基于BAS-BPNN的调频无线电引信目标与扫频干扰识别方法
2023-09-07刘冰郝新红周文杨瑾
刘冰, 郝新红, 周文, 杨瑾
(北京理工大学 机电动态控制重点实验室, 北京 100081)
0 引言
现代信息化战争战场环境使得无线电引信工作环境具有探测背景多变、打击目标多样、面临的电磁环境恶劣等多重复杂特征[1-2]。未来作战方式与战场环境迫切需要智能化无线电引信,其应具有复杂电磁环境感知与目标实时自主识别的能力,具有从目标发现与识别、炸点与毁伤控制推理到毁伤控制决策的全过程控制的智能化[3-4]。因此,研究无线电引信目标与扫频干扰信号的识别方法具有重要意义,可为智能无线电引信精准目标打击提供理论支撑。
目前的国内外文献中,已经有很多对无线电探测器目标识别方法展开了研究。文献[5]提出一种雷达脉冲压缩方法,利用块密码生成相位和频率加密码,同时利用四相码代替二进制码,实现了较好的抗干扰效果。文献[6]基于信息型干扰下脉冲多普勒引信基带滤波器的输出信号,结合脉冲多普勒引信目标函数,并利用二分类与单分类支持向量机构造引信期望信号空间,设计了基于目标联合特征提取和识别的引信原理样机,实验结果表明,分类识别成功率大于90%。文献[7]通过对不同调制类型的汽车雷达信号进行二维傅里叶变换,得到距离-多普勒图像,然后利用卷积神经网络(CNN)进行分类识别,最终的准确率超过96%。文献[8]针对脉冲多普勒引信受到的箔条干扰,以飞机目标调幅带宽和调频带宽作为特征量,结合Kruskal-Wallis检验和反向传播神经网络(BPNN),提出一种能识别出飞机目标和箔条干扰的分类识别方法。文献[9]提出一种基于调频载波(FMCW)雷达的飞行器分类算法,以回波信号的微多普勒特征作为分类依据,利用轻量级CNN对目标进行识别,最终的准确率达到95%。文献[10]提出一种用于雷达目标和欺骗式干扰的信号融合算法,利用目标和干扰信号的空间散射差异,结合奈曼皮尔逊准则,实现干扰信号的恒概率检测,实验和仿真结果证明了该方法的可行性。文献[11]建立了对地调频引信粗糙面差频信号模型,利用二维距离-速度提取方法提取其差频频率和多普勒频率,采用差频频率峰值带宽和多普勒频率峰值带宽2个特征量识别地面目标回波信号和数字射频存储器(DRFM)转发式干扰信号。
本文以某型连续波调频无线电引信为分析对象,针对对调频引信威胁最严重的噪声调幅扫频、正弦调幅扫频、方波调幅扫频和纯扫频干扰信号,提出基于无线电引信检波端输出信号频域信息熵、范数熵和倒频谱熵的特征矩阵,作为天牛须搜索(BAS)-BPNN的输入,对检波端输出信号和干扰进行分类识别的方法。通过对实测数据的实验,结果表明,该方法能够有效地对目标和调幅扫频干扰信号进行分类识别。
1 连续波调频无线电引信目标信号特征提取
1.1 数据采集
本文数据为在微波暗室环境内实测采集的某型调频引信数据,信号的采样频率为1 000 kHz,采集引信启动信号输出时刻前50 ms内的数据点,即采集引信启动信号输出前的50 000个数据点进行信号处理分析。其中,采集微波暗室内铁板模拟的目标作用于引信的检波输出信号200组,噪声调幅扫频干扰信号作用于引信的检波端输出信号78组,正弦调幅扫频干扰和方波调幅扫频干扰作用于引信的检波端输出信号各80组,纯扫频信号作用于引信检波端输出信号40组。图1(a)~图1(e)分别为目标信号作用下、噪声调幅干扰信号作用下、正弦调幅干扰信号作用下、方波调幅干扰信号作用下和扫频信号作用下的引信检波端输出信号时域波形图,通道1的信号(黄色)为检波时域信号,通道2的信号(绿色)为引信启动信号。
1.2 信号预处理
为了最大程度抑制无用的噪声信号的输入,同时降低数据维度减少信号数据处理的复杂度,对无线电引信检波端的输出信号遵循如下的采集策略:引信开机后,对检波端输出信号进行频率为 1 000 kHz 的采样,直到采集到引信的启动信号后,停止采样。将采集到的所有数据点存储下来,选取引信启动信号输出前的50 000个数据点作为后续信号处理分析的样本点,即引信启动前0.05 s的数据点。预处理后的目标和各干扰信号作用下引信检波端输出信号如图2所示。
1.3 基于熵的信号特征提取
1.3.1 频域信息熵特征
信息熵最初提出是为了表示热力学中热状态的不平衡程度,而现在将熵理论应用于信息论中,其物理意义则是表示信息系统描述信息的能力[12]。如果一个系统越有序,熵值越小,反之,一个系统越混乱,熵值越大。熵可以与不同信号处理手段有机结合从而实现不同变换空间的信号特征提取[13]。
(1)
本文中,对引信检波端输出的信号进行频域的信息熵的特征提取,引信检波端时域输出信号为uk,k=1,2,…,K,K为检波端输出信号的采样点个数,对时域信号进行快速傅里叶变换(FFT)后,可以得到检波端输出信号的频谱Ur,r=1,2,…,N,N为检波输出信号频域频点个数,检波端输出信号在频域的能量值表示为
(2)
计算频域每一个频点能量占总能量的比值,计算式为
(3)
将式(3)代入式(1),可求得检波端输出信号频域信息熵值,用Hf表示,即
(4)
1.3.2 范数熵特征
目标回波信号检波端输出信号与干扰信号作用下检波端输出信号频谱形状不同,能量的分布函数不同,范数熵可用来定量描述信号的能量分布情况[14]。范数熵的定义如下:
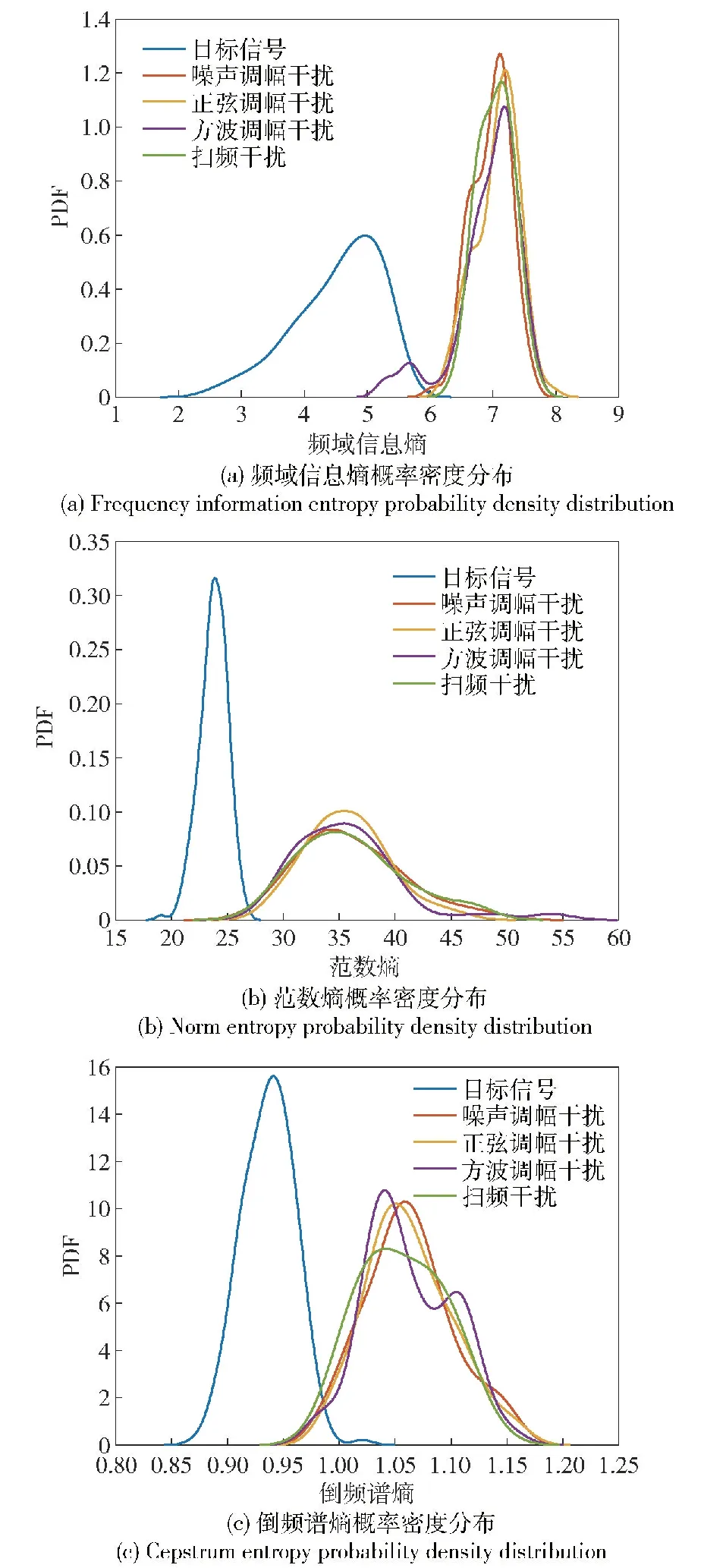
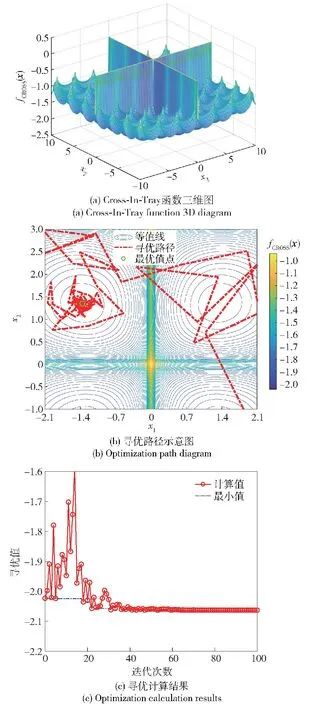
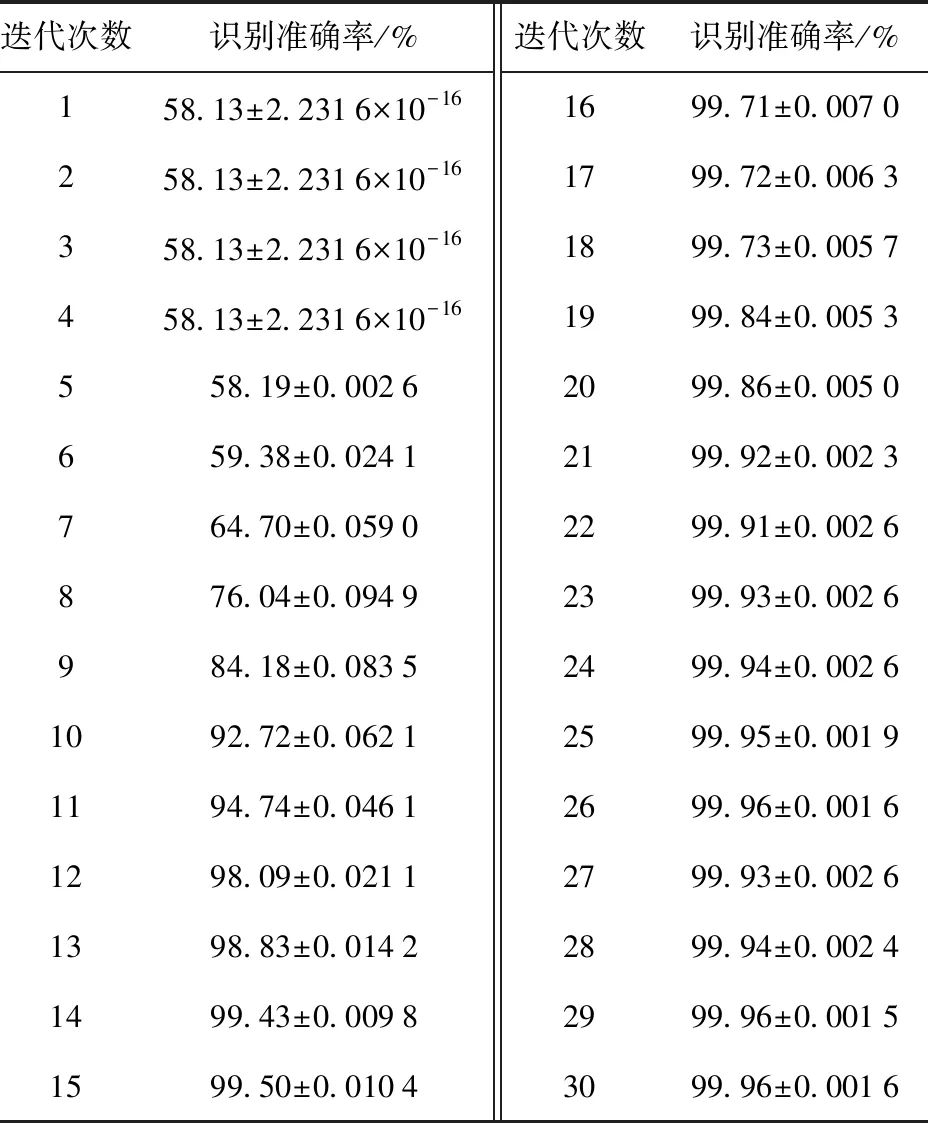
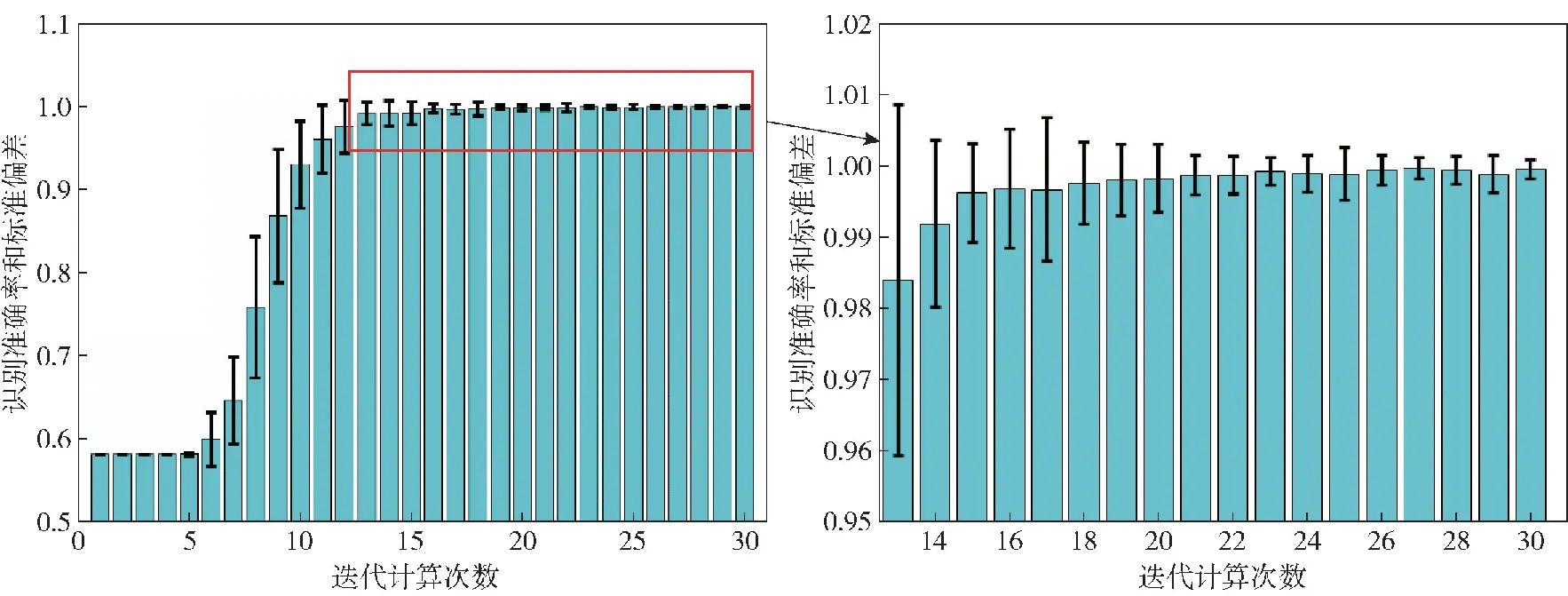
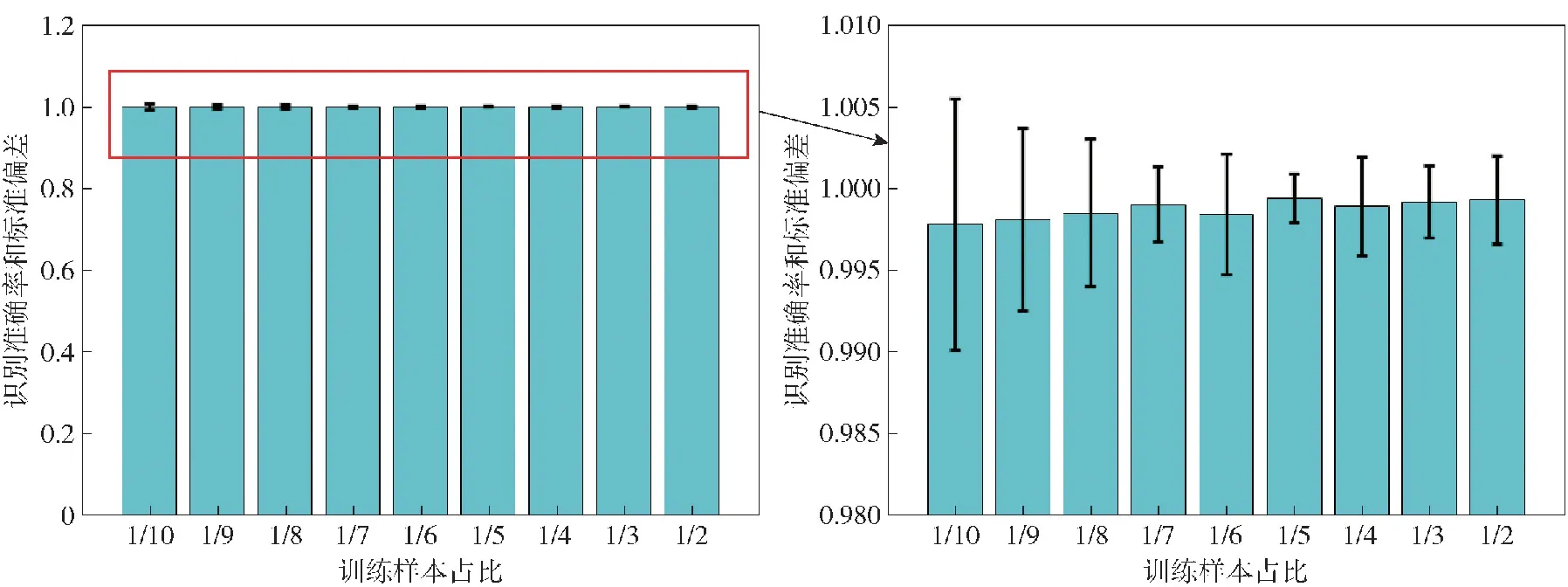
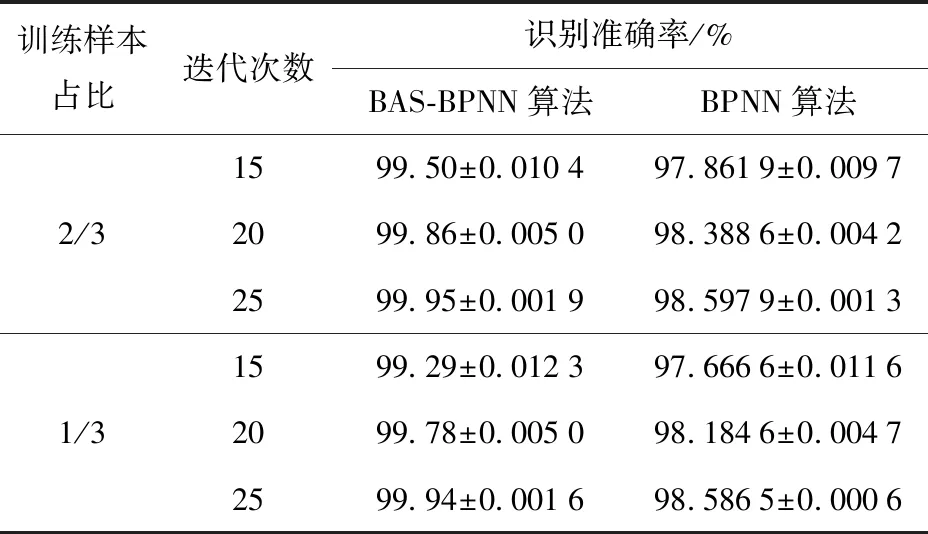
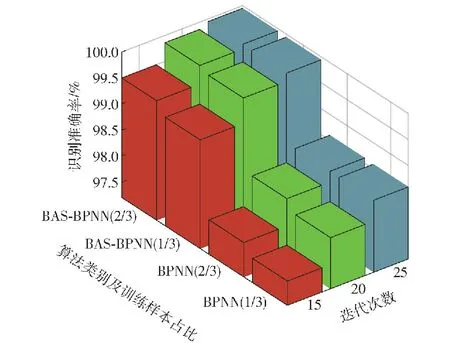
对于随机矩阵x=[x1,x2,…,xi,…,xM],令En(i)=|xi|P,1 (5) 为x的范数熵。检波端输出信号范数熵的计算方式与式(4)中检波输出信号频域信息熵的计算方法相似,只需将范数熵计算中利用的随机序列替换成检波端输出信号频谱序列Ur即为所求。在式(5)中,参数P的选取直接影响范数熵特征值的大小,因此选取合适的参数P值将会使得目标与干扰信号具备不同的差异显著性。以MATLAB软件中的显著性检验函数Kruskal-Wallis的输出p值为目标函数,选取最优范数熵中的P值,使得目标和干扰信号的范数熵特征的差异显著性最大,以利于后续分类准确度的提升。按照式(6)构建范数熵中P值的取值集合, P(j)=1+(j-1)×0.001,j=1,2,…,1 001 (6) 分别计算范数熵中P值对应的目标与干扰信号的Kruskal-Wallis检验输出p值,得到二者关系如图3所示,计算可得,当范数熵中P取值为1.345时,Kruskal-Wallis显著性检验的输出值p最小为3.800 6×10-74。当p值越小时,表明显著性检验的结果越显著,拒绝原假设的理由越充分,因此在范数熵的P值选取1.345时,式(5)中范数熵的表达式可以写为 图3 范数熵P值与差异显著性检验输出值的关系 (7) 且满足目标信号的范数熵与干扰信号的范数熵的差异显著性最大。 1.3.2 倒频谱熵特征 倒频谱也称为二次谱或对数功率谱,可用于分析复杂谱图中的周期性成分,可将谱图中的众多边频谱线简化为单根谱线,具有信息凝聚作用[15]。倒频谱包括的种类分别为幅值倒频谱、功率倒频谱和复倒频谱等,其中,工程中最常用的幅值倒频谱可通过对时域信号的幅值谱密度函数取对数之后,再进行一次傅里叶变换得到。对时域信号x(t)计算幅值倒频谱的方法如式(8)所示: Ca(q)=|F{lgSx(f)}| (8) 式中:q为倒频率,即时间;|F(·)|表示先进行傅里叶变换再取模;Sx(f)为时域信号x(t)的幅值谱密度函数。 本文中,同频域信息熵特征提取的方法类似,首先对引信检波端输出的采样后的时域信号进行FFT,然后对信号的幅值谱取对数,最后再进行FFT,并取模值,至此得到目标信号和干扰信号的倒频谱Ca(r),然后按照式(1)~式(4)的计算方法,求得目标与干扰信号的倒频谱熵。 提取的目标和干扰信号特征直接关系到后续目标与干扰识别分类结果的准确性,因此对于特征进行可行性分析极有必要性。首先采用概率密度函数(PDF)对目标和干扰信号的频域信息熵特征、范数熵特征和倒频谱熵特征进行定性分析。通过不同检波输出信号特征概率密度分布的重叠度来验证特征的可分性,分别绘制目标和干扰信号3种特征的概率密度分布函数图,如图4所示。图4(a)为目标与干扰信号频域信息熵的概率密度分布图,该特征下目标信号和方波调幅干扰信号的曲线有小部分的重合,目标信号与其他干扰信号的曲线仅有极小部分的重合,因此可以初步判定,频域信息熵特征对于目标信号和干扰信号具有区分度。图4(b)为目标与干扰信号范数熵的概率密度分布图,该特征下目标信号的曲线与干扰信号的曲线在范数熵取值范围重合部分占据目标信号范数熵取值范围的较大部分,但是占据的概率密度值极小,因此可以初步判定,范数熵特征对于目标信号和干扰信号具有区分度。图4(c)为目标与干扰信号倒频谱熵特征的概率密度分布图,该特征下4种干扰信号曲线比较类似,与目标信号具备一定程度的重合,但是重合部分面基只占据各自总面积的小部分,同样可以初步认定倒频谱熵对于目标信号和干扰信号具备区分度。 图4 频域信息熵、范数熵和倒频谱熵概率密度分布 通过特征值概率密度分布函数图的重合度判定不同信号类型的可分程度,只能做定性分析,初步大致判定不同特征类型对目标和干扰信号区分的可行性,并没对各自特征下的目标和干扰信号的可分性做定量分析,下一步通过差异显著性分析方法对取不同特征目标和干扰信号的可分程度进行分析。由于目标信号与干扰信号的参数在特征提取之前并不确定具体满足哪一种统计分布类型,因此对于特征的差异显著性检验选取非参数Kruskal-Wallis检验方法,又称为单因素非参数方差分析,该检验的原假设是k个独立样本来自同一个分布总体。MATLAB软件中的Kruskal-Wallis检验工具箱对检验样本的差异显著性进行分析后返回p值,遵照统计学原则认为,当返回值p<0.05时为具有统计学差异,当返回值p<0.01时为具有显著统计学差异,当返回值p<0.001时为具有极其显著的统计学差异。在前一部分对于目标和干扰信号的频域信息熵特征、范数熵特征和倒频谱熵特征进行定性分析之后,利用非参数Kruskal-Wallis检验方法对于这几种特征进行定量分析。利用Kruskal-Wallis 工具箱分别绘制不同特征类型下目标和干扰信号的分布箱型图,并求解出检验返回p值,结果如图5所示。图5(a)为目标与干扰信号频域信息熵特征的箱型图,输出值pFE=3.078 5×10-74。图5(b)为目标与干扰信号范数熵特征的箱型图,输出值pNE=3.806 8×10-74。图5(c)为目标与干扰信号倒频谱熵特征的箱型图,输出值pCN=6.642 4×10-74。3种特征的Kruskal-Wallis检验输出p值均远远小于0.001,因此可认定目标和干扰信号的频域信息熵、范数熵和倒频谱熵具有极其显著的差异特性,用于区分目标和干扰具备可分性。 图5 目标和干扰信号频域信息熵、范数熵和倒频谱熵箱型图 BAS算法是由Jiang等[16]在2017年提出的一种基于天牛觅食过程中搜寻食物具体方位原理的函数全局寻优算法。BAS算法只关注一个个体即天牛本身,并不需要知道函数的具体形式和梯度信息,相比于粒子群优化算法,运算量小、收敛速度快,具有全局寻有能力等优点[17]。建模流程如下: 1)建立天牛头部朝向的随机方向向量: (9) 式中:rands(·)表示随机函数;k表示空间位置的维度。 2)建立天牛左须和右须的空间坐标: (10) (11) 式中:xr为天牛右须的坐标;xl为天牛左须的坐标;xt表示第t次迭代后头部质心位置空间坐标;dt表示第t次更新时两须之间的距离。根据上面得出的左右须的空间位置坐标,分别求解相应的位置的气味浓度值,即目标函数值f(xr)和f(xl),并通过式(12)的迭代更新公式,对于天牛新的头部质心位置进行更新计算: xt=xt-1+δtbsign(f(xr)-f(xl)) (12) 式中:δt为第t次迭代更新时的步长。 为了保证收敛速度同时避免陷入局部最小值,更新步长δt和两须之间的距离dt通常按照如式(13)和式(14)所示的更新规则进行更新: dt=αdt-1 (13) δt=βδt-1 (14) 式中:α和β分别为[0,1]之间的小数,一般取值α=β=0.95。 为验证BAS算法在在处理最优化问题时的有效性,选取加拿大Simon Fraser大学公共的虚拟仿真实验库测试函数集中2个测试函数进行验证,选取的函数分别为Ackley函数和CROSS-IN-TRAY函数。BAS算法参数设置选取两须之间的距离初始值dt=2,初始步长δt=2,迭代更新系数α=β=0.95,迭代次数n=100,空间维度k=2。 Ackley函数广泛地应用于优化算法地测试中,表达式为 (15) 为便于搜索结果的可视化展示,选取维度2,即d=2、a=20、b=0.2、c=2π。 图6中(a)为二维Ackley函数地三维图像,由图6(a)可见该函数存在多个局部极小值,存在一个全局最小值,理论上该函数在x*=(0,0)处取得全局最小值f(x*)=0,图6(b)为BAS算法搜寻Ackley全局最小值地搜索路径示意图,最终地计算结果为在x=(-0.000 342 34,0.002 338 4)处取得最小值f(x)=0.006 833 2,与理论值相近。图6(c)为BAS算法随迭代次数地增减计算最小值与最终最小值的曲线关系图,由图可见在经过67次迭代后,计算值趋于收敛,不再波动。 CROSS-IN-TRAY函数具有多个全局最小值,同样作为测试函数广泛应用于最优化算法的测试中,函数的表达式如式(16)所示: (16) 该函数理论上在x*=(±1.349 1,±1.349 1)可取得全局最小值,f(x*)=-2.062 61,图7(a)为Cross-In-Tray函数三维图,图7(b)为BAS算法搜索测试函数最小值的示意图。计算结果为在x=(-1.348,1.346 4)处取得最小值f(x)=-2.062 6,与理论值几乎一致。由图7(c)可知,在40次迭代之后,BAS算法可计算搜寻到函数的最小值,结果收敛不再波动。 图7 BAS算法搜索Cross-In-Tray函数最小值结果 利用BAS算法在函数全局寻优中的收敛速度快等特点,对BPNN的初始神经元连接权重和神经元输出阈值进行优化,以网络的计算输出值与实际输出值的均方误差为目标函数函数,对网络的初始值进行更新计算,选出均方误差值最小的初始参数集合,即求解目标函数取得的最小值时的参数集合。目标函数可表示为 (17) 式中:自变量组合(w,b)为神经元连接权重和输出阈值的集合,(w,b)的初始值可根据式(9)中的描述,随机生成;i为网络的计算输出值;Yi为网络的实际输出值,在本文中,实际输出值即为训练样本中信号的实际种类。BAS优化BPNN初始参数的算法流程图如图8所示。 图8 BAS确定最优网络初始参数流程图 为进一步验证1.3节所提出的信号频域信息熵特征、范数熵特征和倒频谱熵特征的可分性和BAS-BPNN的分类识别性能,选取某型连续波调频无线电引信的微波暗室实测数据进行实验。由于无线电引信在战场环境中作用的重点是目标和干扰信号的分类与识别问题,并没有对各类干扰信号进行区分的必要性。 本文的研究重点在目标与干扰信号的分类识别。选取引信在目标作用下的检波端输出信号200组,噪声调幅扫频干扰信号作用下检波输出信号78组,正弦调幅扫频干扰信号作用下检波端输出信号80组,方波调幅扫频干扰作用下检波端输出信号80组,纯扫频信号干扰作用下检波端输出信号40组。其中,噪声调幅扫频、正弦调幅扫频、方波调幅扫频和纯扫频干扰信号共同归纳为干扰信号,共计278组。数据实测采集的现场如图9所示,调频引信、目标、干扰机和干扰机天线已经在图中标注。 图9 实验场景示意图 数据采集实验中,干扰机的参数设置对标美国“游击手”电子干扰系统的参数进行等效功率密度换算,引信及干扰机参数设置方法如表1所示。 表1 实验参数设置 为了更高效地对不同特征进行分类识别,避免信号特征量纲差异对识别准确率带来的影响,在特征输入网络之前,首先需要对特征数值进行归一化处理,将不同信号类别的同类特征进行归一化处理,采用线性归一化函数,将原始特征数据映射到[0,1]之间,归一化函数公式为 (18) 式中:mn为归一化之后的特征值;m为原始特征值数据;mmax为同类特征中最大特征值;mmin为同类特征中最小的特征值。 BPNN分类器的隐层神经元和输出层神经元的激活函数选取Sigmoid激活函数,该函数的表达式为 (19) 典型的Sigmoid函数的函数图像如图10所示,它可以把较大范围内变化的输入值挤压到(0,1)输出值的范围内。当输入值在0附近时,Sigmoid函数近似为线性函数;当输入值靠近两端时,对输入进行抑制。输入越小,越接近于0;输入越大,越接近于1[18-20]。 图10 Sigmoid激活函数 在200组检波端目标输出信号和278组检波端干扰输出信号中,随机选取2/3的数据作为训练样本,剩下1/3的数据作为测试样本,即随机选取 133组目标信号和185组干扰信号作为训练样本,67组目标信号和93组干扰信号作为测试样本。对选取出来的每一组信号分别进行特征提取处理,提取出频域信息熵特征、范数熵特征和倒频谱熵特征,组成特征矩阵,经类间归一化处理后,准备作为BPNN的输入参数。 为验证目标与干扰信号识别方法的性能,本实验首先研究对比了训练样本在网络训练过程中迭代次数对于目标识别方法的影响。选取相同的训练样本,网络的训练次数取值范围为1~30,步进间隔为1,共计30组不同的训练迭代次数训练而成的网络,对每组实验分别重复进行100次,测试得到不同样本训练迭代次数识别准确率平均值和标准偏差平均值。 在无线电调频引信的实际作战场景中,为抵抗扫频式信号的干扰,需要对于目标信号和扫频式干扰信号进行区分,即只需要判断检波端输出信号是目标还是干扰信号然后根据判决结果执行下一步的决策。本文使用识别准确率评价所提方法的性能,识别准确率定义为 (20) 式中:DTT为将目标识别成目标的数目;DJJ为将干扰识别成干扰的数目;NT为目标总数;NJ为干扰总数。 测试结果如表2所示。直观观测不同迭代次数对目标识别准确率的影响以及识别准确率的标准偏差变化情况,绘制不同迭代次数目标识别准确率和标准偏差的柱状图如图11所示。由图11可以看出,识别准确率随着迭代次数的增加,初始呈现增加趋势:在迭代次数15次时,识别准确率趋于稳定,且标准偏差变小,即识别准确率趋于稳定;随着迭代次数从15次增加到30次的过程中,识别准确率呈现小幅度波动趋势,在迭代次数为26次时,首次取得最高的识别准确率99.96%,且标准偏差为0.001 6,在迭代次数为 29次、30次时,识别准确率在此时再次达到到最高99.96%。 表2 识别准确率随迭代次数变化 图11 不同迭代次数识别准确率和标准偏差 在验证训练样本不同迭代次数对于识别准确率的影响后,实验再次研究对比了不同训练样本占比对目标识别方法性能的影响。随机选取的训练样本数目分别占据样本总量的1/10、1/9、1/8、1/7、1/6、1/5、1/4、1/3、1/2,为确保测试样本中的数据不包含任何训练样本,选取样本总量除去训练样本的部分作为测试样本,即测试样本分别占据数据总量的9/10、8/9、7/8、6/7、5/6、4/5、3/4、2/3、1/2。训练样本的训练迭代次数选为26次,对于不同的训练样本占据样本总量的实验,分别重复进行100次测试,然后计算求得100次测试的识别准确率平均值和识别准确率标准偏差平均值,结果如表3所示。由表3可以看出,在训练样本数占比分别为1/10、1/9、1/8、1/7、1/6、1/5、1/4、1/3、1/2,训练迭代次数为26次时,分类识别方法均取得了不错的识别准确率,识别准确率最差为训练样本占比1/10时的99.78%,识别准确率最优为训练样本占比为1/2时的99.94%,且标准偏差都相对较小。 表3 识别准确率随训练样本数占比变化 图12为表3中数据的直方图和标准偏差分布直方图,可以看到不同训练样本占比情况下,识别准确率都表现出良好的性能,差异很小,进一步说明信号特征提取方法和目标识别方法对于目标信号和干扰信号具备良好的可分性。 图12 不同训练样本占比识别准确率和标准偏差 为了验证本文算法对目标与干扰信号分类识别的性能,选取BPNN分类器进行对比实验,对比过程选取相同的训练集数据和测试集数据,迭代次数分别选取15次、20次和25次,训练样本占比分别选取2/3和1/3,每组实验分别重复100次,以最终的识别准确率平均值和标准偏差的平均值作为衡量指标,对比结果如表4所示。由表4可以看出,在相同训练样本占比和相同迭代次数的情况下,本文算法的识别准确率均优于BPNN算法。图13为表4的簇形柱状图表示,算法类别及训练样本占比坐标轴中,BPNN(1/3)表示选择的算法为BPNN、训练样本占比为1/3,以此类推。由图13可以更加直观地观察到本文算法相比于BPNN算法,对目标和干扰信号分类具有更优的识别准确率。 表4 不同算法识别准确率对比 图13 不同算法识别准确率 本文针对调幅扫频式干扰对连续波调频无线电引信的威胁,提出一种以频域信息熵、范数熵和倒频谱熵作为特征参量,以BAS优化BPNN初始连接权重值和阈值后作为分类器的连续波调频无线电引信目标与干扰分类识别。通过采集某型连续波调频无线电引信微波暗室实测数据,分别提取目标和干扰信号作用下引信检波端输出信号的频域信息熵、范数熵和倒频谱熵特征。首先对提取的特征可分性进行定性和定量分析,然后作为输入值对优化初始权重值和阈值的神经网络的连接权值和阈值进行再次训练,得到最优的优化神经网络分类模型;对未知的信号经过预处理提取相应特征输入训练好的优化神经网络模型中,根据网络的输出结果对输入信号类型进行识别。得出以下主要结论: 1)所提出的频域信息熵、范数熵和倒频谱熵特征提取方法对于目标和干扰信号具备显著性差异。 2)利用BAS优化初始权重值和阈值的BPNN作为分类器对目标和干扰信号的特征进行分类识别,可获得很高的识别正确率,在迭代次数为 26次的情况下,识别准确率达到99.96%,具备很好的连续波调频无线电引信的对目标和干扰信号的识别能力,为无线电引信的抗干扰设计提供了理论依据。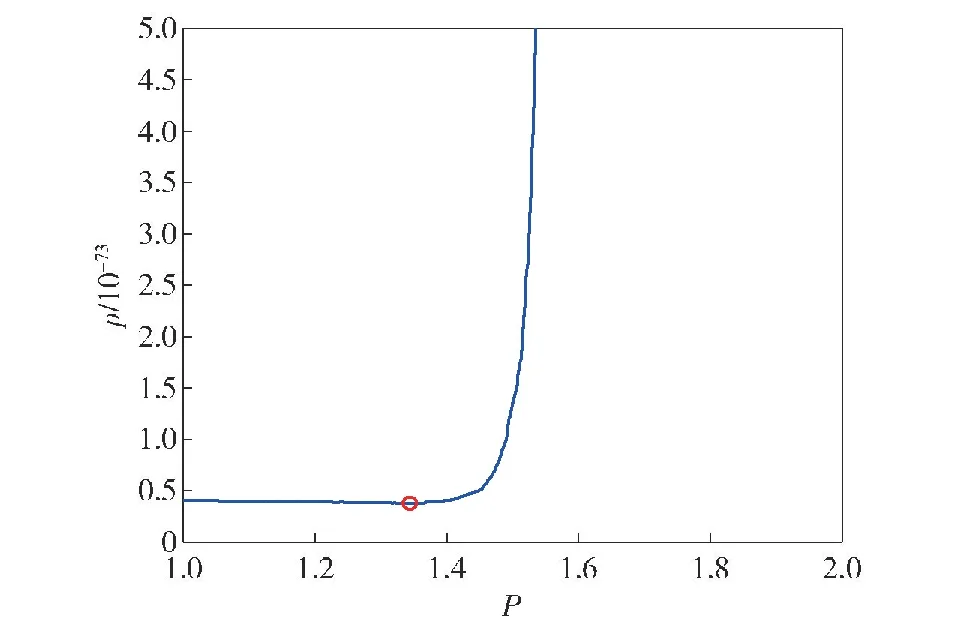
1.4 信号特征可行性分析

2 BAS-BPNN目标信号识别方法
2.1 BAS算法原理
2.2 BAS算法性能验证
2.3 BAS-BPNN算法

3 实验结果与分析



4 结论
