融合网络结构和属性嵌入的社区发现方法
2023-07-15王淑勤
吴 琪,黄 芳,王淑勤,卢 港
(中南大学 计算机学院,长沙 410083)
1 引 言
社区发现是大数据环境下社会网络分析的一个重要研究课题,可以帮助理解社会网络的内在模式和功能[1].传统社区发现方法大多是基于网络拓扑的模块性来实现社区划分的,这样的社区划分方法不能较好地适应不同应用场景下的不同网络特征.此外,社区划分的标准除了模块性外,节点的属性是影响社区发现有效性的一个重要因素,这就需要在传统社区发现方法基础上增加相应的处理步骤[2,3].所以,针对大规模复杂多样性网络,传统的社区发现方法既不具备普适性,也不是一种端到端的高效方法.当前,通过网络嵌入来实现端到端的网络计算已成为了一种流行的方案,网络嵌入能够基于原始数据进行特征学习,将网络中节点和边的拓扑性映射为低维向量,以实现具有复杂多样性特点的网络计算.有大量的研究表明,通过将节点表征为低维向量来解决复杂网络中的链路预测问题,并取得了较好的效果[4,5].
但是常规的网络嵌入方法并不能有效地解决社区发现问题.目前,常规的网络嵌入方法根据对节点相似性的不同假设,主要可以分为两类:1)近邻相似假设,即存在连边的两节点相似;2)空间结构相似假设,即具有相同度(degree)的节点是相似的,若各自邻接节点仍具有相同的度,那么节点的结构相似度就更高[6].而社区的基本定义规则是同一社区中的节点连边较多,不同社区间的节点连边较少[7].这说明不同社区的节点间可能存在连边,因此近邻相似不能等同于社区性相似,所以,基于近邻相似假设网络嵌入方法不完全适用于节点的社区性质表征.同样,节点的空间结构相似不能表示节点属于同一社区的基本性质.因此,基于空间结构相似假设的网络嵌入方法不能完整地体现社区性质的表征.针对社区发现问题,需要一种能够合理反映社区性质相似性假设的网络嵌入方法.另外,除社区的基本定义规则外,社区中的节点往往共享相同的属性或提供类似的功能[1],因此节点属性也是体现社区性的重要因素,这就需要将网络拓扑性与节点属性相结合来实现社区发现.因此,本文提出了一种融合嵌入网络结构和节点属性的综合社区性质向量表征方法对网络进行嵌入,该方法将邻接特征、边介数(Betweenness)、局部模块度(Local Modularity,LM)为代表的社区特征与节点属性相融合,实现节点的综合社区性向量表征,然后根据向量表征的相似性进行无监督聚类,以实现端到端的社区发现.
本文的主要贡献包括以下内容:
1)提出了一种综合社区性嵌入(Comprehensive Community Embedding,CCE)的社区发现方法,该方法首先进行网络的综合社区性嵌入,得到节点的社区性向量表征,然后,基于K-聚类神经网络模型(K-Clustering Neural Network Model,K-CNN)对节点的综合社区性向量进行无监督聚类以实现社区发现.
2)提出了CommunityWalk的结构性社区特征嵌入方法,CommunityWalk采用社区性游走策略,在游走过程中融合网络结构的邻接特征、局部模块度和边介数的社区特征,再通过Skip-Gram模型[8]得到节点的结构性社区特征向量.同时,结合由自编码器(Autoencoder,AE)[9]嵌入的节点属性特征向量,以实现综合社区性的嵌入.
2 相关工作
2.1 社区发现方法
社区发现方法可以分为自顶向下的方法和自底向上的方法两种,前者以GN算法[10]为代表,它将原始网络视为一个大的社区,通过不断删除网络中边介数最大的边,实现网络的社区分割;后者以Louvain算法[11]为代表,最初将每个节点视为一个独立的社区,通过不断地将节点划分到与其邻接的节点所在的社区中,并根据模块度的增减来完成社区划分.Andrea Lancichinetti等人[12]比较了包括上述两种算法在内的12种传统社区发现方法,其中,Infomap算法[13]表现最佳.Infomap算法采用随机游走的方式在原始网络中获取社区特征,提高了对多样化原始数据的社区性分析,但对社区特征的挖掘上也局限于节点间的邻接关系.这3种社区发现方法分别以边介数、模块度和邻接关系作为社区特征进行社区划分,以单一的特征进行社区划分依据,使传统方法不能很好地解决不同网络结构下的社区发现问题.
此外传统社区方法仅针对网络结构特征进行社区划分,对于节点属性信息,需要进行额外处理.例如,SA-Cluster[2]将节点属性转换为属性边,然后在属性边和结构边构建的网络中使用随机游走来确定社区;MOEA-SA[3]提出了一种属性相似性目标函数,同时优化属性相似性目标和模块度目标,确定社区结构.目前,缺乏一种能够综合不同结构性社区特征,以及节点属性进行社区发现的通用性方法.
2.2 基于网络嵌入的社区发现方法
嵌入(Embedding)在学习字/词、图像等原始数据的非线性特征时表现出很大的优势[14,15].网络嵌入可以将网络结构特征嵌入到节点的低维向量中,然后,通过向量计算的方式完成链路预测、社区发现等下游任务.
目前主要的网络嵌入方法旨在学习网络的邻接拓扑特征,这并不适用于解决社区发现问题.例如,SDNE[4]将网络的邻接矩阵作为输入,使用自编码器模型捕获节点的一阶和二阶邻近关系.类似地,GCN[16]通过卷积层叠加实现多阶邻域的信息传递.此外,DeepWalk[17]通过随机游走采样节点序列,实际也是捕获网络中节点邻接关系.学习原始网络的领域特征进行网络嵌入,本质上是以向量的方式还原节点的连边关系,节点向量的相似度代表的是节点间拥有连边可能性,此类网络嵌入方法适用于解决链路预测问题.对于其他下游任务,Struc2vec[6]基于由有序度序列构造的层次带权图实现网络嵌入,解决节点空间结构相似问题;node2vec[5]通过出入参数和返回概率控制随机游走,综合采样深度优先遍历(Depth First Search,DFS)和广度优先遍历(Breadth First Search,BFS)的节点序列,使其适用于链路预测、社区发现等不同的下游任务.
针对社区发现问题,由于一般的网络嵌入方法在嵌入过程中,未考虑节点的社区特征,所以,在基于节点的嵌入向量进行社区发现时,往往会将节点划分到错误的社区[18].针对提取网络的社区特征,目前已有一些研究.DSFCD(community discovery based on deep sparse filtering)在网络嵌入后,基于深度稀疏过滤对社区特征进行抽取[19];NEC( Network Embedding for node Clustering)基于图卷积自动编码器模型实现局部结构和节点属性信息嵌入,并通过模块度最大化决定节点的软分配社区标签[20].然而,DSFCD方法仍依赖于一般的网络嵌入方法,并未基于原始社区结构实现社区特征嵌入;NEC方法对于社区特征的考虑局限于社区的模块性.所以,本文提出了一种综合社区性嵌入(CCE)方法,融合嵌入结构性社区特征和节点属性,来增强社区发现方法的普适性.
当网络中的节点被表征为嵌入了社区特征的向量后,可通过无监督聚类的方法实现社区发现.传统的K-means算法由于随机选择初始化聚类中心,所以存在聚类结果不稳定的缺点[21].Junyuan Xie等人[22]在图像聚类时定义了基于聚类损失的聚类神经网络(Clustering Neural Network,CNN),Bentian Li等人[23]将CNN与自编码器结合应用于网络嵌入.该聚类神经网络通过强化分配的标签和迭代指导优化聚类效果,允许更灵活的距离度量,达到了比传统的K-means算法更佳的效果.本文将该方法应用于基于网络嵌入的社区发现方法中,并针对CNN需预设聚类数目问题,提出一种K-聚类神经网络(K-CNN)的聚类方法,优化聚类的数目和质量.
3 基于综合社区性嵌入的社区发现方法
基于综合社区性嵌入的社区发现方案如图1所示,它分综合社区性嵌入方法和社区发现方法两部分组成.

图1 基于综合社区性嵌入的社区发现方法Fig.1 Community discovery method based on CCE
1)综合社区性嵌入,首先是CommunityWalk采用社区性游走策略,实现结构性社区特征嵌入,得到社区结构性表征向量Φstructure,然后,用自编码器实现属性嵌入,得到属性表征向量Φattribute.最后,结构性社区向量和属性向量拼接,得到综合社区性表征向量Φcommunity,定义为:
Φcommunity=(Φstructure,Φattribute)
(1)
2)社区发现.节点的综合社区性向量融合了节点在网络中的社区特征,因此节点的社区划分可以通过基于综合社区性向量的无监督聚类解决.聚类神经网络模型K-CNN对综合社区性表征向量Φcommunity中节点的社区性表征向量进行无监督聚类以实现社区发现,并通过迭代的方式优化社区数目和社区划分质量.
4 综合社区性嵌入
综合社区性嵌入CCE的重点在于基于CommunityWalk实现结构性社区特征的融合嵌入,然后与节点的属性特征组合,得到综合社区性向量表征.
4.1 结构性社区特征嵌入
网络的结构性社区特征主要体现在节点的连边关系,以及社区内部的连边密集程度上,这些特征可以通过网络的邻接特征和局部模块度体现.此外,边介数可以衡量一条边作为信息共享路径的重要程度,由于社区内外的信息共享程度是不同的,所以,边介数可以作为社区划分的依据.因此,本文的CommunityWalk的结构性社区特征嵌入方法,改进DeepWalk的随机游走方法,通过社区性游走策略来捕获包括邻接特征、局部模块度和边介数在内的结构性社区特征,再通过Skip-Gram实现节点表征.
4.1.1 社区性游走策略
社区性游走策略是一种使游走发生在社区内部的概率计算策略.传统的游走方法基于节点的连边关系进行随机游走,而社区性游走策略为控制游走尽可能发生在社区内部以捕获社区结构特征,其基于社区邻接性特征进行游走,并通过边介数计算游走概率控制游走走向,并以局部模块度作为社区边界的判断依据.
1)社区邻接性游走
有连边的节点比没有连边的节点更可能属于同一社区,节点之间的连边关系,即邻接特征是最基本的结构性社区特征.社区性游走过程中,游走经过的节点序列被视为一个社区,如图2中,游走经过的节点序列为[1,2,6],视为社区C={1,2,6}.与社区C有连边的节点集合{3,4,5,7,9}比与社区C无连边的节点集合{8,10,11,12}更有可能属于社区C,因此,在社区邻接性游走中,下一游走节点是与社区C有连边的节点集合nexts={3,4,5,7,9}.

图2 社区性游走Fig.2 CommunityWalk
在网络G=(V,E,A)中,V,E,A分别是网络G的节点集合、边集合和节点属性矩阵,网络中的节点s和节点t的连边e可以表示为
walk=[n0,n1,n2,…,nl-1]
(2)
社区邻接性游走视已游走节点集合为一个社区,定义为:
C={n|n∈walk}
(3)
下一游走节点为与社区C有连边的节点集合,定义为:
nexts={m|
(4)
在社区邻接性游走过程中,不断在与当前社区C有连边的节点集合nexts中选择下一游走节点进行游走,直至达到社区游走边界时游走结束.下一游走节点选择依赖于基于边介数的游走概率计算,以控制游走走向尽可能发生在社区内部.
2)基于边介数的社区内游走
从信息共享的角度看,社区内部信息传播路径密集,但趋向于分享相似的信息,信息的增益小;而社区间信息传播路径虽然稀疏,但趋向于获取新的信息,信息的增益大.所以,信息增益大的边,是社区间的边.通过去除信息增益大的边,可以实现网络的社区分割,得到社区结构.
与节点的介数中心性[24]相似,边介数代表了一条边对于网络中节点对之间沿着最短路径传输信息的控制能力,边e的边介数定义如公式(5)所示.边介数越大,边的信息增益越大,该边越可能是社区之间的连边.
(5)
其中,σ(s,t)表示节点s和节点t之间的最短路径数,σ(s,t|e)表示节点s和节点t之间经过了边e的最短路径数.在社区性游走中,为控制游走走向尽可能发生在社区内部,应尽可能避免游走边介数大的边,因此,边的社区性游走概率定义为边介数的倒数.
基于边介数计算下一游走节点集合nexts中节点的游走概率.nexts中的节点nexti与社区C的连边数大于等于1,该连边集合定义为:
E (C,nexti)={e|e=
(6)
社区性游走可以通过E(C,nexti)中的任意边游走至节点nexti.如图2中的节点5与社区C的连边数为2,通过边<1,5>,<6,5>皆可以游走至节点5.所以,在计算节点nexti与社区C之间代表信息增益的边介数时,需要对E(C,nexti)中边的边介数求和,节点nexti与社区C的之间的边介数定义为:
betweenness(C,nexti)=∑e∈E(C,nexti)B(e)
(7)
对于社区C,节点nexti的边介数betweenness(C,nexti)越大,节点nexti能够带来的信息增益越大,连边集合E (C,nexti)中的边是社区C与其他社区之间连边的概率越大.所以,为使社区性游走尽可能发生在当前社区C内部,应尽量避免游走边介数大的边,定义节点nexti的游走概率为边介数的倒数:
(8)
在得到节点集合nexts中所有节点的社区性游走概率后,为控制下一游走节点尽可能属于当前社区C,基于游走概率[prod (C,nexti)|nexti∈nexts]选择节点集合nexts的节点作为下一游走节点,直到当前社区C达到社区边界.
3)社区游走边界
社区划分的基本规则是“社区内连边多,社区间连边少”.局部模块度[25]定义为社区内部的边数和与社区中节点有连接的边数的比值:
(9)
其中,I是社区C内部的边数,T是与社区C中节点有连接的边数.
在社区性游走过程中,社区C内部的边数相对于外部连边数增加时,局部模块度增加,反之减小.如图2中,当C={1,2,6}时,lm(C)=2/9.若社区C游走到C′={1,2,3,4,5,6,7}时,lm(C′)=9/10,局部模块度增加,游走继续;若社区C′游走到C″={1,2,3,4,5,6,7,9},lm(C″)=10/12,局部模块度减小,游走结束.在社区性游走过程中,以局部模块度作为社区边界的判断标准,当局部模块度值持续减小时,社区性游走达到社区C的边界,游走结束.
4.1.2 CommunityWalk算法
CommunityWalk算法如算法1所示,遍历网络中的节点作为起始节点,采用社区性游走策略进行游走,得到节点序列集合walks.基于节点序列集合实现节点的向量化,在DeepWalk的基础上,采用Skip-Gram词向量训练模型,求得结构性社区特征矩阵Φstructure∈|V|×d.
社区性游走策略通过getWalk(G,l,u)方法实现.在游走长度不大于最大值l时,根据已游走节点序列walk,计算社区C,下一游走节点集合nexts;根据公式(8)计算nexts集合中每个节点对应的游走概率,得到对应的游走概率数组probs;根据probs选择下一游走节点nextx加入社区C,得到C′;根据公式(9)计算社区C′的局部模块度值,与历史局部模块度值比较,当局部模块度值持续减小时,结束当前游走,节点序列为walk,否则,nextx加入序列walk,游走继续.社区性游走得到的节点序列不是定长的.
算法1.CommunityWalk
输入:networkG=(V,E,A),dimensionsd,max walk lengthl,walks per nodeγ
输出:structural community feature matrix Φstructure∈|V|×d
1.Initializewalksto Empty
2.fori=0 toγdo
3. for all nodesu∈Vdo
4.walk=getWalk(G,l,u) //as Function
5. Appendwalktowalks
6. end for
7.end for
8.return Φstructure=Skip- Gram(walks,l)
Function getWalk(G,l,u):
1.Initializewalkto Empty
2.Initializenextxtou
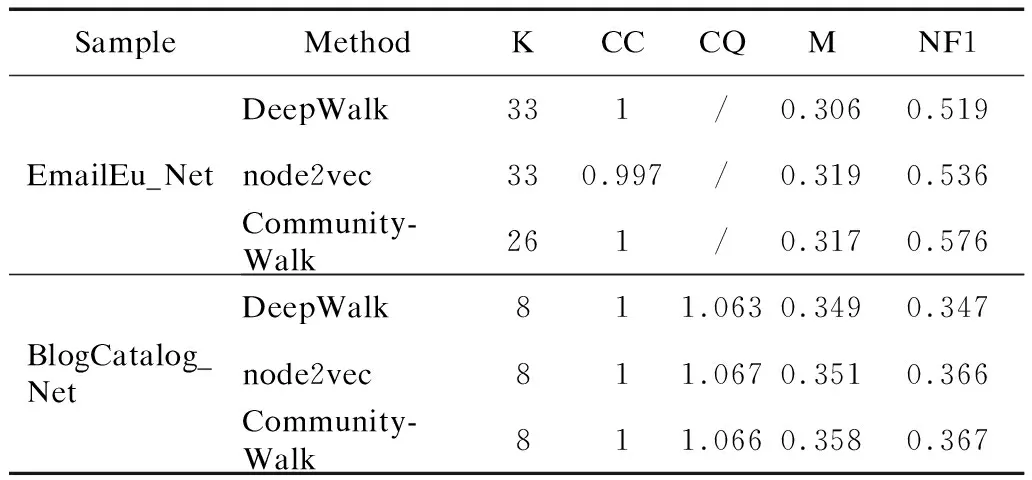
3.while lm(C′)≥lm(C) and |walk| 4. Appendnextxtowalk 5.C={n|n∈walk} 6.nexts={m|[m,n]∈E,n∈C} 7. Initializeprobsto Empty 8. for all nodesnexti∈nextsdo 9. Append prod(C,nexti) toprobs//as Formula(8) 10.end for 11.Setnextxto random(nexts,probs) 12.C′=C∪{nextx} 13.end while 14.returnwalk 属性嵌入采用一个自编码器(AE)[9]将网络G=(V,E,A)中的节点属性矩阵A处理为与Φstructure∈|V|×d同维度的Φattribute∈|V|×d.AE分为编码器(Encoder)和解码器(Decoder)两部分,其结构如图3所示.自编码器是一种非线性的降维方法,编码器处理原始属性矩阵A为向量矩阵H,再通过解码器恢复为属性矩阵A′,自编码器模型通过最小化A和A′的差异,得到模型的最优参数解,使编码器的输出矩阵H中包含了原始的属性特征. 图3 AE结构Fig.3 Structure of AE 自编码器的损失函数为节点属性矩阵A和A′的均方误差(Mean Square Error Loss,MSE Loss).采用Adam优化算法对自编码器进行优化,损失收敛后,编码器的输出H,即属性表征矩阵Φattribute. 在综合社区性表征矩阵Φcommunity中,网络中的节点被表征为嵌入了综合社区性的向量,社区发现问题转换为一个对节点向量进行无监督聚类的问题.本文在文献[22]CNN方法的基础上提出K-聚类神经网络(K-CNN)模型对Φcommunity中的节点向量进行聚类,以实现社区发现. CNN方法通过社区中心向量的迭代更新以优化节点的社区划分质量,但CNN方法需预设聚类数目K,无法在聚类过程中得到最佳K值.K-CNN社区发现方法在CNN的基础上通过迭代发现最佳K值,并输出社区数目为K时,节点社区分配标签的最优解. 如图4所示,K-CNN模型的输入为综合社区性表征矩阵Φcommunity,通过CNN中的软分配为节点分配社区标签,模型的输出是节点的社区标签数组Label.K-CNN通过迭代优化聚类层的权重矩阵WC,达到优化社区发现质量和发现最佳K值的目的.模型分为软分配和聚类效果优化两部分. 图4 K-CNN社区发现模型Fig.4 K-CNN community discovery model 5.1.1 软分配 软分配Q使用t-分布(t-distribution)为核函数(kernel)计算节点与各社区的相似度,从而确定节点的社区划分.由于在无监督学习中无法交叉验证t-分布的自由度[26],所以自由度统一设置为1. 在图4中,遍历综合社区性表征矩阵Φcommunity中节点的社区性向量作为聚类神经网络的输入.当遍历节点为i时,输入节点i的社区性向量xi.聚类层的权重矩阵为WC,矩阵中聚类中心j的表征向量为cj.节点i和聚类中心j的软分配相似度定义为: (10) K-CNN模型的输出为Φcommunity中节点的社区标签数组Label.节点i的聚类结果,即社区标签定义为: labeli=argmaxj∈[0,K-1]qij (11) 5.1.2 聚类效果优化 聚类效果优化体现在两方面,一是K值不变时,通过损失函数优化聚类层的权重矩阵WC,优化社区发现效果,二是基于下降因子a(a∈(0,1))优化聚类中心. 权重矩阵WC基于KL散度损失(Kullback-Leibler Divergence Loss,KL Loss)进行优化,定义为: (12) 其中,P是基于软分配Q的辅助目标分布函数.当节点的社区标签Label较上一次迭代的Label′的更新率较小时,聚类结果收敛,WC优化结束.更新率定义为: (13) 在聚类结果收敛后,若KL Loss大于损失阈值,基于下降因子a(a∈(0,1))优化K值,如公式(14),重构聚类层的权重矩阵WC,直到聚类结果再一次收敛. K=(1-a)K (14) K-CNN算法如算法2所示,通过不断重构聚类层,用下降因子a优化最佳聚类数K,直到KL Loss达到损失阈值θ.在迭代优化过程中,基于K-means方法初始化权重矩阵WC,计算软分配和Q辅助目标分配P,通过损失函数指导优化权重矩阵,当CNN的聚类结果稳定时,即聚类结果Label的更新率ur小于更新阈值t时,迭代优化结束. 算法2.K-CNN 输入:community feature matrix Φcommunity∈|V|×2d,nodesV,update thresholdt,loss threshold θ,descent factora 输出:community labelLabel 1.InitializeKto |V|/3 2.whileL=KL(P‖Q)>θ andK>1 do 3. InitializeWCto K-means(K,Φcommunity) 4. Initializeurtot 5. InitializeLabel′ to Empty 6. whileur≥tdo 7. ComputeQ,Label//as Formula(10)(11) 8. ifLabel′≠Empty then 9. Computeur//as Formula(13) 10. SetLabel′ to Label 11. end if 12.end while 13.K=(1-a)K 14.end while 15.returnLabel 为验证“融合嵌入网络结构和节点属性的社区发现方法”(CCE+K-CNN)的合理有效性,本文在社交网络和合著作者网络两类社区网络数据集上开展实验,并从两个方面对社区发现结果进行评价:1)评估社区发现结果中社区数目的合理性;2)采用社区覆盖率(Community Coverage,CC)、社区质量(Community Quality,CQ)、模块度(Modularity,M)和归一化F1分数(Normalized F1,NF1)4个指标对社区质量进行综合评价.实验在windows10操作系统、8GB内存、四核处理器的PC下运行,算法程序采用python语言编写. 在现实网络中,可能存在无真实社区划分标签的情况,也有可能无法获取节点的属性特征,所以采用多样的评价指标,既能全面地评价社区划分质量,也能避免由于缺少社区标签或节点属性而无法进行社区质量评估的情况. 1)社区覆盖率CC[27,28].社区覆盖率定义为属于非平凡社区的节点占节点总数的比例,其中,非平凡社区是指有3个及以上节点的社区.CC<1表示该社区结构中存在节点数小于3的社区;2)社区质量CQ[27,28].社区质量表示节点对相似性的富裕度(enrichment),节点对的相似度是原始数据中节点属性的余弦相似度;3)模块度M[10].模块度基于网络拓扑结构对社区划分进行评价,M值越大,社区内部边较外部边越密集,社区划分质量越好.M∈[0.3,0.7]时,社区发现的效果良好;4)归一化F1分数NF1[29].F1评估的是与真实社区分区之间的近似水平,NF1定义为每个社区的F1值的归一化结果.与传统的标准化互信息(NMI)方法相比,NF1的计算复杂度更低,适合于评估有大量社团的大规模复杂网络. 1)EmailEu[30]是某机构的电子邮件网络.网络中的节点是研究机构的成员,每个成员都属于该研究所的42个部门之一,成员之间的邮件往来即为网络中的边;2)BlogCatalog[31]是一个博客网络.在博客网络中,网络的节点是博客用户,用户间的关注关系为网络中的边,节点属性是用户对自己博客描述的关键词(keywords),社区类别是用户预定义的博客类别;3)CoauthorA是一个合著作者网络.该网络数据集由Wencong Wan等人[32]从公共文献数据库获取的论文信息数据集处理而成.作者是网络中的节点,存在合著关系的两个作者之间存在边,将作者发表论文中的关键词集合的关键字向量化得到节点属性. 数据集信息如表1所示,除了网络本身的节点数目、边数目和属性维度外,表1还给出了3个网络在真实社区划分情况下的社区数目K、社区质量和模块度.其中,由于EmailEu数据集缺少节点属性,所以无法用CQ指标评价EmailEu的社区质量;由于CoauthorA数据集缺少真实的社区标签,所以无法用NF1指标评价CoauthorA的社区发现的准确率. 表1 数据集描述Table 1 Description on datasets 首先在两个有真实社区标签的EmailEu和BlogCatalog数据集上开展实验,验证本文结构性社区特征嵌入方法CommunityWalk和基于K-CNN聚类实现社区划分方法的有效性.然后将CoauthorA数据集用以验证本文整体社区发现方案(CCE+K-CNN)的有效性,将其与和其他社区发现方法进行实验对比,并评估结果中社区数目的合理性. 6.3.1 嵌入方法对比实验 将CommunityWalk与DeepWalk[17]、node2vec[5]的嵌入方法进行对比以证明CommunityWalk对于结构性社区特征嵌入的有效性,其中,DeepWalk采用随机游走方式;node2vec基于出入参数(q=0.5)和返回概率(p=1)控制深度遍历和广度遍历游走的概率. 在基于表1构造的两个仅包含网络结构的输入样本EmailEu_Net、BlogCatalog_Net上开展实验,聚类方法采用K-CNN. 如表2所示,实验结果表明,基于3种嵌入方法实现节点向量表征后进行社区发现,皆能发现模块度值接近,社区质量尚佳的社区结构,而基于node2vec、CommunityWalk方法的方案得到社区结构在CQ和NF1指标的评价上皆优于DeepWalk.样本EmailEu_Net中,CommunityWalk在NF1的表现上略优于node2vec,并且node2vec的社区覆盖率CC不足1,即存在一些节点未被划分至社区.且NF1表示的是一个与真实情况F1值的归一化结果,所以CommunityWalk在社区标签划分上的性能是最稳定的. 表2 嵌入方法的实验对比Table 2 Experimental comparison on embedding methods 6.3.2 聚类方法对比实验 将K-CNN与传统聚类算法K-means进行实验对比以证明K-CNN聚类方法进行社区发现的有效性,其中,算法K-means通过基于误差平方和(Sum of the Squared Errors,SSE)的拐点法得到社区数目K. 将基于表1构造的一个仅包含网络结构的样本EmailEu_Net,以及一个包含网络结构和节点属性的样本BlogCatalog_NetAtt作为实验对象.由于EmailEu_Net样本无节点属性,所以采用CommunityWalk即可得到节点的社区性向量,BlogCatalog_NetAtt样本则采用综合社区性嵌入方法CCE得到节点的社区性向量. 实验结果如表3所示,在不同数据集上,K-CNN的M和NF1指标皆优于K-means的表现.对于社区数目K,在样本EmailEu_Net的实验上,两种聚类方法得到了接近的社区数目;在样本BlogCatalog_NetAtt的实验上,两种聚类方法得到的社区数目差异较大,而K-CNN的社区数目也更接近于真实的社区数目.实验证明了基于K-CNN聚类实现社区发现的有效性. 表3 聚类方法的实验对比Table 3 Experimental comparison on clustering methods 6.3.3 社区发现方案对比实验 1)基于表1构造的一个仅包含网络结构的样本CoauthorA_Net作为实验对象,将本文不处理节点属性的CommunityWalk+K-CNN方案与经典的社区发现方法,包括Louvain算法[11]、WalkTrap算法[33]、LPA算法[34]和Infomap算法[13]进行对比实验,以验证本文方案的有效性. 实验结果如表4所示,在基于样本CoauthorA_Net不处理节点属性情况实验中,本文方法较其他方法而言需要通过迭代的方式确定社区数目K,时间开销较大.对于社区质量CQ,LPA、InfoMap表现最好,但是这两种方法的社区覆盖率CC皆不及1,特别是LPA,二者以牺牲部分节点的社区划分为前提提高了CQ;在模块度的评价上,除LPA算法远低于其他算法外,其余方法皆得到了不错的社区结构评价.与传统方法对比,本文方法CommunityWalk+K-CNN在CC、CQ、M这3个社区评价指标上综合评估优于其他算法,在保证社区覆盖率的情况下,社区质量和社区模块度皆处在较高水平. 表4 无属性的社区发现方法的实验对比Table 4 Experimental comparison of community discovery without attributes 2)基于表1构造一个包含网络结构和节点属性的样本CoauthorA_NetAtt作为实验对象,将本文社区发现方案CCE+K-CNN,以及基于结构/属性相似度的图聚类方法SAC[35]、DeepWalk+AE+K-CNN、node2vec+AE+K-CNN与不处理属性的方案进行对比,以分析属性对于社区发现的影响和本文方法的有效性. 实验结果如表5所示,基于样本CoauthorA_NetAtt综合属性特征的实验中,SAC方法的CQ表现最佳,但是社区覆盖率CC不足1且M较低,本文方法在所有方法中表现最佳,且在M指标尚佳的情况下,CQ优于表4中不处理节点属性的CommunityWalk+K-CNN方案,说明节点属性对提高社区内部节点的相似度的意义. 表5 有属性的社区发现方法的实验对比Table 5 Experimental comparison of community discovery with attributes 在本文的社区发现方法中K-CNN的模型参数包括下降因子a和损失阈值θ.下降因子a影响的是K值改变的速度,根据K值计算公式(14),a越小,K值每次减小的值就越小,即K值优化的粒度越小,结果越合理,但较小的a值会增加迭代次数,增加模型训练的时间开销.损失阈值参数θ是聚类数目K值优化的终止条件,直接影响社区发现的社区数目.此外更新阈值设为一个较小数,t=1e-3,即当更新率ur 在样本BlogCatalog_NetAtt上,对K-CNN中的损失阈值θ和下降因子a进行实验分析,如图5所示.损失阈值θ值越大,得到的社区数目K值越小,由于损失阈值θ对实验结果影响很大,需要在迭代过程中参照M值变化的拐点设置.如图5(a)所示,θ=0.015时,M达到峰值,实验效果最佳.对于下降因子a,如图5(b)所示,当a≥0.4时,NF1指标较大幅度下降,这是由于K值优化的粒度增加,K-CNN错过了最佳K值,但是若a取值较小,会增加K值的优化次数,增加模型的时间开销.所以,下降因子a的取值范围为a∈(0.1,0.3]时,K-CNN模型能够有较好表现. 图5 参数分析Fig.5 Parametric analysis 由于现实网络的复杂性和多样性,目前缺乏一种端到端的解决社区发现问题的普适性方法.本文提出的综合社区性嵌入方法(CCE)融合嵌入以邻接特征、局部模块度和边介数为代表的结构性社区特征,并结合节点属性,能够更全面的挖掘原始网络的社区特征,实现基于社区相似性假设的节点向量表征.然后,通过聚类神经网络模型(K-CNN)对节点的综合社区性向量进行无监督聚类,在聚类迭代过程中优化社区数目和社区发现质量.本文的方法(CCE+K-CNN)在社交网络和合著作者网络的数据集上皆有不错的表现,在未来的工作中可以就综合社区性嵌入对复杂网络中重叠社区和层次化社区等问题展开研究.4.2 属性嵌入

5 K-CNN社区发现模型
5.1 K-CNN社区发现模型

5.2 K-CNN社区发现算法
6 实验分析
6.1 评价指标
6.2 数据集

6.3 实验结果



6.4 参数讨论

7 结束语
