基于R软件的高中统计教学实践研究
2023-04-11张广民曹雅楠杜晓沛
张广民 曹雅楠 杜晓沛
摘 要:以一次基于R软件的抽样试验教学活动为例,探索R软件在统计教学中应用的可能路径,并基于教学活动的开展效果提出统计教学的几点思考:数据分析素养需要在学生的亲身经历中发展;统计思维需要在学生的批判验证中提升;科学素养需要在信息技术的教学应用中生成.
关键词:R软件;统计教学;随机抽样;数据分析
统计内容近年来在高中数学课程中的地位逐步提高,特别是《普通高中数学课程标准(2017年版2020年修订)》将概率与统计内容设为四条主线之一,贯穿整个高中数学课程体系,将数据分析列入六大数学核心素养,并指出,数据分析是研究随机现象的重要数学技术,是大数据时代数学应用的主要方法,也是“互联网 +”相关领域的重要数学方法,数据分析已经深入到科学、技术、工程和现代社会生活的各个方面.
数据分析素养要求学生有数据意识,认识数据,能用数据的眼光观察世界,能够收集数据、处理数据、分析数据、得出结论,具有统计思维,能够理解并体会随机性. 在高中阶段加强数据分析素养的提升刻不容缓,数据分析素养是时代所需,是信息时代学生应该具备的基本素养. 同时,数据分析素养的培養与提高需要在统计教学中得以落实.
一、统计教学实践中面临的困境与突破
当前高中统计的教学过程中仍然面临着亟须突破的困境.
一是认知困境.统计学的“或然思想”与传统数学的“必然思想”有所区别. 传统数学以概念和定义为基石,以公理体系为推理基础,得到确定的必然结果. 而统计学则建立在数据的基础上,以数据背景为推断,得到或然性的结论,关注的是如何从数据中挖掘更多有效信息. 因此,若仍采用一贯的教学方法和研究思路,容易使学生产生思维上的不适应性,也不利于学生理解统计学的本质.
二是评价困境. 统计内容在高考中或是以简单的形式出现,或是每年以相对固定的模式出现. 客观来说,统计内容在纸笔测试的考查中确有难度,这方面也需要教师做进一步的研究. 教师在日常的统计教学中,倾向于直接给出概念,辅以例题讲解,学生再通过习题训练达到考试要求,这与发展数据分析素养的课程目标相背离.
因此,在统计部分的教学实践中,教师需要根据教学内容和学生的实际情况调整教学策略,让学生由数据出发,通过对数据的处理与分析探索得到研究结论的过程. 这就需要学生自己动手进行实践,而数据处理环节的实践又必须借助统计软件来完成.在统计教学中加强信息技术的应用,既是提高教学效率的举措,又能更好地反映统计的学科特征.
目前,中学阶段常用的统计软件包括Excel,R,SPSS. 其中Excel是常见的数据处理软件,有丰富的图形操作界面,是日常办公的必备软件,但是在进行较为专业的数据处理时不如R语言清晰、简便. SPSS也是一款功能强大的统计软件,一般采用图形界面,但是价格昂贵,对于编写代码有不便之处. R软件是开源软件,在统计工作中有广泛的应用,能够进行随机模拟,使得大量随机试验的完成得以实现,能够更好地帮助学生观察样本与总体之间的联系,增强教学的直观性和实操性,在人教A版《普通高中教科书·数学》(以下统称“教材”)中存在大量的R语言实例. R语言以指令形式运行,入手存在困难,这也是R软件在普及过程中的一个弱点. 笔者所在学校在进行统计教学的过程中,利用课余时间对学生进行了R语言使用的基础培训. 从最终教学效果看,学生掌握得非常好,能够使用R软件进行数据处理的基本操作,这为利用R软件开展统计活动做好了前期技术上的准备.
二、基于R软件的抽样试验教学活动案例
以教材必修第二册第九章第1节“随机抽样”内容为例,通过设计一系列学生实践活动,并在教学中应用R软件辅助统计活动开展,探索与尝试R软件应用于高中数学统计教学的可能路径,以期提升学生的数据分析素养.
教学活动从“调查学生平均身高”这一核心问题出发组织学生开展探究活动,分析不同的抽样方法下样本均值对总体均值的刻画效果,以及R软件的实现方法.
问题:一家家具厂要为树人中学高一年级制作课桌椅,他们事先想了解全体高一年级学生的平均身高,以便设定可调节桌椅的标准高度. 已知树人中学高一年级有712名学生,如果要通过简单随机抽样的方法调查高一年级学生的平均身高,应该怎样抽取样本?
1. 通过随机数法进行简单随机抽样
实现简单随机抽样可以采用抽签法和随机数法. 两种方法都需要产生随机数,只是产生工具有所不同. 面对总体较大的情况,借助信息技术手段生成每个样本的随机数,是最为方便、成本最低的实施方案. 故首先可以借助R软件生成随机数.
试验1:简单随机抽样.
利用R软件,只需要“sample( )”一条指令就能完成抽样过程,包括有放回和无放回的情况.
R软件代码如下.
> Students <- c(1:712) # 建立一个学生编号的向量
> sample(Students,50,replace=FALSE) # 从712名学生中,无放回地抽取50个学生
其中,c(1:712)表示建立一个从1到712的向量(或可以理解为数组). 指令sample表示从Students中抽取50个样本. 参数replace为FALSE时表示无放回的抽取,为TRUE时表示有放回的抽取. 运行结果如图1所示.
通过试验1,初步掌握借助统计软件进行简单随机抽样的基本方法,关注所抽取的样本的均值情况.
2. 样本量对抽样结果的影响
在抽取样本的过程中,样本量的选取是值得讨论的问题. 从抽样问题本质来看,所抽取的样本容量越大,样本的数字特征接近总体数字特征的概率就越大,往往更能反映总体情况. 但是在实际问题中,受到人力、费用、时间成本的影响,并不是抽样容量越大越好. 以下借助R软件完成试验2,考察不同样本量下样本均值与总体均值的差异.
试验2:样本量分别为10,100,200,500对抽样结果的影响.
利用R软件进行不同样本容量下的简单随机抽样,做出图象形象地观察所得数据,考察样本容量对抽樣结果的影响. 仍然针对712名学生身高的探究问题情境进行抽样调查,可以在前期通过问卷调查获取真实的高一学生身高数据,这里通过正态随机数生成712名学生身高数据,并以此作为此问题的总体. 利用无放回简单随机抽样分别抽取10名、50名、100名、200名、500名学生的身高数据,计算几次抽样得到的样本平均身高并与总体均值进行比较,观察其与总体均值的偏离情况.
首先,利用R软件进行抽样,代码如下.
< # 简单随机抽样,样本量是否越大越好?
< Height <- rnorm(712,mean=165,sd=7)
< colnames <- c("NO","X10次","X20次","X50次","X100次","X200次","X500次")
< rownames <- c(1:50)
< A <- matrix(nrow=50,ncol=7,dimnames = list(rownames, colnames))
< A[,1]=c(1:50)
< flag <- c(10,20,50,100,200,500) #分别表示抽取的样本数为10,20,50,100,200,500,可调整
< for (i in c(1:50)) {
< for (k in c(1:length(flag))) {
< A[i,k+1]<- mean(sample(Height,flag[k],replace = FALSE))
< }
< }
< B <- data.frame(A)
为了清晰地反映不同样本容量对抽样结果的影响,选取样本容量为10和100两种情况,分别绘制样本平均值与总体平均值的折线图,体会用样本估计总体的过程.
R软件代码如下.
< # 绘制折线图,比较样本容量不同,对抽样结果的影响
< # 下面的是样本容量为10和100的情况比较
< library(ggplot2)
< p1 <- ggplot(data=B)
< p2 <- p1+geom_point(mapping=aes(x=NO,y=X10次))+
< geom_line(aes(x=NO,y=X10次))+
< geom_point(mapping=aes(x=NO,y=X100次),size=2,shape=2,color="red")+
< geom_line(aes(x=NO,y=X100次),color="red")+
< geom_hline(yintercept =mean(Height),color="red",size=1)
< p2+ylab(" ")
运行结果如图2所示,其中“●”表示抽取样本容量为10的情况,“[△]”表示抽取样本容量为100的情况. 由图2可以看出当样本容量为10时,产生较大偏差的情况更多,而当样本容量为100时,得到的结果相对稳定.
同时,受随机数生成的随机性的影响,某些时候样本容量为10的效果要比样本容量为100的更好. 例如,在第10次试验中,容量为10时所抽取的样本比样本容量为100更贴近总体均值. 通过此试验,可以让学生初步体会利用样本估计整体的统计研究思想,体会在统计研究的过程中,并不是针对确定数值的研究,而是伴随概率问题的.
进一步增加样本容量为200和500的情况,感受样本平均值和总体平均值之间的差异,体会样本容量增大后抽样效果的反映.
R软件代码如下.
< # 增加绘制样本容量为200的情况
< p3 <- p2 +geom_point(mapping=aes(x=NO,y=X200次),size=3,shape=3,color="blue")+
< geom_line(aes(x=NO,y=X200次),color="blue")
< p3
< # 增加绘制样本容量为500的情况
< p4 <- p3 +geom_point(mapping=aes(x=NO,y=X500次),size=4,shape=4,color="purple")+
< geom_line(aes(x=NO,y=X500次),color="purple")
< p4
运行结果如图3所示,其中,“[+]”是样本容量为200的情况,“[×]”是样本容量为500的情况.
可以看出,与样本容量为10和100时的情况相比,样本容量为200和500时的样本均值与总体均值之间的偏差有所减小,表明当样本容量增大时能够更好地反映总体情况. 但从绝对偏差来看,样本容量为200和500之间的差异并不大. 因此,尽管样本容量增大能够更好地估计总体,但是考虑实际抽样过程中的人力、物力和时间成本等因素,样本容量为500并不一定是效益最好的样本容量选择方案. 故在实际的抽样中,需要结合具体问题的需要确定样本容量,而并非一定是越大越好. 在教学中教师要引导学生就此问题展开讨论,体会统计学研究方法的特殊性以及与现实情境的关联性.
为进一步观察不同样本容量下的抽样结果,可以绘制样本容量为100和500,以及200和500的折线比较图,如图4和图5所示,能更加清晰地反映它们之间的关系,也印证上文所得到的结论,即样本量并非越大越好,具体样本容量的选取需要考虑实际问题背景下的抽样效益.
折线图绘制R软件代码如下.
< # 比较100次与500次
< p1+geom_point(mapping=aes(x=NO,y=X100次))+
< ylim(160,170)+
< geom_line(aes(x=NO,y=X100次))+
< geom_point(mapping=aes(x=NO,y=X500次),size=2,shape=2,color="red")+
< geom_line(aes(x=NO,y=X500次),color="red")+
< geom_hline(yintercept=mean(Height),color="red",size=1)
< # 比较200次与500次
< p1+geom_point(mapping=aes(x=NO,y=X200次))+
< ylim(160,170)+
< geom_line(aes(x=NO,y=X200次))+
< geom_point(mapping=aes(x=NO,y=X500次),size=2,shape=2,color="red")+
< geom_line(aes(x=NO,y=X500次),color="red")+
< geom_hline(yintercept=mean(Height),color="red",size=1)
3. 有放回与无放回简单随机抽样之间的比较
简单随机抽样包括有放回和无放回两类,这两类之间是否存在差异,以及對抽样结果有怎样的影响是值得探讨和试验的问题. 由于学生在学习这部分内容时还不具备概率部分的必要知识,故通过设置试验3,对三组不同特征下的数据分别进行有放回和无放回的简单随机抽样,并作出折线图直观地观察它们之间的联系与区别,并为学生后期学习概率知识奠定基础.
与有放回简单随机抽样比较,不放回简单随机抽样效率更高,因此实践中人们更多采用无放回简单随机抽样. 有放回和无放回简单随机抽样,从抽样的结果来看,是否存在差异?通过下面三组不同数据特征下的试验,让学生直观感受它们之间的联系与区别,
试验3:不同数据分布情况下有放回与无放回简单随机抽样的比较.
(1)数据分布整齐(正态分布)情况下的比较.
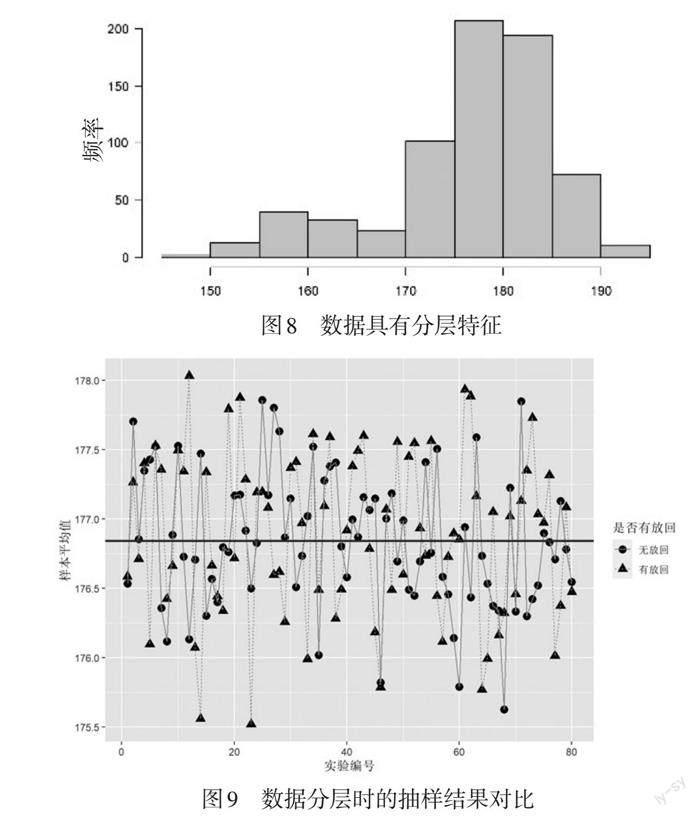
利用正态随机数函数rnorm(700,mean=177,sd=5)生成一个容量为700的总体. 这个总体数据基本服从正态分布,如图6所示. 在其中分别采用有放回和无放回的方式抽取100个样本,进行60次试验,绘制样本平均值和整体平均值的关系,如图7所示,观察它们之间的联系与区别.
R软件代码如下.
< # 比较无放回抽取和有放回抽取
< # 在数据比较规范的情况下
< Height2 <- rnorm(700,mean=177,sd=5)
< N <- 100 #设定抽取样本数,可调整
< M <- 60 #设定试验次数,可调整
< colnames <- c("试验次数","样本平均数","是否有放回")
< rownames <- c(1:(M*2))
< C <- matrix(nrow=M*2,ncol=3,dimnames = list(rownames, colnames))
< C[,] <- 0
< C[,1] <- (c(1:(M*2))-1)%%M+1
< for (i in c(1:M)) {
< C[i,2]<- mean(sample(Height2,N,replace=FALSE))
< C[i,3] <- "无放回"
< C[i+M,2]<- mean(sample(Height2,N,replace=TRUE))
< C[i+M,3] <- "有放回"
< }
< D <- data.frame(C)
< D$试验次数 <- as.numeric(D$试验次数)
< D$样本平均数 <- as.numeric(D$样本平均数)
< p1 <- ggplot(data=D,aes(x=试验次数,y=样本平均数,shape=是否有放回))
< p2 <- p1+geom_point(size=3)+
< geom_line(aes(color=是否有放回,linetype=是否有放回))+
< geom_hline(yintercept = mean(Height2),color="blue",size=1)
< p2
图7中分别表示无放回和有放回的情况. 由图7给出的60次试验结果来看,在700个数据服从正态分布的情况下,有放回与无放回简单随机抽样得到的样本均值偏离情况差距不大,样本均值与整体均值产生较大偏差的情况比较少. 但是由于数据具有随机性,在图中给出的60次试验中也存在出现较大偏差的情况. 例如,有放回抽取的第28次试验,出现了样本均值偏离整体均值大约1.5的情况.
(2)数据分层情况下的比较.
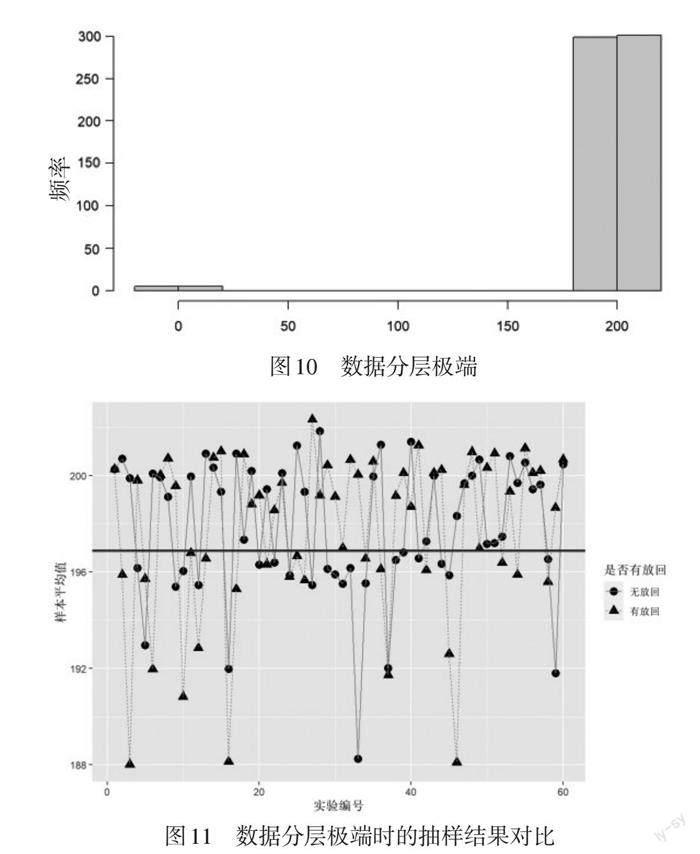
利用语句c(rnorm(600,mean=180,sd=5),rnorm(100,mean=160,sd=5))生成一个容量为700的整体,其中600个数据作为男生身高的模拟,基本服从均值为180、标准差为5的正态分布,另外100个数据作为女生身高的模拟,基本服从均值为160、标准差为5的正态分布,数据分布情况如图8所示. 可以看出,这组数据有比较明显的分层特征. 现从中分别无放回和有放回地抽取200个样本,进行80次试验,绘制样本平均值和整体平均值的折线图,输出结果见图9.
R软件代码如下.
< # 在数据不规范的情况下
< Height3 <- c(rnorm(600,mean=180,sd=5),rnorm(100,mean=160,sd=5))
< X1 <- c(1:600);C1[] <- "男"
< X2 <- c(1:100);C2[] <- "女"
< X3 <- c(C1,C2)
< H <- data.frame(Height3,X3)
< N <- 200 #設定抽取样本数,可调整
< M <- 60 #设定试验次数,可调整
< C <- matrix(nrow=M*2,ncol=3,dimnames = list(c(1:(M*2)),c("试验编号","样本平均值","是否有放回")))
< C[,] <- 0
< C[,1] <- (c(1:(M*2))-1)%%M+1
< for (i in c(1:M)) {
< C[i,2]<- mean(sample(H$Height3,N,replace=FALSE))
< C[i,3]<-"无放回"
< C[i+M,2]<-mean(sample(H$Height3,N,replace=TRUE))
< C[i+M,3] <- "有放回"
< }
< D <- data.frame(C)
< D$试验编号 <- as.numeric(D$试验编号)
< D$样本平均值 <- as.numeric(D$样本平均值)
< p1 <- ggplot(data=D,aes(x=试验编号,y=样本平均值,shape=是否有放回))
< p2 <- p1+geom_point(size=3)+
< geom_line(aes(colour=是否有放回,linetype=是否有放回))+
< geom_hline(yintercept = mean(H$Height3),color="blue",size=1)
< p2
图9中分别表示无放回和有放回的情况. 由图9可见,当700个数据具有分层特点的时候,样本均值与整体均值偏差的幅度明显大于没有分层的情况,尤其是在有放回抽取中发生偏离的情况更多,偏离的幅度也更大. 例如,第21次试验,样本均值偏离整体均值约为1.7. 在教学过程中,教师可以引导学生思考为什么会出现这种情况. 实际上,在有放回抽取的过程中,偏离的数据被重复抽取到的概率会更大. 为了验证这一想法,强化数据的分层特征再次进行试验,考察数据极端情况下无放回和有放回抽样间的差异.
(3)数据极端情况下的比较.
利用语句c(rnorm(600,mean=200,sd=5),rnorm(10,mean=0,sd=5))生成一个容量为610的整体,其中600个数据在200附近,10个数据在0附近,从中抽取50个样本,进行60次试验,得到如图10所示的数据分布情况.R软件代码可以参照前面的试验稍作修改即可,这里不再赘述. 生成的折线图如图11所示,可以看出出现样本均值与总体均值(196.89)的偏差幅度很大的情况较多,而且偏离数值很大. 在这60次试验中,样本平均值小于192的,无放回出现3次,有放回出现6次,其中小于185的,无放回出现1次,有放回出现3次.
从上述三组不同数据分布特征情况下的抽样试验中可以看出,当数据分层情况非常明显的时候,简单随机抽样得到的样本代表性减弱,有放回的抽取更容易产生较大偏差. 由此可见,面对具有分层特征的数据采用简单随机抽样的方法来估计总体特征是不够准确的,因此需要对抽样方法进行改进,这一改进方法即分层随机抽样.
在教学中要注重引导学生基于所生成的折线图得到试验结论并加以讨论,分析不同数据情况下进行抽样的差异,尝试对抽样方法进行改进,探寻最适合数据特征的抽样方法,在此过程中培养学生能够批判性地理解知识的高阶思维.
4. 分层随机抽样与简单随机抽样之间的比较
为了探究数据出现分层情况时分层随机抽样和简单随机抽样何种抽样效果更优,以及效果差异是否明显的问题,安排试验4,开展不同数据情况下分层随机抽样与简单随机抽样间的对比.
试验4:不同数据分层情况下分层随机抽样和简单随机抽样的比较.
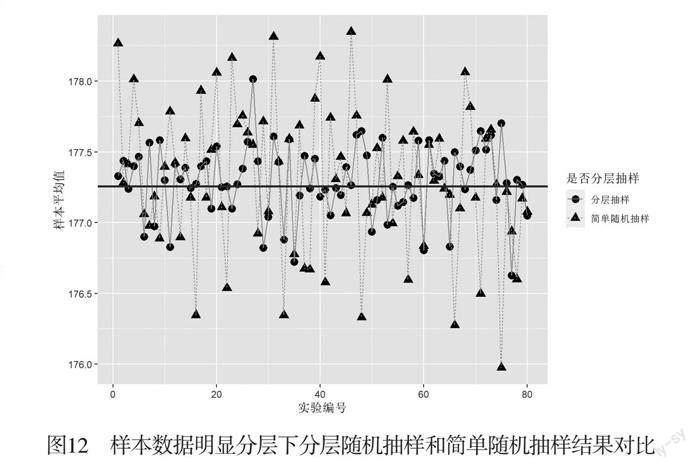
当样本出现比较明显的分层情况. 例如,前面例子中模拟的700个学生身高的数据,其中600个男生的身高数据基本服从均值为180、标准差为5的正态分布,另外100个女生的身高数据基本服从均值为160、标准差为5的正态分布. 对该数据分别进行简单随机抽样和分层随机抽样,并绘制样本均值和总体均值差异的折线图,如图12所示.
R软件代码如下.
< # 分层随机抽样
< # Height3 组的分层试验
< Height3 <- c(rnorm(600,mean=180,sd=5),rnorm(100,mean=160,sd=5))
< X1 <- c(1:600);X1[] <- "男"
< X2 <- c(1:100);X2[] <- "女"
< X3 <- c(X1,X2)
< H <- data.frame(Height3,X3)
< N <- 210 #設定抽取样本数,可调整
< M <- 80 #设定试验次数,可调整
< C <- matrix(nrow=M*2,ncol=3,dimnames= list(c(1:(M*2)),c("试验编号","样本平均值","是否分层随机抽样")))
< C[,] <- 0
< C[,1] <- (c(1:(M*2))-1)%%M+1
< for (i in c(1:M)) {
< C[i,2]<- mean(sample(H$Height3,N,replace=FALSE))
< C[i,3] <- "简单随机抽样"
< C[i+M,2]<- mean(c(sample(H$Height3[1:600],N*6/7,replace=FALSE),sample(H$Height3[601:700],N*1/7,replace = FALSE)))
< C[i+M,3] <- "分层随机抽样"
< }
< C1 <- data.frame(C)
< C1$试验编号 <- as.numeric(C1$试验编号)
< C1$样本平均值 <- as.numeric(C1$样本平均值)
< p1 <- ggplot(data=C1,aes(x=试验编号,y=样本平均值,shape=是否分层随机抽样))
< p2 <- p1+geom_point(size=3)+
< geom_line(aes(colour=是否分层随机抽样,linetype=是否分层随机抽样))+
< geom_hline(yintercept = mean(H$Height3),color="blue",size=1)
< p2
图12中分别表示了分层随机抽样和简单随机抽样的情况. 可见,在分层随机抽样的情况下,样本均值较稳定地围绕总体均值波动,相对于简单随机抽样,其波动情况明显较小.换言之,在这种数据情况下,分层随机抽样明显优于简单随机抽样.
当数据分层情况更加明显,如试验3“数据极端”情况的例子中,通过简单随机抽样和分层随机抽样得到的均值围绕总体的波动情况如图13所示,可以看出在这种情况下,简单随机抽样得到的样本均值偏离整体均值的幅度很大.
当分层的样本容量相当的时候,如男生和女生各有350人,其中男生身高均值约为170,标准差约为5,女生身高均值约为160,标准差约为5,该情况下采用简单随机抽样和分层随机抽样的试验结果如图14所示. 从试验结果可以看出,当分层容量相当的时候,采用简单随机抽样和分层随机抽样,所得样本均值差异并不明显,分层随机抽样略好于简单随机抽样.
通过以上三种不同数据分布情况下对分层随机抽样和简单随机抽样结果的对比,可以引导学生得出结论:分层情况明显且样本量相差很大的时候,分层随机抽样要明显优越于简单随机抽样.
三、反思与总结
1. 数据分析素养需要在学生的亲身经历中发展
数据分析素养的形成与发展离不开学生亲身参与统计过程、积累统计活动的基本活动经验. 整个统计活动教学的展开与推进应该是以学生对实际问题的分析为出发点,以学生对解决路径探索引发的思考为推动,并以学生得出的判断加以验证,让学生经历猜想、实践、观察、分析,并得出结论的过程.
探究活动围绕高一学生平均身高这一问题情境,开展了一系列抽样试验. 由简单随机抽样出发,初步掌握借助统计软件进行简单随机抽样的基本方法,关注所抽取的样本均值的情况. 在抽样过程中样本容量的选取是学生产生的第一个困惑点,由此开展试验2分析不同样本容量下样本均值的表现. 简单随机抽样包括放回与不放回两种形式,故两种抽取方式会对抽样结果产生何种影响是学生很自然所产生的困惑. 故在试验3中设置三组不同特征的数据来探究放回与不放回抽样之间的差异. 对于后两组数据表现出的分层特征,对分层数据选择简单随机抽样和分层随机抽样哪个能更好地反映总体特征、各自效果如何等疑惑展开对比分析. 整个教学过程以学生的思考探究为驱动力,步步深入,层层展开,引导学生经历基于数据分析、讨论、改进最终得到试验结论的过程,培养学生基于数据思考问题的习惯,提升学生基于数据解决现实问题的能力,是学生数据分析素养生成与提升的必要路径.
2. 统计思维需要在学生的批判验证中提升
统计方法的选择是基于实际问题的需求和数据特征所做出的更优方案. 在统计教学中也需要引导学生针对不同分布情况下的总体数据,比较不同抽样方法下的结果表现,分析不同方法的优劣和适用特征,从而批判性地做出更佳的统计分析方案. 例如,在对样本容量的讨论中得出结论:当样本容量增加时,样本均值能够更好地反映总体均值情况,但当样本容量增加到一定数值之后,再扩大样本容量引起的影响并不大,故从抽样效益角度出发,样本容量的选取并非越大越好. 在实际的抽样调查中也会受到人力、费用、时间等成本的影响,故在调查中要根据实际问题的需要,选择恰当的样本容量进行抽样. 在学生探究、讨论、分析并得到结论的过程中,既可以体会利用样本估计总体的思想方法,也能在比较与分析中实现批判思维等高阶思维的发展.
3. 科学素养需要在信息技术的教学应用中生成
科学素养是信息时代对学生提出的新要求,关注学生利用所学的科学知识并将其应用于生活情境的能力. 研究表明,在教学中应用信息技术能够促进学生科学素养的发展. 而在统计教学的过程中离不开信息技术的支持,其中R软件作为重要的统计软件,能够模拟完成大量随机试验并计算得到数据结果,便于学生观察样本与总体之间的关联,提高统计活动开展效率,在统计教学中发挥着重要作用. 故在此次教学活动实践中以R软件作为重要的技术支持贯穿整个教学过程. 师生借助R软件实现数据的分析处理,在引导学生掌握软件使用方法的同时,以可视化的呈现方式生成图象,便于学生观察不同情况下的抽样结果,分析样本与总体之间的关联,讨论选取更优的抽样方案,培养学生达成统计教学目标,培养学生的数据意识. 在提高统计教学质量的同时,学生的科学素养也在探究和应用过程中生成和提高.
参考文献:
[1]中华人民共和国教育部. 普通高中数学课程标準(2017年版2020年修订)[M]. 北京:人民教育出版社,2020.
[2]陈建明,孙小军,杨博谛. 数据分析素养的评价框架与实施路径研究[J]. 数学教育学报,2022,31(2):8-12,57.
[3]史宁中. 数形结合与数学模型:高中数学教学中的核心问题[M]. 北京:高等教育出版社,2018.
[4]程海奎,章建跃. 经历系统的数据处理过程 在解决实际问题中发展数据分析素养[J]. 数学通报,2021,60(4):1-6,14.
[5]高雪松,郭方奇,欧阳亚亚. 基于核心素养的高中统计教学研究[J]. 中国数学教育(高中版),2019(6):17-20.
[6]阳志长. 充分运用教材资源,致力培养数据分析核心素养[J]. 中国数学教育(高中版),2017(3):19-22.
[7]王春丽,顾小清. 中学生信息技术使用及其对科学素养的影响:基于PISA数据的中芬比较研究[J]. 中国远程教育,2019(5):47-56,93.
[8]张广民,康玥,任倩. 将GeoGebra软件融入概率教学体现新课程理念:以“频率与概率”单元为例[J]. 中国数学教育(高中版),2021(1 / 2):83-90.
