结合短文本语义的图查询可视分析系统
2023-01-31秦绪佳
童 宁,徐 珊,汤 颖,秦绪佳
(浙江工业大学 计算机科学与技术学院,杭州 310023)
1 引 言
图数据包含丰富的信息,人们可以使用图查询相关技术来从图结构数据中挖掘到想要的信息.信息网络是一种具有图结构的数据,在实际应用中,大多数的信息网络是异构的,称为异构信息网络,例如影视信息网络、蛋白质结构网络、文献信息网络等.这类网络中的节点和边并不是单一类型的,如在影视信息网络中,节点有“电影”和“影人”2种类型,边有“参演”和“执导”2种类型.节点和边的多样性使得对异构网络的挖掘相较于同构网络更具有挑战性.图查询作为一种常用的异构网络挖掘方法,也面临着节点和边多样性的问题.倘若在进行图查询时不区分网络中节点和边的类型则会损失这些不同的类型所蕴含的语义信息.
在异构信息网络中,节点间的语义关系不但与节点和边类型相关,还与节点属性相关.以影视信息网络为例,电影的简介是电影节点的属性之一,以文本的方式来描述电影的内容,该文本属性能够影响到节点间的关系模式.举例来说,两位影人通过一部电影产生了合作的关系,连接的电影可以是电影A,其文本属性将其描述为关于家庭的喜剧电影,也可以是电影B,其文本属性将其描述为关于校园的爱情电影.当选择电影A作为两位影人之间的连接节点时,他们之间的关系可以被描述成“两位影人合作了一部家庭喜剧类的电影”.当选择电影B时,两位影人之间的关系可以被描述成“两位影人合作了一部校园爱情类的电影”.因此,使用图查询技术挖掘异构信息网络中的关系语义时需要考虑节点文本属性的影响.而以往的异构网络图查询工作往往未结合节点文本属性[1,2],这在一定程度上会影响对异构网络中蕴含的丰富语义信息的分析和挖掘.
由于异构信息网络包含着复杂的类型信息和属性信息,对异构信息网络进行图查询需要解决以下问题:
1)查询输入的问题.常见的查询语言输入和构建查询模板输入都需要用户额外学习查询语言和网络模式.由于异构信息网络的复杂性,对异构信息网络进行查询时,需要构建更复杂的查询模板.这给普通用户带来了一定的负担.
2)不同语义关系组合的问题.在异构信息网络中,两个对象间存在多条、跨越多个节点类型的语义关系.传统的异构网络图查询通常基于元路径来表达这些语义关系,但是节点的文本属性也能对查询对象的语义关系造成影响.因此,在图查询的过程中需要在计算元路径重要度的同时结合文本属性从而提高查询准确率.
3)对查询结果的结构信息和语义信息进行分析.查询得到的结果子图具有拓扑结构特征,而且节点文本属性包含了重要的语义信息.因此,结合结果子图的拓扑结构信息和语义信息对查询结果进行分析对于用户快速理解网络的异构关系模式非常重要.
为了解决上述问题,本文在图查询各阶段任务的驱动下,设计并实现了一个针对异构信息网络的图查询可视分析系统HINQVis(heterogeneous information network query visualization system).首先,针对图查询输入阶段的问题,本文从简单的用户输入中提取可能的关系模式,使用元路径表示这些关系模式,并结合用户输入的短文本计算元路径的重要度来衡量不同关系模式的重要程度,在系统中使用模式视图展示元路径和重要度.其次,在查询过程中,根据元路径的重要度结合多条元路径,得到更复杂的查询模板用于查询.最后,在查询结果分析阶段,提取结果子图中的拓扑结构特征并使用总览视图和子图视图进行展示,使用细节视图对结果子图中节点的相关属性进行可视化,通过总览视图、子图视图和细节视图间的联动交互探索查询结果中潜藏的信息.
本文提出了一种结合短文本的元路径重要度计算方法,在计算元路径重要度时能够将用户输入的短文本与节点的文本属性相结合;实现了一种结合多条元路径的实例生成和向量化方法,能够根据元路径的重要度生成查询实例并将其向量化;设计并实现了一个针对异构信息网络的基于图查询的可视化分析系统,对查询结果进行展示,供用户交互探索.
2 相关工作
2.1 图查询输入
常见的图查询输入方式有查询语言输入,如SPARQL[3],XPATH[4],XQUERY[5].但是这些查询语言的使用需要研究人员有着相关的专业知识,因此为了简化查询输入,一些图形工具被开发了出来.Ng等[6]开发了FGreat框架,能够交互式地自动完成图查询.Lissandrini等[7]通过直观的建议来对用户的查询进行扩展,以帮助用户探索知识图谱.Qiu等[8]将具有复杂语义的问题转化成查询图,以对知识图谱进行图查询.Huang等[9]提出一种跨语言的检索方法,能解决用户输入与查询内容语言不不同的问题.Orko[10]能够从语音输入中提取出目标节点进行查询.VIGOR[11]从用户输入的查询语言中提取查询示例,然后将查询结果可视化并进行分析.Wang等[12]简化了SPARQL查询来帮助用户对知识图进行查询.Jung等[13]提出了一种将韩语查询直接转化为SPARQL查询的方法.Hu等[14]将关键词搜索和SPARQL语句结合,提出了一种准确率更高的问答系统.Shuai等[15]设计了一个针对电影数据的问答系统,能够将用户输入的中文问题转换成知识图查询语句,在Neo4j图数据库中查询答案.Eviza[16]通过用户与系统之间的交互式对话,不断更新系统的查询能力.
由于自然语言的便利性,本文的工作在图查询阶段使用自然语言作为目标节点对和其约束的输入.同时为了使系统更加简便,与上述部分工作不同的是,本文的工作不需要用户构建查询模板.
2.2 子图查询
子图查询一般可以根据其查询方式的不同,分成关键词子图、凝聚子图以及图模式匹配3大类.凝聚子图查询(cohesive subgraph search)[17]关注于图数据中联系紧密的部分子图.关键词图查询(keyword search on graph)[18]能够根据输入的关键词,在图数据中搜索匹配关键词的子图,这些子图的顶点满足了关键词带来的约束.图模式匹配(graph pattern matching)能够根据输入的模式图,从图数据中搜索出拥有相同模式的所有子图.然而该方法面临的困难一是大部分图数据中的顶点和边过多,二是根据不同的匹配语义会形成图模拟[19]、子图同构[20]和强模拟等问题[21].Gao等[22]提出了“时间尊重流程图”的概念,在带有时间属性的图数据上进行图模式匹配.Liu等[23]提出了一种多约束的图模式匹配方法,通过“强社交图”的概念来探索大型的社交网络数据.DiffWalk[24]以图数据中影响最大的节点作为起始,通过扩散游走来遍历大型图数据,从而达到图模式匹配的目的.
图模式匹配查询被广泛应用于大规模图数据的挖掘.本文使用图模式匹配进行子图查询,并且通过借助节点对的相似性,使其避免了子图同构等问题来完成子图查询.
3 系统任务分析和概述
3.1 任务分析
在图查询输入、子图查询和查询结果分析3阶段任务驱动下,本文为HINQVis系统定义了如下任务,以指导系统的设计:
任务1.自动地从查询输入中提取用户所希望的关系模式.在本文的图查询过程中,用户首先输入一对或者一个实例节点,然后通过一句短文本对其所希望的查询结果进行描述,该输入方式通俗易懂且便于操作.系统需要根据用户的输入,从中提取出所有可能的关系模式.
任务2.支持用户以交互的方式构造查询模板.根据用户的输入可能会提取到较多的关系模式,若结合所有提取到的模式进行查询,则很可能会得到很多用户不希望的结果.所以系统需要向用户提供一种交互方式,让用户选择感兴趣的关系模式,再根据用户所选的结果进行后续的图查询.
任务3.对子图特征进行概述,提供一个自上而下的探索方式.用户难以从相似的拓扑结构中看出各个结果子图的特征,所以系统在得到查询结果之后,需要向用户展示不同子图的特征,让用户可以根据此特征来对不同的查询结果进行有效区分.
任务4.对查询得到的所有子图的细节信息进行有效展示.在通过查询得到结果子图后,用户需要通过观察节点的 详细信息来理解查询的结果.所以系统需要在展示结果子图时,以直观的方式向用户呈现每个结果子图中各个节点与边的细节信息.
任务5.对查询得到的各个节点的属性信息进行有效展示.本文通过用户输入的短文本来约束查询结果,通过观察节点属性中包含的文本属性可以分析出短文本约束的效果.所以系统需要有效地向用户展示查询结果中节点的文本属性,同时也需要将节点的其他属性同步地呈现出来.
3.2 系统概述
HINQVis系统概览如图1所示,针对每个任务,本文都设计了相应的视图来满足需求,这些视图分别为输入视图、模式视图、总览视图、子图视图以及属性视图.在输入视图中,用户可以输入希望查询的节点以及用来约束的短文本;在模式视图中,用户可以选择其感兴趣的关系来构建查询模式;在总览视图中,用户可以观察到查询结果子图的分布特征;在子图视图中,用户可以观察到节点的连接关系及其细节信息;在属性视图中,用户可以观察到节点的属性信息.
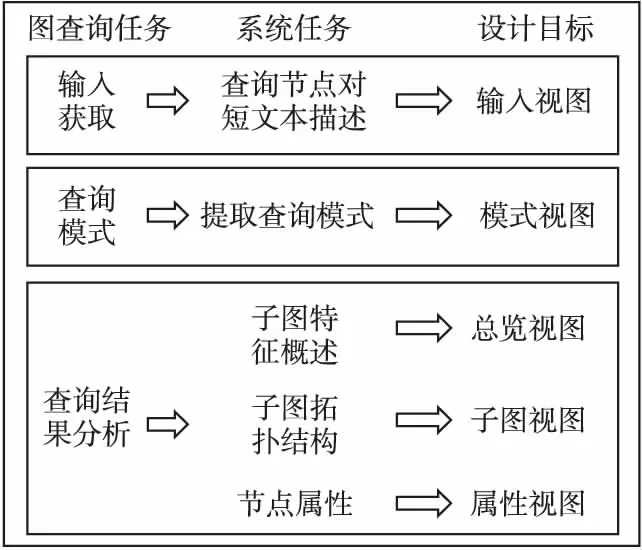
图1 可视分析系统组成Fig.1 Composition of the visual analysis system
4 结合短文本的图查询实现
本节介绍如何结合短文本生成元路径以及其重要度.进一步,本文结合多条元路径进行查询并对查询结果进行挖掘.
4.1 元路径及重要度生成
两个节点间存在多条元路径,这些元路径的语义以及重要度受到多种因素的影响.下面介绍如何结合多方面因素生成元路径并计算重要度.
4.1.1 元路径及其重要度的定义
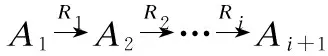
根据Zhu等[2]的研究,元路径的重要度受到长度、路径实例数量和路径的稀有度的约束.因此,本文根据这3项约束,将连接给定节点对〈s,t〉的元路径P的重要度Is,t(P)计算函数定为:
Is,t(P)=Ss,t(P)×Rs,t(P)×fPenalty(|P|) (P∈Ps→t)
(1)
其中,Ps→t是连接节点s和t的元路径集合,元路径P是该集合中的一个元素.fPenalty(|P|)表示元路径P的长度衰减函数,Rs,t(P)表示的是元路径P的稀有程度,Ss,t(P)则是一个元路径重要度支持函数.
本文在构建元路径重要度支持函数Ss,t(P)时结合了电影节点的文本属性.元路径P中的电影节点包含了电影的实例,本文通过计算用户输入的短文本与电影实例的文本简介的相似度来对该重要度支持函数进行约束.
首先分别将用户输入的短文本约束以及电影的文本简介计算成向量,然后以向量相乘的形式得到两者的相似度,最后根据相似度排名筛选出受到短文本约束的电影节点.针对输入的短文本查询,使用结巴分词算法对短文本进行分词,并使用定向Skip-Gram模型(directional skip-gram,DSG)[25]计算出每个词的向量表示.之后将所有词向量的平均值作为短文本的句向量,其计算公式为:
(2)
其中,Vi为短文本分词后的其中一个词向量,VQ为短文本的句向量,n为短文本分词后的词数量.
电影节点的文本简介记作T,经过结巴分词后可以得到简介的词序列,接着为每个词计算其TF-IDF值,作为该词的权重值.然后使用DSG模型计算出没个词的到词向量.最后将每个词向量与其相应的TF-IDF值加权求和取平均得到文本简介的句向量,其计算公式为:
(3)
其中VTj是文本简介分词后的其中一个词向量,wj是当前词对应的TF-IDF值,VT是文本简介的句向量,m是文本简介分词后的词数量.
在经过以上计算得到查询的短文本和电影简介的句向量后,计算两段文本的相似性,公式为:
(4)
元路径的重要度支持函数定义为:
Ss,t(P)=fstrength(P)×fMNIs(P)
(5)
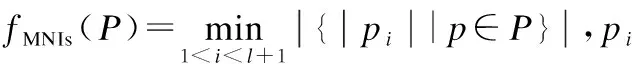
(6)
其中pA为节点A的实例集合,是Vu是A中每个电影节点实例的文本向量,VQ是查询输入的短文本向量.当A为电影节点时,本文基于A中所有实例与用户输入的短文本的相似性来计算强度权值,若两个文本向量越相似,fsim的值就会越小,随之fstrength的值就会越大,最终会作用到元路径重要度支持函数上,Ss,t(P)的值也就越大.当A为影人节点时,本文通过A的出/入度的最小值的倒数来计算fstrength.在Zhu等[2]的研究中,fstrength仅由节点A出/入度的最小值来计算,该方法只能基于元路径挖掘异构网络的结构信息,无法引入节点的文本属性,而本文的方法能够同时保留网络的结构信息和节点的语义信息.
4.1.2 元路径的生成过程
本文通过一种基于贪婪树的数据结构来生成连接输入节点对的元路径,总共分为3个阶段.第1个阶段,针对用户输入的节点对和短文本约束,系统会生成一棵贪婪树.以输入节点对“张艺谋”和“巩俐”为例,图2给出了贪婪树的生成过程,其中贪婪树中对象节点的结构如图2左上角所示.一个贪婪树节点包含了两个信息,一是在路径扩展过程中所生成的以键值对(Key-Value)的形式储存的节点,二是用来表示当前的贪婪树节点能否继续向下扩展的“True/False”标记——“True”还能继续扩展;“False”则表示不能,此时的节点可能已经达到了元路径的最大长度也可能是元路径的终点(目标节点出现在Value中).本文将异构信息网络中的边类型作为连接贪婪树节点的边.图中Value列表中存储的是当前节点key根据相应的边可达的节点.
第2个阶段对第1阶段中生成的贪婪树进行遍历从而得到一系列由节点ID组成的路径;然后从遍历得到的路径中根据边来推导出组成路径的节点类型,举例来说,如图2中的根节点通过边“Direct_in”连接到其子节点,则可推断出根节点的类型为影人,子节点的类型为导演;最后将节点的类型连接成元路径,在此阶段中,会有多条不同的元路径被生成.第3个阶段统计贪婪树中每个节点所含的实例节点数量,从而得到用来计算元路径重要度的各种参数.
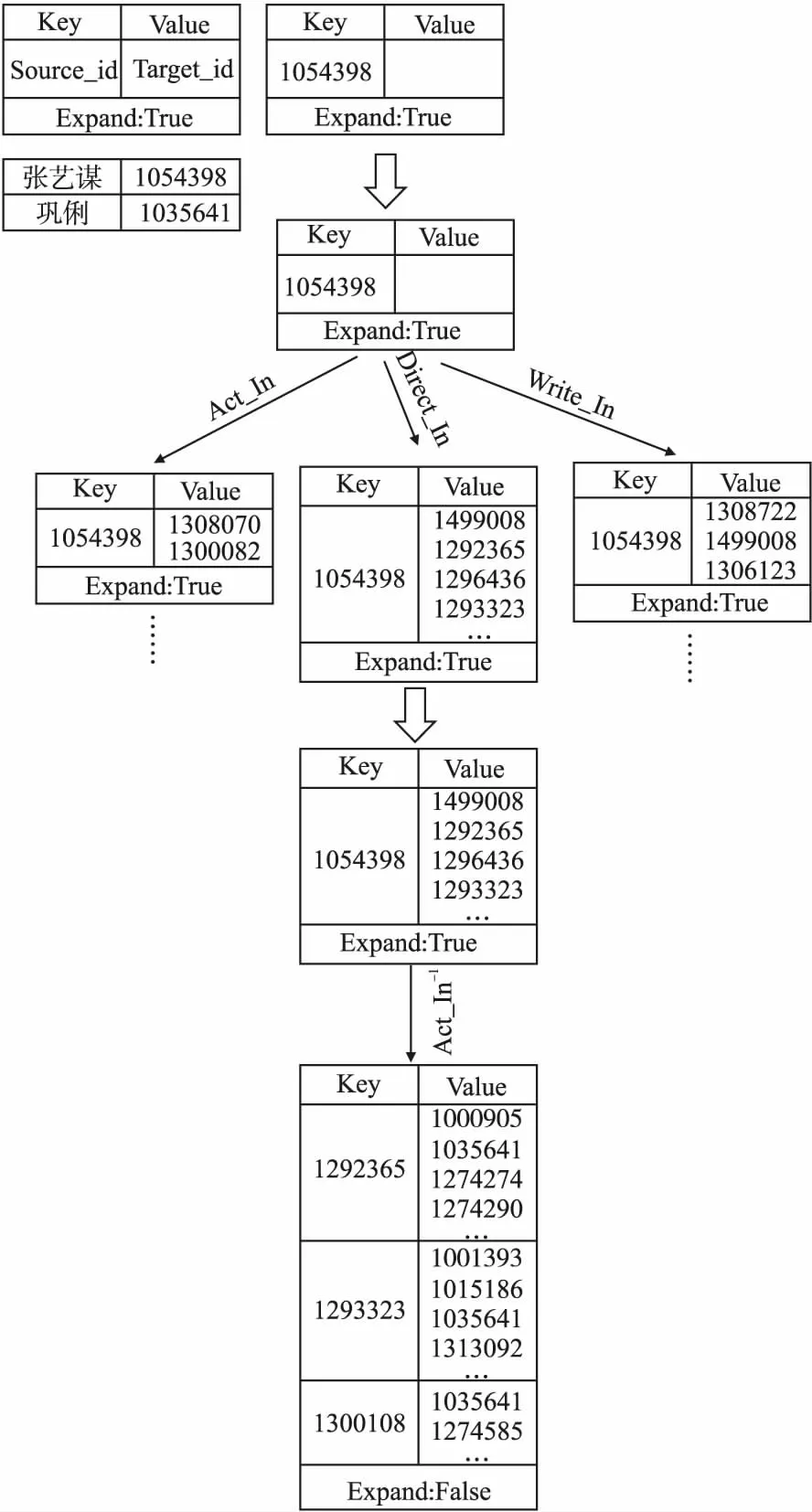
图2 贪婪树结构Fig.2 Greedy tree structure
4.2 多条元路径结合的查询结果生成
本文将图查询的结果称为实例节点对,该节点对之间的语义与输入的节点对之间的语义相同,其语义由多条元路径组合而成,且受到输入的短文本的约束.同时本文将节点对之间的连接关系符合某条元路径的程度定义为节点对在该条元路径上的相似度,通过搜索在每条元路径上都有较高相似度的节点对,来得到符合要求的查询结果.节点对根据不同元路径的相似度计算公式为:
(7)
其中,ρei(vi,Ci+1)表示类型为Ci+1,通过边ei连接到节点vi
1http://39.105.145.46:8000/video/
的节点x的集合.Pi,n表示元路径中从节点Ci到Cn的子序列.α为固定参数,设置为0.5.当节点x的类型Ci+1为电影时,使用电影文本简介和查询短文本的相似度和∑fsim(Vu,VQ)来替代公式(7)中的|ρei(vi,Ci+1)|.
然后,本文使用一个线性聚合函数计算节点对s和t之间的相似度σ(s,t|P),将每条元路径相应的重要度作为相似度的权重,聚合函数为:
(8)
其中,Ij是通过公式(1)计算出的元路径Pj的重要度.
最后本文为每条所用到的元路径,针对每个影人节点计算一个相似度矩阵,用来表示两位影人之间的关系符合该元路径程度.元路径P的相似性矩阵Sp中每个元素的计算公式为:
(9)
每条元路径在第1次被生成时,就构建好与其对应的相似度矩阵.通过在每条元路径的相似度矩阵搜索非0的位置及其相应的值,就能很方便地找到在该元路径上相似的节点对及其相似度.
4.3 查询结果的特征提取和表示
本文基于查询结果的拓扑特征提取每个结果子图的特征向量,将其降维到2维后进行聚类操作来得到每个子图的特征分布.该过程可以被分为以下4个步骤:
步骤1.提取子图的拓扑特征.假设通过结合语义与多条元路径查询后得到了一系列节点对,每个节点对与连接它们的每条元路径形成一个结果子图,本文针对结果子图提取以下3个特征(所需的各个参数在生成贪婪树的时候统计得到):
1)节点出入度比值:该比值表示的是在当前集合中,能沿着元路径到达目标节点的成员所占的比例.节点ni的入度记为In(ni),出度记为Out(ni),出入度比值计算公式则为:
(10)
2)平均实例数:一条长度为s的元路径除去头尾后的序列记为{n2,…,ni,…,ns-1},序列上第i个节点的实例集合为ni,平均实例数的计算公式为:
(11)
3)与源/目标节点有着相同类型的节点数量:本文通过这两个特征来分别表示结果子图所包含的节点中与源/目标节点相似的个数.
步骤2.特征的向量化.针对每个查询得到的节点对,将其每条元路径上的子图特征以向量的形式记录下来,然后根据各条元路径的重要度对这些向量加权求和,最终得到了每个节点对所形成的结果子图的特征向量.
步骤3.降维.将每个查询结果子图的特征向量降维到2维以便于可视化.介于降维的时效性,本文选择主成分分析(principal component analysis,PCA)进行降维.
步骤4.聚类.本文使用速度较快的k-means方法对降维结果实行聚类操作.通过反复的实验本文发现,降维后的结果子图形成的聚簇个数通常元路径数量多1个,所以本文将k值定为元路径的数量+1.
5 可视化设计与实现
本节介绍可视化系统HINQVis的设计与实现,为了更好的展示,本文在网址1上发布了一个介绍视频来对系统的使用进行说明.
5.1 可视化系统的设计目标
设计目标1.便于操作的输入界面.为了便于用户操作,系统的输入不能使用过于复杂图查询语言,而是要用简单的自然语言作为输入.系统的输入应该仅包含必要的查询信息,即源/目标节点以及短文本约束.所以系统需要一个简洁且完整输入界面以接收必要的信息.
设计目标2.关系模式可视化.系统将元路径作为关系模式,需要将所有匹配查询条件的元路径及其相应的重要度展示出来.同时为了让用户自行构建想要的关系模式,系统还需要向用户提供一定的交互功能.
设计目标3.查询结果总览.根据“Overview first,zoom and filter,then details-on-demand”的设计准则,系统应该向用户提供一种自上而下的方式方式来探索查询得到的结果.所以系统需要先向用户呈现一个总览视图,再让用户根据这个视图来进行交互式探索.
设计目标4.查询结果细节特征可视化.查询得到的结果子图包含丰富的细节信息,包括拓扑结构特征与语义特征,因此系统需要针对两种细节分别向用户提供不同的视图来展示与分析.
5.2 可视化系统的设计
图3展示了HINQVis系统的界面,本文将在此对系统的各个视图进行详细的介绍.
在图3(a)是系统的输入视图,该视图能够让用户以自然语言的方式输入查询节点对和短文本.系统要求必须输入短文本对查询结果进行约束,但是对于输入的节点,系统能够支持“完整输入源/目标节点”、“仅输入源节点”与“仅输入目标节点”3种查询模式.
图3(b)是系统的模式视图.元路径能够表达节点间的连接模式,同时它也是一种图结构的数据,因此本文使用节点链接图进行可视化以更好地表达图数据.进一步,本文将每条元路径的重要度通过其右侧矩形的长度来表示,以便用户对不同元路径间的重要度进行对比.用户还可以勾选多条元路径对其进行组合,以得到自己想要的节点连接模式.
在图3(c)是系统的总览视图.查询得到的结果子图在被提取特征后,在总览视图中以散点图的形式被展示出来.系统通过聚类算法将散点图分割成不同的集群,并且使用不同的颜色对不同的集群进行编码,使用户能够直观地看出不同集群的分布.
图3(d)是在总览视图中选择某一集群后,该集群在指定元路径上的子图视图.本文使用桑基图来可视化结果子图的拓扑特征,以流的形式将查询得到的结果子图清晰地呈现给用户.
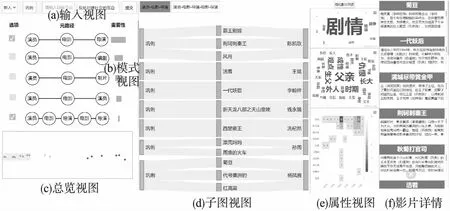
图3 本文系统界面Fig.3 System interface
本文在图4中给出了3种不同查询模式下对应的子图视图.在图4(a)是将源/目标节点完整输入时的子图视图,此时查询得到的所有结果子图中每个子图的首/尾节点与用户输入的源/目标节点的连接关系是相同的.在图4(b)是只输入源节点时的子图视图,此时查询得到的结果子图的首节点固定为输入的源节点,尾结点与首节点的连接关系符合用户在模式视图中构建的元路径模式.在图4(c)是只输入目+标节点时的子图视图,此时查询得到的结果子图的尾结点固定为输入的目标节点,首节点与尾结点的连接关系符合用户构建的元路径模式.视图上方的按钮可以将子图视图转换成与按钮相对应的元路径的形式显示.
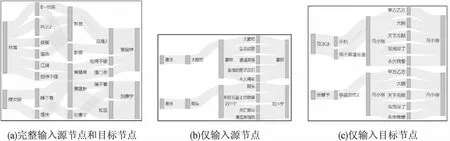
图4 不同输入形式的子图可视化Fig.4 Subgraph visualization of different input forms
如图3(e)和图3(f)所示,属性视图展示了查询得到的电影节点一些关键属性信息,这些信息能够体现出查询结果符合用户输入的短文本约束.首先本文通过词云来对查询结果中电影节点的类别信息进行展示,同时用描述类别的词的大小来编码属于此类别的电影数量,用户可以直观地看出不同集群中的电影在类别上的区别.然后,本文提取电影简介的关键词,再次使用词云对其进行可视化展示,并且将词的大小设计为关键词与用户输入的短文本的相似性,通过这种方法来呈现查询得到的节点对受短文本语义约束程度.最后本文统计当查询结果子图中所有电影的上映年份,以及在每个年份中每位影人参与的电影数量,通过像素视图的形式对这些统计信息进行展示,其中每一行对应了一个影人,每一列对应了一个年份,每个像素块的颜色深浅就表示了某位的影人在某年中参与的电影数量.图3(f)展示了查询结果中的电影列表,包含了电影的名称及简介.列表中电影的排列顺序是由电影与查询输入的短文本的相似度来决定,相似度越高,电影就越靠上.
6 系统评估
6.1 元路径有效性验证
实验通过将本文方法SMNIs(short-text strengthened-minimum instances,MNIs)与增强最小实例数(strengthened-minimum instances,MNIs)[2]、k最短元路径(k-shortest meta paths,SMP)[26]、结合路径长度与重要度的方法(strength-and-length-based versioned,SLV)SLV1[27]和SLV2[28]方法进行对比,来验证结合短文本生成的元路径的有效性.
实验使用了从DBLP数据集中抽取的子集.该数据集从DBLP数据集中挑选了4个领域的20个最具代表性的会议,然后提取其中的相关论文与作者,其统计数据如表1所示,其中还包含了332338条边.该数据集根据会议将作者的研究领域划分为数据库,数据挖掘,机器学习和信息检索4个领域.在该数据集中,有4236位作者被标记了其研究领域.本文的实验将每篇论文的标题视为短文本数据,在提取标题中的关键词之后与查询输入的短文本进行匹配.
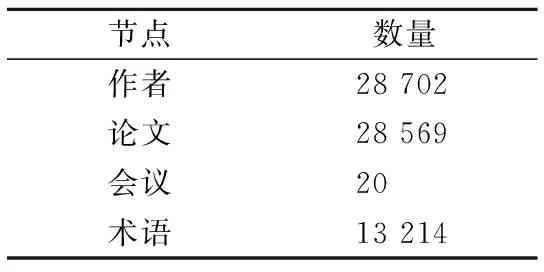
表1 实验数据集Table 1 Experimental data set
首先选择两位作者,分别是Philip S.Yu和Jiawei Han,其中Philip S.Yu的研究领域为数据库和数据挖掘,Jiawei Han的研究领域为数据挖掘.实验希望查询得到的作者节点对能够被输入的短文本所约束,使两者的研究领域都包含“数据挖掘”.
查询输入的节点对为

表2 节点对
然后本文根据各种方法计算得到的元路径重要度进行查询得到5组实验结果,将每个方法生成的节点对集合记为{〈s1,t1〉,…,〈si,ti〉,…,〈sn,tn〉},并对每个节点对使用公式(8)计算其相似度,其中〈si,ti〉表示查询得到的某一个作者节点对.当si的研究领域与ti的研究领域相同,且都为“数据挖掘”时,可以看作查询输入的短文本对该节点对进行了约束.本文将查询准确率定为节点对受短文本约束的比例,其公式为:
(12)
(13)
其中,d表示作者的领域,n表示查询得到的相似度排名靠前的n对节点对.
图5展示了取不同对数的节点对后统计查询准确率的结果.横坐标表示的是实验提取的n对查询得到的节点对,纵坐标则表示相应的查询准确率,即在所取的节点对中被短文本约束了的节点对的比例.从图中可以看出,使用本文提出的方法设定元路径重要度而查询得到的节点对能够更好地受到短文本语义的约束,特别是当节点对的相似性排名较高时,该方法得到的查询准确率达到其他方法的近2倍.

图5 实验结果统计Fig.5 Statistics of experimental results
6.2 案例分析
本文通过一个案例来展示HINQVis系统的使用方法,并对查询结果进行挖掘与分析.系统使用了豆瓣电影数据集,且能够实时地与用户进行交互.该数据集含有6794个影人节点和40661个电影节点,以及193194条电影与影人的关系.
用户首先需要在输入视图输入其想要查询的节点以及短文本约束.以仅输入源节点的查询模式为例,用户在输入视图的源节点方框处填入“巩俐”,在短文本方框处填入“反抗封建社会的压迫”.用户在完成输入之后点击“查询”键,系统便会在模式视图中生成了如图6所示的元路径及其相应的重要度.用户通过观察模式视图可以得知,“巩俐”在作为源节点时,她的身份只有“演员”,且在该视图中的长度为3的元路径的重要度比长度为5的元路径都高.为了探索“巩俐”与“导演”类型节点的合作关系,选择了在相同长度中重要度最高的2条元路径“演员—电影—导演”和“演员—电影—导演—电影—导演”作为模式用于之后的查询.
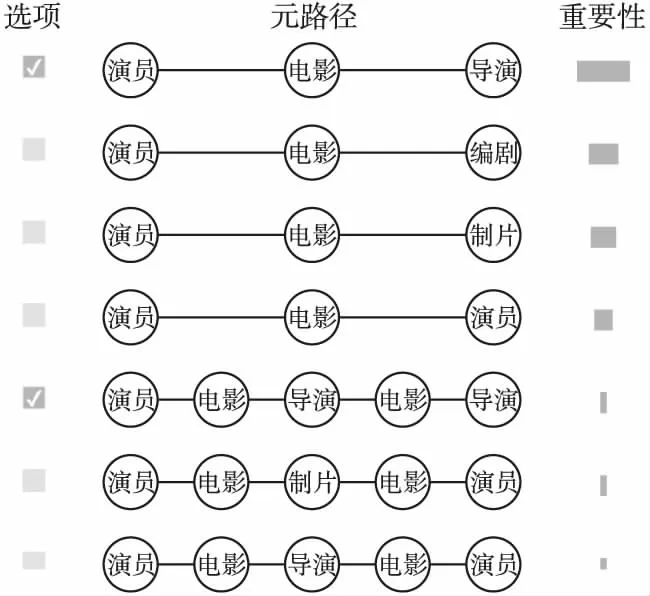
图6 显示元路径和重要度的模式视图Fig.6 Pattern view which shows meta-paths with importance

图7 查询结果特征总览视图Fig.7 Feature summary view of the query results
用户点击提交按钮后,系统生成了如图7所示的查询结果总览视图.查询得到的结果被分成了3类,视图中的每个散点表示1个结果子图.用户需要在总览视图选择一个集群,便可观察该集群的结果子图与属性信息.图8分别展示了3个集群的子图视图,用户通过观察子图视图的详细内容能够了解3个集群之间的差异:集群a中的电影节点大部分都是较为经典且评价较高的电影;在集群b和c中,与“巩俐”节点有着合作关系的“导演”节点都是香港的导演,且其电影节点的内容与集群a中的电影相差较大.这证明了本文在提取和表示查询结果特征上的有效性.
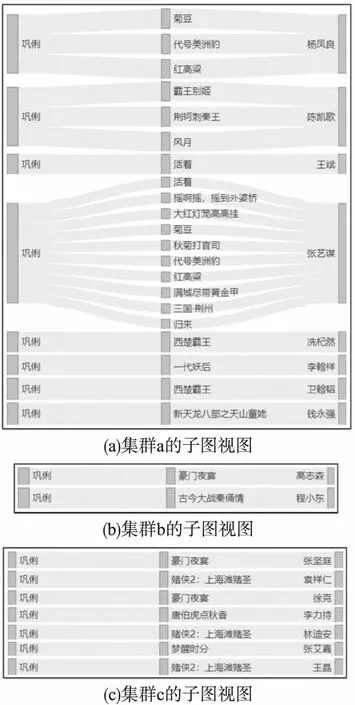
图8 不同类型集群的子图视图对比Fig.8 Comparison of subgraph views of different clusters
最后,观察如图9所示的属性视图.图9分别展示了3个不同集群的属性视图.通过对比可以发现,在第1行的类别词云视图中,集群a的“剧情”词云最大,表示其电影几乎都含有“剧情”的类别;集群b的词云大小分布较为平均,说明其电影的类别分布较为分散;集群c中的词云中“喜剧”与“奇幻”大于其他词,其中“喜剧”更加显著,表明其电影的类别以“喜剧”为主.用户能够从3个集群的词云中看出明显的不同,这进一步说明了本文在提取查询结果特征上的有效性.属性视图的第2行展示的是关键词词云,用户能够从中看出词云的内容与其输入的短文本约束存在着联系,这能够证明本文提出的方法在利用短文本语义计算元路径重要度后对查询结果有着较好的约束效果.属性视图的最后部分是一个像素图,统计了电影的年份属性,用户对其进行分析后可以发现3个集群在年份上的特征,集群a中包含了最多的“巩俐”参演的电影,且其时间跨度在3个集群中是最大的,从1987年至2000年都有分布,而在另外两个集群中,电影的上映时间都要早于1995年.
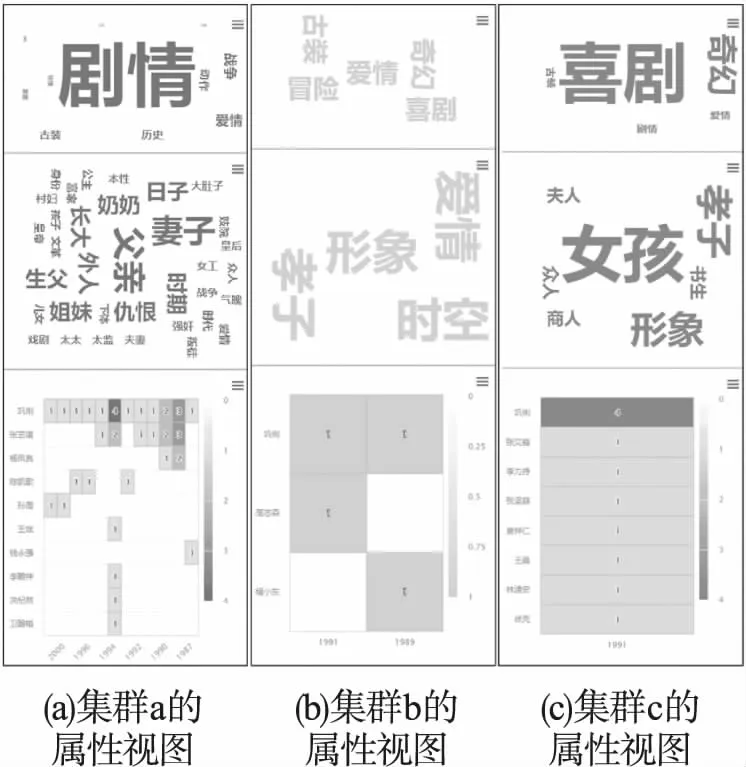
图9 3个集群的属性视图对比Fig.9 Comparison of attribute views of 3 clusters
7 结 语
本文提出了一种结合短文本的图查询方法,并在此基础上基于豆瓣电影数据设计并实现了一个图查询驱动的可视分析系统HINQVis.系统利用元路径表示节点间的关系模式,并结合节点的短文本属性计算不同元路径的重要度用于查询.针对结果子图的拓扑结构特征和语义特征进行可视分析.最后使用DBLP数据集的子集进行了验证实验,并使用一个案例介绍如何对查询结果进行可视分析.
未来的工作可以通过神经网络的方式学习元路径特征,利用注意力机制来得到元路径的重要度.同时在结合短文本语义进行查询时,还可以计算每个词的重要度,结合每个词不同的重要度来对结果进行语义匹配.研究短文本中每个词分别对短文本语义的重要度也是一个有价值的方向.
