电网厂站接线图人工智能识别关键方法
2023-02-11王梓耀罗庆全萧文聪王艺澎
王梓耀,罗庆全,萧文聪,王艺澎,余 涛
(1. 华南理工大学电力学院,广东省 广州市 510640;2. 广东省电网智能量测与先进计量企业重点实验室,广东省 广州市 510640)
0 引言
电网厂站接线图是调度控制系统中用于描述电气设备及其拓扑结构的图形,目前需要调度运维人员参考图纸进行人工识别和分析后,将其中的电气元件、图文信息以及拓扑关系进行手动录入。随着电网规模的扩大,网络拓扑、电网设备的快速更新迭代,仅依赖人工识别极易出现属性缺失、关联错误、连接线虚接等问题,更难以满足电网运行调度系统的实时更新要求。
为了满足“电网一张图”以及“数字电网”的建设要求,电力系统信息可视化和一体化成为必然趋势,图模一体化的发展进入了崭新的时代[1-2]。结合近年来迅速发展的人工智能技术,特别是图像识别技术的巨大突破[3],一些研究机构开始尝试将其应用于电力图像识别领域[4-7]。然而,不同地区、不同时间、不同专业人员绘制的电网厂站接线图有着一定的差异,如何运用人工智能方法对各类电网厂站接线图进行自动识别是一项极具挑战的任务[8]。总结来看,当前电网厂站接线图识别存在以下难点:
1)图元识别方面的挑战。图元识别是电网厂站接线图信息自动化提取的首要任务,也是计算机视觉识别领域典型的目标检测任务[9-10]。得益于深度学习领域的蓬勃发展,多种性能优异的目标检测算法被提出,包括以区域卷积神经网络(regional convolutional neural network,RCNN) 、Faster-RCNN、SPPNet(spatial pyramid pooling network)为代表的两阶段算法,以及以YOLO(you only look once)、SSD(single shot multibox detector)为代表的单阶段算法[11-14]。然而,直接使用传统的目标检测算法解决具体的电网厂站接线识别时仍存在一系列的问题:不同接线图的大小、清晰度、规范差别较大,难以用统一的算法进行识别;图元种类众多、大小不一、方向各异,且部分图元在整张图中所占的比例极小;不同图元、连线、文本混叠对识别目标图元造成的干扰较大等。
2)文字识别方面的挑战。文字识别领域将应用到OCR(optical character recognition)技术,现今基于深度学习的端到端OCR 技术有两大主流技术:卷积循环神经网络(convolutional recurrent neural network,CRNN)-OCR[15]和Attention-OCR[16]。其中,CRNN-OCR 在识别中文字符时表现较好,更适用于包含大量中文字符的图纸[17]。但在包含电气领域的中文字符后,当前文字识别仍存在以下难题:低质量图像中的文字识别效率不高;不规则文字或图元对文字识别的干扰;复杂背景下的文字识别;电气接线图中专业术语、简写的识别效率不高。
3)接线识别方面的挑战。区别于计算机视觉领域简单的直线检测,电气接线识别的关键难点在于需要深度融合电气领域知识进行判断和识别。文献[18]采用“去除图元+保护处理”进行接线识别;文献[19]提出基于子图匹配算法进行拓扑关系自动校核。但已有研究仍未有效解决以下问题:难以区分母线和其他常规线路;线路中关于交叉、跨接的识别效果较差;图中其余直线部分对直线检测存在一定的干扰。
为了解决上述问题,本文针对图元、文字以及接线识别进行逐个突破,在图元识别方面采用重叠滑窗机制和YOLOv4 结合解决“大图像小图元”的识别问题,在文字识别方面基于迁移学习方法融合电力领域知识提升识别准确率,在接线识别方面充分利用领域知识完成复杂拓扑下的接线识别,在此基础上构建一套完整的电网厂站接线图全自动识别方法。最后,在算例分析部分与其他识别、处理方法进行对比,验证了本文提出的电网厂站接线图智能识别方法的有效性。
1 电网接线图识别的主要思路
电网接线图识别本质是利用图像识别技术、人工智能技术以及电力系统相关业务逻辑,对输入的各类电网厂站接线图(JPG/PNG 格式)进行自动识别,输出符合标准的XML 文件,整体识别流程如图1 所示。

图1 电网厂站接线图识别框架Fig.1 Framework of wiring diagram recognition for power plant and substation
实际开展电网接线图识别工作主要分为4 个阶段:
1)预处理阶段——对训练集中的图片进行标注以及相应的预处理。对训练集中每一张图片进行标注;为了提升模型的识别效果,还需要对图片进行分级膨胀、等比例放缩等操作。
2)模型训练阶段——输入训练集对网络进行训练。其中,图元检测采用YOLOv4 模型,文字识别采用CRNN 模型。
3)图像识别阶段。首先完成图元识别、文字识别,然后结合电力系统业务规则与直线周边的文字,完成母线与常规线路的识别以及图元连接关系的识别。
4)后处理阶段。在完成基本的图元、文字、接线关系识别的基础上,还需要完成一系列下游任务,包括厂站基本信息提取、图元工作电压识别、图元-文字关联匹配、文字简写补全等。需要注意的是,后处理阶段可基于上述图像识别结果自动完成。
2 电网接线图识别的关键技术
电网厂站接线图实现的功能较多,且各功能间联系紧密,关系繁杂。本文主要介绍电网厂站接线识别中的3 个核心任务:图元识别任务、文字识别任务以及接线识别任务。
图元识别任务包括典型图元的检测与识别,其中包含断路器、隔离刀闸、接地刀闸、两卷变、三卷变、电容器、电抗器、线路、发电机、文字共10 种图元的种类、方向识别以及图元的定位。图元识别任务将完成图元类型、图元坐标、旋转角度等的输出。
文字识别的任务是根据图元检测任务输出的文字图元检测结果,对文本区域进行文字内容的识别。
连线识别任务包括母线识别、线路识别、拓扑关系检测。其中,母线识别需要根据文字识别的结果判断是母线还是常规线路;拓扑关系检测需要结合图元的坐标和识别出的线路给出图元之间的拓扑连接关系。
需要说明的是,由于母线的尺度与形态和其余图元相差较远,本文根据水平或垂直线检测、粗度检测等相关底层视觉特征完成母线图元提取,将母线识别归于连线检测任务中。此外,文字识别可分解为文字图元检测(即文字区域的坐标)与文本内容识别,由于文字图元检测与图元检测的实现原理基本相同,本文将文字检测纳入图元检测中。
2.1 图元识别
图元识别由图元定位与分类两部分组成,其得到的文字区域与各设备图元的种类、位置、旋转角度分别作为文字识别与连线识别的预备条件。
经过测试和对比,本文采用基于重叠滑窗机制与YOLOv4 目标检测算法实现图元识别。关于图元旋转方向的识别,对识别得到的各种图元分别构建旋转方向分类器,便可实现图元的细分类。
2.1.1 基于YOLOv4 的目标检测算法
本文综合考虑电网厂站接线图信息自动化提取的精度与速度,图元识别部分采用单阶段的YOLOv4 算 法[20],以CSPDarkNet53[21]作 为 特 征 提取网络,获得多幅尺度不同的特征图,后接SPP 模块,利用多尺寸的池化核综合扩大感受野,使用改进的PAN 模块通过上采样与下采样深度融合多尺度的特征图以提高不同尺度目标的检测效果,训练和推理过程的时间与空间复杂度均较低,有利于实际部署应用。
2.1.2 基于重叠滑窗机制与YOLOv4 的图元识别方法
由于电网厂站接线图信息密度远大于日常图片,其分辨率通常较高,且断路器、隔离刀闸、电容器等多种图元的宽高与接线图的宽高比例均小于0.1,属于“大图像小目标”检测问题。若采用传统的目标检测算法,则需要将图像缩小至算法要求的大小,再经过目标检测模型中的多层卷积、池化后,图元信息丢失问题严重,且密集的小目标在特征图中更容易聚集成一点,导致漏检、错检率较高。
为了解决这一问题,受卫星图中检测船只这一类“大图像小目标”检测算法的启发,采用YOLT(you only look twice)算法[22]。YOLT 算法中的重叠滑窗机制具体做法是:设定重叠率为r,滑动窗口大小为wwindow×wwindow,如图2 中红色方框所示,从左至右、从上至下进行滑动切割,图中灰色阴影为切割的2 幅相邻子图的重叠部分,重叠部分一边长为wwindow,另一边长为r×wwindow。使用重叠滑窗机制后无须对子图进行缩小,相当于增大了小目标图元在YOLOv4 模型输入中的尺寸与密集图元的间距,减少预处理及模型推理过程中的信息损失,能有效提高图元识别效果。合理设置重叠率可减少切割对图元完整性的影响,使图元至少在一幅子图中保持完整,且一定程度上等效于对样本进行上采样,对于密集的小目标图元来说更为突出,有利于模型的训练。

图2 重叠滑窗机制示意图Fig.2 Schematic diagram of overlapping sliding window mechanism
然而,实验发现,对不同尺寸的接线图直接使用重叠滑窗机制获得的切割子图数过多,将导致模型计算量较大、推理时间较长。因此,本文针对接线图识别任务分辨率高与信息密度大的特点,在重叠滑窗机制前先按接线图尺寸进行分级预处理,具体做法为:当输入接线图的高或宽大于10 000 像素时,先使用5×5 的卷积核进行膨胀处理;当输入接线图的高或宽大于6 000 像素且小于10 000 像素时,则先使用3×3 的卷积核进行膨胀处理,再将输入接线图的最长边缩小至3 000 像素,另一边按原接线图高宽比例缩小。参考附录A 图A1 可知,左图为无膨胀处理、直接整图压缩后的局部图,右图为先膨胀处理再整图压缩后的局部图。对比可见,膨胀处理有效减少了图像在缩放过程中的信息损失。
2.2 文字识别
基于上述图元识别方法可以提取到接线图中所有的文字图片,因此,电网厂站接线图中的文字识别可视为对获取的文字图片进行多分类。本文通过设计合适的预处理环节,基于CRNN 框架和迁移学习的思想,实现了对文字图片的内容识别。
区别于传统的CRNN,本文采用分层解冻的方法对CRNN 进行训练(分层解冻式训练步骤见3.2.1节)。为提高训练效果,本文对文字图片进行了预处理操作。除此之外,本文采用迁移学习的思想,将通用文字特征和电网领域文字特征融入模型,有效提升了电网厂站接线图中文本识别的准确率。
2.2.1 CRNN 框架
本文文字识别部分所采用的CRNN 框架[15]主要包括三部分:卷积神经网络(CNN)卷积层实现对输入图像的特征提取,得到特征图;双向循环神经网络(RNN)层实现对特征向量的预测,得到各特征向量的概率分布;时序联结分类损失函数(CTC Loss)转录层则根据各特征向量的概率分布,得到相应的标签序列,并结合序列合并机制,输出最终的预测文本。
2.2.2 预处理
在进行文字识别模型的训练之前,需要对接线图标注所得的文字图片进行预处理,包括填充、自适应二值化以及分类膨胀3 个环节。
1)填充
填充环节的具体操作为:在图片周围添加n维背景像素(n一般取1~5 的整数),通过背景像素的填充,可以使得距离边框很近的边缘文字与边框分离,提高边缘文字的识别准确率。
2)自适应二值化
自适应二值化的具体操作为:首先,对文字图片进行灰度化;然后,采用大津算法(OTSU)求取图片二值化的分割阈值[23];最后,进行二值化处理。
自适应二值化环节可以根据图片的实际情况凸显文字特征,同时具有降噪的效果,排除了一定的干扰信息,有助于文字识别模型的学习。
3)分类膨胀
分类膨胀的具体操作为:根据图片大小,选取图片分类阈值h1=50、h2=100,将图片按照式(1)分为3 类:
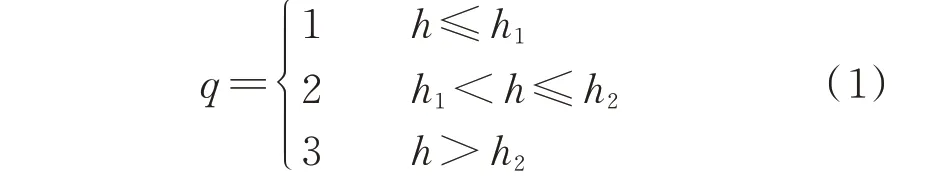
式中:q为图片分类的类别号;h为图片高度。根据图片所属类别号q,使用3×3 的卷积核对图片进行q−1 次 膨 胀 处 理。
由于文字图片最终需要压缩为统一高度h=32,故分类膨胀环节可以避免较大图片在压缩过程中信息的丢失,提升模型的学习效果。
2.2.3 迁移学习
在进行文字识别模型的训练时,由于电网接线图文字图片数据量有限,使用电网接线图文字图片训练出的模型识别准确率不高,特征提取不够充分。目前,大型的中文识别数据集包含数据量充足的通用文字图片。为了解决数据匮乏的情况,本文将通用文字图片视为源域、将电网厂站接线图文字图片视为目标域进行迁移学习,提升电网厂站接线图文字的识别准确率。图3 为迁移学习示意图。
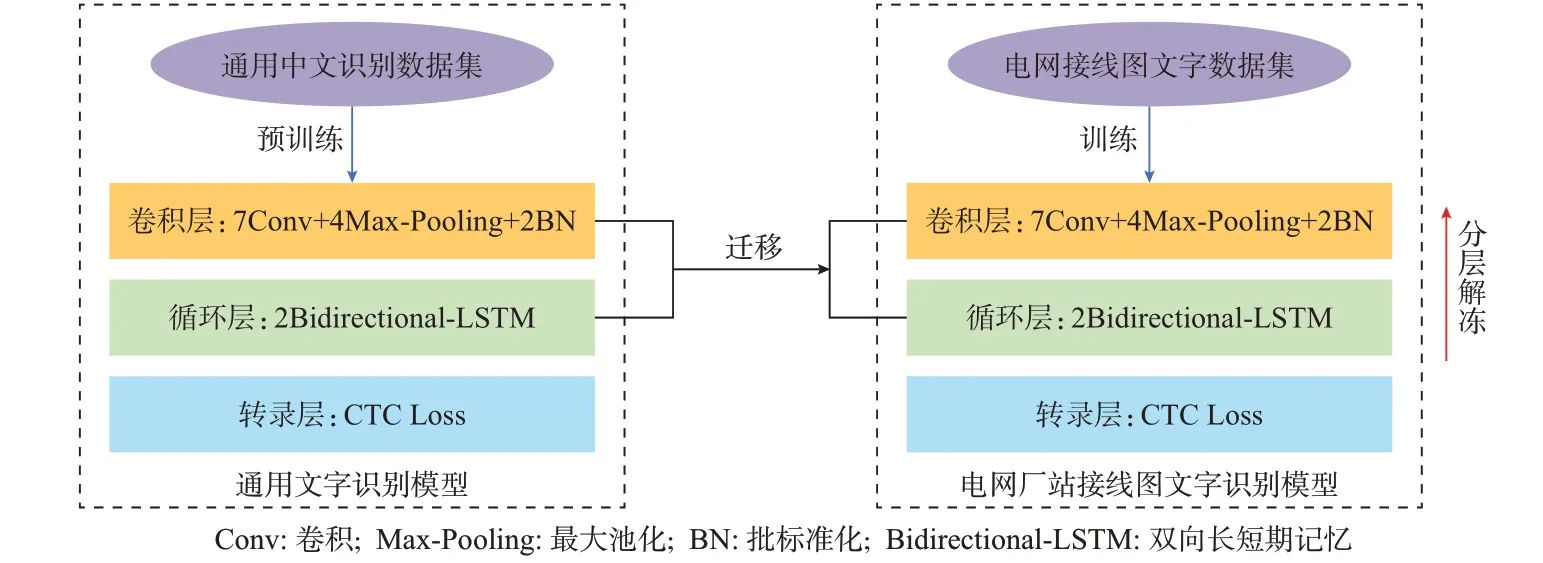
图3 迁移学习在电网厂站接线图文字识别中的应用示意图Fig.3 Schematic diagram of application of transfer learning to text recognition of wiring diagram for power plant and substation
迁移学习的基本步骤如下:
1)利用中文识别数据集Synthetic Chinese String Dataset 对模型进行预训练,该数据集数据量十分庞大且种类丰富,得到的通用文字识别模型学习了大量的通用文字特征,可以很好地进行通用文字识别。
2)保存通用文字识别模型的卷积层和循环层网络权重,通过将权重载入电网厂站接线图文字识别模型,实现迁移过程。迁移步骤可以破除电网接线图文字特定场景的知识局限,同时也使模型的初始性能更高、提升速率更快、收敛效果更好。
3)在迁移后的模型基础上,利用电网接线图文字图片对模型进一步进行分层解冻式训练:先冻结CRNN,再从后向前依次解冻网络各层,分别进行数个轮次的训练,最终选取对测试集识别准确率最高的模型。电网接线图文字图片对模型的进一步训练使得模型充分学习电网接线图文字的实际特征,将通用文字特征同电网领域文字特征相结合,实现对电网接线图应用场景下文字的高准确率识别。
2.3 接线识别
接线识别部分是建立在图元识别和文字识别已完成的基础上,实现母线识别、连接线检测、拓扑关系检测3 个功能。本文在处理接线识别中,分预处理、拓扑检测、后处理3 个步骤进行,关键是模仿电网接线图专家的经验知识进行判断,构建“知识库”,经过“推理”完成对接线关系的识别。
2.3.1 预处理
在进行接线拓扑关系识别前,为了减少干扰,提升识别准确率,需要进行以下预处理操作。
1)图像灰度转换处理:电网厂站接线图为红黄蓝(RGB)三通道图像,对图像进行灰度转换处理,能够简化图像矩阵,减少图像处理运算量,加快运算速度。
2)去除干扰项:采用直线检测时,图元、文字以及接线图外围的直线部分都会被检测出来,为了避免干扰,本文在直线检测前先将此类干扰项涂白,也即置零给定坐标框内的像素。
3)直线检测、分类和交叉直线切割:为了便于后续开展“拓扑检测”工作,需要对检测出的直线进行分类,对交叉直线进行切割,具体步骤如下。
步骤1:直线检测。使用直线检测算法(LSD)对处理后的厂站接线图进行直线检测[24],并把检测出的直线存储至直线列表中(存储直线两端点坐标)。
步骤2:直线分类。为了便于后续的拓扑关系检测,根据直线两端的坐标关系将识别出的直线分为垂直直线和水平直线。
步骤3:交叉直线切割。由于交叉直线使得电网厂站接线图存在复杂的多图元拓扑关系,因此,本文将交叉的直线切割为独立的直线段,再根据领域知识进行接线关系识别。
2.3.2 拓扑关系检测
经过预处理阶段的直线操作后,需要对直线连接的图元或直线的拓扑关系进行挖掘。
由于一条连接线其中的一个端点只能与一个图元匹配,或者与一条/多条连接线匹配,因此对所有直线段进行图元或其他直线段端点的匹配,融入“知识库”的规则为:遍历所有直线段,先尝试将直线段其中的一个端点与图元匹配,匹配的规则为若直线段的端点与图元的距离小于设定值,则匹配成功;若匹配失败,尝试与其他直线段的端点进行匹配,匹配规则为若一条直线段的某个端点与另一条直线段的某个端点的距离小于设定值,则匹配成功;若一条直线段的2 个端点都能与图元或者其他直线段的端点进行匹配,则将这条直线段添加进连接线列表中。
需要说明的是,经过推理引擎即可检测得到拓扑关系,此时的拓扑关系仍以“直线-图元”和“直线-直线”的形式存储,尚未转化为“图元-图元”的形式。
2.3.3 后处理
为了进一步提高接线识别的准确率,排除非典型图元的干扰(如接地变/站线变的连接线),完成上述步骤后需要结合电网厂站接线图领域知识/规则进行后处理,融入“知识库”的规则如下:
1)对跨越母线直线进行重新拓扑连接
由于在预处理阶段中已对所有交叉直线进行了切割处理,但跨越母线的直线在电气连接关系上是相连的,因此,跨接线的识别和重连需要结合电力领域知识进行区分。
根据国家电网公司赛题中提供的接线关系规则,连接线与母线之间的关系可分为以下3 种(也可根据具体电网厂站接线导则归纳)。如图4 所示,当连接线与母线成“T”字交叉关系时,连接线与母线为联通关系;当连接线与母线成“十”字交叉关系且连接线的2 个端点均连接了图元时,连接线与母线为联通关系;当连接线与母线成“十”字交叉关系且连接线的2 个端点中有一个连接了图元时,连接线与母线不为联通关系,该连接线为跨越母线直线。
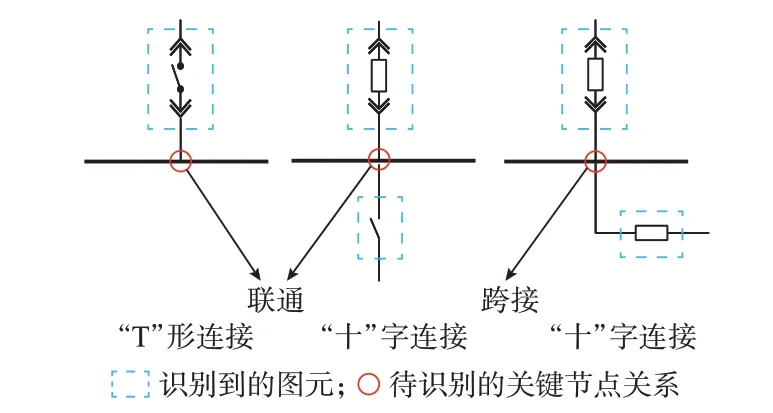
图4 嵌入电气领域知识的接线关系识别示意图Fig.4 Schematic diagram of wiring relationshiprecognition embedded with electrical domain knowledge
2)排除非典型图元对接线识别的干扰
非典型图元及其接线往往对接线识别造成干扰,因此需要根据文本信息和连接线信息,找到非典型图元及连接到非典型图元的接线并删去。
第1 种为与典型图元具有较高特征相似程度,容易在图元识别阶段被误识别的图元(如接地变/站线变的图元),这种图元的连接线数量往往和它近似的典型图元不同,因此可以根据图元识别模型和文字识别模型分别得到该图元的连接线数量以及文字信息,结合接线规则(专家知识)进行判断,自动删除该图元以及与它相连的连接线;第2 种为无法在图元识别阶段识别出的非典型图元(如避雷器的图元),这类图元由于未被涂白,其像素信息仍保留在图中,运用直线检测可能会得到分离的直线,产生冗余的连接线树,从而影响拓扑关系的结果,因此需要进行连接线剪枝处理,删去这部分冗余的直线。
3)去除孤岛拓扑
由于图元识别得到的框存在一部分偏小的情况,导致图元并未被完整涂白,在后续直线检测中可能会检测出干扰直线。这类干扰直线本身是图元的一部分,在拓扑关系检测中往往会被检测出只与它本身所属图元相连,出现孤岛拓扑的情况。为了解决这种情况,采取遍历所有拓扑关系的方法,最后删除只有一个图元的拓扑关系。
为了便于读者理解,在附录B 中结合具体实例给出了电网厂站接线图“接线识别”的完整流程。
3 算例分析
为了验证所提电厂接线识别方法的有效性,本文分图元识别、文字识别、连线识别三部分分别设置消融实验并进行分析。
本文采用的数据集来源于国家电网的真实运行场景,共有101 张大小、规范不一的电网厂站接线图,格式为JPG 或PNG。接线图大小分布较广,能有效验证本文设计的多种算法对于接线图大小的鲁棒性。使用Labelimg 软件对数据集进行标注,共标注约18 700 个标注框,包含的种类有断路器、隔离刀闸、接地刀闸、两卷变、三卷变、电容器、电抗器、母线、线路、发电机、文字等。对比接线图大小与图元标注框大小可知,大部分图元标注框的宽高与接线图的宽高比例均小于0.1,且接线图大小为模型输入大小的3~34 倍,符合“大图像小图元检测”的任务设定。
3.1 图元识别实验
3.1.1 实验设计
为验证提出的分级预处理以及结合YOLT 重叠滑窗机制的效果,实验数据集涉及的10 种关键图元对应的大小统计表如附录C 表C1 所示,训练集和测试集划分如附录C 表C2 所示。本文设置4 个对比组,在各对比组中,从训练集中随机抽取10%样本作为验证集,先冻结 YOLOv4 模型的CSPDarknet53 网络部分,单独训练模型的SPP、PAN 等其余模块50 轮,再解冻特征提取部分,对整个模型训练50 轮,最终选取验证集中损失值最小的模型。其中,对比组3、4 的滑窗重叠率均设为0.4。
3.1.2 评价指标
本文使用召回率、精确率、F1 值(F1-score)[18]、精确度均值(AP)评价图元识别模型性能[25]。需要注意的是,AP 为各检测图元精确率-召回率曲线下面积,平均精确度均值(mAP)即为各检测图元AP的均值[15]。本文计算的召回率、精确率、F1 值、mAP 的各阈值均为0.5。
3.1.3 实验结果与分析
各对比组中,模型在测试集上的mAP 如表1所示。
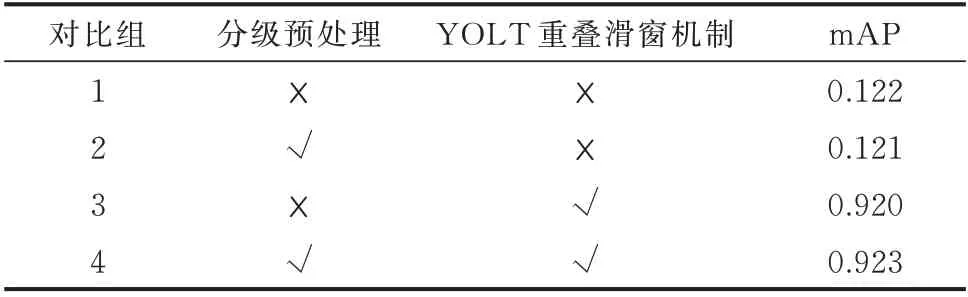
表1 不同对比组的mAPTable 1 mAP of different comparison groups
对比4 组性能,使用YOLT 重叠滑窗机制后性能提升明显,可有效解决“大图像小图元检测”问题。而分级预处理在不使用YOLT 重叠滑窗机制时几乎没有作用,无法缓解过多的信息损失;在使用YOLT 重叠滑窗机制时有较小的提升作用,原因是仅有极少的接线图尺寸过大且线条较细,大部分接线图在经过缩小后剩余的信息量分辨率仍较高,故分级预处理在测试中作用不明显。
为讨论滑窗切割重叠率的选择对模型性能的影响,对比组4 的重叠率依次取为0、0.1、0.2、0.3、0.4、0.5、0.6,对应测试集上的性能如表2 所示。
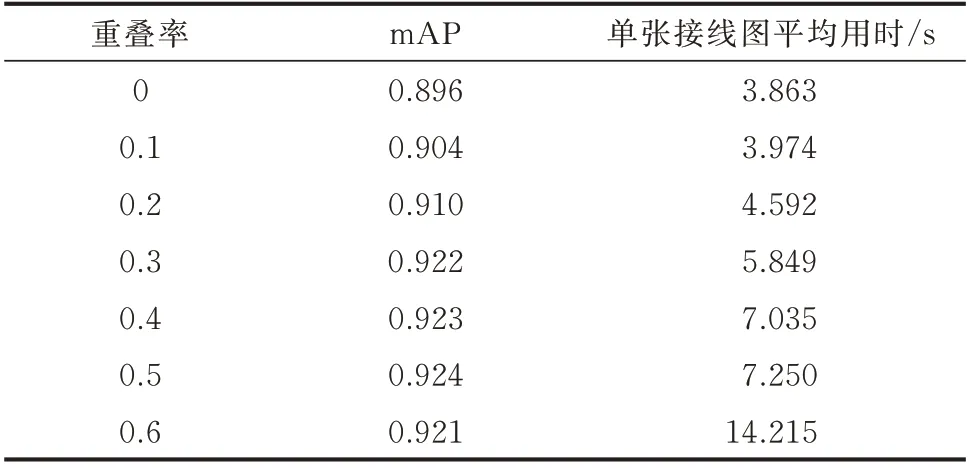
表2 不同的滑窗切割重叠率性能对比Table 2 Performance comparison of different sliding window cutting overlap rates
重叠率由0 上升至0.5 的过程中,测试集上mAP 逐渐升高,说明切割过程中适当的重叠可减少切割对图元完整性的影响且训练样本量的适当增加利于训练。重叠率大于0.3 后,增加重叠率带来的性能增益较小,且因子图数的增加导致单张接线图的预测时间过长。
考虑到长条形文字的识别效果,重叠率设为0.4较为合适,此时对应各种图元的AP、F1 值、召回率、精确率如表3 所示。

表3 对比组4 各类图元识别性能Table 3 Performance of various element recognition for comparison group 4
由于文字、接地刀闸、断路器图元的样本较多且较易检测,故综合识别性能最为突出。其余图元因样本量较少或相对尺寸较小,识别性能有所下降。从整体上看,多种接线图中的各种图元识别性能较好,样本量较少、相对尺寸较小的电容器与电抗器的AP 不低于0.83,且精确率均高于0.95,说明本文提出的接线图图元识别方法可有效应对输入的多种尺度的接线图,解决了该领域下的“大图像小图元检测”问题,在实际应用中鲁棒性强。
3.2 文字识别实验
3.2.1 实验设计
将标注得到的10 947 张文字图片按照9∶1 的数量比构建为训练集和测试集,训练集和测试集中的文字图片大小分布如附录C 表C3 所示。
为验证提出的迁移学习的效果,设置了如下3 个对比组:
1)迁移了Synthetic Chinese String Dataset 预训练出的模型,不采用电气厂站的文字图片训练集训练;
2)不迁移预训练模型,直接采用电气厂站的文字图片训练集训练;
3)迁移了预训练模型,并在此基础上进一步采用电气厂站的文字图片训练集训练。
在进行文字图片训练集训练时,采用分层解冻式训练:先冻结CRNN,再从后向前依次解冻网络各层,分别进行50 个轮次的训练,最终选取对测试集识别准确率最高的模型。
3.2.2 评价指标
文字识别实验采用识别准确率(正确识别的文字图片数量占识别文字图片的总数)作为评价指标。
3.2.3 实验结果与分析
各对比组中,模型在测试集上的识别准确率如表4 所示。
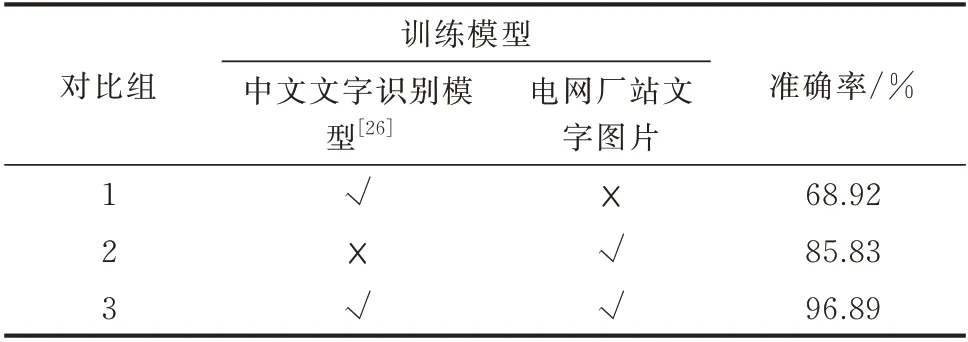
表4 不同对比组的识别准确率Table 4 Recognition accuracy of different comparison groups
对比3 组性能可以发现,对比组1 的模型对测试集的识别准确率不到70%,说明只迁移预训练的模型仅仅学习了通用文字特征,缺乏对电网领域文字实际特征的学习;对比组2 的模型充分学习了电网领域的文字特征,对测试集的识别准确率高于对比组1,但仍存在一定的提升空间;对比组3 则融合了对比组1、2 所学习的文字特征,将通用文字特征和电网领域文字特征融入模型,大大提升了模型的识别准确率。
3.3 接线关系识别
3.3.1 实验设计
为了验证预处理和后处理对含干扰图元的厂站接线图拓扑关系检测的有效性和准确性,本文对算例所使用的数据集分别采取4 个对比组,如表5 所示。由于本文所使用的LSD 需要以灰度图为输入,且预处理阶段对图像的灰度化处理更多的是为了简化图像矩阵、提高运算速度,对拓扑关系检测的精确性与召回率影响不大,因此,对比组3 和4 均具有图像灰度化处理操作。

表5 连接关系识别性能对比Table 5 Performance comparison of connection relationship recognition
3.3.2 实验结果与分析
在接线关系的4 种处理方式下,连接关系识别对应的精确率、召回率以及F1 值如表5 所示。
将对比组1 和3、2 和4 进行对比,可以发现,采取预处理操作后结果的精确率与召回率都得到了大幅度的提高。深入分析可知,这是由于未采取预处理过程中的交叉直线切割操作,拓扑关系检测只能检测出简单的“一对一”图元拓扑关系,无法检测出多个图元相连接的复杂拓扑关系,从而导致检测结果的精确率和召回率下降。上述结果表明预处理操作对厂站接线图拓扑关系检测有效性与准确性具有巨大的作用。
将对比组1 和2、3 和4 进行对比,可以发现,采取后处理操作后结果的精确率得到了较大幅度的提高,而对结果的召回率影响不大。经过分析,主要原因如下:
1)去除孤岛拓扑的操作。由于图元检测存在有些检测出的图元框偏小,导致图元并未被完整去除,在后续直线检测中可能会检测出干扰直线,这类干扰直线本身是图元的一部分,在后续拓扑关系检测中往往会被检测出只与它本身所属图元相连,使得出现孤岛拓扑的情况,而孤岛拓扑不会对正确的拓扑关系造成影响,只会导致检测出多余的拓扑关系,因此,采取去除孤岛拓扑的操作将会提高接线识别结果的精确率,而对结果的召回率影响不大。
2)采取跨越母线直线重连操作。由于厂站接线图存在一部分干扰图元,容易导致拓扑关系检测得到的初步结果出现错误的连接线树的情况,这类情况的特征是连接线树的末端并未连接图元。采取跨越母线直线重连操作后,把跨越母线且直线一端不是图元、在交叉直线切割过程中被错误切割并识别为两段的直线重新连接,因此增加了正确检测的拓扑数目,能够提高结果的精确率与召回率。
4 结语
本文提出了一套电网厂站接线图人工智能识别方法,并通过真实数据验证了方法的有效性,主要结论如下:
1)在图元识别方面基于结合分级预处理的重叠滑窗机制和YOLOv4 算法,有效地解决了电网厂站接线图中“大图像小图元检测”问题,实验表明本文方法的鲁棒性较强。
2)在文字识别方面采用迁移学习,提取电网接线图文字特征,使文字识别准确率大大提升。
3)在接线关系方面综合用预处理-后处理相结合的方法,深度融合电网接线图领域知识,弥补了图元识别、文字识别中存在的缺陷,进一步提升电网厂站接线图的识别效率。
为进一步提升接线图识别准确率,针对图元和文本错检问题,后续可以采取数据增强的方式,增加训练样本丰富度,在接线识别方面归纳更多专家知识,提高识别模型的鲁棒性。
本文在开展实验过程中得到“国家电网调控人工智能创新大赛”提供的数据支持,特此感谢!
附录见本刊网络版(http://www.aeps-info.com/aeps/ch/index.aspx),扫英文摘要后二维码可以阅读网络全文。
