无向高维稀疏网络的深度潜在因子模型
2023-07-15吴金荣胡建华沈春根
吴金荣,胡建华,宋 燕,沈春根
1(上海理工大学 理学院,上海 200093) 2(上海理工大学 光电信息与计算机工程学院,上海 200093)
1 引 言
大数据时代,高维稀疏数据大量出现在工业和日常生活中,常用高维稀疏矩阵表示,如推荐系统,这些稀疏数据的背后存在着大量有待发现的重要信息.潜在因子模型是从高维稀疏矩阵中提取有用知识的一种经典方法,常采用矩阵二分解形式,即将稀疏矩阵分解为行潜在因子矩阵和列潜在因子矩阵的乘积,对应于推荐系统的用户潜在因子矩阵和项目潜在因子矩阵.随着深度学习的广泛应用,基于深度学习思想的潜在因子模型也被应用于解决高维稀疏数据的填补问题[1].例如文献[2]建立深度潜在因子模型来填补稀疏的评分矩阵,这种通过增加参数个数和增加网络层数来分层次传递信息的深度网络模型往往能获得一个高效的学习效果.但在实际处理问题时,二分解模型难以满足目标稀疏矩阵的对称性和非负性约束,而这样的高维稀疏数据(例如,社交网络[3,4]、无线传感网络[5-7]、生物数据分析[8])大量存在于生活中.更加精细、深入地挖掘高维非负、对称稀疏矩阵蕴藏的信息依然是一个挑战性的问题.针对非负性和对称性约束的高维稀疏矩阵,文献[9]从三分解的角度提出了基于三分解的对称非负潜在因子模型(TF-based SNLF)模型,大大提高了预测的精度.基于深度学习的成功,设计一个深度网络用于解决高维非负、对称稀疏数据的填补问题也成为一个非常有意义的课题.众所周知,一个采用多层线性函数(例如,全联接(Affine Function,Affine))的网络与采用单层线性函数的网络在本质上并无区别.而采用非线性激活函数(例如,线性整流函数(Rectified Linear Unit,ReLU)和Sigmoid函数)的网络通过加深层数能更好的学习到数据更深层次的信息.但是如果只是简单的增加网络层次,而选取不适当的激活函数,也容易导致数值稳定性下降的问题.
为应对上述挑战,本文提出了一个深度非负对称潜在因子模型(Deep nonnegative symmetric latent factor model,DNSLF),用以解决无向高维稀疏网络的稀疏问题.为了获取项目更深层次的潜在因子,本文选取非线性函数ReLU作为传递函数,这是由于加深层次容易引发数值稳定性下降,而ReLU函数使网络具有稀疏性,能有效缓解数值稳定性下降并且能有效防止过拟合;为了加快模型训练,本文采用了自适应步长进行模型学习.本文的主要贡献有:
1)提出了一个深度非负对称潜在因子模型,用于对具有非负、对称限制的高维稀疏矩阵中的缺失值估计.
2)为了缓解因加深层次导致的数值稳定性下降,使用ReLU作为传递函数;模型迭代优化过程中,采用自适应步长的方法进行模型训练.
3)在多个具有不同稀疏度的公共数据集上进行对比实验,结果表明所提出的深度非负对称潜在因子模型优于最新的模型.
本文的剩余部分介绍如下:第2节讨论了相关工作;第3节提出深度非负对称潜在因子模型;第4节给出了不同稀疏度数据集的实验结果,并解释了超参数设置并分析了模型收敛性;最后,第5节对本文进行了总结.
2 相关工作
2.1 潜在因子模型
潜在因子模型是基于内容过滤模型[10,11]的推广.它基于这样一个假设,即矩阵行项目选择某个列项目的因素不需要明确知道.给定一个完全矩阵R∈m×n,包括m个行项目和n个列项目,可以表示为:
R=UVT
U=[u1|…|um],V=[v1|…|vn]
(1)
这里U和V分别表示行项目和列项目潜在因子组成的潜在因子矩阵.
以上分解如果针对完全观测矩阵,问题是简单的.但若矩阵R∈m×n仅有部分被观察到,那么目标矩阵的分解将会变得不容易,其目标也变成了通过矩阵分解来估计缺失值.表示成数学形式为:
R=Y⊙(UVT)
(2)
这里Y表示指示矩阵,由0&1组成,yi,j=1对应R位于i行j列的元素ri,j被观测到,否则为0;⊙表示哈达玛积.一般通过为式设定一个合适的损失函数,
(3)
实际问题中,经常需要在式中对U或V设置一些限制,如低秩、正交和非负性等.这些限制通常会减少模型的解空间,模型往往显示出更好的性能[12].
2.2 表示学习
受限玻尔兹曼机器(Restricted Boltzmann Machine)[13]是当今流行的深信度网络的基础模块,但它最初是为了解决协同过滤问题而引入的.然而,由于一个重要限制,即对输入限制为0&1,使得受限玻尔兹曼机在协同过滤领域并没有流行.
基于深度学习的协同过滤的更为彻底、更为合理的方法由文献[14]提出,将基于用户隐式反馈的历史记录(二进制数据0&1)作为输入,把得分高的作为推荐项目;使用用户过去的历史记录(项目评级)作为输入,并优先使用评级的日期较新的项目,进行模型的训练.文献[1]结合了深度学习与潜在因子模型,提出了深层潜在因子模型,用于稀疏矩阵的缺失值估计.模型以两个潜在因子矩阵的乘积代替行项目的潜在因子矩阵,如图1所示.

图1 深度潜在因子模型Fig.1 Deep latent factor model
近年来,由于潜在因子模型在推荐系统领域获得的成功,致使其得到了广泛的研究,同时也迎来了许多新的发展,其中包括利用多域进行模型的学习.一个典型的模型由Jiang等[15]提出,基于双域的数据,提出了深度低等级稀疏集体因子分解;在模型的求解过程中,考虑了数据的噪声并约束了解空间.Zhang 等[16]提出了一个联合矩阵分解框架,是一个更为深入的多域潜在因子模型,核心思想是在贝叶斯框架下,以共同矩阵分解的形式呈现,同时利用高斯分布对多域异质噪声进行建模.
另一个重要的发展便是借鉴深度学习的思想,如He 等[14]提出的模型,综合神经网络与潜在因子模型的输出作为新项目的推荐;更为彻底的是Xue 等[17]提出了一个神经网络的回归框架.但值得注意的是文献[14] 和文献[17]的模型,它们都只能给出推荐的项目,却无法给出具体评分,Mongia 等[1]则提出了新的深度潜在因子模型,能给出具体项目的具体评分.但文献[1]中也忽略了现实中稀疏矩阵中蕴含的诸多约束条件,例如非负约束,对称约束.
3 提出模型
本节提出了一个深度非负对称潜在因子模型(Deep non-negative symmetric latent factor model,DNSLF)(图2),并设计了一个迭代算法来训练模型(算法1).

图2 深度非负对称潜在因子模型Fig.2 Deep non-negative symmetric latent factor model
3.1 问题描述
目前潜在因子模型在估计高维稀疏矩阵缺失值上获得了瞩目的效果,广泛用于稀疏数据潜在信息的挖掘,也成为推荐系统领域的重要模型.但是,目前常见的潜在因子模型往往忽视这些稀疏数据背后的结构信息和更深层次的信息.本文专注于解决具有非负、对称限制的高维稀疏矩阵的估计问题.
令R=[ri,j]n×n∈{+,?},R=RT,R是具有非负、对称限制的高维稀疏矩阵.n表示R的行数.ri,j为R位于i行j列的元素,表示行项目i与列项目j的关联度.问号“?”表示缺失值.Yn×n表示R的指示矩阵,与式中定义一致.
深度非负对称潜在因子模型通过深层分解,将R分解为多层项目潜在因子.由于R的对称性,这里假设R的行项目潜在空间与列项目的潜在空间是一致的.行项目与对应列项目的潜在联系,用关联度矩阵B表示,且B=BT.
3.2 深度非负对称潜在因子模型
本节描述了深度非负对称潜在因子模型(DNSLF),模型的目的是通过深层的潜在因子的学习,来更好的估计具有非负、对称限制高维稀疏矩阵的缺失值.
如图2所示,R表示非负、对称的高维稀疏矩阵,由于网络的无向性,行项目和列项目有一样的潜在空间.为了发掘更多的信息,模型学习多层次潜在因子矩阵,用Ui表示第i层的潜在因子矩阵.ReLU表示非线性函数α(x)=max(x,0),x为输入值.由于加深层次容易引发数值稳定性下降,采用ReLU函数能使网络具有稀疏性,从而有效缓解数值稳定性下降并且能有效防止过拟合.
模型采用观察值的误差平方和作为目标函数f,数学表达式如下:

(4)
3.3 自适应梯度优化算法
为了求解模型式,本节将设计一个步长自适应的迭代优化算法:基于学习衰减[18]的自适应梯度优化算法.为防止学习率衰减为0,采用指数移动平均的方式[19]实现学习率的衰减.由于深度非负对称潜在因子模型的非线性性,一起更新所有变量并不容易[20].这里选择交替投影梯度法[21,22],即自适应梯度优化算法在优化某个变量时,固定其他变量.
因为传递函数ReLU的导数为:
(5)
因此更新每个变量参数时,只需要更新参数参与传递的部分.对于任意矩阵X=[xi,j],定义传递指示矩阵如下:
(6)
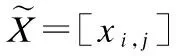
下面用交替投影梯度法更新B与Ui.
首先更新B:经计算

(7)
通过记录过去的梯度和,并设置合适的遗忘率,使得随着学习的深入,更新幅度逐渐减小.B的更新规则如下:
(8)
这里符号μ表示衰减系数,用来控制遗忘的比例,一般设定μ=0.9,符号η表示学习率.
其次更新Ui:经计算:

(9)
Ui的更新规则如下:
(10)
深度非负对称潜在因子模型致力于具有非负、对称限制的高维稀疏矩阵的缺失值估计.只要矩阵B初始化时为对称矩阵,则在之后的迭代过程中,B的对称性依然能得到保证.同时每一个变量经过α函数的传导,最后模型的估计值依然非负.
3.4 模型实现与复杂度

(11)


算法1.深度非负对称潜在因子模型
输入:R,Step=itermax
初始化:U1,…,Uk,B
hU1=0,…,hUk=0,hB=0,t=1
1.while not converge andt 6. fori,i∈{1,…,k}: 11.t+=1 12.end 输出:U1,…,Uk,B 本节将介绍数据集、评估指标和比较方法,然后给出准确度的评价结果,并进行显著性检验.实验的目的是回答以下问题: 1)对比一些先进的潜在因子模型,新提出的模型DNSLF是否能表现出更好的效果? 2)ReLU作为潜在因子层的传递函数,是否有效? 3)加深潜在因子的层数是否能提高模型效果? 表1 实验数据集Table 1 Experimental data sets 本文采用平均绝对误差(MAE)和均方根误差(RMSE)[26]这两个指标来评估每种方法的预测性能,定义如下: (12) (13) 本节列出了与深度非负对称潜在因子模型相比的两种方法. TF-based SNLF[8]:TF-based对称非负潜在因子模型关注具有对称性和非负性约束的稀疏矩阵,以矩阵三分解的形式将非负、对称矩阵分解为项目潜在因子矩阵和对称潜在因子评级矩阵. WLRA[27]:加权低秩近似应用两个潜在因子矩阵和一个潜在因子评级矩阵,即行项潜在因子、列项潜在因子和评级矩阵来对缺失数据估计. 对于高维非负、对称的稀疏数据补全任务,本文将深度非负对称潜在因子模型DNSLF与TF-based SNLF和WLRA作对比实验,并作了ReLU、和增加层数的消融实验,实验结果见表2~表4.每组实验独立重复10次,最后取平均值[28,29],表中加粗表示对比实验中最好的结果.实验中DNSLF的潜在因子层数是二层. 表2 对比模型性能表现Table 2 Performance of compared models 表3 是否包含ReLU函数的模型性能Table 3 Performance of model with and without ReLU function 表4 加深层次模型性能表现Table 4 Performance of deeper model 3)在表4中,对比了包含两层潜在因子的DNSLF(即U1,U2,B)和一个潜在因子层的NSLF(即U1,B),DNSLF表现出了更好的模型效果,这说明层数的增加能挖掘更多的潜在信息.但是,三层的DNSLF实验中,模型效果不如两层和一层的效果,且独立实验的结果方差较大,这说明层数的加深,会引起数值稳定性下降.如何缓解多层DNSLF的数值稳定性下降也是接下来的研究方向之一. 为了评估DNSLF与其他方法相比的提高效果是否显著,本文采用成对双尾T检验,检验结果的P值如表5~表7所示.P值越小,差异性效果越显著.在3个表中,除了表7(SuiteSparse数据集)的RMSE评价指标上P>0.05外,其余所有P<0.05,这表明了新模型DNSLF在3个数据上的效果提升是显著的. 表5 对比模型性能表现的显著性检验 Table 5 Significance test of the comparison model 表6 是否包含ReLU函数的模型性能的显著性检验Table 6 Significance test of the models with and without ReLU functions 表7 加深层次模型性能表现的显著性检验Table 7 Significance test of the deeper models 实验在一台32G物理内存、4.8GHz的Intel i5 CPU、运行Deepin(OS)计算机上进行,模型参数设置为32位单精度浮点.由于目标矩阵的稀疏性, 多重非线性因式分解模型中存在耦合,整个模型的收敛性不易确定,且分解出的潜在因子矩阵并不唯一,即不能收敛到唯一的矩阵.因此这里只通过实验说明新算法是经验收敛的,经过独立的实验,在允许误差范围下,每次迭代损失函数的损失值相近,则认为该矩阵分解模型是收敛的,即经验收敛[1].如图3~图5所示,展示了模型的收敛性, 而模型收敛时求得的潜在因子矩阵即为所求的分解矩阵.之后选定评价指标,通过与其它模型进行多次独立重复的对比实验,进而评估模型的性能提升.T检验则保证模型性能提升的有效性,避免因实验误差导致结果的差异. 图3 蛋白质网络数据集的经验收敛图Fig.3 Empirical convergence graph for protein network dataset 图4 矿山声纳数据集的经验收敛图Fig.4 Empirical convergence diagram of mine sonar dataset 图5 SuiteSparse数据集的经验收敛图Fig.5 Empirical convergence graph for SuiteSparse dataset 本文提出了一个深度潜在因子模型DNSLF,它以多重非线性矩阵分解的形式来估计具有非负和对称约束的高维稀疏目标矩阵的缺失值.通过引入对称深层潜在因子层和关联层完成模型建立,并且采用ReLU函数作为潜在因子层的传递函数,通过加深层次学习潜在因子空间更多的信息.通过与两个较新的潜在因子模型对比,本文提出的深度潜在因子模型具有如下优点:1)专注处理对称结构的非负稀疏数据;2)缺失值的高预测精度;3)可通过加深层次,改善模型.但加深层次可能带来的数值不稳定性,依然是一个挑战性问题,也是我们接下来的研究方向之一.本文模型可应用于一些工业数据,例如,社交网络[3,4]、无线传感网络[4,5]、生物数据分析[7].我们希望在未来探索更多的应用.4 实 验
4.1 数据集和设置


4.2 评价指标

4.3 对比方法
4.4 实验结果





4.5 显著性验证



4.6 收敛性分析



5 总 结
