,使变换后的矩阵更适合作为神经网络的输入。在此基础上,提出了一个新的基于多模态数据联合学习的卷积码智能识别模型。模型首先利用解调软信息对数据进行筛选,再对筛选后得到的码字矩阵进行变换得到特征矩阵。然后,将特征矩阵和原始码字矩阵分别作为网络两个支路的输入,利用网络完成特征的融合与识别。从仿真结果来看,本文方法的识别性能相比于已有基于深度学习的方法有较大的提升,弥补了当前基于深度学习的识别方法无法适应高码率卷积码的不足。与传统方法相比,本文方法对低码率卷积码的识别性能更强,但对高码率卷积码的识别仍需要在后续工作中继续进行研究。
