双通道动静态特征的微表情识别
2023-07-15丘嘉豪
陈 庄,赵 源,罗 颂,丘嘉豪
(重庆理工大学 计算机科学与工程学院,重庆 400054)
1 引 言
人脸表情是传播人类情感信息与协调人际关系的重要方式,是人类内心的情感流露.人脸表情又被分为宏表情和微表情.宏表情是一种幅度大,持续时间久的人脸表情,经常出现在日常生活中,且容易被人察觉.而微表情是一种轻微、短暂、不易察觉的人脸表情,普通人很难发现人脸表情中的微表情,只有经过面部表情识别训练的心理学家才可以去发现这种表情.
在过去的几十年里,许多学者在宏表情识别中开展了许多工作.随着研究的深入,学者发现宏表情可以被人为的伪装,从而掩饰自己内心的真实情感,而微表情则难以隐藏.因此,近些年,针对微表情的识别工作逐渐成为新的研究热门.
微表情是一种微妙的面部表情,当人们试图隐藏自己真实的情感时,微表情就会在无意中暴露出来,它可以揭示人们内心真正的想法.微表情具有以下特点:
1)微表情的产生是通过人们隐藏自己的情感和掩饰情绪时不经意间流露出的面部表情.
2)微表情是一个微弱而短暂的动态表情变化,通常需要在视频中进行动态特征分析.
3)微表情的持续时间较短,仅持续1/25~1/3秒[1].
4)微表情通常只出现在特定的位置[2,3].
自动微表情分析分为微表情检测和微表情识别.微表情检测是指在一段完整的视频帧序列中检测出微表情发生的开始与结束的时间段.同时,微表情检测也包括在一段微表情视频中检测出峰值帧,即微表情视频中表情变化强度最为剧烈的一帧.微表情识别是对于一段微表情视频帧序列,分析出微表情所属的类别.本文中主要聚焦于微表情识别任务.
基于微表情微弱且无意识等特点,自发的微表情识别有助于揭露人类内心的真实情感.因此,微表情识别在国家安全、临床诊断、司法制度和政治选举等方面有广泛的应用.但是由于微表情变化微弱等特点,使人类很难肉眼识别微表情.事实上在早期,Ekman和Paul在训练人类识别微表情上做了许多努力,并且在2002年开发了一个微表情识别的工具——METT[4].METT可以有效地改进人类识别微表情的能力.但是尽管如此,人类识别微表情的能力依旧较差.根据报告[5],人类识别微表情的准确率仅仅47%.因此,通过计算机视觉的方式来识别微表情则变得尤为重要.随着科学技术的发展和深度学习[6]的兴起使得微表情的准确识别成为可能.但微表情识别也面临着巨大的挑战,即如何设计一种有效的微表情识别算法去克服微表情识别中的困难.
本文的贡献如下:
1)提出了一种将视频动态变化信息压缩为稀疏残差积的方式,有效地避免了帧冗余的问题,加快了网络提取视频特征的速度.
2)提出了一种通过稀疏卷积提取动态特征的方式,在稀疏数据下,有较高的精度与较快的速度.
3)提出了一种动静态特征融合识别微表情的方式,将视频特征划分为动态特征与静态特征,并通过动静态嵌入因子学习特征融合的最佳组合.
2 相关工作
2.1 手工特征
早期的微表情识别工作通常提取手工特征,然后使用机器学习方法进行识别.手工提取的特征可以分为两类:基于表观的特征和基于几何的特征.
2.1.1 基于表观的特征
基于表观的特征,即基于像素值的方法,通过统计视频像素值提取面部区域数据的强度或纹理信息.
LBP-TOP[7]是一种基于表观的特征,是LBP算子在三维空间的扩展.LBP-TOP通过提取在三维上的LBP特征,然后将其拼接融合作为提取到的视频特征.LBP-TOP考虑了时间和空间上的信息,是典型的具有时空特征的LBP算子.作为一个前期工作,LBP-TOP取得了较好的效果,为后续微表情识别研究提供了参考.
继LBT-TOP工作之后,Huang提出了STCLQP[8],有效地避免了LBP-TOP特征仅考虑局部外观和运动特征的局限性.STCLQP首先提取了符号分量、幅值分量和方向分量3个重要信息;其次对外观域和时间域的每个分量进行有效的矢量量化和码本选择,以学习紧凑和有辨别力的码本;最后基于码本去提取并融合符号分量、幅值分量和方向分量3个兴趣信息.
通常,基于表观的方法提取的特征丢失的信息比较少,但会有更高特征维度.如LBP-TOP特征维度就比较高.与LBP-TOP相比,虽然STCLQP方法考虑了更多的信息,但不可避免的引入了更高的维度.
2.1.2 基于几何的特征
基于几何的特征通常不会直接考虑像素值,而是考虑部分特征区域或特征点的位移.最具代表性的几何特征就是光流特征.光流通过计算面部特征点的位移或作用区域的光流来识别微表情.该方法能够提取具有代表性的运动特征,对人脸纹理的多样性具有较强的鲁棒性.
Liu等[9]人提出了一种简单而有效的主方向平均光流特征用于微表情识别.主方向平均光流是应用在视频片段上一种鲁棒的光流方法.它基于部分动作单元将面部区域划分为感兴趣区域,同时考虑了局部统计运动信息和空间位置信息.
光流法的优势是特征维度小,并且能够捕获到细微的肌肉运动.在第2届国际微表情大赛中,有许多工作[10-12]利用光流信息取得了良好的效果.例如,Liu[10]等人构建了一个可靠的微表情识别系统,他们采用了两种域适应技术,包括对抗训练和表情放大与缩小方法.然后对原始图像进行预处理,从起始帧(微表情视频中的第一帧)到峰值帧(微表情视频中变化强度最大的帧)捕捉面部运动的时空光流,进而编码微弱的面部运动.然后通过从宏表情识别的任务中使用迁移学习的方式解决少样本微表情数据集的问题.最后取得了较好的效果,并获得了MEGC2019[13]的冠军.
但光流对光线有更高的要求,易受外界环境影响,并且这些工作仅利用了峰值帧与起始帧的光流信息,丢失了视频其他帧的运动信息.
2.2 深度神经网络
深度学习已经被广泛应用于许多领域,并且取得了颠覆性的成果.近年来,由于深度学习方法的有效性,深度学习的热度更是高居不下.同样在微表情领域,许多的学者也在尝试使用深度学习方法去识别微表情.
Xia等[14]提出了时空循环卷积网络,该网络通过几个循环的卷积层捕捉微表情序列中的时空变化,采用端到端的优化,避免了人工特征设计.相比于传统方法进行微表情识别,该工作取得了不错的效果.
Khor等[15]提出了一种ELRCN网络,该网络结合卷积神经网络(Convolutional Neural Network,CNN)提取空间信息和长短期记忆网络(Long Short-Term Memory,LSTM)提取时空信息.首先通过CNN模块将每个微表情帧编码成一个特征向量,然后通过LSTM模块传递特征向量来预测微表情.ELRCN利用门控单元可以保留长期信息的优点检测微表情,并取得了较好的效果.然而,微表情视频片段较短,相邻帧之间变化较小,导致神经网络重复计算相似的视频帧,时间复杂度较大,并且很难捕捉到相邻帧之间的动态信息变化.而通过压缩视频信息为残差积的方法很好地克服了帧冗余的问题,并且可以更好地提取相邻帧之间的变化信息.
综上所述,与传统的人工特征识别微表情相比,深度学习技术可以从微表情视频中提取特征并进行分类,准确率更高.但由于微表情视频中存在帧冗余,深度学习训练模型的速度受到很大影响.因此,本文提出了将视频动态变化信息压缩为稀疏残差积的微表情视频预处理方法来克服微表情视频中的帧冗余问题.此外,由于传统的微表情特征提取时,仅利用了起始帧和峰值帧的信息,无法有效地将视频中有效信息全部提取,导致微表情视频识别精度较低,而本文提出将视频特征分解为动态特征与静态特征的方式,有效地利用了视频中的有效信息.
3 方 法
3.1 预处理
微表情视频包含着大量的背景干扰信息,需要预处理剪辑出人脸部分,使神经网络能够学习有效特征.预处理共分为3步:1)通过dlib库检测人脸68个地标点;2)通过眼角地标点,对齐人脸面部,确保面部水平端正;3)通过地标点裁剪人脸面部图像.处理结果如图1所示.

图1 预处理Fig.1 Preprocessed
3.2 网络总体架构
视频由连续不断、相互关联、变化幅度小的图像帧组成.但是本文并没有将视频作为静态图像集合处理,而将其视为静态特征与动态特征的结合.静态特征是指首帧图像中的人脸信息,而动态特征是指部分图像间的残差帧信息,由浅层动态特征和深层动态特征组成.模型中使用双通道网络分别提取动态特征与静态特征.模型如图2所示,模型图左侧为动态特征提取模块,模型图右侧为静态特征提取模块,在分别提取深层动态特征和静态特征后,通过可训练的动静态残差连接模块融合动静态特征得到动静态融合特征,即微表情视频特征,最后分类得出微表情类别.

图2 模型Fig.2 Model
3.3 视频特征分解原理推导
通常,公式zt=w×xt用来计算特征映射.其中w∈c0×ci×kh×kw、Xt∈c×h×w、zt∈c0×h×w分别表示卷积核、第t帧图像和第t帧的特征.co、ci、h、w分别为卷积核的输出通道数、输入通道数、高和宽.通过卷积的分配率可得出公式(1)[16]:
z1=w×x1
zt=w×(x1+xt-xt-1+…+x2-x1)
=w×x1+w×(xt-xt-1+…+x2-x1)
=z1+w×(rt+…+r2)
(1)
其中rt表示第t个残差帧,是第xt帧与第xt-1帧的差值.由公式(1)可知通过计算首帧图像特征与t-1个残差帧特征可以计算出第t帧特征.视频特征可以被量化为每一帧特征的组合,因此可以通过公式(2)计算首帧到第t帧的视频特征zv∈c0×h×w.

(2)
其中rsum=ci×h×w、z1∈c0×h×w、zr∈c0×h×w和⊙分别表示残差积、静态特征、残差积特征和哈达玛积.首帧特征和残差积特征分别被称为静态特征与深层动态特征.因此根据公式(2),视频特征可以分解为静态特征与深层动态特征的组合.
3.4 动态特征提取
微表情从起始帧到峰值帧,峰值帧到偏移帧(即微表情视频中的最后一帧),是一个表情幅度由弱到强,再由强到弱的过程.起始帧到峰值帧与峰值帧到偏移帧是一个互逆的过程,因此采用从起始帧到峰值帧的微表情片段进行识别.此外,由于微表情的幅度较为微小,相邻帧差异非常小,因此需要舍弃部分变化微小的帧,并均匀选取关键的帧,以避免帧信息的冗余.通过公式(3)根据视频长短选择合适的间隔.
(3)
其中g、fonset、fapex、「·⎤和n,分别表示采样帧间隔、微表情视频中起始帧的次序、微表情视频中峰值帧的次序、向上取整和关键帧的数量.通过公式(4)以g为间隔均匀采样微表情视频片段,即从起始帧每隔g帧取一帧,共取n帧,将采样得到的n个关键帧作为集合中的元素.
={fonset+g,fonset+2g,…,min(fonset+ng,fapex)}
(4)

图3 计算残差积Fig.3 Compute the residual sum
={(xi-xi-1)×(n-i+1)|xi∈,1 (5) 其中xi表示集合中的第i个元素.通过门控公式(6),将中的带权残差帧聚合,计算残差积rsum∈ci×h×w.由于16位RGB图像范围是0~255,因此在计算残差积时本文使用最大最小归一化将结果范围线性调整到0~255. (6) 其中max(·)、min(·)、gmax和gmin分别表示取最大值、取最小值,调整范围的最大值和调整范围的最小值.gmax和gmin在文中分别取255和0. 图4 浅层稀疏卷积模型Fig.4 Shallow sparse convolution model 深层稀疏卷积模型如图5所示,s代表深层稀疏卷积步长,深层稀疏卷积的边缘填充被设置为1.深层稀疏卷积模型由9个稀疏卷积层、1个批量归一化层、1个稀疏池化层和1个展平层组成.相比于浅层稀疏卷积模型,它使用了更多的稀疏卷积层,能够增加网络的非线性表达能力.相比于使用5×5及更大的卷积核,它通过使用3×3的卷积能够有效较少模型的参数[18].深层稀疏卷积模型中参考了ResNet[19]的网络结构,使用步长为2的稀疏卷积层执行下采样操作,并在网络最后使用稀疏池化及展平层生成深层动态特征. 图5 深层稀疏卷积模型Fig.5 Deep sparse convolution model (7) 其中α,β是可训练的参数.在静态特征提取模块深度可分离卷积部分,本文参考ReXNet[20]深度可分离卷积网络架构. 有效地结合动态特征和静态特征是提高微表情识别精度的重要部分,本文通过公式(8)将得到的深层动态特征与静态特征进行自适应细粒度融合,得到动静态融合特征zv∈576. zv=λ⊙z1+γ⊙zr (8) 其中λ,γ和zv∈d分别表示静态嵌入因子、动态嵌入因子和动静态融合特征.静态嵌入因子与动态嵌入因子是可训练的参数,通过网络中深层动态特征与静态特征的关系自适应学习最佳组合,有效地结合动静态特征,提高了微表情识别的精度. 微表情数据集样本非常稀少,所以数据增强可以提高识别精度.由于人脸的左右镜像对称,将人脸进行水平翻转有助于训练网络泛化能力,并且图像增强的一些不会改变图像语义的基本增强方法也有助于泛化模型.因此训练共采用以下数据增强方法:随机进行图片水平翻转;随机灰度化图片;随机轻微旋转图像;随机调整图像饱和度、对比度、色相及亮度. 此外,本文利用标签平滑损失函数[21]正则化方法,损失函数如公式(9)所示.标签平滑损失函数可以有效避免过拟合,改善泛化能力差的问题.此外,本文使用Adamp[22]优化器,Adamp优化器可以抑制权重范数的增长,提高模型训练速度. (9) 其中s,C和pi分别表示标签平滑因子、样本类别数量和第i类的预测概率. 实验中共涉及微表情的自发数据集有3种:SMIC[23]、CASME II[24]和SAMM[25].3个数据集的详细信息见表1. 表1 微表情数据集,括号中的数字代表了它的样本数量Table 1 Micro-expression dataset,the numbers in parentheses represent the number of samples SMIC的数据采集受试者总共是20人,平均年龄在26.7岁左右,并且受试者来自于不同的种族,其中有10名亚洲人,9名白种人和1名非洲人.并且其中10名参与者佩戴着眼镜.SMIC是基于3种基本情感(消极,积极,惊讶)通过100fps的高速摄像机,要求20个受试者进行同样的情感诱发拍摄得到微表情序列,最后仅16个受试者的微表情视频满足要求,此外为了增加数据的多样性,SMIC还通过常规相机和红外摄像机记录其中8位参与者的视频序列片段.最后,SMIC数据集中微表情样本总数共157个,微表情视频帧的分辨率为640×480. CASME II数据集是中国科学院心理研究所创建的自发微表情数据库.CASME II共招募了35名参与者,平均年龄在22.03岁左右.在CASME II中,微表情是在一个控制良好的实验室环境激发出来的,通过要求26个受试者观看基于7种基本情感(其他,厌恶,高兴,压抑,惊讶,悲伤,恐惧)的短片进行情感诱发,并采用一些方法使受试者压抑自己的情感流露,然后使用200fps的高速摄像机拍摄得到近3000个面部运动中挑选出来.经过筛选去除一些特别细微的微表情(特别细微的的微表情无法标定起始帧和偏移帧)以及其他不符合微表情特征的样本.最后,CASME II数据集中共包含255个微表情样本,比早期的微表情数据库数据更丰富.在空间分辨率上,CASME II中采用640×480的视频帧大小,它的分辨率大于早期自发的微表情数据集样本.较大的视频帧尺寸更有助于检测微弱的变化,有利于特征提取和进一步更好的分类. SAMM的数据集较为多样化,SAMM数据集的受试者平均年龄在33.24岁左右.并且受试者来自于多个不同的国家.SAMM共招募了32名在校大学生受试者,参与者的种族有17个英国白人、3个中国人、2个阿拉伯人、2个马来人.此外,非洲人、非洲加勒比人,阿拉伯人,印度人,尼泊尔人,巴基斯坦人和西班牙人各1个.并且男女各一半,男性受试者和女性受试者都是16个.最后基于7种基本情感(生气,高兴,其他,惊讶,鄙视,厌恶,恐惧,悲伤)诱发微表情.最终通过筛选,SAMM数据集共29个受试者和159个微表情样本,且微表情视频帧的分辨率为960×650. 3个数据集样本分别来自不同的国家和人种.此外,SAMM样本是灰度图,CASME和SMIC样本都是RGB图像.因此跨数据集识别具有很大的挑战性,同时也是对算法鲁棒性的巨大考验. 所有实验都是在Ubuntu 16.04上使用NVIDIA GTX TITAN RTX GPU(24GB),Python 3.6.2和Pytorch 1.6进行的.在实验中,分别使用了3个评价指标:UF1(未加权F1得分)、UAR(系统的平衡精度)和Accuracy(准确率). UF1得分在多分类评估中是一个很好的评判标准,因为它可以强调稀少的类.UF1的计算方法如公式(10)所示.它不会受类别数量所影响,对于每个类别都平等对待. (10) UAR是较为合理的识别指标,它能够很好地评判不平衡的数据.UAR计算方法如公式(11)所示: (11) 其中Nc表示c类的样本数量. Accuracy的计算方法如公式(12)所示: (12) 由于CASME II数据集相比SAMM数据集和SMIC数据集具有较多的样本,因此微表情识别领域的学者通常在CASME II上进行5类微表情识别实验. CASME II被选择作为评估的数据集.由于CASME II数据集中的恐惧和悲伤样本非常稀少,因此在实验中,仅考虑5个类别(惊讶、厌恶、高兴、压抑和其他).实验采用留一人交叉验证法作为评估方法,并使用UF1得分来比较识别方法的性能.在每一轮实验中,一个受试者的样本作为测试集,其余的样本用于训练.该方法可以防止数据泄露,避免训练集和验证集中来自同一受试者的样本的外观,从而保证实验结果的可靠性. 表2将提出的方法在相同的评估标准下与文献中许多最近的工作进行了比较,通过比较可以发现本文方法在CASME II数据集上整体识别率相对较高.采用该方法得到的混淆矩阵如图6所示,从混淆矩阵可以看出对于其他、高兴、惊讶和厌恶的微表情有较高的识别精度,而对于压抑微表情识别有相对较低的识别精度,这是因为压抑微表情相对与其他4种微表情变化幅度更微小,样本数量更少. 表2 CASME II 5个类别的识别表现Table 2 CASME II recognition performance in five categories 图6 CASME II的5个类别实验混淆矩阵Fig.6 CASME II′s five category experimental confusion matrices 混合数据集评估是跨数据集识别中非常有效的评价方法.在实验中使用MEGC2019[13]的标准.通过减少类的数量,将来自数据集(SMIC,CASME II和SAMM)的所有样本组合到一个混合数据集中.在MEGC2019标准中,微表情分为3类,消极、积极和惊讶.愤怒、悲伤、蔑视、恐惧和厌恶被认为是消极类.高兴被认为是积极类.惊讶保持不变.留一人交叉验证用于确定训练集和测试集的分割,以避免数据泄漏和有效衡量算法性能. 值得注意的是,由于SMIC数据集没有对峰值帧进行标定,所以峰值帧定位对于微表情识别是必不可少的.近年来,已经有很多的峰值帧检测工作.事实上,峰值帧精确检测是一项较为困难的工作.因此,实验考虑效率和有效性之间的权衡,最后使用SMIC数据集中的视频中间帧作为峰值帧. 表3在MEGC2019评估标准下将提出的方法与一些最近的工作分别在混合数据集及3个单独数据集上的效果进行比较,根据实验可以看出提出的方法在混合数据集上表现的较好,能够有效的克服跨数据集识别的环境变化等问题,并且在CASME II数据集表3在MEGC2019评估标准下将提出的方法与一些最近的工作分别在混合数据集及3个单独数据集上的效果进行上能够得到较高的识别精度.但是对于SMIC数据集和SAMM数据集的识别表现略低,这是因为模型稍大,而SMIC数据集和SAMM数据集样本比较少,因此在两个数据集上效果略差. 表3 混合数据集及单独数据集3个类别的识别表现Table 3 Recognition performance of three categories of mixed dataset and single dataset 图7所示为本文方法在不同数据集下识别的混淆矩阵.实验结果表明,本文方法在4个数据集上的总体识别率比较高,并且对不平衡数据也具良好的拟合效果. 图7 MEGC2019标准下的混合数据集及单独数据集3个类别实验混淆矩阵Fig.7 Experimental confusion matrix of mixed dataset and single dataset under MEGC2019 standard 为了进一步验证动静态特征融合方法,粗粒度融合模块和细粒度融合模块的有效性,将模型在MEGC2019的评估标准下进行以下消融实验:1)仅使用稀疏卷积提取动态特征进行微表情识别;2)仅使用深度可分离卷积提取静态特征进行微表情识别;3)去除模型粗粒度融合模块进行微表情识别;4)将模型细粒度融合模块由自适应学习变更为使用动态特征与静态特征的平均值. 消融实验结果如表4所示,由此得出,动静态特征融合方法自适应结合了动态特征与静态特征,有效地利用了视频信息.此外,粗粒度融合模块和细粒度融合模块在多层级进行融合有效提高了微表情识别的精度. 表4 消融实验Table 4 Ablation experiments 本文提出了一种端到端的动静态特征融合的微表情识别网络.一方面,压缩视频信息为残差积,进而通过稀疏卷积分两阶段识别残差积,第1阶段使用浅层稀疏卷积识别得到浅层动态特征,第2阶段通过深层稀疏卷积识别更具代表性的深层动态特征.另一方面,将浅层动态特征与首帧图像进行粗粒度特征融合.然后通过深度可分离卷积提取图像的静态特征,并将深层动态特征与静态特征进行细粒度特征融合.通过可训练的动态嵌入因子与静态嵌入因子学习动静态特征的最佳组合,最后通过标签平滑损失函数提高模型的泛化能力. 本文提出的方法避免了提取视频特征时,输入所有视频帧进行提取特征,有效加快了训练和推理时间.根据实验表明,通过双通道动静态特征融合网络的方式能够更好提取到细粒度特征,并且在MEGC2019的评估标准下,模型具有更好的性能. 未来的研究工作主要从以下两个方面进行: 1)将视频压缩为固定的几帧不能完全代表视频所有信息.因此,需要找到更有效的方法压缩视频信息. 2)由于自发的微表情数据集样本少之又少,而且每个样本类别极为不均衡,对于微表情识别产生了巨大的困难.因此,摸索出解决样本不均衡引入的决策边界偏移和克服少样本的方法,将会大大提升识别的准确率.


3.5 静态特征提取

3.6 动静态残差连接
3.7 训练细节
4 实 验
4.1 数据集

4.2 实验设置

4.3 CASME II上的5类微表情实验

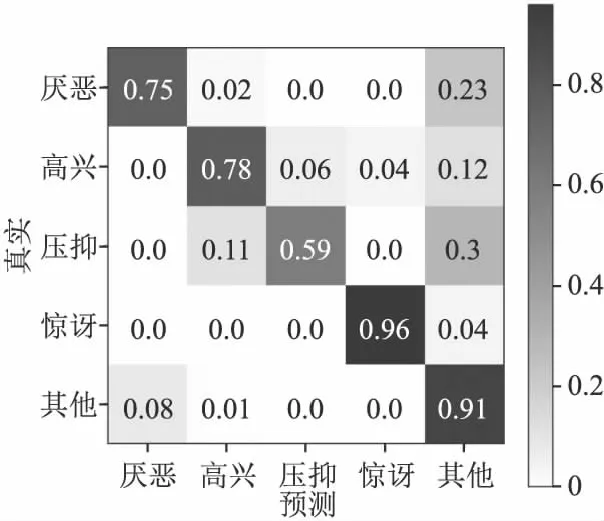
4.4 MEGC2019混合数据集实验

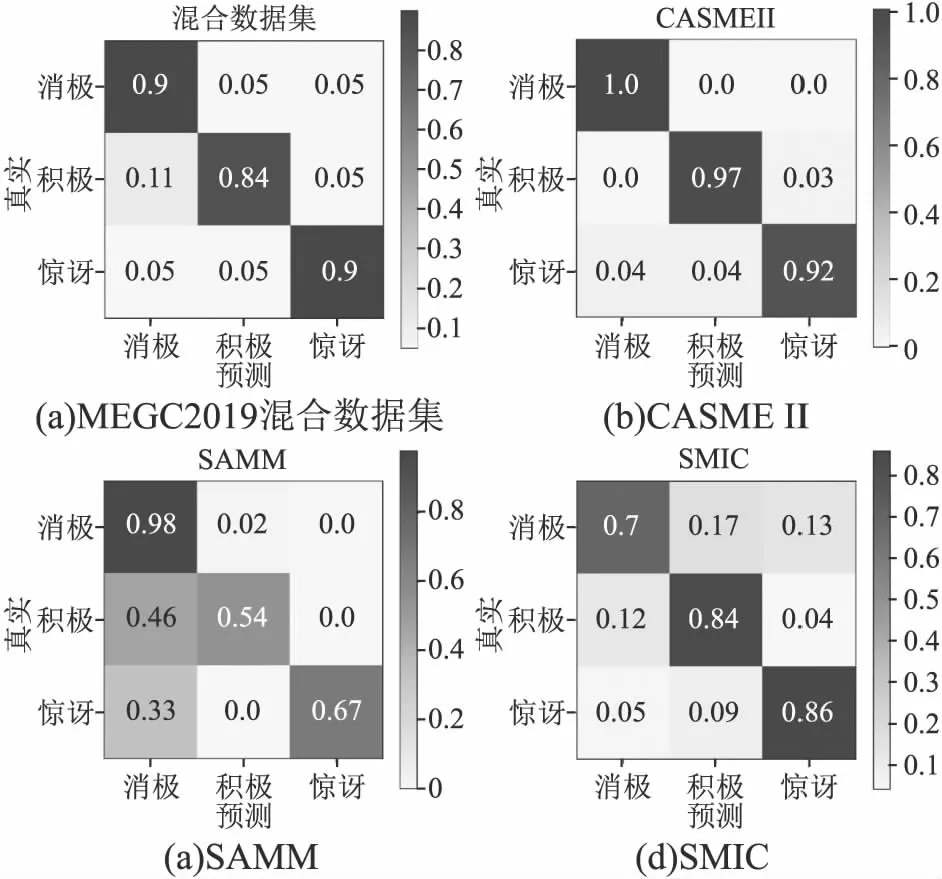
4.5 消融实验

5 总 结
