基于特征优选和SVM的船舶航行事故致因分析
2023-02-22石荣丽林艺舒
石荣丽, 林艺舒
(1.广东药科大学 医药商学院,广东 中山 528000; 2.广东省药品监管科学研究基地,广东 中山 528000; 3.国家药品监督管理局 药物警戒技术研究与评价重点实验室,广东 中山 528000; 4.广东金融学院 互联网金融与信息工程学院,广东 广州 510521)
0 引言
在“海运强国”战略和建设“海上丝绸之路”的大背景下,我国的水上交通运输量不断增长,船舶趋于大型化和高速化,这使得船舶通航环境日益恶化,水上交通事故频发。由于搜救难度大,这些事故往往会造成严重的经济损失、人员伤亡和环境污染[1]。其中,船舶航行事故占所有水上交通事故的绝大部分。因此,分析船舶航行事故致因具有重要意义。
关于事故致因模型的研究,最早的事故因果模型之一是由HEINRICH等[2]在1931年提出的多米诺模型(DominoModel),该模型为链式模型,成为很多事故模型的基础。REASON[3]在1990年提出瑞士奶酪模型(SCM)用于分析流行病学事故致因,并基于SCM模型开发了HFACS和ICAM等实用工具。但由于这些模型及工具都没有考虑系统部件之间的动态和非线性交互,因此不适合分析复杂事故系统的致因。为了分析复杂的、相互关联的事件网络,一些学者们基于系统理论,提出系统性事故致因模型,如社会技术系统层次模型、基于社会技术系统层次模型形成的AcciMap、系统理论模型和流程分析法(STAMP)模型、基于认知系统工程原理的认知可靠性和误差分析方法(CREAM)、24Model模型和功能性共振分析法(FRAM)。然而,这些基于系统理论的模型,不可同时避免缺乏客观性、效率低及缺乏对事故原因概率的充分分析的问题。由于机器学习具有相对客观、高效、可用于深层分析复杂的网状指标关联性、可用于预测概率等优势,一些机器学习模型渐渐地应用到事故致因的分析中[4]。
当前对于水上交通事故致因的研究方法主要包括FRAM模型、24Model模型、贝叶斯网络、文本挖掘、有序模型、决策树模型和Logistic分类模型等。FRAM模型能全面系统地考虑事故致因,并通过网状系统分析复杂的事故,但是该模型需要依赖专家的深入分析。24Model模型作为模块化的系统模型保证了模型的效率,但不能对事故原因概率进行分析。吴伋等[5]对内河船舶碰撞事故的报告进行文本挖掘,能客观地将事故报告中频繁出现的关联词识别为事故致因。分类模型能很好地对事故概率进行预测,但大多数分类模型不能像有序模型一样直接分析各个因素对事故的影响程度[6]。
通过文献综述可知,当前关于水上交通事故致因的研究存在以下不足:(1)缺乏对致因的全面客观考虑,特别是缺乏对人为因素的详细分析,尽管很多研究表明人为因素是重要的水上交通事故致因[7];(2)由于缺乏公开数据,当前的水上交通事故样本容量不能满足大部分的研究模型。为了满足样本容量的需求,当前研究主要是通过扩大研究区域[6]和数据扩充[8]以获得大容量样本。但是,由于水上交通事故致因存在明显的地域差异[4],数据扩充不能充分地反映数据特征的变化。所以扩大研究区域和数据扩充都不利于精准地挖掘出事故致因;(3)模型不可用于预测事故概率,或者不可直接用于分析各个致因对事故的影响程度;(4)关于水上交通事故致因的现有研究主要通过分析事故船舶的数据或者通过比较某类事故船舶与其他类事故船舶的数据来挖掘出事故致因[4,8]。但事实上,并非所有发生事故的船舶都具有致险特征。比如被撞的船舶虽然发生了航行事故,但其本身并不具备致险特征。针对问题一,本文将通过文本挖掘及文献综述筛选出潜在的航行事故致因,包括较为全面的人为因素、船舶因素、管理因素和环境因素;针对问题二,本文通过特征优选和构建改进SVM(支持向量机)模型的方法降低模型对样本容量的要求。通过特征优选能够降低输入变量的维数,进而降低模型对样本容量的要求,提高模型的精度。SVM作为一种有监督分类模型,对样本容量的要求较小。其在交通事故严重程度研究中已得到了成功的运用。研究表明SVM模型对于事故影响因素的挖掘具有一定的优势[9]。目前SVM模型还尚未涉及水上交通事故致因的分析;针对问题三,借助RFE(递归特征消除)算法分析自变量对目标变量的影响程度;针对问题四,本文通过比较航行事故责任船舶与其他船舶间的差异来挖掘出航行事故的致因。
综合上述分析,本文结合特征优选、群体智能优化算法和机器学习,提出一种船舶航行事故致因分析模型。首先,通过文本挖掘、文献综述和相关性分析对模型特征进行优选;然后,借助网络搜索算法(GS)、遗传算法(GA)、粒子群算法(PSO)和帝国竞争算法(ICA)对模型参数进行寻优,构建航行事故责任船舶与其他事故船舶的SVM识别模型。最后,利用RFE算法将事故致因对事故的影响程度进行排序和筛选,挖掘出事故的关键致因,为预防船舶航行事故提供科学的理论基础。
1 模型构建
如图1所示,本模型主要包括2大步骤:基于文本挖掘和相关性分析的特征优选和基于改进SVM的航行事故责任船舶识别模型的构建与训练。
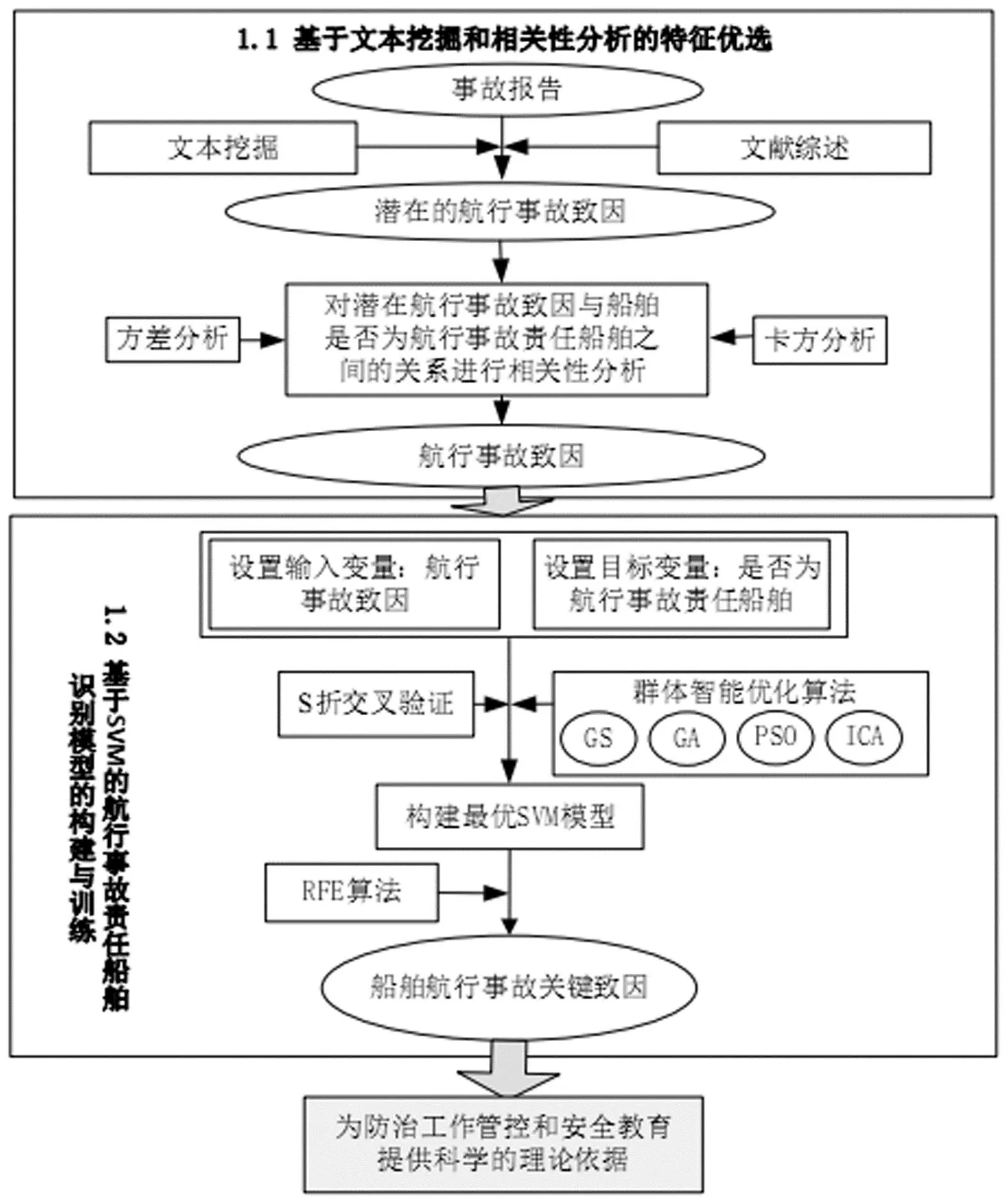
图1 船舶航行事故致因分析模型流程图
1.1 基于文本挖掘和相关性分析的特征优选
为了获得更全面的航行事故致因,本模型通过文本挖掘和文献综述的方法挖掘出高频的潜在航行事故致因。首先,利用分词程序对水上交通事故报告进行处理,挖掘出高频词。然后,删除与事故致因无关的高频词(包括虚词),并将同义的高频词进行统一。最后,将多个相近的指标合并成一个指标。筛选出潜在的航行事故致因。同时,结合文献综述,将现有研究中常见的水上事故致因也添加到潜在的航行事故致因集中。
为了降低模型计算的复杂性和提高模型的精确性,本模型对潜在的航行事故致因与目标变量(是否为航行事故责任船舶)之间的关系进行相关性分析。根据分析结果,将与因变量存在明显相关关系的潜在航行事故致因识别为航行事故致因,并作为航行事故责任船舶识别模型的输入变量。
1.2 基于SVM的航行事故责任船舶识别模型的构建与训练
SVM分类模型是建立一个最优决策超平面,使得该平面能够正确地将样本进行划分,且平面与两类样本之间的距离最大化。
在实际应用中,样本往往是非线性和线性不可分的。当样本非线性时,需要将因变量通过某种非线性映射映射到另一个高维特征空间,使得映射后的样本在这个高维特征空间中存在线性的分类规则。
非线性映射是通过设计核函数的方法来实现。为了得到理想的事故判别模型,本文选取RBF核函数构建SVM识别模型,并通过利用RFE算法将事故致因对事故的影响程度进行排序和筛选。其中,模型的参数通过S折交叉验证法[10]及群体智能优化算法获得最优值。基于SVM的航行事故责任船舶识别模型的构建步骤具体如下:
(1)设置优选出来的“航行事故致因”为输入变量,设置“是否为航行事故责任船舶”为目标变量。
(2)分别利用GA,GS,PSO,ICA算法和S折交叉验证法优化SVM模型的惩罚参数C和RBF核函数的参数g。
(3)基于RFE理念对船舶事故致因进行排序和筛选。本模型根据特征变量的权重进行排序,每次迭代都去掉权重最小的特征变量。然后在下一次迭代中保留SVM模型的剩余特征,重新对剩余的特征变量进行排序。重复这个过程,直至删除所有的特征变量。其中,各个特征变量的权重由删除该变量后SVM模型的正确度所决定,正确度越高,对应的权重越小,说明其对船舶是否会引发航行事故的影响越小。
2 数据
2.1 数据来源
本文中所需要的数据为水上交通事故报告,本文中的事故报告来源于广东海事局官网[11],共搜集广东省2012—2020年水上交通事故报告74份。
2.2 数据处理
本文根据事故报告,对每艘事故船舶的潜在航行事故致因进行整理。通过查询相关的船舶档案[12]、历史天气预报和新闻报道,补充缺失的船舶、天气等信息。
本文将相撞、碰撞、搁浅、翻沉、沉没、进水等在航行中发生的事故归类为航行事故,将其他事故(包括工伤、落水、火灾、爆炸等)归类成非航行事故。将航行事故中需要承担责任的船舶归类为航行事故责任船舶,将其他事故船舶归类成非航行事故责任船舶。
通过上述处理,共整理出满足研究要求的事故样本83个,涉及事故67起,船舶83艘(其中相撞事故涉及多艘船舶,每艘事故船舶为1个样本),包括航行事故责任船舶58艘和非航行事故责任船舶25艘。
3 实例验证
3.1 特征优选结果
本算例将广东省2012—2020年的水上交通事故报告中的事故原因分析部分梳理成文本格式,进行文本挖掘,挖掘出高频指标作为潜在的航行事故致因。如图2所示,为了实现数据的可视化,本节构建潜在事故致因的词云图。其中,图2(a)是基于事故报告中的事故原因分析部分的分词结果。图2(b)是将图2(a)中的同义项进行统一并删除无关项后的挖掘结果。图2(c)是将图2(b)中近义项合并后的挖掘结果。字体越大的指标,代表出现的频率越大。

(a) (b) (c)图2 基于广东省2012—2020年的水上交通事故报告的潜在航行事故致因挖掘结果
根据图2(c)所显示的挖掘结果,综合现有研究中对水上交通事故造成影响的指标,筛选出41个指标作为潜在的航行事故致因(见表1)。本节对筛选出来的潜在航行事故致因与目标变量(是否为航行事故责任船舶)之间的关系进行相关性分析。检验结果表明:不同船型、船长、时间段、区域、能见度、通航环境、船流量、是否由第三方监管、检验情况、是否疏于瞭望、是否风险估计错误/航行技术不足、是否开启AIS并通报港口、是否履职得当、航速是否安全对船舶的致航行事故率存在显著影响(其p值均小于0.1),这些因素是船舶航行事故的致因。表2显示了在这些致因下,各类船舶的致航行事故率(R)。

表1 船舶航行事故的潜在致因体系
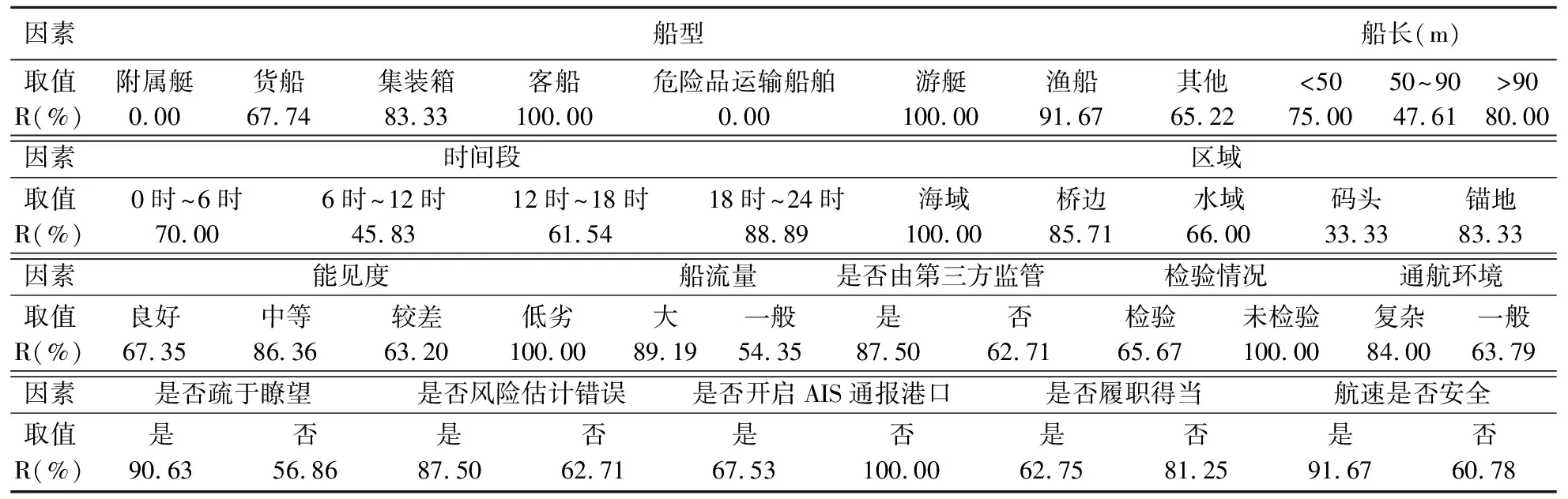
表2 船舶的致航行事故率
3.2 模型构建与训练结果
为了分析船舶航行事故致因对事故的影响程度,本算例将识别出来的14个事故致因设置为输入变量,将“是否为航行事故责任船舶”设置为目标变量。利用S折交叉验证法(设S=10)比较各类常见分类模型的泛化能力,分析结果如表3所示。其中,正确率是指9组训练集及测试集的正确率的平均值。由表3可知,SVM模型相比其他模型具有更强的泛化能力。
为了提高SVM模型的精确度,利用GA,GS,PSO,ICA算法和S折交叉验证法优化SVM模型,实验结果及模型参数的设置如表4所示。根据检测结果,本算例选取GS算法搜索模型的最优参数,记对应的模型为GS-SVM模型。通过对比,可知改进后的GS-SVM模型的泛化能力相对于未改进的SVM模型有了显著的提高。

表3 不同模型的正确率

表4 不同算法获得的最优参数及对应模型的正确率
利用RFE算法将事故致因对事故的影响程度进行筛选和排序。经过多次迭代得出所有致因的影响程度排序,如表5所示。
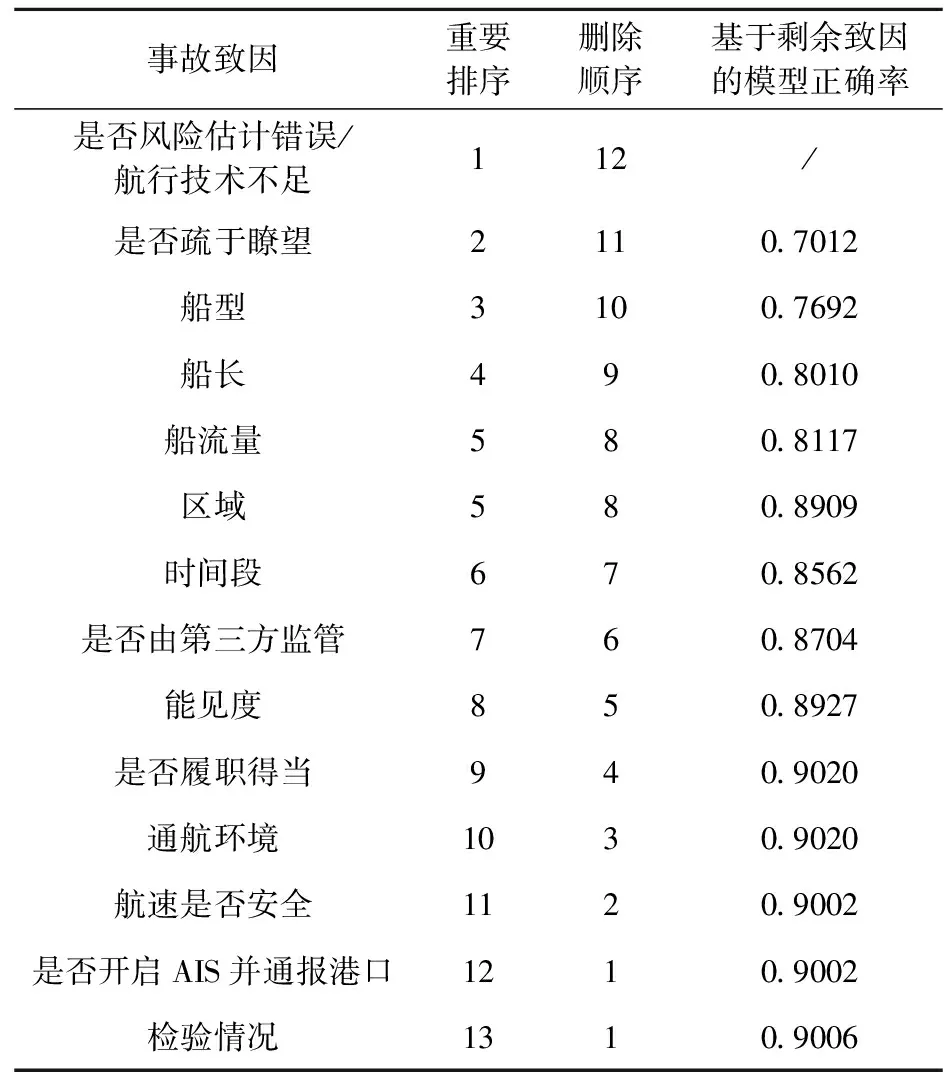
表5 船舶航行事故致因的影响程度排序
结合表2和表5可知:
(1)当GS-SVM选取前9个事故致因作为模型输入变量时,模型的正确率达到最高值0.9020。因此,本算例筛选这9个事故致因(是否风险估计错误/航行技术不足、是否疏于瞭望、船型、船长、船流量、区域、时间段、是否由第三方监督和能见度)作为船舶航行事故关键致因,这些指标应该作为航行事故防治工作管控和安全教育的重点,且越靠前的指标越应该被重点管控和教育;
(2)借助分类模型,通过调整9个关键致因,可判断船舶是否会导致航行事故。由此可为降低船舶航行事故率提供科学的参考方法;
(3)对于人为因素,风险估计错误/航行技术不足、疏于瞭望都会提高航行事故率;对于船舶因素,客船、渔船、游艇、集装箱、小型船舶(船长<50米)和大型船舶(船长>90米)的致航行事故率更高;对于环境因素,当处于船流量大、海域、桥边、锚地、夜间、能见度低劣的环境时,船舶更易发生航行事故;对于管理因素,第三方监管能有效降低航行事故率。
4 结论
为了减少船舶航行事故,本文基于水上交通事故报告,构建一种基于特征优选、群体智能优化算法及递归特征消除算法的SVM模型用于挖掘船舶航行事故关键致因,并分析各个事故致因对事故的影响程度。分析结果可为防治航行事故决策工作提供科学的理论依据。
本文以广东2012—2020年的水上交通事故为例,验证了所推模型的可行性及可靠性。结果表明航行事故责任船舶识别模型具有较高的正确度,这说明:(1)模型所挖掘出来的事故关键致因对船舶是否会引发航行事故具有决定性意义。因此,这些关键致因应视为安全教育和管控工作的重点。通过分析各个事故关键致因下各类船舶的致航行事故率,可以获得致航行事故率较高的船舶、环境、管理单位和作业人员。对其加强管控和引导有利于提高船舶航行的安全性。(2)借助模型可判别出船舶是否会导致航行事故,通过调整事故关键致因的状态,能找出避免航行事故的有效措施,从而更好地形成预警方案,降低船舶航行事故率。
未来,随着数据量的扩大和研究深入,可进一步完善实验,提高实验结果的准确性。
