基于北斗船位数据的拖网渔船捕捞努力量算法研究
2023-09-14刘慧媛薛沐涵崔国辉
李 丹,鲁 峰,2,徐 硕,2,刘慧媛,薛沐涵,方 辉,崔国辉
(1.中国水产科学研究院渔业工程研究所,北京 100141;2.崂山实验室,山东青岛 266237;3.中国水产科学研究院东海水产研究所,上海 200090)
捕捞努力量是在一定时间段内以某种渔业作业方式在渔场中投入的工作量,可作为渔业生产管理、渔业资源评估以及生态脆弱性评估的重要参考依据[1-4],精确识别与评估我国海域内捕捞努力量的时空特征可为捕捞限额策略规划和渔业资源评估提供关键信息[5-6]。传统的捕捞努力量统计主要依靠捕捞日志及渔获数据,存在记录不规范、漏报、误报等人为因素和时间滞后等问题。采用图像识别捕捞作业行为来评估捕捞努力量的方法能有效减少漏报、误报等人为因素[7],但也存在检测覆盖范围小、数据获取成本高等缺陷。船位监控系统(vessel monitoring system,VMS)作为一种渔船监控手段,可获取渔船船位、航速、发报时间等动态信息,为渔业科学研究扩充新的数据来源[8],同时为捕捞努力量估算方法提供新思路。
船位监控系统数据包含渔船运行状态信息,通过船位数据挖掘可以判别渔船捕捞作业状态[9-16],从而实现捕捞努力量估算[17]。渔船作业状态的识别准确率决定了捕捞努力量估算的精度。最初捕捞作业行为识别算法多直接提取船速、航向、作业时间等信息,用阈值划分渔船作业状态,如张胜茂等[18]提取拖网渔船的捕捞航速及航相差阈值判定渔船捕捞状态,ZHANG等[19]利用作业时间和速度阈值判定金枪鱼围网捕捞作业行为。然而阈值划分方法存在判定特征局限的缺点,很难适用于所有渔船[8],易使捕捞努力量估算值偏高[20]。机器学习算法能进一步挖掘船位信息与捕捞作业行为之间的非线性关系,是当前渔船状态判别的研究重点[8]。SOUZA等[21]提出基于速度的隐马尔可夫链模型,用于拖网渔船的捕捞作业行为识别,准确率达85%。该方法建立了速度与捕捞作业行为的非线性关系模型,提高了识别准确率,但特征输入单一,准确率偏低。BEHIVOKE等[22]利用连续轨迹提取几何特征,采用随机森林模型实现捕捞作业行为判别,识别拖网渔船捕捞作业行为准确率达88%。该研究优化了特征构成,但未考虑空间位置信息,准确率提升不高。KROODSMA等[23]提取大量空间信息及行船动态信息构成特征矩阵,利用深度卷积神经网络识别捕捞作业行为,该算法特征构成全面,准确率达96%,但深度网络存在网络参数多、调参难、算力消耗大及训练时间久等问题。综上,现有基于船位数据的捕捞作业行为识别算法在特征和算法选取上存在一定的局限性,致使算法在准确率和实现难度上难以平衡。
本文基于北斗船位数据,在特征构造方面,提取行船动态信息的同时,补充了空间信息。采用灵活、高效的极限梯度提升算法(eXtreme Gradient Boosting,XGBoost)构建辽宁省拖网渔船捕捞作业行为识别模型,挖掘2021年全年在渤海及黄海北部海域的捕捞努力量时空分布特征,为我国近海海域拖网渔船捕捞努力量估算提供新方法,以期为渔业资源评估与限额捕捞政策制定提供新依据。
1 材料与方法
1.1 数据来源
实验数据为辽宁省渔船的北斗渔船船位数据,共计渔船853艘,数据48 256 060条,采集时间为2019年9月—2022年1月,调查区域为37°~40°N、119°~124°E内海域。北斗船位数据的时间精度为秒,时间分辨率为3 min,空间分辨率约为10 m。每条船的船位数据中包含渔船经纬度、速度、收发时间及渔区等信息。
1.2 数据处理与标注

图1 调查区域示意图Fig.1 Map of investigation area
拖网渔船作业通常将一张或多张网拖到渔船尾部,作业时渔船通常会放慢速度,并力求保持速度稳定,尽可能使拖网的张力均匀。拖网作业时间取决于鱼群密度,通常持续3~5 h,本文中拖网作业包括布网到收网全过程[21],将拖网渔船状态划分为捕捞状态和非捕捞状态,其中捕捞状态包含渔网部署、拖网作业和收网过程,非捕捞状态包括抛锚停泊和航行[7]。标注前,首先根据数据的整体范围,剔除报位中经度、纬度、速度和时间中存在缺项、漏项及超限的数据。计算每条船位到海岸线的距离,以进出港时间划分数据段。由于卫星接收回传数据的过程中会受到信号波动的影响,偶尔有人为遮挡发射源等情况,若前后两条报位时间间隔超过3 h,则将切分轨迹段,最后删除点数小于5的轨迹段。
本研究具体标注方法参照SOUZA等[21]和KROODSMA等[23]针对拖网渔船作业特征的描述,结合渔业专家经验,对2019年9月至2022年1月的12条辽宁省拖网渔船船位数据进行标定。将每段数据的经纬度和速度按时序输入Arcgis,综合分析路线、行船位置及船速,对起止时间进行标注,标定数据共计175 096条。标定过程中,将捕捞状态标记为1,非捕捞状态标记为0。对标定好的数据,参考文献[22-23]提取每条记录向前时间间隔、距离、到中国海岸线最短距离、理论速度、当前速度、时刻(h)、月份等渔船作业特征重要参数。由于数据量大,本研究随机选取5条船60 362条数据用作模型训练,剩余7条船114 734条数据用于外部验证。
1.3 拖网渔船捕捞努力量计算体系架构
本研究获取北斗船位数据,提取特征向量,判断其是否为捕捞作业状态,然后计算捕捞努力量,体系架构如图2所示。
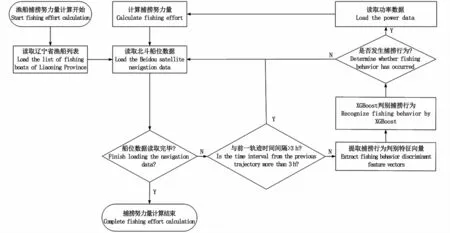
图2 拖网渔船捕捞努力量计算体系结构Fig.1 Framework for calculating traw ling fishing effort
本文提出的基于北斗船位数据的拖网渔船捕捞努力量计算方法主要由两部分组成,第一部分利用船位数据生成捕捞作业行为判别向量,再使用XGBoost判别其是否发生捕捞作业行为;第二部分则依据分类器的判别结果,结合船位信息计算捕捞努力量。
1.4 基于XGBoost的拖网渔船捕捞作业行为识别算法原理
在得到船位数据特征向量后,使用XGBoost进行拖网渔船捕捞作业行为识别。XGBoost是一种梯度提升集成学习框架[24-26],即通过增加第n个弱学习器,使其输入为第n-1个预测结果的残差,将多个弱学习器做叠加使得残差越来越小,直至接近真实值,用这样的方式来训练模型。XGBoost中的弱学习器选用决策树。基于XGBoost的渔船捕捞状态识别模型的目标函数为:
式(1)中,Obj为目标函数;L为损失函数;n表示弱学习器个数(fj)为复杂度正则化项。另损失函数L为:
式(2)~式(3)中,i表示样本编号;xi表示训练船位数据;yl为对应真实捕捞状态;f为预测结果;k表示弱学习器编号;K表示弱学习器数量;^yl表示训练后输出值。
第t次迭代中,第i个样本的模型预测值为:
式(4)中,t为迭代次数;i表示样本编号;xi表示训练船位数据是第t次迭代之后样本i的预测结果;ft(xi)是第t个弱学习器的预测结果;k表示弱学习器编号。将式(2)和式(4)代入式(1)得:
对式(5)损失函数进行二级泰勒展开得到:
式(7)中,Ω(ft)为第t个弱学习器的复杂度正则化项;j表示第j个叶子节点;N为弱学习器中叶子节点数量;ωj为叶子节点权重,γ和λ为正则化的超参数。目标函数中对全部船位数据的求和可以转化为对叶子节点求和,由此去掉式(6)中常数项代入式(7):
式(8)中,N为弱学习器中叶子节点数量;ωq(xi)表示当前弱学习器中,样本q(xi)被预测后落入对应节点上,ωq(xi)=ft(xi)=ωj;GJ=∑i∈IJgi;HJ=∑i∈IJhi,其中,IJ表示全部叶子节点;gi为泰勒展开一阶导数;hi为泰勒展开二阶导数;γ和λ为正则化的超参数。为了获取最优解q(xi),可以计算叶子j的最优权重ωj为:
式(9)~式(10)中,ωj为叶子j的最优权重;t为迭代次数;j表示第j个叶子节点;i表示样本编号;N为弱学习器中叶子节点数量;ωj表示叶子j的最优权重;IJ表示全部叶子节点;gi为泰勒展开一阶导数;hi为泰勒展开二阶导数;γ和λ为正则化的超参数。式(10)可作为弱学习器的子叶分数,分数越高算法对渔船捕捞作业行为识别的效果越好。
1.5 模型构建
基于XGBoost的拖网渔船捕捞作业行为识别模型采用Python语言实现。模型训练首先随机选取5条标定船,共60 362条船位数据,构成实验数据集。确保捕捞作业行为与非捕捞作业行为船位数据各占50%,使训练样本平衡。取实验数据集中约1/5作为测试集,由此获得模型训练数据49 912条,及内部测试数据10 450条。通过五折交叉选取最优超参数,确定学习率为0.01,弱分类器数量200个,每个分类器随机采样比例0.8,采样列数比0.8,γ和λ采用默认值1和0。完成模型训练后,采用114 734条船位数据进行外部验证,同时选取极限学习机[27]和随机森林[28]与XGBoost进行比较,测试算法的泛化能力。
1.6 评价指标
为了评价基于XGBoost的拖网渔船捕捞作业行为识别模型的性能,本研究选取4个评价指标[29-30],分别是特异性(Specificity,SP)、敏感性(Sensitivity,SN)、准确率(Accuracy,ACC)和马修斯相关系数(Matthews correlation coefficient,MCC),指标定义如下:
式(11)~式(14)中,TP表示真正例数,即捕捞状态被正确识别的样本数;TN表示真负例数,即非捕捞状态被正确识别的样本数;FP表示假正例数,即非捕捞状态被识别为捕捞状态的样本数;FN表示假负例数,即捕捞状态被识别为非捕捞状态的样本数。
1.7 捕捞努力量
依据联合国粮农组织的计算方法,捕捞努力量可由发动机功率和捕捞作业天数(kW·d)表达[5,31]。本研究中捕捞努力量的计算方法参考了文献[5]及[32],时间精确到小时,捕捞努力量单位为(kW·h)。渔船i处于出海活动状态时,假定研究区域可分为S个网格,则研究区域内捕捞努力量计算公式为:
式(15)中,m表示一个网格内某个渔船轨迹位置;Ti,m和Ti,m-1是渔船i行船过程中的前后2点连续轨迹的时间;Wi为渔船功率;Pi,m表示Ti,m时刻渔船i在位置m处的作业状态;N表示渔船i在网格内作业位置总数;I表示第s个网格内渔船总数;S表示网格总数;E表示研究区域内总渔船捕捞努力量。
将辽宁省拖网渔船船位数据输入训练好的捕捞作业识别模型中,获取捕捞作业行为判定结果。将渤海及黄海北部37°N以北区域按×划分网格,依照公式(15)计算捕捞努力量,统计网格中所有辽宁省拖网渔船在2021年1月1日0时至2021年12月31日24时的捕捞努力量,在ArcGIS中绘制捕捞努力量热力图。
2 结果与分析
2.1 基于XGBoost的拖网渔船捕捞作业行为识别算法结果
训练数据用5条船的船位数据共计60 362条,随机分配训练和内部测试集,用于评估模型的拟合程度。由49 912条数据训练XGBoost分类器,五折交叉训练平均准确率为96.60%。在10 450的内部测试集中,包含捕捞作业行为数据6140条,正确识别5 962个,测试集敏感性为97.10%;包含非捕捞作业行为4 310个,正确识别4 135个,测试集特异性为95.94%,整个内部测试集准确率为96.62%。由内部测试结果可知,模型能够较好地拟合捕捞作业行为数据特征。
为了进一步评估模型对新样本的适应能力,即泛化能力,本研究将标注的剩余7条船包含114 734条数据用作外部验证集,该测试集包含36 580条捕捞作业行为数据和78 154条非捕捞作业行为数据。在相同的训练集上,利用网格搜索训练了极限学习机和随机森林模型,计算其准确率、马修斯相关系数、灵敏性及特异性。测试对比结果如表1所示。

表1 拖网渔船捕捞作业行为识别模型的外部测试结果Tab.1 External validation results of traw ler fishing behavior recognition algorithm s
通过外部验证结果可以发现,相较于极限学习机和随机森林算法,XGBoost的准确率高出1.12和0.09个百分点,敏感性高出12.23和9.38个百分点。与随机森林和XGBoost相比,极限学习机在特异性方面表现更好,分别高出0.22和4.92个百分点。然而从捕捞作业行为和非捕捞作业行为整体识别结果来看,为了综合考虑实际样本与预测样本之间的相关性,马修斯相关系数是二分类问题的最佳度量指标。XGBoost的马修斯相关系数比极限学习机和随机森林高2.18和0.22个百分点,这表明在拖网渔船捕捞作业行为分类问题上,XGBoost的性能相对更好,泛化能力也更强。
为了分析XGBoost对外部测试集的捕捞和非捕捞作业行为的具体识别性能,统计了两种行为的预测结果如表2所示。

表2 基于XGBoost的拖网渔船捕捞作业行为分类条数混淆矩阵Tab.2 Confusion table of traw ler fishing behavior recognition based on XGBoost
通过表2的统计数据和表1的特异性和敏感性都可以看出,模型对捕捞作业行为的识别效果明显好于非捕捞作业行为。主要考虑与数据体量和多样性相关,由于数据规模庞大,本文随机选择5条标注好的渔船。
总体分析内部测试和外部验证的结果可看出,基于XGBoost的拖网渔船捕捞作业行为识别模型的准确率、敏感性、特异性和马修斯相关系数都优于其他算法,且通过外部测试验证了模型具有较好的泛化能力,因此模型得出的分类结果可以用于后续捕捞努力量评估。
2.2 辽宁省拖网渔船捕捞努力量计算结果
根据XGBoost模型识别结果,统计辽宁省拖网渔船2021年1月1日0时至2021年12月31日24时在渤海及黄海北部的捕捞努力量(单位:kW·h)分布,如图3所示。
由计算结果可知,2021年辽宁省拖网渔船全年在渤海及黄海北部海域内捕捞努力量数值总计约5 327.27×104kW·h,大部分位于辽东湾渔场、石岛渔场及莱州湾渔场,尤其集中在海洋岛渔场、烟威渔场海域。捕捞努力量密集区分别位于2处:①38°00′~39°22′N、120°07′~124°00′E,即海洋岛渔场、辽东湾渔场南部和烟威渔场北部海域,区域内累计捕捞努力量约为4 341.74×104kW·h,最高网格内捕捞努力量累计约103.09×104kW·h,位于海洋岛渔场内;②37°00′~38°00′N、121°53′~124°00′E,即烟威渔场东部和石岛渔场东北部海域,区域内累计捕捞努力量约为903.28×104kW·h,最高网格内捕捞努力量累计约60.55×104kW·h。
为了分析捕捞努力量的时空分布特征,本研究按月统计了辽宁拖网渔船在渤海及黄海北部区域内的累计捕捞努力量,图4为非禁渔期的8个月中每个月的捕捞努力量热力分布图。

图4 辽宁省拖网渔船捕捞努力量热度按月分布图(黄渤海区)Fig.4 M onthly distribution of fishing fever of traw ler in Liaoning Province(the Bohai Sea and the Yellow Sea)
由图4可知,辽宁省拖网渔船在2021年1月渤海及黄海北部区域内的捕捞努力量主要集中在38°13′~39°13′N、120°30′~123°47′E,主要为海洋岛渔场南部、辽东湾渔场东南部、莱州湾渔场东北部及烟威渔场北部海域。2月由于春节因素总体捕捞努力量减少,主要集中在38°14′~39°00′N、120°30′~123°30′E海域。
3月后捕捞努力量增加,主要集中在2个区域:①38°07′~39°06′N、120°30′~123°07′E,主要为海洋岛渔场南部、烟威渔场北部和辽东湾渔场东南部近海岸和莱州湾渔场东北部海域;②37°00′~38°00′N、123°22′~124°00′E,主要为烟威渔场和石岛渔场。4月相比3月在区域①附近海域捕捞努力量增加幅度大,主要集中在38°07′~39°22′N、121°00′~123°52′E近海岸区域,分布在辽东湾渔场、海洋岛渔场和烟威渔场。
9月禁渔期结束后捕捞努力量集中分布在37°45′~39°30′N、120°07′~124°00′E,主要包含辽东湾渔场、烟威渔场和海洋岛渔场。10、11月捕捞努力量大幅增加,主要分布在2个区域:①38°00′~39°30′N、120°07′~124°00′E近海岸区域捕捞努力量累计最高;②37°00′~38°00′N、123°37′~124°00′E,主要为烟威渔场和石岛渔场。12月捕捞努力量累积量比10、11月分布相对集中,主要集中在海洋岛渔场和烟威渔场。
3 讨论
捕捞努力量估计精度取决于渔船捕捞作业状态识别准确率。捕捞作业行为受海上船只运动模式和渔民捕捞习惯等多方面因素影响[32],仅以单一特征对其描述会造成误判,致使捕捞努力量误差高,影响渔业管理政策制定。
XGBoost在分类问题上具有良好的性能和计算效率[24]。本文采用XGBoost构建拖网渔船捕捞作业行为分类模型,内部和外部验证的准确率均超过96%,马修斯相关系数达0.923 4。根据SOUZA等[21]描述的拖网作业速度阈值,本文以2.5~5.5 kn航速对测试数据进行阈值分类,实验准确率为92.84%,远低于XGBoost算法结果。结果证实,在捕捞作业行为识别任务中,非线性模型相对简单的阈值分类能更准确地描述特征与捕捞作业行为的关系。为比较XGBoost与其他经典机器学习算法的结果,本文复现了BEHIVOKE等[22]采用的RF算法,实验结果表明,XGBoost的准确率和马修斯相关系数略高于RF算法。事实上,XGBoost适用于结构化数据,减少了模型偏差,且XGBoost在GBDT基础上加入RF的列采样思想,进一步避免了过拟合。实验结果也证实,在处理捕捞作业行为识别任务方面,XGBoost的boosting串行算法比RF的bagging并行机制更加适用。除此之外,本文实现了一种基于前馈神经网络ELM的捕捞作业行为识别模型,实验准确率为95.35%,低于XGBoost。实验过程中观察到ELM的实验结果不稳定,隐含层参数的随机初始化结果对准确率存在很大影响,本文给出的ELM结果为网格搜索过程中最优模型的测试结果,与ELM相比,XGBoost的捕捞特征学习性能更具稳定性。本文构建的拖网渔船作业行为识别模型具有良好的泛化能力,能够为捕捞努力量计算提供有效的数据支撑。
我国海域内拖网渔船作业具有较强的空间特性,本文构建的渔船作业特征向量在现有研究的基础上增加了船到海岸线实时距离,在输入的特征参量上补充了渔船行驶的空间信息。为证实本文新增的特征对提高模型准确率有效,实验分别用包含和非包含到岸距离的特征训练XGBoost算法并测试。结果表明,新增到岸距离后模型准确率提高约0.3%。证实了本文增加的空间关系信息可以提高捕捞作业行为识别模型的准确率。
为了评估实验误差,本文选取4条标注渔船进行捕捞努力量计算。标定捕捞努力量共计3.74×104kW·h,经本文算法计算,捕捞努力量共计4.36×104kW·h,平均绝对误差(MAE)为0.100 9 kW·h,均方根误差(RMSE)为0.985 1 kW·h。造成误差的原因可能有两个:1)不同拖网渔船作业航速不同,通过对拖网捕捞船行驶过程中速度的观察分析,发现部分拖网船作业时速度偏高,部分拖网船速度较低。2)不同渔船作业渔场不同,多数渔船选择较远渔场捕捞作业,也有部分渔船选择近岸渔场。
为进一步提高捕捞作业行为识别模型的准确率,减小捕捞努力量误差,可以从特征优化、超参设置和扩大数据规模3个角度考虑。在特征优化方面,本文虽补充了到岸距离作为空间信息,但渔船作业具有更多空间特性,未来可以通过提取有效的船与船间的空间信息作为特征参数,提高模型准确率。在超参数设置优化方面,本文采用交叉验证和网格搜索的方法确定模型的超参数,相关文献有采用灰狼优化算法(GWO)[33]和果蝇优化算法(FOA)[34]等启发式算法优化超参数选择,未来可以选取合适的启发式算法优化XGBoost的超参数选择,提高模型准确率。另外由于船位数据标注的工作量非常大,本文选取的拖网渔船数据量有限,为后续优化模型,可以扩充数据量进一步提高模型性能。
