基于线段投影的ADMM-LP译码算法硬件实现
2023-04-10张俊伟郑昱津刘惠阳夏巧桥
张俊伟, 郑昱津, 刘惠阳, 夏巧桥*
(1.华中师范大学物理科学与技术学院, 武汉 430079; 2.武汉大学计算机学院, 武汉 430072)
低密度奇偶校验(low density parity check, LDPC)码[1]有纠错能力强、结构简单、错误平台低、便于硬件实现等优点,因此被广泛地应用于光纤通信、5G通信以及卫星通信等领域[2-4]。研究者针对LDPC码提出了各种译码算法,当前应用最广泛的为BP译码算法,且一直是当前硬件实现的重点[5]。但该算法在高性噪比下存在错误平台问题。Barman等[6]提出了一种基于交替方向乘子法(alternating direction method of multipliers,ADMM)的线性规划(linear programming,LP)译码算法,该算法可有效解决错误平台问题,且与传统LP译码算法相比,有效地降低了算法的复杂度,并具有最大似然特性。在此基础上,研究者针对ADMM译码算法提出了各种改进算法[7]。
硬件实现是ADMM译码算法落地于实际的关键,而硬件实现的难点在于其中涉及的奇偶校验多胞体投影算法[8]。Barman等[6]对此提出了求解欧几里得投影的“two-slice”法。但是,“two-slice”法涉及排序和反排序操作,复杂度较高。对此,Zhang等[9]提出了一种割查找(cut search algorithm, CSA)算法,CSA算法与原始投影算法相比,拥有更低的复杂度,但仍然涉及排序操作。Zhang等[10]提出在奇偶多面体上的投影可以转化为在单纯形上的投影,但单纯形投影方法仍然涉及部分排序操作。Wasson等[11]提出在奇偶多胞体和概率单纯形上投影的硬件实现,并在现场可编程逻辑门阵列(field programmable logic gate array,FPGA)平台上实现了ADMM译码器[12]。但以上投影算法都是精确投影,复杂度较高,降低了ADMM-LP译码器的吞吐率,增加了硬件资源的消耗。Jiao等[13]提出了一种基于查找表(look up table,LUT)的投影方法,进一步简化了投影算法。Samhan[14]在Wasson的ADMM-LP译码器的基础上结合LUT投影方法做了进一步改进,在FPGA上实现了约50%的位宽缩减。最近,Xia等[15]提出了一种不需要排序和迭代操作的线段投影算法(line segment projection algorithm,LSA),并在此算法的基础上进行了改进研究[16-18]。LSA是一种近似投影,复杂度低,且比CSA更节省投影时间。
结合LSA的硬件友好特性,现开展ADMM-LP译码算法的硬件实现研究。首先针对硬件实现对线段投影算法进行简化,并设计完整的ADMM译码硬件实现方案,最后在FPGA上搭建完整的译码测试平台。本文所实现的译码器使得译码速率更高,且译码器的资源消耗更低,得以更好地应用于实际。
1 改进的ADMM-LP译码算法
1.1 ADMM-LP译码算法
对于一个m×n阶的校验矩阵H,其行下标索引可用J={1,2,…,m}表示,其列下标索引可用I={1,2,…,n}表示。vi表示第i个变量节点,cj表示第j个校验节点。与vi关联的校验节点用Nv(i)表示,与cj关联的变量节点用Nc(j)表示。dcj=|Nc(j)|和dvi=|Nv(i)|则分别表示校验节点的度以及变量节点的度。
ADMM-LP译码的基本模型为
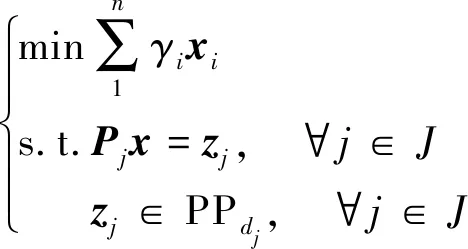
(1)
式(1)中:x为待求解的发送码字;γi为对数似然比;Pj为选择矩阵;zj为校验节点cj对应的辅助变量;PPdj为第j个校验节点对应的校验多胞体。增广拉格朗日函数为
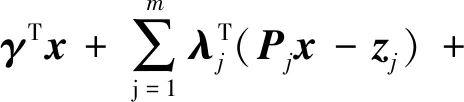
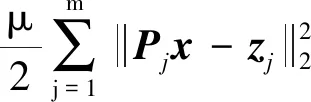
(2)
式(2)中:λ为对偶变量或拉格朗日乘子;μ为惩罚系数且为正数。式(2)可以通过式(3)迭代求解。
xk+1=argminLμ(x,zk,λk)
(3)
zk+1=argminLμ(xk+1,z,λk)
(4)
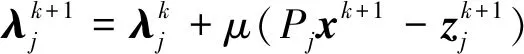
(5)
在对式(3)中xk+1求解时,将zk和λk当作常量,并对x求偏导,由式(6)表示。
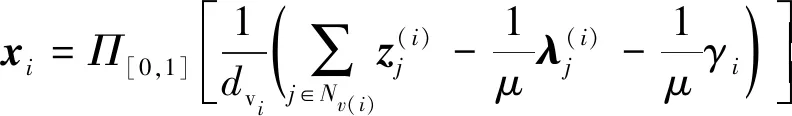
(6)
式(6)中:Π[0,1]为在区间[0,1]上的投影。同理,在更新z时,将x和λ看作常数,对z求偏导,得到zj的解为
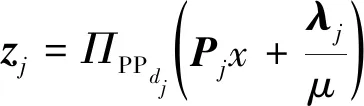
(7)
式(7)中:ΠPPdj为在校验多胞体PPdj上做欧几里得投影操作,此操作是ADMM-LP译码算法中最复杂的部分,也是本文的研究重点所在。
1.2 改进的ADMM-LP算法
改进的ADMM-LP算法合并了原始ADMM-LP算法中的部分参数,使得消息传递变量更简洁。具体地,本文研究将常量μ从变量λj和zj的计算中移除,降低无关变量的迭代传递计算。此外,针对硬件实现中,定点计算可能出现的不对称性,可以将ADMM译码算法改为中心对称的译码模型,即
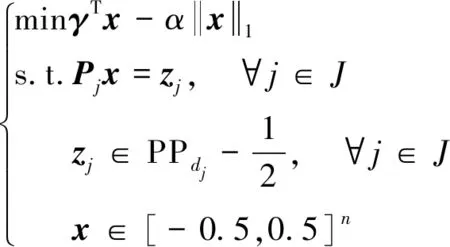
(8)
与原始ADMM译码模型不同的是,超立方体由[0,1]n变换到了[-0.5,0.5]n,通过简单的加减法计算就能将原始的非对称模型变化为中心对称模型。改进后的基于中心对称的ADMM-LP译码算法的具体流程如算法1所示。

算法1 改进的ADMM-LP 译码算法输入:信道接收到的对数似然比(LLR)向量γ∈Rn输出:译码结果x∈[-0.5,0.5]n1:for ∀j∈J,do2: λj←0 //对参数λj进行初始化3: for ∀i∈I, do4: mj→i←0 //对mj→i做初始化5: end for6:end for 7:repeat8: for ∀i∈I,do //变量节点更新9: ti=1TmNv(i)←i-γi10: si=ti+α, 如果ti≥0ti-α, 如果ti<0{11: xi=Π-12,12[]siNv(i) //变量节点的计算12: end for13: for ∀j∈J, do //校验节点更新14: vj=xNc(j)+λj15: zj=ΠPP|Nc(j)|-12(vj) //对zj进行投影计算16: λj=vj-zj //参数λj的更新17: mj→Nc(j)=2zj-vj //校验节点计算18:end for19:直到达到最大迭代次数
1.3 简化的LSA算法
投影算法是ADMM-LP译码算法中最复杂且最耗时的部分,为了使ADMM译码算法在硬件上更容易实现,寻求一种简单的投影算法至关重要。LSA算法是一种近似投影算法,原始的LSA算法需要判断待投影向量是否在超立方体上,如果待投影向量在超立方体上,则此待投影向量为投影结果,此过程为精确投影。反之,若待投影向量不在超立方体上,则需进行近似投影操作。为消除分支在硬件实现中对流水线的影响,本文去除超立方体投影判断该步骤,将统一采用近似投影作为投影结果,实验结果表明,该简化操作对译码器性能并无明显影响。
为使LSA算法硬件实现更为简便,本文将原始LSA算法中的可合并变量进行合并,进一步简化了算法流程以及变量的传递。简化后的LSA算法如算法2所示。其中,βv表示待投影向量v的二值化向量,它是将指示向量与奇数顶点向量合并后的变量。相较于传统的LSA算法,简化后的中心对称LSA算法的步骤1、步骤3和步骤6中的比较阈值

算法2 简化的中心对称LSA算法输入:待投影向量v′∈Rdj1:βv,i=1, v′i>00, v′i≤0{2:if 集合{i|βv,i=1}的元素个数为偶数3: i∗=argmaxi||v′i-0||4: βv,i∗=1-βv,i∗5: end if6: 位置索引a=argmini(|v′i-0|),位置索引b=argmini≠a(|v′i-0|)7:偶数顶点:A=βv,i, 如果 i≠a1-βv,i, 如果 i=a{,偶数顶点:B=βv,i, 如果 i≠b1-βv,i, 如果 i=b{8:输出:投影向量s=ΠAB(v′)9:return s
由原始的0.5变为0,中心对称可消除硬件实现中定点数计算带来的不利影响。然后对索引a和b位置上的元素进行翻转得到其相对应的偶数顶点A和B。最后,计算待投影向量v在线段AB上的投影s=ΠAB(v′)。
2 ADMM-LP译码算法的硬件实现
2.1 译码器总体框架
在ADMM-LP译码器进行译码过程中,首先输入对数似然比(likelihood rate,LLR)向量数据,将数据写入输入缓存中,变量节点计算模块从输入缓存中读取数据并进行计算。若译码未通过且迭代次数未达到最大值,则将变量节点信息通过变量节点信息缓存(VN-To-CN)传递到校验节点计算模块进行计算。校验节点计算完毕后将计算结果写入到校验节点信息缓存(CN-To-VN),中间变量写入校验节点变量缓存供下次迭代使用。信息在变量节点计算模块与校验节点计算模块之间来回迭代,在译码成功或达到最大迭代次数之后将译码结果输出。
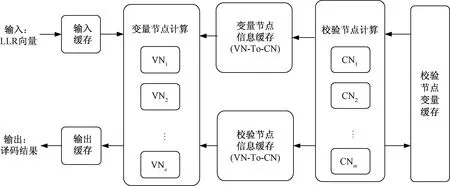
图1 硬件结构框图Fig.1 Block diagram of hardware structure
2.2 并行度设计
采用准循环低密度奇偶校验(QC-LDPC)码作为实验码字,由于QC-LDPC码特殊的矩阵结构,在硬件实现中,可以通过移位寄存器来完成存储和寻址,从而降低了硬件译码器的部署难度。
本次实验采用c1(155,64)码字进行实验,该码字是一个校验节点度为5,变量节点度为3的码字,该码字的校验矩阵可以由5×3个31×31的单位矩阵的循环位移矩阵组成。从译码效率的角度考虑,可以实例化5个VN模块和3个CN模块并行计算。
在本实验中,所有的数据存储模块都将使用RAM模块实现。具体地,结合本实验所使用的QC-LDPC码字,输入缓存采用5个深度为31的RAM存储。但由于VN模块和CN模块之间串行工作,在VN-To-CN模块和CN-To-VN模块之间只需2个深度为31的RAM来进行数据交互。
2.3 变量节点计算模块
变量节点计算模块主要完成1.2节中算法1的变量节点的更新计算部分。首先对所有校验节点传递给变量节点的信息求和,并减去LLR向量γ。然后对ti的值进行判断,若ti>0则加上惩罚系数α,反之则减去惩罚系数α。算法1中步骤11用步骤10的计算结果除以变量节点的度,最后将结果投影到区间[-0.5,0.5]。VN模块硬件结构图如图2所示。
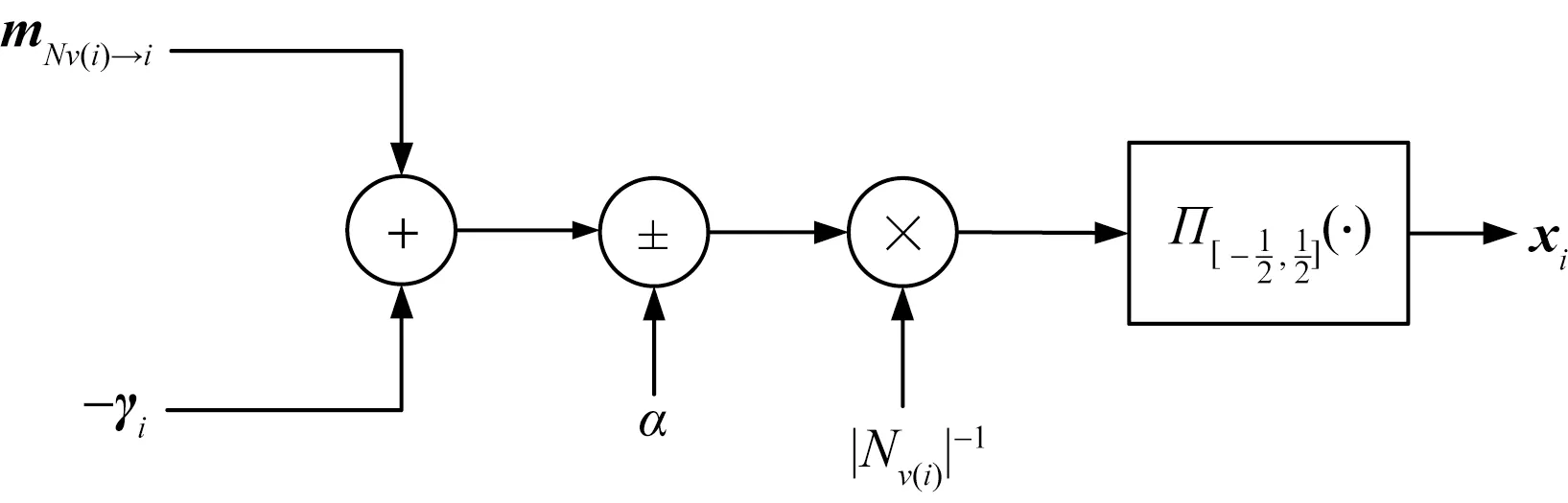
图2 VN模块硬件结构图Fig.2 Hardware structure diagram of VN module
变量节点计算模块经过Vivado HLS生成的模块IP如图3所示。

图3 变量节点计算模块IPFig.3 Compute module IP of variable node
度为3的变量节点计算模块生成的intellectual property IP包含时钟接口ap_clk、复位接口ap_rst、控制接口ap_ctrl、LLR向量输入接口llr_V_V、惩罚系数输入接口p_V_V、三个变量节点输入datain_V_V以及一个输出数据dataout_V_V。变量节点计算模块采用1个时钟周期间隔的流水线设计,每次并行的输入LLR向量、惩罚系数以及3个输入数据,经过6个时钟周期的计算,输出结果数据。
为了对装配式建筑工程施工在进行招标评标时出现的各种问题加以解决,可以采取两段式评标方法来对工程项目进行招标评标工作。实际操作时,在第一阶段主要评审资质标和技术标,并以第一阶段的评审结果为基础确定具备进入商务标的第二阶段评审的资格。同时可以根据招标方的实际需要,对两个阶段的评标得分权重进行适当的调整,并计算出最终的评标结果,确定中标单位。
2.4 校验节点计算模块
校验节点计算模块主要完成1.2节算法1中的校验节点更新计算部分,根据算法结构,校验节点计算模块由3个向量加法运算以及投影模块组成。如图4所示,首先,从变量节点计算模块传来的数据与参数λj求和,然后经过投影模块进行计算,将计算结果mj→Nc(j)传递给变量节点计算模块,并将计算后的中间变量λj存入校验节点变量缓存,供下一次校验节点计算时使用。
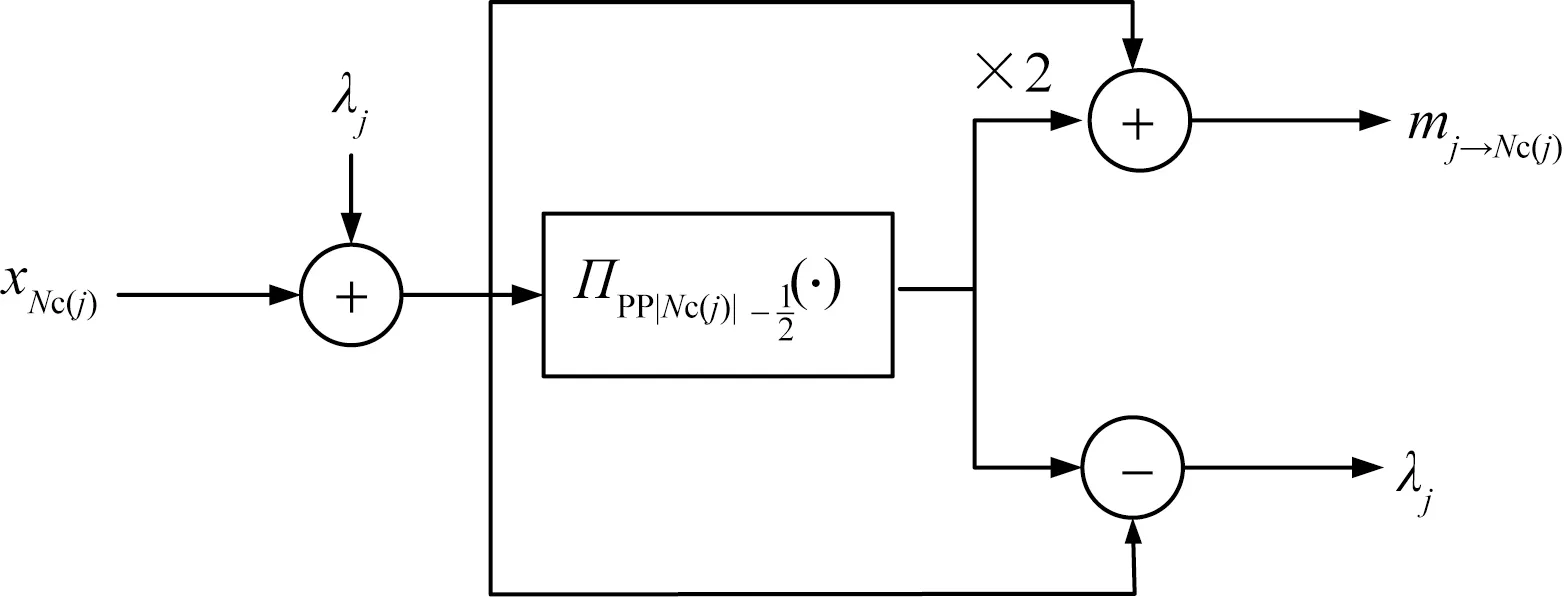
图4 CN模块硬件结构图Fig.4 Hardware structure diagram of CN module
其中,投影模块是校验节点计算模块中最复杂的算法模块,也是本实验实现过程的关键所在,将采用1.3节提出的算法2。
基于前述LSA算法给出对应的硬件实现框图如图5所示,首先对待投影向量v进行二值化操作,使其大于等于0时为1,小于0时为0。然后对向量βv进行奇偶判断,若元素为偶数个,则对距离中心点“0”最近的元素取反,反之则无需取反。接下来将距离中心点“0”最近的两个索引取反,得到A、B两个偶数顶点,最后,在线段AB上进行投影操作。
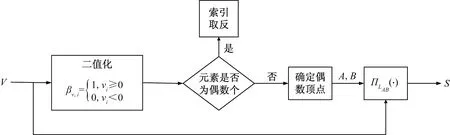
图5 LSA模块硬件结构图Fig.5 Hardware structure diagram of LSA module
整个校验节点模块需要58个时钟周期完成,其中数据流水输入输出需要31个时钟周期,投影模块需要13个时钟周期,校验节点计算需要10个时钟周期以及4个时钟周期的时钟同步。校验节点计算模块虽然是整个译码器中最耗时的模块,但由于其并行的流水线结构和简单的投影算法,相较于其他ADMM-LP硬件译码器而言,仍然具有优势。
2.5 定点位宽设计
在投影模块计算过程中涉及较多定点数的计算,而定点数的位宽将影响译码的精度以及资源的占用。因此,为达到译码准确度与资源占用之间的最佳平衡,本文研究需选取合适的定点量化方案,采用Q(S,I,D)来表示,其中,S、I、D分别为符号位、整数位宽和小数位宽。例如,Q(1,2,3)表示符号位为1位,整数部分位宽为2,小数部分位宽为3。
为达到译码速度与资源的平衡,结合文献[11]给出各模块的量化方案,具体量化方案如表1所示。
其中,变量节点计算模块VN中的LLR向量输入采用Q(1,0,7)的量化方案,即1位符号位,7位小数位,校验节点传递给变量节点信息CN-To-VN采用Q(1,3,7)的量化方案。VN模块输出数据,即变量节点传递给校验节点信息VN-To-CN的数据采用Q(1,0,10)的量化方案。校验节点计算模块CN的中间数据以及输出数据均采用Q(1,3,7)的量化方案。最后LSA模块的输入量化方案为Q(1,4,10),输出数据量化方案为Q(1,0,14)。

表1 ADMM-LSA各个模块量化方案
3 实验结果
为了能够验证译码器的译码性能,在 FPGA 平台中搭建了完整的测试平台。本文的ADMM-LP译码器采用改进后的ADMM-LP译码算法,投影算法采用基于中心对称的LSA 算法,信道选取AWGN(additive white gaussian noise)信道,并采用BPSK调制。实验平台为Xilinx 公司的型号为ZCU102评估板。软件则采用Xilinx 公司的Vivado、Vivado HLS等工具。实验使用HLS生成测试码流的IP,其他部分使用Vivado进行开发。测试平台上的测试过程如图6所示。
如图6所示,数据c经过BPSK(binary phase shift keying)调制,然后经过高斯白噪声并求出对数似然比,经过双缓存后,ADMM-LP译码器对γ进行译码,译码结果x经过校验模块与数据c进行对比校验,若译码失败,则统计错误码字个数,最后求得误码率。
译码器整个流程可以简单地用图7所示状态机进行调度。ADMM-LP译码器的状态机主要设计了4种状态来完成调度,数据载入完成后进行变量节点的计算,在变量节点计算完毕后进入校验节点计算的状态,然后进行判决和信息的来回迭代,直到满足译码成功条件或达到最大迭代次数之后,进入状态3,译码完成。
图8展示了ADMM-LP译码器的时序仿真图。其中最大错误帧ERROR_FRAME_MAX设置为100,信噪比(signal noise ratio,SNR)设置为3 db,最大迭代次数MAX_ITER设置为64,状态机decoderState包含4种状态,状态0表示载入数据,状态1表示变量节点的计算,状态2表示校验节点的计算,状态3表示译码完成状态。如图8所示,状态机在数据载入后,在状态1和状态2之间反复迭代计算。即消息在变量节点和校验节点之间来回迭代计算,直到译码通过或迭代次数达到最大值,状态机进入状态3译码完成。若未成功译出该帧数据,则错误帧error_frame_cnt数值加1,直到达到最大错误帧100,完成数据统计,求出在该信噪比下,该码字的误码率。
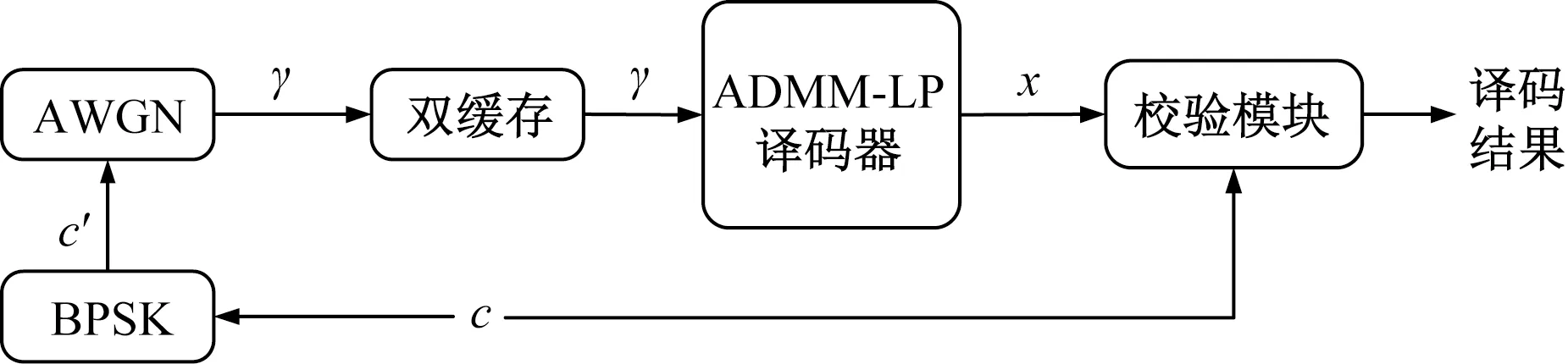
图6 ADMM-LP译码器测试平台Fig.6 Test platform for ADMM-LP decoder
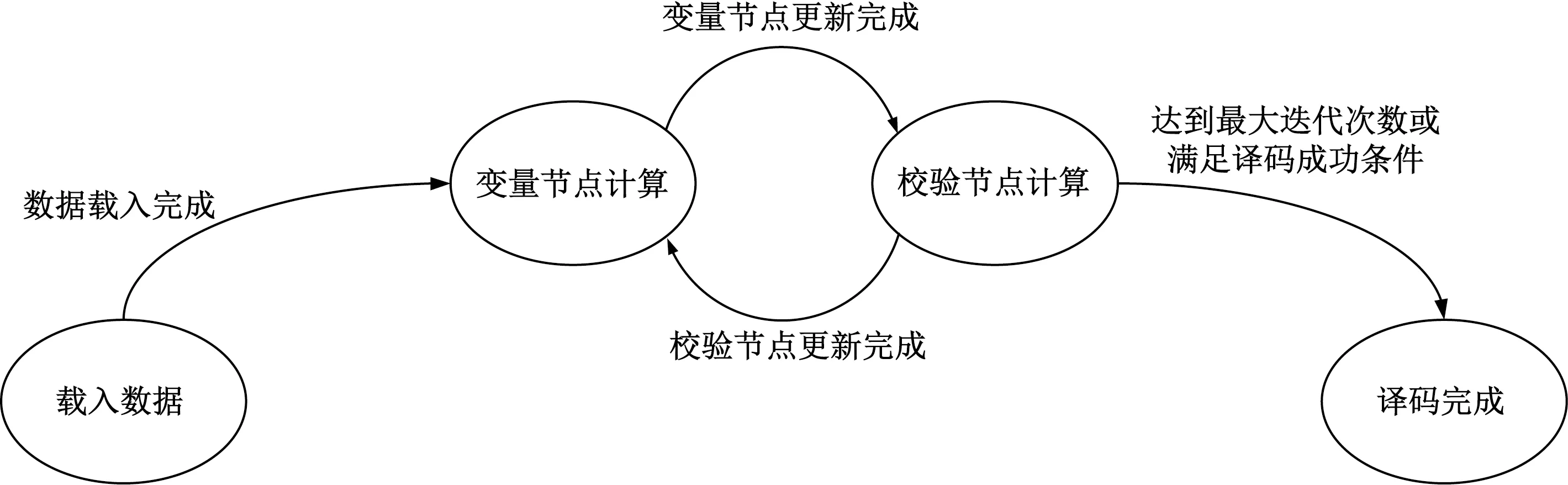
图7 ADMM-LP译码器状态机Fig.7 State machine of ADMM-LP decoder
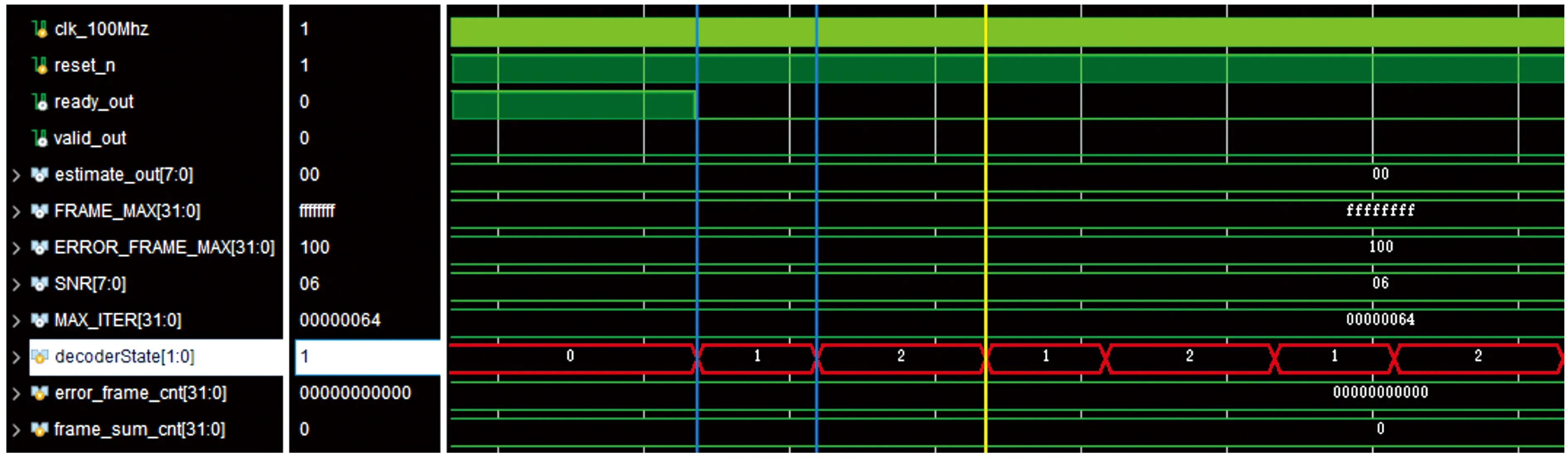
图8 ADMM-LP译码器时序仿真图Fig.8 Timing simulation diagram of ADMM-LP decoder
译码器的整体时序仿真后,在硬件平台上进行译码器的性能测试。针对在不同信噪比下,迭代次数对译码性能的影响情况,进行了相关实验对此进行验证。
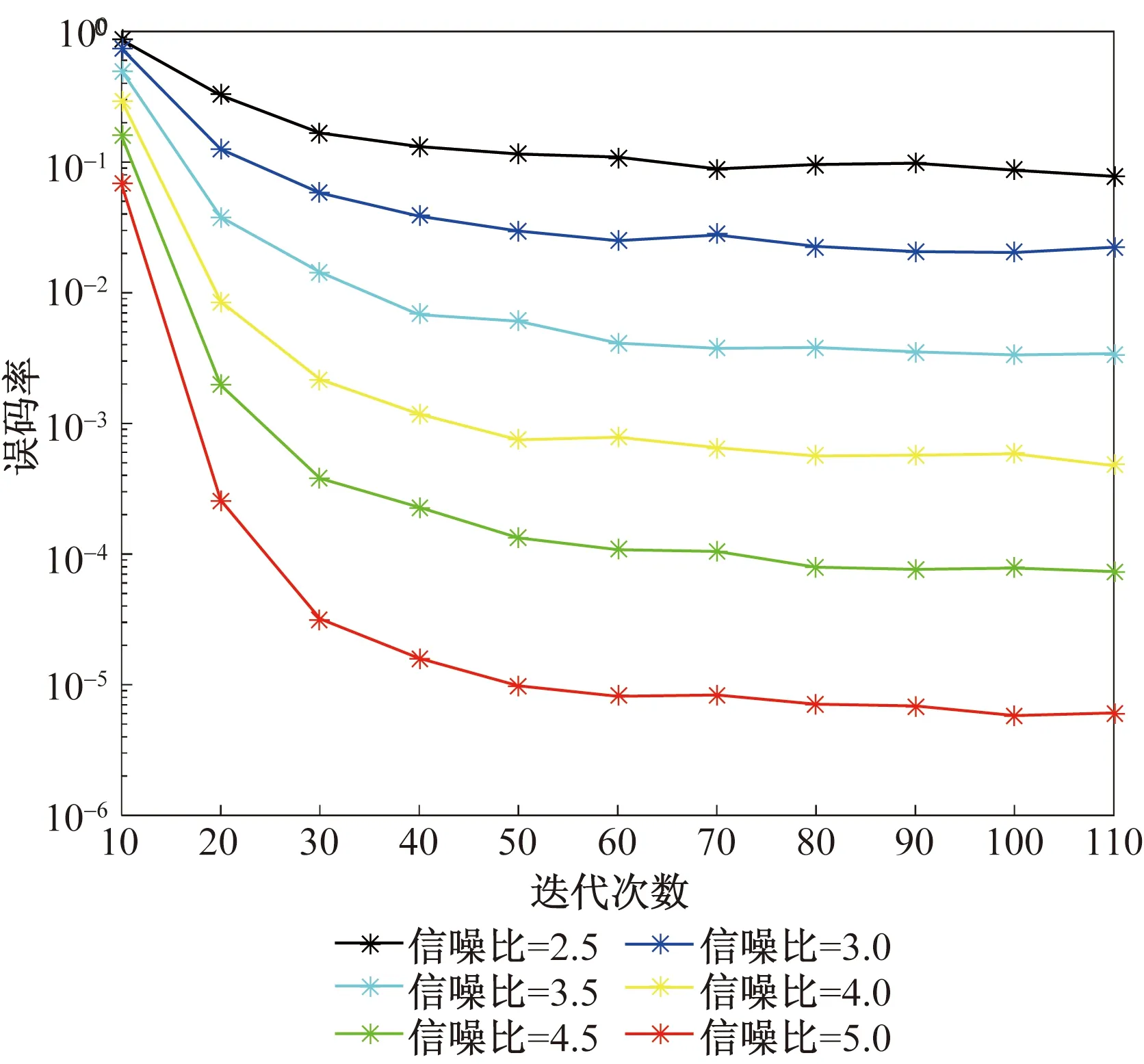
图9 不同迭代次数的误码率Fig.9 Frame error rate for different iterations
图9展示了在不同迭代次数下,各信噪比的误码率,由实验数据可以得出,迭代次数的增加,使得各信噪比下的误码率不断降低,但在迭代次数为64以后,迭代次数对译码性能影响很小,误码率不再明显降低。因此,将选取64次迭代来达到资源与性能的最佳平衡。
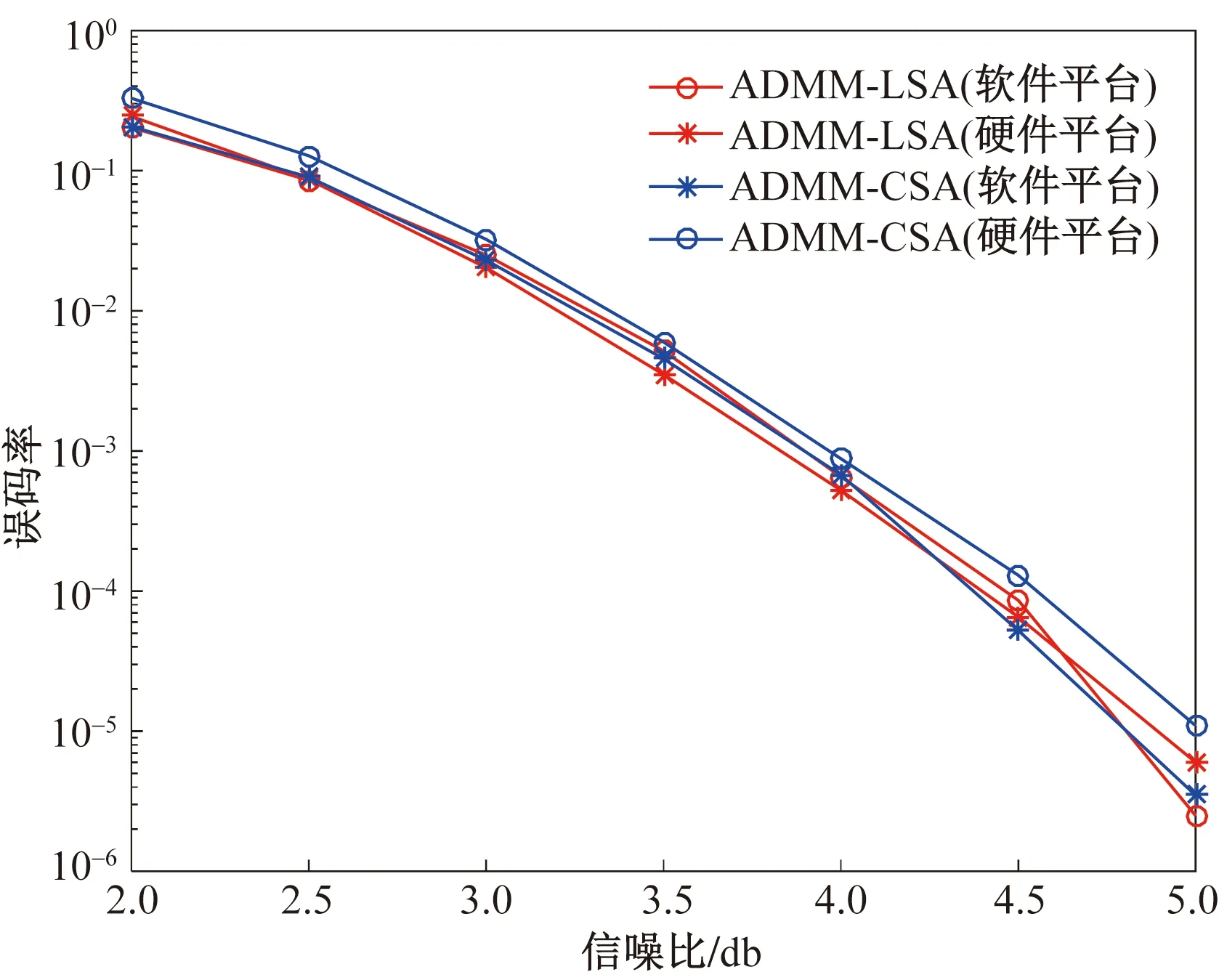
图10 ADMM-LSA译码器与ADMM-CSA译码器译码性能对比Fig.10 Comparison of decoding performance between ADMM-LSA decoder and ADMM-CSA decoder
图10展示了在硬件平台FPGA以及软件平台下的译码器性能比较,并将本文提出的ADMM-LSA译码器性能与Wasson等[11]提出的ADMM-CSA译码器进行比较。从图10中可以看出,在相同定点量化位宽条件下,本次实验的ADMM-LSA译码器在硬件平台与软件平台的译码性能基本一致,且与ADMM-CSA译码器性能相差无几。但本文实现的ADMM-LSA译码器的译码效率更高,且在译码器资源占用方面,有较大提高。
表2展示了本文提出的ADMM-LSA译码器与已有的ADMM-CSA译码器的译码效率以及资源消耗情况。
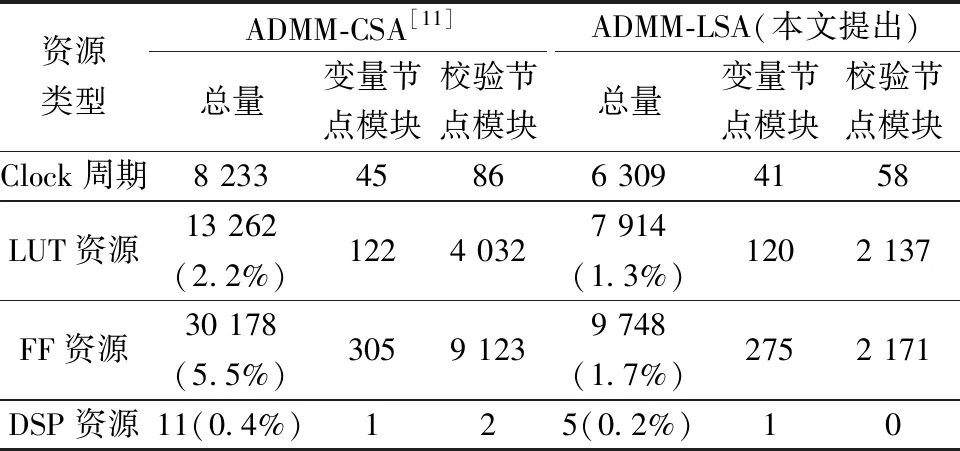
表2 ADMM-LP译码器资源占用情况对比
从计算效率情况来看,在250 M时钟下,相较于ADMM-CSA译码器,本文提出的ADMM-LSA译码器,无论变量节点模块还是校验节点模块的计算效率都有所提升,但由于本文所提出的改进投影算法计算复杂度大大降低,校验节点模块的计算效率提高显著,资源占用情况大幅下降。整体而言,本文提出的译码器译码速率相较已有方法的4.7 Mbps提升至6.14 Mbps,提升了30%以上。而查找表(LUT)资源占用量由13 262降为7 914,触发器(FF)资源占用量由30 178降为9 748,而DSP资源由11降为5。
4 结论
在ADMM-LSA算法的基础上,进行了一系列算法优化,使其利于在硬件平台上实现,并给出了对应的硬件实现方案,在FPGA上成功搭建实验平台。实验结果表明:相较于ADMM-CSA译码器,本实验所实现的ADMM-LSA译码器在译码性能上与之相当,但在译码效率与资源消耗上改善显著。具体地,译码速率提升了约30.6%,LUT资源占用减少了40.3%,FF资源占用减少了约67.6%,DSP资源占用减少了约54.5%。
