基于三阶段集成学习的信用卡欺诈检测研究
2023-02-22阮素梅孙旭升甘中新
阮素梅, 孙旭升, 甘中新
(1.安徽财经大学 金融学院,安徽 蚌埠 233030; 2.合肥工业大学 管理学院,安徽 合肥 230009; 3.Solbridge International School of Business,Woosong University, Daejeon 300814, South Korea)
0 引言
欺诈是指用狡猾手段使人发生错误认识从而施诈于人的故意行为。信用卡欺诈则是指为了谋取个人经济利益故意使用伪造、废弃的信用卡或盗用他人信用卡进行恶意消费和恶意透支的行为。近年来,互联网的快速发展促进了各大传统行业的变革,而“互联网+信用卡”的结合更是促进了信用卡在全球范围内的普及。仅在2018年,全球信用卡欺诈的损失就高达278.5亿美元。BUONAGUIDI等[1]表明:2020年“新冠”肺炎流行期间,全球发生信用卡欺诈案件数量更是激增,美国4月份信用卡欺诈交易的金额同比增长了35%。为避免信用卡欺诈带来的巨大的经济损失,众多学者都致力于研究信用卡欺诈检测系统,以阻止欺诈交易的发生。
信用卡欺诈交易检测通常包括不均衡样本处理、特征工程和模型搭建三个环节。LIN等[2]提出信用卡交易数据集通常在前两个阶段呈现出样本类别高度不平衡和特征冗余的特点,即正常交易远多于欺诈交易并且交易数据特征的维度较高。这些特通常会导致模型对多数类样本产生过拟合,从而导致模型的预测精度下降。近年来,随着机器学习算法的兴起以及其展现出的良好性能,学者们将其引入到信用卡欺诈检测系统中,包括人工神经网络(ANN)[3]、逻辑回归(LR)[4]、支持向量机(SVM)[5]、决策树(DT)[6]等单一模型和极端梯度提升(XGBoost)[3]、随机森林(RF)[7]等集成学习模型。其中,集成学习通过综合若干基模型的学习成果提升模型的泛化能力,是解决训练过拟合的重要方法[8]。但是,以往研究通常仅在模型搭建这一环节使用了集成学习,并没有通过集成学习解决前两个环节中的样本不均衡和特征冗余问题,因而检测效果差强人意。
针对以往研究存在的不足,本文尝试从特征选择、不平衡处理以及分类器融合进行三阶段集成学习,将集成学习的思想贯穿始终,并据此提出“FS-IFKK-Stacking”模型:第一阶段针对数据集特征冗余,分别采用六种基学习器筛选最优特征,并结合投票方法得到低维重要特征子集;第二阶段针对数据集高度不平衡性,基于孤立森林IsolationForest[8]、K-Means++聚类以及KNN-IFKK重采样算法生成若干个具有代表性的平衡数据组供模型训练使用,第三阶段基于Stacking算法集成由11种机器学习单一模型组成的模型,并结合多数投票法Majority voting构建异构集成模型作为最终预测模型。基于欧洲信用卡交易数据的预测实验表明,本文提出的“FS-IFKK-Stacking”模型对信用卡欺诈检测效果显著优于基于原始样本训练得到的单分类基准模型。相对于表现最佳的基准模型,该模型对欺诈交易的召回率Recall提升了3.27%,AUC值提升了0.44%。本文提出的“FS-IFKK-Stacking”是对现有信用卡欺诈交易模型的有效改进。具有重要的理论意义和实践价值。
1 三阶段“FS-IFKK-Stacking”检测模型
1.1第一阶段:特征选择
信用卡欺诈数据中存在的特征高维度、冗余特征会影响传统检测模型的性能,因此要对其进行特征选择,常用的方法包括主成分分析(PCA)、互信息、随机森林,XGBoost特征排序等方法,但是不同的方法有各自优缺点,例如PCA算法使用方差衡量信息量,并且可以消除原始数据特征间相互影响的因素,但生成的特征模糊性高、可解释性不强;互信息算法具有简单、易实现的优势,但容易导致特征冗余,同时易受边缘概率影响,偏向于选择稀有特征;随机森林随机选择决策树节点划分特征,能够高效地对高维样本进行训练,但倾向于选择取值较多的特征。只运用一种方法并不能有效满足高维信用卡欺诈数据的特征选择,使用集成方法将多个基分类器特征选择的结果进行排序,将各种特征子集的交集选为最优特征选择结果能够提高特征选择的鲁棒性。
本文将过滤法(Filter)、封装法(Wrapper)和嵌入法(Embedded)结合起来进行特征选择,首先将过滤法中的卡方检验、互信息分类以及嵌入法中的带L1惩罚项的逻辑回归、极端提升树、XGBoost和LightGBM这六种基模型进行特征选择,对这六种模型选择的最优特征进行投票。特征每被选中一次得一张票,删除得2张及以下票数的弱特征,本文最终保留得4张及以上票数的强特征,将得3张票数的特征列为临界特征。为了进一步检验临界特征的有效性,本文引入了封装法,将得4张及4张以上票数的特征集列为A组,3张及3张以上票数的特征集列为B组,将A、B两个特征组输入多个模型进行训练对比效果,最终选出能够明显区分信用卡欺诈交易的最佳特征组。
1.2 第二阶段:数据不平衡处理
解决信用卡欺诈数据高不平衡性问题的重采样方法包括欠采样和过采样,LIN等[2]研究证明了欠采样技术优于过采样技术,因此本文基于欠采样方法的改进。基于K-Means聚类的欠采样是目前常用的欠采样方法,其核心思想是对多数类样本进行聚类,从每个簇中提取聚类中心点或聚类中心点近邻来代表各个簇的多数类样本,直至多数类样本数量接近少数类样本。但是K-Means算法对异常点和噪声敏感,受初始聚类中心的位置影响较大,同时该聚类欠采样方法仅仅选取各簇中一个代表性的点,可能会删除多数类中有价值的样本点。为了弥补单一欠采样技术的不足,本文提出一种基于孤立森林、K-Means++聚类、KNN的平衡数据的方法——IFKK。
孤立森林(Isolation Forest)是由FEI 等[8]提出的一种异常点检测算法。该方法将异常点定义为容易被孤立的离群点,即稀疏并且距离密度高的群体较远的样本点。IFKK方法通过IsolationForest去除异常点和噪声,随后使用K-Means++算法优化初始聚类中心选择和提升算法收敛速度,保证了平衡数据组中样本的代表性。本文利用KNN算法提取各簇聚类中心第一最近邻点和少数类样本组成第一平衡数据组,再提取各簇聚类中心第二最近邻点和少数类样本组成第二平衡数据组并进行下一步迭代。最终,本文根据数据规模共提取出21组具有代表性的平衡数据组,以保证均衡样本的多样性。
1.3 第三阶段:集成模型
欺诈检测模型包括单一的机器学习模型和集成学习模型,众多研究证明主流的集成学习模型要优于单一机器学习模型。集成学习模型中常用的Bagging和Boosting是只包括单一基模型的同质集成学习器,而Stacking算法属于异构集成学习器,基模型的种类更加多样化,能够实现“博采众长”。不同基模型间较低的相关性可以提高算法的误差校正能力,因此基模型差异度和精度越高,最终Stacking集成算法的效果也会更好。
图1和图2是加入了交叉验证的Stacking算法示意图。第一层基模型训练过程如图1所示,用Model1对训练集进行五折交叉验证生成Model1的新特征New Feature,包含了每折训练时的预测值Predict1,Predict2,Predict3,Predict4,Predict5,同时每一折训练时对测试集进行预测并求均值得到Model1的预测值Aver-test1,即输入元模型的新特征。第二层元模型训练过程如图2所示,将第一层n个基模型得到的新特征及目标值和Target输入元模型进行训练,将第一层基模型得到的测试集预测值带入元模型进行预测得出最终结果Pred。
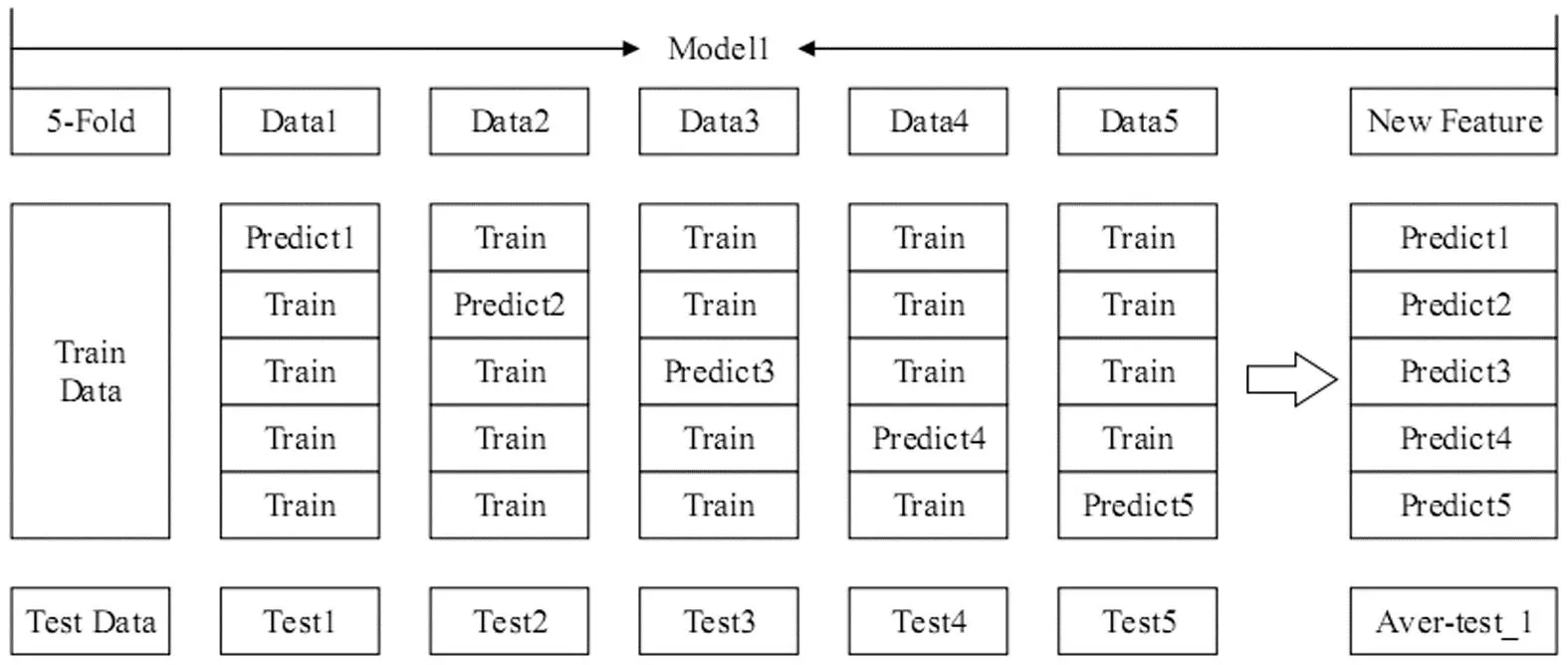
图1 第一层基模型训练过程
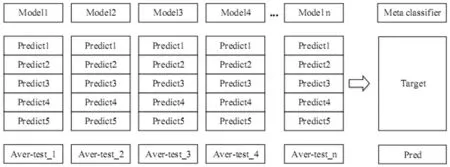
图2 第二层元模型训练过程
为了增强Stacking分类效果,本文将基与性能较优的GBDT的三种改进算法XGBoost,LightGBM,CatBoost作为基模型,由于第一层基模型的输出结果和最终分类标签呈线性相关的关系,因此本文在第二层元模型上选择高效快捷的逻辑回归模型。为了进一步提高模型的泛化能力,本文将第二阶段IFKK方法生成的21组平衡数据分别用Stacking算法进行拟合产生测试集样本21个预测值,利用多数类投票法“少数服从多数”的原则,将产生的超过一半数量的相同预测值作为测试集样本的最终预测值。基于三阶段集成学习的信用卡欺诈检测流程如图3所示。

图3 信用卡欺诈检测流程图
2 实证研究与分析
本节首先介绍了数据集和评价指标,然后通过欺诈检测模型对数据集进行训练预测,对实证结果进行分析。本文基于python3.7进行程序开发,使用5折交叉验证提高模型的泛化能力,其中训练集占80%,测试集占20%,所有模型均使用网格搜索法进行调参。
2.1 数据集
本文使用的数据集选自Kaggle提供的欧洲持卡人2013年9月两天内的信用卡交易数据,该数据集共有284807个样本,无缺失值,其中包含284315个信用卡合法交易样本,492个欺诈样本,不平衡比例为1:577;数据集共31个特征,其中1个特征是目标标签Class,表示该样本是否为欺诈交易数据,值为1表示是,0表示否;30个特征表示信用卡交易的相关信息,出于保密原因,除了“Time”和“Amount”这两个特征外用PCA转换得到V1到V28这28个特征变量,“Time”表示交易发生时间,单位为秒,本文将其转换为每天以小时为单位的时间,“Amount”表示信用卡交易金额,特征“Time”和“Amount”的数据规格和其他特征不一致,对其进行标准化处理。为了让测试集满足欺诈交易真实的不平衡分布,划分训练集和测试集时按照原始不平衡比例1:577均匀划分。
2.2 评价指标
为了尽可能地检测出欺诈交易并尽可能地少地判错合法交易,本文选取了召回率Recall来衡量欺诈交易检测的效果,Recall即所有真实欺诈交易实例中预测为欺诈交易的比例;并选取接收者操作特征曲线ROC曲线下面积AUC值作为综合评价标准对模型进行评估,AUC值可以看作从所有样本中随机选取一对正负样本,正样本预测为正的概率值大于负样本预测为正的概率值的概率,AUC值在0.5和1之间,AUC值越接近1,表示模型的分类性能越好。
2.3 实验结果分析
基模型选择的最优特征如表1所示。特征每被选中一次得一张票,我们抛弃得票数在2票及2票以下的弱特征,共删除12个特征,保留得票数在4票及4票以上的强特征,共保留12个特征,记为A组,将得票数为3票的6个临界特征加入A组形成B组,共18个特征。为了检验临界特征的有效性引入封装法,将A,B两个特征组分别输入多个模型进行训练并对比效果,结果如表2所示。
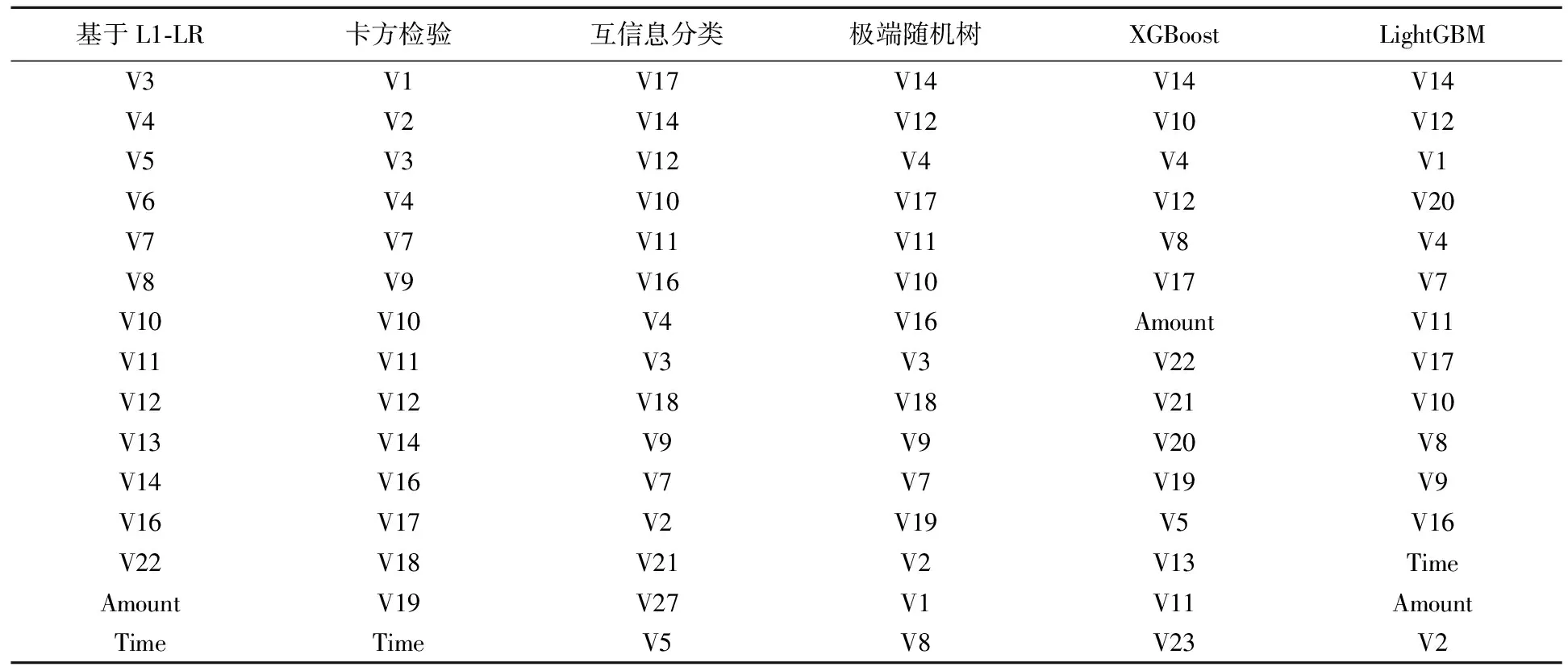
表1 基模型特征选择排序

表2 FS-IFKK方法与基准方法对比实验结果
将原始特征输入模型进行拟合后,我们发现在未加入GBDT算法的Stacking模型中,鲁棒性强的SVM的分类效果最好,召回率Recall达到了0.9061,AUC值达到了0.9431;将 GBDT第一种改进算法XGBoost加入Stacking算法时,X-Stacking的效果提升明显,AUC值达到0.9451;当继续加入GBDT第二种改进算法LightGBM时,XL-Stacking的效果进一步提升,AUC值达到了0.9455;加入GBDT第三种改进算法CatBoost时,XLC-Stacking的效果最佳,Recall达到0.9102,AUC值达到0.9465,分类效果优于基模型,由此可以看出基于原始数据的Stacking欺诈检测方法是有效的,且分类效果优于单一分类器。从表2可以看出经过集成特征选择FS后的A特征组比B特征组在各模型上得到的效果均更好,这说明6个临界特征可能是冗余特征影响了模型性能,应该剔除,因此在后续实验中,本文使用A特征组进行数据实验。A特征组包括V2,V3,V4,V7,V8,V9,V10,V11,V12,V14,V16,V17这12个特征。另外,从表2可以看出在A特征组上依次引入GBDT三种改进算法时,Stacking算法的性能得到了不同程度的提高。其中,引入GBDT三种改进算法(XGBoost、LightGBM和CatBoost)的XLC-Stacking的分类效果最好,Recall高达0.9122,AUC值高达0.9477,这说明基于FS-Stacking的欺诈检测方法是有效的。为了进一步提升模型性能,我们使用集成了孤立森林IsolationForest、K-Means++聚类、KNN的IFKK方法来生成多个平衡数据组输入模型进行对比实验,为了验证本文提出的三阶段集成学习方法在信用卡欺诈检测识别上的有效性,表2对比了原始数据和经过FS-IFKK方法处理后的数据在各模型上的分类效果。从表2中可以看出经过FS-IFKK方法处理后的数据在各模型上的分类效果均得到显著提升,其中GBDT的三种改进算法XGBoost、LightGBM和CatBoost的分类性能在基模型中表现优异,并且将这三种算法依次引入Stacking中性能将得到进一步提升,其中同时引入GBDT三种改进算法的XLC-Stacking算法的性能最好,召回率Recall达到0.9388,AUC值达到0.9499,与原始数据中分类性能最佳的基模型CatBoost作对比,召回率Recall提升了3.27%,AUC值提升了0.44%。
综合以上实验结果可以发现,在FS-IFKK方法投票选取重要特征和处理不均衡样本数据集之后,本实验选取的基准模型对信用卡欺诈的识别能力均有提升;在进一步使用Stacking方法集成单分类模型之后,最终模型的预测能力在单分类模型的基础上进一步提升。三阶段模型实现了模型预测能力的“阶梯”状提升。
3 结论
针对高维不均衡的信用卡交易数据集,仅在某阶段使用集成学习是远远不够的,在模型训练的各个环节都使用合适的集成学习方法。本文提出的“FS-IFKK-Stacking”将集成学习的思想贯穿信用卡欺诈交易检测任务的三阶段,同时解决了数据特征高维性和样本不均衡性问题,证明了集成学习在特征选择、不均衡样本处理和构建预测模型的三阶段具有重要作用和良好表现。
