基于轻量级卷积门控循环神经网络的语声增强方法∗
2023-07-13李江和宋浠瑜刘小娟
王 玫 李江和 宋浠瑜 刘小娟
(1 桂林理工大学信息科学与工程学院 桂林 541004)
(2 桂林电子科技大学 认知无线电与信息处理省部共建教育部重点实验室 桂林 541004)
0 引言
语声信号是人与人、人与智能设备之间传递信息的重要载体之一。在现实生活环境中,各种各样噪声的干扰,严重影响了语声信号的质量与可懂度,给人们带来了糟糕的听觉体验,同时阻碍了人与人之间的交流,以及人与智能设备之间的交互。因此,语声增强是语声信号处理中不可或缺的一部分[1]。语声增强的目标是尽可能地从带噪语声中还原出纯净语声[2],从而提高语声质量和语声可懂度等评价指标。
传统的语声增强技术经过不断发展,衍生出了多种基于数字信号处理和统计学的语声增强算法。经典的传统语声增强算法有谱减法[3−4]、维纳滤波[5−7]、子空间[8]等。在传统的谱减法中,语声增强的效果主要依赖于对带噪语声中噪声频谱的估计,对噪声频谱的估计一般在静音部分实现。然而,在现实中,对噪声频谱的准确估计是非常困难的一项工作。在基于子空间的语声增强方法中,通过将带噪语声分解为不同的子空间成分,这些不同的子空间分别代表语声成分和噪声成分[9−11]。传统的语声增强算法在平稳噪声条件下性能比较稳定,但是在非平稳噪声条件下的性能急剧恶化[12],这是由于其本身存在着一些不合理的假设。
针对传统的基于数字信号处理的无监督语声增强算法因存在不合理的假设,导致在非平稳噪声条件下语声增强性能急剧下降的问题,人们开始关注基于有监督学习的语声增强算法。非负矩阵分解[13−15]是早期的基于有监督的语声增强方法之一。随着深度学习的发展,基于深度学习[16−18]的语声增强算法取得了越来越好的语声增强性能。基于深度学习的语声增强算法利用了深度神经网络强大的非线性映射能力,实现从带噪语声到纯净语声的复杂非线性映射。基于深度学习的语声增强方法分为频域映射和时域端到端的语声增强。在频域中,由于相位信息缺乏结构性,所以难以建模学习,因此一般只对带噪语声信号的幅度信息做学习建模,最后采用带噪语声信号的相位信息实现语声增强。但是在低信噪比条件下语声质量,语声可懂度会受到采用带噪语声信号相位合成语声的影响,因此人们开始采用时域端到端的语声增强方法[19−21]。基于深度学习的语声增强方法相对于传统的基于数字信号处理的方法在增强后的语声质量、语声可懂度等评价指标上得到了非常大的提升。循环神经网络能够建模语声信号的时间相关性,因此许多文献常常采用循环神经网络实现对带噪语声信号的建模[22−24]。但是循环神经网络存在参数数量巨大的问题,这不利于模型的推广,同时,在训练阶段易出现过拟合导致模型泛化能力较差。
本文针对传统的基于循环神经网络的语声增强方法中,其全连接的结构忽略了语声信号的时频结构特征[25],导致语声增强性能下降,同时参数数量巨大的问题,设计了一种采用卷积核替代循环神经网络中的全连接结构的轻量级卷积门控循环神经网络(Lightweight convolution gated recurrent neural network,LCGRU),在提高网络性能的同时降低了网络参数的数量。针对在基于深度学习因果式语声增强的方法中采用了因果式的网络输入(N+1 帧)导致语声增强性能下降的问题,本文充分利用了先前N帧的带噪语声信号特征,在LCGRU 网络当前时刻网络单元的输入中融合了上一时刻的输入xt−1与输出ht−1,这充分利用了先前N帧的语声信号特征[26]。针对网络训练过程中易出现过拟合的问题,本文采用了线性门控机制[27]控制网络信息的传输,进一步提高了网络的语声增强性能。仿真实验结果表明,LCGRU 在增强后的语声短时客观可懂度(Short time objective intelligibility,STOI)、语声感知质量(Perceptual evaluation of speech quality,PESQ)、分段信噪比(Segmented signal-to-noise ratio,SSNR)等评价指标上均优于传统的网络结构,如长短时记忆(Long short term memory,LSTM)网络、门控循环单元(Gated recurrent unit,GRU)以及简单循环神经网络(Simple recurrent neural network,SRNN)。同时,LCGRU 网络的参数数量为GRU 网络的13%,LSTM网络的9.82%。
1 深度学习因果式语声增强
通常为了使神经网络能够更准确地建模语声信号的时频结构特征,常常会采用非因果式的网络输入(2N+1 帧)。然而,采用非因果式的网络输入会给语声增强算法带来固定时延,不能满足实时语声增强的系统要求。为了保证语声增强系统的实时性,基于深度学习的语声增强算法需要采用因果式的网络输入(N+1 帧),即网络的输入只包含当前帧以及先前N帧的语声信号特征,未包含后续未来帧的语声信号特征信息。由此可知,当对第t帧带噪语声增强时,神经网络的输入可表示为
式(1)中,t、k分别表示第t帧、第k个频点,n为连续帧的数量即网络输入的窗长;φt表示多帧带噪语声拼接后的特征,用于对第t帧中纯净语声成分的估计。本文采用非负幅度谱[22]特征作为网络的输入特征,计算方法可以由(2)表示:
式(2)中,n=1,2,···,N,N表示拼接的帧数数量,即网络输入的窗长;Z(k,t,n)表示非负幅度谱特征。基于深度学习的语声增强方法利用了神经网络强大的复杂映射能力,实现将带噪语声到纯净语声的复杂映射。神经网络可以表示为复杂函数fx(x),如式(3)所示:
式(3)中,带噪语声到纯净语声的复杂映射关系由函数fx(x)表示。表示估计的第t帧、第k个频点的纯净语声特征。在网络的训练过程中,本文采用平均绝对误差(Mean absolute error,MAE)作为损失函数,如式(4)所示:
式(4)中,M表示批量大小,本文设置为128;Ti表示标签数据(纯净语声的非负幅度谱特征),即纯净语声的特征向量。通过多次训练计算损失函数值,经过反向传播调整网络权重,最终获得泛化能力较好的网络模型实现语声增强。
2 门控循环神经单元
2.1 GRU
传统的循环神经网络能够建模时间相关序列,但是容易出现梯度消失的问题,导致模型无法训练,对此有学者提出了GRU,缓解了网络梯度消失,同时能够建模时间序列的长期依赖关系。图1 为常用的GRU模型。
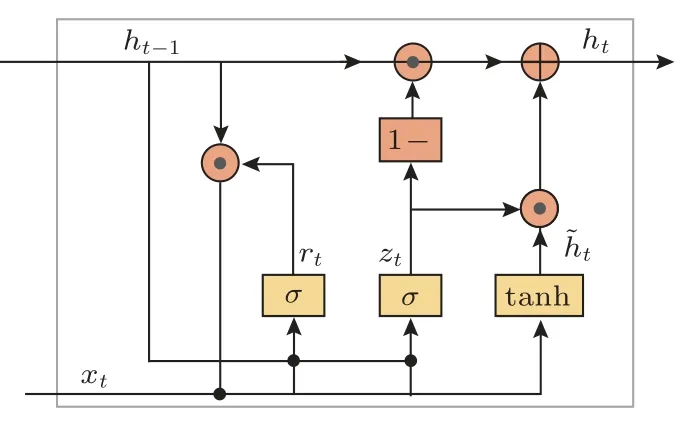
图1 GRU 单元Fig.1 GRU unit
图1 的GRU 是对LSTM 网络的简化设计。GRU网络单元的前向传播可由式(5)表示:
式(5)中,Zt、rt、ht分别表示更新门、重置门以及网络单元的输出。其中⊙为Hadmard 乘积,σ为Sigmoid激活函数。
2.2 LCGRU
传统的门控循环神经网络(GRU,LSTM)能够有效建模语声信号的长期依赖关系。但是其全连接的网络结构忽略了语声信号的时频结构特征,导致语声增强性能下降。对此,本文设计了一种LCGRU,采用卷积核替代GRU传统的全连接结构。LCGRU网络在对语声信号的时间相关性建模的同时保留了语声信号的时频结构特征,降低了网络参数的数量。针对在深度学习因果式的语声增强方法中,由于采用了因果式的网络输入(N+1 帧),语声增强性能下降的问题,LCGRU 网络为充分利用先前帧(N帧)的语声信号特征,网络单元当前时刻的网络输入融合了上一时刻的网络输入xt−1与输出ht−1,这充分利用了语声信号的先前N帧的特征信息,极大地提高了网络的语声增强性能。为了缓解网络训练过程中的过拟合问题,本文采用了线性门控机制(Gated linear unit,GLU)[27]控制信息的传输。图2为本文设计的LCGRU。

图2 LCGRUFig.2 Lightweight convolutional gated recurrent neural network
图2 为LCGRU 网络的前向传播示意图,图中xt−1、ht−1、xt分别代表上一时刻的输入、上一时刻的输出以及当前时刻的输入。ft、分别表示遗忘门与候选隐藏状态。在LCGRU 网络单元中,首先计算输入特征的带权特征向量:
式(6)中,xt、xt−1、ht−1分别代表网络当前时刻的输入、网络单元上一时刻的输入以及输出;W∗代表网络的卷积核,为可训练参数。得到带权特征向量后计算遗忘门ft与候选隐藏状态可由式(7)与式(8)表示:
式(7)∼(8)中,w∗代表网络的卷积核,本文采用一维卷积核替代传统的全连接结构;b∗代表偏置项,为可学习的参数向量。最后网络的输出可由式(9)表示:
式(9)中,ft为遗忘门的输出为上一时刻输出的带权特征向量。其中⊙代表Hadmard 乘积,∗代表卷积运算。
3 实验与结果分析
3.1 仿真实验设置
为了验证所提算法的有效性,本文通过在tensorflow/keras 平台上实现网络的搭建及训练,验证算法的优越性。数据集中的纯净语声来自于TIMIT[28]数据集,同时包含了不同性别、地区、人种等不同说话人的声频信息,文本方面也不会出现有重叠,这保证了模型的可推广性。噪声数据集来自于文献[29]中的100 种噪声以及文献[30]中的15 种噪声。通过在TIMIT 训练集中随机提取1000条纯净语声与文献[29]中随机抽取的噪声在信噪比为−5 dB、0 dB、5 dB、10 dB 条件下生成4000 条带噪语声作为训练集。通过在TIMIT 测试集中随机抽取200 条纯净语声与文献[30]中的噪声同样在−5 dB、0 dB、5 dB、10 dB 信噪比条件下生成800条带噪语声作为测试集。网络的学习率为1×10−4,学习率的衰减系数为1×10−6。本文采用批量数据的训练方式,批量大小为128,并采用MAE 作为网络的损失函数。为验证所提算法的有效性,本文采用的对比网络结构为简单SRNN、GRU以及LSTM网络。网络均采用层叠加的方法,网络均采用4 层结构,每一层均为512个神经单元。LCGRU同样采用4层的网络结构,每一层的卷积核为32,卷积核的大小为9。
3.2 仿真实验结果与分析
本文采用的评价指标为平均PESQ、平均STOI以及SSNR作为对增强后的语声评价。STOI的取值范围为0∼1 之间PESQ 的取值范围为−0.5∼4.5之间。二者均为数值越大,增强后的语声质量与可懂度越高。统计结果如表1与表2所示。
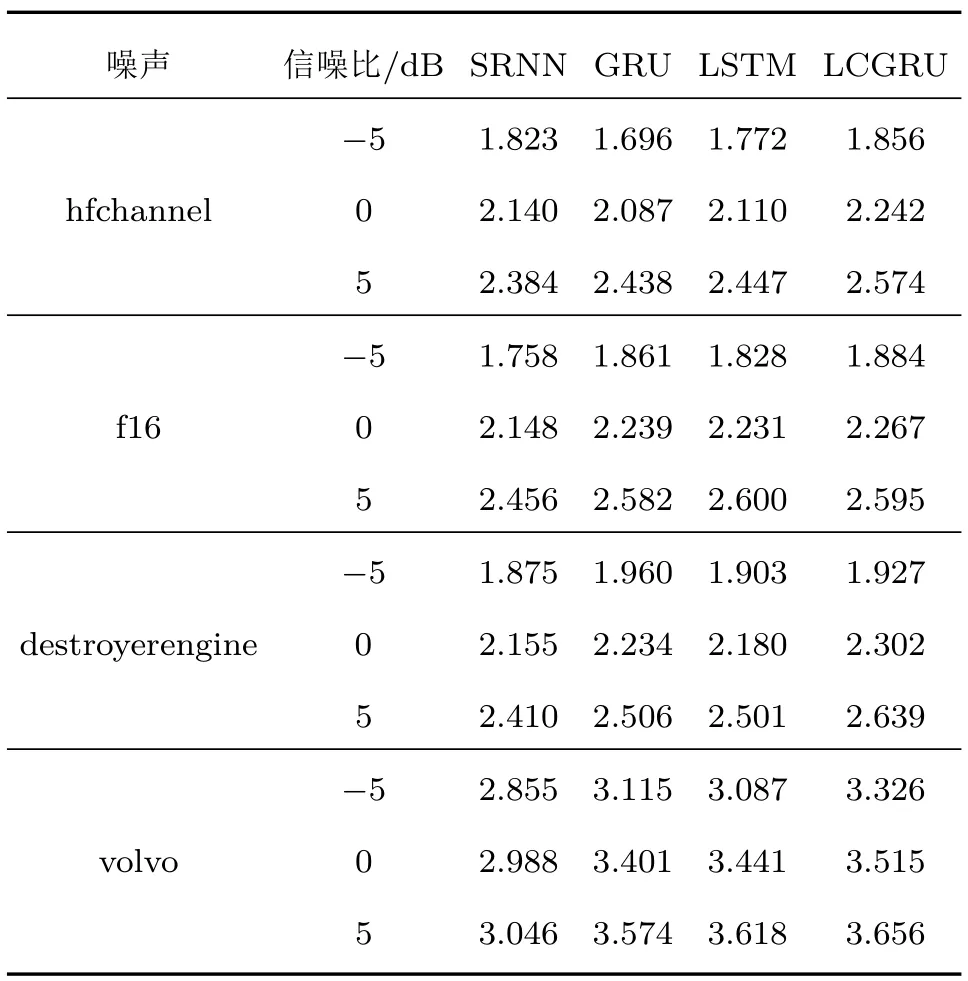
表1 平均PESQTable 1 Average PESQ

表2 平均STOITable 2 Average STOI
表1∼2 统计了文献[30]中的4 种噪声hfchannel、f16、destroyerengine 以及volvo 在不同信噪比条下生成的带噪语声经过不同的网络结构增强后的平均PESQ以及平均STOI。从表1∼2中可以得出,本文所设计的LCGRU 增强后的语声在STOI、PESQ 的得分上均高于传统的网络结构,这充分证明了本文所提出的基于LCGRU的语声增强方法的有效性。LSTM 与GRU 的性能相对于SRNN 更加优越,这是由于LSTM、GRU采用了门控机制,能够学习到语声信号的长期依赖关系,而SRNN 未采用门控机制。LCGRU 网络不但采用了门控机制,并且采用了卷积核替代了全连接结构,所以性能得到了较大提高。为进一步验证所提算法的优越性,本文统计了不同噪声条件下不同模型增强后的语声SSNR,如图3所示。
从图3 中可以得出,LCGRU 网络结构相对于传统的网络结构(SRNN,GRU,LSTM)增强后的语声SSNR 更高。SRNN 网络结构虽然在图3(a)、图3(b)中在低信噪比条件下的语声SSNR 高于GRU、LSTM,但是依然低于LCGRU,同时随着信噪比的提高其性能逐渐低于GRU、LSTM。然而,可以看出LCGRU网络依然拥有较好的语声增强性能,这证明了相对于传统的网络结构(GRU,LSTM,SRNN),LCGRU的鲁棒性更好。
综上所述,LCGRU 网络相对于传统的网络结构(SRNN,GRU,LSTM)在增强后的STOI、PESQ、SSRN 等评价指标上获得更高的得分。而LSTM 相对于GRU、SRNN 拥有更好的语声增强性能,但是其参数数量较多,导致网络训练困难,同时容易出现过拟合的问题。而LCGRU 网络因为采用了卷积核替代了传统循环神经网络的全连接结构,同时采用了线性门控机制控制信息的传输,因此不但极大地减少了网络的参数数量,同时保留了语声信号的时频结构特征,从而获得了较好的语声增强性能。针对在深度学习因果式语声增强方法中因采用因果式的网络输入导致语声增强性能下降的问题,LCGRU 为充分利用先前帧的语声信号特征,在LCGRU 网络单元当前时刻的输入中融合了上一时刻的输入xt−1与输出ht−1,这充分利用了先前N帧的语声信号特征,降低了因为采用因果式网络输入特征信息减少所带来的影响。表3、表4 统计了不同网络结构的参数数量,以及模型收敛后的绝对误差;表5 中统计了采用不同网络模型NVIDIA GeForce MX350 环境下,GPU 平台中处理一帧带噪语声数据所需要的平均时间。

表3 不同网络模型的参数数量Table 3 Parameters of different network models

表4 不同网络模型的验证损失Table 4 Verification loss of different network models

表5 不同网络模型处理一帧语声数据所需要的时间Table 5 The time of different models to process a frame of data
从表3 可以得出LCGRU 网络的参数数量为GRU网络的13%,为LSTM网络的9.82%。LCGRU网络的参数数量得到大幅度减少,这得益于本文采用卷积核替代传统的全连接结构。从表4 中可以看到,LCGRU获得了最低的损失值,这证明了该网络结构能够更好地建模带噪语声到纯净语声的复杂映射关系。从表5 可以看出,本文所提算法相对耗时,这是由于本文采用卷积核做特征计算,计算量相对较大,但依然满足实时性要求。
4 结论
针对传统的循环神经网络因采用全连接的网络结构忽略了语声信号的时频结构特征,本文采用卷积核替代了传统的全连接结构,在对语声信号的长期依赖关系建模的同时,保留了其时频结构特征信息,极大降低了网络的参数数量。针对基于深度学习的因果式语声增强方法中因采用了因果式的网络输入导致语声增强性能下降的问题,本文设计了一种LCGRU网络结构。为充分利用先前帧的语声信号特征,在LCGRU 网络单元当前时刻的输入中融合了上一时刻的输入xt−1与输出ht−1,这充分利用了先前N帧的语声信号特征,降低了因为采用因果式网络输入特征信息减少所带来的影响。注意力机制能够更好地关注到带噪语声中纯净语声成分。此外,在语声和声频处理领域,利用人耳掩蔽效应,取得了极大成功。下一步将研究利用注意力机制结合人耳掩蔽效应提高网络的语声增强性能。同时,为了缩短模型的计算时间,将采用扩张卷积等方式做进一步的改进,以提升系统的性能。
