基于关联规则挖掘的车辆故障码分析
2023-05-04李源洁耿黄政童敏敏
胡 杰,耿 號,李源洁,耿黄政,童敏敏
(1.武汉理工大学,现代汽车零部件技术湖北省重点实验室,汽车零部件技术湖北省协同创新中心,湖北省新能源与智能网联车工程技术研究中心,武汉 430070;2.上汽通用五菱股份有限公司,柳州 545007)
前言
车辆故障码诞生的初衷是为了简化对车辆故障的判断和定位过程,缩短故障检修时间。现代汽车包含大量的传感器、执行器和电控单元(electronic control units,ECUs)[1],单辆车定义的故障码数量可达1 000以上。车辆电控模块的独立生产,使得单个电控模块仅针对所接收的信号及报文数据进行故障判定,并不考虑与其他电控模块的故障关联。故障码总数多,且单个模块形成了故障判定“孤岛”,实际电控故障发生时,由于电控系统的耦合性,电控信号的流转使故障码的产生出现了耦合与驳杂的情况,单次维修读取的故障码数量可以达到20 个甚至更多,大量的故障码模糊了故障源头,增加了故障定位时间。
目前基于车辆故障码优化车辆故障诊断过程研究主要集中在故障码模式识别和以故障码为特征输入的机器学习:Theissler[1]提出了一种基于故障码和车辆信号的车辆操作模式的分类方法,对故障诊断中的新颖的操作模式进行判断;Kriebel 等[2]基于故障码产生的时间和空间对特定时空产生的故障码模式进行识别,并提出了一种模式融合的方法,但未将故障码和实际故障结合进行分析;Thoorpu 等[3]将故障码使用序列模型、非序列模型、深度学习模型进行分析,探寻其与车辆部件故障之间的关系,并提出了一种序列故障码的嵌入方法以增加故障诊断的精确度;Kopuru[4]使用深度学习算法计算故障码和车内信号之间的关系,并提出了一种故障码的预测方法;Oliveira 等[5]提出一种基于故障码的检修过程融合和模块可靠性分析方法。国内对于使用故障码进行车辆故障诊断的研究较少,仍直接以故障码释义进行故障诊断[6],已不再满足基于故障码进行车辆故障诊断的实际需求。综上,现有研究仅将故障码作为分析的数据特征而忽略了故障码本身的故障语言属性,研究得出的结果对车辆内部故障的耦合及传播机理没有解释作用,在终端检修过程中,对基于故障码定义进行检修的工作流程没有帮助。
车辆故障码是车辆故障的语言载体,对故障码间关系的分析,即是对车辆内有故障码定义的故障之间关系的分析,这一分析结果对车辆耦合故障的解耦具有一定意义。对故障码数据进行分析,挖掘故障码之间的关联性,形成故障码关联知识并保存。针对耦合电控故障产生的大量故障码,基于关联关系定位主要故障码,可以显著缩短故障检修时间。
本文中基于某一新能源车型产生的历史故障码数据进行关联规则挖掘,以故障码之间的关联规则建立整车故障码关联图以存储关联知识,提出了基于此关联图的两种应用场景:(1)故障码关联可视化,提供耦合故障码的可解释性;(2)主要故障码的确定,缩短基于故障码的故障分析时间。
1 故障码关联规则挖掘
基于故障码产生及车辆信号传播原理,对故障码之间的关联关系挖掘提出理论依据,给出故障码之间的关联规则定义、挖掘和应用流程。
1.1 车辆故障产生与信号传播
车辆电子电气故障发生时,车辆电控模块会进行一系列的自诊断与自处理过程,如图1 所示,主要包括诊断监测、故障确认、诊断故障检查、故障抑制处理和诊断故障事件存储。在诊断故障事件存储阶段,故障所产生的故障码被存储于存储器中。车辆电控模块不断增加的同时也变得更加集中[6],一些功能模块对典型故障判断仅仅依靠电控单元信号与通信报文进行。
故障信号传播模型如图2 所示,某车辆故障发生时,单一电控模块的信号异常会导致相关联的电控模型所监测的信号值异常,若达到其他电控模块自诊断监测阈值等条件时,其他电控模块也会进行相应的故障抑制处理。当多个电控模块存在上述流程时,故障传播形成一条复杂的“链路”。这种状态下,由诊断设备读取到的故障码数据处于一种大量且驳杂的状态。
根据上述讨论,单次故障时产生的故障码集合有如下特点。
特点1:同一故障产生的故障码集合是确定的。由于模块自诊断程序不会变化,诊断逻辑不会变化,同一故障产生的故障码集合应是统一的。
特点2:故障码集合中所有元素可以组成一个故障码传播有向图。故障信号的传递过程就是故障码的产生过程,与图2 所示的传播模型相似,是一个有向图。
1.2 故障码关联规则定义
1.2.1 故障码关联关系
由上节所述,单次故障产生的故障码集合不变且内部元素可构建故障码关联有向图。设当某故障码集合表述为有向图时,存在相邻故障码节点为D1、D2,有关联关系:D1→D2,表述此关联关系为:“当D1发生的情况下,D2必然会发生”。将单次故障存在的关联关系拓展至所有历史数据,表述为:“在历史故障码数据中,当D1发生的情况下,D2必然会发生”,也即
由于电控模块的不稳定性,式(1)一般不会得到满足。在实际情况中,则应有
式中p应为接近1的数字,在本文后续分析中,取p=0.84(本文3.2小节给出原因)。
由于故障信号传播,故障码关联关系与一般单维布尔型数据的关联关系的不同点在于:故障码关联关系揭示了故障码的“因果”。可以认为,有关联关系D1→D2,即意味着D1的产生为D2产生的原因,D2的产生为D1产生的结果。
综上,可认为在历史数据中出现的故障码,若满足式(2),则故障码之间有相应的关联关系。
1.2.2 故障码关联规则
关联规则挖掘是数据挖掘中的重要组成部分[8],设某一数据库为D,项目集为某单一数据特征的所有可能取值,记为Γ={I1,I2,…,Im},其中Γ为项目集,Ii为某一可能取值,称为项,1 ≤i≤m。事务由项组成,记为T。每个事务中的项集都是项目集的子集,即有T⊆Γ。每条事务都有其唯一标识,记为TID。某一项集的支持度是指在事务数据库中,包含此项集的事务个数与总体事务个数的比值;对于两个项集A、B(A⊂I,B⊂I,A∩B= ∅)产生的形如A→B的蕴含式,此蕴含式的置信度是指数据库事务中同时包含A、B项集的个数与仅包含A项集的事务个数的比值。支持度和置信度的计算公式为
式中:||·||指某一数据“·”的数据个数;sup(A∪B)为同时包含项集A、B的事务个数。
关联规则即为形如A→B的蕴含式,关联规则的关联性强弱由支持度和置信度阈值来决定,通常将支持度和置信度阈值称为最小支持度和最小值置信度。满足这些阈值,也即满足sup(A∪B) ≥minsup,conf(A→B) ≥minconf的关联规则认为是有趣的,将其称为强关联规则。
综上,1.2.1 节所述的故障码关联关系可与关联规则相结合,此时则有:(1)数据库D为车辆故障所传回的历史数据;(2)Γ为车辆的故障码清单;(3)Ii为某一故障码;(4)T为单例故障产生的故障码集合;(5)minconf为式(2)中的p。
式(2)的计算也即计算式(3)和式(4),由于电控系统存在偶发故障,使得低支持度阈值关联规则的可信性较低,而选取较大支持度阈值可能会将部分重要但支持度较低的故障码丢弃,所以minsup的选择原则为:在可以对极少数偶然发生故障码进行清理的情况下,取尽可能低的阈值。本文中取参数minsup= 0.0005。综上,将1.2.1 节所述故障码间关联关系定义转化为关联规则挖掘中的置信度定义,为后续关联规则计算及应用分析提供理论基础。
1.3 挖掘方法及应用流程
关联规则挖掘及应用流程主要如图3 所示。主要包括数据预处理过程、基于改进Fp-Tree 的关联规则挖掘过程和关联规则存储为故障码关联图的方法。最后,探讨使用故障码关联图进行故障码关联挖掘与可视化、主要故障码确定的应用方法,并举例说明验证。
2 关联规则计算及图构建
数据来源是某企业某一新能源车型在2021 年3 月与8月在维修站点所读取并保存的故障码数据,数据集中共有故障码279 122条,原始部分故障码数据如表1所示。
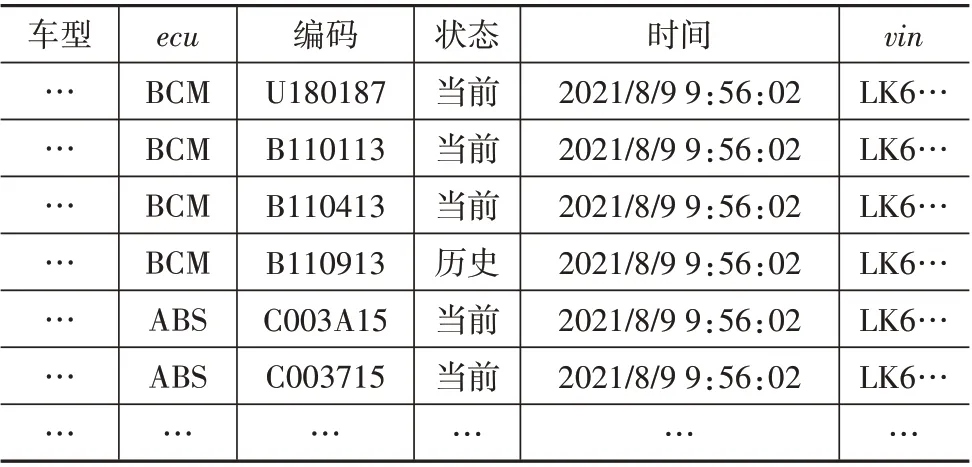
表1 故障码数据表
2.1 数据定义与预处理
表1数据中每一条数据定义为
式中:ecu为对应的ECU 代码;s为故障码状态;t为上传时间;vin为车辆识别代号。
以vin、time为标签,则有
式中j代表第j辆车上传的数据。
由于存在部分车辆故障码重复上传、乱码等情况,对数据预处理中的其他规则做如下规定:
(1)同一车辆的检修时间限定为同一辆车故障码上传时间间隔不得低于3天,对于3天内同一车辆多次上传的事务丢弃;
(2)对于存在大量编码乱码情况的事务进行丢弃,对于少量编码乱码的数据仅丢弃乱码项;
(3)丢弃所有故障码项都以“U”开头的故障码事务,由于以“U”开头的故障码为网络报文类故障码,若整个事务中仅包含此类故障码,则此时对故障码关联进行判断得到的关联无效(无故障原因对应的故障码项)。
数据预处理后共有事务20 188 例,预处理完成的部分事务的项集合如表2所示。

表2 部分事务数据
2.2 基于改进Fp-Tree的关联规则计算
本文基于Fp-growth 算法[9]中的Fp-Tree 思想,提出计算故障码关联规则的算法。
Fp-Tree 是Fp-growth 算法中的频繁模式树,其通过扫描两次数据库即可建立。建立过程如下:
(1)扫描一次数据库,删去支持度较小的数据项并将原始数据中的事务中的单个数据项按支持度降序进行排列;
(2)再次扫描数据库,定义一个空的根节点进行Fp-Tree 的创建,同时构建头部表(HeaderTable)进行相关节点信息存储。
对Fp-Tree 中的节点属性进行修改,除father、children 属性以外,实际参与计算过程的属性变化如图4 所示,增加3 个基础属性,各属性的含义如表3所示。各节点属性值在Fp-Tree 构建过程中实时更新计算。

表3 Fp-Tree节点属性及其含义
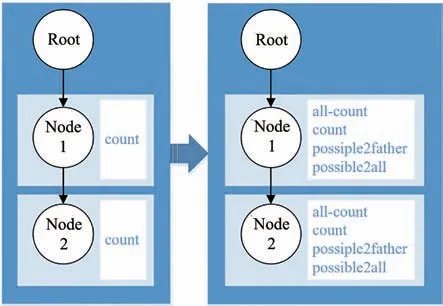
图4 Fp-Tree节点计算相关属性变化
Fp-Tree 的构建过程赋予了Fp-Tree 如下的基本性质:
(1)每一个可能的分支都是一次或多次事务数据的体现,这就代表每一个分支从叶子节点开始回溯时,叶子节点及其父辈节点肯定出现在同一个事务中,且同时出现的事务支持度为叶子结点的支持度;
(2)越接近Root 节点的节点支持度越大,某分支的叶子节点在此分支的所有节点中支持度最小;
(3)Fp-Tree 可以由HeaderTable 中出现的节点链接进行分层,低支持度的节点在Fp-Tree 的最高层。
基于上述性质,记项目支持度从小到大排序列表为OrderItem,则计算所有项目之间置信度的伪代码如表4所示。
从低频次节点开始,也即从树的最高层开始,计算节点出现在某分支中的置信度大小,再将多个分支计算得到的置信度相加。此计算方法相较于多次扫描数据库计算式(3)和式(4),有如下优点:
(1)减小遍历数据库次数,仅遍历两次数据库进行Fp-Tree 的构建,生成的Fp-Tree 已经包含了数据库中所有相关联信息,且关联关系的计算可以直接根据已得Fp-Tree中各个节点的属性值进行;
(2)减少了需要保存的参数数量,避免了冗余计算,Fp-Tree 的基础性质中,有着树分支即为事务这一特点,则对于没有出现在同一个事务中的项目,在基于树分支进行置信度计算的过程中,不会计算这些项目之间的置信度关系,避免了冗余计算,且减小了在计算过程中需要保存的参数量。
设一数据案例有Fp-Tree和HeaderTable,如图5所示。
根据上述算法对各个节点之间的关联关系进行计算。频次最低的节点为I5,以I5在HeaderTable 中保存的节点链接开始,I5节点存在如图5所示树结构中最左两个树分支。分别计算两个分支中的节点置信度,可得到:
其他节点之间的置信度计算与I5节点计算类似,此处不再赘叙。
综上,基于Fp_Tree提出快速计算式(3)和式(4)的算法,实际计算过程共计算参数69 150个,其中满足最小置信度阈值的参数共5 115个。
2.3 图构建
对于满足最小置信度的节点进行有向图构建,有向图中节点关系存在的规则如下。设图中节点A、B,在2.2 节计算置信度过程中,若满足:conf(A→B) ≥p,则认为有边A→B。
使用networkx 工具包进行有向图构建,构建完成的图结构共有节点666 个,存在5 115 条边。构建的有向图如图6所示,其中蓝色圆点代表故障码。

图6 故障码有向图
在上述的故障码有向图中,存在部分故障码成环。成环故障码之间的关联关系可表述为:“故障码互为因果,同时出现,同时消失”。在故障判断环节,可认为成环故障码是同一故障码,可同时分析处理。使用Tarjan算法[10]进行有向图的强连通分量检测,并可将强连通分量缩点处理,简化故障码有向图结构。
3 基于故障码有向图的应用
基于故障码有向图可以对历史故障码中出现的有趣故障码规则进行可视化挖掘分析;对故障检修过程读取的故障码进行因果链路分析,确定主要故障码,协助维修人员检修故障。
3.1 有趣关联规则分析及可视化
故障码传播规则挖掘原理如图7 所示,主要挖掘对象为某故障码的前后链路节点,辅以图结构进行故障码规则链路的可视化。
如图7 所示,橙色节点为故障核心节点,为分析输入,通过故障码有向图对橙色节点的前驱节点和后置节点进行计算,可以得到橙色节点对应的故障码与车辆其他故障码的关联规则。
以故障码:“P140516:单体电压低-2 级”节点为例,检索与其相关故障码,关联关系如图8 所示,从图中可以取得如下结论:
(1)P140416,P140516,P140616 几乎同时产生,同时消失,应为同一故障,进行缩点处理;
(2)单体电压低故障码会伴随整车控制器报“B102A00:电池包告警级别--放电跛行行车”、“B104A00:电池包告警级别--电池停车请求”、“B101B00:电池包单体电压告警状态--电压过低”。
有趣的故障码关联规则蕴含了电控系统内部的故障关联关系,也是故障因果关系。如在上述以故障码P140516 的分析中,可以明确得到的故障因果为:单体电压低故障会导致行车异常或无法行车。类似的,以其他故障相关的故障码节点为输入,挖掘在实际使用中较为重要的故障关联知识,对车辆故障的知识库形成有良好的参考意义。如根据故障码B102A00输入得到的关联图(图9),可以揭示在历史数据中出现并会导致“电池包告警级别--放电跛行行车”的故障码情况。
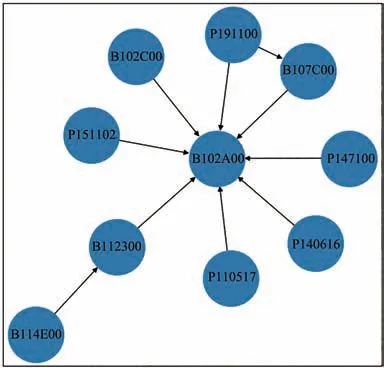
图9 故障码B102A00关联图(缩点后)
以某一故障码为输入,关联图为输出,并结合故障码定义进行故障分析的过程,是对历史数据中出现的故障情况以及故障在车内传播情况的剖析过程。这种分析方法可以站在更高的维度对故障情况进行全面解释,所形成的故障规则,对于车辆质量把控以及检修方案的制订,有着良好的指导作用。
3.2 主要故障码分析
故障码有向图除了可用于对历史数据中的故障码关联进行剖析之外,还可以用于故障维修过程,实现故障源所对应的主要故障码的定位分析。
对复杂故障所产生的驳杂故障码进行关联分析,给出其内已存在的传播路径,从而确认故障源。若直接确认某一故障源对应的主要故障码,此故障必须在历史数据中多次出现,对于历史数据要求较高。然而,即使对于部分案例无法直接定位故障源故障码,得到的分析结果有一定冗余,也依旧对诊断设备直接读出的故障码有一定的精简效果,可以大大缩短故障码排查时间。分析过程主要分为关联子图构建和主要故障码计算两步。
基于实际故障时产生的故障码进行关联子图构建,主要流程如图10 所示。由于报文类故障(报文丢失、验证错误等)一般在非报文故障之后检修,则首先去除以“U”开头的故障码,然后将读取的故障码去重,取整车故障码有向图转化的关联矩阵中相同故障码标识的行和列,组成故障时故障码的关联矩阵,根据此关联矩阵生成故障码子图。

图10 故障码子图构建流程
主故障码分析过程如图11 所示。基于前述构建的故障码子图,使用Tarjan 算法检测强连通分量后缩点。考虑到故障源产生的故障码无前驱节点,则此故障码入度为0。通过计算所有节点的入度,此时入度为0 的强连通分量或单个故障码即为故障源对应的故障码,如图11 中的1、2、6 橙色节点所示。
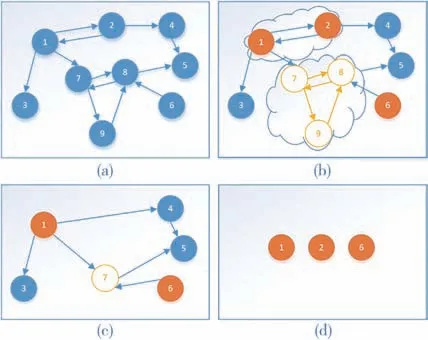
图11 故障源故障码分析原理
由于数据决定了关联规则的挖掘结果,会使故障源故障码判定仅对较高支持度的故障源故障码有良好效果,但关联规则依旧对读取的故障码有精简作用。对于所有历史事务数据进行关联分析。采用5-fold 交叉验证,计算在不同置信度条件下故障码平均精简率,结果如图12所示。
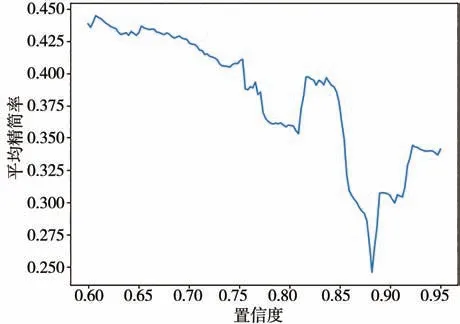
图12 不同置信度故障码数据的精简率
从图12 中可以看出,随着置信度上升,精简率整体呈下降趋势,这是由于关联规则数量降低而产生的结果。在下降过程中,存在某些置信度条件下,精简率升高的特点,这是因为关联规则的准确性提高,成强连通分量的故障码团内元素减少,数据精简率上升。
为了满足节点间高置信度需求,同时获得更高的精简率,本文在对已有的历史数据分析过程中,取置信度为0.84,此时得到的关联规则对历史数据的精简率为39.35%.
取此车型支持度较高的5 个典型故障产生的故障码事务,使用基于历史数据构建完成的有向图模型对各个事务进行分析,分析结果如表5 所示。故障源故障码的平均直接判别率约54.08%,典型故障的平均故障码数据精简率为65.06%。
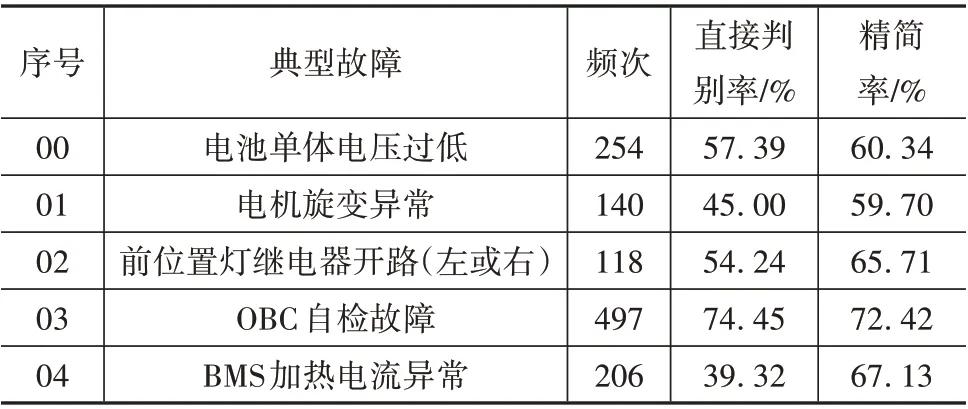
表5 典型故障分析结果
通过对特定事务进行分析,可以在实现故障码精简的基础上,对于部分支持度较高的故障,实现故障源故障码的判定。能够简化或免去维修人员对于故障码的分析工作,优化了检修流程。
4 结论
本文中基于关联规则挖掘对车辆故障时产生的历史故障码数据进行分析,提出了故障码关联定义与基于Fp-Tree 的关联规则挖掘算法;将故障码间的关联规则以图结构存储,提出了两种应用场景及方法。在本文的故障码数据集中,取置信度为0.84,通过对历史数据分析可以发现部分故障码传播的兴趣规则;根据故障码间关联规则对整体历史数据进行精简,精简率为39.35%;选取部分支持度较高的故障数据,分析所得到的平均故障源故障码判别率可达54.08%,平均故障码精简率为65.06%。
本文中的故障码分析方法仅依靠历史故障码数据为输入,分析结果可以应用于车内故障传播链路分析与可视化和主要故障码分析,能够提高对耦合故障的诊断准确性和检修时效性。
