一种面向中医文本的实体关系深度学习联合抽取方法
2023-04-07杨延云杜建强罗计根
杨延云 杜建强 聂 斌 罗计根 贺 佳
(江西中医药大学计算机学院 江西 南昌 330004)
0 引 言
为推进国家中医药信息化的发展,各种中医药信息化平台的建设接踵而至,例如,中医辅助诊疗系统、中医智能问答系统、中医电子病历系统等。中医文献作为中医传承载体,记录了证型、方剂、中药、病因、病机和治则治法等数据,且存在着大量实体重叠的问题。而实体和关系抽取作为底层最基础的任务,能够快速地从半结构化、非结构化的中医文本中提取出实体以及它们之间的语义关系,对中医文献数据的有效利用和中医药的信息化研究具有促进作用和重要意义。
1 相关研究
1.1 流水线方法研究
实体关系抽取作为信息抽取的重要子任务[1],处理该任务的方法主要可以分为流水线方法和实体关系联合抽取方法两类。流水线方法即将实体关系抽取任务分为命名实体识别[2](Named Entity Recognition,NER)和关系抽取[3](Relation Extraction,RE)两个子任务,即给定一段半结构化或非结构化文本,首先通过命名实体识别提取出文本中的实体,然后对每个候选实体对进行关系分类。
典型的命名实体识别方法主要分为三类:基于规则的方法;基于统计学习的方法和基于深度学习的方法。其中,基于规则的方法大多是利用语言学知识,通过语言规则识别实体;基于统计学习的方法主要有隐马尔可夫模型(Hidden Markov Models,HMM)[4]、最大熵模型(Maximum Entropy Model,MEM)、支持向量机(Support Vector Machine,SVM)[5]和条件随机场[6]等,该方法依赖复杂的特征工程。近几年,循环神经网络(Recurrent Neural Networks,RNN)、长短期记忆网络(Long Short-Term Memory)等神经网络模型被应用于实体识别任务,并展现出强大的优势。
关系抽取方法主要可以分为经典的关系抽取方法和基于深度学习的抽取方法。经典的关系抽取方法主要包括有监督、半监督、弱监督和无监督4种[7],这几种方法存在特征提取误差传播的问题,很大程度上影响最终关系抽取的结果。基于深度学习的方法避免了人工特征提取,Zeng等[8]于2014年首次使用CNN进行关系分类。Vu等[9]采用深度循环神经网络(Deep Recurrent Neural Networks,DRNN)进行关系抽取。
流水线方法虽然在模型选择和实验操作比较灵活、简单,但是这种方法存在以下几个问题:① 导致错误累积;② 忽略了两个子任务间的相关性;③ 产生大量冗余信息。例如文本:“方剂麻杏石甘汤是由麻黄、杏仁等多味中药组成”,采用流水线方法的具体流程如图1所示。假如在命名实体识别阶段模型没有识别出实体“麻杏石甘汤”,由于关系抽取完全依赖实体识别的结果,则所有包含“麻杏石甘汤”的三元组皆无法得到,因此导致错误累积;已知文本中存在“方剂/中药”这一关系,可以推理第一个实体的类别是“方剂”类,第二个实体的类型是“中药”类,而采用流水线方法无法利用该信息进行推理;关系抽取是对每个候选实体对进行关系分类,不属于预定义关系的实体组合就是冗余信息,如(麻黄,None,杏仁)。
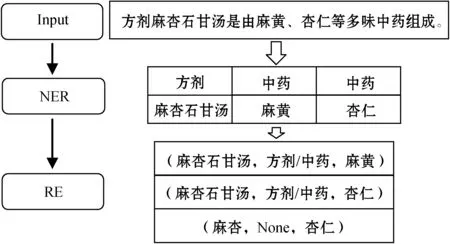
图1 流水线方法流程
1.2 联合抽取方法研究
针对以上流水线方法存在的问题,实体关系联合抽取直接抽取给定文本中含有的实体和实体间语义关系的三元组(Entity1,Relation,Entity2),不仅能够充分考虑二者的相关性,将二者联合学习,还使两个子任务的性能得到了不同程度的提升。
Ren等[10]提出CoType框架。Miwa等[11]使用填表方法,将实体识别和关系抽取进行联合学习,但是都基于人工提取特征,依赖于复杂的特征工程,还需使用各种自然语言处理工具包。随着深度学习方法的兴起,Miwa等[12]使用BiLSTM实现实体识别,通过共享输入层和LSTM编码层的参数,连用Bi-TreeLSTM结构实现关系抽取。Katiyar等[13]针对Miwa等[12]利用依存树结构的缺点提出融合注意力机制的RNN方法实现实体关系联合抽取。Zheng等[14]采用BiLSTM对输入层进行编码,选用LSTM进行解码,实现实体识别;通过共享BiLSTM编码器参数,利用CNN模块对编码层结果进行关系分类。文献[15]通过引入互反馈机制,反馈更新共享层的参数来提升联合抽取的效果。基于参数共享的实体和关系联合抽取方法增强了实体识别和关系抽取两个子任务的相关性,改善了传统流水线方法错误累积的不足。但是由于该方法都是利用共享底层模型参数来增强两者的相关性,实质上仍是先进行NER,再利用NER的结果进行RE,因此仍会产生不存在关系的实体对冗余信息,也存在错误传递。
Zheng等[16]首次将实体关系联合抽取转化为序列标注问题,还设计了带有偏置损失函数的端到端模型,实现了真正意义上的实体关系联合抽取。但在最终三元组的抽取时采用就近距离策略,且规定一个实体只能存在一个三元组中,导致大量关系数据丢失,无法解决实体重叠问题。曹明宇等[17]借鉴Zheng等[16]的方法,改进标注策略,采用BiLSTM-CRF模型有效缓解了同一实体参与多个关系的重叠问题,在生物医学领域的药物实体关系数据集上取得了较好的效果。
鉴于传统流水线方法的不足和中医文本中存在大量实体重叠的问题,本文提出一种基于字词向量拼接的中医实体关系联合抽取方法。首先将字词向量拼接作为输入,再采用改进的序列标注策略在BiLSTM-CRF(Bi-directional Long Short-Term Memory Conditional Random Fields,BiLSTM-CRF)模型上对中医文本进行标注,最后通过自定义的抽取规则进行关系三元组提取。
2 中医实体及关系联合抽取方法
该方法使用改进的序列标注策略,将中医的实体关系联合抽取转换成序列标注任务,词向量与字符向量并联拼接作为双向LSTM-CRF输入,利用双向LSTM神经网络强大的特征提取能力,以及CRF在序列标注上的突出优势,结合优化的抽取规则完成中医实体关系联合抽取。整体方法流程如图2所示。

图2 方法流程
该方法的整体流程为:
1) 对输入的文本句子利用Word2vec进行向量转化,分别生成字向量和词向量;
2) 将生成的向量以字为基本语义单元进行字词向量并联拼接;
3) 采用改进的标注策略,通过BiLSTM-CRF模型对每个句子进行序列标注;
4) 根据序列标注结果,结合自定义的抽取规则来抽取关系三元组。
2.1 模型输入
One-hot编码得到的是稀疏向量,向量的维度完全取决于语料库的大小,且每个词的向量之间都是独立的,相近意思的词语也没有关联关系。相较于One-hot编码,Word2vec得到的词向量降低了向量的维度,且语义相近的词语被映射在相近的位置。
本文训练向量所用语料来源于《中医证候鉴别诊断学》《中医150证候辨证论治辑要(何晓晖)》和《中医药学概论》三本中医相关书籍。而采用分词工具得到的中文分词结果并非完全正确,且单独用词作为语义单元也忽略了词内字间的联系;单独用字作为语义单元,又不能准确地表达当前的语境,因此本文采用了字词向量并联拼接作为模型输入,将字和词的信息有效地结合起来。中医语料利用jieba分词工具,并加载自定义的中医领域自定义词典进行分词,自定义词典主要包含大量的证型、方剂等信息,通过Word2vec训练得到100维词向量。中医语料使用Word2vec训练得到100维字向量。最终,本文采用以字向量为基本语义单元与该字所在词的词向量进行并联拼接得到200维字向量作为模型的输入,字词向量并联拼接丰富了词的语义信息,提取有效特征,如图3所示。例如文本:“四逆散中重用柴胡为君药”,则该句中作为模型输入“胡”的向量由“胡”的字向量与“胡”所在的词“柴胡”的词向量构成。
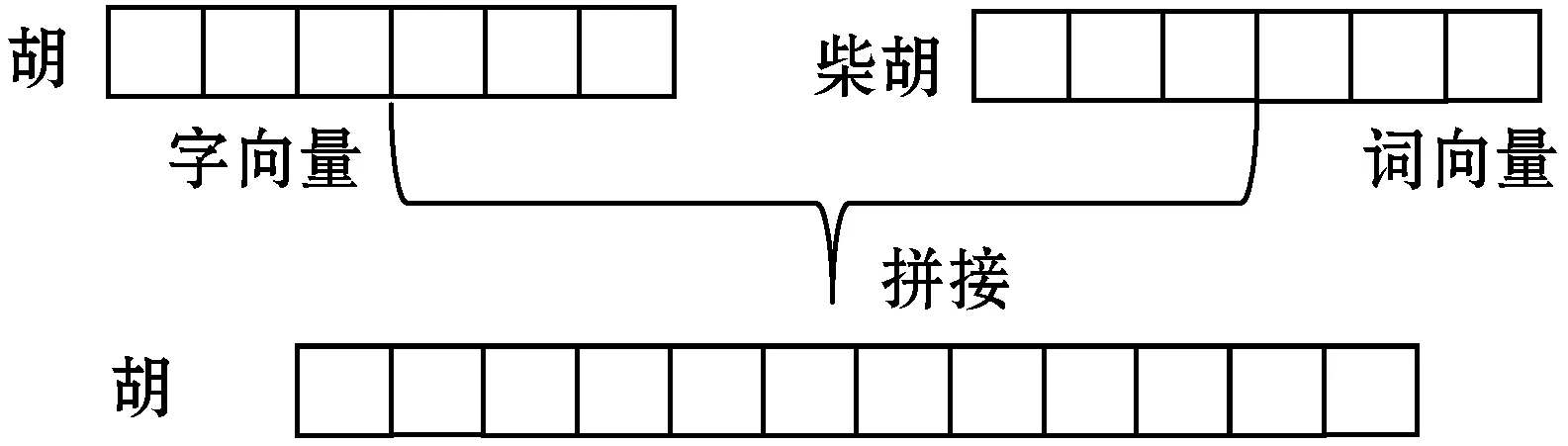
图3 字词向量拼接
2.2 标注策略
本文在Zheng等[16]提出的标注策略和曹明宇等[17]的标注策略基础上进行改进,将实体关系联合抽取转化为序列标注的问题,对每个字符根据标注策略进行标注。如图4所示。

图4 标注实例
其中“O”表示该字不与其他字构成实体,且在该句中与其他任何实体不存在预定义的关系;此外,每个标签共包含三部分的内容:该字在实体中的位置、关系类别、实体在三元组中的位置。该字在实体中的位置采用“BIES”策略进行表示,“B”代表实体开始,“I”代表实体中部,“E”代表实体末尾,“S”代表单个字构成实体;关系类别是根据中医语料预先定义好的,本文共涉及5种关系,分别为方剂/中药、证型/方剂、证型/症状、病因/证型和M,M表示该实体与多个实体组成关系不同的三元组;实体在三元组中的位置有3种:1、2和P,其中P表示该实体与多个实体组成三元组且处于不同的位置。此种标注策略有效缓解了实体重叠的问题。
2.3 BiLSTM-CRF
本文采用BiLSTM-CRF模型进行中医文本的序列标注任务,具体模型结构如图5所示。
LSTM网络是RNN的一种变种[18],引入了细胞状态概念,通过决定哪些信息需要被记忆,哪些需要被遗忘来解决RNN梯度爆炸和梯度消失的问题。LSTM主要通过遗忘门、输入门和输出门来达到信息传递目的。具体计算公式如下:
ft=sigmoid(Wf[ht-1,xt]+bf)
(1)
it=sigmoid(Wi[ht-1,xt]+bi)
(2)
ot=sigmoid(Wo[ht-1,xt]+bo)
(5)
ht=ot*tanh(Ct)
(6)
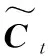
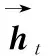
BiLSTM使用softmax进行归一化处理得到每个字对应每个标签的概率,然而每个标签并非独立存在,它们之间存在一定的约束,例如“E-方剂/中药-1”之前一定是“I-方剂/中药-1”,“B-方剂/中药-1”之后一定是“I-方剂/中药-1”。而CRF可以更好地学习各标签之间的依赖关系,进行全局优化,使标注处理更加准确和高效。
2.4 抽取规则
Zheng等[16]默认一个实体只存在一个三元组中,关系抽取采取就近距离原则,这样便损失了大量实体关系信息,而中医文本中存在大量一个实体与多个实体构成关系三元组的情况。曹明宇等[17]在此基础上进行改进,取得了较好的效果,但在匹配最近实体时设置了匹配方向而导致一些三元组丢失。
依据上述分析以及中医文本的信息抽取需要,本文在采用就近原则抽取的基础上,自定义了以下3条抽取规则:
规则1:对于命名实体识别任务,当实体标签的三个部分信息均正确时进行抽取;对于联合抽取任务,当组成三元组的实体1、实体2和关系类别均正确时进行抽取。
规则2:组成三元组的关系类别约束。关系类别相同,或者其中一个或者两个实体的关系类别为M,即本文预定义的4种关系类型可以与其相同的关系类型匹配也可以与M匹配。
规则3:组成三元组的实体位置约束:实体位置分别为1和2,或者其中一个或者两个实体的实体位置为P,即1可以与2匹配,也可以与P匹配,2和P同理。如图2样例所示,麻黄汤可与麻黄组成关系三元组(麻黄汤,方剂/中药,麻黄),与桂枝组成关系三元组(麻黄汤,方剂/中药,桂枝),与风寒表实证组成关系三元组(风寒表实证,证型/方剂,麻黄汤)。
3 实验及结果分析
3.1 实验数据集
本文使用的语料源于中医古籍、中医相关教材等整理的2 968个句子,均经人工按照本文的标注策略进行标注。该中医语料共包含方剂、中药、证型、症状和病因5类实体,方剂/中药、证型/方剂、证型/症状、病因/证型和M共5类关系,其中M表示该实体与多个实体组成关系不同的三元组。具体的占比见表1,按照7 ∶3的比例划分训练集和测试集。
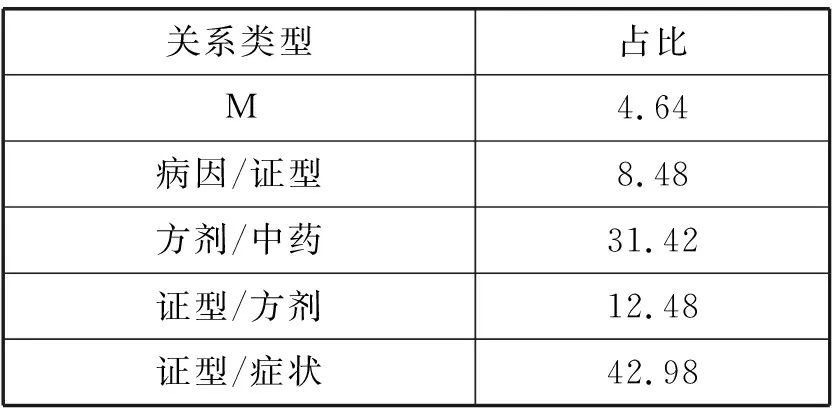
表1 各关系类型语料占比(%)
3.2 评价指标
实验采用的评价指标是准确率(Precision,P)、召回率(Recall,R)、F1值。对于命名实体识别任务,当实体标签的三个部分信息均正确时认为其正确;对于联合抽取任务,当组成三元组的实体1、实体2和关系类别均正确时认为其正确。具体三元组的P、R、F1的计算公式为:
式中:npredictright表示预测得到且正确三元组的数目;npredict表示预测得到三元组的数目;nright表示实际三元组的数目。
3.3 实验设置
向量输入由Word2vec训练得到100维字向量和100维词向量拼接而成200维字向量。模型训练涉及的主要超参数:学习率设置为0.001;dropout设置为0.5;优化器(optimizer)设置为Adam等。
3.3.1向量输入对比实验
为了验证字词向量拼接作为模型输入的有效性,通过多组不同维度的单独字向量作为输入和字词向量拼接作为输入对比实验进行验证,实验结果见表2。
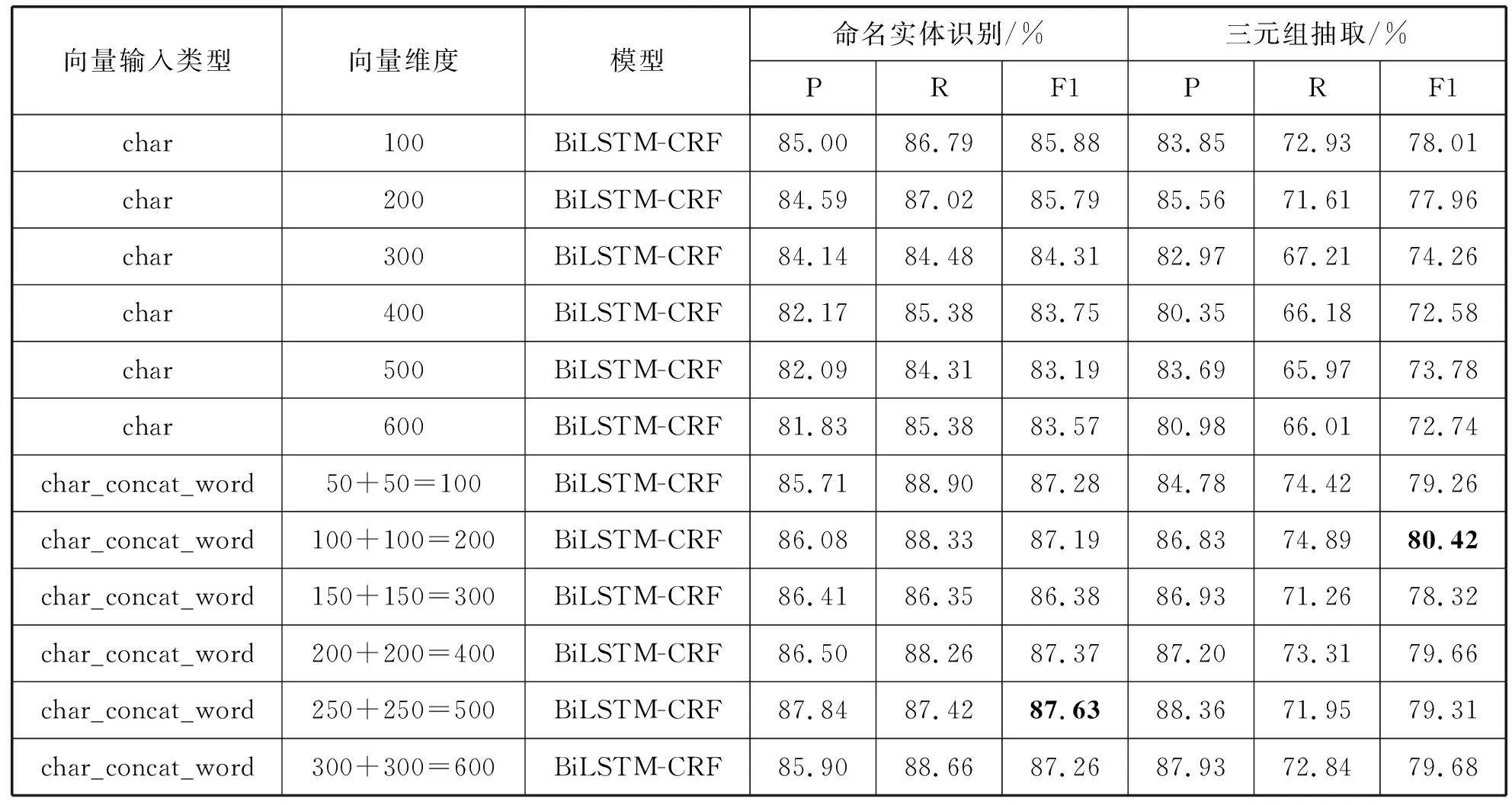
表2 输入对比实验
其中char表示字向量,char_concat_word表示字词向量拼接。由表2可知,字词向量拼接作为输入的效果均优于单独字向量作为输入。本文最终目的是提取关系三元组,因此选用字向量100维和词向量100维并联拼接作为模型输入。
如表2所示,与实体识别相比,三元组抽取具有更高的精确率,但其召回结果低于实体识别任务,这意味着存在预测的实体并不能构成实体对,只找到了Entity1而没有找到相应的Entity2,或者Entity2而没有找到相应的Entity1。因此,实体对具有比单个实体更高的精度率和更低的召回率。
3.3.2模型对比实验
将本文方法与两种流水线方法进行对比实验,方法一:BiLSTM-CRF序列标注用于实体识别,在实体识别结果的基础上使用SVM进行关系抽取。方法二:BiLSTM-CRF序列标注用于实体识别,在实体识别结果的基础上利用LSTM进行关系抽取。这两种方法所用语料均为中医语料,序列标注时采用“实体中字的位置-实体类别”的标注策略。
由表3实验结果可以得出,本文采用的联合抽取方法较传统的流水线方法F1值有较大的提升,较方法二(BiLSTM-CRF+LSTM)F1值提升4.49%,较方法一(BiLSTM-CRF+SVM)F1值提升接近10%,说明了本文方法的有效性。
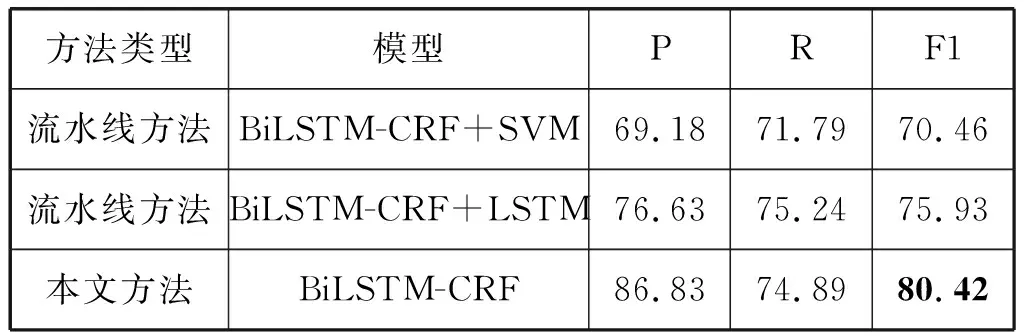
表3 模型对比实验(%)
3.3.3抽取规则对比实验
采用本文提出的标注策略,字词向量拼接作为输入,通过BiLSTM-CRF模型进行序列标注,分别采用Zheng等[16]、曹明宇等[17]和本文的抽取规则进行三元组抽取对比实验,如表4所示。
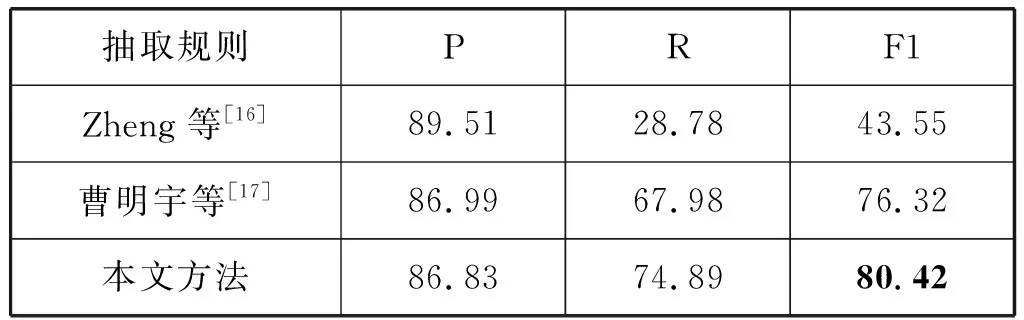
表4 抽取规则对比实验(%)
根据表4可知,使用本文的抽取规则实验效果整体更佳。前两种方法P值偏高的原因如下:Zheng等[16]默认一个实体只存在一个三元组,且在三元组抽取时采用就近原则;曹明宇等[17]在标注策略中增加了实体类别的信息,且在三元组抽取时规定实体位置1只能向后匹配,实体位置2只能向前匹配。为了进一步对比这3种方法的抽取结果,表5举例进行说明。
由表5可知:本文方法可以抽取到Zheng等[16]和曹明宇等[17]丢失的部分信息,改善了实体重叠的问题,但还是存在关系三元组损失的现象,仍需进一步改进。
4 结 语
本文使用改进的序列标注策略,将中医的实体关系联合抽取转换成序列标注任务,词向量与字符向量并联拼接作为BiLSTM-CRF输入,利用BiLSTM神经网络强大的特征提取能力,以及CRF在序列标注上的突出优势,结合优化的抽取规则完成中医实体关系联合抽取,不仅克服了传统流水线方法的弊端,很大程度地缓解了实体重叠的问题,并在中医语料上达到80.42%的F1值。
但是,本文的方法仍存在丢失三元组的现象。此外该方法依赖人工标注语料,而现实中存在大量无标签数据,可以借助远程监督的方法来缓解该问题。探究每个字符在句中的位置信息是否对实体关系联合抽取有促进作用是未来的工作。
